Python第十三章-網路編程
- 2020 年 4 月 8 日
- 筆記
網路編程
一、網路編程基礎
python 的網路編程模組主要支援兩種Internet協議: TCP 和 UDP.
1.1通訊協議
通訊協議也叫網路傳輸協議或簡稱為傳送協議(Communications Protocol),是指電腦通訊或網路設備的共同語言。
現在最普及的電腦通訊為網路通訊,所以「傳送協議」一般都指電腦通訊的傳送協議,如:TCP/IP、NetBEUI、HTTP、FTP等。
然而,傳送協議也存在於電腦的其他形式通訊,例如:面向對象編程裡面對象之間的通訊;作業系統內不同程式之間的消息,都需要有一個傳送協議,以確保傳信雙方能夠溝通無間。
1.2TCP/IP協議
在Internet中TCP/IP協議是使用最為廣泛的通訊協議(互聯網上的一種事實的標準)。TCP/IP是英文Transmission Control Protocol/Internet Protocol的縮寫,意思是「傳輸控制協議/網際協議」
TCP/IP 協議是一個工業標準協議套件,專為跨廣域網(WAN)的大型互聯網路而設計。
TCP/IP 網路體系結構模型就是遵循TCP/IP 協議進行通訊的一種分層體系,現今,Internet和Intranet所使用的協議一般都為TCP/IP 協議。
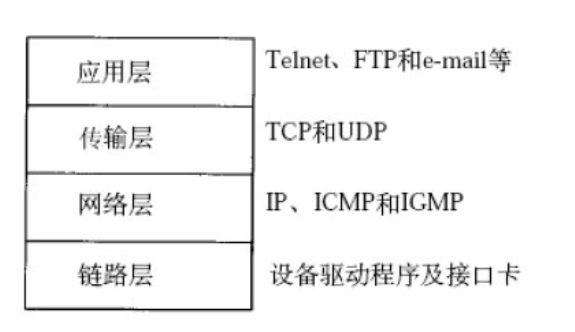
在了解該協議之前,我們必須掌握基於該協議的體系結構層次,而TCP/IP體系結構分為四層。
第 1 層 網路介面層
包括用於協作IP數據在已有網路介質上傳輸的協議,提供TCP/IP協議的數據結構和實際物理硬體之間的介面。比如地址解析協議(Address Resolution Protocol, ARP )等。
第 2 層 網路層
對應於OSI模型的網路層,主要包含了IP、RIP等相關協議,負責數據的打包、定址及路由。還包括網間控制報文協議(ICMP)來提供網路診斷資訊。
第 3 層 傳輸層
對應於OSI的傳輸層,提供了兩種端到端的通訊服務,分別是TCP和UDP協議。
第 4 層 應用層
對應於OSI的應用層、表達層和會話層,提供了網路與應用之間的對話介面。包含了各種網路應用層協議,比如Http、FTP等應用協議。
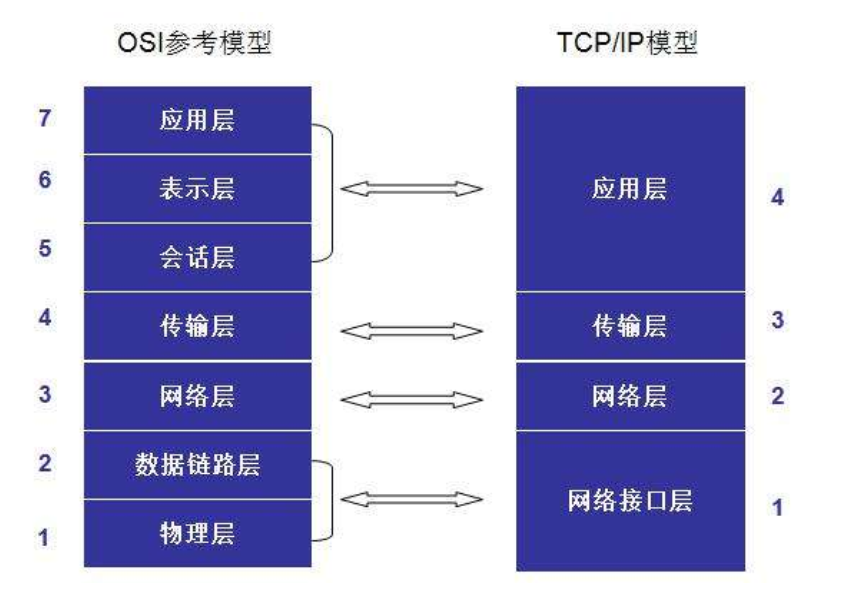
附錄:OSI 七層參考模型
1.3 IP 地址和埠號
1.3.1 IP 地址
互聯網協議地址(英語:Internet Protocol Address,又譯為網際協議地址),縮寫為IP地址(英語:IP Address)
IP 地址是分配給網路上使用網際協議(英語:Internet Protocol, IP)的設備的數字標籤。常見的IP地址分為IPv4與IPv6兩大類。
IPV4地址
IP地址由32位二進位數組成,為便於使用,常以XXX.XXX.XXX.XXX形式表現,每組XXX代表小於或等於255的10進位數。例如維基媒體的一個IP地址是208.80.152.2。
地址可分為A、B、C、D、E五大類,其中E類屬於特殊保留地址。
