孤立森林演算法簡介
前言
現有的異常檢測方法主要是通過對正常樣本的描述,給出一個正常樣本在特徵空間中的區域,對於不在這個區域中的樣本,視為異常。這些方法的主要缺點是,異常檢測器只會對正常樣本的描述做優化,而不會對異常樣本的描述做優化,這樣就有可能造成大量的誤報,或者只檢測到少量的異常。
異常具有兩個特點:異常數據只佔很少量,異常數據特徵值和正常數據差別很大。而孤立森林不再是描述正常的樣本點,而是孤立異常點。
在孤立森林中,異常被定義為「容易被孤立的離群點 (more likely to be separated)」,可以將其理解為分布稀疏且離密度高的群體較遠的點。 在特徵空間里,分布稀疏的區域表示事件發生在該區域的概率很低,因而可以認為落在這些區域里的數據是異常的。
孤立森林是一種適用於連續數據的無監督異常檢測方法。在孤立森林中,遞歸地隨機分割數據集,直到所有的樣本點都是孤立的。在這種隨機分割的策略下,異常點通常具有較短的路徑。
直觀上來講,那些密度很高的簇是需要被切很多次才能被孤立,但是那些密度很低的點很容易就可以被孤立。
如下圖:

Xi 需要多次的分割才能被孤立,而 Xo 需要較少的分割次數就能被孤立。因此 Xi 為正常點,Xo 為異常點。
分割方式採用的是,隨機選擇一個特徵以及拆分的值(這個值位於該特徵的最小值和最大值之間)。
isolation tree (iTree)
定義:假設 T 是孤立樹的一個節點,它要麼是沒有子節點的葉子節點,要麼是只有兩個子節點 (Tl,Tr) 的內部節點。
每一步分割,都包含特徵 q 和分割值 p,將 q < p 的數據分到Tl,將 q ≥ p 的數據分到Tr。
給定 n 個樣本數據 X = {x1,⋯,xn},特徵的維度為 d。為了構建一棵孤立樹,需要隨機選擇一個特徵 q 及其分割值 p,遞歸地分割數據集 X
直到滿足以下任意一個條件:(1) 樹達到了限制的高度;(2) 節點上只有一個樣本;(3) 節點上的樣本所有特徵都相同。
異常檢測的任務是給出一個反應異常程度的排序,常用的排序方法是根據樣本點的路徑長度或異常得分來排序,異常點就是排在最前面的那些點。
Path Length(路徑長度)
定義: 樣本點 x 的路徑長度 h(x) 為從 iTree 的根節點到葉子節點所經過的邊的數量。
Anomaly Score(異常得分)
給定一個包含 n 個樣本的數據集,樹的平均路徑長度為:

其中 H(i) 為調和數,該值可以被估計為 ln(i) + 0.5772156649。c(n) 為給定樣本數 n 時,路徑長度的平均值,用來標準化樣本 x 的路徑長度 h(x)。
樣本 x 的異常得分定義為
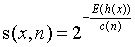
其中,E(h(x)) 為樣本 x 在一批孤立樹中的路徑長度的期望。下圖給出了 s 和 E(h(x)) 的關係。
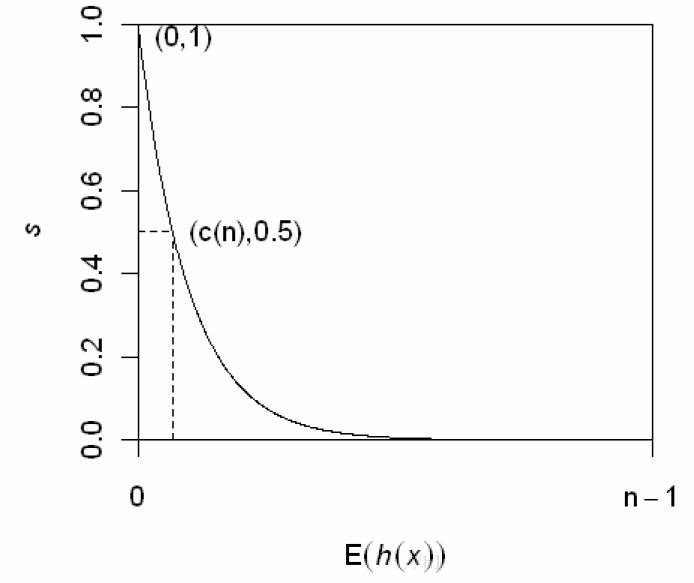
由上圖可以得到一些結論:
當 E(h(x))→c(n) 時,s→0.5,即樣本 x 的路徑平均長度與樹的平均路徑長度相近時,則不能區分是不是異常。
當 E(h(x))→0 時,s→1,即 x 的異常分數接近1時,被判定為異常。
當 E(h(x))→n−1 時,s→0,被判定為正常。
參考鏈接://blog.csdn.net/extremebingo/article/details/80108247

