CVPR2020|3D-VID:基於LiDar Video資訊的3D目標檢測框架
- 2020 年 4 月 18 日
- 筆記
作者:蔣天園Date:2020-04-18
Brief
paper地址://arxiv.org/pdf/2004.01389.pdf
code地址://github.com/yinjunbo/3DVID
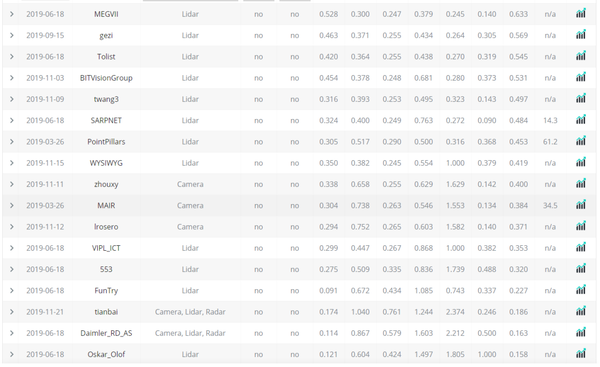
這是一篇來自北理工和百度合作的文章,目前還未開源,只有項目地址,2020年3月份放置在arxiv上,已經被CVPR2020接收;從標題我們猜測該文採用的時空資訊將多幀的點雲資訊融合做3D目標檢測,目前的確是沒有研究是通過影片流的方式做3D目標檢測,不過這也要求數據集是一些連續的幀才能使得這樣一個任務的完成,但是KITTI的確是沒有滿足這樣的要求,因此作者在Nuscence上進行的實驗。這是一個CVPR19年上的公布的數據集,這裡先給出一張目前在公布的nuscence的榜單,如下,這裡的榜一的文章目前將SECOND的程式碼重構,加入了更多SOTA的方法開源了新的3Ddetection base,即Det 3D項目,鏈接為://github.com/poodarchu/Det3D,而MEGV則是採用了多尺度檢測的head,規定了不同大小的物體的檢測採用不同的head,同時採用了一種數據增廣方式緩解了nuscence中的longtail問題
本文主要內容
本文主要內容可以簡單總結為,在目前的SoTA的文章中,第一個採用3Dvideo點雲做3D目標檢測的,利用了前人所沒有用到的幀與幀之間的時間連續關係,為此,作者在pointpillars的基礎上添加了grap-basd的GNN卷積,使得每個節點的感受野擴大,以此設計了空間特徵提取模組;然後根據得到的空間特徵送入由GRU為基礎模組搭建的時空特徵融合模組得到連續幀之間的更加豐富的特徵資訊,在該模組中,作者分別採用了空間注意力和「時間」注意力機制分別對前景物體加以更大注意和對運動物體加以配准。本文中並不是一個以問題為導向的思路,而是一種新奇的思想引入,但是文章任然指出,之前的方法會出現的FP問題在本文中會得到一定程度的環境。對比由問題為導向的文章3DSSD而言,本文的內容涉及更廣。
Abstract
-
當前的基於LiDar輸入的目標檢測網路都是只使用了單幀的資訊,都沒有使用連續點雲之間的時空資訊。所以本文作者提出了一種處理點雲序列的end2end的online的影片檢測方法。
-
本文提出的模型由空間特徵編碼模組和時空特徵融合模組兩部分組成。這裡的空間特徵編碼模組——PMPNet(PillarMessage Passing Network)用於編碼獨立的每一幀的點雲特徵,該模組通過迭代消息傳遞,自適應地從相鄰節點處為該pillarnode收集節點資訊,有效地擴大了該pillarnode的感受野。時空特徵融合模組則是採用的時空注意力結合GRU的設計(AST-GRU)來整合時空資訊,該模組通過一個attentivememory gate來加強傳統的ConvGRU。其中AST-GRU模組又包含了一個空間注意力模組(STA)和TTA模組(TemporalTransformer Attention ),使得AST-GRU可以注意到前景物體和配准動態物體。
