IBN-Net: 提升模型的域自適應性
- 2020 年 4 月 8 日
- 筆記
本文解讀內容是IBN-Net, 筆者最初是在很多行人重識別的庫中頻繁遇到比如ResNet-ibn這樣的模型,所以產生了閱讀並研究這篇文章的興趣,文章全稱是: 《Two at Once: Enhancing Learning and Generalization Capacities via IBN-Net》。IBN-Net和SENet非常相似:
- 可以方便地集成到現有網路模型中。
- 在多個視覺任務中有著出色的表現,如分類、分割。
- 拿到了比賽第一名,IBN-Net拿到了 WAD 2018 Challenge Drivable Area track ,一個分割比賽的第一名。SENet拿到了最後一屆ImageNet比賽的冠軍。
1. 概述
IBN-Net出發點是:提升模型對影像外觀變化的適應性。在訓練數據和測試數據有較大的外觀差異的時候,模型的性能會顯著下降,這就是不同域之間的gap。比如訓練數據中的目標光線強烈,測試數據中的目標光線昏暗,這樣一般效果都不是很好。
之前有一個群友就是在研究一個域的數據如何遷移到另外一個分布不一致的域中的問題,當時認為在機器學習中訓練的數據和測試數據的分布應該儘可能一致,這樣才符合要求。但是實際應用中不可避免遇到訓練數據無法將所有情況下(色調變化,明暗變化 )的數據都收集到,所以如何提升模型對影像外觀變化的適應性、如何提高模型在不同域之間的泛化能力也是一個非常值得研究的課題。
IBN-Net能夠有效提升模型在一個域中的效果(比如cityscapes-真實場景的數據),同時可以做到不fine-tuning就可以泛化到另外一個域中(比如GTA5-非真實場景的數據)。
文章主要有三個貢獻:
- 通過深入IN和BN,發現IN對目標的外觀變化具有不變性,比如光照、顏色、風格、虛擬和現實,BN可以保存內容相關的資訊。
- IBN-Net可以應用到現有的STOA網路架構中,比如DenseNet, ResNet, ResNeXt, SENet等網路中,可以再不增加模型計算代價的情況下,有效提升模型的效果。
- IBN-Net域適應能力非常強,在cityscape數據集訓練的模型,不需要再GTA5上fine-tuning就可以有比較可觀的效果。


2. 方法
