SQL——語法基礎篇(上)
用資料庫的方式思考SQL是如何執行的
雖然 SQL 是聲明式語言,我們可以像使用英語一樣使用它,不過在 RDBMS(關係型資料庫管理系統)中,SQL 的實現方式還是有差別的。今天我們就從資料庫的角度來思考一下 SQL 是如何被執行的。
Oracle 中的 SQL 是如何執行的
我們先來看下 SQL 在 Oracle 中的執行過程:
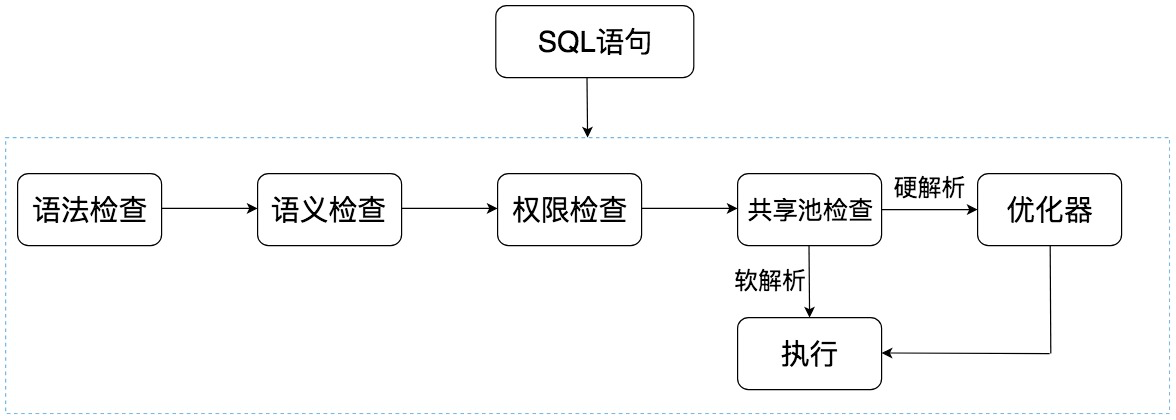
從上面這張圖中可以看出,SQL 語句在 Oracle 中經歷了以下的幾個步驟。
-
語法檢查:檢查 SQL 拼寫是否正確,如果不正確,Oracle 會報語法錯誤。
-
語義檢查:檢查 SQL 中的訪問對象是否存在。比如我們在寫 SELECT 語句的時候,列名寫錯了,系統就會提示錯誤。語法檢查和語義檢查的作用是保證 SQL 語句沒有錯誤。
-
許可權檢查:看用戶是否具備訪問該數據的許可權。
-
共享池檢查:共享池(Shared Pool)是一塊記憶體池,最主要的作用是快取 SQL 語句和該語句的執行計劃。Oracle 通過檢查共享池是否存在 SQL 語句的執行計劃,來判斷進行軟解析,還是硬解析。那軟解析和硬解析又該怎麼理解呢?
在共享池中,Oracle 首先對 SQL 語句進行 Hash 運算,然後根據 Hash 值在庫快取(Library Cache)中查找,如果存在 SQL 語句的執行計劃,就直接拿來執行,直接進入「執行器」的環節,這就是軟解析。
如果沒有找到 SQL 語句和執行計劃,Oracle 就需要創建解析樹進行解析,生成執行計劃,進入「優化器」這個步驟,這就是硬解析。
-
優化器:優化器中就是要進行硬解析,也就是決定怎麼做,比如創建解析樹,生成執行計劃。
-
執行器:當有了解析樹和執行計劃之後,就知道了 SQL 該怎麼被執行,這樣就可以在執行器中執行語句了。
共享池是 Oracle 中的術語,包括了庫快取,數據字典緩衝區等。我們上面已經講到了庫快取區,它主要快取 SQL 語句和執行計劃。而數據字典緩衝區存儲的是 Oracle 中的對象定義,比如表、視圖、索引等對象。當對 SQL 語句進行解析的時候,如果需要相關的數據,會從數據字典緩衝區中提取。
庫快取這一個步驟,決定了 SQL 語句是否需要進行硬解析。為了提升 SQL 的執行效率,我們應該盡量避免硬解析,因為在 SQL 的執行過程中,創建解析樹,生成執行計劃是很消耗資源的。
如何避免硬解析,盡量使用軟解析呢?在 Oracle 中,綁定變數是它的一大特色。綁定變數就是在 SQL 語句中使用變數,通過不同的變數取值來改變 SQL 的執行結果。這樣做的好處是能提升軟解析的可能性,不足之處在於可能會導致生成的執行計劃不夠優化,因此是否需要綁定變數還需要視情況而定。
舉個例子,我們可以使用下面的查詢語句:
SQL> select * from player where player_id = 10001;
你也可以使用綁定變數,如:
SQL> select * from player where player_id = :player_id;
這兩個查詢語句的效率在 Oracle 中是完全不同的。如果你在查詢 player_id = 10001 之後,還會查詢 10002、10003 之類的數據,那麼每一次查詢都會創建一個新的查詢解析。而第二種方式使用了綁定變數,那麼在第一次查詢之後,在共享池中就會存在這類查詢的執行計劃,也就是軟解析。
因此我們可以通過使用綁定變數來減少硬解析,減少 Oracle 的解析工作量。但是這種方式也有缺點,使用動態 SQL 的方式,因為參數不同,會導致 SQL 的執行效率不同,同時 SQL 優化也會比較困難。
MySQL 中的 SQL 是如何執行的
Oracle 中採用了共享池來判斷 SQL 語句是否存在快取和執行計劃,通過這一步驟我們可以知道應該採用硬解析還是軟解析。那麼在 MySQL 中,SQL 是如何被執行的呢?
首先 MySQL 是典型的 C/S 架構,即 Client/Server 架構,伺服器端程式使用的 mysqld。整體的 MySQL 流程如下圖所示:

你能看到 MySQL 由三層組成:
- 連接層:客戶端和伺服器端建立連接,客戶端發送 SQL 至伺服器端;
- SQL 層:對 SQL 語句進行查詢處理;
- 存儲引擎層:與資料庫文件打交道,負責數據的存儲和讀取。
其中 SQL 層與資料庫文件的存儲方式無關,我們來看下 SQL 層的結構:
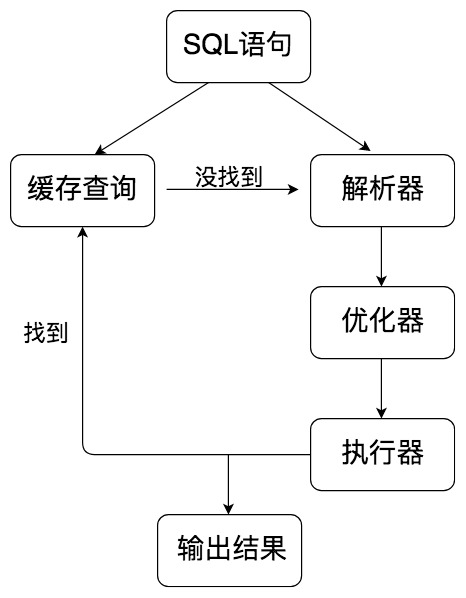
- 查詢快取:Server 如果在查詢快取中發現了這條 SQL 語句,就會直接將結果返回給客戶端;如果沒有,就進入到解析器階段。需要說明的是,因為查詢快取往往效率不高,所以在 MySQL8.0 之後就拋棄了這個功能。
- 解析器:在解析器中對 SQL 語句進行語法分析、語義分析。
- 優化器:在優化器中會確定 SQL 語句的執行路徑,比如是根據全表檢索,還是根據索引來檢索等。
- 執行器:在執行之前需要判斷該用戶是否具備許可權,如果具備許可權就執行 SQL 查詢並返回結果。在 MySQL8.0 以下的版本,如果設置了查詢快取,這時會將查詢結果進行快取。
你能看到 SQL 語句在 MySQL 中的流程是:SQL 語句→快取查詢→解析器→優化器→執行器。在一部分中,MySQL 和 Oracle 執行 SQL 的原理是一樣的。
與 Oracle 不同的是,MySQL 的存儲引擎採用了插件的形式,每個存儲引擎都面向一種特定的資料庫應用環境。同時開源的 MySQL 還允許開發人員設置自己的存儲引擎,下面是一些常見的存儲引擎:
- InnoDB 存儲引擎:它是 MySQL 5.5 版本之後默認的存儲引擎,最大的特點是支援事務、行級鎖定、外鍵約束等。
- MyISAM 存儲引擎:在 MySQL 5.5 版本之前是默認的存儲引擎,不支援事務,也不支援外鍵,最大的特點是速度快,佔用資源少。
- Memory 存儲引擎:使用系統記憶體作為存儲介質,以便得到更快的響應速度。不過如果 mysqld 進程崩潰,則會導致所有的數據丟失,因此我們只有當數據是臨時的情況下才使用 Memory 存儲引擎。
- NDB 存儲引擎:也叫做 NDB Cluster 存儲引擎,主要用於 MySQL Cluster 分散式集群環境,類似於 Oracle 的 RAC 集群。
- Archive 存儲引擎:它有很好的壓縮機制,用於文件歸檔,在請求寫入時會進行壓縮,所以也經常用來做倉庫。
需要注意的是,資料庫的設計在於表的設計,而在 MySQL 中每個表的設計都可以採用不同的存儲引擎,我們可以根據實際的數據處理需要來選擇存儲引擎,這也是 MySQL 的強大之處。
資料庫管理系統也是一種軟體
我們剛才了解了 SQL 語句在 Oracle 和 MySQL 中的執行流程,實際上完整的 Oracle 和 MySQL 結構圖要複雜得多
如果你只是簡單地把 MySQL 和 Oracle 看成資料庫管理系統軟體,從外部看難免會覺得「晦澀難懂」,畢竟組織結構太多了。我們在學習的時候,還需要具備抽象的能力,抓取最核心的部分:SQL 的執行原理。因為不同的 DBMS 的 SQL 的執行原理是相通的,只是在不同的軟體中,各有各的實現路徑。
既然一條 SQL 語句會經歷不同的模組,那我們就來看下,在不同的模組中,SQL 執行所使用的資源(時間)是怎樣的。下面我來教你如何在 MySQL 中對一條 SQL 語句的執行時間進行分析。
首先我們需要看下 profiling 是否開啟,開啟它可以讓 MySQL 收集在 SQL 執行時所使用的資源情況,命令如下:
mysql> select @@profiling;
profiling=0 代表關閉,我們需要把 profiling 打開,即設置為 1:
mysql> set profiling=1;
然後我們執行一個 SQL 查詢(你可以執行任何一個 SQL 查詢):
mysql> select * from wucai.heros;
查看當前會話所產生的所有 profiles:
你會發現我們剛才執行了兩次查詢,Query ID 分別為 1 和 2。如果我們想要獲取上一次查詢的執行時間,可以使用:
mysql> show profile;
當然你也可以查詢指定的 Query ID,比如:
mysql> show profile for query 2;
查詢 SQL 的執行時間結果和上面是一樣的。
在 8.0 版本之後,MySQL 不再支援快取的查詢,原因我在上文已經說過。一旦數據表有更新,快取都將清空,因此只有數據表是靜態的時候,或者數據表很少發生變化時,使用快取查詢才有價值,否則如果數據表經常更新,反而增加了 SQL 的查詢時間。
你可以使用 select version() 來查看 MySQL 的版本情況。
總結
我們在使用 SQL 的時候,往往只見樹木,不見森林,不會注意到它在各種資料庫軟體中是如何執行的,今天我們從全貌的角度來理解這個問題。你能看到不同的 RDBMS 之間有相同的地方,也有不同的地方。
相同的地方在於 Oracle 和 MySQL 都是通過解析器→優化器→執行器這樣的流程來執行 SQL 的。
但 Oracle 和 MySQL 在進行 SQL 的查詢上面有軟體實現層面的差異。Oracle 提出了共享池的概念,通過共享池來判斷是進行軟解析,還是硬解析。而在 MySQL 中,8.0 以後的版本不再支援查詢快取,而是直接執行解析器→優化器→執行器的流程,這一點從 MySQL 中的 show profile 里也能看到。同時 MySQL 的一大特色就是提供了各種存儲引擎以供選擇,不同的存儲引擎有各自的使用場景,我們可以針對每張表選擇適合的存儲引擎。
使用DDL創建資料庫&數據表時需要注意什麼?
DDL 是 DBMS 的核心組件,也是 SQL 的重要組成部分,DDL 的正確性和穩定性是整個 SQL 運行的重要基礎。面對同一個需求,不同的開發人員創建出來的資料庫和數據表可能千差萬別,那麼在設計資料庫的時候,究竟什麼是好的原則?我們在創建數據表的時候需要注意什麼?
DDL 的基礎語法及設計工具
DDL 的英文全稱是 Data Definition Language,中文是數據定義語言。它定義了資料庫的結構和數據表的結構。
在 DDL 中,我們常用的功能是增刪改,分別對應的命令是 CREATE、DROP 和 ALTER。需要注意的是,在執行 DDL 的時候,不需要 COMMIT,就可以完成執行任務。
1.對資料庫進行定義
CREATE DATABASE nba; // 創建一個名為 nba 的資料庫
DROP DATABASE nba; // 刪除一個名為 nba 的資料庫
2.對數據表進行定義
創建表結構的語法是這樣的:
CREATE TABLE table_name
創建表結構
比如我們想創建一個球員表,表名為 player,裡面有兩個欄位,一個是 player_id,它是 int 類型,另一個 player_name 欄位是varchar(255)類型。這兩個欄位都不為空,且 player_id 是遞增的。
那麼創建的時候就可以寫為:
CREATE TABLE player (
player_id int(11) NOT NULL AUTO_INCREMENT,
player_name varchar(255) NOT NULL
);
需要注意的是,語句最後以分號(;)作為結束符,最後一個欄位的定義結束後沒有逗號。數據類型中 int(11) 代表整數類型,顯示長度為 11 位,括弧中的參數 11 代表的是最大有效顯示長度,與類型包含的數值範圍大小無關。varchar(255)代表的是最大長度為 255 的可變字元串類型。NOT NULL表明整個欄位不能是空值,是一種數據約束。AUTO_INCREMENT代表主鍵自動增長。
實際上,我們通常很少自己寫 DDL 語句,可以使用一些可視化工具來創建和操作資料庫和數據表。在這裡我推薦使用 Navicat,它是一個資料庫管理和設計工具,跨平台,支援很多種資料庫管理軟體,比如 MySQL、Oracle、MariaDB 等。基本上專欄講到的資料庫軟體都可以使用 Navicat 來管理。
假如還是針對 player 這張表,我們想設計以下的欄位:
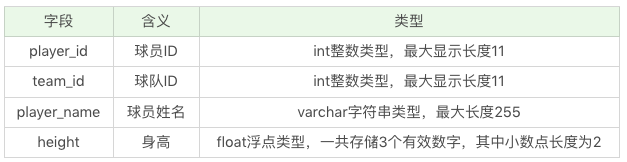
其中 player_id 是數據表 player 的主鍵,且自動增長,也就是 player_id 會從 1 開始,然後每次加 1。player_id、team_id、player_name 這三個欄位均不為空,height 欄位可以為空。
按照上面的設計需求,我們可以使用 Navicat 軟體進行設計,如下所示:
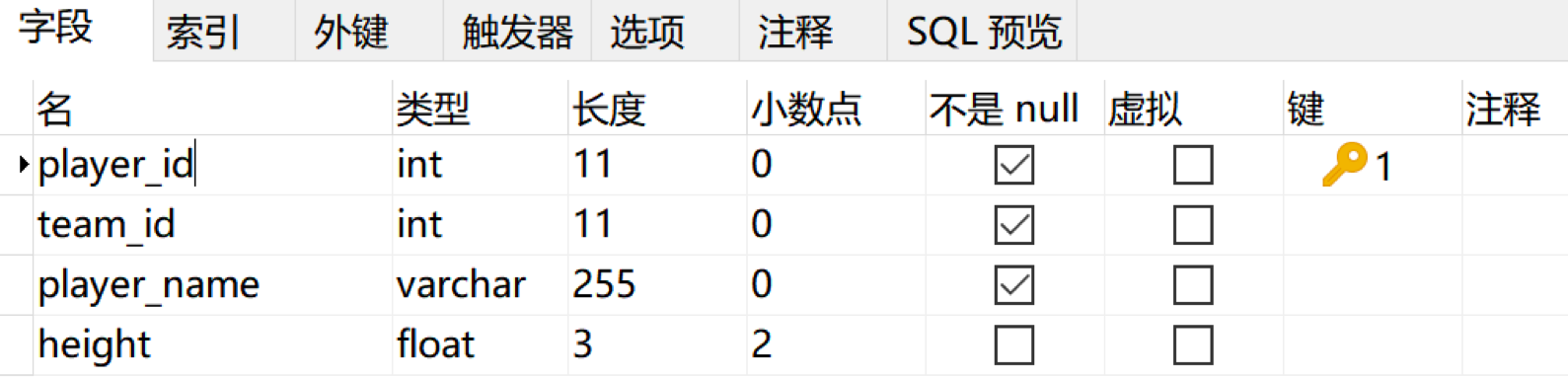
然後,我們還可以對 player_name 欄位進行索引,索引類型為Unique。使用 Navicat 設置如下:

這樣一張 player 表就通過可視化工具設計好了。我們可以把這張表導出來,可以看看這張表對應的 SQL 語句是怎樣的。方法是在 Navicat 左側用右鍵選中 player 這張表,然後選擇「轉儲 SQL 文件」→「僅結構」,這樣就可以看到導出的 SQL 文件了,程式碼如下:
DROP TABLE IF EXISTS `player`;
CREATE TABLE `player` (
`player_id` int(11) NOT NULL AUTO_INCREMENT,
`team_id` int(11) NOT NULL,
`player_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`height` float(3, 2) NULL DEFAULT 0.00,
PRIMARY KEY (`player_id`) USING BTREE,
UNIQUE INDEX `player_name`(`player_name`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
你能看到整個 SQL 文件中的 DDL 處理,首先先刪除 player 表(如果資料庫中存在該表的話),然後再創建 player 表,裡面的數據表和欄位都使用了反引號,這是為了避免它們的名稱與 MySQL 保留欄位相同,對數據表和欄位名稱都加上了反引號。
其中 player_name 欄位的字符集是 utf8,排序規則是utf8_general_ci,代表對大小寫不敏感,如果設置為utf8_bin,代表對大小寫敏感,還有許多其他排序規則這裡不進行介紹。
因為 player_id 設置為了主鍵,因此在 DDL 中使用PRIMARY KEY進行規定,同時索引方法採用 BTREE。
因為我們對 player_name 欄位進行索引,在設置欄位索引時,我們可以設置為UNIQUE INDEX(唯一索引),也可以設置為其他索引方式,比如NORMAL INDEX(普通索引),這裡我們採用UNIQUE INDEX。唯一索引和普通索引的區別在於它對欄位進行了唯一性的約束。在索引方式上,你可以選擇BTREE或者HASH,這裡採用了BTREE方法進行索引。我會在後面介紹BTREE和HASH索引方式的區別。
整個數據表的存儲規則採用 InnoDB。之前我們簡單介紹過 InnoDB,它是 MySQL5.5 版本之後默認的存儲引擎。同時,我們將字符集設置為 utf8,排序規則為utf8_general_ci,行格式為Dynamic,就可以定義數據表的最後約定了:
ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
你能看出可視化工具還是非常方便的,它能直接幫我們將資料庫的結構定義轉化成 SQL 語言,方便資料庫和數據表結構的導出和導入。不過在使用可視化工具前,你首先需要了解對於 DDL 的基礎語法,至少能清晰地看出來不同欄位的定義規則、索引方法,以及主鍵和外鍵的定義。
修改表結構
在創建表結構之後,我們還可以對錶結構進行修改,雖然直接使用 Navicat 可以保證重新導出的數據表就是最新的,但你也有必要了解,如何使用 DDL 命令來完成表結構的修改。
\1. 添加欄位,比如我在數據表中添加一個 age 欄位,類型為int(11)
ALTER TABLE player ADD (age int(11));
\2. 修改欄位名,將 age 欄位改成player_age
ALTER TABLE player RENAME COLUMN age to player_age
\3. 修改欄位的數據類型,將player_age的數據類型設置為float(3,1)
ALTER TABLE player MODIFY (player_age float(3,1));
\4. 刪除欄位, 刪除剛才添加的player_age欄位
ALTER TABLE player DROP COLUMN player_age;
數據表的常見約束
當我們創建數據表的時候,還會對欄位進行約束,約束的目的在於保證 RDBMS 裡面數據的準確性和一致性。下面,我們來看下常見的約束有哪些。
首先是主鍵約束。
主鍵起的作用是唯一標識一條記錄,不能重複,不能為空,即 UNIQUE+NOT NULL。一個數據表的主鍵只能有一個。主鍵可以是一個欄位,也可以由多個欄位複合組成。在上面的例子中,我們就把 player_id 設置為了主鍵。
其次還有外鍵約束。
外鍵確保了表與表之間引用的完整性。一個表中的外鍵對應另一張表的主鍵。外鍵可以是重複的,也可以為空。比如 player_id 在 player 表中是主鍵,如果你想設置一個球員比分表即 player_score,就可以在 player_score 中設置 player_id 為外鍵,關聯到 player 表中。
除了對鍵進行約束外,還有欄位約束。
唯一性約束
唯一性約束表明了欄位在表中的數值是唯一的,即使我們已經有了主鍵,還可以對其他欄位進行唯一性約束。比如我們在 player 表中給 player_name 設置唯一性約束,就表明任何兩個球員的姓名不能相同。需要注意的是,唯一性約束和普通索引(NORMAL INDEX)之間是有區別的。唯一性約束相當於創建了一個約束和普通索引,目的是保證欄位的正確性,而普通索引只是提升數據檢索的速度,並不對欄位的唯一性進行約束。
NOT NULL 約束。對欄位定義了 NOT NULL,即表明該欄位不應為空,必須有取值。
DEFAULT,表明了欄位的默認值。如果在插入數據的時候,這個欄位沒有取值,就設置為默認值。比如我們將身高 height 欄位的取值默認設置為 0.00,即DEFAULT 0.00。
CHECK 約束,用來檢查特定欄位取值範圍的有效性,CHECK 約束的結果不能為 FALSE,比如我們可以對身高 height 的數值進行 CHECK 約束,必須≥0,且<3,即CHECK(height>=0 AND height<3)。
設計數據表的原則
我們在設計數據表的時候,經常會考慮到各種問題,比如:
- 用戶都需要什麼數據?
- 需要在數據表中保存哪些數據?
- 哪些數據是經常訪問的數據?
- 如何提升檢索效率?
- 如何保證數據表中數據的正確性,當插入、刪除、更新的時候該進行怎樣的約束檢查?
- 如何降低數據表的數據冗餘度,保證數據表不會因為用戶量的增長而迅速擴張?
- 如何讓負責資料庫維護的人員更方便地使用資料庫?
除此以外,我們使用資料庫的應用場景也各不相同,可以說針對不同的情況,設計出來的數據表可能千差萬別。那麼有沒有一種設計原則可以讓我們來借鑒呢?這裡我整理了一個「三少一多」原則:
數據表的個數越少越好
RDBMS 的核心在於對實體和聯繫的定義,也就是 E-R 圖(Entity Relationship Diagram),數據表越少,證明實體和聯繫設計得越簡潔,既方便理解又方便操作。
數據表中的欄位個數越少越好
欄位個數越多,數據冗餘的可能性越大。設置欄位個數少的前提是各個欄位相互獨立,而不是某個欄位的取值可以由其他欄位計算出來。當然欄位個數少是相對的,我們通常會在數據冗餘和檢索效率中進行平衡。
數據表中聯合主鍵的欄位個數越少越好
設置主鍵是為了確定唯一性,當一個欄位無法確定唯一性的時候,就需要採用聯合主鍵的方式(也就是用多個欄位來定義一個主鍵)。聯合主鍵中的欄位越多,佔用的索引空間越大,不僅會加大理解難度,還會增加運行時間和索引空間,因此聯合主鍵的欄位個數越少越好。
使用主鍵和外鍵越多越好
資料庫的設計實際上就是定義各種表,以及各種欄位之間的關係。這些關係越多,證明這些實體之間的冗餘度越低,利用度越高。這樣做的好處在於不僅保證了數據表之間的獨立性,還能提升相互之間的關聯使用率。
你應該能看出來「三少一多」原則的核心就是簡單可復用。簡單指的是用更少的表、更少的欄位、更少的聯合主鍵欄位來完成數據表的設計。可復用則是通過主鍵、外鍵的使用來增強數據表之間的復用率。因為一個主鍵可以理解是一張表的代表。鍵設計得越多,證明它們之間的利用率越高。
總結
今天我們學習了 DDL 的基礎語法,比如如何對資料庫和資料庫表進行定義,也了解了使用 Navicat 可視化管理工具來輔助我們完成數據表的設計,省去了手寫 SQL 的工作量。
在創建數據表的時候,除了對欄位名及數據類型進行定義以外,我們考慮最多的就是關於欄位的約束,我介紹了 7 種常見的約束,它們都是數據表設計中會用到的約束:主鍵、外鍵、唯一性、NOT NULL、DEFAULT、CHECK 約束等。
當然,了解了如何操作創建數據表之後,你還需要動腦思考,怎樣才能設計出一個好的數據表?設計的原則都有哪些?針對這個,我整理出了「三少一多」原則,在實際使用過程中,你需要靈活掌握,因為這個原則並不是絕對的,有時候我們需要犧牲數據的冗餘度來換取數據處理的效率。
檢索數據
SELECT 可以說是 SQL 中最常用的語句了。你可以把 SQL 語句看作是英語語句,SELECT 就是 SQL 中的關鍵字之一,除了 SELECT 之外,還有 INSERT、DELETE、UPDATE 等關鍵字,這些關鍵字是 SQL 的保留字,這樣可以很方便地幫助我們分析理解 SQL 語句。我們在定義資料庫表名、欄位名和變數名時,要盡量避免使用這些保留字。
SELECT 的作用是從一個表或多個表中檢索出想要的數據行。
SELECT 查詢的基礎語法
SELECT 可以幫助我們從一個表或多個表中進行數據查詢。我們知道一個數據表是由列(欄位名)和行(數據行)組成的,我們要返回滿足條件的數據行,就需要在 SELECT 後面加上我們想要查詢的列名,可以是一列,也可以是多個列。如果你不知道所有列名都有什麼,也可以檢索所有列。
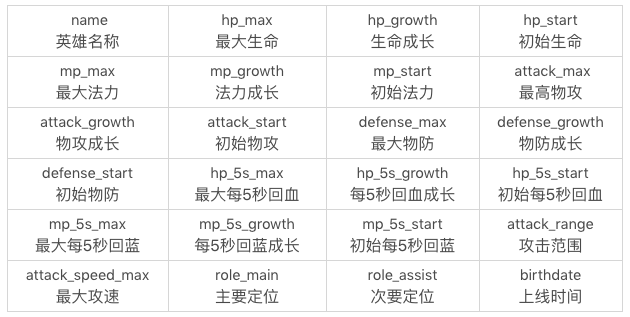
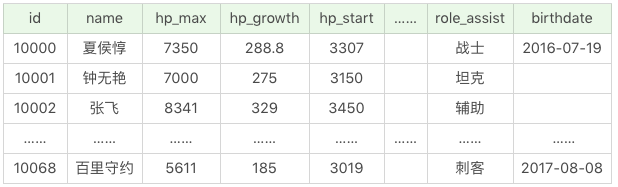
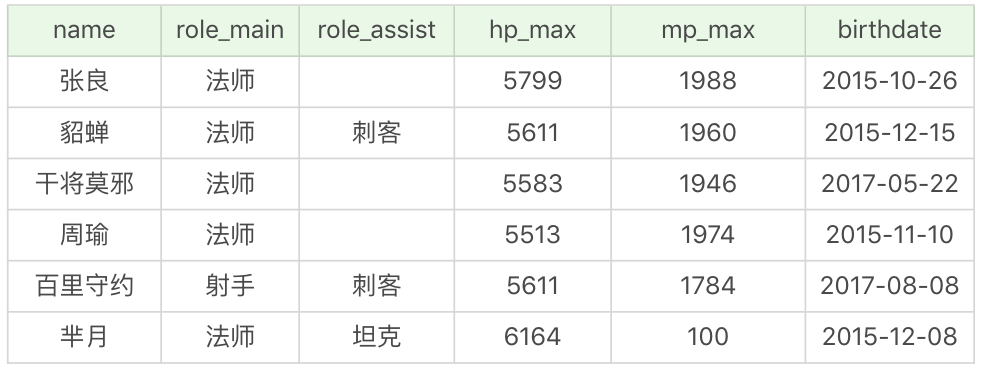
我創建了一個王者榮耀英雄數據表,這張表裡一共有 69 個英雄,23 個屬性值(不包括英雄名 name)。SQL 文件見百度網盤鏈接 提取碼:gov5

數據表中這 24 個欄位(除了 id 以外),分別代表的含義見下圖。
查詢列
如果我們想要對數據表中的某一列進行檢索,在 SELECT 後面加上這個列的欄位名即可。比如我們想要檢索數據表中都有哪些英雄。
SQL:SELECT name FROM heros
運行結果(69 條記錄)見下圖,你可以看到這樣就等於單獨輸出了 name 這一列。

我們也可以對多個列進行檢索,在列名之間用逗號 (,) 分割即可。比如我們想要檢索有哪些英雄,他們的最大生命、最大法力、最大物攻和最大物防分別是多少。
SQL:SELECT name, hp_max, mp_max, attack_max, defense_max FROM heros
運行結果(69 條記錄):

這個表中一共有 25 個欄位,除了 id 和英雄名 name 以外,還存在 23 個屬性值,如果我們記不住所有的欄位名稱,可以使用 SELECT * 幫我們檢索出所有的列:
SQL:SELECT * FROM heros
運行結果(69 條記錄):
我們在做數據探索的時候,SELECT *還是很有用的,這樣我們就不需要寫很長的 SELECT 語句了。但是在生產環境時要盡量避免使用SELECT*。
起別名
我們在使用 SELECT 查詢的時候,還有一些技巧可以使用,比如你可以給列名起別名。我們在進行檢索的時候,可以給英雄名、最大生命、最大法力、最大物攻和最大物防等取別名:
SQL:SELECT name AS n, hp_max AS hm, mp_max AS mm, attack_max AS am, defense_max AS dm FROM heros
運行結果和上面多列檢索的運行結果是一樣的,只是將列名改成了 n、hm、mm、am 和 dm。當然這裡的列別名只是舉例,一般來說起別名的作用是對原有名稱進行簡化,從而讓 SQL 語句看起來更精簡。同樣我們也可以對錶名稱起別名,這個在多表連接查詢的時候會用到。
查詢常數
SELECT 查詢還可以對常數進行查詢。對的,就是在 SELECT 查詢結果中增加一列固定的常數列。這列的取值是我們指定的,而不是從數據表中動態取出的。你可能會問為什麼我們還要對常數進行查詢呢?SQL 中的 SELECT 語法的確提供了這個功能,一般來說我們只從一個表中查詢數據,通常不需要增加一個固定的常數列,但如果我們想整合不同的數據源,用常數列作為這個表的標記,就需要查詢常數。
比如說,我們想對 heros 數據表中的英雄名進行查詢,同時增加一列欄位platform,這個欄位固定值為「王者榮耀」,可以這樣寫:
SQL:SELECT '王者榮耀' as platform, name FROM heros
運行結果:(69 條記錄)