-
在nuscence上得到了sota的效果
1. Introduction
-
point cloud video的定義點雲影片是一系列點雲幀的集合,在數據集Nuscence中,採用的32線每一秒可以捕獲20幀的點雲的光學雷達。
-
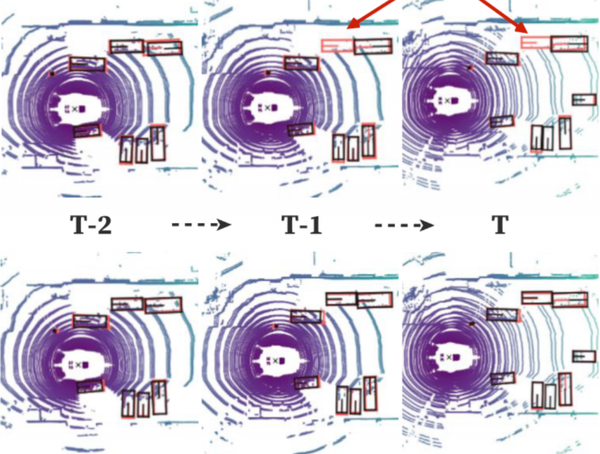
單幀檢測方法的弊端如果採用單幀影像直接處理就受到單幀影像就必須受到單幀影像稀疏性過大的影響,再嚴重一點,距離和遮擋都會成為單幀檢測方法的重大阻礙。如下圖所示,最上一層的檢測經常處才能False-negative的結果,但是本文提出的online3D video 檢測方法就可以做到更好的效果。這是因為point cloud video具有更加豐富的物體特徵。 當前比較流行的一些單幀檢測方法有可分為voxel-based的voxelnet、second、pointpillars和point-based的pointrcnn等方法,在本文中,作者也是採用的這種Pillar劃分的方式提取特徵,但是這種方法只會關注局部特徵。所以作者對此提出了graph-based的方法PMPnet
-
核心問題 (1)構建3D video 目標檢測的關鍵問題在於如何對連續的時空特徵資訊進行建模表示,本文中,作者提出了融合graph-based空間編碼特徵的模組並結合時空注意力感知模組,來捕獲影片一致性。 (2)上文提到作者為了改變pillars特徵提取僅僅提取一個Pillar中的特徵的問題,自己設計了PMPnet,該網路把每一個非空的pillar當做圖的一個節點,通過mesh從旁邊節點融合特徵的方式來擴大感受野,因此PMPNet通過在K-NNgraph中採用迭代的方式可以深度挖掘不同pillar節點之間的相對關係,該網路是在同一幀的點雲中進行空間的特徵融合。 (3)上面的PMPnet僅僅在同一幀的空間中提取到感受野更多的特徵資訊,然後將這些單幀的特徵在作者設計的第二個網路結構AST-GRU中進行融合,ConvGRU這一篇ICLR16年的文章證實了在2Dvideo中ConvGRU是非常有效的,作者設計的AST-GRU則是把該工作通過一個注意力記憶體門機制來捕獲連續幀點雲之間的依賴關係來擴展到三維點雲中處理中。 (4)在俯視圖下,前景物體僅僅只佔一小部分區域,背景點佔據了大部分的區域,這會使得在迭代過程中,背景雜訊會越來越大,因此作者採用了空間注意力模組來緩解背景雜訊並強調前景物體。(5)更新memory時,舊的空間特徵和新的輸入之間存在沒配準的問題,如果是靜態物體,可以採用ego-pose資訊配准,但是具有很大運動幅度的動態物體則是不能的,為了解決這問題,作者採用了短暫注意力機制(TTA)模組,自適應的捕捉連續幀中的運動關係。
-
整體設計作者首先通過PMPNet模組自適應擴大感受野的提取每一幀的空間特徵,再將輸出的特徵序列送入AST-GRU模組。
2. Related Work
本文的這一章節主要運用了基於點雲的檢測方法的backbone和graph-based的方法,因此主要介紹這兩方面內容。
