Flink| 實時需要分析
- 2020 年 4 月 11 日
- 筆記
========================實時流量統計
1. 實時熱門商品HotItems
每隔 5 分鐘輸出最近一小時內點擊量最多的前 N 個商品。
抽取出業務時間戳,告訴 Flink 框架基於業務時間做窗口
• 過濾出點擊行為數據
• 按一小時的窗口大小,每 5 分鐘統計一次,做滑動窗口聚合( Sliding Window)
• 按每個窗口聚合,輸出每個窗口中點擊量前 N 名的商品
2. 實時流量統計 NetworkFlow
"實時流量統計" 對於一個電商平台而言,用戶登
錄的入口流量、不同頁面的訪問流量 都是值得分析的重要數據,而這些數據,可以
簡單地從 web 伺服器的日誌中提取出來。
實現"熱門頁面瀏覽數"的統計,也就是讀取伺服器日誌中的每
一行log統計在一段時間內用戶訪問每一個url的次數,然後排序輸出顯示。
具體做法為:
每隔 5 秒,輸出最近 10 分鐘內訪問 量最多的前 N 個 URL。可以看出,這個需求與之前“實時熱門商品統計”非常類似,
所以我們完全可以借鑒此前的程式碼。
3. PV 網站頁面流量 - PageView
衡量網站流量一個最簡單的指標,就是網站的頁面瀏覽量(Page View PV );
用戶每次打開一個頁面便記錄 1 次 PV ,多次打開同一頁面則瀏覽量累計。一般來說PV 與來訪者的數量成正比,但是 PV 並不直接決定頁面的真實來訪者數量,
如同一個來訪者通過不斷的刷新頁面,也可以製造出非常高的 PV 。
我們知道,用戶瀏覽頁面時,會從瀏覽器向網路伺服器 發出一個請求 Request網路伺服器接到這個請求後,會將該請求對應的一個網頁( Page )發送給瀏覽器
從而產生了一個 PV。所以我們的統計方法,可以是從 web 伺服器的日誌中去提取對應的頁面訪問然後統計,就向上一節中的做法一樣;也可以直接從埋點日誌中提
取用戶發來的頁面請求,從而統計出總瀏覽量。
實現一個網站總瀏覽量的統計。可以設置滾動時間窗口,實時統計每小時內的網站 PV
4. UV 獨立訪客數
* 上例中,我們統計的是所有用戶對頁面的所有瀏覽行為,也就是說,同一用戶的瀏覽行為會被重複統計。而在實際應用中,我們往往還會關注,在一段
* 時間內到底有多少不同的用戶訪問了網站。另外一個統計流量的重要指標是網站的獨立訪客數(Unique Visitor UV )。 UV指的是一段時間(比如一小時)內訪問網站 的 總人數, 1 天內同一訪客的多次訪問
* 只記錄為一個訪客。通過 IP 和 cookie 一般 是判斷 UV 值的兩種方式。 當客戶端第一次訪問某個網站伺服器的時候,網站伺服器會給這個客戶端的電腦發出 一個 Cookie
* 通常放在這個客戶端電腦的 C 盤當中。在這個 Cookie 中會分配一個獨一無二的編號,這其中會記錄一些訪問伺服器的資訊,如訪問時間,訪問了哪些頁面等等。當你下次再訪問這個伺服器的時候,伺服器就可以直接從你的電腦中找到上一次放進去的
* Cookie 文件,並且對其進行一些更新,但那個獨一無二的編號是不會變的。
* 此例中可以根據 userId 來區分不同的用戶。
5. 使用布隆過濾器查重-過濾的UV統計
/**
* 上例中,把所有數據的userId 都存在了窗口計算的狀態里,在窗口收集數據的過程中,狀態會不斷增大。一般情況下,只要不超出記憶體的承受範圍,
