Inception系列理解
- 2020 年 4 月 3 日
- 筆記
寫在前面
Inception 家族成員:Inception-V1(GoogLeNet)、BN-Inception、Inception-V2、Inception-V3、Inception-ResNet-V1、Inception-V4、Inception-ResNet-V2。
Inception系列網路結構可以模組化為:
- Stem:前處理部分
- A B C:網路主體「三段式」,A B C每段的輸入feature size依次折半,channel增加
- ReductionA B:完成feature size折半操作(降取樣)
- Avg Pooling (+ Linear):後處理部分
Inception系列的演化過程就是上面各環節不斷改進(越來越複雜)的過程,其進化方向大致為
- Stem:大卷積層→多個小卷積層堆疊→multi-branch 小卷積層堆疊
- A B C:相同multi-branch結構→每階段不同multi-branch結構→每階段不同Residual+multi-branch結構,big convolution→ small convolution + BN → factorized convolution
- ReductionA B:max pooling → 不同multi-branch conv(stride 2)結構
- 後處理:Avg Pooling + Linear → Avg Pooling
性能進化如下圖所示,single model通過center crop 在ImageNet上 Top1 和 Top5 準確率,
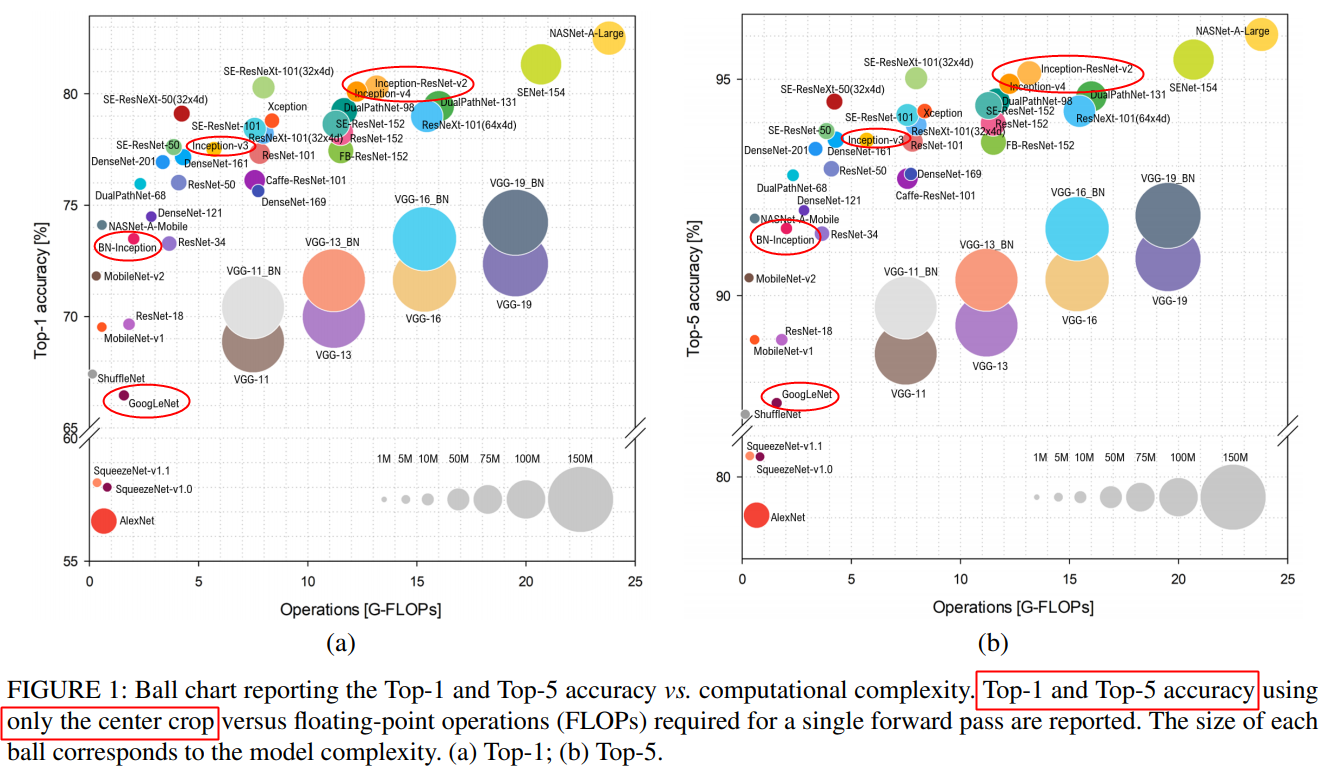
具體如下。
Inception-V1 (GoogLeNet)
Inception-V1,更被熟知的名字為GoogLeNet,意向Lenet致敬。
通過增加網路深度和寬度可以提升網路的表徵能力。
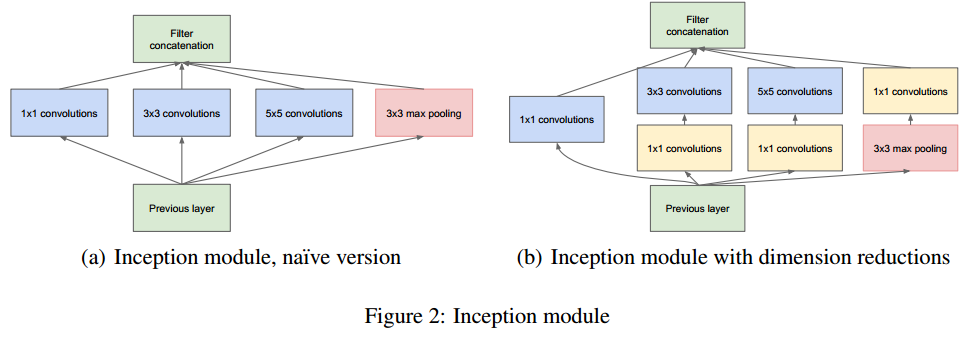
增加寬度可以簡單地通過增加卷積核數量來實現,GoogLeNet在增加卷積核數量的同時,引入了不同尺寸的卷積核,來捕捉不同尺度的特徵,形成了multi-branch結構——這是GoogLeNet網路結構的最大特點,如下圖所示,然後將不同branch得到的feature map 拼接在一起,為了讓feature map的尺寸相同,每個branch均採用SAME padding方式,同時stride為1(包括max pooling)。