1.LiDAR-based 3D Object Detection
作者一樣把基於lidar的方法分為了三類,point-based、voxel-based和multi-sensors的方法,前面兩種方法已經在前面的博文中有了挺詳細的介紹,這裡不再介紹。而multi-sensor的研究方法更多的是在18年以前,最新的文章有19年的MVF和AAAI的PIRCNN,採用的都是結合影像和lidar輸入的檢測方法,不同的是,目前這樣做的方法主要有兩類,其一是特徵融合後在提proposals,第二種是都先提出proposals再融合。後者更像是打比賽中的模型融合的方法。
2.Graph Neural Networks
圖神經網路(Graph Neural Networks, GNNs)最早是由Gori等人引入的,用來對圖結構數據的內在關係進行建模。然後Scarselli等人將其擴展到不同類型的圖。之後的GNN研究可以分為兩個方向:(1)第一個研究方向是使用選通機制使資訊能夠在圖中傳播,比如利用RNN描述每個節點的狀態或者將圖形推理概括為參數化的消息傳遞網路。(2)另外一個研究方向是則是將CNN引入到GNN中,因此GNN在該方向下也可以叫GCNN。本文作者的PMPnet屬於第一個方向中的內容,通過門控消息傳遞策略來捕獲pillar特徵,用於對每一幀的點雲做特徵提取。
3. Model Architecture
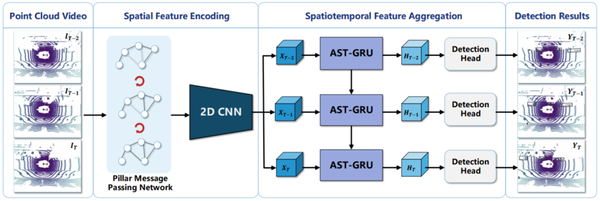
整體結構圖如下,可以看出主包含了空間特徵編碼和時空特徵融合兩個模組。前者是對每一幀的點雲提取空間特徵,後者是採用空間和時間上的注意力機制對提取到的特徵序列做融合。
作者首先當前幀的前一幀點雲通過GPS資訊將其對應的坐標轉換到當前幀來,目的是消除運動影響,使靜態物體在幀間對齊。然後再採用PMPnet提取空間特徵和AST-GRU進行時空特徵融合。
3.1 PMPnet
作者指出之前的提取voxel特徵的方法VFE(被提出在voxelnet,其中SECOND1.0和pointpillars也都有使用)由於感受野的問題並不能完全挖掘voxel的特徵(實際上後續有採用3DCNN或者稀疏卷積再次提取,相當於是做了感受野的擴大吧,只是在VFE層僅僅是對單個voxel進行了特徵提取);因此這一部分則是為了來解決這樣一個問題,即將非空的pillar當做節點,然後將其構建成圖結構(怎麼構建,距離?),作者稱這種圖結構有效的保留了非歐式的原始結構。(流型結構就是一個非歐式結構,因為點雲掃描得到的都是表面點,可以這樣理解)。我們記通過pillar構建的圖結構為
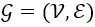
,前者表示非空的pillar,後者表示的是邊的特徵。這裡作者表示本文採用的是K-NN建圖,採用周圍的最近的幾個pillar作為鄰居節點。採用迭代的方式更新特徵,我們假設一個pillar節點為,其對應是初始特徵為,該初始特徵是通過pillar內採用PFE(簡化版的pointnet)提取到,整體運行流程為:
1.得到初始特徵:
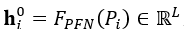
