AI學習筆記:特徵工程
- 2020 年 4 月 7 日
- 筆記

一、概述
-
Andrew Ng:Coming up with features is difficult, time-consuming, requires expert knowledge. 「Applied machine learning」 is basically feature engineering( 吳恩達, 人工智慧和機器學習領域國際最權威學者之一:提取特徵是困難的,耗時的,需要豐富的專家知識。「應用機器學習」從根本上來說就是特徵工程)
-
業界廣泛流傳:數據和特徵決定了機器學習的上限, 而模型和演算法只是逼近這個上限而已。
-
特徵工程:Feature Engineering,指使用專業背景知識和技巧進行數據處理,使得特徵能夠在機器學習演算法上發揮更好的作用。特徵工程在機器學習中佔有相當重要的地位。在實際應用當中,可以說特徵工程是機器學習成功的關鍵。
特徵工程主要包含三部分內容
- 特徵提取:包含字典特徵提取、文檔特徵提取、影像特徵提取(深度學習)等
- 特徵預處理:對數據進行無量綱化處理:標準化、歸一化等。無量綱化方法有很多,但是從幾何角度來說可以分為:直線型、折線型、曲線形無量綱化方法。
- 特徵降維:包含特徵選擇,PCI(主要內容分析)、PCA(線性判別分析法),PCA( 主成分分析法)等
二、數據的基本描述
2.1 定義
- 數據:data,指事實或觀察的結果,是對客觀事物的邏輯歸納,是用於表示客觀事物的未經加工的原始素材。
- 屬性:attribute,是一個數據欄位,表述數據對象的一個特徵。
- 特徵向量:用來描述一個給定對象的一組屬性。
2.2 數據的基本屬性:
包括標稱屬性、二元屬性、序數屬性、數值屬性、連續/離散屬性等等。
- 標稱屬性:一些符號或事物的名稱,每種值代表某種類別、編碼或狀態。比如顏色、職業等。標稱值不具有有意義的順序,且不是定量的。
- 二元屬性:布爾屬性,比如0/1、true/false。通常1表示對結果重要的 。
- 序數屬性:具有意義的順序或排序等級,但是相繼值之間的差是未知的。比如size(大、中、小), 客戶價值(高、中、低) 。序數也可能是通過將數值量的值域劃分有限個有序類別,把數值屬性離散化後得到的。
- 數值屬性:略
- 離散/連續屬性:機器學習的分類演算法通常把屬性分成離散的或連續的,每種類型都可以用不同的方法處理。離散屬性具有有限或無限個值 如果屬性不離散,則它是連續的。在實際應用中,連續屬性一般用浮點(float)變數表示 。 補充說明:標稱、二元和序數屬性都是定性的,不是定量的,即它們能夠描述對象的特徵,而不能給出實際大小或數量。
三、數據型特徵處理
3.1 歸一化
歸一化可以使不同維度的數據在點乘和核函數計算相似性時擁有統一的標準, 數學上就是把每整個向量轉化為「單位向量」。
常用的方法:
-
min-max標準化(Min-Max Normalization)
 公式解釋:(當前數據-最小數據)/(最大值-最小值)。 不難發現,x1每列的值都在[0,1]之間,也就是說,該模組是按列計算的。並且MinMaxScaler在構造類對象的時候也可以直接指定最大最小值的範圍:scaler = MinMaxScaler(feature_range=(min, max)).