IP地址是唯一的。目前IP技術可能使用的IP地址最多可有4,294,967,296個(即232)。驟看可能覺得很難會用盡,但由於早期編碼和分配上的問題,使很多區域的編碼實際上被空出或不能使用。加上互聯網的普及,使大部分家庭都至少有一部電腦,連同公司的電腦,以及連接網路的各種設備都消耗了大量IPv4地址資源。
隨著互聯網的快速成長,IPv4的42億個地址的分配最終於2011年2月3日用盡[1][2]。相應的科研組織已研究出128位的IPv6,其IP地址數量最高可達3.402823669 × 1038個,屆時每個人家居中的每件電器,每件對象,甚至地球上每一粒沙子都可以擁有自己的IP地址。
在A類、B類、C類IP地址中,如果主機號是全1,那麼這個地址為直接廣播地址,它是用來使路由器將一個分組以廣播形式發送給特定網路上的所有主機。32位全為1的IP地址「255.255.255.255」為受限廣播地址("limited broadcast" destination address),用來將一個分組以廣播方式發送給本網路中的所有主機,路由器則阻擋該分組通過,將其廣播功能限制在本網內部。
IPV6地址
IPv6地址為128位長但通常寫作8組每組四個十六進位數的形式。例如:
2001:0db8:85a3:08d3:1319:8a2e:0370:7344
是一個合法的IPv6地址。
IPv4地址可以很容易的轉化為IPv6格式。舉例來說,如果IPv4的一個地址為135.75.43.52(十六進位為0x874B2B34),它可以被轉化為0000:0000:0000:0000:0000:0000:874B:2B34或者::874B:2B34。同時,還可以使用混合符號(IPv4-compatible address),則地址可以為::135.75.43.52。
1.3.2埠
在網路技術中,埠(Port)包括邏輯埠和物理埠兩種類型。
物理埠指的是物理存在的埠,如ADSL Modem、集線器、交換機、路由器上用 於連接其他網路設備的介面,如RJ-45埠、SC埠等等。
邏輯埠是指邏輯意義上用於區分服務的埠,如TCP/IP協議中的服務埠,埠號的範圍從0到65535,比如用於瀏覽網頁服務的80埠,用於FTP服務的21埠等。由於物理埠和邏輯埠數量較多,為了對埠進行區分,將每個埠進行了編號,這就是埠號。
我們主要研究的是邏輯埠號.我們平時所說的埠號也是指的邏輯埠號
埠是一個軟體結構,被客戶程式或服務程式用來發送和接收數據,一台伺服器有 256*256個埠。 埠號範圍: 0 – 65535
0-1023是公認埠號,即已經公認定義或為將要公認定義的軟體保留的
1024-65535是並沒有公共定義的埠號,用戶可以自己定義這些埠的作用。
埠與協議有關:TCP和UDP的埠互不相干
二、TCP編程
什麼是 TCP 協議
TCP(Transmission Control Protocol 傳輸控制協議)是一種面向連接(連接導向)的、可靠的、基於IP的傳輸層協議。
彌補了IP協議的不足,屬於一種較高級的協議,它實現了數據包的有力捆綁,通過排序和重傳來確保數據傳輸的可靠(即數據的準確傳輸以及完整性)。
排序可以保證數據的讀取是按照正確的格式進行,重傳則保證了數據能夠準確傳送到目的地!
