spark shuffle的寫操作之準備工作
- 2019 年 10 月 3 日
- 筆記
前言
在前三篇文章中,spark 源碼分析之十九 — DAG的生成和Stage的劃分 剖析了DAG的構建和Stage的劃分,spark 源碼分析之二十 — Stage的提交 剖析了TaskSet任務的提交,以及spark 源碼分析之二十一 — Task的執行細節剖析了Task執行的整個流程。在第三篇文章中側重剖析了Task的整個執行的流程是如何的,對於Task本身是如何執行的 ResultTask 和 ShuffleMapTask兩部分並沒有做過多詳細的剖析。本篇文章我們針對Task執行的細節展開,包括Task、ResultTask、ShuffleMapTask的深入剖析以及Spark底層的shuffle的實現機制等等。
Spark的任務劃分為ResultTask和ShuffleMapTask兩種任務。
其中ResultTask相對來說比較簡單,只是讀取上一個Stage的執行結果或者是從數據源讀取任務,最終將結果返回給driver。
ShuffleMapTask相對複雜一些,中間涉及了shuffle過程。
緊接上篇
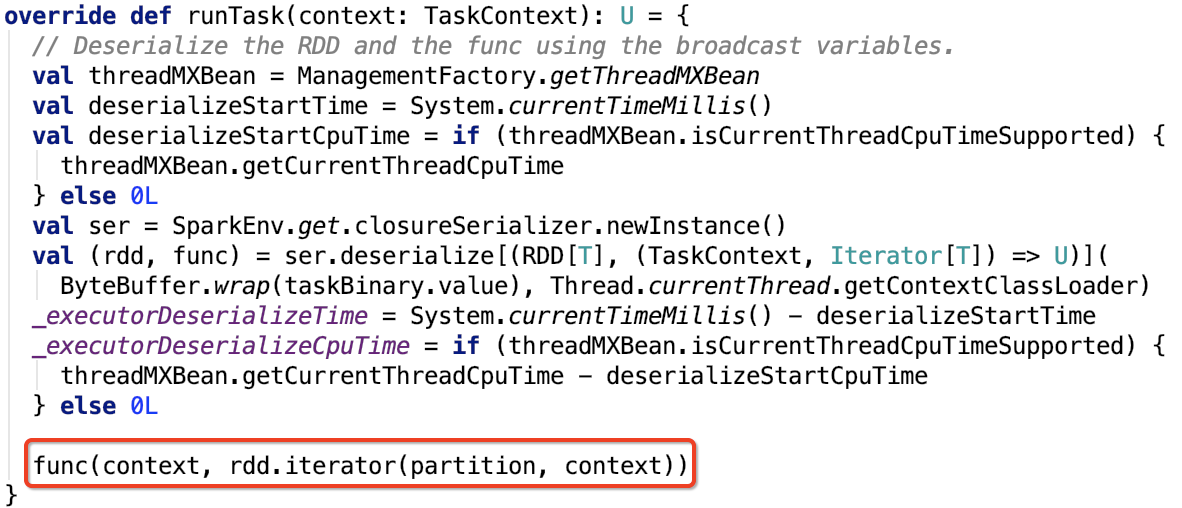
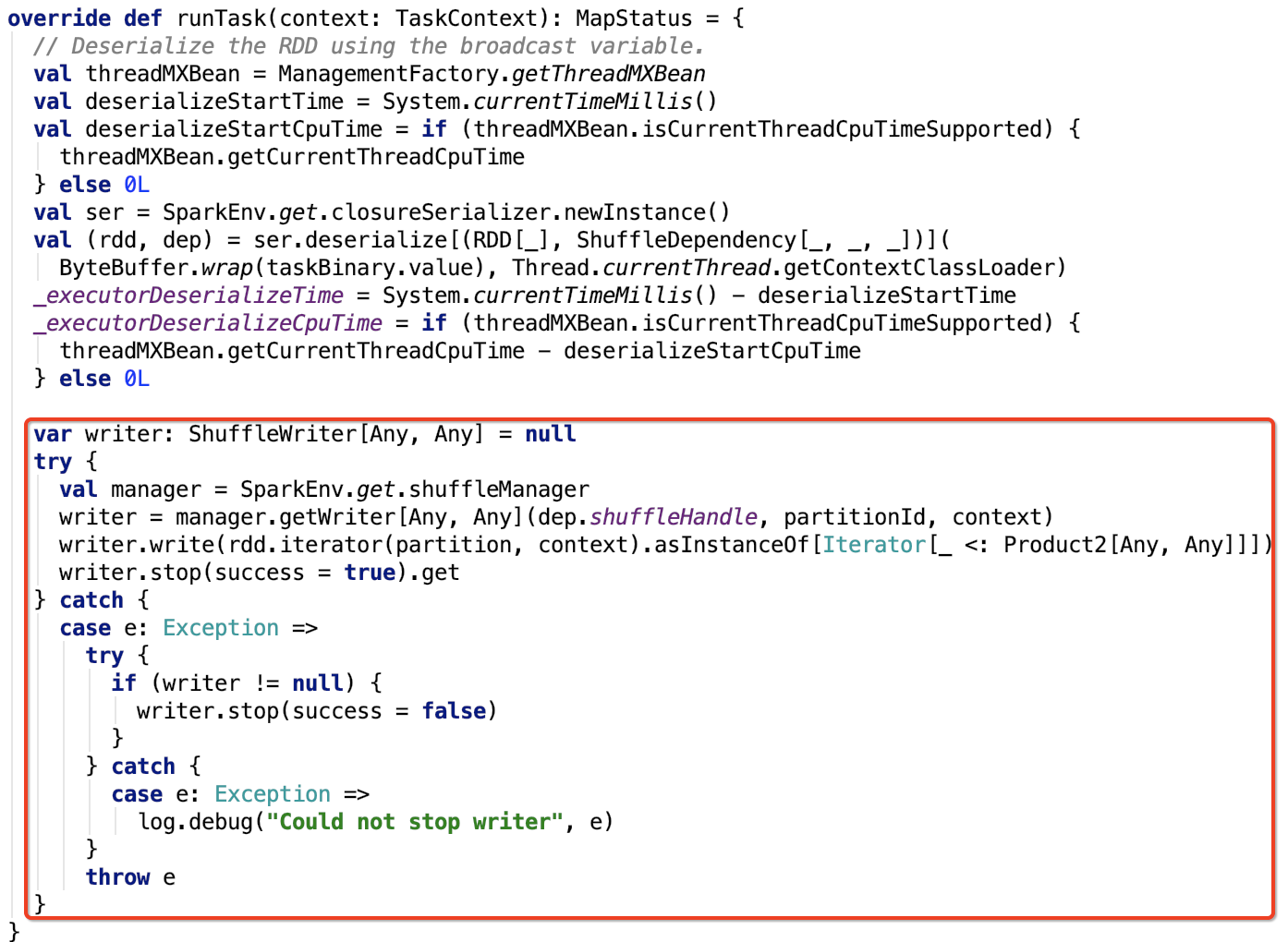
我們再來看一下,ResultTask和ShuffleMapTask的runTask方法。現在只關注數據處理邏輯,下面的兩張圖都做了標註。