為了降低計算量,又引入了(1times 1)卷積層來降維,如下圖右所示,該multi-branch結構稱之為一個Inception Module,在GoogLeNet中採用的是下圖右的Inception Module。
直接增加深度會導致淺層出現嚴重的梯度消失現象,GoogLeNet引入了輔助分類器(Auxiliary Classifier),在淺層和中間層插入,來增強回傳時的梯度訊號,引導淺層學習到更具區分力的特徵。
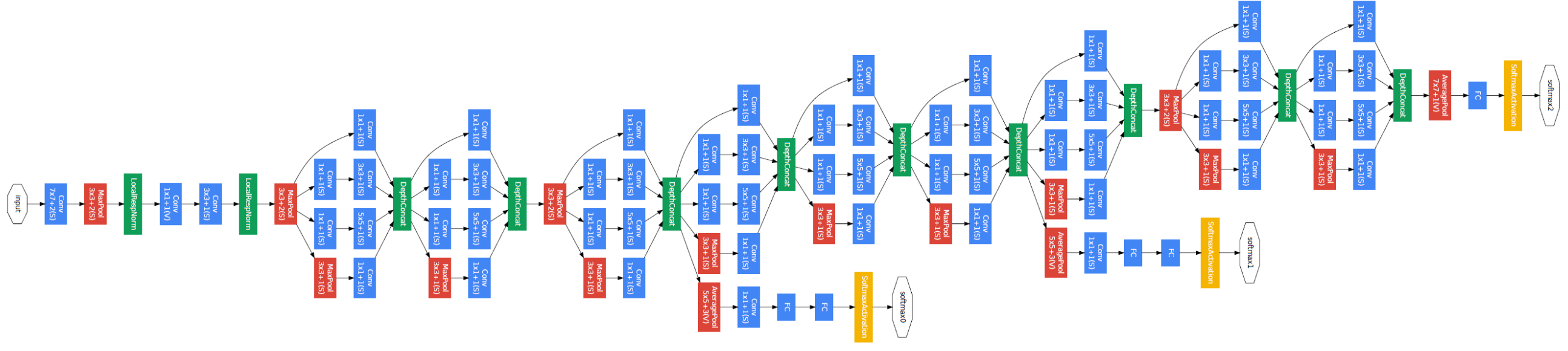
最終,網路結構如下,主體三段式A B C 即 3x、4x、5x,
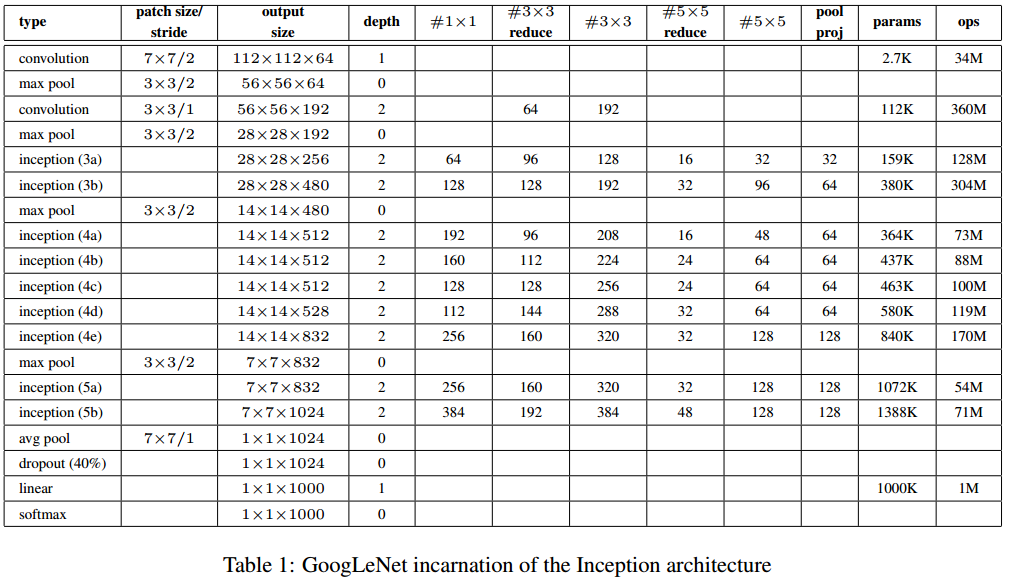
GoogLeNet網路結構的特點可以概括為,
- 同時使用不同尺寸的卷積核,形成multi-branch結構,來捕捉不同尺度的特徵
- 使用(1 times 1)卷積降維,壓縮資訊,降低計算量
- 在classifier前使用average pooling
BN-Inception