在這個 SQL 語句中,我們虛構了一個platform欄位,並且把它設置為固定值「王者榮耀」。
需要說明的是,如果常數是個字元串,那麼使用單引號(『』)就非常重要了,比如『王者榮耀』。單引號說明引號中的字元串是個常數,否則 SQL 會把王者榮耀當成列名進行查詢,但實際上數據表裡沒有這個列名,就會引起錯誤。如果常數是英文字母,比如'WZRY'也需要加引號。如果常數是個數字,就可以直接寫數字,不需要單引號,比如:
SQL:SELECT 123 as platform, name FROM heros
運行結果:(69 條記錄)
去除重複行
關於單個表的 SELECT 查詢,還有一個非常實用的操作,就是從結果中去掉重複的行。使用的關鍵字是 DISTINCT。比如我們想要看下 heros 表中關於攻擊範圍的取值都有哪些:
SQL:SELECT DISTINCT attack_range FROM heros
這是運行結果(2 條記錄),這樣我們就能直觀地看到攻擊範圍其實只有兩個值,那就是近戰和遠程。

如果我們帶上英雄名稱,會是怎樣呢:
SQL:SELECT DISTINCT attack_range, name FROM heros
運行結果(69 條記錄):
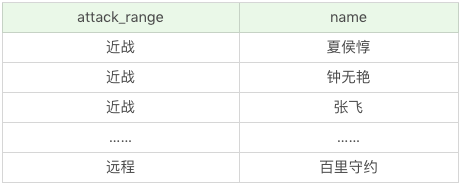
這裡有兩點需要注意:
- DISTINCT 需要放到所有列名的前面,如果寫成
SELECT name, DISTINCT attack_range FROM heros會報錯。 - DISTINCT 其實是對後面所有列名的組合進行去重,你能看到最後的結果是 69 條,因為這 69 個英雄名稱不同,都有攻擊範圍(attack_range)這個屬性值。如果你想要看都有哪些不同的攻擊範圍(attack_range),只需要寫
DISTINCT attack_range即可,後面不需要再加其他的列名了。
如何排序檢索數據
當我們檢索數據的時候,有時候需要按照某種順序進行結果的返回,比如我們想要查詢所有的英雄,按照最大生命從高到底的順序進行排列,就需要使用 ORDER BY 子句。使用 ORDER BY 子句有以下幾個點需要掌握:
- 排序的列名:ORDER BY 後面可以有一個或多個列名,如果是多個列名進行排序,會按照後面第一個列先進行排序,當第一列的值相同的時候,再按照第二列進行排序,以此類推。
- 排序的順序:ORDER BY 後面可以註明排序規則,ASC 代表遞增排序,DESC 代表遞減排序。如果沒有註明排序規則,默認情況下是按照 ASC 遞增排序。我們很容易理解 ORDER BY 對數值類型欄位的排序規則,但如果排序欄位類型為文本數據,就需要參考資料庫的設置方式了,這樣才能判斷 A 是在 B 之前,還是在 B 之後。比如使用 MySQL 在創建欄位的時候設置為 BINARY 屬性,就代表區分大小寫。
- 非選擇列排序:ORDER BY 可以使用非選擇列進行排序,所以即使在 SELECT 後面沒有這個列名,你同樣可以放到 ORDER BY 後面進行排序。
- ORDER BY 的位置:ORDER BY 通常位於 SELECT 語句的最後一條子句,否則會報錯。
在了解了 ORDER BY 的使用語法之後,我們來看下如何對 heros 數據表進行排序。
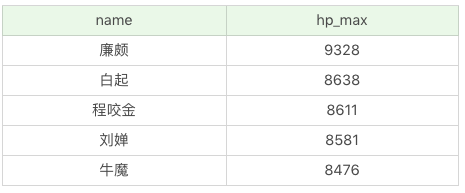
假設我們想要顯示英雄名稱及最大生命值,按照最大生命值從高到低的方式進行排序:
SQL:SELECT name, hp_max FROM heros ORDER BY hp_max DESC
運行結果(69 條記錄):
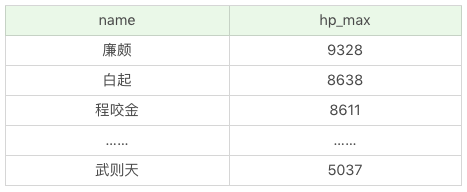
如果想要顯示英雄名稱及最大生命值,按照第一排序最大法力從低到高,當最大法力值相等的時候則按照第二排序進行,即最大生命值從高到低的方式進行排序:
SQL:SELECT name, hp_max FROM heros ORDER BY mp_max, hp_max DESC
運行結果:(69 條記錄)
約束返回結果的數量
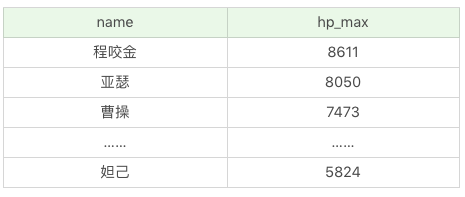
另外在查詢過程中,我們可以約束返回結果的數量,使用 LIMIT 關鍵字。比如我們想返回英雄名稱及最大生命值,按照最大生命值從高到低排序,返回 5 條記錄即可。
SQL:SELECT name, hp_max FROM heros ORDER BY hp_max DESC LIMIT 5
運行結果(5 條記錄):
有一點需要注意,約束返回結果的數量,在不同的 DBMS 中使用的關鍵字可能不同。在 MySQL、PostgreSQL、MariaDB 和 SQLite 中使用 LIMIT 關鍵字,而且需要放到 SELECT 語句的最後面。如果是 SQL Server 和 Access,需要使用 TOP 關鍵字,比如:
SQL:SELECT TOP 5 name, hp_max FROM heros ORDER BY hp_max DESC
如果是 DB2,使用FETCH FIRST 5 ROWS ONLY這樣的關鍵字:
SQL:SELECT name, hp_max FROM heros ORDER BY hp_max DESC FETCH FIRST 5 ROWS ONLY
如果是 Oracle,你需要基於 ROWNUM 來統計行數:
SQL:SELECT name, hp_max FROM heros WHERE ROWNUM <=5 ORDER BY hp_max DESC
需要說明的是,這條語句是先取出來前 5 條數據行,然後再按照 hp_max 從高到低的順序進行排序。但這樣產生的結果和上述方法的並不一樣。我會在後面講到子查詢,你可以使用SELECT name, hp_max FROM (SELECT name, hp_max FROM heros ORDER BY hp_max) WHERE ROWNUM <=5得到與上述方法一致的結果。
約束返回結果的數量可以減少數據表的網路傳輸量,也可以提升查詢效率。如果我們知道返回結果只有 1 條,就可以使用LIMIT 1,告訴 SELECT 語句只需要返回一條記錄即可。這樣的好處就是 SELECT 不需要掃描完整的表,只需要檢索到一條符合條件的記錄即可返回。
SELECT 的執行順序
查詢是 RDBMS 中最頻繁的操作。我們在理解 SELECT 語法的時候,還需要了解 SELECT 執行時的底層原理。只有這樣,才能讓我們對 SQL 有更深刻的認識。
其中你需要記住 SELECT 查詢時的兩個順序:
關鍵字的順序是不能顛倒的:
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ...
SELECT 語句的執行順序(在 MySQL 和 Oracle 中,SELECT 執行順序基本相同):
FROM > WHERE > GROUP BY > HAVING > SELECT 的欄位 > DISTINCT > ORDER BY > LIMIT
比如你寫了一個 SQL 語句,那麼它的關鍵字順序和執行順序是下面這樣的:
SELECT DISTINCT player_id, player_name, count(*) as num # 順序 5
FROM player JOIN team ON player.team_id = team.team_id # 順序 1
WHERE height > 1.80 # 順序 2
GROUP BY player.team_id # 順序 3
HAVING num > 2 # 順序 4
ORDER BY num DESC # 順序 6
LIMIT 2 # 順序 7
在 SELECT 語句執行這些步驟的時候,每個步驟都會產生一個虛擬表,然後將這個虛擬表傳入下一個步驟中作為輸入。需要注意的是,這些步驟隱含在 SQL 的執行過程中,對於我們來說是不可見的。
詳細解釋一下 SQL 的執行原理。
首先,你可以注意到,SELECT 是先執行 FROM 這一步的。在這個階段,如果是多張表聯查,還會經歷下面的幾個步驟:
- 首先先通過 CROSS JOIN 求笛卡爾積,相當於得到虛擬表 vt(virtual table)1-1;
- 通過 ON 進行篩選,在虛擬表 vt1-1 的基礎上進行篩選,得到虛擬表 vt1-2;
- 添加外部行。如果我們使用的是左連接、右鏈接或者全連接,就會涉及到外部行,也就是在虛擬表 vt1-2 的基礎上增加外部行,得到虛擬表 vt1-3。
當然如果我們操作的是兩張以上的表,還會重複上面的步驟,直到所有表都被處理完為止。這個過程得到是我們的原始數據。
當我們拿到了查詢數據表的原始數據,也就是最終的虛擬表 vt1,就可以在此基礎上再進行 WHERE 階段。在這個階段中,會根據 vt1 表的結果進行篩選過濾,得到虛擬表 vt2。
然後進入第三步和第四步,也就是 GROUP 和 HAVING 階段。在這個階段中,實際上是在虛擬表 vt2 的基礎上進行分組和分組過濾,得到中間的虛擬表 vt3 和 vt4。
當我們完成了條件篩選部分之後,就可以篩選表中提取的欄位,也就是進入到 SELECT 和 DISTINCT 階段。
首先在 SELECT 階段會提取想要的欄位,然後在 DISTINCT 階段過濾掉重複的行,分別得到中間的虛擬表 vt5-1 和 vt5-2。
當我們提取了想要的欄位數據之後,就可以按照指定的欄位進行排序,也就是 ORDER BY 階段,得到虛擬表 vt6。
最後在 vt6 的基礎上,取出指定行的記錄,也就是 LIMIT 階段,得到最終的結果,對應的是虛擬表 vt7。
當然我們在寫 SELECT 語句的時候,不一定存在所有的關鍵字,相應的階段就會省略。
同時因為 SQL 是一門類似英語的結構化查詢語言,所以我們在寫 SELECT 語句的時候,還要注意相應的關鍵字順序,所謂底層運行的原理,就是我們剛才講到的執行順序。
什麼情況下用 SELECT*,如何提升 SELECT 查詢效率?
當我們初學 SELECT 語法的時候,經常會使用SELECT *,因為使用方便。實際上這樣也增加了資料庫的負擔。所以如果我們不需要把所有列都檢索出來,還是先指定出所需的列名,因為寫清列名,可以減少數據表查詢的網路傳輸量,而且考慮到在實際的工作中,我們往往不需要全部的列名,因此你需要養成良好的習慣,寫出所需的列名。
如果我們只是練習,或者對數據表進行探索,那麼是可以使用SELECT *的。它的查詢效率和把所有列名都寫出來再進行查詢的效率相差並不大。這樣可以方便你對數據表有個整體的認知。但是在生產環境下,不推薦你直接使用SELECT *進行查詢。
總結
對 SELECT 的基礎語法進行了講解,SELECT 是 SQL 的基礎。但不同階段看 SELECT 都會有新的體會。當你第一次學習的時候,關注的往往是如何使用它,或者語法是否正確。再看的時候,可能就會更關注 SELECT 的查詢效率,以及不同 DBMS 之間的差別。
在我們的日常工作中,很多人都可以寫出 SELECT 語句,但是執行的效率卻相差很大。產生這種情況的原因主要有兩個,一個是習慣的培養,比如大部分初學者會經常使用SELECT *,而好的習慣則是只查詢所需要的列;另一個對 SQL 查詢的執行順序及查詢效率的關注,比如當你知道只有 1 條記錄的時候,就可以使用LIMIT 1來進行約束,從而提升查詢效率。
數據過濾
提升查詢效率的一個很重要的方式,就是約束返回結果的數量,還有一個很有效的方式,就是指定篩選條件,進行過濾。過濾可以篩選符合條件的結果,並進行返回,減少不必要的數據行。
你可能已經使用過 WHERE 子句,說起來 SQL 其實很簡單,只要能把滿足條件的內容篩選出來即可,但在實際使用過程中,不同人寫出來的 WHERE 子句存在很大差別,比如執行效率的高低,有沒有遇到莫名的報錯等。
比較運算符
在 SQL 中,我們可以使用 WHERE 子句對條件進行篩選,在此之前,你需要了解 WHERE 子句中的比較運算符。這些比較運算符的含義你可以參見下面這張表格:
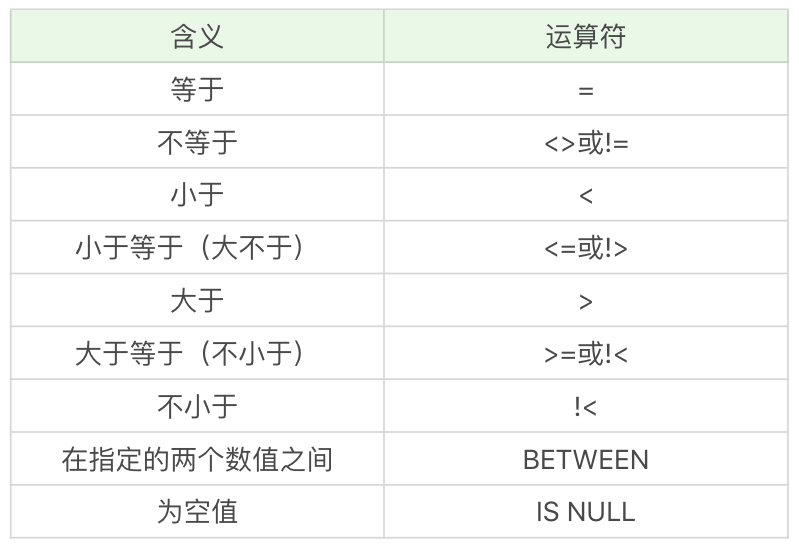
實際上你能看到,同樣的含義可能會有多種表達方式,比如小於等於,可以是(<=),也可以是不大於(!>)。同樣不等於,可以用(<>),也可以用(!=),它們的含義都是相同的,但這些符號的順序都不能顛倒,比如你不能寫(=<)。需要注意的是,你需要查看使用的 DBMS 是否支援,不同的 DBMS 支援的運算符可能是不同的,比如 Access 不支援(!=),不等於應該使用(<>)。在 MySQL 中,不支援(!>)(!<)等。
WHERE 子句的基本格式是:SELECT ……(列名) FROM ……(表名) WHERE ……(子句條件)
比如我們想要查詢所有最大生命值大於 6000 的英雄:
SQL:SELECT name, hp_max FROM heros WHERE hp_max > 6000
運行結果(41 條記錄):