ResultTask
類名:org.apache.spark.scheduler.ResultTask
其runTask方法如下:
ShuffleMapTask
類名:org.apache.spark.scheduler.ShuffleMapTask
其runTask方法如下:
兩種Task執行的相同和差異
相同點
- 這兩種Task都是在RDD的分區上執行的。
- 兩種Task都需要調用父RDD的iterator方法來獲取父RDD對應分區的數據。
- 這些數據可以直接來自於數據源,也可以直接來自於上一個ShuffleMapTask執行的結果。
- 當一個Stage中所有分區的Task都執行完畢,這個Stage才算執行完畢。
差異點
- ResultTask獲取父RDD分區數據之後,把分區數據作為參數輸入到action函數中,最終計算出特定的結果返回給driver。
- ShuffleMapTask獲取父RDD分區數據之後,把分區數據作為參數傳入分區函數,最終形成新的RDD中的分區數據,保存在各個Executor節點中,並將分區數據資訊MapStatus返回給driver。
總結關注點
由兩種Task執行的相同和差異點可以總結出,要想對這兩種類型的任務執行有非常深刻的理解,必須搞明白shuffle 數據的讀寫。這也是spark 計算的核心的關注點 — Shuffle的寫操作、Shuffle的讀操作。
shuffle數據分類
shuffle過程中寫入Spark存儲系統的數據分為兩種,一種是shuffle數據,一種是shuffle索引數據,如下:

shuffle數據的管理類–IndexShuffleBlockResolver
下面說一下 IndexShuffleBlockResolver 類。這個類負責shuffle數據的獲取和刪除,以及shuffle索引數據的更新和刪除。
IndexShuffleBlockResolver繼承關係如下:
我們先來看父類ShuffleBlockResolver。
ShuffleBlockResolver
主要是負責根據邏輯的shuffle的標識(比如mapId、reduceId或shuffleId)來獲取shuffle的block。shuffle數據一般都被File或FileSegment包裝。
其介面定義如下:

其中,getBlockData根據shuffleId獲取shuffle數據。
下面來看 IndexShuffleBlockResolver的實現。
IndexShuffleBlockResolver
這個類負責shuffle數據的獲取和刪除,以及shuffle索引數據的更新和刪除。
類結構如下:

blockManager是executor上的BlockManager類。
transportCpnf主要是包含了關於shuffle的一些參數配置。
NOOP_REDUCE_ID是0,因為此時還不知道reduce的id。
核心方法如下:
1. 獲取shuffle數據文件,源碼如下,思路:根據blockManager的DiskBlockManager獲取shuffle的blockId對應的物理文件。
![]()
2. 獲取shuffle索引文件,源碼如下,思路:根據blockManager的DiskBlockManager獲取shuffle索引的blockId對應的物理文件。
![]()
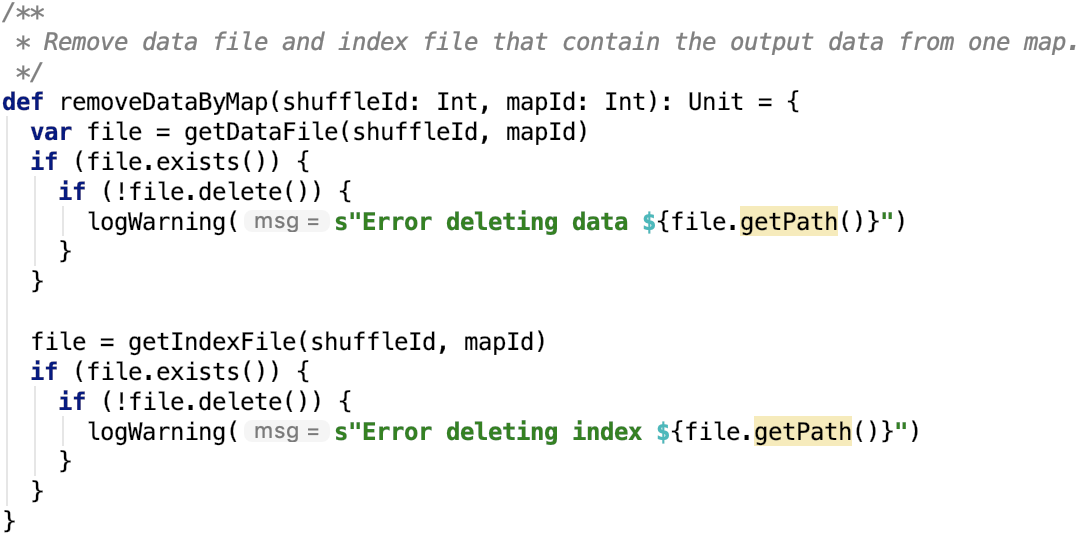
3.根據mapId將shuffle數據移除,源碼如下,思路:根據shuffleId和mapId刪除shuffle數據和索引文件
4.校驗shuffle索引和數據,源碼如下。

從上面可以看出,文件里第一個long型數是佔位符,必為0.
後面的保存的數據是每一個block的大小,可以看出來,每次讀的long型數,是前面所有block的大小總和。
所以,當前block的大小=這次讀取到的offset – 上次讀取到的offset
這種索引的設計非常巧妙。每一個block大小合起來就是整個文件的大小。每一個block的在整個文件中的offset也都記錄在索引文件中。
5. 寫索引文件,源碼如下。

思路:首先先獲取shuffle的數據文件並創建索引的臨時文件。
獲取索引文件的每一個block 的大小。如果索引存在,則更新新的索引數組,刪除臨時數據文件,返回。
若索引不存在,將新的數據的索引數據寫入臨時索引文件,最終刪除歷史數據文件和歷史索引文件,然後臨時數據文件和臨時數據索引文件重命名為新的數據和索引文件。
這樣的設計,確保了數據索引隨著數據的更新而更新。
6. 根據shuffleId獲取block數據,源碼如下。