使用 TCP 協議通訊是, 首先創建 TCP 連接, 主動發起連接的叫客戶端, 被動響應連接的叫伺服器
比如:
當我們在瀏覽器中訪問新浪主頁時,我們自己的電腦就是客戶端,瀏覽器會主動向新浪的伺服器發起連接。如果一切順利,新浪的伺服器接受了我們的連接,一個TCP連接就建立起來的,後面的通訊就是發送網頁內容了。
2.1什麼是Socket
Socket又稱"套接字",應用程式通常通過"套接字"向網路發出請求或者應答網路請求,使主機間或者一台電腦上的進程間可以通訊。
可以把Socket理解成類似插座的東西, 通過Socket就可以發送和接受數據了, 就像插座插上電器之後就可以向外提供電能了.
TCP編程的客戶端和伺服器端都是通過Socket來完成的.
其實UDP協議通訊也是使用的套接字, 和TCP協議稍有差別. TCP是面向連接的套接字, 而UDP是面向無連接的套接字.
套接字的起源可以追溯到20世紀70年底, 他是加利福尼亞大學的伯克利版本 Unix(也成 BSD Unix) 的一部分. 因此, 有時你可能會聽過將套接字稱為伯克利套接字或 BSD 套接字.
套接字最初是為同一主機上的應用程式鎖創建, 使得主機上一個程式(也叫一個進程)與另一個允許的程式進行通訊. 這就是所謂的進程間通訊(Inter Process Communication IPC)
Socket families
有兩種類型的套接字: 基於文件的和面向對象的.
基於文件的套接字:AF_UNIX
AF_UNIX是基於文件的套接字.
因為兩個進程允許在同一台電腦上, 所以這些套接字都是基於文件的, 這意味著文件系統支援他們的底層基礎結構. 這是能夠說的通的, 因為文件系統是一個運行在同一主機上的多個進程之間的共享常量.
AF_UNIX在編程的時候並不是太常用.
基於網路的套接字:AF_INET
AF_INET用於基於網路的Socket. 還有一個地址家族AF_INET6, 用於IPv6.
其實還有一些其他地址家族, 哪些要麼是專業的, 過時的, 很少使用的, 要麼是仍未實現的.
在所有的地址家族中, AF_INET是使用最廣泛的.
因為本章重點討論網路編程, 所以本章剩餘的內容中, 都是將使用AF_INET
socket模組
要創建套接字, 必須使用socket模組下的socket()函數.
他的一般語法如下:
import socket socket.socket(socket_family, socket_type, protocal=0) 說明:
1, 其中, socket_family是AF_UNIX 或 AF_INET, Socket_type如果是TCP編程是SOCKET_STREAM, 如果是 UDP 編程則使用SOCKET_DGRAM. protocal通常省略, 默認是0
- 返回值就是
Socket對象.Socket對象提供了一些方法來讓我們操作這些套接字.