想要查詢所有最大生命值在 5399 到 6811 之間的英雄:
SQL:SELECT name, hp_max FROM heros WHERE hp_max BETWEEN 5399 AND 6811
運行結果:(41 條記錄)

需要注意的是hp_max可以取值到最小值和最大值,即 5399 和 6811。
我們也可以對 heros 表中的hp_max欄位進行空值檢查。
SQL:SELECT name, hp_max FROM heros WHERE hp_max IS NULL
運行結果為空,說明 heros 表中的hp_max欄位沒有存在空值的數據行。
邏輯運算符
我剛才介紹了比較運算符,如果我們存在多個 WHERE 條件子句,可以使用邏輯運算符:
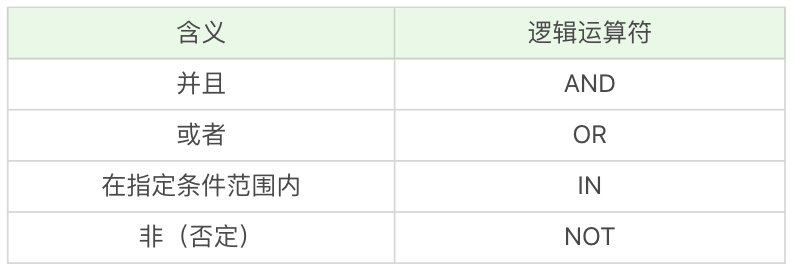
假設想要篩選最大生命值大於 6000,最大法力大於 1700 的英雄,然後按照最大生命值和最大法力值之和從高到低進行排序。
SQL:SELECT name, hp_max, mp_max FROM heros WHERE hp_max > 6000 AND mp_max > 1700 ORDER BY (hp_max+mp_max) DESC
運行結果:(23 條記錄)

如果 AND 和 OR 同時存在 WHERE 子句中會是怎樣的呢?假設我們想要查詢最大生命值加最大法力值大於 8000 的英雄,或者最大生命值大於 6000 並且最大法力值大於 1700 的英雄。
SQL:SELECT name, hp_max, mp_max FROM heros WHERE (hp_max+mp_max) > 8000 OR hp_max > 6000 AND mp_max > 1700 ORDER BY (hp_max+mp_max) DESC
運行結果:(33 條記錄)

你能看出來相比於上一個條件查詢,這次的條件查詢多出來了 10 個英雄,這是因為我們放寬了條件,允許最大生命值 + 最大法力值大於 8000 的英雄顯示出來。另外你需要注意到,當 WHERE 子句中同時存在 OR 和 AND 的時候,AND 執行的優先順序會更高,也就是說 SQL 會優先處理 AND 操作符,然後再處理 OR 操作符。
如果我們對這條查詢語句 OR 兩邊的條件增加一個括弧,結果會是怎樣的呢?
SQL:SELECT name, hp_max, mp_max FROM heros WHERE ((hp_max+mp_max) > 8000 OR hp_max > 6000) AND mp_max > 1700 ORDER BY (hp_max+mp_max) DESC
運行結果:

所以當 WHERE 子句中同時出現 AND 和 OR 操作符的時候,你需要考慮到執行的先後順序,也就是兩個操作符執行的優先順序。一般來說 () 優先順序最高,其次優先順序是 AND,然後是 OR。
如果我想要查詢主要定位或者次要定位是法師或是射手的英雄,同時英雄的上線時間不在 2016-01-01 到 2017-01-01 之間。
SQL:
SELECT name, role_main, role_assist, hp_max, mp_max, birthdate
FROM heros
WHERE (role_main IN ('法師', '射手') OR role_assist IN ('法師', '射手'))
AND DATE(birthdate) NOT BETWEEN '2016-01-01' AND '2017-01-01'
ORDER BY (hp_max + mp_max) DESC
你能看到我把 WHERE 子句分成了兩個部分。第一部分是關於主要定位和次要定位的條件過濾,使用的是role_main in ('法師', '射手') OR role_assist in ('法師', '射手')。這裡用到了 IN 邏輯運算符,同時role_main和role_assist是 OR(或)的關係。
第二部分是關於上線時間的條件過濾。NOT 代表否,因為我們要找到不在 2016-01-01 到 2017-01-01 之間的日期,因此用到了NOT BETWEEN '2016-01-01' AND '2017-01-01'。同時我們是在對日期類型數據進行檢索,所以使用到了 DATE 函數,將欄位 birthdate 轉化為日期類型再進行比較。
這是運行結果(6 條記錄):
使用通配符進行過濾
剛才講解的條件過濾都是對已知值進行的過濾,還有一種情況是我們要檢索文本中包含某個詞的所有數據,這裡就需要使用通配符。通配符就是我們用來匹配值的一部分的特殊字元。這裡我們需要使用到 LIKE 操作符。
如果我們想要匹配任意字元串出現的任意次數,需要使用(%)通配符。比如我們想要查找英雄名中包含「太」字的英雄都有哪些:
SQL:SELECT name FROM heros WHERE name LIKE '% 太 %'
運行結果:(2 條記錄)

需要說明的是不同 DBMS 對通配符的定義不同,在 Access 中使用的是(*)而不是(%)。另外關於字元串的搜索可能是需要區分大小寫的,比如'liu%'就不能匹配上'LIU BEI'。具體是否區分大小寫還需要考慮不同的 DBMS 以及它們的配置。
如果我們想要匹配單個字元,就需要使用下劃線 (_) 通配符。(%)和(_)的區別在於,(%)代表一個或多個字元,而(_)只代表一個字元。比如我們想要查找英雄名除了第一個字以外,包含「太」字的英雄有哪些。
SQL:SELECT name FROM heros WHERE name LIKE '_% 太 %'
運行結果(1 條記錄):

因為太乙真人的太是第一個字元,而_%太%中的太不是在第一個字元,所以匹配不到「太乙真人」,只可以匹配上「東皇太一」。
同樣需要說明的是,在 Access 中使用(?)來代替(_),而且在 DB2 中是不支援通配符(_)的,因此你需要在使用的時候查閱相關的 DBMS 文檔。
你能看出來通配符還是很有用的,尤其是在進行字元串匹配的時候。不過在實際操作過程中,我還是建議你盡量少用通配符,因為它需要消耗資料庫更長的時間來進行匹配。即使你對 LIKE 檢索的欄位進行了索引,索引的價值也可能會失效。如果要讓索引生效,那麼 LIKE 後面就不能以(%)開頭,比如使用LIKE '%太%'或LIKE '%太'的時候就會對全表進行掃描。如果使用LIKE '太%',同時檢索的欄位進行了索引的時候,則不會進行全表掃描。
總結
對 SQL 語句中的 WHERE 子句進行了講解,你可以使用比較運算符、邏輯運算符和通配符這三種方式對檢索條件進行過濾。
比較運算符是對數值進行比較,不同的 DBMS 支援的比較運算符可能不同,你需要事先查閱相應的 DBMS 文檔。邏輯運算符可以讓我們同時使用多個 WHERE 子句,你需要注意的是 AND 和 OR 運算符的執行順序。通配符可以讓我們對文本類型的欄位進行模糊查詢,不過檢索的代價也是很高的,通常都需要用到全表掃描,所以效率很低。只有當 LIKE 語句後面不用通配符,並且對欄位進行索引的時候才不會對全表進行掃描。
你可能認為學習 SQL 並不難,掌握這些語法就可以對數據進行篩選查詢。但實際工作中不同人寫的 SQL 語句的查詢效率差別很大,保持高效率的一個很重要的原因,就是要避免全表掃描,所以我們會考慮在 WHERE 及 ORDER BY 涉及到的列上增加索引。
SQL函數
函數在電腦語言的使用中貫穿始終,在 SQL 中我們也可以使用函數對檢索出來的數據進行函數操作,比如求某列數據的平均值,或者求字元串的長度等。從函數定義的角度出發,我們可以將函數分成內置函數和自定義函數。在 SQL 語言中,同樣也包括了內置函數和自定義函數。內置函數是系統內置的通用函數,而自定義函數是我們根據自己的需要編寫的,下面講解的是 SQL 的內置函數。
什麼是 SQL 函數
當我們學習程式語言的時候,也會遇到函數。函數的作用是什麼呢?它可以把我們經常使用的程式碼封裝起來,需要的時候直接調用即可。這樣既提高了程式碼效率,又提高了可維護性。
SQL 中的函數一般是在數據上執行的,可以很方便地轉換和處理數據。一般來說,當我們從數據表中檢索出數據之後,就可以進一步對這些數據進行操作,得到更有意義的結果,比如返回指定條件的函數,或者求某個欄位的平均值等。
常用的 SQL 函數有哪些
SQL 提供了一些常用的內置函數,當然你也可以自己定義 SQL 函數。SQL 的內置函數對於不同的資料庫軟體來說具有一定的通用性,我們可以把內置函數分成四類:
- 算術函數
- 字元串函數
- 日期函數
- 轉換函數
這 4 類函數分別代表了算術處理、字元串處理、日期處理、數據類型轉換,它們是 SQL 函數常用的劃分形式,你可以思考下,為什麼是這 4 個維度?
函數是對提取出來的數據進行操作,那麼數據表中欄位類型的定義有哪幾種呢?
我們經常會保存一些數值,不論是整數類型,還是浮點類型,實際上對應的就是數值類型。
同樣我們也會保存一些文本內容,可能是人名,也可能是某個說明,對應的就是字元串類型。
此外我們還需要保存時間,也就是日期類型。那麼針對數值、字元串和日期類型的數據,我們可以對它們分別進行算術函數、字元串函數以及日期函數的操作。
如果想要完成不同類型數據之間的轉換,就可以使用轉換函數。
算術函數
算術函數,顧名思義就是對數值類型的欄位進行算術運算。常用的算術函數及含義如下表所示:

舉一些簡單的例子:
SELECT ABS(-2),運行結果為 2。
SELECT MOD(101,3),運行結果 2。
SELECT ROUND(37.25,1),運行結果 37.3。
字元串函數
常用的字元串函數操作包括了字元串拼接,大小寫轉換,求長度以及字元串替換和截取等。具體的函數名稱及含義如下表所示:
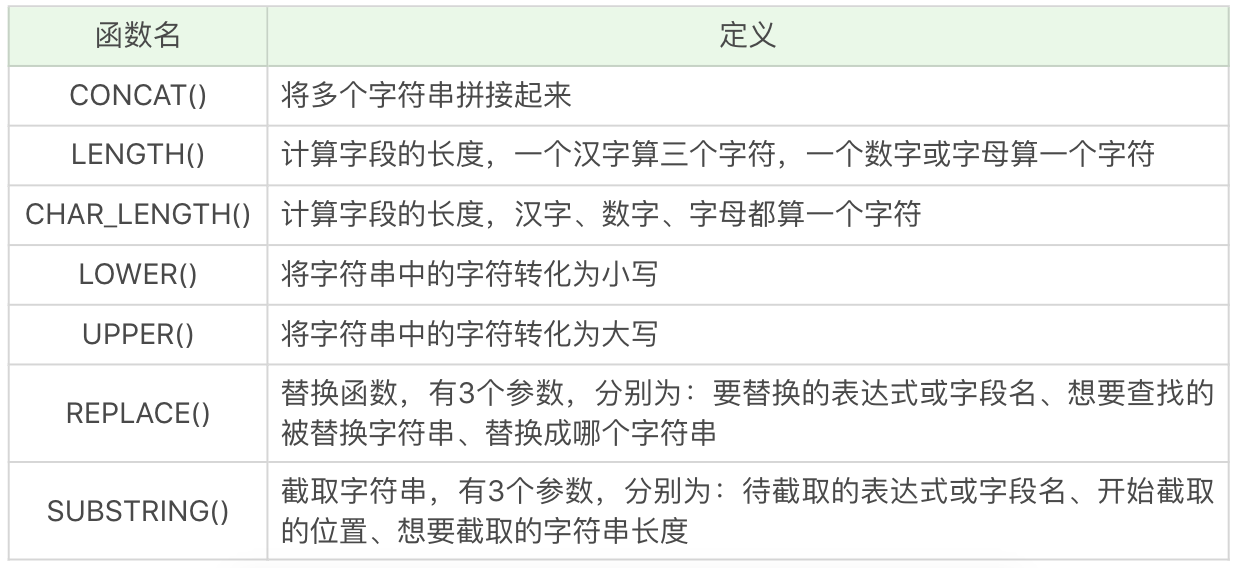
同樣有一些簡單的例子:
SELECT CONCAT('abc', 123),運行結果為 abc123。
SELECT LENGTH('你好'),運行結果為 6。
SELECT CHAR_LENGTH('你好'),運行結果為 2。
SELECT LOWER('ABC'),運行結果為 abc。
SELECT UPPER('abc'),運行結果 ABC。
SELECT REPLACE('fabcd', 'abc', 123),運行結果為 f123d。
SELECT SUBSTRING('fabcd', 1,3),運行結果為 fab。
日期函數
日期函數是對數據表中的日期進行處理,常用的函數包括:
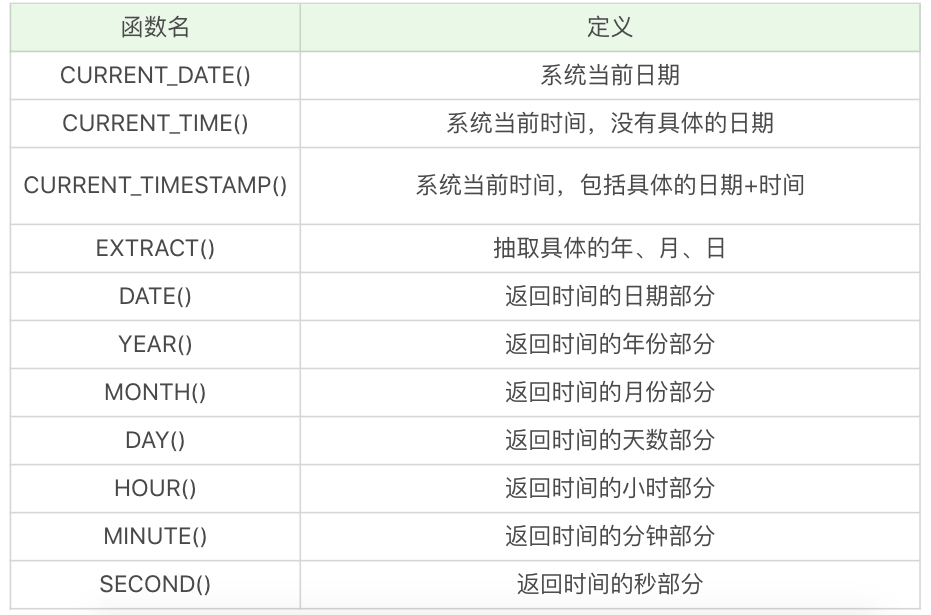
下面是一些簡單的例子:
SELECT CURRENT_DATE(),運行結果為 2019-04-03。
SELECT CURRENT_TIME(),運行結果為 21:26:34。
SELECT CURRENT_TIMESTAMP(),運行結果為 2019-04-03 21:26:34。
SELECT EXTRACT(YEAR FROM '2019-04-03'),運行結果為 2019。
SELECT DATE('2019-04-01 12:00:05'),運行結果為 2019-04-01。
這裡需要注意的是,DATE 日期格式必須是 yyyy-mm-dd 的形式。如果要進行日期比較,就要使用 DATE 函數,不要直接使用日期與字元串進行比較,我會在後面的例子中講具體的原因。
轉換函數
轉換函數可以轉換數據之間的類型,常用的函數如下表所示:

實踐
假設我們想顯示英雄最大生命值的最大值,就需要用到 MAX 函數。在數據中,「最大生命值」對應的列數為hp_max,在程式碼中的格式為MAX(hp_max)。
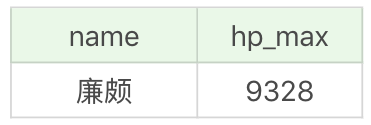
SQL:SELECT MAX(hp_max) FROM heros
運行結果為 9328。
假如我們想要知道最大生命值最大的是哪個英雄,以及對應的數值,就需要分成兩個步驟來處理:首先找到英雄的最大生命值的最大值,即SELECT MAX(hp_max) FROM heros,然後再篩選最大生命值等於這個最大值的英雄,如下所示。
SQL:SELECT name, hp_max FROM heros WHERE hp_max = (SELECT MAX(hp_max) FROM heros)
運行結果:
假如我們想顯示英雄的名字,以及他們的名字字數,需要用到CHAR_LENGTH函數。
SQL:SELECT CHAR_LENGTH(name), name FROM heros
運行結果為:
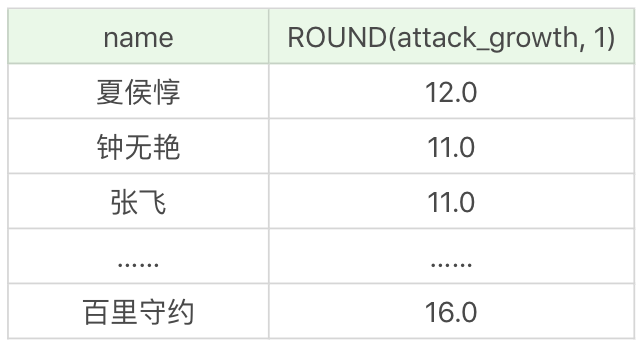
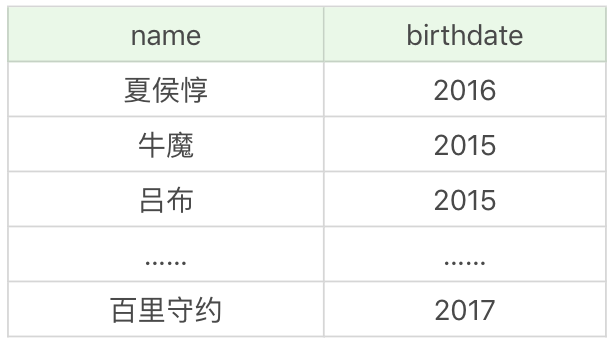
假如想要提取英雄上線日期(對應欄位 birthdate)的年份,只顯示有上線日期的英雄即可(有些英雄沒有上線日期的數據,不需要顯示),這裡我們需要使用 EXTRACT 函數,提取某一個時間元素。所以我們需要篩選上線日期不為空的英雄,即WHERE birthdate is not null,然後再顯示他們的名字和上線日期的年份,即:
SQL: SELECT name, EXTRACT(YEAR FROM birthdate) AS birthdate FROM heros WHERE birthdate is NOT NULL
或者使用如下形式:
SQL: SELECT name, YEAR(birthdate) AS birthdate FROM heros WHERE birthdate is NOT NULL
運行結果為:
假設我們需要找出在 2016 年 10 月 1 日之後上線的所有英雄。這裡我們可以採用 DATE 函數來判斷 birthdate 的日期是否大於 2016-10-01,即WHERE DATE(birthdate)>'2016-10-01',然後再顯示符合要求的全部欄位資訊,即:
SQL: SELECT * FROM heros WHERE DATE(birthdate)>'2016-10-01'
需要注意的是下面這種寫法是不安全的:
SELECT * FROM heros WHERE birthdate>'2016-10-01'
因為很多時候你無法確認 birthdate 的數據類型是字元串,還是 datetime 類型,如果你想對日期部分進行比較,那麼使用DATE(birthdate)來進行比較是更安全的。
運行結果為:

假設我們需要知道在 2016 年 10 月 1 日之後上線英雄的平均最大生命值、平均最大法力和最高物攻最大值。同樣我們需要先篩選日期條件,即WHERE DATE(birthdate)>'2016-10-01',然後再選擇AVG(hp_max), AVG(mp_max), MAX(attack_max)欄位進行顯示。
SQL: SELECT AVG(hp_max), AVG(mp_max), MAX(attack_max) FROM heros WHERE DATE(birthdate)>'2016-10-01'
運行結果為:

為什麼使用 SQL 函數會帶來問題
儘管 SQL 函數使用起來會很方便,但我們使用的時候還是要謹慎,因為你使用的函數很可能在運行環境中無法工作,這是為什麼呢?
如果你學習過程式語言,就會知道語言是有不同版本的,比如 Python 會有 2.7 版本和 3.x 版本,不過它們之間的函數差異不大,也就在 10% 左右。但我們在使用 SQL 語言的時候,不是直接和這門語言打交道,而是通過它使用不同的資料庫軟體,即 DBMS。DBMS 之間的差異性很大,遠大於同一個語言不同版本之間的差異。實際上,只有很少的函數是被 DBMS 同時支援的。比如,大多數 DBMS 使用(||)或者(+)來做拼接符,而在 MySQL 中的字元串拼接函數為Concat()。大部分 DBMS 會有自己特定的函數,這就意味著採用 SQL 函數的程式碼可移植性是很差的,因此在使用函數的時候需要特別注意。
關於大小寫的規範
實際上在 SQL 中,關鍵字和函數名是不用區分字母大小寫的,比如 SELECT、WHERE、ORDER、GROUP BY 等關鍵字,以及 ABS、MOD、ROUND、MAX 等函數名。
不過在 SQL 中,你是要確定大小寫的規範,因為在 Linux 和 Windows 環境下,你可能會遇到不同的大小寫問題。
比如 MySQL 在 Linux 的環境下,資料庫名、表名、變數名是嚴格區分大小寫的,而欄位名是忽略大小寫的。
而 MySQL 在 Windows 的環境下全部不區分大小寫。
這就意味著如果你的變數名命名規範沒有統一,就可能產生錯誤。這裡有一個有關命名規範的建議:
- 關鍵字和函數名稱全部大寫;
- 資料庫名、表名、欄位名稱全部小寫;
- SQL 語句必須以分號結尾。
雖然關鍵字和函數名稱在 SQL 中不區分大小寫,也就是如果小寫的話同樣可以執行,但是資料庫名、表名和欄位名在 Linux MySQL 環境下是區分大小寫的,因此建議你統一這些欄位的命名規則,比如全部採用小寫的方式。同時將關鍵詞和函數名稱全部大寫,以便於區分資料庫名、表名、欄位名。
總結
函數對於一門語言的重要性毋庸置疑,我們在寫 Python 程式碼的時候,會自己編寫函數,也會使用 Python 內置的函數。在 SQL 中,使用函數的時候需要格外留意。不過如果工程量不大,使用的是同一個 DBMS 的話,還是可以使用函數簡化操作的,這樣也能提高程式碼效率。只是在系統集成,或者在多個 DBMS 同時存在的情況下,使用函數的時候就需要慎重一些。
比如CONCAT()是字元串拼接函數,在 MySQL 和 Oracle 中都有這個函數,但是在這兩個 DBMS 中作用卻不一樣,CONCAT函數在 MySQL 中可以連接多個字元串,而在 Oracle 中CONCAT函數只能連接兩個字元串,如果要連接多個字元串就需要用(||)連字元來解決。
SQL的聚集函數
聚集函數是對一組數據進行匯總的函數,輸入的是一組數據的集合,輸出的是單個值。通常我們可以利用聚集函數匯總表的數據,如果稍微複雜一些,我們還需要先對數據做篩選,然後再進行聚集,比如先按照某個條件進行分組,對分組條件進行篩選,然後得到篩選後的分組的匯總資訊。
聚集函數都有哪些
SQL 中的聚集函數一共包括 5 個,可以幫我們求某列的最大值、最小值和平均值等,它們分別是:
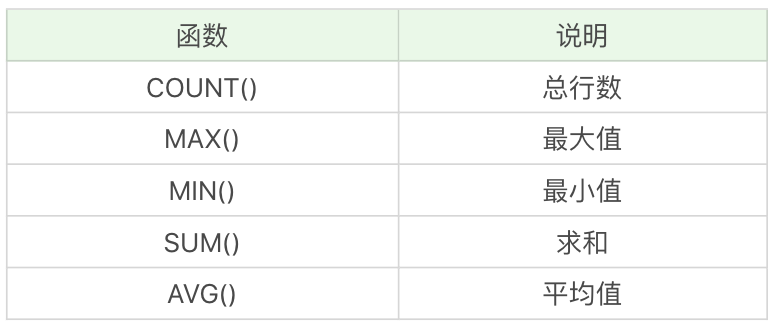
這些函數你可能已經接觸過,我們再來簡單複習一遍。我們繼續使用 heros 數據表,對王者榮耀的英雄數據進行聚合。
如果我們想要查詢最大生命值大於 6000 的英雄數量。
SQL:SELECT COUNT(*) FROM heros WHERE hp_max > 6000
運行結果為 41。
如果想要查詢最大生命值大於 6000,且有次要定位的英雄數量,需要使用 COUNT 函數。
SQL:SELECT COUNT(role_assist) FROM heros WHERE hp_max > 6000
運行結果是 23。
需要說明的是,有些英雄沒有次要定位,即 role_assist 為 NULL,這時COUNT(role_assist)會忽略值為 NULL 的數據行,而 COUNT(*) 只是統計數據行數,不管某個欄位是否為 NULL。
如果我們想要查詢射手(主要定位或者次要定位是射手)的最大生命值的最大值是多少,需要使用 MAX 函數。
SQL:SELECT MAX(hp_max) FROM heros WHERE role_main = '射手' or role_assist = '射手'
運行結果為 6014。
你能看到,上面的例子里,都是在一條 SELECT 語句中使用了一次聚集函數,實際上我們也可以在一條 SELECT 語句中進行多項聚集函數的查詢,比如我們想知道射手(主要定位或者次要定位是射手)的英雄數、平均最大生命值、法力最大值的最大值、攻擊最大值的最小值,以及這些英雄總的防禦最大值等匯總數據。
如果想要知道英雄的數量,我們使用的是 COUNT(*) 函數,求平均值、最大值、最小值,以及總的防禦最大值,我們分別使用的是 AVG、MAX、MIN 和 SUM 函數。另外我們還需要對英雄的主要定位和次要定位進行篩選,使用的是WHERE role_main = '射手' or role_assist = '射手'。
SQL: SELECT COUNT(*), AVG(hp_max), MAX(mp_max), MIN(attack_max), SUM(defense_max) FROM heros WHERE role_main = '射手' or role_assist = '射手'
運行結果:

需要說明的是 AVG、MAX、MIN 等聚集函數會自動忽略值為 NULL 的數據行,MAX 和 MIN 函數也可以用於字元串類型數據的統計,如果是英文字母,則按照 A—Z 的順序排列,越往後,數值越大。如果是漢字則按照全拼拼音進行排列。比如:
SQL:SELECT MIN(CONVERT(name USING gbk)), MAX(CONVERT(name USING gbk)) FROM heros
運行結果:

需要說明的是,我們需要先把 name 欄位統一轉化為 gbk 類型,使用CONVERT(name USING gbk),然後再使用 MIN 和 MAX 取最小值和最大值。
我們也可以對數據行中不同的取值進行聚集,先用 DISTINCT 函數取不同的數據,然後再使用聚集函數。比如我們想要查詢不同的生命最大值的英雄數量是多少。
SQL: SELECT COUNT(DISTINCT hp_max) FROM heros
運行結果為 61。
實際上在 heros 這個數據表中,一共有 69 個英雄數量,生命最大值不一樣的英雄數量是 61 個。
假如我們想要統計不同生命最大值英雄的平均生命最大值,保留小數點後兩位。首先需要取不同生命最大值,即DISTINCT hp_max,然後針對它們取平均值,即AVG(DISTINCT hp_max),最後再針對這個值保留小數點兩位,也就是ROUND(AVG(DISTINCT hp_max), 2)。
SQL: SELECT ROUND(AVG(DISTINCT hp_max), 2) FROM heros
運行結果為 6653.84。
你能看到,如果我們不使用 DISTINCT 函數,就是對全部數據進行聚集統計。如果使用了 DISTINCT 函數,就可以對數值不同的數據進行聚集。一般我們使用 MAX 和 MIN 函數統計數據行的時候,不需要再額外使用 DISTINCT,因為使用 DISTINCT 和全部數據行進行最大值、最小值的統計結果是相等的。
如何對數據進行分組,並進行聚集統計
我們在做統計的時候,可能需要先對數據按照不同的數值進行分組,然後對這些分好的組進行聚集統計。對數據進行分組,需要使用 GROUP BY 子句。
比如我們想按照英雄的主要定位進行分組,並統計每組的英雄數量。
SQL: SELECT COUNT(*), role_main FROM heros GROUP BY role_main
運行結果(6 條記錄):
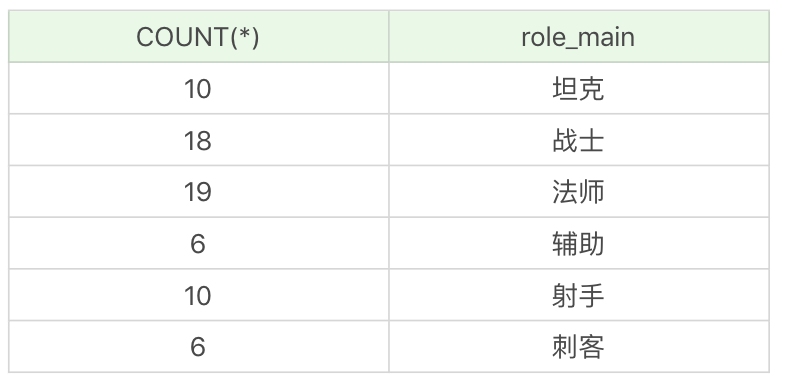
如果我們想要對英雄按照次要定位進行分組,並統計每組英雄的數量。
SELECT COUNT(*), role_assist FROM heros GROUP BY role_assist
運行結果:(6 條記錄)
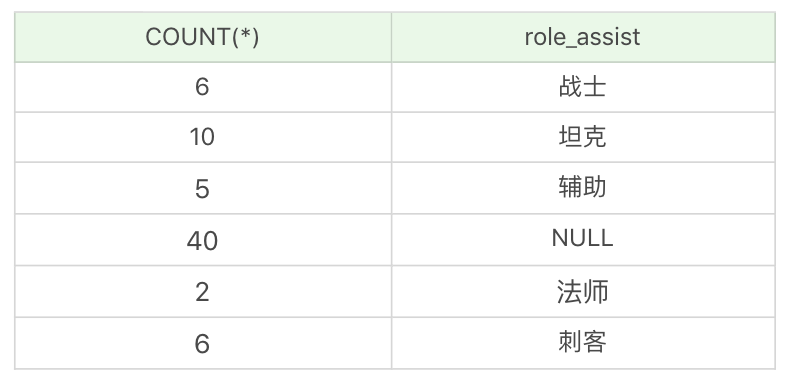
你能看出如果欄位為 NULL,也會被列為一個分組。在這個查詢統計中,次要定位為 NULL,即只有一個主要定位的英雄是 40 個。
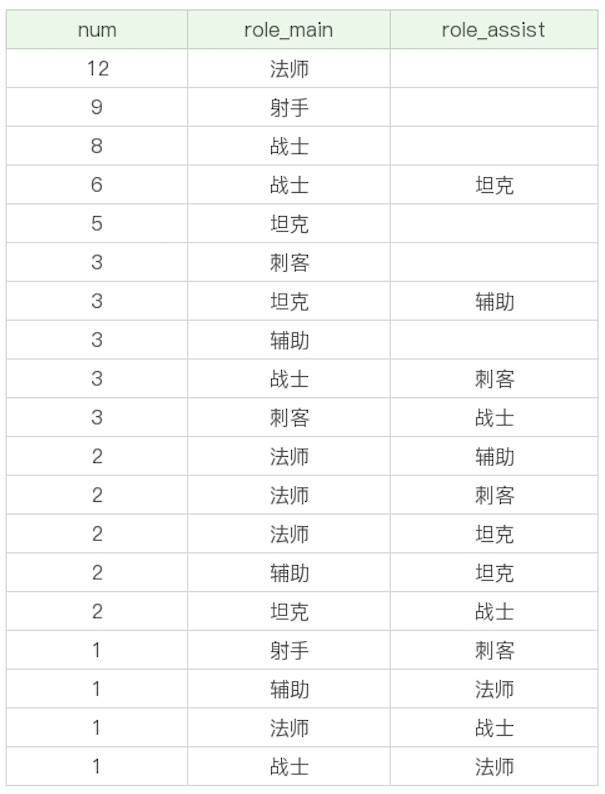
我們也可以使用多個欄位進行分組,這就相當於把這些欄位可能出現的所有的取值情況都進行分組。比如,我們想要按照英雄的主要定位、次要定位進行分組,查看這些英雄的數量,並按照這些分組的英雄數量從高到低進行排序。
SELECT COUNT(*) as num, role_main, role_assist FROM heros GROUP BY role_main, role_assist ORDER BY num DESC
運行結果:(19 條記錄)
如何使用 HAVING 過濾分組,它與 WHERE 的區別是什麼?
當我們創建出很多分組的時候,有時候就需要對分組進行過濾。你可能首先會想到 WHERE 子句,實際上過濾分組我們使用的是 HAVING。HAVING 的作用和 WHERE 一樣,都是起到過濾的作用,只不過 WHERE 是用於數據行,而 HAVING 則作用於分組。
比如我們想要按照英雄的主要定位、次要定位進行分組,並且篩選分組中英雄數量大於 5 的組,最後按照分組中的英雄數量從高到低進行排序。
首先我們需要獲取的是英雄的數量、主要定位和次要定位,即SELECT COUNT(*) as num, role_main, role_assist。然後按照英雄的主要定位和次要定位進行分組,即GROUP BY role_main, role_assist,同時我們要對分組中的英雄數量進行篩選,選擇大於 5 的分組,即HAVING num > 5,然後按照英雄數量從高到低進行排序,即ORDER BY num DESC。
SQL: SELECT COUNT(*) as num, role_main, role_assist FROM heros GROUP BY role_main, role_assist HAVING num > 5 ORDER BY num DESC
運行結果:(4 條記錄)