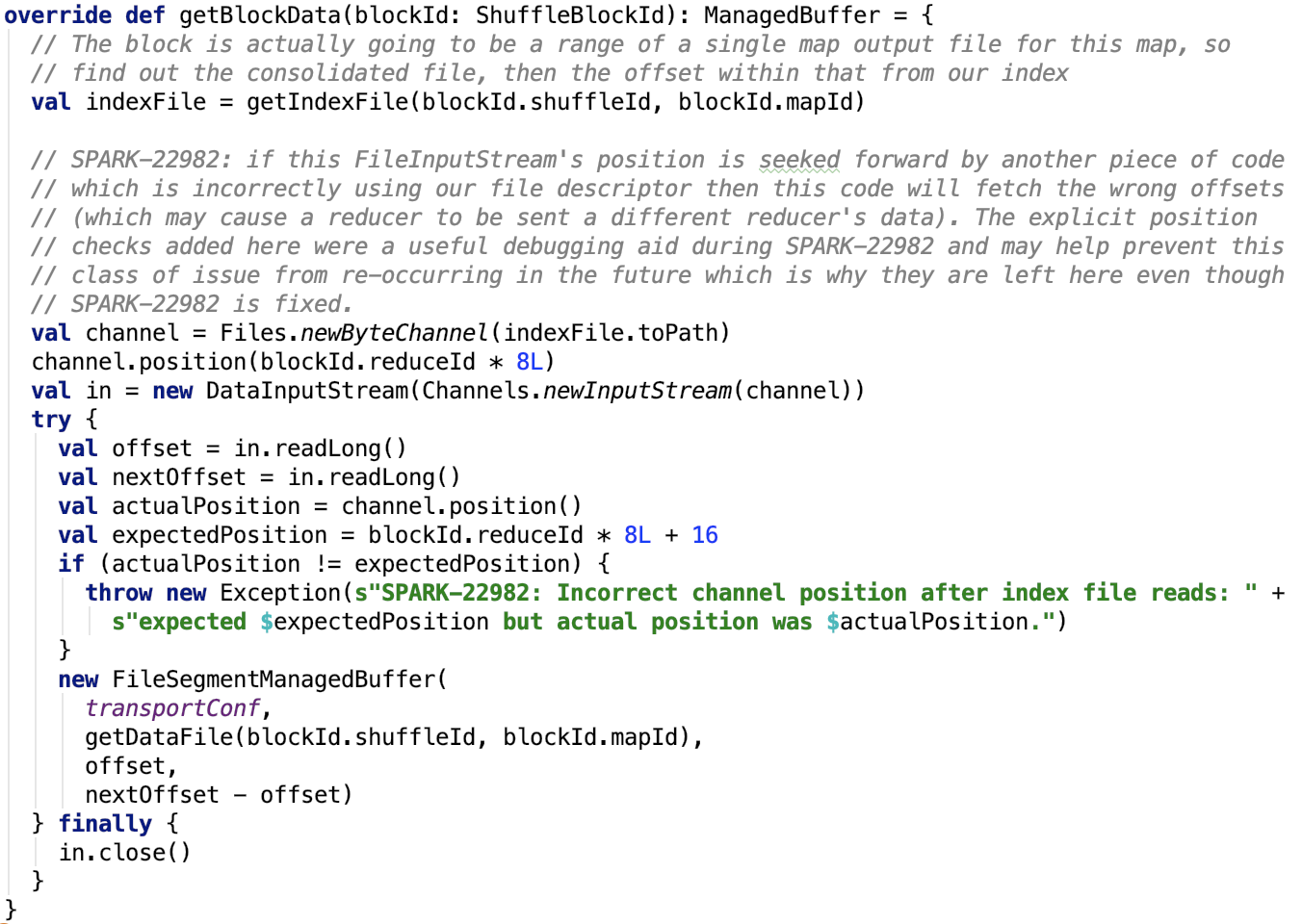
思路:
先獲取shuffle數據的索引數據,然後調用position位上,獲取block 的大小,然後初始化FileSegmentManagedBuffer,讀取文件的對應segment的數據。
可以看出 reduceId就是block物理文件中的小的block(segment)的索引。
7. 停止blockResolver,空實現。
總結,在這個類中,可以學習到spark shuffle索引的設計思路,在工作中需要設計File和FileSegment的索引文件,這也是一種參考思路。
Shuffle的寫數據前的準備工作
直接來看 org.apache.spark.scheduler.ShuffleMapTask 的runTask的關鍵程式碼如下:
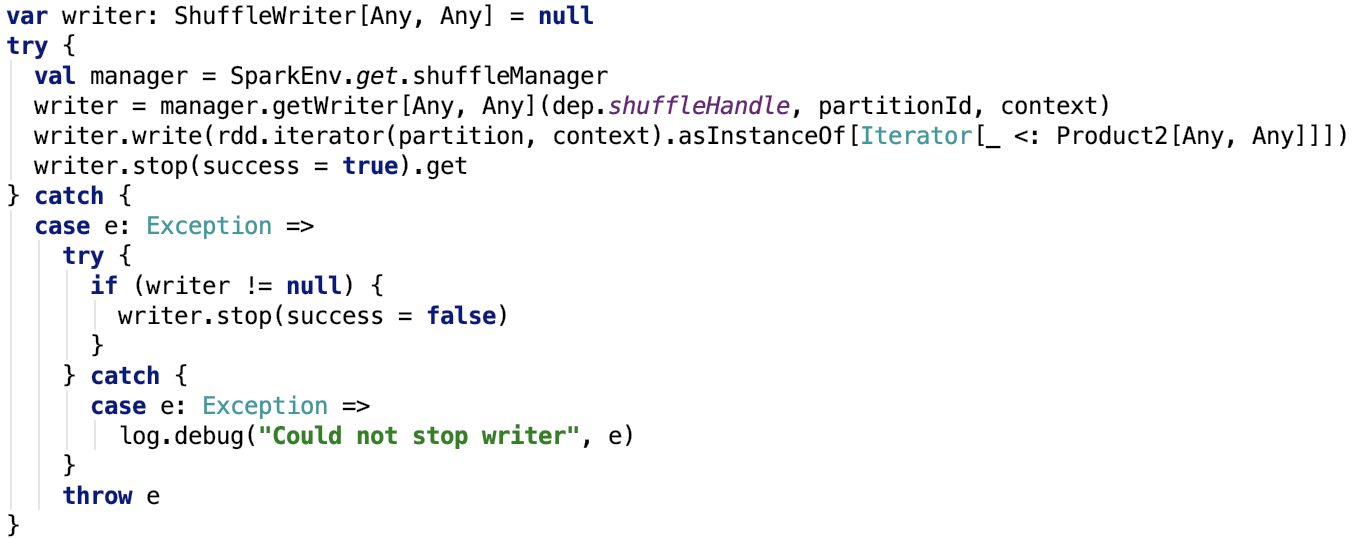
這裡的manager是SortShuffleManager,是ShuffleManager的唯一實現。
org.apache.spark.shuffle.sort.SortShuffleManager#getWriter 源碼如下:
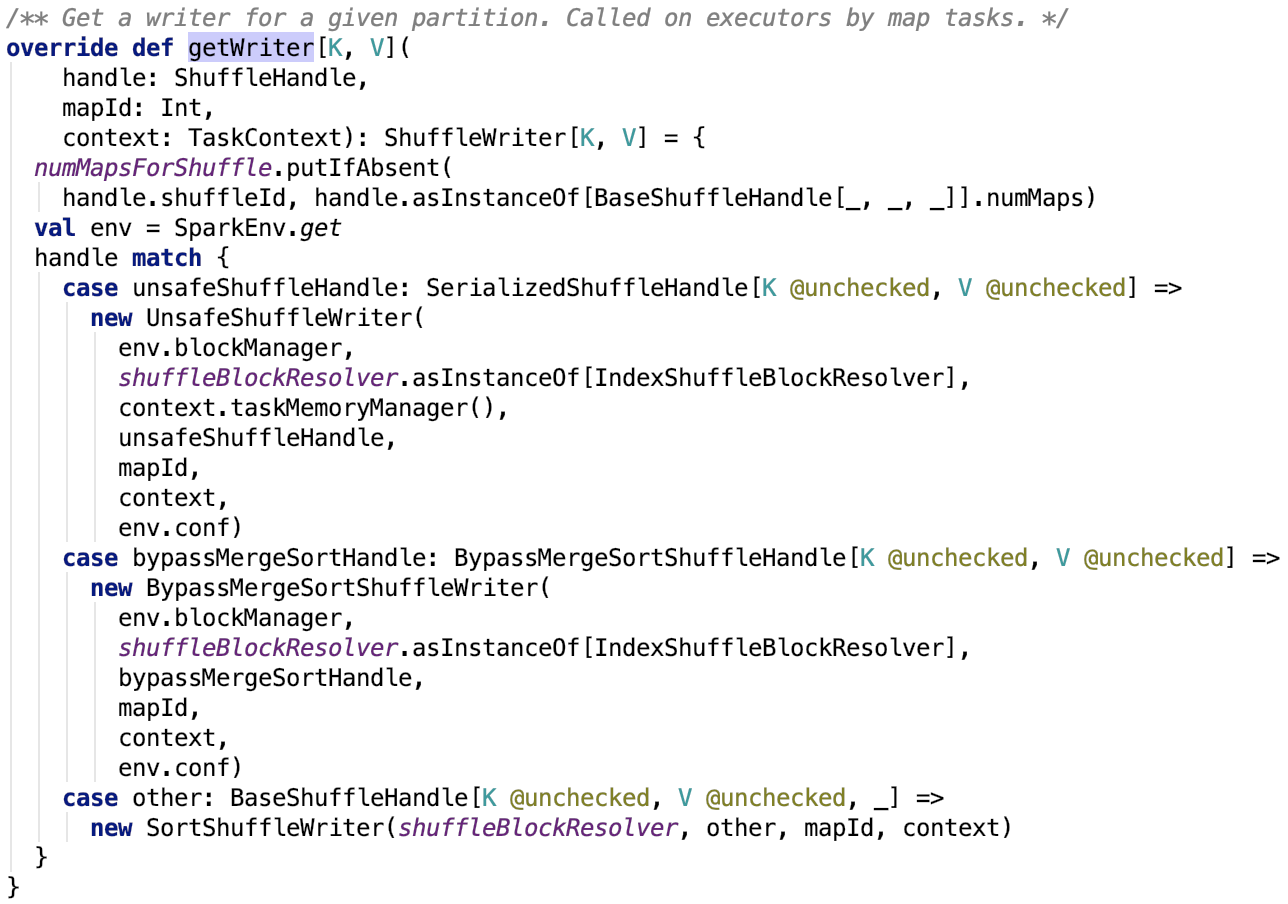
其中,numMapsForShuffle 定義如下:

它保存了shuffleID和mapper數量的映射關係。
獲取ShuffleHandle