2.2 TCP 客戶端編程
客戶端程式碼參考下面的程式碼:
from socket import * host = "localhost" # 客戶端準備連接的伺服器的地址 port = 10000 # 伺服器的埠號 address = (host, port) # 伺服器的地址 bufSize = 1024 # 客戶端緩衝區的大小(單位位元組) tcpCliSock = socket(AF_INET, SOCK_STREAM) # 所有的套接字都使用 socket 函數來創建 tcpCliSock.connect(address) # 客戶端去連接伺服器 while True: data = input("> ") # 從鍵盤讀取數據 if not data: break # 給伺服器發送消息. 由於 send 只能發送位元組數據,所以把字元串編碼之後再發送 tcpCliSock.send(data.encode("utf-8")) data = tcpCliSock.recv(bufSize) # 接受伺服器發送來的資訊 if not data: break # 由於通過網路傳遞過來的其實是位元組數據, 解碼之後再輸出 print(data.decode("utf-8")) tcpCliSock.close() 2.3 TCP 伺服器編程
伺服器程式碼參考下面的程式碼:
from socket import * host = "localhost" # 伺服器要綁定的主機地址 port = 10000 # 伺服器要監聽的埠號 address = (host, port) bufSize = 1024 # 設置伺服器的緩衝區大小 tcpSevSock = socket(AF_INET, SOCK_STREAM) # 創建 socket 對象 tcpSevSock.bind(address) # 把 socket 綁定到指定的地址和埠 tcpSevSock.listen() # 開啟伺服器監聽器 print("正在等等客戶端連接...") tcpCliSock, cliAddress = tcpSevSock.accept() # 接受客戶端的連接 print("來自:", cliAddress, "的連接...") while True: data = tcpCliSock.recv(bufSize) # 接受客戶端發來的數據 if not data: break # 把接收到位元組數據解碼 data = data.decode("utf-8") # 向客戶端發送數據. 先把字元串編碼, 再發送 tcpCliSock.send(("我是...伺服器...你的資訊是:" + data).encode("utf-8")) tcpCliSock.close() # 關閉客戶端 tcpSevSock.close() # 關閉伺服器 2.4 運行伺服器和客戶端
執行 TCP 伺服器和客戶端
現在開始運行伺服器和客戶端程式, 看看他們是如何工作的.
那麼應該先運行客戶端還是伺服器呢?
當然是先運行伺服器, 讓伺服器先處於等等客戶端接入的狀態, 這樣在客戶端申請接入的時候才不會出錯.
其實, 伺服器是被動端, 客戶端是主動端.
三、UDP編程
UDP簡介
UDP也叫用戶數據報協議
UDP編程相比TCP編程簡單了很多.
因為UDP不是面向連接的, 而是面向無連接的.
TCP是面向連接的, 客戶端和服務端必須連接之後才能通訊, 就像打電話, 必須先接通才能通話.
UDP是面向無連接的, 一方負責發送數據(客戶端), 只要知道對方(接受數據:伺服器) 的地址就可以直接發數據了, 但是能不能達到就沒有辦法保證了.
雖然用UDP傳輸面向無連接, 數據不可靠,但它的優點是和TCP比,速度快,對於不要求可靠到達的數據,就可以使用UDP協議。 比如區域網的影片同步, 使用 udp 是比較合適的:快, 延遲越小越好
創建UDP的Socket對象
創建方式和TCP的Socket一樣的, 只是需要把socket_tpye的值設置為SOCKET_DGRAM
socket(AF_INET, SOCKET_DGRAM) 3.1 UDP客戶端編程
參考下面的程式碼:
from socket import * host = "localhost" # 對方地址 port = 20000 # 對方埠 address = (host, port) bufSize = 1024 udpCliSock = socket(AF_INET, SOCK_DGRAM) while True: data = input("> ") if not data: break # 把數據發送到指定的 udp 伺服器 udpCliSock.sendto(data.encode("utf-8"), address) udpCliSock.close() 3.2 UDP伺服器編程
UDP伺服器需要做的事情比較少, 除了等待傳入的連接之外, 幾乎不需要做其他工作.