你能看到還是上面這個分組,只不過我們按照數量進行了過濾,篩選了數量大於 5 的分組進行輸出。如果把 HAVING 替換成了 WHERE,SQL 則會報錯。對於分組的篩選,我們一定要用 HAVING,而不是 WHERE。另外你需要知道的是,HAVING 支援所有 WHERE 的操作,因此所有需要 WHERE 子句實現的功能,你都可以使用 HAVING 對分組進行篩選。
我們再來看個例子,通過這個例子查看一下 WHERE 和 HAVING 進行條件過濾的區別。篩選最大生命值大於 6000 的英雄,按照主要定位、次要定位進行分組,並且顯示分組中英雄數量大於 5 的分組,按照數量從高到低進行排序。
SQL: SELECT COUNT(*) as num, role_main, role_assist FROM heros WHERE hp_max > 6000 GROUP BY role_main, role_assist HAVING num > 5 ORDER BY num DESC
運行結果:(2 條記錄)

你能看到,還是針對上一個例子的查詢,只是我們先增加了一個過濾條件,即篩選最大生命值大於 6000 的英雄。這裡我們就需要先使用 WHERE 子句對最大生命值大於 6000 的英雄進行條件過濾,然後再使用 GROUP BY 進行分組,使用 HAVING 進行分組的條件判斷,然後使用 ORDER BY 進行排序。
總結
今天我對 SQL 的聚集函數進行了講解。通常我們還會對數據先進行分組,然後再使用聚集函數統計不同組的數據概況,比如數據行數、平均值、最大值、最小值以及求和等。我們也可以使用 HAVING 對分組進行過濾,然後通過 ORDER BY 按照某個欄位的順序進行排序輸出。有時候你能看到在一條 SELECT 語句中,可能會包括多個子句,用 WHERE 進行數據量的過濾,用 GROUP BY 進行分組,用 HAVING 進行分組過濾,用 ORDER BY 進行排序……
要記住,在 SELECT 查詢中,關鍵字的順序是不能顛倒的,它們的順序是:
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ...
另外需要注意的是,使用 GROUP BY 進行分組,如果想讓輸出的結果有序,可以在 GROUP BY 後使用 ORDER BY。因為 GROUP BY 只起到了分組的作用,排序還是需要通過 ORDER BY 來完成。
子查詢
SQL 還能進行子查詢,也就是嵌套在查詢中的查詢。這樣做的好處是可以讓我們進行更複雜的查詢,同時更加容易理解查詢的過程。因為很多時候,我們無法直接從數據表中得到查詢結果,需要從查詢結果集中再次進行查詢,才能得到想要的結果。這個「查詢結果集」就是我們要講的子查詢。
什麼是關聯子查詢,什麼是非關聯子查詢
子查詢雖然是一種嵌套查詢的形式,不過我們依然可以依據子查詢是否執行多次,從而將子查詢劃分為關聯子查詢和非關聯子查詢。子查詢從數據表中查詢了數據結果,如果這個數據結果只執行一次,然後這個數據結果作為主查詢的條件進行執行,那麼這樣的子查詢叫做非關聯子查詢。
同樣,如果子查詢需要執行多次,即採用循環的方式,先從外部查詢開始,每次都傳入子查詢進行查詢,然後再將結果回饋給外部,這種嵌套的執行方式就稱為關聯子查詢。
單說概念有點抽象,我們用數據表舉例說明一下。這裡創建了 NBA 球員資料庫,文件在之前網盤中。
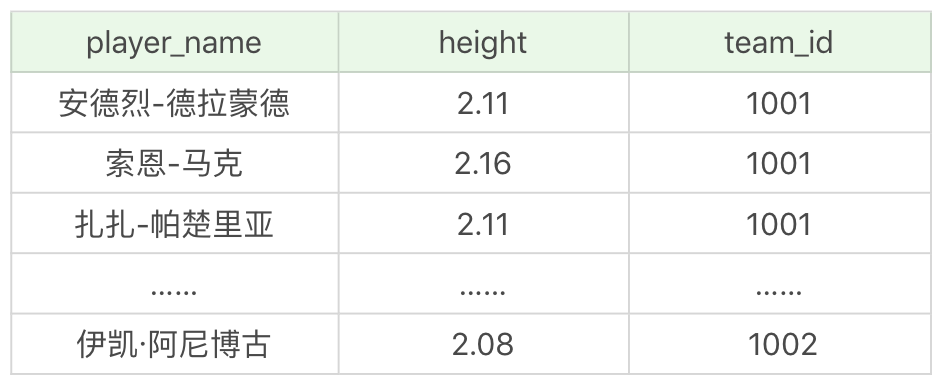
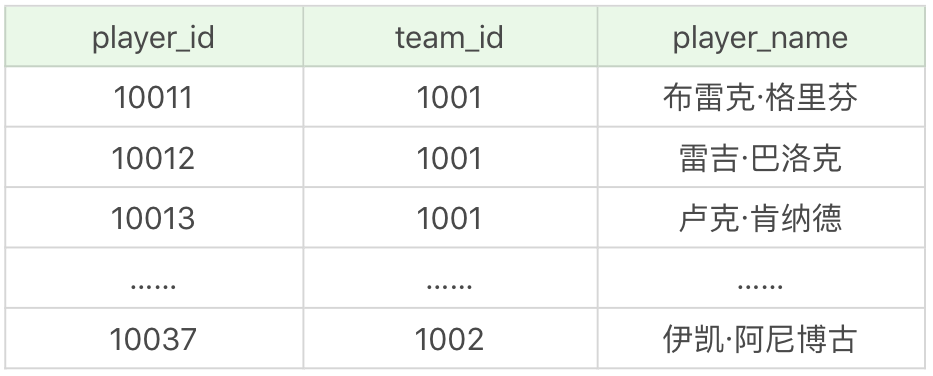
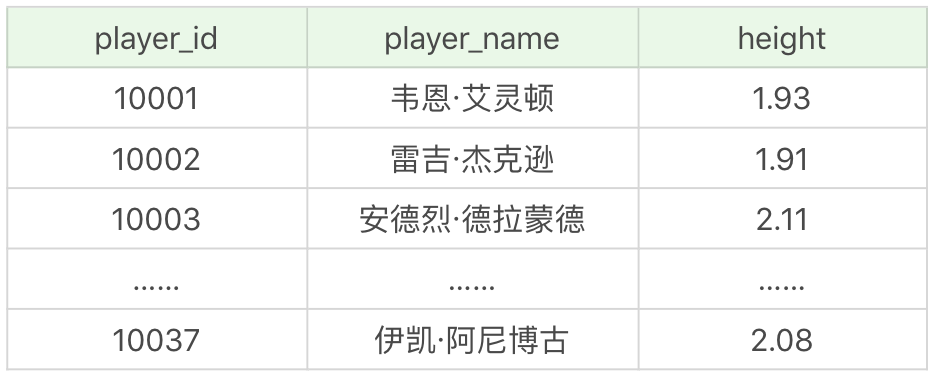
文件中一共包括了 5 張表,player 表為球員表,team 為球隊表,team_score 為球隊比賽表,player_score 為球員比賽成績表,height_grades 為球員身高對應的等級表。
其中 player 表,也就是球員表,一共有 37 個球員,如下所示:
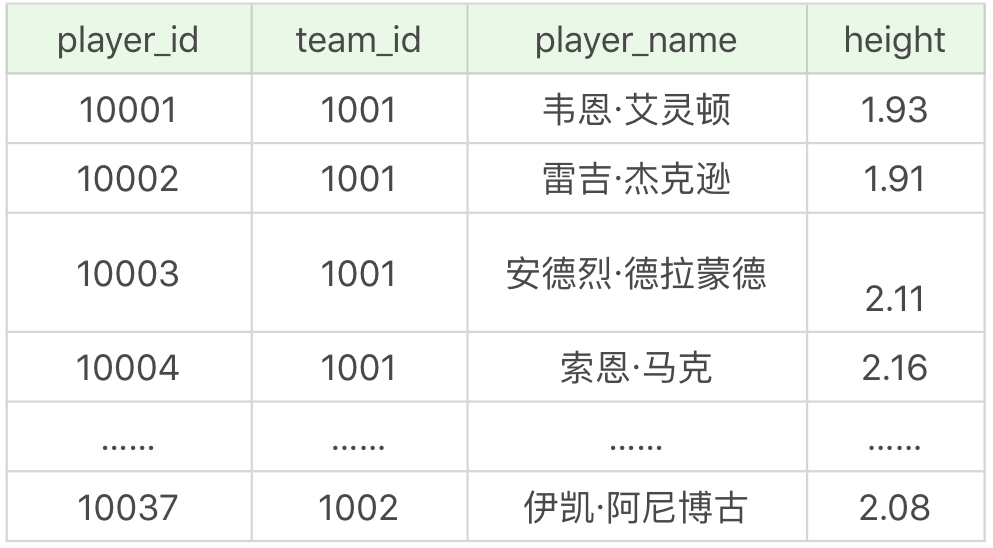
team 表為球隊表,一共有 3 支球隊,如下所示:
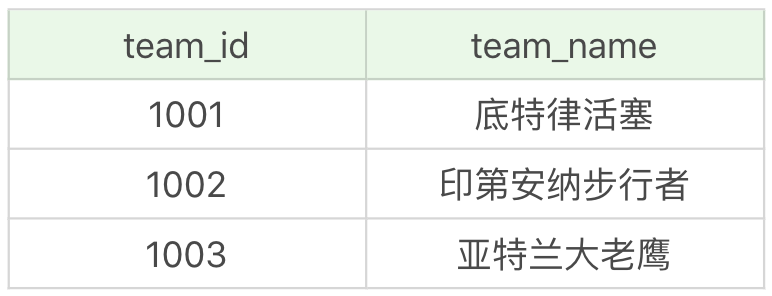
team_score 表為球隊比賽成績表,一共記錄了兩場比賽的成績,如下所示:

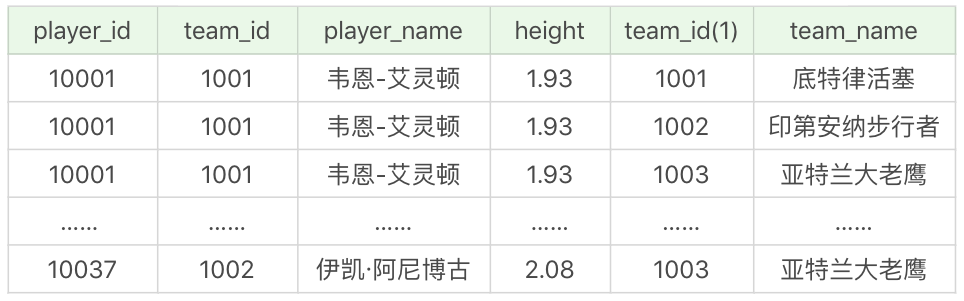
player_score 表為球員比賽成績表,記錄了一場比賽中球員的表現。這張表一共包括 19 個欄位,代表的含義如下:


其中 shoot_attempts 代表總出手的次數,它等於二分球出手和三分球出手次數的總和。比如 2019 年 4 月 1 日,韋恩·艾靈頓在底特律活塞和印第安納步行者的比賽中,總出手次數為 19,總命中 10,三分球 13 投 4 中,罰球 4 罰 2 中,因此總分 score=(10-4)×2+4×3+2=26,也就是二分球得分 12+ 三分球得分 12+ 罰球得分 2=26。
需要說明的是,通常在工作中,數據表的欄位比較多,一開始創建的時候會知道每個欄位的定義,過了一段時間再回過頭來看,對當初的定義就不那麼確定了,容易混淆欄位,解決這一問題最好的方式就是做個說明文檔,用實例舉例。
比如 shoot_attempts 是總出手次數(這裡的總出手次數 = 二分球出手次數 + 三分球出手次數,不包括罰球的次數),用上面提到的韋恩·艾靈頓的例子做補充說明,再回過頭來看這張表的時候,就可以很容易理解每個欄位的定義了。
我們以 NBA 球員數據表為例,假設我們想要知道哪個球員的身高最高,最高身高是多少,就可以採用子查詢的方式:
SQL: SELECT player_name, height FROM player WHERE height = (SELECT max(height) FROM player)
運行結果:(1 條記錄)