首先,先來了解一下ShuffleHandle類。
ShuffleHandle
下面大致了解一下ShuffleHandle的相關內容。
類說明:
這個類是Spark內部使用的一個類,包含了關於Shuffle的一些資訊,主要給ShuffleManage 使用。本質上來說,它是一個標誌位,除了包含一些用於shuffle的一些屬性之外,沒有其他額外的方法,用case class來實現更好一點。
類源碼如下:
![]()
繼承關係如下:
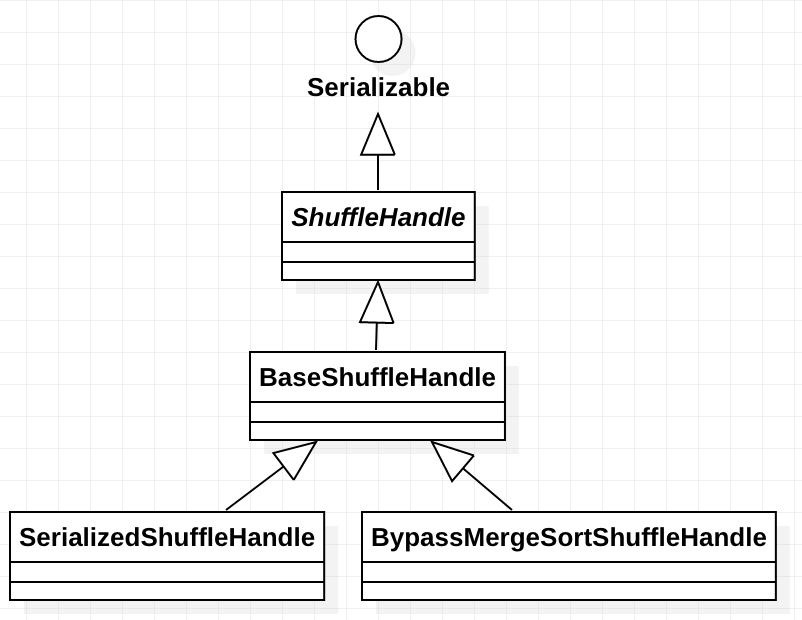
BaseShuffleHandle
全稱:org.apache.spark.shuffle.BaseShuffleHandle
類說明:
它是ShuffleHandle的基礎實現。
類源碼如下:

下面來看一下它的兩個子類實現。
BypassMergeSortShuffleHandle
全稱:org.apache.spark.shuffle.sort.BypassMergeSortShuffleHandle
類說明:
如果想用於序列化的shuffle實現,可以使用這個標誌類。其源碼如下:

SerializedShuffleHandle
全稱:org.apache.spark.shuffle.sort.SerializedShuffleHandle
類說明:
used to identify when we’ve chosen to use the bypass merge sort shuffle path.