* 這種做法也沒什麼問題;但如果我們遇到的數據量很大呢?把所有數據暫存放到記憶體里,顯然不是一個好注意。我們會想到,可以利用 redis這種記憶體級 k v 資料庫,為我們做一個快取。
* 但如果我們遇到的情況非常極端,數據大到驚人呢?比如上億級的用戶,要去重計算 UV 。
* 如果放到redis 中,億級的用戶id (每個 20 位元組左右的話)可能需要幾G甚至幾十G的空間來存儲。當然放到 redis 中,用集群進行擴展也不是不可以,但明顯
* 代價太大了。一個更好的想法是,其實我們不需要完整地存儲用戶ID 的資訊,只要知道他在不在就行了。所以其實我們可以進行壓縮處理,用一位( bit )就可以表示一個用戶
* 的狀態。這個思想的具體實現就是布隆過濾器( Bloom Filter )。
* 本質上布隆過濾器是一種數據結構,比較巧妙的概率型數據結構(probabilisticdata structure ),特點是高效地插入和查詢,可以用來告訴你 “某樣東西一定不存在或者可能存在”。
* 它本身是一個很長的二進位向量,既然是二進位的向量,那麼顯而易見的,存放的不是 0 ,就是 1 。 相比於傳統的 List 、 Set 、 Map 等數據結構,它更高效、佔用空間更少,
* 但是缺點是其返回的結果是概率性的,而不是確切的。
* 我們的目標就是,利用某種方法(一般是Hash 函數)把每個數據,對應到一個點陣圖的某一位上去;如果數據存在,那一位就是1,不存在則為 0 。
*/

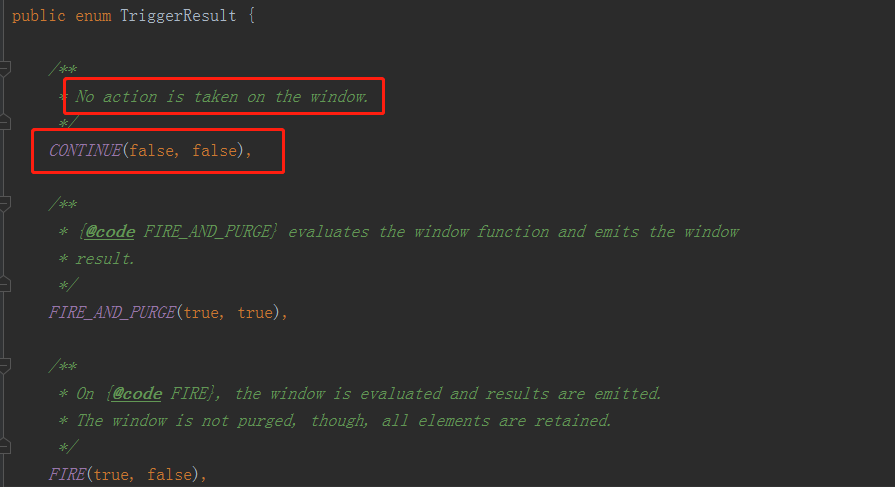
判斷當前最大的時間戳 <= 當前的watermark,就返回一個TriggerResult.FIRE(觸發);否則就註冊一個定時器(關窗的操作)
TriggerResult的類型:CONTINUE-什麼都不做繼續處理窗口;FIRE觸發窗口的計算操作但並不會關閉窗口清除它的狀態;PURGE清除窗口的狀態;FIRE_AND_PURGE觸發並清除掉;


redis:

==========================市場營銷商業指標統計分析===========
* 對於電商企業來說,一般會通過各種不同的渠道對自己的APP進行市場推廣,而這些渠道的統計數據(比如,不同網站上廣告鏈接的點擊量、APP下載量)就成了市場營銷的重要商業指標。
* 首先考察分渠道的市場推廣統計。
* 需要自定義一個測試源SimulatedEventSource來生成用戶行為的事件流。
*1. 分渠道統計 AppMarketingByChannel.scala
/**
* 2. 不分渠道(總量)統計
* 同樣我們還可以考察不分渠道的市場推廣統計,這樣得到的就是所有渠道推廣的總量 AppMarketing.scala 。
* /
/**
* 電商網站的市場營銷商業指標中,除了自身的APP 推廣,還會考慮到頁面上的廣告投放(包括自己經營的產品和其它網站的廣告)。 所以廣告相關的統計分析,也是市場營銷的重要指標。
* 對於廣告的統計,最簡單也最重要的就是頁面廣告的點擊量,網站往往需要根據廣告點擊量來制定定價策略和調整推廣方式,而且也可以藉此收集用戶的偏好資訊。