參考下面的程式碼:
from socket import * host = "localhost" # 伺服器要綁定的地址 port = 20000 # 伺服器要綁定的埠 address = (host, port) bufSize = 1024 udpServeSock = socket(AF_INET, SOCK_DGRAM) udpServeSock.bind(address) while True: print("等待有人給我發資訊:") data, cliAddress = udpServeSock.recvfrom(bufSize) print(cliAddress, "發來的資訊是:", data.decode("utf-8")) udpServeSock.close() 3.3 運行UDP伺服器和客戶端
仍然需要先執行伺服器再執行客戶端.
四、socket模組其他屬性和函數
在socket模組中, 除了目前熟悉的socket.socket()函數之外, 還提供了更多用於網路應用開發的屬性.
| 屬性 | 描述 |
|---|---|
| AF_UNIX, AF_INET, AF_INET6, AF_NETLINK, AF_TIPC | python 中支援的套接字地址家族 |
| SOCK_STREAM, SOCK_DGRAM | 套接字類型(TCP=流, UDP=數據包) |
| has_ipv6 | 指示是否支援 IPv6的布爾標記 |
| 異常 | 描述 |
|---|---|
| error | 套接字相關錯誤 |
| haserror | 主機和地址相關錯誤 |
| gaierror | 地址相關錯誤 |
| timeout | 超時時間 |
| 函數 | 描述 |
|---|---|
| socket() | 創建套接字對象 |
| getaddrinfor() | 獲取一個五元組序列形式的地址資訊 |
| getnameinfo() | 給定一個套接字地址, 返回二元組(主機名, 埠號) |
| getfqdn() | 返回完整域名 |
| gethostname() | 返回當前主機名 |
| gethostbyname() | 將一個主機名, 映射到他的 ip 地址 |
| gethostbyname_ex() | gethostbyname()的擴展版本, 返回主機名, 別名主機集合和 ip 地址列表 |
五、python web 客戶端
TCP和UDP是比較低級的協議, 是底層網路通訊協議, 是當今網際網路中大部分客戶端/伺服器協議的核心.
大部分情況我們並不會直接使用TCP, UDP去編程, 而是使用更加高級的協議去編程.
比如 HTTP(超文本傳輸協議), FTP(文件傳輸協議)等.
本節內容主要學習使用 HTTP 去訪問互聯網中的內容.
所以我們先從 HTTP 協議開始講起, 他是目前互聯網上應用最廣泛的通訊協議.
5.1 HTTP 協議簡介
5.1.1 什麼是 HTTP 協議
HTTP協議是Hyper Text Transfer Protocol(超文本傳輸協議)的縮寫,是用於從萬維網(WWW:World Wide Web )伺服器傳輸超文本到本地瀏覽器的傳送協議。
HTTP 是基於 TCP/IP 協議的應用層協議。它不涉及數據包(packet)傳輸,主要規定了客戶端和伺服器之間的通訊格式,默認使用80埠。
5.1.2 HTTP 協議發展簡史
- 最早版本是1991年發布的0.9版。該版本極其簡單,只有一個命令GET。
- 1996年5月,HTTP/1.0 版本發布,內容大大增加。
任何格式的內容都可以發送。這使得互聯網不僅可以傳輸文字,還能傳輸影像、影片、二進位文件。這為互聯網的大發展奠定了基礎。 - 1997年1月,HTTP/1.1 版本發布,只比 1.0 版本晚了半年。它進一步完善了 HTTP 協議,一直用到了20年後的今天,直到現在還是最流行的版本。
5.1.3 HTTP 協議工作原理
HTTP協議工作於客戶端-服務端架構為上, 是一種請求應答式的.
