[一起面試AI]NO.5過擬合、欠擬合與正則化是什麼?
Q1 過擬合與欠擬合的區別是什麼,什麼是正則化
欠擬合指的是模型不能夠再訓練集上獲得足夠低的「訓練誤差」,往往由於特徵維度過少,導致擬合的函數無法滿足訓練集,導致誤差較大。
過擬合指的是模型訓練誤差與測試誤差之間差距過大;具體來說就是模型在訓練集上訓練過度,導致泛化能力過差。
「所有為了減少測試誤差的策略統稱為正則化方法」,不過代價可能是增大訓練誤差。
Q2 解決欠擬合的方法有哪些
降低欠擬合風險主要有以下3類方法。
-
加入新的特徵,對於深度學習來講就可以利用因子分解機、子編碼器等。
-
增加模型複雜度,對於線性模型來說可以增加高次項,對於深度學習來講可以增加網路層數、神經元個數。
-
減小正則化項的係數,從而提高模型的學習能力。
Q3 防止過擬合的方法主要有哪些
「1.正則化」
正則化包含L1正則化、L2正則化、混合L1與L2正則化。
「L1正則化」目的是減少參數的絕對值總和,定義為:
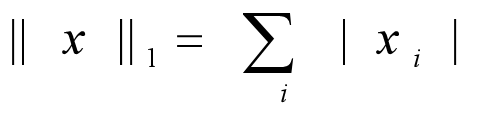
「L2正則化」目的是減少參數平方的總和,定義為:
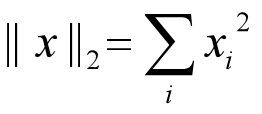
**混合L1與L2**正則化是希望能夠調節L1正則化與L2正則化,定義為:
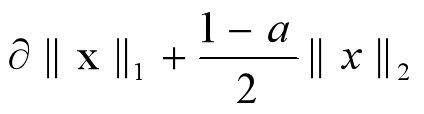
因為最優的參數值很大概率出現在「坐標軸」上,這樣就會導致某一維的權重為0,產生「稀疏權重矩陣」。而L2正則化的最優的參數值很小概率出現在坐標軸上,因此每一維的參數都不會是0。
所以由於L1正則化導致參數趨近於0,因此它常用於特徵選擇設置中。而機器學習中最常用的正則化方法是對權重施加「L2範數約束」。
L1正則化與L2正則化還有個「重要區別」就是L1正則化可通過假設權重w的先驗分布為「拉普拉斯分布」,由最大後驗概率估計導出。L2正則化可通過假設權重w的先驗分布為「高斯分布」,由最大後驗概率估計導出。
「2.Batch Normalization」
Batch Normalization是一種深度學習中減少泛化誤差的「正則化」方法,主要是通過緩解梯度下降加速網路的訓練,防止過擬合,降低了參數初始化的要求。
由於訓練數據與測試數據分布不同會降低模型的泛化能力。因此,應該在開始訓練前對數據進行「歸一化處理」。因為神經網路每層的參數不同,每一批數據的分布也會改變,從而導致每次迭代都會去擬合不同的數據分布,增大過擬合的風險。
Batch Normalization會針對每一批數據在輸入前進行歸一化處理,目的是為了使得輸入數據均值為0,標準差為1。這樣就能將數據限制在統一的分布下。
「3.Dropout」
Dropout是避免神經網路過擬合的技巧來實現的。Dropout並不會改變網路,他會對神經元做「隨機」刪減,從而使得網路複雜度「降低」,有效的防止過擬合。
具體表現為:每一次迭代都刪除一部分隱層單元,直至訓練結束。
運用Dropout相當於訓練了非常多的僅有部分隱層單元的神經網路,每個網路都會給出一個結果,隨著訓練的進行,大部分網路都會給出正確的結果。
「4.迭代截斷」
迭代截斷主要是在迭代中記錄準確值,當達到最佳準確率的時候就截斷訓練。
「5.交叉驗證」
K-flod交叉驗證是把訓練樣本分成k份,在驗證時,依次選取每一份樣本作為驗證集,每次實驗中,使用此過程在驗證集合上取得最佳性能的迭代次數,並選擇恰當的參數。
hi 認識一下?
❝
微信關注公眾號:「全都是碼農」 (allmanong)
你將獲得:
關於人工智慧的所有面試問題「一網打盡」!未來還有「思維導圖」哦!
回復「121」 立即獲得 已整理好121本「python學習電子書」。
回復「89」 立即獲得 「程式設計師」史詩級必讀書單吐血整理「四個維度」系列89本書。
回復「167」 立即獲得 「機器學習和python」學習之路史上整理「大數據技術書」從入門到進階最全本(66本)
回復「18」 立即獲得 「資料庫」從入門到進階必讀18本技術書籍網盤整理電子書(珍藏版)
回復「56」 立即獲得 我整理的56本「演算法與數據結構」書
未來還有人工智慧研究生課程筆記等等,我們一起進步呀!
❞