* 更加具體的應用是,我們可以根據用戶的地理位置進行劃分,從而總結出不同省份用戶對不同廣告的偏好,這樣更有助於廣告的精準投放。
* 3. 頁面廣告點擊量統計
* 接下來我們就進行頁面廣告按照省份劃分的點擊量的統計。AdStatisticsByGeo .scala 文件 。
* 自定義一些測試數據AdClickLog,用來生成用戶點擊廣告行為的事件流。
* 主函數以 province 進行 keyBy ,然後開一小時的時間窗口,滑動距離為5秒,統計窗口內的點擊事件數量。
*
* 廣告點擊量統計,同一用戶的重複點擊是會疊加計算的。在實際場景中,同一用戶確實可能反覆點開同一個廣告,這也說明了用戶對廣告更大的興趣;
* 但是如果用戶在一段時間非常頻繁地點擊廣告,這顯然不是一個正常行為,有刷點擊量的嫌疑。所以我們可以對一段時間內(比如一天內)的用戶點擊行為進行約束,
* 如果對同一個廣告點擊超過一定限額(比如 100 次),應該把該用戶加入黑名單並報警,此後其點擊行為不應該再統計。
* 4. 黑名單過濾
==========================惡意登錄監控==================
* 對於網站而言,用戶登錄並不是頻繁的業務操作。如果一個用戶短時間內頻繁登錄失敗,就有可能是出現了程式的惡意攻擊,比如密碼暴力破解。因此我們考慮,
* 應該對用戶的登錄失敗動作進行統計,具體來說,如果同一用戶(可以是不同 IP)在2秒之內連續兩次登錄失敗,就認為存在惡意登錄的風險,輸出相關的資訊進行
* 報警提示。這是電商網站、也是幾乎所有 網站風控的基本一環。
* 1. 狀態編程的方式實現:LoginFail .scala
* 由於同樣引入了時間,我們可以想到,最簡單的方法其實與之前的熱門統計類似,只需要按照用戶 ID 分流,然後遇到登錄失敗的事件時將其保存在 ListState 中,
* 然後設置一個定時器,2秒後觸發。定時器觸發時檢查狀態中的登錄失敗事件個數,如果大於等於2,那麼就輸出報警資訊。
*
* 新建一個單例對象。 定義樣例類LoginEvent ,這是輸入的登錄事件流。登錄數據本應該從UserBehavior日誌里提取
* 由於UserBehavior.csv中沒有做相關埋點,從另一個文件 LoginLog.csv 中讀取登錄數據 。
*
*
* 2. 優化操作:
* 第一次的程式碼實現中我們可以看到,直接把每次登錄失敗的數據存起來、設置定時器一段時間後再讀取,這種做法儘管簡單,但和我們開始的需求還是略有差異
* 的。這種做法只能隔 2 秒之後去判斷一下這期間是否有多次失敗登錄,而不是在一次登錄失敗之後、再一次登錄失敗時就立刻報警。這個需求如果嚴格實現起來,相
* 當於要判斷任意緊鄰的事件,是否符合某種模式。於是我們可以想到,這個需求其實可以不用定時器觸發,直接在狀態中存取上一次登錄失敗的事件,每次都做判斷和比對,就可以實現最初的需求。
* 在程式碼MatchFunction中刪掉onTimer processElement
*
* 我們通過對狀態編程的改進,去掉了定時器,在 process function 中做了
* 更多的邏輯處 理,實現了最初的需求。不過這種方法里有很多的條件判斷,目前僅僅實現的是檢測“連續2次登錄失敗”,這是最簡單的情形。
* 如果需要檢測更多次,內部邏輯顯然會變得非常複雜。那有什麼方式可以方便地實現呢?