公式解釋:(當前數據-最小數據)/(最大值-最小值)。 不難發現,x1每列的值都在[0,1]之間,也就是說,該模組是按列計算的。並且MinMaxScaler在構造類對象的時候也可以直接指定最大最小值的範圍:scaler = MinMaxScaler(feature_range=(min, max)). -
Z-score標準化方法
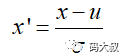 公式解釋:(原始數據-樣本均值)/樣本標準差。 可以看出,z-score標準化方法試圖將原始數據集標準化成均值為0,方差為1且接近於標準正態分布的數據集。然而,一旦原始數據的分布 不 接近於一般正態分布,則標準化的效果會不好。該方法比較適合數據量大的場景(即樣本足夠多,現在都流行大數據,因此可以比較放心地用)。此外,相對於min-max歸一化方法,該方法不僅能夠去除量綱,還能夠把所有維度的變數一視同仁(因為每個維度都服從均值為0、方差1的正態分布),在最後計算距離時各個維度數據發揮了相同的作用,避免了不同量綱的選取對距離計算產生的巨大影響。所以,涉及到計算點與點之間的距離,如利用距離度量來計算相似度、PCA、LDA,聚類分析等,並且數據量大(近似正態分布),可考慮該方法。相反地,如果想保留原始數據中由標準差所反映的潛在權重關係應該選擇min-max歸一化。
公式解釋:(原始數據-樣本均值)/樣本標準差。 可以看出,z-score標準化方法試圖將原始數據集標準化成均值為0,方差為1且接近於標準正態分布的數據集。然而,一旦原始數據的分布 不 接近於一般正態分布,則標準化的效果會不好。該方法比較適合數據量大的場景(即樣本足夠多,現在都流行大數據,因此可以比較放心地用)。此外,相對於min-max歸一化方法,該方法不僅能夠去除量綱,還能夠把所有維度的變數一視同仁(因為每個維度都服從均值為0、方差1的正態分布),在最後計算距離時各個維度數據發揮了相同的作用,避免了不同量綱的選取對距離計算產生的巨大影響。所以,涉及到計算點與點之間的距離,如利用距離度量來計算相似度、PCA、LDA,聚類分析等,並且數據量大(近似正態分布),可考慮該方法。相反地,如果想保留原始數據中由標準差所反映的潛在權重關係應該選擇min-max歸一化。
3.2 離散化
有些場合,比如廣告點擊率預測, 最適合用線性分類器來分類預測, 但是採集到的Y和X是非線性的關係, 因此需要對X做離散化, 使離散化後的單值X變成一個向量, 進一步訓練這個向量和Y之間的線性模型。離散化有利於分類模型的訓練。 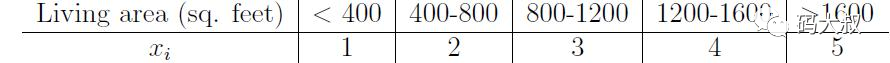
四、類別型特徵處理
別特徵特徵指的是能在有限範圍內取值的特徵,如性別(男,女),血型(A,B,O,AB)等。類別特徵的輸入往往是原始的字元串,因此除了例如決策樹等少數能直接處理字元串形式輸入的模型,其他模型往往需要將類別特徵處理成數值型才能正常處理。幾種常見的類別特徵處理方法:
4.1、序號編碼(Ordinal Encoding)
序號編碼通常用於處理類別具有大小或順序關係的數據,例如成績可以分為「高」,「中」,「低」,且「高>中>低」,因此可以相應的轉換成3,2,1。
4.2、獨熱編碼(One-hot Encoding)
One-hot 編碼通常用於處理類別不具有大小關係的類別特徵,最常見的用法是NLP中對詞庫中單詞的編碼。例如對於血型(A,B,O,AB),對應的One-hot編碼可以表示為((1000),(0100),(0010),(0001))。但是使用One-hot編碼需要注意以下問題:
- 使用稀疏向量節省空間。對於範圍特別大的常見,例如字典,生產的one-hot編碼非常稀疏,因此需要節省存儲空間。
- 配合特徵選擇來降低特徵維度。同樣是為了解決高維情況下的存儲問題。
4.3、二進位編碼(Binary Encoding)
二進位編碼主要分為兩步,先用序號編碼給每個類別賦予一個唯一的ID,然後將該ID對應的二進位編碼作為結果。同樣以血型(A,B,O,AB)為例,其對應的序號編碼為(1,2,3,4),那麼其對應的二進位棉麻可以表示為(001,010,011,100)。相比較One-hot編碼,在高維特徵的情況下,能節省大量的存儲空間。
五、日期型特徵處理
問題:比如日期時間 (比如2014-09-20 20:45:40), 如何轉化成有用的特徵?