BN-Inception網路實際是在Batch Normalization論文中順帶提出的,旨在表現BN的強大。
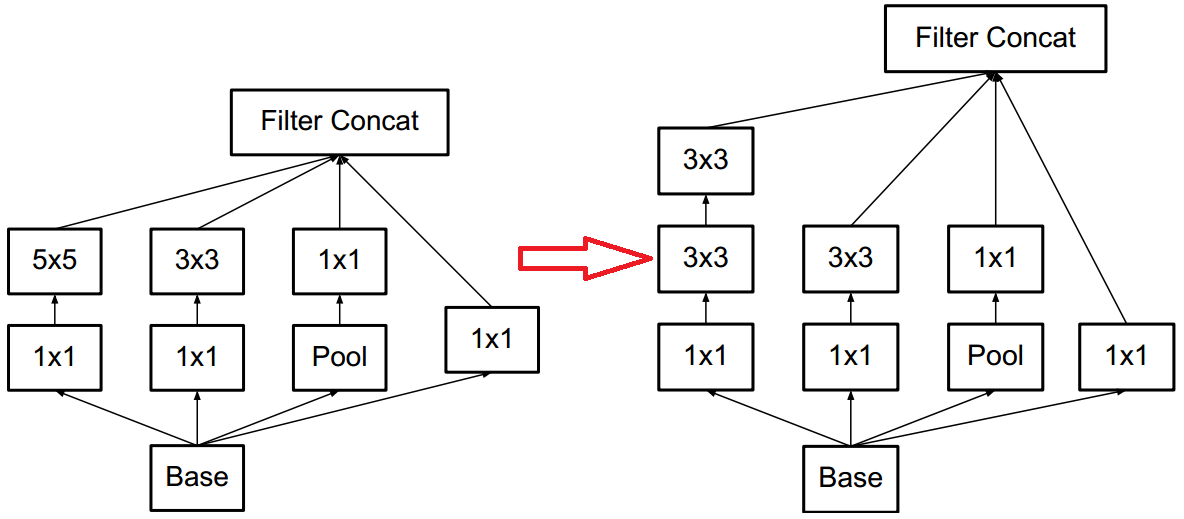
與GoogLeNet的不同之處在於,
- 在每個激活層前增加BN層
- 將Inception Module中的(5 times 5) 卷積替換為2個(3times 3) 卷積,如上圖所示
- 在Inception 3a和3b之後增加Inception 3c
- 部分Inception Module中的Pooling層改為average pooling
- 取消Inception Module之間銜接的pooling層,而將下取樣操作交給Inception 3c和4e,令stride為2
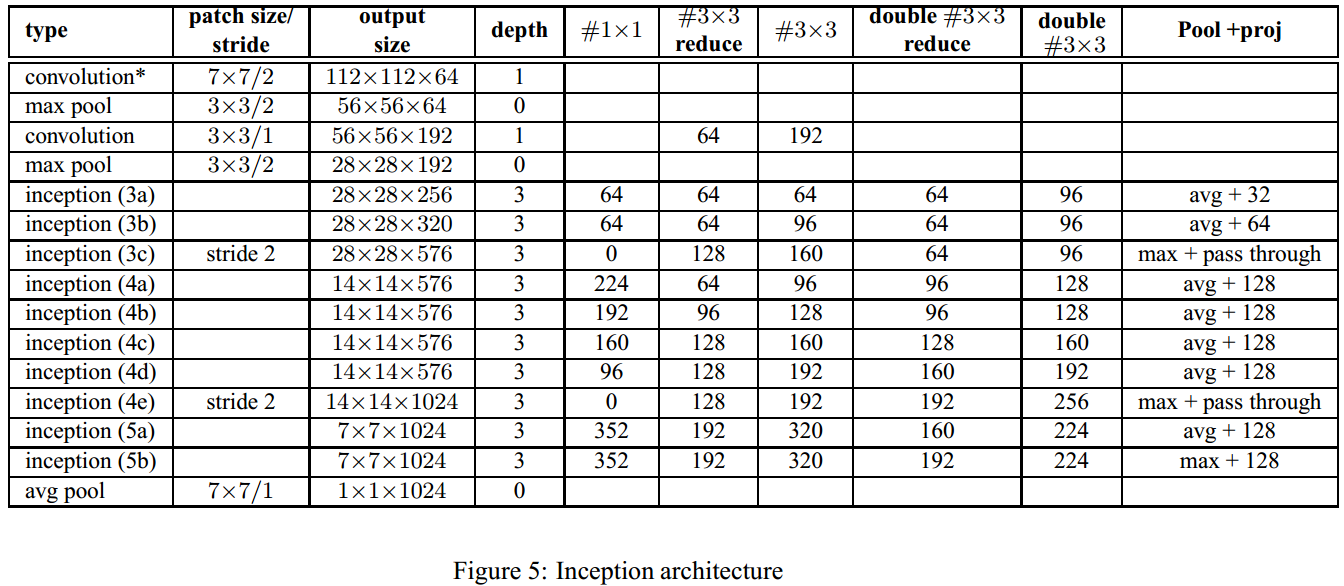
BN-Inception網路結構如下
Inception-V2, V3
Inception V2和V3出自同一篇論文Rethinking the Inception Architecture for Computer Vision。