,這裡的表示的是一個pillar節點內的點。
2.特徵在圖網路中傳遞:
(1)如下圖所示,假設在第s次迭代的時候表示為坐邊的形式,左上表示的是當前圖的感受範圍,可以看出此時的僅僅與有關,與 的特徵無關,在點雲中表示為左上的形式;在第s+1次迭代後,該可以看出 的特徵被融合,得到了新的更大感受野的特徵。
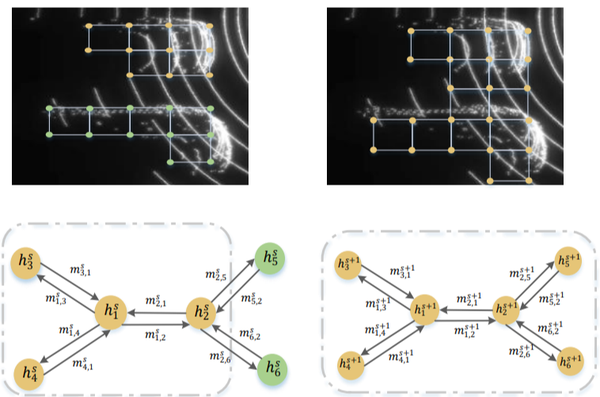
(2)上圖中的mj,i表示的是兩節點之間的傳遞資訊,作者把第s+1次的資訊傳遞定義為:
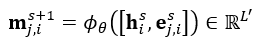
這裡的hi表示的是節點特徵,  是邊的特徵,邊的特徵直接定義為 ,上式表示的是從第s次的邊和節點特徵得到第s+1次的資訊傳遞特徵,採用的方式是FC層連接。但是一個節點相鄰的節點可能不止一個,因此,在通過
是邊的特徵,邊的特徵直接定義為 ,上式表示的是從第s次的邊和節點特徵得到第s+1次的資訊傳遞特徵,採用的方式是FC層連接。但是一個節點相鄰的節點可能不止一個,因此,在通過  更新當前節點特徵之前,需要周圍所有節點的傳遞資訊進行融合得到最終的傳遞資訊;採用最大池化:
更新當前節點特徵之前,需要周圍所有節點的傳遞資訊進行融合得到最終的傳遞資訊;採用最大池化:
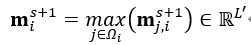
而後再根據  對當前的節點特徵進行更新:
對當前的節點特徵進行更新:
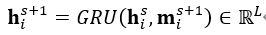
通過上述的迭代後,節點vi就算是包含了所有鄰居節點的特徵資訊,同時,鄰居節點也包含了它鄰居節點的特徵;所以第s次迭代完全結束後,該點的特徵也聚集了鄰居的鄰居的特徵,使得每個節點的特徵對應的感受野資訊更加擴大了。
(3)傳遞完特徵後,再採用二維卷積進一步提取高維語義資訊。總結一下,上述的backbone,僅僅比pointpillars多了一步資訊傳遞,其餘的兩步(PFE ,2DCNN)都是一樣的。
3.2 AST-GRU
如果直接採用傳統的ConvGRU對上文backbone得到的特徵進行融合會得到兩個問題:
1.BEV視圖下的點雲的的前景佔比很小,在feamap中統計出來是18×8個像素值,背景點過多會導致背景雜訊會主導哦Menory。
2.問題2是在連續幀中,靜態物體可以通過GPS資訊配准,但是動態物體卻不能。針對上述的兩個問題,作者的應對方法分別是在空間和時間上採用注意力機制即STA(spatial transformer attention)和TTA(temporal transformer attention)。如下圖所示,STA模組專註空間中的前景資訊,輸出的是新的GRU的輸入fea map;TTA模組配准memory中和輸入的特徵中的動態物體,輸出配准後的memory資訊。
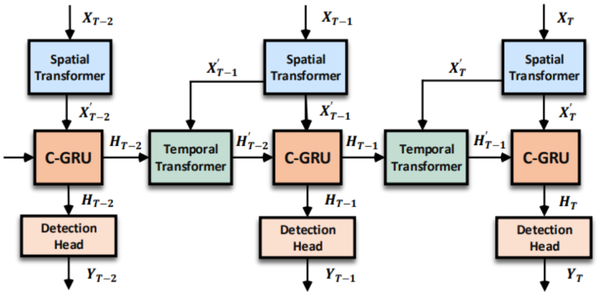
上圖的核心組件分為如下三部分:
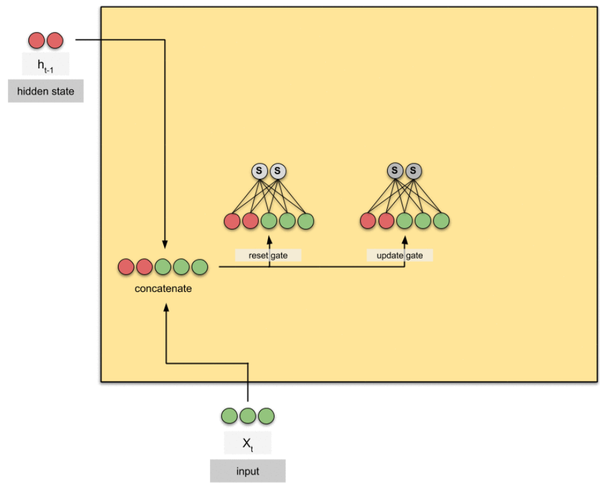
