一款基於SVM演算法的分散式法律助手
- 2020 年 4 月 8 日
- 筆記
一. 項目簡介 與 使用說明
體驗網站(適配手機端): http://www.zhuchangwu.com
項目基於 Spring Cloud 、Vue 構建,平台針對需要維權的用戶而設計,主要提供如下三個功能模組。
-
一、提供問答服務模組。
用戶可以在本模組中描述一句簡短的話,系統將為用戶推送出與用戶描述相似的問題及答案。
-
二、罪名推斷模組。
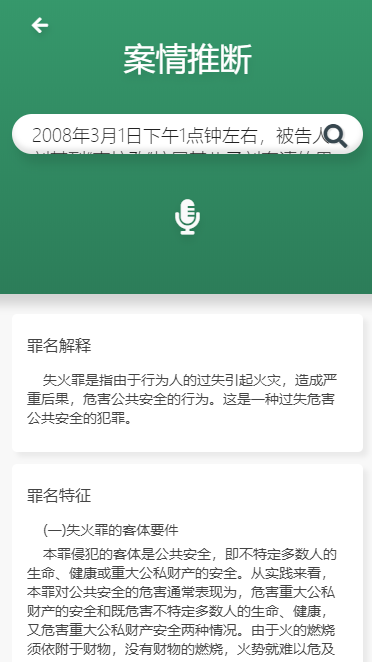
用戶可以輸入一個場景,系統將給用戶推送出此場景可能觸發的罪名,量刑區間,以及可能觸發的法律法規。
-
三、相似判決文書查詢模組。
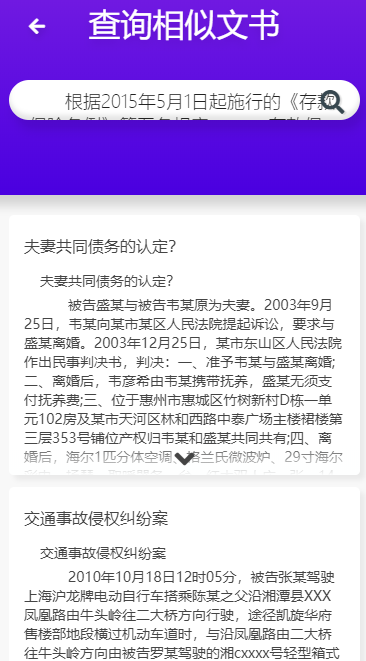
用戶可以將自己的判決文書輸入到系統中,系統將會為用戶推送相似的判決文書。
主頁
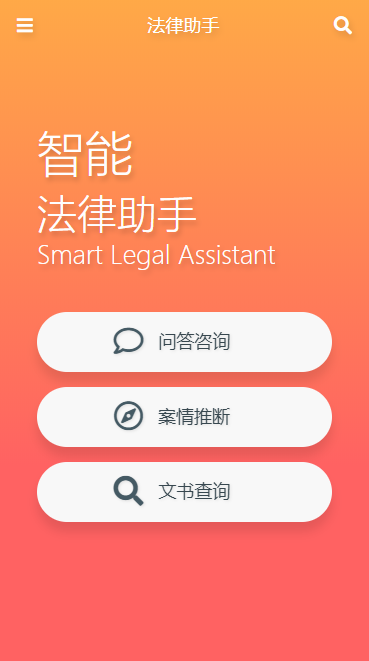
問答服務 – 支援前綴匹配,全文檢索
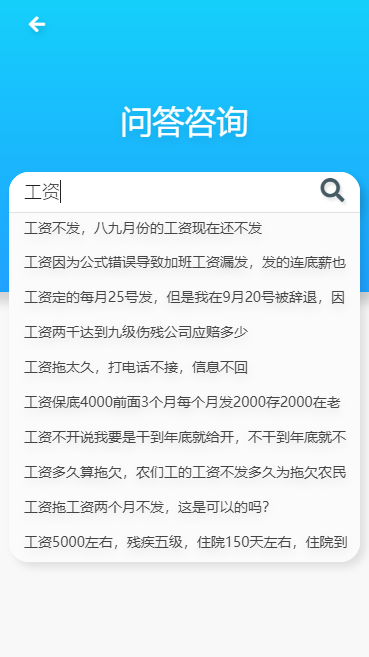
罪名推斷:
點擊主頁的案情推斷,輸入一段場景
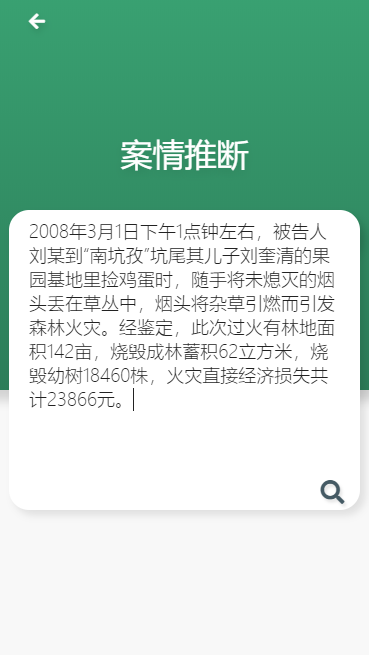
點擊搜索:得出如下響應
相似文書查詢:
將您的文書拷貝進文書查詢模組,點擊搜索,系統將推送給您往年相似的判決文書

結果如下:
二. 主要技術點
- 前後端分離架構,前端Vue + 後端SpringCloud。
- 基於 ElasticSearch 的搜索提示及全文檢索功能為用戶提供問答服務。
- 集成機器學習分類演算法模型 SVM, 文本分類,推斷相關罪名。
- 基於simhash演算法,實現相似文本檢查。
- Java 與 Python 使用Apache Thrift完成異構RPC調用。
- 使用Docker將SVM模型容器化,可移植性很強。
- 項目部署:靜態資源伺服器 Nginx。
三. 環境搭建
3.1 後端
- 後端SpringCloud版本:Finchley.SR2
- 開發工具: IDEA
- Maven版本: 3.3.9
同學們自行將本項目clone到本地導入idea即可使用。
3.2 前端
前端github地址: https://github.com/zhuchangwu/lawyer-lover-vue-frontend
nodejs版本: v10.14.1
安裝命令:
npm install serve 前端程式碼精簡,如果感興趣可以拉取下來自行開發
鳴謝: 前端貢獻者 ‘集智慧與美貌於一身’的:CamWang
3.3 SVM演算法-Docker鏡像
推薦: 使用我封裝好的SVM演算法模型的Docker鏡像,目前已經打包發布在雲上, 優點如下:
- 基於Docker構建,可移植性很好,同學們可以直接拉取到自己伺服器的Docker上,開箱即用。
- 添加了ApacheThrift 依賴,將演算法模型封裝成了 Thrift – Server ,實現了和 Java-SpringCloud 的非同步RPC通訊。
如何拉取鏡像:
### 1. 啟動docker ### 2. 拉取鏡像 sudo docker pull registry.cn-beijing.aliyuncs.com/changwu/lawyer:release 使用鏡像
# 1. 啟動鏡像: docker run --name [指定容器名] -i -t -p 9998:9998 -d [ImageId] # 2. 進入容器: docker container exec -it [指定的容器名或者容器的ID] /bin/bash # 3. 啟動模型: docker run # 4. 切入目錄 cd /home/lawer # 5. 使用tmux使py在後台運行 , 在bash輸入如下命令 tmux # 6. 進入tmux,在tmux中啟動程式 ,模型需要載入大約30s完成啟動,在控制台可以看到啟動日誌 python thrift_server.py # 7. 模型啟動後,可以退出鏡像 `exit` 或者直接關閉ssh終端, 模型都會正常運行 # 8. 重新ssh上去之後,執行如下命令,可以看到python程式還在正常執行 tmux attach 鳴謝:liuhuanyong教授: 演算法模型來源
3.4 Nginx相關配置
同學們在上線當前項目時推薦使用Nginx伺服器代理靜態資源 。
當前項目使用Nginx做了如下幾點工作,同學們自行可以參照提供的配置項做適當修改。
- Nginx代理Vue打包生成的靜態資源。
- 解決前段端的跨域配置。
