kafka高吞吐量之消息壓縮
- 2020 年 4 月 24 日
- 筆記
- Java技術 技術管理

背景
保證kafka高吞吐量的另外一大利器就是消息壓縮。就像上圖中的壓縮餅乾。
壓縮即空間換時間,通過空間的壓縮帶來速度的提升,即通過少量的cpu消耗來減少磁碟和網路傳輸的io。
消息壓縮模型
消息格式V1

kafka不會直接操作單條消息,而是直接操作一個消息集合。
消息格式V2:
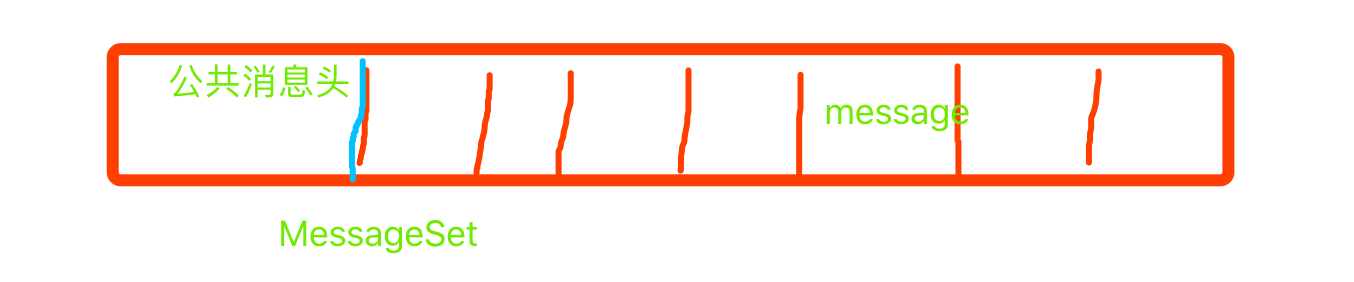
1, 抽取了消息的公共部分放到消息集合中;去掉每條消息的公共部分,減少了總體積。
2,消息的CRC校驗由對每一條消息,移動到了對消息集合進行校驗,減少了校驗次數,節省了cpu;
3, 對單個消息進行壓縮,放到消息的body欄位 pk 對消息集合整個進行壓縮 更好的壓縮效果;
壓縮過程模型

壓縮演算法比較
如何衡量一個壓縮演算法的好壞。

常見的壓縮演算法對比:
Zstandard 演算法(簡寫為 zstd)。它是 Facebook 開源的一個壓縮演算法,能夠提供超高的壓縮比

啟用壓縮場景
如果cpu負載比較高,不適合啟用壓縮;
如果頻寬不足,而cpu負載不高,最適合啟用壓縮,節約大量的頻寬;
盡量避免消息格式不一致帶來的解壓縮消耗。
小結
壓縮的目的是較少空間佔用,帶來傳輸速度的提升,但是需要消耗一定的cpu ;
是一種提高kafka消息吞吐量的有效辦法。
本節回顧了新版的kafka是如何對消息進行壓縮的,壓縮和解壓縮的流程是怎樣的,
然後對比了常見的4種壓縮演算法,根據具體的使用場景來選擇是否啟用壓縮,以及選擇合適的壓縮演算法。
然後給出了壓縮的配置參數,在producer和borker端都可以使用compression.type來設置。
原創不易,點贊關注支援一下吧!轉載請註明出處,讓我們互通有無,共同進步,歡迎溝通交流。
我會持續分享Java軟體編程知識和程式設計師發展職業之路,歡迎關注,我整理了這些年編程學習的各種資源,關注公眾號『李福春持續輸出』,發送’學習資料’分享給你!



