解決GPU顯示記憶體未釋放問題
- 2020 年 4 月 4 日
- 筆記
前言
今早我想用多塊GPU測試模型,於是就用了PyTorch里的torch.nn.parallel.DistributedDataParallel來支援用多塊GPU的同時使用(下面簡稱其為Dist)。
程式運行時,由於程式中其他部分的程式碼(與Dist無關的程式碼)出現了錯誤,導致程式退出。這次使用Dist時沒有考慮和處理這種程式崩潰的情況,因此在程式退出前沒有用Dist關閉生成的所有進程,最終導致本次進程運行後GPU顯示記憶體未釋放(經觀察,發現是由於沒有用Dist關閉所有進程,導致程式運行後還有一部分進程在運行)。
下面介紹這次我解決該問題的過程。
正文
MVE
Minimal Verifiable Examples,關於本問題的程式程式碼如下:
import torch.distributed as dist # 一些程式碼:定義model等 some code # 初始化並行訓練 dist.init_process_group(xxxx) # 函數參數省略 model = torch.nn.parallel.DistributedDataParallel(model, find_unused_parameters=True) # 一些程式碼:訓練、測試模型等 some code # 我的程式在這個部分出錯且程式直接退出,導致下面的關閉進程的程式碼沒有運行 # 關閉所有進程 dist.destroy_process_group() 問題的出現
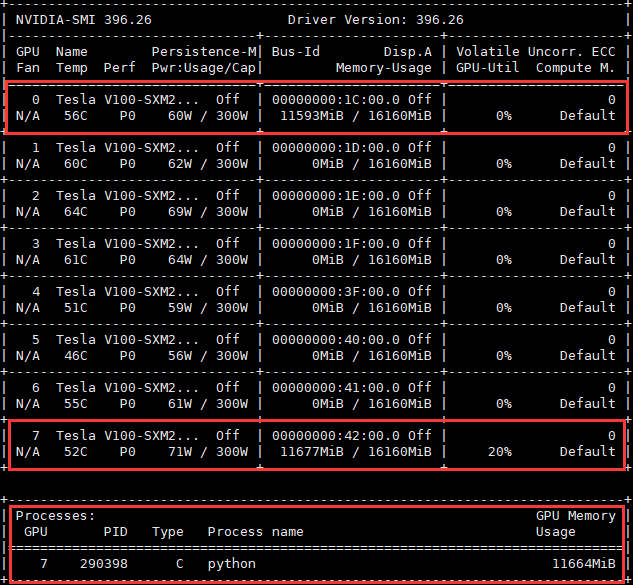
如下圖所示,程式退出後,並沒有進程在使用0號GPU,但0號GPU的顯示記憶體卻被佔用。原因是程式退出前沒有用Dist關閉所有進程,一部分進程還在運行,這些進程佔用0號GPU的顯示記憶體。
佔用7號GPU的進程是我的另外一個進程,與本文討論的問題無關。
定位佔用GPU顯示記憶體的PID
執行下面的指令
fuser -v /dev/nvidia* 該命令執行後得到下圖所示的結果,可以看到是PID為285448的進程佔用了0號GPU。
下面的圖中忘記打了馬賽克,後來用黑色遮擋了一下資訊,所以USER這一列是看起來是空的。
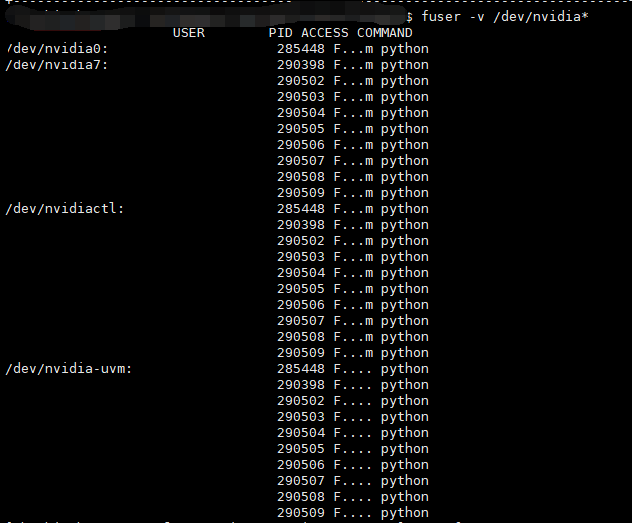
執行下面這條命令,查看該進程的資訊,可以發現該進程的PPID(其父進程的PID)是1,說明該進程不是我佔用7號GPU的進程生成的,並且現在只有它在使用0號GPU。可以推斷出這個進程是因為程式運行錯誤導致其沒有被關閉,因此可以手動關閉該進程。
ps -f -p 285448 下面的圖中忘記打了馬賽克,後來用黑色遮擋了一下資訊,所以圖中的路徑不是很清晰。

先後執行下面這兩條命令,殺掉該進程,再查看GPU情況,可以看到0號GPU的顯示記憶體已經被釋放,現在的GPU顯示記憶體佔用情況是正常的。
kill -9 2885448 nvidia-smi 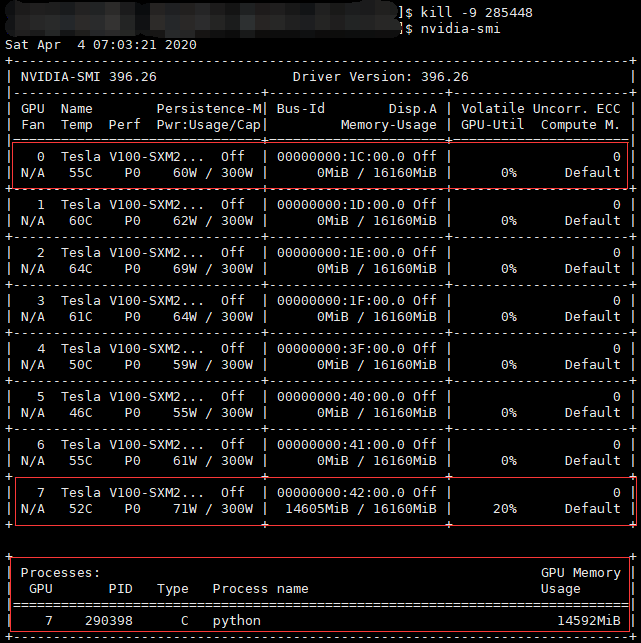
作者:@臭鹹魚
轉載請註明出處:https://www.cnblogs.com/chouxianyu/
歡迎討論和交流!

