Web Scraper 高級用法——使用 CouchDB 存儲數據 | 簡易數據分析 18
- 2020 年 4 月 15 日
- 筆記
- web scraper, 簡易數據分析

這是簡易數據分析系列的第 18 篇文章。
利用 web scraper 抓取數據的時候,大家一定會遇到一個問題:數據是亂序的。在之前的教程里,我建議大家利用 Excel 等工具對數據二次加工排序,但還是存在部分數據無法排序的情況。
其實解決數據亂序的方法也有,那就是換一個資料庫。
web scraper 作為一個瀏覽器插件,數據默認保存在瀏覽器的 localStorage 資料庫里。其實 web scraper 還支援外設資料庫——CouchDB。只要切換成這個資料庫,就可以在抓取過程中保證數據正序了。
1.CouchDB 下載安裝
CouchDB 可以從官網下載,官網鏈接為://couchdb.apache.org/。
因為伺服器在外網,中國訪問可能比較慢,我存了一份雲盤文件,可以公眾號後台回復「CouchDB」獲取下載連接,Mac 和 Win 安裝包都有,版本為 3.0.0。
具體的安裝過程我就忽略了,大家平常怎麼安裝軟體就怎麼安裝 CouchDB。
2.配置 CouchDB
1.創建帳號
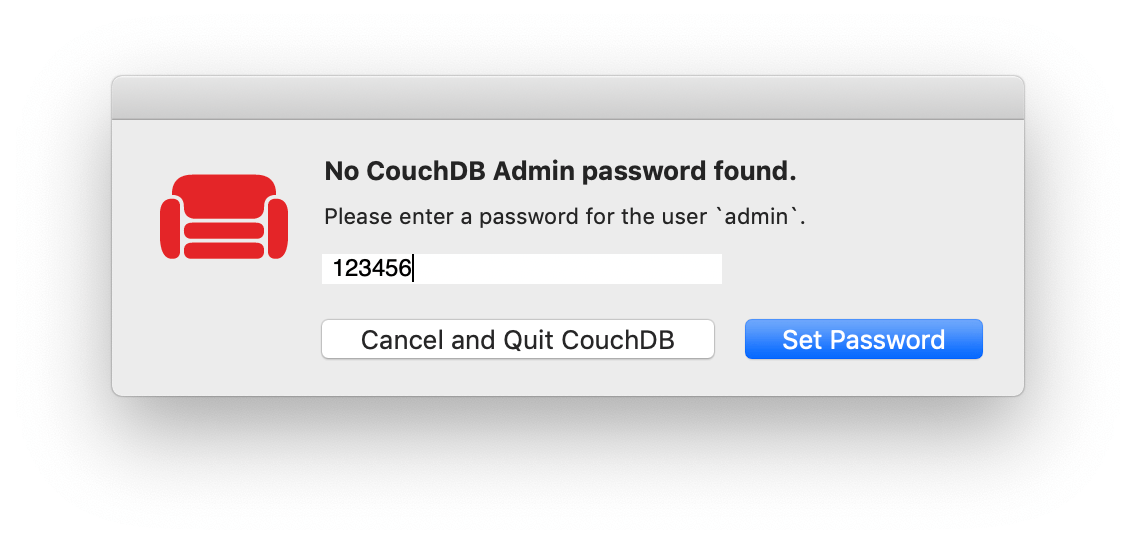
第一次打開 CouchDB,可能會要求你創建一個 CouchDB 帳號(或設置帳號密碼),這裡我為了演示方便就取個簡單的密碼。大家一定要記住帳號密碼,因為之後訪問 CouchDB 都要填寫。
2.訪問 CouchDB
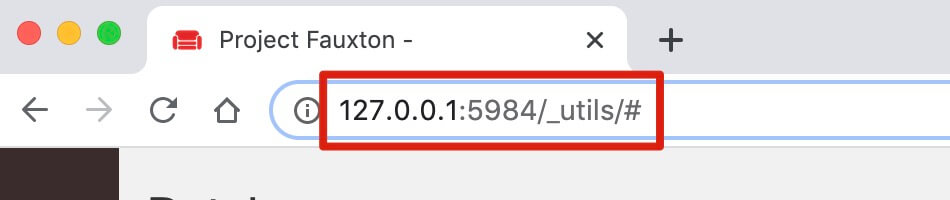
一般第一次打開 CouchDB,會自動打開一個網頁,網址為://127.0.0.1:5984/_utils/#,如果沒有自動打開,可以瀏覽器手動輸入這個網址。
3.創建 Database
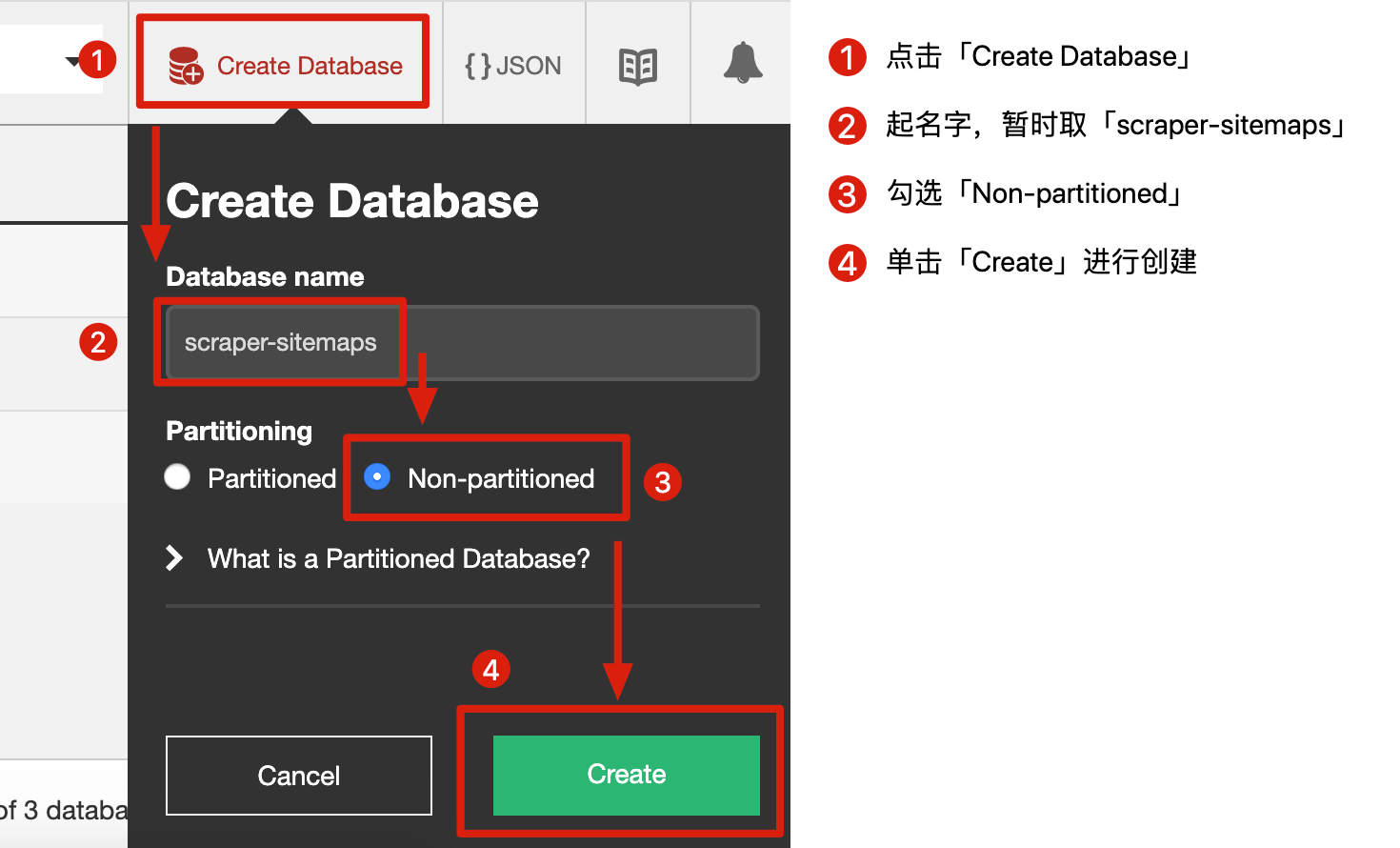
我們可以把 Database 理解為一個文件,我們要創建一個文件專門保存 sitemap,創建流程可以看下圖:
- 點擊「Create Database」
- 為這個文件起個名字,叫「scraper-sitemaps」
- 勾選「Non-partitioned」
- 單擊「Create」創建
3.Web Scraper 切換到 CouchDB
