K均值演算法
一、概念
K-means中心思想:事先確定常數K,常數K意味著最終的聚類類別數,首先隨機選定初始點為質心,並通過計算每一個樣本與質心之間的相似度(這裡為歐式距離),將樣本點歸到最相似的類中,接著,重新計算每個類的質心(即為類中心),重複這樣的過程,直到質心不再改變,最終就確定了每個樣本所屬的類別以及每個類的質心。由於每次都要計算所有的樣本與每一個質心之間的相似度,故在大規模的數據集上,K-Means演算法的收斂速度比較慢。
二、特點:
常用距離
a.歐式距離
b.曼哈頓距離
三、演算法流程
K-means是一個反覆迭代的過程,演算法分為四個步驟:
(x,k,y)
(1) 選取數據空間中的K個對象作為初始中心,每個對象代表一個聚類中心;
def initcenter(x, k): kc
(2) 對於樣本中的數據對象,根據它們與這些聚類中心的歐氏距離,按距離最近的準則將它們分到距離它們最近的聚類中心(最相似)所對應的類;
def nearest(kc, x[i]): j
def xclassify(x, y, kc):y[i]=j
(3) 更新聚類中心:將每個類別中所有對象所對應的均值作為該類別的聚類中心,計算目標函數的值;
def kcmean(x, y, kc, k):
(4) 判斷聚類中心和目標函數的值是否發生改變,若不變,則輸出結果,若改變,則返回2)。
while flag:
y = xclassify(x, y, kc)
kc, flag = kcmean(x, y, kc, k)
四、實踐
(1).撲克牌手動演練k均值聚類過程:>30張牌,3類
①本次模擬k均值用到的撲克牌,初始中心為(2,9,12)

②經過一輪計算(選出中心:3,8,12)
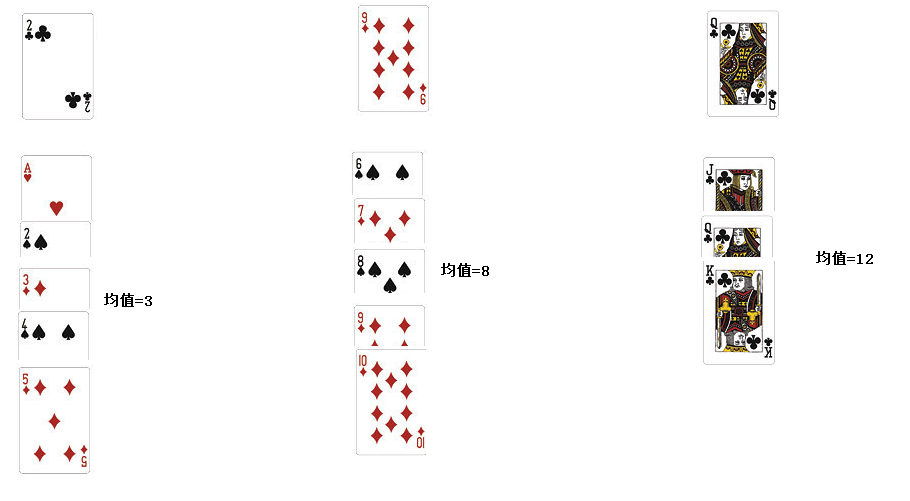
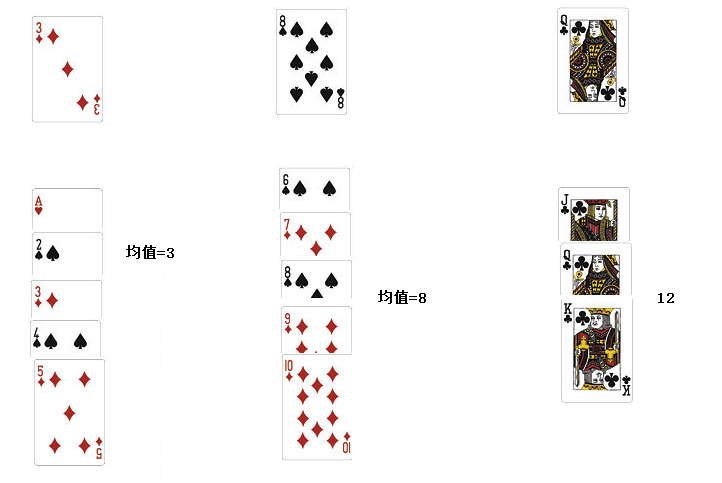
③一直算到最後
(2).*自主編寫K-means演算法 ,以鳶尾花花瓣長度數據做聚類,並用散點圖顯示。
### 1、導入鳶尾花數據
from sklearn.datasets import load_iris
import numpy as np
### 2、鳶尾花數據
iris = load_iris()
data=iris['data']
#樣本屬性個數
m=data.shape[1]
#樣本個數
n=len(data)
#類中心個數,即最終分類
k=3
### 3、數據初始化
#距離矩陣
dist=np.zeros([n,k+1])
#初始類中心
center=np.zeros([k,m])
#新的類中心
new_center=np.zeros([k,m])
### 4、選中心
#選擇前三個樣本作為初始類中心
center=data[:k, :]
while True:
#求距離
for i in range(n):
for j in range(k):
dist[i,j]=np.sqrt(sum((data[i,:]-center[j,:])**2))
#歸類
dist[i,k]=np.argmin(dist[i,:k])
#求新類中心
for i in range(k):
index=dist[:,k]==i
new_center[i,:]=np.mean(data[index, :])
#判斷結束
if(np.all(center==new_center)):
break
else:
center=new_center
print('聚類結果:',dist[:,k])

(3)用sklearn.cluster.KMeans,鳶尾花花瓣長度數據做聚類,並用散點圖顯示。
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 獲取鳶尾花數據集
iris = load_iris()
data = iris.data[:, 1]
# 鳶尾特徵值
x = data.reshape(-1, 1)
# 構建模型
model = KMeans(n_clusters=3)
# 訓練
model.fit(x)
# 預測樣本的聚類索引
y = model.predict(x)
print("預測結果:", y)
#畫圖
plt.scatter(x[:, 0], x[:, 0], c=y, s=50, cmap='rainbow')
plt.show()
預測結果:

散點圖可視化:

(4)鳶尾花完整數據做聚類並用散點圖顯示。
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 導入鳶尾花數據集
iris = load_iris()
# 鳶尾花花瓣長度數據
x = iris.data
# 構建模型
model = KMeans(n_clusters=3)
# 訓練
model.fit(x)
# 預測
y = model.predict(x)
print("預測結果:", y)
#畫圖
plt.scatter(x[:, 2], x[:, 3], c=y, s=50, cmap='rainbow')
plt.show()
預測結果:

散點圖可視化:

(5)想想k均值演算法中以用來做什麼?
- 文本分析和歸類
- K均值演算法實現影像壓縮
- 像素處理
- K均值演算法處理影像