-
場景1:如果你想知道某一天的時間段跟其它屬性的關係, 你可以創建一個數字特徵「Hour_Of_Day」來幫你建立一個回歸模型, 或者你可以建立一個序數特徵, 「Part_Of_Day」,取值「Morning,Midday,Afternoon,Night」來關聯你的數據。
-
場景2:研究一個商場的銷售額, 時間可以抽取出季節、 月份、 一年第幾周等作為新的特徵, 進而進行模型訓練。
-
場景3:研究星期幾對交通壓力的影響, 可以採取One-hot方法變成7個變數, 每個代表1天, 周一為(0,1,0,0,0,0,0),周三為(0,0,0,1,0,0,0)等,再進行模型訓練。
常見處理方式:
- 時間本身的特徵:將時間變數作為類別變數處理
- 時間變數之間的組合特徵:根據兩個或多個時間變數的含義,進行特徵組合
- 時間序列相關特徵:滯後特徵、滑動窗口統計特徵
六、文本型特徵處理
問題:垃圾郵件檢測時, 如何建立特徵?
採用Word2vector方法, 或者TF-IDF的方法, 將所有郵件中出現的單詞按詞頻從高到低排序, 再取前m個(比如5000) 單詞叫做詞袋, 再將每個郵件中出現的在詞袋中的單詞次數累計為相應向量位置的數字, 這樣對每個郵件都構造了一個m維的一個向量, 作為這個郵件的特徵。處理過程中一些技巧比如去掉stopword 如英文的「a」, 「the」 漢語「的」, 「這」, 「是」之類的詞。
常用方式如下:
- 詞袋法(BOW/TF)
- TF-IDF(Term frequency-inverse document frequency)
- HashTF4、Word2Vec(主要用於單詞的相似性考量)
七、組合特徵分析
比如進行自動疾病診斷時, 有些疾病帶有一些併發症, 或者有幾個典型的特徵, 如果可以組合成這樣的一個典型的發病癥狀組合特徵, 對疾病的診斷會更有把握。
比如:評價一個人在網路課程中的積極性指標,可通過資料完善度、社區活躍度、作業完成率、考核得分率等等方面。
八、基於權重的特徵選取
自變數和目標變數之間的關聯, 通過分析特徵子集內部的特點來衡量其好壞, 然後選擇排名靠前的特徵, 比如前10%, 或前10個, 或者相關係數大於預設閾值, 從而達到特徵選擇目的。
本質:篩選器, 側重於單個特性
評價函數: Pearson相關係數、Gini-index 基尼係數、IG 資訊增益, 互資訊、卡方檢驗、Distance Metrics距離度量
