集合和映射(Set And Map)
- 2020 年 4 月 5 日
- 筆記
集合 Set
Set是一種新的數據結構,類似於數組,但是不能添加重複的元素,基於Set集合的這個特性,我們可以使用Set集合進行客戶統計和辭彙統計等,集合中常用的方法如下:
public interface Set<E> { void add(E e); //添加元素e,不能添加重複元素 boolean contains(E e); //當前集合中是否包含元素e void remove(E e); //刪除元素e int getSize(); //獲取當前集合中元素的個數 boolean isEmpty(); //判斷當前集合是否為空 } 基於二分搜索樹實現集合
現在讓我們基於我們上章實現的二分搜索樹,來實現集合中的常用操作,若你對二分搜索樹還不了解,你可以先看我的上一篇文章:二分搜索樹(Binary Search Tree)進行學習,基於二分搜索樹實現的集合程式碼實現如下:
public class BSTSet<E extends Comparable<E>> implements Set<E> { //基於二分搜索樹實現集合 private BST<E> bst; public BSTSet(){ bst = new BST<E>(); } //直接調用bst的添加方法 @Override public void add(E e) { bst.add(e); } @Override public boolean contains(E e) { return bst.contains(e); } @Override public void remove(E e) { bst.removeElement(e); } @Override public int getSize() { return bst.getSize(); } @Override public boolean isEmpty() { return bst.isEmpty(); } } 現在讓我們使用該集合實現對詞數的統計,我們可以寫一個簡單的測試類,來實現分別對《傲慢與偏見》和《雙城記》這兩本書中不同單詞的統計,這兩本書英文版的下載鏈接:https://files.cnblogs.com/files/reminis/test-text.zip , 在使用我們的集合類進行詞數統計之前,我們需要先寫一個讀取文件的工具類,該文件操作工具類可以實現讀取文件中的內容,並將其中包含的所有詞語放進words中,具體實現程式碼如下:
import java.io.FileInputStream; import java.util.ArrayList; import java.util.Scanner; import java.util.Locale; import java.io.File; import java.io.BufferedInputStream; import java.io.IOException; // 文件相關操作 public class FileOperation { // 讀取文件名稱為filename中的內容,並將其中包含的所有詞語放進words中 public static boolean readFile(String filename, List<String> words){ if (filename == null || words == null){ System.out.println("filename is null or words is null"); return false; } // 文件讀取 Scanner scanner; try { File file = new File(filename); if(file.exists()){ FileInputStream fis = new FileInputStream(file); scanner = new Scanner(new BufferedInputStream(fis), "UTF-8"); scanner.useLocale(Locale.ENGLISH); } else return false; } catch(IOException ioe){ System.out.println("Cannot open " + filename); return false; } // 簡單分詞 // 這個分詞方式相對簡陋, 沒有考慮很多文本處理中的特殊問題 // 在這裡只做demo展示用 if (scanner.hasNextLine()) { String contents = scanner.useDelimiter("\A").next(); int start = firstCharacterIndex(contents, 0); for (int i = start + 1; i <= contents.length(); ) if (i == contents.length() || !Character.isLetter(contents.charAt(i))) { String word = contents.substring(start, i).toLowerCase(); words.add(word); start = firstCharacterIndex(contents, i); i = start + 1; } else i++; } return true; } // 尋找字元串s中,從start的位置開始的第一個字母字元的位置 private static int firstCharacterIndex(String s, int start){ for( int i = start ; i < s.length() ; i ++ ) if( Character.isLetter(s.charAt(i)) ) return i; return s.length(); } } 大家如果不是很懂上面文件類中的程式碼,可以先直接拷貝在自己的項目中,直接進行使用就行了,因為本文主要是講的集合,關於文件操作的知識不會涉及太多,下面讓我們使用集合來進行詞樹統計操作,測試程式碼如下:
public static void main(String[] args) { System.out.println("Pride and Prejudice"); List<String> words1 = new ArrayList<String>(); //注意自己文件的路徑的問題 if(FileOperation.readFile("pride-and-prejudice.txt", words1)) { //輸出《傲慢與偏見》這本書中的總詞數 System.out.println("Total words: " + words1.size()); BSTSet<String> set1 = new BSTSet<String>(); for (String word : words1) { //將《傲慢與偏見》這本書中的所有單詞加如我們的基於二分搜索樹實現的集合中 set1.add(word); } //輸出《傲慢與偏見》這本書中去重後的總詞數 System.out.println("Total different words: " + set1.getSize()); } System.out.println(); //測試《雙城記》這本書 System.out.println("A Tale of Two Cities"); List<String> words2 = new ArrayList<String>(); //注意自己文件路徑的問題 if(FileOperation.readFile("a-tale-of-two-cities.txt", words2)){ System.out.println("Total words: " + words2.size()); BSTSet<String> set2 = new BSTSet<String>(); for(String word: words2) set2.add(word); System.out.println("Total different words: " + set2.getSize()); } } 測試程式碼的運行結果如下:
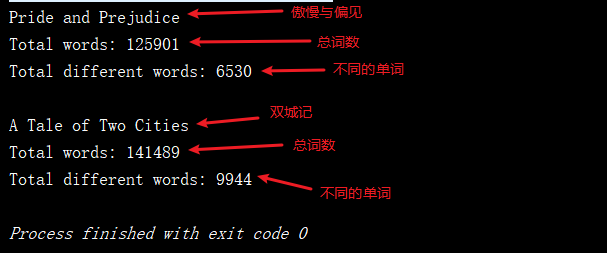
注意:在本次測試中,只是進行簡單的分詞,對單詞的不同形式未進行處理(例如同一個單詞的不同時態是作為不同的單詞在進行處理)。
基於鏈表實現集合
由於我們在常見的線性結構中講過鏈表,為了與基於二分搜索實現的集合進行對比,我們也可以基於鏈表來實現集合,也順便複習一下鏈表的相關操作,基於鏈表實現集合的具體程式碼如下:
public class LinkedListSet<E> implements Set<E> { //基於鏈表實現 private LinkedList<E> linkedList; public LinkedListSet(){ linkedList = new LinkedList<E>(); } //由於鏈表中的添加操作是可以添加重複元素的 //所以這裡向集合中添加元素時,需要先判斷集合中是否有該元素 @Override public void add(E e) { if ( !linkedList.contains(e)) linkedList.addFirst(e); } @Override public boolean contains(E e) { return linkedList.contains(e); } @Override public void remove(E e) { linkedList.removeElement(e); } @Override public int getSize() { return linkedList.getSize(); } @Override public boolean isEmpty() { return linkedList.isEmpty(); } } 現在我們再來使用基於鏈表實現的集合來進行詞數統計操作,與上面的測試程式碼一樣,只不過將BSTSet改為LinkedListSet,如下:
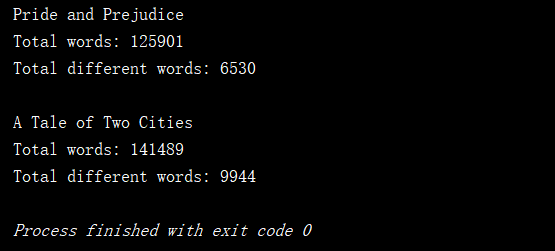
public static void main(String[] args) { System.out.println("Pride and Prejudice"); List<String> words1 = new ArrayList<String>(); if(FileOperation.readFile("pride-and-prejudice.txt", words1)) { System.out.println("Total words: " + words1.size()); LinkedListSet<String> set1 = new LinkedListSet<String>(); for (String word : words1) set1.add(word); System.out.println("Total different words: " + set1.getSize()); } System.out.println(); System.out.println("A Tale of Two Cities"); ArrayList<String> words2 = new ArrayList<String>(); if(FileOperation.readFile("a-tale-of-two-cities.txt", words2)){ System.out.println("Total words: " + words2.size()); LinkedListSet<String> set2 = new LinkedListSet<String>(); for(String word: words2) set2.add(word); System.out.println("Total different words: " + set2.getSize()); } } 最後通過我們的測試結果可以看出,運行結果是相同的
集合的時間複雜度分析
現在先讓我們使用基於二分搜索數實現的集合與基於鏈表實現的集合,都對《傲慢與偏見》這本書進行詞數統計,讓我們對比一下運行所需要花費的時間,測試如下:
/** * 該集合對指定文件進行添加操作所需要花費的時間 * @param set 集合 * @param filename 文件名 * @return */ private static double testSet(Set<String> set, String filename){ long startTime = System.nanoTime(); System.out.println(filename); List<String> words = new ArrayList<String>(); if(FileOperation.readFile(filename, words)) { System.out.println("Total words: " + words.size()); for (String word : words) set.add(word); System.out.println("Total different words: " + set.getSize()); } long endTime = System.nanoTime(); //將納秒轉為秒 return (endTime - startTime) / 1000000000.0; } public static void main(String[] args) { String filename = "pride-and-prejudice.txt"; Set<String> bstSet = new BSTSet<String>(); //基於二分搜索樹實現的集合進行測試 double time1 = testSet(bstSet, filename); System.out.println("BST Set: " + time1 + " s"); System.out.println(); Set<String> linkedListSet = new LinkedListSet<String>(); //基於鏈表實現的集合進行測試 double time2 = testSet(linkedListSet, filename); System.out.println("Linked List Set: " + time2 + " s"); } 測試程式碼運行結果如下:
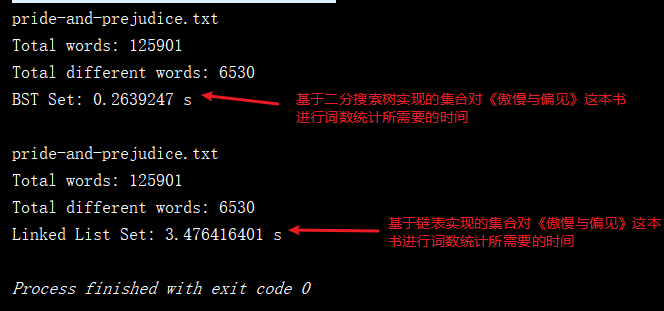
從運行結果可以看出,兩種不同的實現性能上的差異是非常大的,現在就讓我們來對比下二者的時間複雜度:
| LinkedListSet | BSTSet | |
|---|---|---|
| 增 add | O(n) | O(h) |
| 查 contains | O(n) | O(h) |
| 刪 remove | O(n) | O(h) |
這裡的n是指節點的個數,鏈表的add()方法的時間複雜度是O(1)級別的,為什麼這裡LinkedListSet的時間複雜度為O(n)呢,因為Set集合中不允許添加重複的元素,所以在基於鏈表實現的集合中,我們每次添加元素時都會先遍歷這個鏈表,看這個鏈表中是否有這個元素,沒有才進行添加,這就讓我們的LinkedListSet添加一個元素所需要的時間與鏈表中節點的個數n呈線性關係,即時間複雜度為O(n)級別的。而基於二分搜索樹實現的集合,增刪查的時間複雜度都為O(h),這裡的h是指樹的高度,即BSTSet的這些操作都只和這棵二分搜索樹的高度相關。但我們的時間複雜度是研究的和節點個數n的關係,所以下面讓我們來看一下二分搜索樹的高度h和節點個數n之間的關係。
特殊情況:當我們的二分搜索樹為滿二叉樹時,來進行分析二分搜索樹的高度和節點個數之間的關係。滿二叉樹就是除了葉子節點外,其他每個節點的左孩子和右孩子都不為空。一棵滿的二叉樹並且是二分搜索樹如下圖:
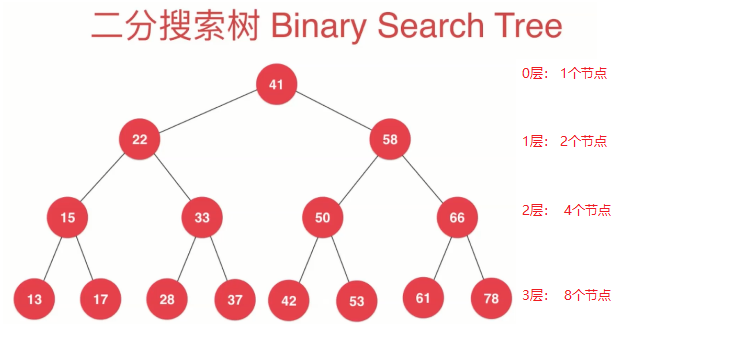
我們可以從圖中發現高度和節點個數有如下關係:
| 層數 | 節點個數 | 關係 |
|---|---|---|
| 0層 | 1個節點 | 20 |
| 1層 | 2個節點 | 21 |
| 2層 | 4個節點 | 22 |
| 3層 | 8個節點 | 23 |
| 4層 | 16個節點 | 24 |
| … | … | … |
| h-1層 | 2(h-1) | 2(h-1) |
所以在h層,一共有多少個節點呢?相信大家都已經學過高中數學的等比數列,我們通過我們推導出的通項公式,可以知道這是一個以2為底,以2為公比的等比數列,所以在第h層的節點個數推導如下:
所以二分搜索數高度h和節點個數n的關係是:(h=log_2(n+1)),所以二分搜索樹的複雜為:(O(h)=O(log_2 n)=O(log n))
下面我們看一下O(log n)複雜度和O(n)複雜度之間的差距(這裡就把log的底看為2進行對比):
| 節點個數 | log n | n | 執行時間差別 |
|---|---|---|---|
| n=16 | 4 | 16 | 相差4倍 |
| n=1024 | 10 | 1024 | 相差100倍 |
| n=100萬 | 20 | 100萬 | 相差5萬倍 |
由上面的對比我們可以看出,時間複雜度為O(log n)的程式運行時間要比時間複雜度為O(n)的程式快很多,特別是在進行大數據量處理時,差別效果是很明顯的。這也是為什麼基於二分搜索樹實現的集合要比基於鏈表實現的集合在執行相同操作時用時更少了。
注意:上面我們是根據二分搜索樹是滿二叉樹的情況下推導出來的時間複雜度為O(logn),但當我們向二分搜索樹中按順序添加這些數據時,二分搜索樹就會退化成一個鏈表,這時我們的二分搜索樹的時間複雜度就為log(n)了,因為此時數的高度就為鏈表的長度了,即等於鏈表中節點的個數。

所以兩種實現的集合的時間複雜度分析如下:
| LinkedListSet | BSTSet | 平均 | 最差 | |
|---|---|---|---|---|
| 增 add | O(n) | O(h) | O(logn) | O(n) |
| 查 contains | O(n) | O(h) | O(logn) | O(n) |
| 刪 remove | O(n) | O(h) | O(logn) | O(n) |
下面讓我們來通過leetcode上的804號練習題關於唯一摩爾斯密碼詞問題,來對集合這種數據結構進行運用:
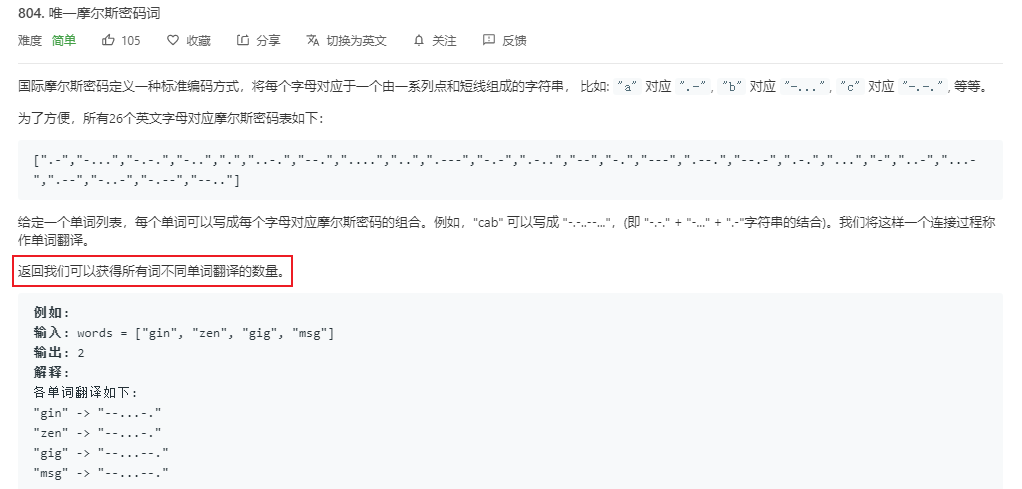
上面是關於804號問題描述的部分截圖,建議大家去看leetcode官網上看該問題的完整要求,現在就讓我們來使用基於二分搜索樹實現的集合來解決該問題:
public int uniqueMorseRepresentations(String[] words) { //a~z的摩斯密碼 String[] codes = {".-","-...","-.-.","-..",".","..-.","--.","....","..",".---","-.-",".-..","--","-.","---",".--.","--.-",".-.","...","-","..-","...-",".--","-..-","-.--","--.."}; BSTSet<String> set = new BSTSet<String>(); for(String word: words){ StringBuilder res = new StringBuilder(); for(int i = 0 ; i < word.length() ; i ++){ //因為題目描述中每個單詞 words[i]只包含小寫字母 //我們需要減去a對應ASCII碼的偏移量,就可以獲的對應字元的摩斯密碼 res.append(codes[word.charAt(i) - 'a']); } //因為set集合中不能添加重複元素,所以我們的集合中不會有重複的單詞 set.add(res.toString()); } return set.getSize(); } 你也可以使用我們上面基於鏈表實現的集合,當你使用基於我們自己實現的集合,提交程式碼到leetcode上時,你需要把我們自己實現的集合作為私有類一起提交到leetcode上,不然會報錯,當然你也可以使用Java類庫中的TreeSet來解決這個問題。
映射 Map
Map是一種用來存儲(鍵,值)數據對的數據結構(key,value);根據鍵(key)尋找值(value),非常容易使用鏈表或者二分搜索樹來實現,當然Map中的key是不允許重複的。Map介面中常用的操作如下:
/** * 定義Map介面,由於Map是用來存儲數據對的數據結構,所以定義時需要兩個泛型 * @param <K> 鍵的類型使用泛型代替 * @param <V> 值的類型使用泛型代替 */ public interface Map<K, V> { //添加一個數據對 void add(K key, V value); //根據鍵來刪除這個數據對,並且返回刪除的值 V remove(K key); //查找這個map中是否包含key boolean contains(K key); //通過鍵查找這個數據對的值 V get(K key); //修改 void set(K key, V newValue); //獲取當前映射中數據對的個數 int getSize(); //判斷當前映射是否為空 boolean isEmpty(); } 基於鏈表實現映射
我們在之前實現的鏈表中的節點,只包含一個數據E,由於這裡Map是存儲的一個數據對,所以我們我們鏈表中的節點需要存儲兩個數據,分別是key和value。具體程式碼實現如下:
public class LinkedListMap<K,V> implements Map<K,V> { //定義鏈表的節點 private class Node{ //存儲Map的鍵值對 public K key; public V value; //指向像下一個節點 public Node next; //鏈表節點的有參構造 public Node(K key, V value, Node next) { this.key = key; this.value = value; this.next = next; } //當用戶在創建節點時,上傳了key和value的初始值 public Node(K key, V value){ this(key, value, null); } //鏈表節點的無參構造 public Node(){ this(null, null, null); } //鍵和值的輸出格式為: key:value @Override public String toString(){ return key.toString() + " : " + value.toString(); } } //虛擬頭節點(不存儲數據) private Node dummyHead; private int size; //Map的無參構造 public LinkedListMap(){ dummyHead = new Node(); size = 0; } @Override public int getSize() { return size; } @Override public boolean isEmpty() { return size==0; } //根據key所在的節點,Map中的key是唯一的 private Node getNode(K key){ Node cur = dummyHead.next; while (cur != null){ if (cur.key.equals(key)){ return cur; } cur = cur.next; } return null; } @Override public boolean contains(K key) { //若根據key找到了對應的節點,則該Map中含有該鍵 return getNode(key) != null; } @Override public V get(K key) { Node node = getNode(key); return node == null ? null : node.value; } @Override public void add(K key, V value) { //添加之前,先查找該映射中key是否已經存在了 Node node = getNode(key); if (node == null){ dummyHead.next = new Node(key,value,dummyHead.next); size ++; }else { //如果該節點已存在,則覆蓋值 node.value =value; } } @Override public void set(K key, V newValue) { Node node = getNode(key); //在進行修改操作時,如果該節點不存在,則拋出異常 if(node == null) throw new IllegalArgumentException(key + " doesn't exist!"); node.value = newValue; } @Override public V remove(K key) { Node prev = dummyHead; while (prev.next != null){ if (prev.next.key.equals(key)){ break; } prev = prev.next; } //prev.next 就是需要刪除的節點 if (prev.next != null){ Node delNode = prev.next; prev.next = delNode.next; delNode.next = null; size --; return delNode.value; } return null; } } 現在我們可以來簡單測試一下我們使用鏈表實現的映射是否正確,測試用例還是和前面測試集合一樣,來對《傲慢與偏見》這本書進行測試,這本書的文本下載鏈接在前面已經寫出來了,現在就進行測試吧
public static void main(String[] args){ System.out.println("Pride and Prejudice"); List<String> words = new ArrayList<String>(); if(FileOperation.readFile("pride-and-prejudice.txt", words)) { //《傲慢與偏見》這本書的總詞數 System.out.println("Total words: " + words.size()); //讓我們的映射中存儲key,value分別表示單詞和這個單詞出現的次數 Map<String, Integer> map = new LinkedListMap<String,Integer>(); for (String word : words) { //如果當前應次數已經存在這個單詞(鍵)了,就讓我們對這個次數進行加一 if (map.contains(word)){ map.set(word, map.get(word) + 1); } else { //如果該單詞是第一次出現,頻次就設置為一 map.add(word, 1); } } //輸出《傲慢與偏見》這本書不同單詞的總數 System.out.println("Total different words: " + map.getSize()); //輸出這本書中出「pride」這個單詞的次數 System.out.println("Frequency of PRIDE: " + map.get("pride")); //輸出這本書中出「prejudice」這個單詞的次數 System.out.println("Frequency of PREJUDICE: " + map.get("prejudice")); } System.out.println(); } 上面測試程式碼的運行結果如下:

說明:測試程式碼中文件操作類在對集合進行測試時,已經寫出來了,這裡的文件操作類是同一個類,直接使用即可。
基於二分搜索樹實現映射
若你對二分搜索樹的相關操作實現還不了解,建議你在看我的上篇部落格二分搜索樹後,在進行向下閱讀,因為下面我實現的BSTMap是基於我之前寫的二分搜索樹來進行實現的,之前我們樹節點中只存儲了一個數據,現在我們需要同時存儲鍵和值這種數據對,所以我們需要對樹的節點做一些調整,具體實現如下:
/** * 前面我們說過二分搜索樹中元素必須具有可比較性,所以這裡讓Map的鍵實現Comparable介面 * @param <K> * @param <V> */ public class BSTMap<K extends Comparable<K>,V> implements Map<K,V> { //二分搜索樹的節點 private class Node{ public K key; public V value; //左孩子和右孩子節點 public Node left,right; public Node(K key, V value) { this.key = key; this.value = value; this.left = null; this.right = null; } } //根節點 private Node root; private int size; //Map的無參構造 public BSTMap() { this.root = null; this.size = 0; } @Override public int getSize() { return size; } @Override public boolean isEmpty() { return size == 0; } @Override public void add(K key, V value) { // 向二分搜索樹中添加新的元素(key, value) root = add(root,key,value); } // 向以node為根的二分搜索樹中插入元素(key, value),遞歸演算法 // 返回插入新節點後二分搜索樹的根 private Node add(Node node, K key, V value) { if (node == null){ size ++; return new Node(key,value); } if (key.compareTo(node.key) < 0){ node.left = add(node.left,key,value); }else if (key.compareTo(node.key) > 0){ node.right = add(node.right,key,value); }else { // key.compareTo(node.key) == 0 node.value = value; } return node; } // 返回以node為根節點的二分搜索樹中,key所在的節點 public Node getNode(Node node,K key){ if (node == null) return null; if (key.equals(node.key)){ return node; } else if (key.compareTo(node.key) < 0) { return getNode(node.left,key); }else { //key.compareTo(node.key) > 0 return getNode(node.right,key); } } @Override public boolean contains(K key) { return getNode(root,key) != null; } @Override public V get(K key) { Node node = getNode(root, key); return node == null ? null : node.value; } @Override public void set(K key, V newValue) { Node node = getNode(root, key); if(node == null) throw new IllegalArgumentException(key + " doesn't exist!"); node.value = newValue; } @Override public V remove(K key) { Node node = getNode(root, key); if (node != null){ root = remove(root,key); return root.value; } return null; } private Node remove(Node node, K key) { if (node == null){ return null; } if (key.compareTo(node.key) <0 ){ node.left = remove(node.left,key); return node; }else if (key.compareTo(node.key) > 0){ node.right = remove(node.right,key); return