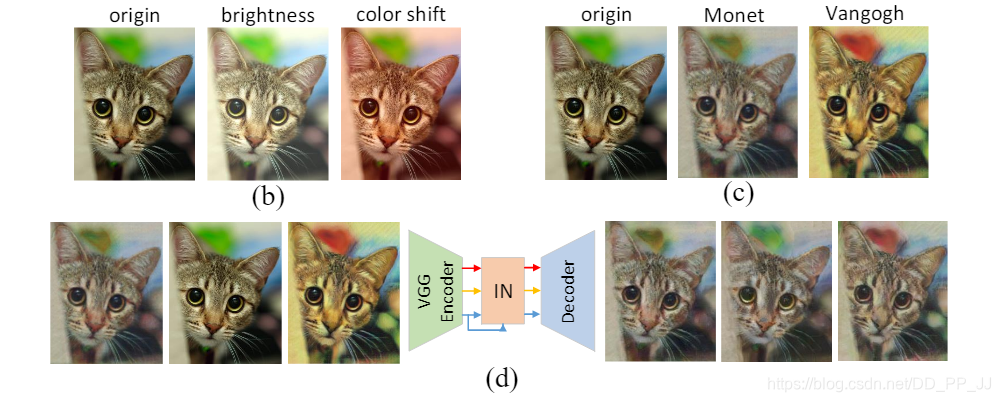 (b) 圖是對原圖進行亮度調整和色彩平移(c)圖是對原圖使用了兩種風格化方法 (d)圖是對(c)圖使用Instance Norm以後的結果,這說明IN可以過濾掉複雜的外觀差異。
(b) 圖是對原圖進行亮度調整和色彩平移(c)圖是對原圖使用了兩種風格化方法 (d)圖是對(c)圖使用Instance Norm以後的結果,這說明IN可以過濾掉複雜的外觀差異。
通常IN用於處理底層視覺任務,比如影像風格化,而BN用於處理高層視覺任務,比如目標檢測,影像識別等。IBN-Net首次將BN和IN集成起來,同時提高了模型的學習能力和泛化能力。
此外,IBN-Net設計原則是:
- 在網路的淺層同時使用IN和BN
- 在網路的深層僅僅使用BN
作者做了一個實驗,下圖展示了隨著網路深度的變化,特徵差異的變化情況: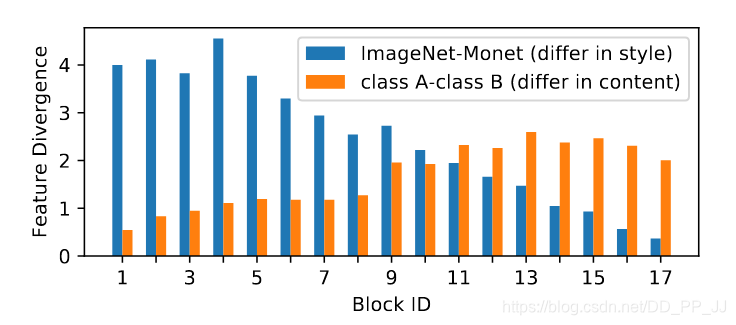
藍色代表外觀差異帶來的特徵差異,橙色代表圖片內容之間的特徵差異。可以看出在淺層是由外觀差異帶來的特徵差異,這部分可以使用BN和IN聯合起來解決;在深層網路,外觀差異帶來的特徵差異已經非常小了,內容之間的差異是主導地位,所以這部分使用BN來解決。
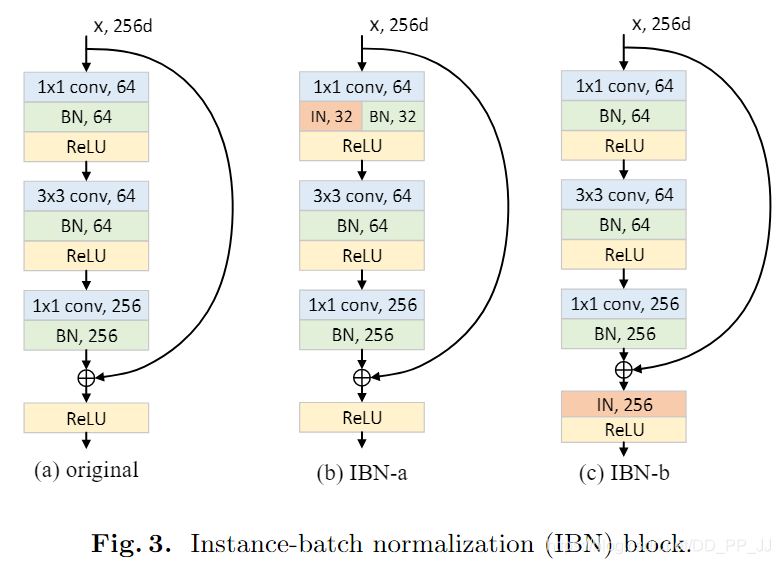
這部分是論文的核心,作者提出了兩個結合BN和IN的模組,IBN-a和IBN-b。(a)圖其實是ResNet中的一個殘差模組,(b)和(c)圖都是在此基礎上融入了IN和BN
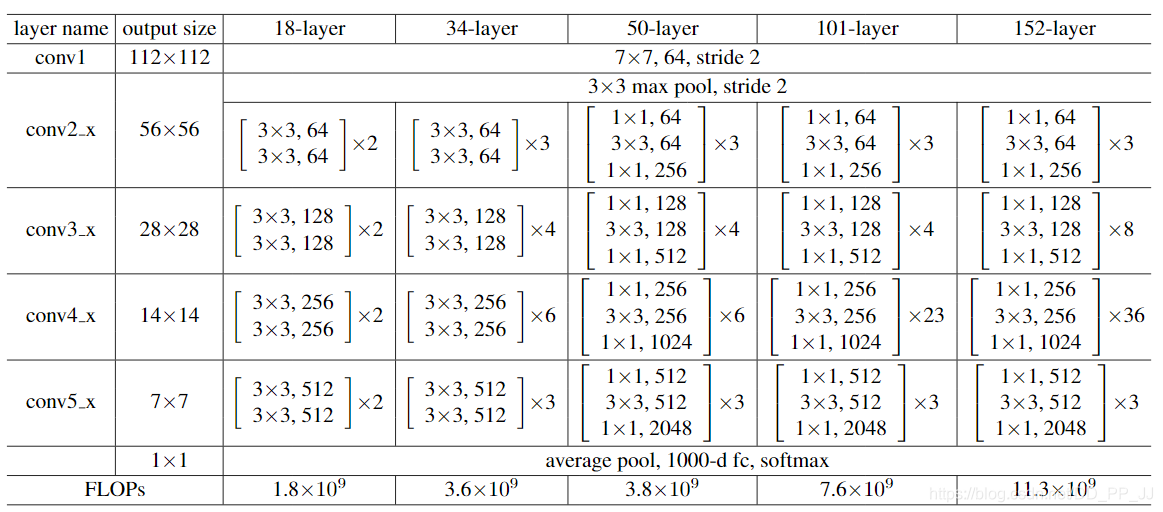
- 具體哪個算淺層哪個算深層?
ResNet由4組殘差塊組成,在IBN-Net的改進中,僅僅在Conv2_x, Conv3_x, Conv4_x三個塊中加入IN,Conv5_x不進行改動。
- IBN-a的改動理由:
第一,在ResNet論文中說明了恆等映射路徑的必要性,所以IN應該添加在殘差路徑上。
第二,殘差網路可以用以下公式來表達:
其中的(F(x,{W_i}))是為了能夠得到與恆等映射路徑對齊的特徵,所以IN被添加在殘差模組中第一個卷積以後,而不是最後一個卷積以後,這樣可以防止特徵出現不對齊的問題。
第三,根據之前提到的設計原則,淺層應當同時使用BN和IN,所以選擇將一半通道通過BN計算,另一半通道通過IN進行計算。
- IBN-b的改動理由:
為了更充分地利用IN來提高模型的泛化的能力,對IBN-a進行了改進。作者認為目標的表觀資訊將保留在殘差路徑或者恆等映射路徑上,所以可以考慮將IN直接添加在加法之後。同時需要說明的是和IBN-a不同,IBN-b使用的範圍是(Conv2_x和Conv3_x)
除了上述兩種BN和IN結合方法,作者還探索出更多變體,如下圖所示:
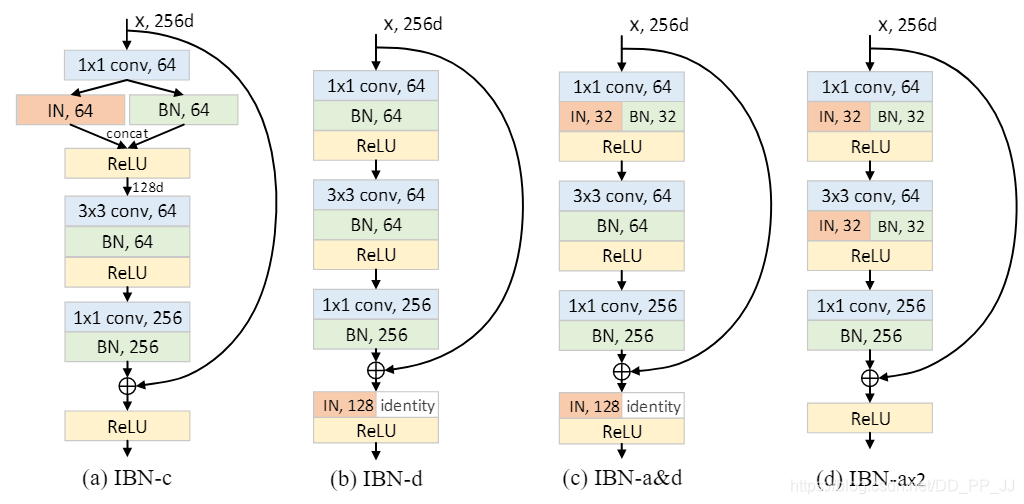
(a)圖中,IBN-c的做法是將IN和BN分成兩路,然後將得到的特徵進行concate。
(b)圖中,IBN-d的做法是在IBN-b基礎上進行了改動,對其中一半通道的feature map施加IN。
(c)圖中,IBN-a&d的做法很顯然結合了IBN-a和IBN-d
(d)圖中,IBN-ax2在IBN-a基礎上,多增加了一對BN和IN,用於測試添加更多BN和IN是否能夠提升模型泛化能力。
IBN-a和IBN-b程式碼:
這部分程式碼來自: https://github.com/pprp/reid_for_deepsort
IBN-a:
class IBN(nn.Module): def __init__(self, planes): super(IBN, self).__init__() half1 = int(planes / 2) self.half = half1 half2 = planes - half1 self.IN = nn.InstanceNorm2d(half1, affine=True) self.BN = nn.BatchNorm2d(half2) def forward(self, x): split = torch.split(x, self.half, 1) out1 = self.IN(split[0].contiguous()) out2 = self.BN(split[1].contiguous()) out = torch.cat((out1, out2), 1) return out IBN-b:
class Bottleneck(nn.Module): expansion = 4 def __init__(self, inplanes, planes, stride=1, downsample=None, IN=False): super(Bottleneck, self).