你能看到,通過SELECT max(height) FROM player可以得到最高身高這個數值,結果為 2.16,然後我們再通過 player 這個表,看誰具有這個身高,再進行輸出,這樣的子查詢就是非關聯子查詢。
如果子查詢的執行依賴於外部查詢,通常情況下都是因為子查詢中的表用到了外部的表,並進行了條件關聯,因此每執行一次外部查詢,子查詢都要重新計算一次,這樣的子查詢就稱之為關聯子查詢。比如我們想要查找每個球隊中大於平均身高的球員有哪些,並顯示他們的球員姓名、身高以及所在球隊 ID。
首先我們需要統計球隊的平均身高,即SELECT avg(height) FROM player AS b WHERE a.team_id = b.team_id,然後篩選身高大於這個數值的球員姓名、身高和球隊 ID,即:
SELECT player_name, height, team_id FROM player AS a WHERE height > (SELECT avg(height) FROM player AS b WHERE a.team_id = b.team_id)
運行結果:(18 條記錄)
EXISTS 子查詢
關聯子查詢通常也會和 EXISTS 一起來使用,EXISTS 子查詢用來判斷條件是否滿足,滿足的話為 True,不滿足為 False。
比如我們想要看出場過的球員都有哪些,並且顯示他們的姓名、球員 ID 和球隊 ID。在這個統計中,是否出場是通過 player_score 這張表中的球員出場表現來統計的,如果某個球員在 player_score 中有出場記錄則代表他出場過,這裡就使用到了 EXISTS 子查詢,即EXISTS (SELECT player_id FROM player_score WHERE player.player_id = player_score.player_id),然後將它作為篩選的條件,實際上也是關聯子查詢,即:
SQL:SELECT player_id, team_id, player_name FROM player WHERE EXISTS (SELECT player_id FROM player_score WHERE player.player_id = player_score.player_id)
運行結果:(19 條記錄)

同樣,NOT EXISTS 就是不存在的意思,我們也可以通過 NOT EXISTS 查詢不存在於 player_score 表中的球員資訊,比如主表中的 player_id 不在子表 player_score 中,判斷語句為NOT EXISTS (SELECT player_id FROM player_score WHERE player.player_id = player_score.player_id)。整體的 SQL 語句為:
SQL: SELECT player_id, team_id, player_name FROM player WHERE NOT EXISTS (SELECT player_id FROM player_score WHERE player.player_id = player_score.player_id)
運行結果:(18 條記錄)
 集合比較子查詢
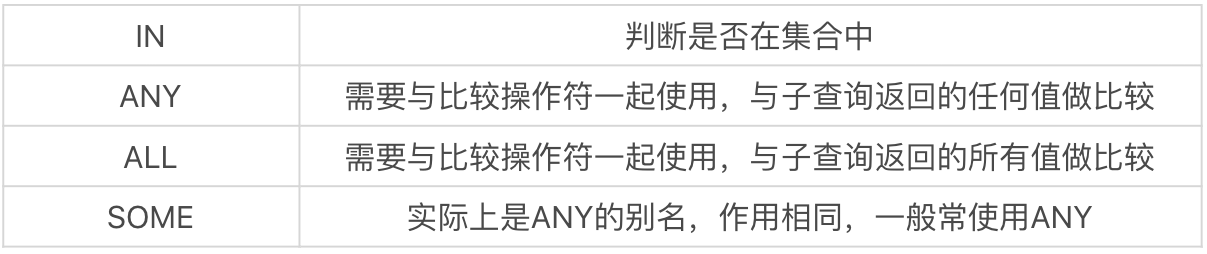
集合比較子查詢
 集合比較子查詢
集合比較子查詢集合比較子查詢的作用是與另一個查詢結果集進行比較,我們可以在子查詢中使用 IN、ANY、ALL 和 SOME 操作符,它們的含義和英文意義一樣:
 還是通過上面那個例子,假設我們想要看出場過的球員都有哪些,可以採用 IN 子查詢來進行操作:
還是通過上面那個例子,假設我們想要看出場過的球員都有哪些,可以採用 IN 子查詢來進行操作:
SELECT player_id, team_id, player_name FROM player WHERE player_id in (SELECT player_id FROM player_score WHERE player.player_id = player_score.player_id)
你會發現運行結果和上面的是一樣的,那麼問題來了,既然 IN 和 EXISTS 都可以得到相同的結果,那麼我們該使用 IN 還是 EXISTS 呢?
我們可以把這個模式抽象為:
SELECT * FROM A WHERE cc IN (SELECT cc FROM B)
SELECT * FROM A WHERE EXIST (SELECT cc FROM B WHERE B.cc=A.cc)
實際上在查詢過程中,在我們對 cc 列建立索引的情況下,我們還需要判斷表 A 和表 B 的大小。
在這裡例子當中,表 A 指的是 player 表,表 B 指的是 player_score 表。如果表 A 比表 B 大,那麼 IN 子查詢的效率要比 EXIST 子查詢效率高,因為這時 B 表中如果對 cc 列進行了索引,那麼 IN 子查詢的效率就會比較高。
同樣,如果表 A 比表 B 小,那麼使用 EXISTS 子查詢效率會更高,因為我們可以使用到 A 表中對 cc 列的索引,而不用從 B 中進行 cc 列的查詢。
了解了 IN 查詢後,我們來看下 ANY 和 ALL 子查詢。剛才講到了 ANY 和 ALL 都需要使用比較符,比較符包括了(>)(=)(<)(>=)(<=)和(<>)等。
如果我們想要查詢球員表中,比印第安納步行者(對應的 team_id 為 1002)中任何一個球員身高高的球員的資訊,並且輸出他們的球員 ID、球員姓名和球員身高,該怎麼寫呢?
首先我們需要找出所有印第安納步行者隊中的球員身高,即SELECT height FROM player WHERE team_id = 1002,然後使用 ANY 子查詢即:
SQL: SELECT player_id, player_name, height FROM player WHERE height > ANY (SELECT height FROM player WHERE team_id = 1002)
運行結果:(35 條記錄)
運行結果為 35 條,你發現有 2 個人的身高是不如印第安納步行者的所有球員的。
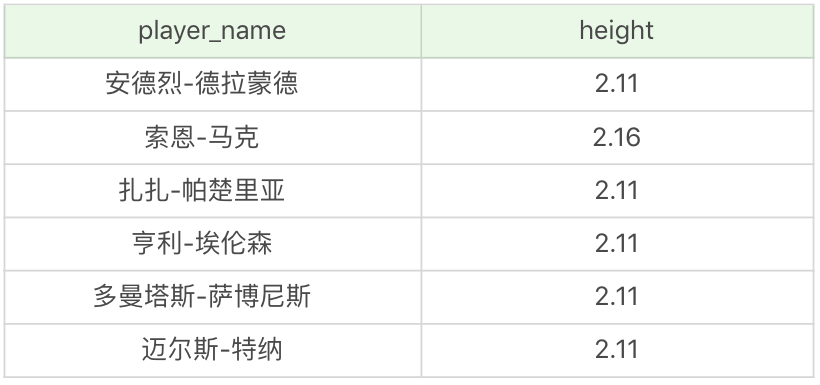
同樣,如果我們想要知道比印第安納步行者(對應的 team_id 為 1002)中所有球員身高都高的球員的資訊,並且輸出球員 ID、球員姓名和球員身高,該怎麼寫呢?
SQL: SELECT player_id, player_name, height FROM player WHERE height > ALL (SELECT height FROM player WHERE team_id = 1002)
運行結果:(1 條記錄)

我們能看到比印第安納步行者所有球員都高的球員,在 player 這張表(一共 37 個球員)中只有索恩·馬克。
需要強調的是 ANY、ALL 關鍵字必須與一個比較操作符一起使用。因為如果你不使用比較操作符,就起不到集合比較的作用,那麼使用 ANY 和 ALL 就沒有任何意義。
將子查詢作為計算欄位
我剛才講了子查詢的幾種用法,實際上子查詢也可以作為主查詢的計算欄位。比如我想查詢每個球隊的球員數,也就是對應 team 這張表,我需要查詢相同的 team_id 在 player 這張表中所有的球員數量是多少。
SQL: SELECT team_name, (SELECT count(*) FROM player WHERE player.team_id = team.team_id) AS player_num FROM team
運行結果:(3 條記錄)

你能看到,在 player 表中只有底特律活塞和印第安納步行者的球員數據,所以它們的 player_num 不為 0,而亞特蘭大老鷹的 player_num 等於 0。在查詢的時候,我將子查詢SELECT count(*) FROM player WHERE player.team_id = team.team_id作為了計算欄位,通常我們需要給這個計算欄位起一個別名,這裡我用的是 player_num,因為子查詢的語句比較長,使用別名更容易理解。
總結
講解了子查詢的使用,按照子查詢執行的次數,我們可以將子查詢分成關聯子查詢和非關聯子查詢,其中非關聯子查詢與主查詢的執行無關,只需要執行一次即可,而關聯子查詢,則需要將主查詢的欄位值傳入子查詢中進行關聯查詢。
同時,在子查詢中你可能會使用到 EXISTS、IN、ANY、ALL 和 SOME 等關鍵字。在某些情況下使用 EXISTS 和 IN 可以得到相同的效果,具體使用哪個執行效率更高,則需要看欄位的索引情況以及表 A 和表 B 哪個表更大。同樣,IN、ANY、ALL、SOME 這些關鍵字是用於集合比較的,SOME 是 ANY 的別名,當我們使用 ANY 或 ALL 的時候,一定要使用比較操作符。
最後,講解了如何使用子查詢作為計算欄位,把子查詢的結果作為主查詢的列。
SQL 中,子查詢的使用大大增強了 SELECT 查詢的能力,因為很多時候查詢需要從結果集中獲取數據,或者需要從同一個表中先計算得出一個數據結果,然後與這個數據結果(可能是某個標量,也可能是某個集合)進行比較。
常用的SQL標準
下面主要講解連接表的操作。在講解之前,先介紹下連接(JOIN)在 SQL 中的重要性。
我們知道 SQL 的英文全稱叫做 Structured Query Language,它有一個很強大的功能,就是能在各個數據表之間進行連接查詢(Query)。這是因為 SQL 是建立在關係型資料庫基礎上的一種語言。關係型資料庫的典型數據結構就是數據表,這些數據表的組成都是結構化的(Structured)。你可以把關係模型理解成一個二維表格模型,這個二維表格是由行(row)和列(column)組成的。每一個行(row)就是一條數據,每一列(column)就是數據在某一維度的屬性。
正是因為在資料庫中,表的組成是基於關係模型的,所以一個表就是一個關係。一個資料庫中可以包括多個表,也就是存在多種數據之間的關係。而我們之所以能使用 SQL 語言對各個數據表進行複雜查詢,核心就在於連接,它可以用一條 SELECT 語句在多張表之間進行查詢。你也可以理解為,關係型資料庫的核心之一就是連接。
常用的 SQL 標準有哪些
在正式開始講連接表的種類時,我們首先需要知道 SQL 存在不同版本的標準規範,因為不同規範下的表連接操作是有區別的。
SQL 有兩個主要的標準,
分別是 SQL92 和 SQL99。92 和 99 代表了標準提出的時間,SQL92 就是 92 年提出的標準規範。
當然除了 SQL92 和 SQL99 以外,還存在 SQL-86、SQL-89、SQL:2003、SQL:2008、SQL:2011 和 SQL:2016 等其他的標準。
這麼多標準,到底該學習哪個呢?
實際上最重要的 SQL 標準就是 SQL92 和 SQL99。一般來說 SQL92 的形式更簡單,但是寫的 SQL 語句會比較長,可讀性較差。而 SQL99 相比於 SQL92 來說,語法更加複雜,但可讀性更強。我們從這兩個標準發布的頁數也能看出,SQL92 的標準有 500 頁,而 SQL99 標準超過了 1000 頁。實際上你不用擔心要學習這麼多內容,基本上從 SQL99 之後,很少有人能掌握所有內容,因為確實太多了。就好比我們使用 Windows、Linux 和 Office 的時候,很少有人能掌握全部內容一樣。我們只需要掌握一些核心的功能,滿足日常工作的需求即可。
在 SQL92 中是如何使用連接的
相比於 SQL99,SQL92 規則更簡單,更適合入門。在這篇文章中,我會先講 SQL92 是如何對連接表進行操作的,下一篇文章再講 SQL99,到時候你可以對比下這兩者之間有什麼區別。
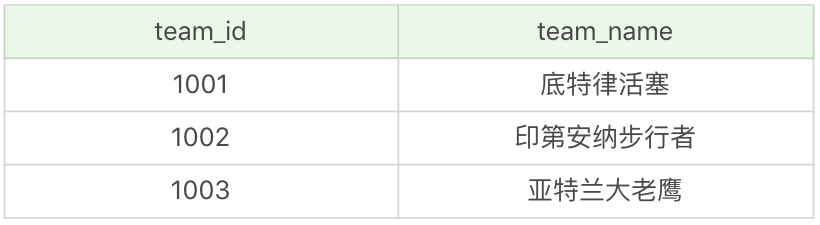
在進行連接之前,我們需要用數據表做舉例。這裡有NBA 球員和球隊兩張表。
其中 player 表為球員表,一共有 37 個球員,如下所示:

team 表為球隊表,一共有 3 支球隊,如下所示:
有了這兩個數據表之後,我們再來看下 SQL92 中的 5 種連接方式,它們分別是笛卡爾積、等值連接、非等值連接、外連接(左連接、右連接)和自連接。
笛卡爾積
笛卡爾乘積是一個數學運算。假設我有兩個集合 X 和 Y,那麼 X 和 Y 的笛卡爾積就是 X 和 Y 的所有可能組合,也就是第一個對象來自於 X,第二個對象來自於 Y 的所有可能。
我們假定 player 表的數據是集合 X,先進行 SQL 查詢:
SELECT * FROM player
再假定 team 表的數據為集合 Y,同樣需要進行 SQL 查詢:
SELECT * FROM team
你會看到運行結果會顯示出上面的兩張表格。
接著我們再來看下兩張表的笛卡爾積的結果,這是笛卡爾積的調用方式:
SQL: SELECT * FROM player, team
運行結果(一共 37*3=111 條記錄):

笛卡爾積也稱為交叉連接,英文是 CROSS JOIN,它的作用就是可以把任意表進行連接,即使這兩張表不相關。但我們通常進行連接還是需要篩選的,因此你需要在連接後面加上 WHERE 子句,也就是作為過濾條件對連接數據進行篩選。比如後面要講到的等值連接。
等值連接
兩張表的等值連接就是用兩張表中都存在的列進行連接。我們也可以對多張表進行等值連接。
針對 player 表和 team 表都存在 team_id 這一列,我們可以用等值連接進行查詢。
SQL: SELECT player_id, player.team_id, player_name, height, team_name FROM player, team WHERE player.team_id = team.team_id
運行結果(一共 37 條記錄):