瀏覽器(或其他客戶端)作為HTTP客戶端通過URL向HTTP服務端即WEB伺服器發送所有請求。Web伺服器根據接收到的請求後,向客戶端發送響應資訊。
5.1.4 HTTP協議格式
通訊規則規定了客戶端發送給伺服器的內容格式,也規定了伺服器發送給客戶端的內容格式。
客戶端發送給伺服器的格式叫「請求協議」;
伺服器發送給客戶端的格式叫「響應協議」。
重點學習這兩個格式。
5.1.5 請求協議格式
請求行 例:GET /images/logo.gif HTTP/1.1,表示從/images目錄下請求logo.gif文件。 請求頭 例:Accept-Language: en(很多請求頭) 空行 必須的,服務通過這個空行來區別出請求頭和請求體 請求體 有時候也叫消息體,是可選的,get請求時無請求體,post請求會有。 瀏覽器向伺服器發送請求時必須依據該格式,否則伺服器無法識別。http協議中的請求行中可以有8種請求方法,但是目前為止,通用和大家都在用的只有兩種:post請求和get請求。
5.1.6 響應協議格式
狀態行; 響應頭資訊; 空行; 響應體(響應正文)。 5.1.7 GET 請求和 POST 請求的區別
注意區別就是請求數據的傳送方式:
1.GET 方法
查詢字元串(名稱/值對)是在 GET 請求的 URL 中發送的:
/test/demo_form.asp?name1=value1&name2=value2 2.POST 方法
請求數據(名稱/值對)是在 POST 請求的 HTTP 消息主體中發送的:
POST /test/demo_form.asp HTTP/1.1 Host: w3schools.com name1=value1&name2=value2 比較
| 項目 | GET | POST |
|---|---|---|
| 後退按鈕/刷新 | 無害 | 數據會被重新提交(瀏覽器應該告知用戶數據會被重新提交)。 |
| 書籤 | 可收藏為書籤 | 不可收藏為書籤 |
| 快取 | 能被快取 | 不能快取 |
| 編碼類型 | application/x-www-form-urlencoded | application/x-www-form-urlencoded 或 multipart/form-data。為二進位數據使用多重編碼。 |
| 歷史 | 參數保留在瀏覽器歷史中。 | 參數不會保存在瀏覽器歷史中。 |
| 對數據長度的限制 | 是的。當發送數據時,GET 方法向 URL 添加數據;URL 的長度是受限制的(URL 的最大長度是 2048 個字元)。 | 無限制。 |
| 對數據類型的限制 | 只允許 ASCII 字元。 | 沒有限制。也允許二進位數據。 |
| 安全性 | 與 POST 相比,GET 的安全性較差,因為所發送的數據是 URL 的一部分。在發送密碼或其他敏感資訊時絕不要使用 GET ! | POST 比 GET 更安全,因為參數不會被保存在瀏覽器歷史或 web 伺服器日誌中。 |
| 可見性 | 數據在 URL 中對所有人都是可見的。 | 數據不會顯示在 URL 中。 |
5.2 URL
前面我們用瀏覽器使用 HTTP 協議去訪問網路。 但是有一點大家需要記住, 瀏覽器只是 web 客戶端的一種。
- 可以這麼說, 任何一個向 web 伺服器發送求來獲得應用程式的都是客戶端。
- 瀏覽器作為一個比較特別的客戶端,主要用於瀏覽網頁內容並同其他 web 站點交互。
- 而一個更普通的客戶端可以完成更多的工作,不僅可以下載數據, 還可以存儲、操作數據, 甚至可以將其傳送到另外一個地方或者傳給另外一個應用。
python 提供的 urllib 模組, 使用它, 就可以編寫可以下載或或者訪問互聯網上資訊的簡單 web 客戶端。
你首先需要做的就是為程式提供一個有效的 web 網址, 這個 web 網站就是一個URL。
我們先了解URL是什麼?
