用Python簡單批量處理數據
- 2020 年 4 月 4 日
- 筆記
近期碰到一個問題,兩套系統之間數據同步出了差錯,事後才發現的,又不能將業務流程倒退,但是這麼多數據手工處理量也太大了,於是決定用Python偷個小懶。
1、首先分析數據。
兩邊資料庫欄位的值都是一樣,先將這邊資料庫的數據查詢導出,正好是2列120多行的數據。那麼目標就是拼接成update from_name set data= where id= 格式,將導出內容中的第1列和第2列內容放到等號=後面即可。

2、下面開始動手。
前提肯定是要有一個python環境的,沒有的去下載安裝一個也很快。有了環境之後打開編輯器,這裡用自帶的IDLE或者pycharm都行,程式碼簡單用哪個都不影響。
2.1 打開文件(注意文件存放路徑),默認打開為 r 模式,seek(0):從起始位置讀取內容。

2.2 讀取文件中的數據,得到一個列表,用以for循環

輸出f1查看數據格式,可以看出中間的製表符t 和換行符n

2.3 先將列表內容的換行符n替換為;,再從指標表t位置進行切割,分開為兩個字元。
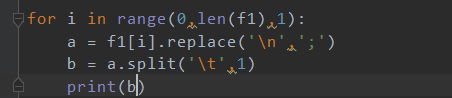
輸出結果:

2.4 然後就可以進行拼接了,使用最簡單拼接方式,再將所有內容存到一個對象中

2.5 最後將成果封裝寫入到一個文件當中

檢查電腦存放的路徑中是否存在最終輸出的文件,大功告成,11行程式碼就完了,簡單粗暴又有效。