__init__() self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False) self.bn1 = nn.BatchNorm2d(planes) self.conv2 = nn.Conv2d( planes, planes, kernel_size=3, stride=stride, padding=1, bias=False ) self.bn2 = nn.BatchNorm2d(planes) self.conv3 = nn.Conv2d( planes, planes * self.expansion, kernel_size=1, bias=False ) self.bn3 = nn.BatchNorm2d(planes * self.expansion) self.IN = None if IN: self.IN = nn.InstanceNorm2d(planes * 4, affine=True) self.relu = nn.ReLU(inplace=True) self.downsample = downsample self.stride = stride def forward(self, x): residual = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out = self.relu(out) out = self.conv3(out) out = self.bn3(out) if self.downsample is not None: residual = self.downsample(x) out += residual if self.IN is not None: out = self.IN(out) out = self.relu(out) return out 3. 實驗
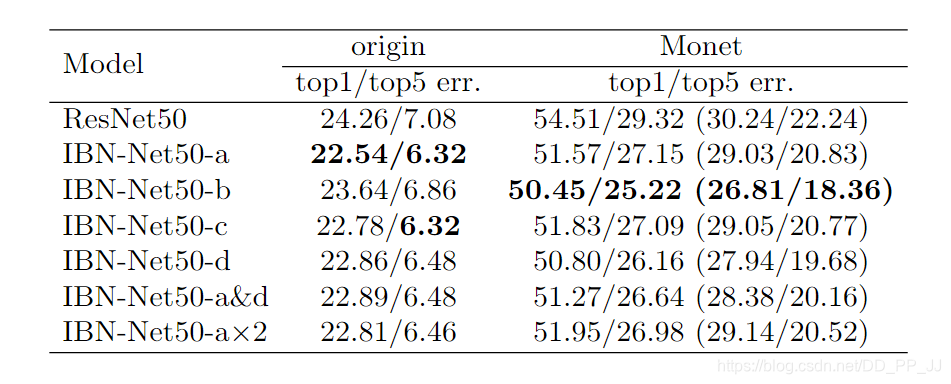
可以看到,IBN-a可以提升在原先域(訓練數據)內的泛化能力,比原來ResNet50要高1-2個百分點。IBN-b可以提升在目標域(訓練數據中未出現的數據)的泛化能力,可以看到要比ResNet50提高4個百分點。
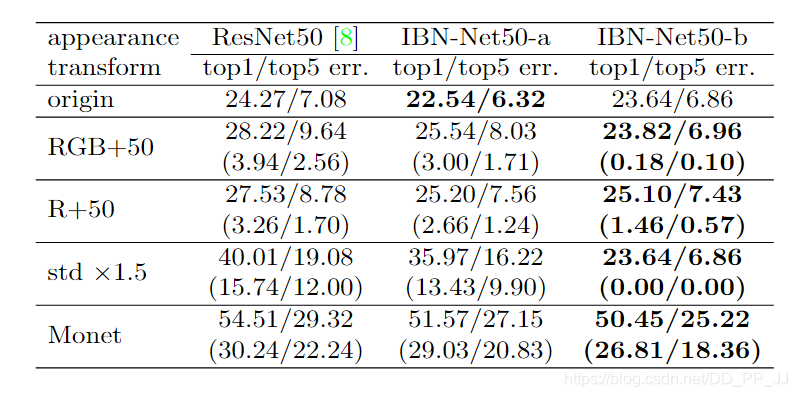