類源碼如下:

獲取ShuffleHandle
在org.apache.spark.ShuffleDependency中有如下定義:

shuffleId是SparkContext生成的唯一全局id。
org.apache.spark.shuffle.sort.SortShuffleManager#registerShuffle 源碼如下:
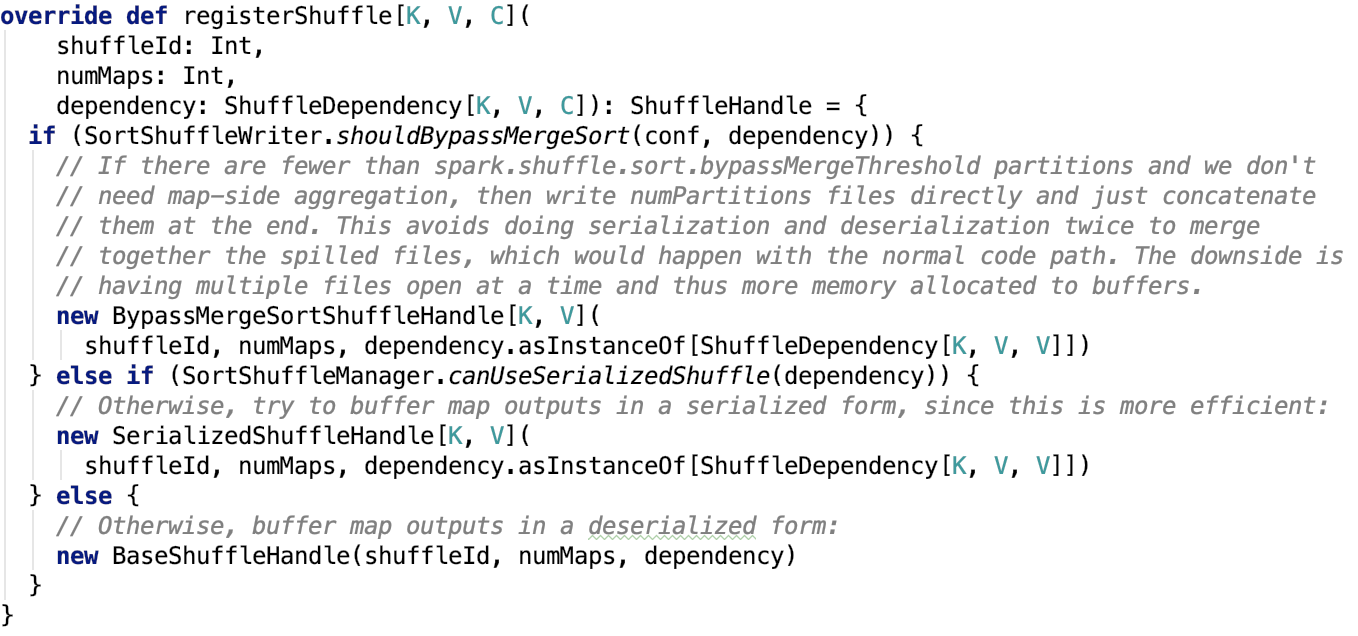
可以看出,mapper的數量等於父RDD的分區的數量。
下面,看一下使用bypassMergeSort的條件,即org.apache.spark.shuffle.sort.SortShuffleWriter#shouldBypassMergeSort 源碼如下:

思路:首先如果父RDD沒有啟用mapSideCombine並且父RDD的結果分區數量小於bypassMergeSort閥值,則使用 bypassMergeSort。其中bypassMergeSort閥值 默認是200,可以通過 spark.shuffle.sort.bypassMergeThreshold 參數設定。
使用serializedShuffle的條件,即org.apache.spark.shuffle.sort.SortShuffleManager#canUseSerializedShuffle 源碼如下:

思路:序列化類支援支援序列化對象的遷移,並且不使用mapSideCombine操作以及父RDD的分區數不大於 (1 << 24) 即可使用該模式的shuffle。
根據ShuffleHandle獲取ShuffleWriter
首先先對ShuffleWriter做一下簡單說明。
ShuffleWriter
類說明:它負責將map任務的輸出寫入到shuffle系統。其繼承關係如下,對應著ShuffleHandle的三種shuffle實現標誌。
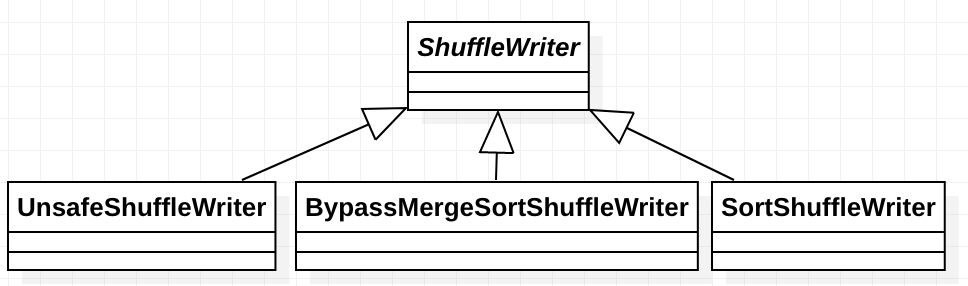
獲取ShuffleWriter
org.apache.spark.shuffle.sort.SortShuffleManager#getWriter源碼如下:
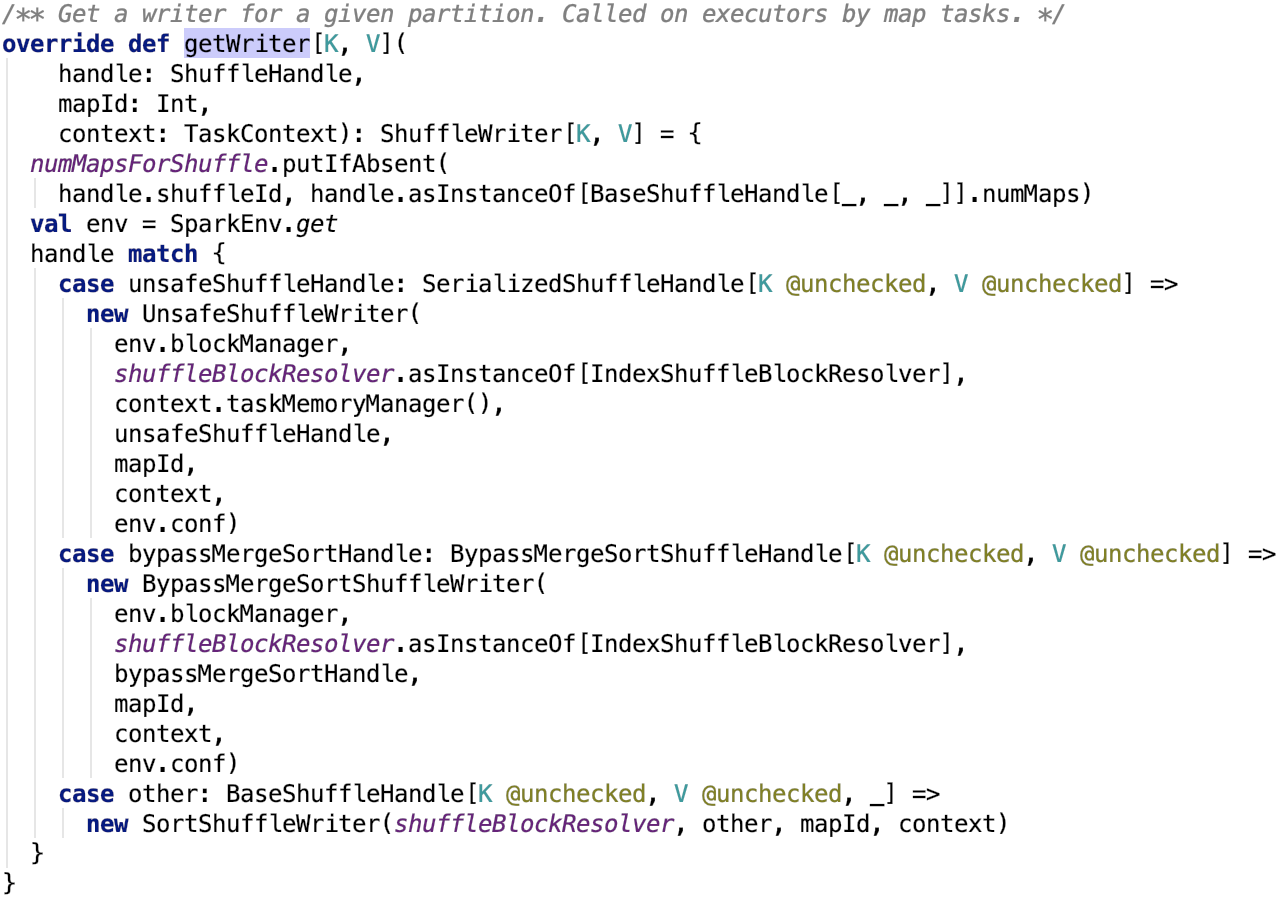
一個mapper對應一個writer,一個writer往一個分區上的寫數據。
總結
本篇文章主要從Task 的差異和相同點出發,引出spark shuffle的重要性,接著對Spark shuffle數據的類型以及spark shuffle的管理類做了剖析。最後介紹了三種shuffle類型的標誌位以及如何確定使用哪種類型的數據的。
接下來,正式進入mapper寫數據部分。spark內部有三種實現,每一種寫方式會有一篇文章專門剖析,我們逐一來看其實現機制。