GoogLeNet和BN-Inception網路結構中Inception Module可分為3組,稱之為3x、4x和5x(即主體三段式A B C),GoogLeNet和BN-Inception這3組採用相同Inception Module結構,只是堆疊的數量不同。
Inception V2和V3與以往最大的不同之處在於3組分別使用了不同結構的Inception Module,分別如下圖從左到右所示,
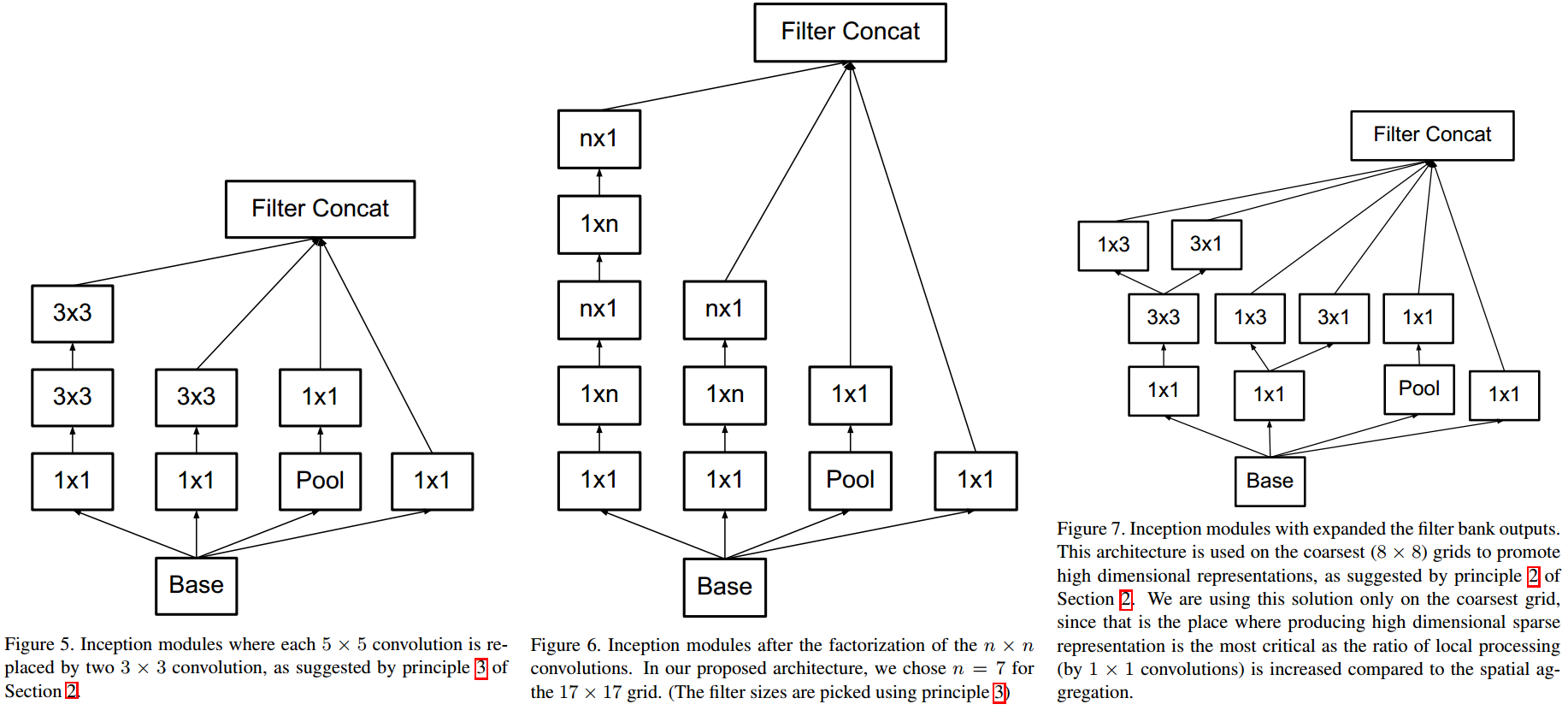
具體地,
- 3x使用的Inception Module與BN-Inception相同,即將(5times 5)拆分成2個堆疊的(3times 3) ;
- 4x使用的Inception Module採用了factorized convolutions ,將2維卷積拆分成2個堆疊的1維卷積,可類比傳統電腦視覺中的「行列可分解卷積」,但中間夾了個激活,1維卷積的長度為7;
- 5x使用的Inception Module,1維卷積不再堆疊而是並列,將結果concat;
除此之外,
- 3x和4x之間,4x和5x之間,均不存在銜接的池化層,下取樣通過Inception Module中的stride實現
- 取消了淺層的輔助分類器,只保留中層的輔助分類器