node; }else { // key.compareTo(node.key) == 0 // 待刪除節點左子樹為空的情況 if (node.left == null){ Node rightNode = node.right; node.right = null; size -- ; return rightNode; } //待刪除節點右子樹為空的情況 if (node.right == null){ Node leftNode = node.left; node.left = null; size -- ; return leftNode; } // 待刪除節點左右子樹均不為空的情況 // 找到比待刪除節點大的最小節點, 即待刪除節點右子樹的最小節點 // 用這個節點頂替待刪除節點的位置 Node successor = minNum(node.right); successor.right = removeMin(node.right); successor.left = node.left; node.left = node.right = null; return successor; } } // 刪除掉以node為根的二分搜索樹中的最小節點 // 返回刪除節點後新的二分搜索樹的根 private Node removeMin(Node node) { if (node.left == null){ Node rightNode = node.right; node.right = null; size -- ; return rightNode; } node.left = removeMin(node.left); return node; } // 返回以node為根的二分搜索樹的最小值所在的節點 private Node minNum(Node node) { if (node.left == null){ return node; } return minNum(node.left); } } 現在來對我們基於二分搜索樹實現的映射進行測試,測試程式碼與基於鏈表實現的映射的測試程式碼相同,如下:
public static void main(String[] args){ System.out.println("Pride and Prejudice"); List<String> words = new ArrayList<String>(); if(FileOperation.readFile("pride-and-prejudice.txt", words)) { System.out.println("Total words: " + words.size()); BSTMap<String, Integer> map = new BSTMap<String,Integer>(); for (String word : words) { if (map.contains(word)) map.set(word, map.get(word) + 1); else map.add(word, 1); } System.out.println("Total different words: " + map.getSize()); System.out.println("Frequency of PRIDE: " + map.get("pride")); System.out.println("Frequency of PREJUDICE: " + map.get("prejudice")); } System.out.println(); } 基於二分搜索樹實現的映射的測試結果如下:
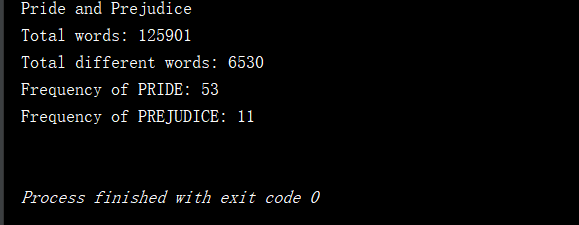
我們可以看到該測試結果和基於鏈表實現映射的測試結果是相同的,下面就讓我們來對這兩種實現的時間複雜度進行分析吧。
映射的時間複雜度分析
我們現在先來寫一個程式,來測試這兩種不同實現的映射運行所需要的時間,這段測試程式碼其實大家已經很熟悉了,和我們前面測試集合的運行時間程式碼是一樣的,如下:
private static double testMap(Map<String, Integer> map, String filename){ //獲取當前系統的時間,單位時納秒 long startTime = System.nanoTime(); System.out.println(filename); List<String> words = new ArrayList<String>(); if(FileOperation.readFile(filename, words)) { System.out.println("Total words: " + words.size()); for (String word : words){ if(map.contains(word)) map.set(word, map.get(word) + 1); else map.add(word, 1); } System.out.println("Total different words: " + map.getSize()); System.out.println("Frequency of PRIDE: " + map.get("pride")); System.out.println("Frequency of PREJUDICE: " + map.get("prejudice")); } long endTime = System.nanoTime(); //將時間單位納秒轉為秒 return (endTime - startTime) / 1000000000.0; } public static void main(String[] args) { String filename = "pride-and-prejudice.txt"; //基於二分搜索樹實現的映射 Map<String, Integer> bstMap = new BSTMap<String, Integer>(); double time1 = testMap(bstMap, filename); System.out.println("BST Map: " + time1 + " s"); System.out.println(); //基於鏈表實現的映射 Map<String, Integer> linkedListMap = new LinkedListMap<String, Integer>(); double time2 = testMap(linkedListMap, filename); System.out.println("Linked List Map: " + time2 + " s"); } 測試程式碼的運行結果如下:
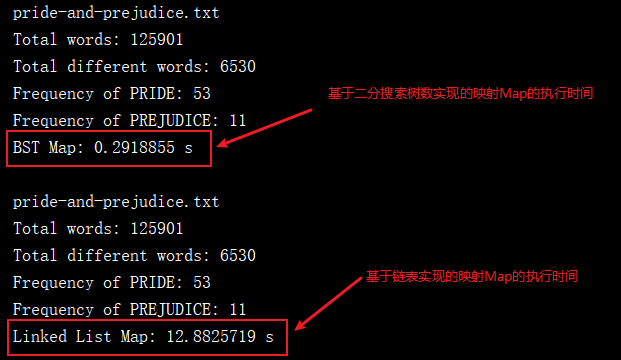
由於我們前面在集合中的學習可以知道,二分搜索樹的增刪改查的時間複雜度平均為O(logn),而鏈表的時間複雜度為O(n),如下:
| LinkedListMap | BSTMap | 平均 | 最差 | |
|---|---|---|---|---|
| 增 add | O(n) | O(h) | O(logn) | O(n) |
| 刪 remove | O(n) | O(h) | O(logn) | O(n) |
| 改 set | O(n) | O(h) | O(logn) | O(n) |
| 查 get | O(n) | O(h) | O(logn) | O(n) |
| 查 contains | O(n) | O(h) | O(logn) | O(n) |
其實通過集合和映射的學習我們可以發現,由於集合種元素也是不允許重複的,和映射種鍵的唯一性是一樣的,所以我們完全可以基於集合,來實現映射,當然也可以基於映射的鍵,來實現集合。
leetcode上關於集合和映射的問題
349號問題:兩個數組的交集
問題:給定兩個數組,編寫一個函數來計算它們的交集。該題的詳細題目描述請上leetcode搜索題號進行查看!
思路:先定義一個動態數組ArrayList,用來存儲兩個數組的交集元素,我們可以把其中一個數組的所有元素加入Set集合中,然後再對另外一個數組進行遍歷,判斷Set中是否有該元素,如已經存在,則把該元素加入動態數組ArrayList中,程式碼實現如下:
public int[] intersection(int[] nums1, int[] nums2) { //這裡是使用的Java類庫中的TreeSet,我們也可以使用我們自己基於二分搜索樹是實現的Set TreeSet<Integer> set = new TreeSet<Integer>(); for (int num : nums1) { set.add(num); } List<Integer> list = new ArrayList<Integer>(); for (int num : nums2) { if (set.contains(num)){ list.add(num); //從set集合刪除該元素,為了避免下次運到該元素進行重複添加 set.remove(num); } } //返回值需要一個數組 int[] res = new int[list.size()]; for (int i=0; i<res.length; i++){ res[i] = list.get(i); } return res; } 350號問題:兩個數組的交集II
題目要求:輸出結果中每個元素出現的次數,應與元素在兩個數組中出現的次數一致。
說明:該題的詳細題目描述請上leetcode搜索題號進行查看!
仔細審題後,我們會發現對比於349題,多了應與元素在兩個數組中出現的次數一致的這個要求,我們可以對數組中交集元素的出現次數進行統計,即可以採用 映射這中數據結構,具體實現如下:
public int[] intersect(int[] nums1, int[] nums2) { //key-代表數組中的元素,value表示的是該元素出現的次數 //這裡我們使用的是Java類庫提供的TreeMap,你也可以使用我們基於二分搜索樹實現的Map來解決這個問題 Map<Integer,Integer> map = new TreeMap<Integer, Integer>(); for (int num : nums1) { if (map.containsKey(num)){ map.put(num,map.get(num)+1); }else { map.put(num,1); } } //用來存儲包含重複元素的集合 List<Integer> res = new ArrayList<Integer>(); for(int num: nums2){ if(map.containsKey(num)){ res.add(num); map.put(num, map.get(num) - 1); if(map.get(num) == 0) map.remove(num); } } int[] ret = new int[res.size()]; for(int i = 0 ; i < res.size() ; i ++) ret[i] = res.get(i); return ret; } 