5.2.1 URL
URL 是Uniform Resource Locator的縮寫, 中文叫:統一資源定位符。
瀏覽網頁需要 URL, 這個 URL 就表示這個網頁的地址。 這個地址用來在 web 上定位定位一個文檔。
如街道地址一樣, URL 地址也有一些結構。URL 使用如下的這種格式:
prot_sch://net_loc/path;params?query#frag
| URL組件 | 描述 |
|---|---|
| pro_sch | 網路協議, 如:http, https |
| net_loc | 伺服器所在地 |
| path | 使用/分割的路徑 |
| params | 可選參數 |
| ? | 可選, 表示後面是查詢參數 |
| query | 可選, 用連接符(&)分割的一系列鍵值對, 如: user=lisi&pwd=aaa |
| #frag | 可選, 指定文檔內特點錨的部分 |
5.3 urllib包和parse模組
urllib是一個package, 這個package包含了幾個模組, 這幾個模組都是使用url來工作.
urllib.request模組, 用於打開和讀取urlurllib.error模組, 包含了urllib.request拋出的一些異常.urllib.parse模組, 解析urlurllib.robotparser模組, 解析robots.txt文件
5.3.1 urllib包
在python2中的模組urllib, urlparse, urllib2, 以及其他內容都整合在了urllib單一包中.
urllib和urllib2的內容整合在了urllib.request模組中urlparse的內容整合在了urllib.parse模組中urllib包還包括其他模組如:response, error, robotparse, 後面再學習.
python支援兩種不同的模組來處理url, 一個是parse, 另一個是request.
兩種模組的功能不一樣, 下面會分別介紹兩個模組.
5.3.2 parse模組
parse是包urllib下的模組, 只是用來處理url這個字元串本身, 而不負責使用這個url去聯網獲取資源.
parse主要提供了三個功能: urlparse(), urlunparse(), urljoin()
1. parse.urlparse()
urlparse()用來將url字元串解析成我們前面說的那些組件.
語法:
urlparse(urlstr, defProSch='', allowFrag=True) **說明:
**
- 參數1就是
url字元串. 返回值一個ParseResult類型的數據 defProSch默認網路協議.allowFrag表示url中是否允許使用片段.
from urllib.parse import * o = urlparse('http://www.cwi.nl:80/%7Eguido/Python.html') print(o) 結果:
ParseResult(scheme='http', netloc='www.cwi.nl:80', path='/%7Eguido/Python.html', params='', query='', fragment='') 2. parse.urlunparse()
是把各個部分組合成url字元串.
from urllib.parse import * o = urlparse('http://www.cwi.nl:80/%7Eguido/Python.html') urlstr = urlunparse(o) print(urlstr) 3. parse.urljoin()
urljoin()實現了url的連接功能.
urljoin(base, new_url, allow_fragments=True) 說明:
取得base的根路徑(不包括路徑中末端的文件), 然後與new_url連接起來.
from urllib.parse import * newUrl = urljoin('http://www.cwi.nl/abc/Python.html', 'FAQ.html') print(newUrl) 5.4 request模組
urllib.request模組提供了許多函數, 可用於從指定URL載入數據, 同時也可以對字元串進行編碼解碼工作, 以便再URL中以正確的形式顯示出來.
request.urlopen()
urlopen(url, data=None[, timeout])
說明:
- 該函數, 打開指定的url並返回類文件對象, 可使用該對象讀取返回的數據.
- 對所有HTTP請求, 最常用的是
GET請求, 向伺服器發送的請求參數應該是url的一部分. 注意使用到的參數應該是已經經過url編碼的(使用parse.urlencode()編碼). - 如果是
post請求, 請求的字元串(包括表單數據)應該放在第二個參數data中.
from urllib.request import * with urlopen("http://www.yztcedu.com") as r: print(r) urlopen()的返回值類文件對象
一旦連接成功, urlopen()會返還一個類文件對象, 就像在目標路徑下打開了一個可讀文件。
| urlopne()類文件對象方法 | 描述 |
|---|---|
| f.read([bytes]) | 從文件中讀取所有或bytes個位元組 |
| f.readline() | 從f中讀取一行 |
| f.readlines() | 從f中讀取所有行, 作為列表返回 |
| f.close() | 關閉f的url連接 |
| f.fileno() | 返回f的文件句柄 |
| f.info() | 返回f的mime頭文件 |
| f.geturl() | 返回f的真正url |
from urllib.request import * with urlopen("http://www.yztcedu.com") as r: for line in r.readlines(): print(line.decode("utf-8")) 