- 將用戶在前端請求轉發到後端SpringCloud網關。
nginx相關配置文件路徑: /reources/nginx-conf 。
四. ElasticSearch相關
4.1 版本:
推薦使用 6.2.4
因為我針對法律主題,做了的分詞器訂製化( 拓展了詞庫 ), 下文有提及。
至於ES的安裝本文不再展開了,同學們可以自行百度安裝。
4.2 創建Index:實體類->Index
- 問答模組index的建立腳本
PUT /ai_answer_question { "mappings": { "answer_question" : { "properties" : { "title" : { "type": "text", "analyzer": "ik_max_word", "fields": { // 添加搜索推薦 suggest "suggest" : { "type" : "completion", // 特定的類型 "analyzer": "ik_max_word" // 指定分詞器 } } }, "content": { "type": "text", "analyzer": "ik_max_word" } } } } } 另外兩個模組的測試類像下面這樣寫測試類,通過Template無腦創建就行
@RunWith(SpringRunner.class) @SpringBootTest public class CrimeTest { @Autowired ElasticsearchTemplate template; @Autowired CrimeRepository repository; @Test public void deleteIndex(){ template.deleteIndex(Crime.class); } @Test public void testCreateIndexAndMapping() { template.createIndex(Crime.class); template.putMapping(Crime.class); } } 4.3 Ik分詞器
推薦我提供的IK分詞器: 路徑: /resource/ik
原因:
- 拓展中文詞庫。
- 加入了法律相關的專有名詞,提高專業名詞的得分率和召回率。
-
加入了停用詞(問候詞)
- 這麼設計的初衷是考慮到項目中的搜索提供功能, 比如用戶輸入了 房產XXX ,那麼我們將為其進行搜索並提示他有哪些以用戶輸入關鍵字開頭的詞條。
- 如果用戶僅僅是輸入了: 你好,請問 這類詞語將被ES過濾掉,而不理會。
- 如果你覺得不合理,可以去ik/conf中修改相關配置。
五. 數據
下面三個模組的數據挺大的, 就不上傳到github了,同學搭建項目時如果需要如下三個模組的測試數據 , 可以掃描下面二維碼關注,回復:data 領取後,自行導入ES即可。
-
相似文書模組依賴的數據:
-
罪名推斷模組依賴的數據:
-
問答模組依賴的數據:
導入罪名模組測試的方法
@Test public void add() { File file = new File("F:\新建文件夾\crime.json"); try { Set<Crime> set = new TreeSet<Crime>(new Comparator<Crime>() { @Override public int compare(Crime o1, Crime o2) { //字元串,則按照asicc碼升序排列 return o1.getCrimeName().compareTo(o2.getCrimeName()); } }); BufferedReader bufferedReader = new BufferedReader(new FileReader(file)); String result = null; while (((result = bufferedReader.readLine()) != null)) { Crime crime = JsonUtils.jsonToPojo(result, Crime.class); set.add(crime); } System.out.println(set.size()); for (Crime crime : set) { repository.save(crime); } } catch (Exception e) { e.printStackTrace(); } } 六. 聯繫
可以通過部落格聯繫我:
https://www.cnblogs.com/ZhuChangwu/
歡迎關注微信公眾號領取數據,(公共號剛起步,後續會分享整理的面試題) :