我們在進行等值連接的時候,可以使用表的別名,這樣會讓 SQL 語句更簡潔:
SELECT player_id, a.team_id, player_name, height, team_name FROM player AS a, team AS b WHERE a.team_id = b.team_id
需要注意的是,如果我們使用了表的別名,在查詢欄位中就只能使用別名進行代替,不能使用原有的表名,比如下面的 SQL 查詢就會報錯:
SELECT player_id, player.team_id, player_name, height, team_name FROM player AS a, team AS b WHERE a.team_id = b.team_id
非等值連接
當我們進行多表查詢的時候,如果連接多個表的條件是等號時,就是等值連接,其他的運算符連接就是非等值查詢。
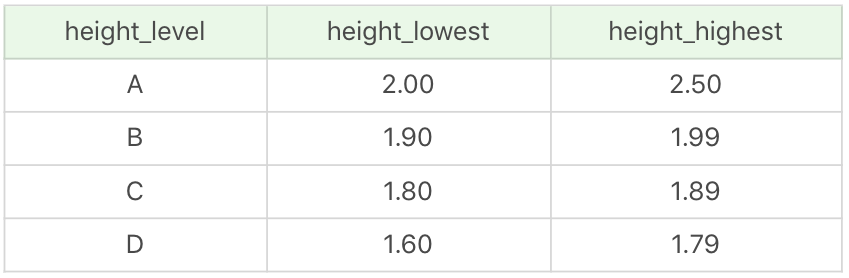
這裡我創建一個身高級別表 height_grades,如下所示:
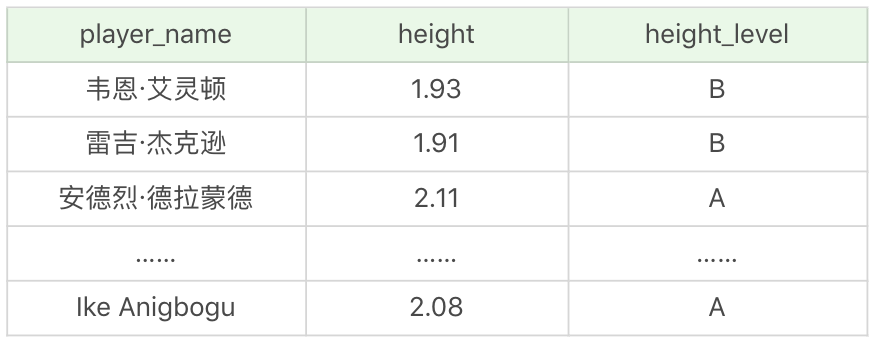
我們知道 player 表中有身高 height 欄位,如果想要知道每個球員的身高的級別,可以採用非等值連接查詢。
SQL:SELECT p.player_name, p.height, h.height_level
FROM player AS p, height_grades AS h
WHERE p.height BETWEEN h.height_lowest AND h.height_highest
運行結果(37 條記錄):
外連接
除了查詢滿足條件的記錄以外,外連接還可以查詢某一方不滿足條件的記錄。
兩張表的外連接,會有一張是主表,另一張是從表。如果是多張表的外連接,那麼第一張表是主表,即顯示全部的行,而第剩下的表則顯示對應連接的資訊。
在 SQL92 中採用(+)代表從表所在的位置,而且在 SQL92 中,只有左外連接和右外連接,沒有全外連接。
什麼是左外連接,什麼是右外連接呢?
左外連接,就是指左邊的表是主表,需要顯示左邊表的全部行,而右側的表是從表,(+)表示哪個是從表。
SQL:SELECT * FROM player, team where player.team_id = team.team_id(+)
相當於 SQL99 中的:
SQL:SELECT * FROM player LEFT JOIN team on player.team_id = team.team_id
右外連接,指的就是右邊的表是主表,需要顯示右邊表的全部行,而左側的表是從表。
SQL:SELECT * FROM player, team where player.team_id(+) = team.team_id
相當於 SQL99 中的:
SQL:SELECT * FROM player RIGHT JOIN team on player.team_id = team.team_id
需要注意的是,LEFT JOIN 和 RIGHT JOIN 只存在於 SQL99 及以後的標準中,在 SQL92 中不存在,只能用(+)表示。
自連接
自連接可以對多個表進行操作,也可以對同一個表進行操作。也就是說查詢條件使用了當前表的欄位。
比如我們想要查看比布雷克·格里芬高的球員都有誰,以及他們的對應身高:
SQL:SELECT b.player_name, b.height FROM player as a , player as b WHERE a.player_name = '布雷克 - 格里芬' and a.height < b.height
運行結果(6 條記錄):
如果不用自連接的話,需要採用兩次 SQL 查詢。首先需要查詢布雷克·格里芬的身高。
SQL:SELECT height FROM player WHERE player_name = '布雷克 - 格里芬'
運行結果為 2.08。
然後再查詢比 2.08 高的球員都有誰,以及他們的對應身高:
SQL:SELECT player_name, height FROM player WHERE height > 2.08
運行結果和採用自連接的運行結果是一致的。
總結
今天我講解了常用的 SQL 標準以及 SQL92 中的連接操作。SQL92 和 SQL99 是經典的 SQL 標準,也分別叫做 SQL-2 和 SQL-3 標準。也正是在這兩個標準發布之後,SQL 影響力越來越大,甚至超越了資料庫領域。現如今 SQL 已經不僅僅是資料庫領域的主流語言,還是資訊領域中資訊處理的主流語言。在圖形檢索、影像檢索以及語音檢索中都能看到 SQL 語言的使用。
除此以外,我們使用的主流 RDBMS,比如 MySQL、Oracle、SQL Sever、DB2、PostgreSQL 等都支援 SQL 語言,也就是說它們的使用符合大部分 SQL 標準,但很難完全符合,因為這些資料庫管理系統都在 SQL 語言的基礎上,根據自身產品的特點進行了擴充。即使這樣,SQL 語言也是目前所有語言中半衰期最長的,在 1992 年,Windows3.1 發布,SQL92 標準也同時發布,如今我們早已不使用 Windows3.1 作業系統,而 SQL92 標準卻一直持續至今。
當然我們也要注意到 SQL 標準的變化,以及不同資料庫管理系統使用時的差別,比如 Oracle 對 SQL92 支援較好,而 MySQL 則不支援 SQL92 的外連接。
SQL99是如何使用連接的
SQL99 標準中的連接查詢
交叉連接
交叉連接實際上就是 SQL92 中的笛卡爾乘積,只是這裡我們採用的是 CROSS JOIN。
我們可以通過下面這行程式碼得到 player 和 team 這兩張表的笛卡爾積的結果:
SQL: SELECT * FROM player CROSS JOIN team
運行結果(一共 37*3=111 條記錄):
如果多張表進行交叉連接,比如表 t1,表 t2,表 t3 進行交叉連接,可以寫成下面這樣:
SQL: SELECT * FROM t1 CROSS JOIN t2 CROSS JOIN t3
自然連接
你可以把自然連接理解為 SQL92 中的等值連接。它會幫你自動查詢兩張連接表中所有相同的欄位,然後進行等值連接。
如果我們想把 player 表和 team 表進行等值連接,相同的欄位是 team_id。還記得在 SQL92 標準中,是如何編寫的么?
SELECT player_id, a.team_id, player_name, height, team_name FROM player as a, team as b WHERE a.team_id = b.team_id
在 SQL99 中你可以寫成:
SELECT player_id, team_id, player_name, height, team_name FROM player NATURAL JOIN team
實際上,在 SQL99 中用 NATURAL JOIN 替代了 WHERE player.team_id = team.team_id。
ON 連接
ON 連接用來指定我們想要的連接條件,針對上面的例子,它同樣可以幫助我們實現自然連接的功能:
SELECT player_id, player.team_id, player_name, height, team_name FROM player JOIN team ON player.team_id = team.team_id
這裡我們指定了連接條件是ON player.team_id = team.team_id,相當於是用 ON 進行了 team_id 欄位的等值連接。
當然你也可以 ON 連接進行非等值連接,比如我們想要查詢球員的身高等級,需要用 player 和 height_grades 兩張表:
SQL99:SELECT p.player_name, p.height, h.height_level
FROM player as p JOIN height_grades as h
ON height BETWEEN h.height_lowest AND h.height_highest
這個語句的運行結果和我們之前採用 SQL92 標準的查詢結果一樣。
SQL92:SELECT p.player_name, p.height, h.height_level
FROM player AS p, height_grades AS h
WHERE p.height BETWEEN h.height_lowest AND h.height_highest
一般來說在 SQL99 中,我們需要連接的表會採用 JOIN 進行連接,ON 指定了連接條件,後面可以是等值連接,也可以採用非等值連接。
USING 連接
當我們進行連接的時候,可以用 USING 指定數據表裡的同名欄位進行等值連接。比如:
SELECT player_id, team_id, player_name, height, team_name FROM player JOIN team USING(team_id)
你能看出與自然連接 NATURAL JOIN 不同的是,USING 指定了具體的相同的欄位名稱,你需要在 USING 的括弧 () 中填入要指定的同名欄位。同時使用 JOIN USING 可以簡化 JOIN ON 的等值連接,它與下面的 SQL 查詢結果是相同的:
SELECT player_id, player.team_id, player_name, height, team_name FROM player JOIN team ON player.team_id = team.team_id
外連接
SQL99 的外連接包括了三種形式:
- 左外連接:LEFT JOIN 或 LEFT OUTER JOIN
- 右外連接:RIGHT JOIN 或 RIGHT OUTER JOIN
- 全外連接:FULL JOIN 或 FULL OUTER JOIN
我們在 SQL92 中講解了左外連接、右外連接,在 SQL99 中還有全外連接。全外連接實際上就是左外連接和右外連接的結合。在這三種外連接中,我們一般省略 OUTER 不寫。
- 左外連接
SQL92
SELECT * FROM player, team where player.team_id = team.team_id(+)
SQL99
SELECT * FROM player LEFT JOIN team ON player.team_id = team.team_id
- 右外連接
SQL92
SELECT * FROM player, team where player.team_id(+) = team.team_id
SQL99
SELECT * FROM player RIGHT JOIN team ON player.team_id = team.team_id
- 全外連接
SQL99
SELECT * FROM player FULL JOIN team ON player.team_id = team.team_id
需要注意的是 MySQL 不支援全外連接,否則的話全外連接會返回左表和右表中的所有行。當表之間有匹配的行,會顯示內連接的結果。當某行在另一個表中沒有匹配時,那麼會把另一個表中選擇的列顯示為空值。
也就是說,全外連接的結果 = 左右表匹配的數據 + 左表沒有匹配到的數據 + 右表沒有匹配到的數據。
自連接
自連接的原理在 SQL92 和 SQL99 中都是一樣的,只是表述方式不同。
比如我們想要查看比布雷克·格里芬身高高的球員都有哪些,在兩個 SQL 標準下的查詢如下。
SQL92
SELECT b.player_name, b.height FROM player as a , player as b WHERE a.player_name = '布雷克 - 格里芬' and a.height < b.height
SQL99
SELECT b.player_name, b.height FROM player as a JOIN player as b ON a.player_name = '布雷克 - 格里芬' and a.height < b.height
運行結果(6 條記錄):

SQL99 和 SQL92 的區別
至此我們講解完了 SQL92 和 SQL99 標準下的連接查詢,它們都對連接進行了定義,只是操作的方式略有不同。我們再來回顧下,這些連接操作基本上可以分成三種情況:
- 內連接:將多個表之間滿足連接條件的數據行查詢出來。它包括了等值連接、非等值連接和自連接。
- 外連接:會返回一個表中的所有記錄,以及另一個表中匹配的行。它包括了左外連接、右外連接和全連接。
- 交叉連接:也稱為笛卡爾積,返回左表中每一行與右表中每一行的組合。在 SQL99 中使用的 CROSS JOIN。
不過 SQL92 在這三種連接操作中,和 SQL99 還存在著明顯的區別。
首先我們看下 SQL92 中的 WHERE 和 SQL99 中的 JOIN。
你能看出在 SQL92 中進行查詢時,會把所有需要連接的表都放到 FROM 之後,然後在 WHERE 中寫明連接的條件。而 SQL99 在這方面更靈活,它不需要一次性把所有需要連接的表都放到 FROM 之後,而是採用 JOIN 的方式,每次連接一張表,可以多次使用 JOIN 進行連接。
另外,我建議多表連接使用 SQL99 標準,因為層次性更強,可讀性更強,比如:
SELECT ...
FROM table1
JOIN table2 ON table1 和 table2 的連接條件
JOIN table3 ON table2 和 table3 的連接條件
它的嵌套邏輯類似我們使用的 FOR 循環:
for t1 in table1:
for t2 in table2:
if condition1:
for t3 in table3:
if condition2:
output t1 + t2 + t3
SQL99 採用的這種嵌套結構非常清爽,即使再多的表進行連接也都清晰可見。如果你採用 SQL92,可讀性就會大打折扣。
最後一點就是,SQL99 在 SQL92 的基礎上提供了一些特殊語法,比如 NATURAL JOIN 和 JOIN USING。它們在實際中是比較常用的,省略了 ON 後面的等值條件判斷,讓 SQL 語句更加簡潔。
不同 DBMS 中使用連接需要注意的地方
SQL 連接具有通用性,但是不同的 DBMS 在使用規範上會存在差異,在標準支援上也存在不同。在實際工作中,你需要參考你正在使用的 DBMS 文檔,這裡我整理了一些需要注意的常見的問題。
1. 不是所有的 DBMS 都支援全外連接
雖然 SQL99 標準提供了全外連接,但不是所有的 DBMS 都支援。不僅 MySQL 不支援,Access、SQLite、MariaDB 等資料庫軟體也不支援。不過在 Oracle、DB2、SQL Server 中是支援的。
2.Oracle 沒有表別名 AS
為了讓 SQL 查詢語句更簡潔,我們經常會使用表別名 AS,不過在 Oracle 中是不存在 AS 的,使用表別名的時候,直接在表名後面寫上表別名即可,比如 player p,而不是 player AS p。
3.SQLite 的外連接只有左連接
SQLite 是一款輕量級的資料庫軟體,在外連接上只支援左連接,不支援右連接,不過如果你想使用右連接的方式,比如table1 RIGHT JOIN table2,在 SQLite 你可以寫成table2 LEFT JOIN table1,這樣就可以得到相同的效果。
除了一些常見的語法問題,還有一些關於連接的性能問題需要你注意:
1. 控制連接表的數量
多表連接就相當於嵌套 for 循環一樣,非常消耗資源,會讓 SQL 查詢性能下降得很嚴重,因此不要連接不必要的表。在許多 DBMS 中,也都會有最大連接表的限制。
2. 在連接時不要忘記 WHERE 語句
多表連接的目的不是為了做笛卡爾積,而是篩選符合條件的數據行,因此在多表連接的時候不要忘記了 WHERE 語句,這樣可以過濾掉不必要的數據行返回。
3. 使用自連接而不是子查詢
我們在查看比布雷克·格里芬高的球員都有誰的時候,可以使用子查詢,也可以使用自連接。一般情況建議你使用自連接,因為在許多 DBMS 的處理過程中,對於自連接的處理速度要比子查詢快得多。你可以這樣理解:子查詢實際上是通過未知表進行查詢後的條件判斷,而自連接是通過已知的自身數據表進行條件判斷,因此在大部分 DBMS 中都對自連接處理進行了優化。
總結
連接可以說是 SQL 中的核心操作,通過兩篇文章的學習,你已經從多個維度對連接進行了了解。同時,我們對 SQL 的兩個重要標準 SQL92 和 SQL99 進行了學習,在我們需要進行外連接的時候,建議採用 SQL99 標準,這樣更適合閱讀。
此外我還想強調一下,我們在進行連接的時候,使用的關係型資料庫管理系統,之所以存在關係是因為各種數據表之間存在關聯,它們並不是孤立存在的。在實際工作中,尤其是做業務報表的時候,我們會用到 SQL 中的連接操作(JOIN),因此我們需要理解和熟練掌握 SQL 標準中連接的使用,以及不同 DBMS 中對連接的語法規範。剩下要做的,就是通過做練習和實戰來增強你的經驗了,做的練習多了,也就自然有感覺了。