- 最開始的幾個卷積層調整為多個堆疊的(3times 3) 卷積
據論文所述,V2的網路結構如下
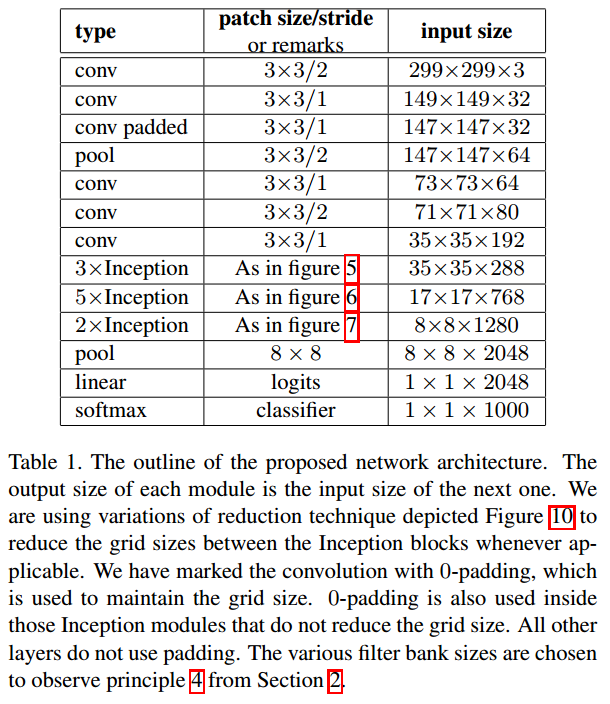
據論文所述,V3與V2的差異在於,
- RMSProp Optimizer
- Label Smoothing,訓練中使用的label為one hot label與均勻分布的加權,可以看成一種正則
- Factorized (7 times 7),即將第一個(7 times 7)卷積層變為堆疊的3個(3 times 3)
- BN-auxiliary,輔助分類器中的全連接層也加入BN
但是,實際發布的Inception V3完全是另外一回事,參見pytorch/inception,有人繪製了V3的網路架構如下——網上少有繪製正確的,下圖中亦存在小瑕疵,最後一個下取樣Inception Module中(1times 1)的stride為1。
需要注意的是,起下取樣作用兩個Inception Module並不相同。
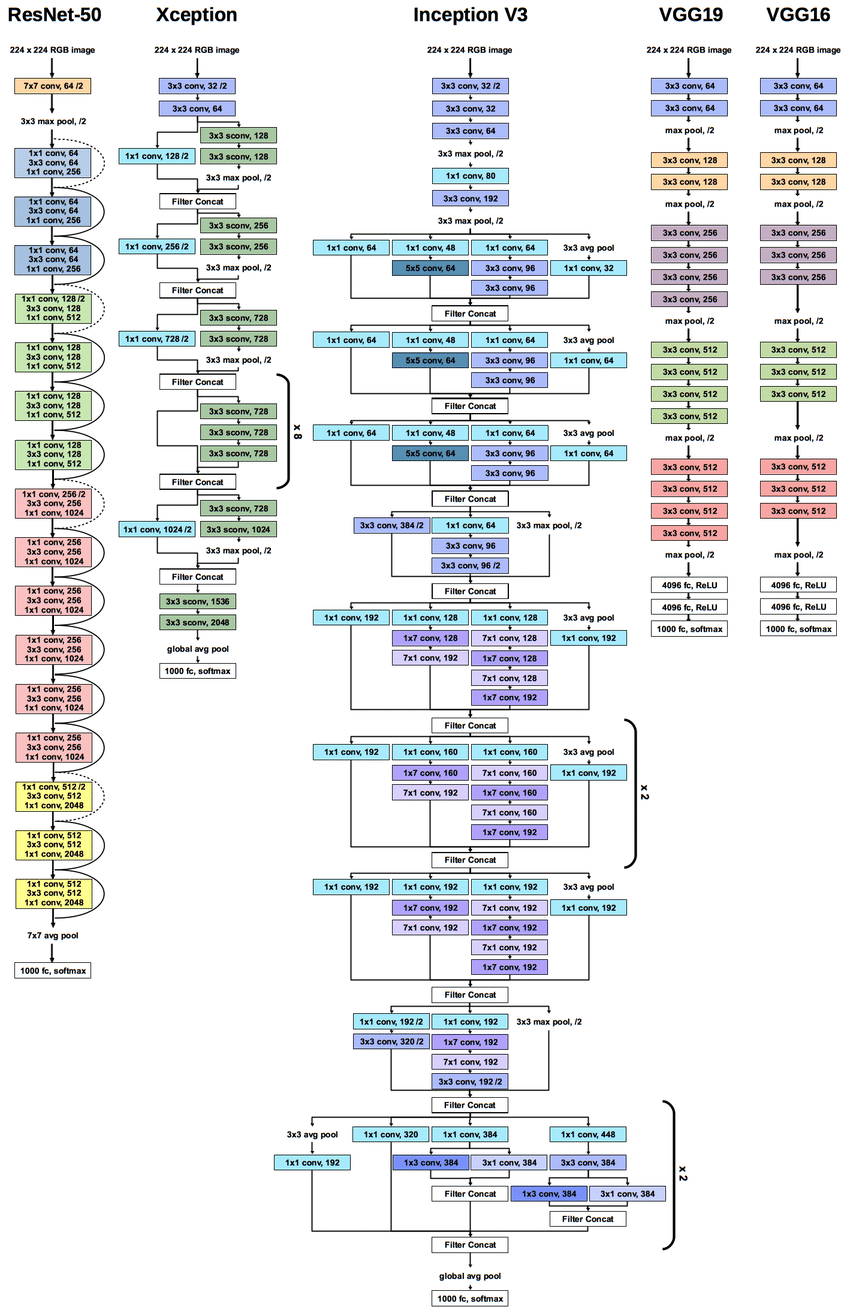
有的時候,Inception-V2和BN-Inception是混淆的。從Inception-V3開始,Inception架構變得越來越不像人搞的……