(1)VanillaConvGRU:ConvGRU是卷積形式的GRU,相比FC的GRU具有更少的參數和更好的空間表達能力,同時比LSTM具有更少的收斂時間,其工作模式如下,動態圖講解GRU,LSTM運行模式,鏈接://towardsdatascience.com/animated-rnn-lstm-and-gru-ef124d06cf45
本文中,採用如下的公式表示使用舊memory中的狀態和輸入得到新memory中的狀態的過程:
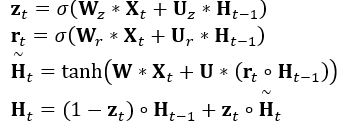
其中字元表示的含義由如下的表格顯示:
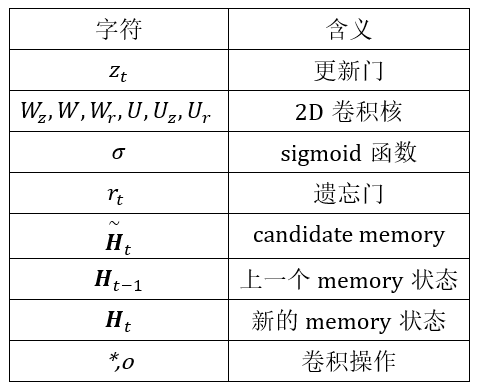
配合上文的動態圖,就可以比較清晰的知道本文中的GRU的運行流程了。
(2)STA 空間注意力模組
和以往的空間注意力機制類似,作者設計了對於輸入的fea map的每一個像素採用一個加權的方式,如下公式:
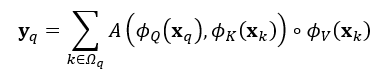
其中代表的含義表示如下:
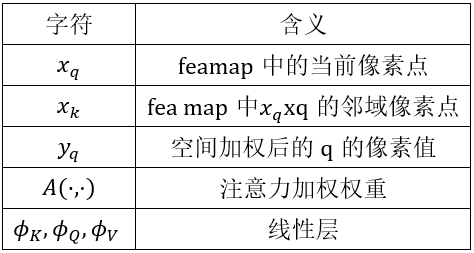
也就是說,上式表示的內容是對目標pix的輸出為:和鄰域Pix的加權值再和鄰域資訊卷積。(3)TTA 時間注意力機制前文提到,這個模組是為了對運動的物體進行配准,作者採用的是改進的DCN結構,也就是可變型卷積結構,目的是通過融合運動資訊自適應的篩選出關鍵支援區域。DCN簡化表達為下式子:
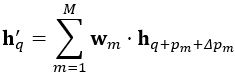
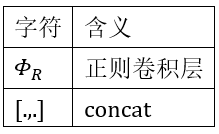
其中,下表表示字元含義:

如果將TTA模組中的輸入和空間注意力模組中的輸出帶入,可以表示為:
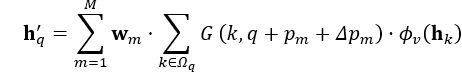
可以看出實際上在TTA模組中,鄰域資訊也是起到了非常重要的作用的,該TTA模組由偏移量  決定,上表格中提到這裡的偏移通過卷積層學習到,表達為如下:
決定,上表格中提到這裡的偏移通過卷積層學習到,表達為如下:
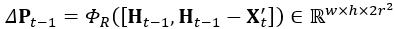
這裡面有:
ils總的來講,該模組為了配准動態物體,採用上一次memory和本次feamap作為輸入,預測了偏移值  ,和下一個的menory特徵結合出得到新的輸入。
,和下一個的menory特徵結合出得到新的輸入。
3.3 Network Deta
(1)PMPNet
1.在提取pillar的特徵時,採用的也是max-pooling的形式
2.中間graph-based的消息傳遞採用的K-NN進行建圖,其中從邊到節點的特徵採用1×1卷積代替全連接層。
(2)Backbone Module
和以往的lidar-based的方法一樣,不多介紹。
(3)AST-GRU Module
這其中採用的卷積核大小都是3×3的,除非是用1×1卷積代替全連接的形式。
(4)Detection Head
該結構的輸入是經過AST-GRU迭代到最後的menory feature,loss函數和其他的lidar-based的方法一致,採用的是L1 loss和focal loss.