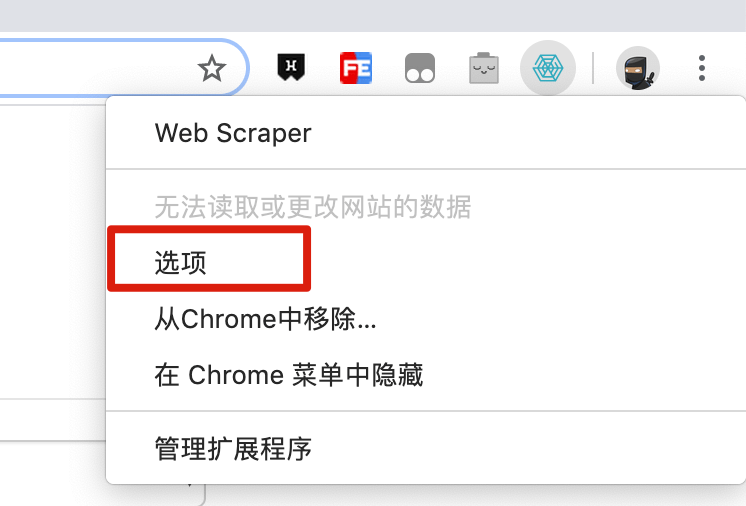
1.首先從瀏覽器右上角的插件列表中找到 Web Scraper 的圖標,然後右鍵點擊,在彈出的菜單里再點擊「選項」。
2.在新打開的管理頁面里,要做這幾步:
- Storage type 切換為 CouchDB
- Sitemap db 填入 //127.0.0.1:5984/scraper-sitemaps
- Data db 填入 //127.0.0.1:5984/
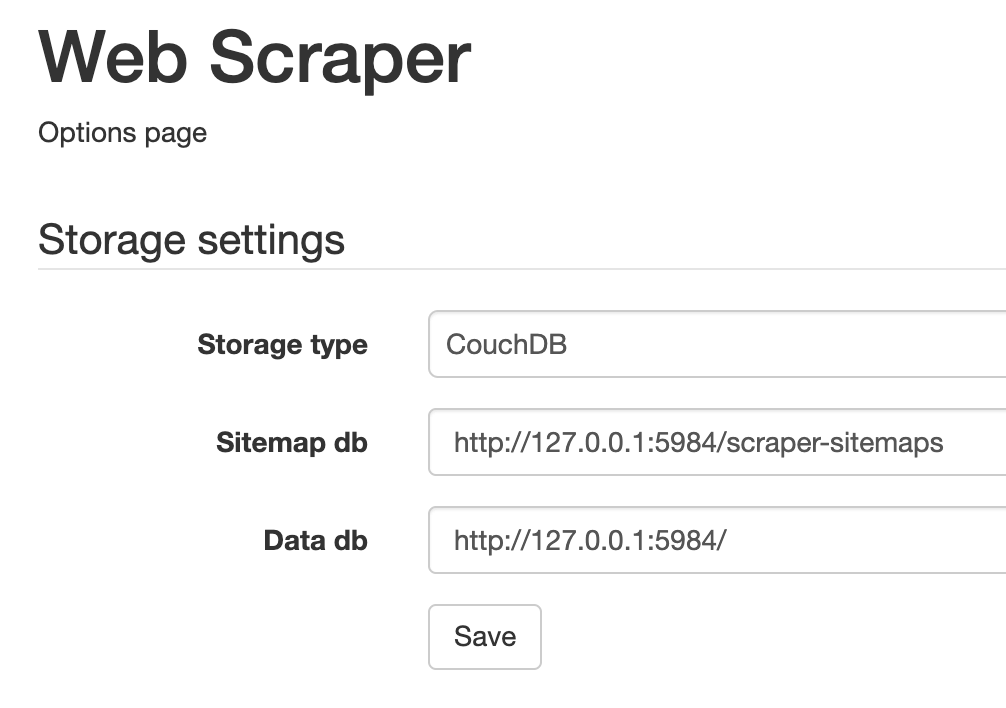
3.最後點擊「Save」按鈕保存配置,重啟瀏覽器讓配置生效。
4.抓取數據
抓取數據前,我們需要把電腦的各種網路代理關掉,要不然可能會連接不到 CouchDB。
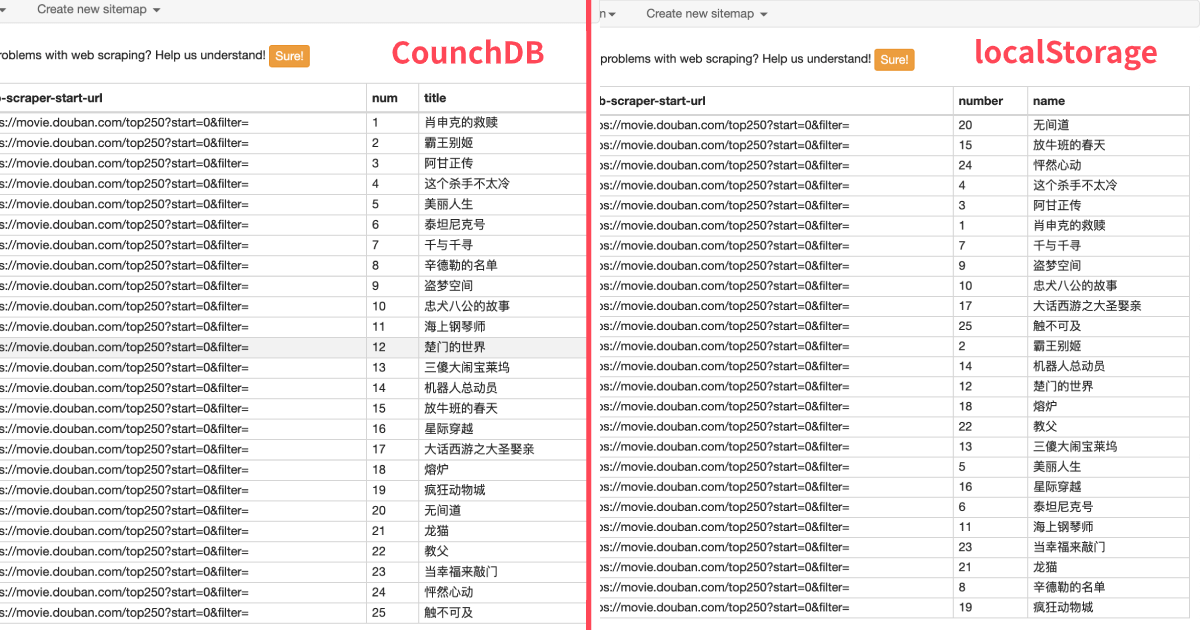
網頁還是拿豆瓣 TOP250 做個簡單的演示。web scraper 的操作和以前都是一樣的,預覽數據時我們就會發現,和 localStorage 比起來,數據都是正序的:
我們也可以在 CouchDB 的操作頁面預覽數據。//127.0.0.1:5984/_utils/# 這個頁面是主介面,我們可以看到保存 sitemap 的 database 和豆瓣數據的 database:
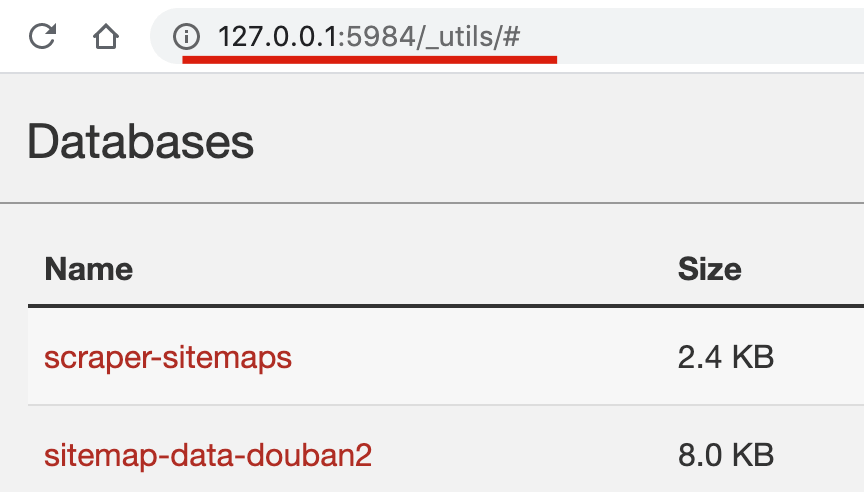
點擊「sitemap-data-douban2」進入數據詳情頁,可以預覽數據:

5.導出數據
導出數據也是老樣子,在 web scraper 插件面板里點擊「Export data as CSV」就可以導出。其實也可以從 CouchDB 里導出數據,但這樣還得寫一些腳本,我這裡就不多介紹了,感興趣的人可以自行搜索。
6.個人感悟
其實一開始我並不想介紹 CouchDB,因為從我的角度看,web scraper 是一個很輕量的插件,可以解決一些輕量的抓取需求。加入 CouchDB 後,這個安裝下來要幾百兆的軟體,只是解決了 web scraper 數據亂序的問題,在我看來還是有些大炮打蚊子,也脫離了輕量抓取的初衷。但是有不少讀者私信我相關內容,為了教程的完整性,我還是寫下了這篇文章。
7.聯繫我
因為文章發在各大平台上,帳號較多不能及時回複評論和私信,有問題可關注公眾號 ——「鹵代烴實驗室」,(或 wx 搜索 sky-chx)關註上車防失聯。