上圖是採用了不同的外觀轉換比如RGB直接+50,R+50等方法,可以發現,依然遵從上一條發現,IBN-a可以提升原有域的泛化能力,IBN-b可以提升目標域的泛化能力,可以看到除了Monet風格化對IBN-b影響稍大,其他幾種影響非常之小。

可以看到,IBN-a最好是施加在前三個block中,效果最好。
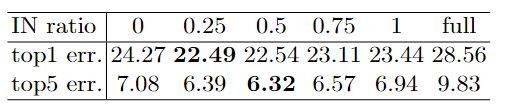
這個比例是IN/BN, 可以看出IN/BN=0.25的時候top1 最好,IN/BN=0.5的時候top5最好,一般默認還是設置為0.5.
以上是分類問題,再來看看分割問題,cityscape數據集和GTA5數據集上的結果如下:
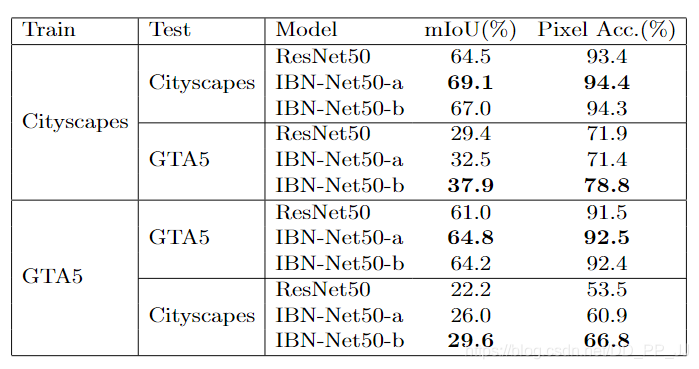
可以看到,訓練集和測試集來自同一個數據的時候,IBN-a模型的mIoU是能夠比原模型ResNet50高4個百分點。而訓練集和測試集不同的時候,IBN-b模型更佔優勢,說明IBN-b能夠在跨域的問題上表現更好。
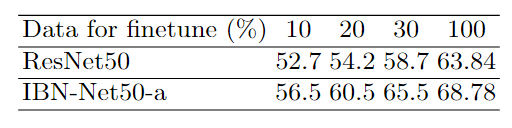
上圖的實驗還可以證明IBN-a和ResNet50同時在目標域進行fine tuning, IBN-a微調的效果要遠遠好於ResNet50。
4. 總結
IBN-Net中有幾個重要結論,在總結部分梳理一下:
-
IBN-Net在淺層同時使用IN和BN,深層網路僅僅使用BN。
-
IBN-Net中有兩個出色的模型IBN-a和IBN-b,IBN-a適用於當前域和目標域一致的問題,比如說提升ResNet50的分類能力,可以用IBN-a,並且IBN-a微調以後結果是比原模型結果更好的。
-
IBN-b適合使用在當前域和目標域不一致的問題,比如說在行人重識別中,訓練數據是在白天收集的,但是想在黃昏的時候使用的時候。這也是為何IBN-Net在行人重識別領域用的非常多的原因。
-
cityscape和GTA5這個實驗非常有說服力,證明了IBN-Net的泛化能力,效果提升非常明顯,在分割問題上對模型帶來的提升效果更大。
5. 參考
https://arxiv.org/pdf/1512.03385
https://arxiv.org/pdf/1807.09441
https://github.com/XingangPan/IBN-Net
https://github.com/pprp/reid_for_deepsort/tree/master/models