* flink為我們提供了CEP Complex Event Processing ,複雜事件處理庫,用於在流中篩選符合某種複雜模式的事件。
* 3. 基於 CEP 來完成這個模組的實現。
========================訂單支付實時監控=========================
在電商網站中,訂單的支付作為直接與營銷收入掛鉤的一環,在業務流程中非常重要。對於訂單而言,為了正確控制業務流程,也為了增加用戶的支付意願,網
站一般會設置一個支付失效時間,超過一段時間不支付的訂單就會被取消。另外,對於訂單的支付,我們還應保證用戶支付的正確性,這可以通過第三方支付平台的
對於訂單的支付,我們還應保證用戶支付的正確性,這可以通過第三方支付平台的交易數據來做一個實時對賬。
將實現這兩個需求。交易數據來做一個實時對賬。
* 在電商平台中最終創造收入和利潤的是用戶下單購買的環節;更具體一點,是用戶真正完成支付動作的時候。用戶下單的行為可以表明用戶對商品的需求,但
* 在現實中,並不是每次下單都會被用戶立刻支付。當拖延一段時間後,用戶支付的意願會降低。所以為了讓用戶更有緊迫感從而提高支付轉化率,同時也為了防範訂
* 單支付環節的安全風險,電商網站往往會對訂單狀態進行監控,設置一個失效時間(比如 15 分鐘),如果下單後一段時間仍未支付,訂單就會被 取消。
* 使用 CEP 實現
* 利用 CEP 庫來實現這個功能。我們先將事件流按照訂單號orderId分流,
* 定義這樣的一個事件模式:在15分鐘內,事件“create”與pay非嚴格緊鄰,這樣調用.select 方法時,就可以同時獲取到匹配出的事件和超時未匹配的事件。
* 1. CEP實現訂單超時報警
* 2. 用狀態編程來實現:
* 我們同樣可以利用Process Function ,自定義實現檢測訂單超時的功能。為了簡化問題,我們只考慮超時報警的情形,在 pay 事件超時未發生的情況下,輸出超時報警資訊。
* 一個簡單的思路是,可以在訂單的create 事件到來後註冊定時器,15分鐘後觸發;然後再用一個布爾類型的 Value 狀態來作為標識位,表明 pay 事件是否發生過。
* 如果 pay 事件已經發生,狀態被置為 true ,那麼就不再需要 做什麼操作;而如果 pay事件一直沒來,狀態一直為 false,到定時器觸發時,就應該輸出超時報警資訊。
* 現在只考慮兩種情況:①來一個create,來一個pay create後邊有pay就正常匹配,如果沒來就超時報警
* 亂序的數據,有可能create和pay的先後順序
* 超時報警的情況: 遇到create設一個定時器,遇到pay改一個狀態(或者不刪定時器,直接設定一個狀態看有沒有pay來過,有則定時器觸發時說是正常的,沒有就超時報警
-----來自兩條流的訂單交易匹配----------
* 對於訂單支付事件,用戶支付完成其實並不算完,我們還得確認平台賬戶上是否到賬了。而往往這會來自不同的日誌資訊,所以我們要同時讀入兩條流的數據來
* 做合併處理。這裡我們利用 connect 將兩條流進行連接,
* 1. 用自定義的CoProcessFunction 進行處理。
* 2. 雙流join
* window join(Tumbling Window Join、 Sliding Window Join)適用於兩條流join,後邊還要開窗口的分析
*Interval join(區間join)適用於感測器報警(溫度煙霧出現異常,它倆時間得匹配上在同一時間範圍內同時出現,溫度又升高的很快)
* Join中當做狀態保存起來
*此需求是兩條流匹配上就可以了
統計類:讀取數據、做簡單包裝轉換map、filter、按某個欄位分組,開窗,做聚合
排序| TopN:再做一個ProcessFunction,把所有數據都收集到排序輸出;
以上是基於DataStreamAPI,也可以用高級API、TableAPI和FlinkSQL
業務流程中的狀態做檢測輸出和警告:自定義編程、狀態
事件邏輯、風控:CEP