優點:計算時間上較為高效, 對於過擬合問題具有高的魯棒性。
缺點:傾向於選擇冗餘的特徵;因為不考慮特徵之間的相關性, 導致雖然某一個特徵分類能力很差, 但是和其他特徵組合起來效果不錯, 這樣的特徵被篩選掉了(多重共線性) 。
九、自動特徵學習
很多演算法工程也在思考,能不能通過模型的方式來自動的學習和構成特徵呢?"所有的想法都會有實現的一天",現在市面上有效的特徵構造模型有 深度學習(提取訓練好的模型中隱層作為特徵)可以自己學習出一些特徵以及特徵之間的組合關係。主題模型 LDA、word2vec來作為特徵生成的模型,將模型訓練的中間結果,比如 LDA 的主題分布、word2vec 生成的詞向量用於LR 這樣的線性模型,線上測試效果都非常好。
從場景目標出發,去找出與之有關的因素。但是在實際場景除了天馬行空想特徵之外,還需要對於想出來的特徵做一可行性評估:獲取難度、覆蓋度、準確度等,比如笛卡爾積會使得特徵維度增加的非常快,會出現大量覆蓋度低的特徵,如果把這些覆蓋度低的特徵加入到模型中訓練,模型會非常不穩定;然而這一系列的工作就是傳說中的特徵工程比如卷積神經網路。
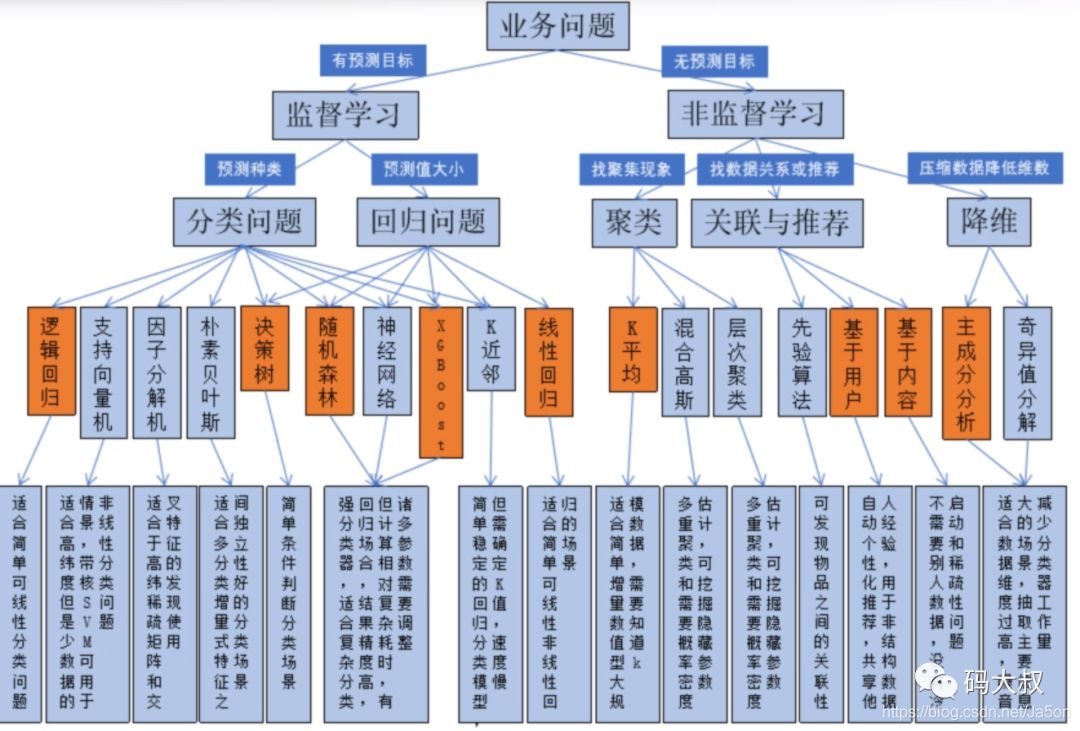
十、演算法選擇導圖
說明:
本文大部分內容來自星環科技AI工程師公開培訓影片,版權歸星環科技所有。大家也可以直接去觀看影片,老師講的更為詳細。 B站直播地址:https://live.bilibili.com/21878856,免費噢(星環科技最近不定時有很多大數據、雲計算、人工智慧相關的分享) AI講師:孫國庫 星環科技AI架構師&金牌講師
其他參考資料: https://www.jianshu.com/p/7066558bd386 https://www.cnblogs.com/ftl1012/p/10498480.html https://blog.csdn.net/onthewaygogoing/article/details/79871559
推薦閱讀: AI學習筆記(一):人工智慧與機器學習概述 從千萬級數據查詢來聊一聊索引結構和資料庫原理 讀Hadoop3.2源碼,深入了解java調用HDFS的常用操作和HDFS原理 我成功攻擊了Tomcat伺服器,大佬們的反應亮了 原創 史上最強的Java堆內快取框架,不接受反駁(附源碼)
微信公眾號:「碼大叔」,架構師,十年戎「碼」,老「叔」開花,我們一起學習交流! 