4. Experimental Results
nuscenes簡單介紹
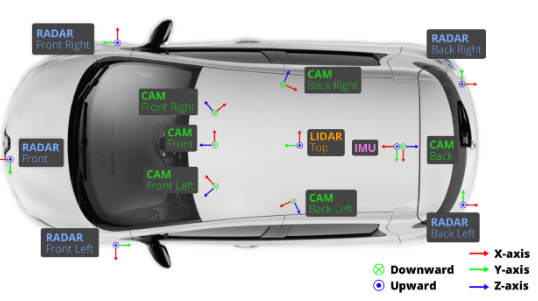
作者在nuscenes數據集上進行了測試, Nuscene數據集簡單介紹:這個數據採集是由6個攝影機,1個LIDAR,5個RADAR,GPS,IMU採集得到,與KITTI相比,nuScenes包含7倍以上的對象注釋。重要資訊:
-
1000個場景,每個場景20s,這些場景使用人類專家進行了仔細注釋
-
感測器安裝位置和採集的數據命名:
-
數據注釋:
(1)以2Hz對同步良好的關鍵幀(影像,光學雷達,雷達)進行取樣,並將它們發送到我們的注釋軟體Scale進行注釋。
(2)nuScenes數據集中的所有對象都帶有語義類別,以及它們出現的每個幀的3D邊界框和屬性。
(3)一共有23個對象(截圖並不完整)
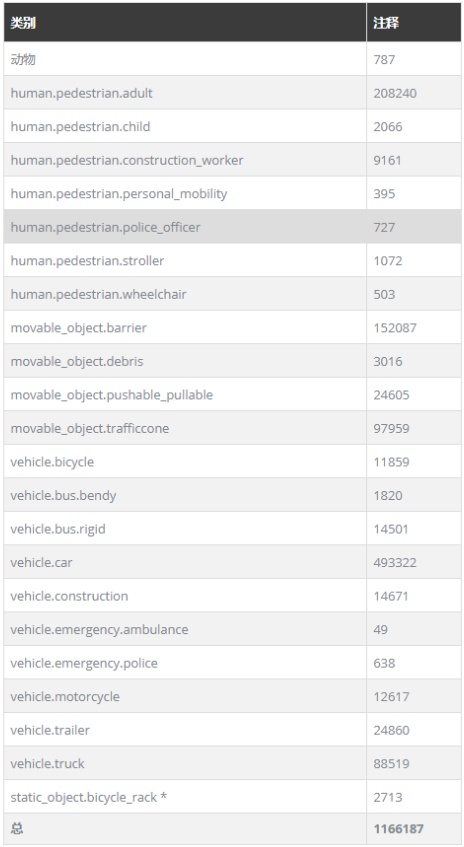
-
數量一共有1000多個場景,其中700個提供為訓練,150個場景作為測試,大概是KITTI的7倍左右影片中關鍵幀每隔0.5s標註,由10個非關鍵幀融合得到。資訊包含為,其中最後一個資訊是KITTI不含有的,表示離關鍵幀的時間從0~0.45.
更多細節大家可以去官網上的文檔細細研究,這裡不做過多介紹。本文採用在nuscenes而不在KIITTI上進行實驗的原因正是KITTI並不提供3D video.
實現細節
-
對於關鍵幀,輸入場景大小設置為[−50,50] × [−50, 50] ×[−5, 3],Pillar的劃分為[0.5×0.5]。
-
點雲數量的輸入為16384,從原始的2w+的點雲中取樣得到,每個pillar中最多包含點雲數量為60
-
最初的輸入維度是5,在GNN中的維度變為64
-
最終在backbone中的fea map為100 × 100 × 384(和voxelnet一樣的兩層concat)
Qualitative Performance
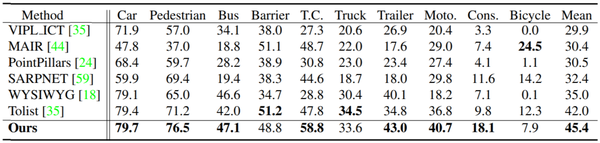
如下圖,對於nuscenes的10類目標檢測得到的結果如下,可以看出效在大部分物體上都是達到的sota的
消融實驗
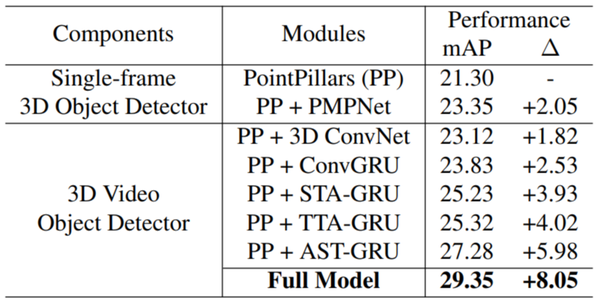
下圖展示了在pointpillars的基礎上添加本文提出的模組後的性能提升,最後的指標不僅僅是檢測的IOU值,還和很多其他指標加權得到的結果,在官網中有介紹。
推薦閱讀文獻
[1]Delving deeper into convolutional networks for learning videorepresentations
[2] Fast point r-cnn
[3] graph convolutional networks: Semisupervised learning via gaussianprocesses
[4]Deep hough voting for 3d object detection in point clouds