Inception-V4,Inception-ResNet-v1,Inception-ResNet-v2
Inception-V4,Inception-ResNet-v1 和 Inception-ResNet-v2出自同一篇論文Inception-V4, Inception-ResNet and the Impact of Residual Connections on Learning,
Inception-V4相對V3的主要變化在於,前處理使用更複雜的multi-branch stem模組,主體三段式與V3相同。
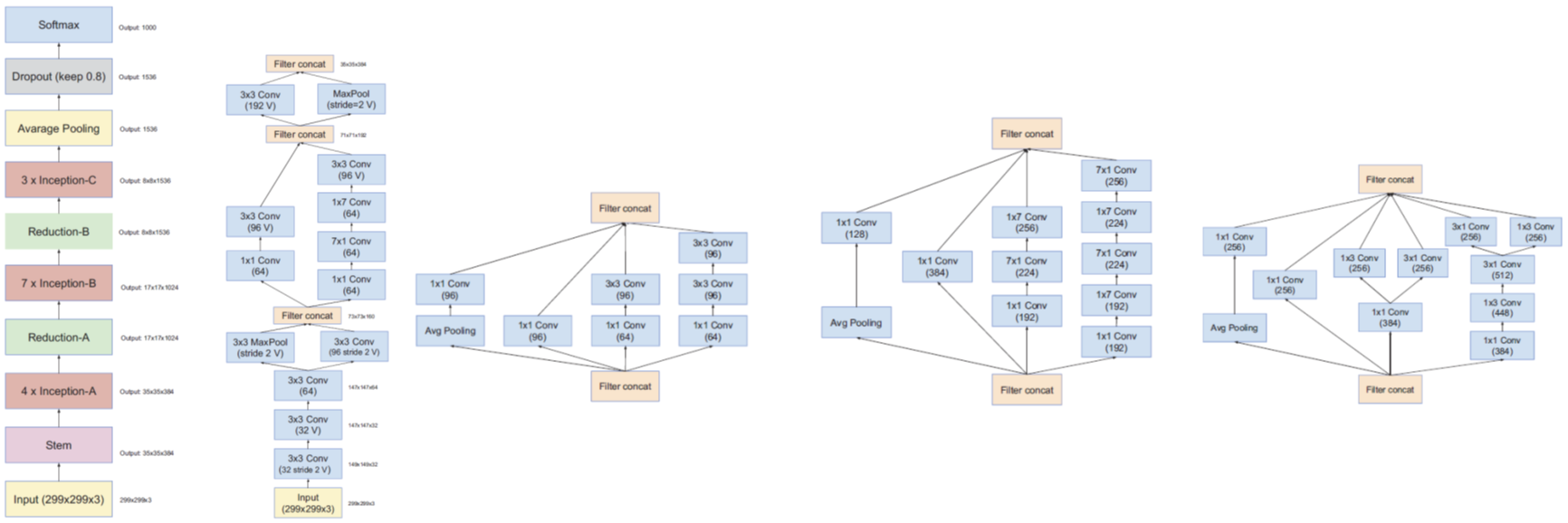
Inception-ResNet-V1與Inception-ResNet-V2,將Inception與ResNet結合,使用Inception結構來擬合殘差部分,兩者在A B C部分結構相同,只是後者channel數更多,兩者的主要差異在前處理部分,後者採用了更複雜的multi-branch stem結構(與V4相同)。相比純Inception結構,引入ResNet結構極大加快了網路的收斂速度。
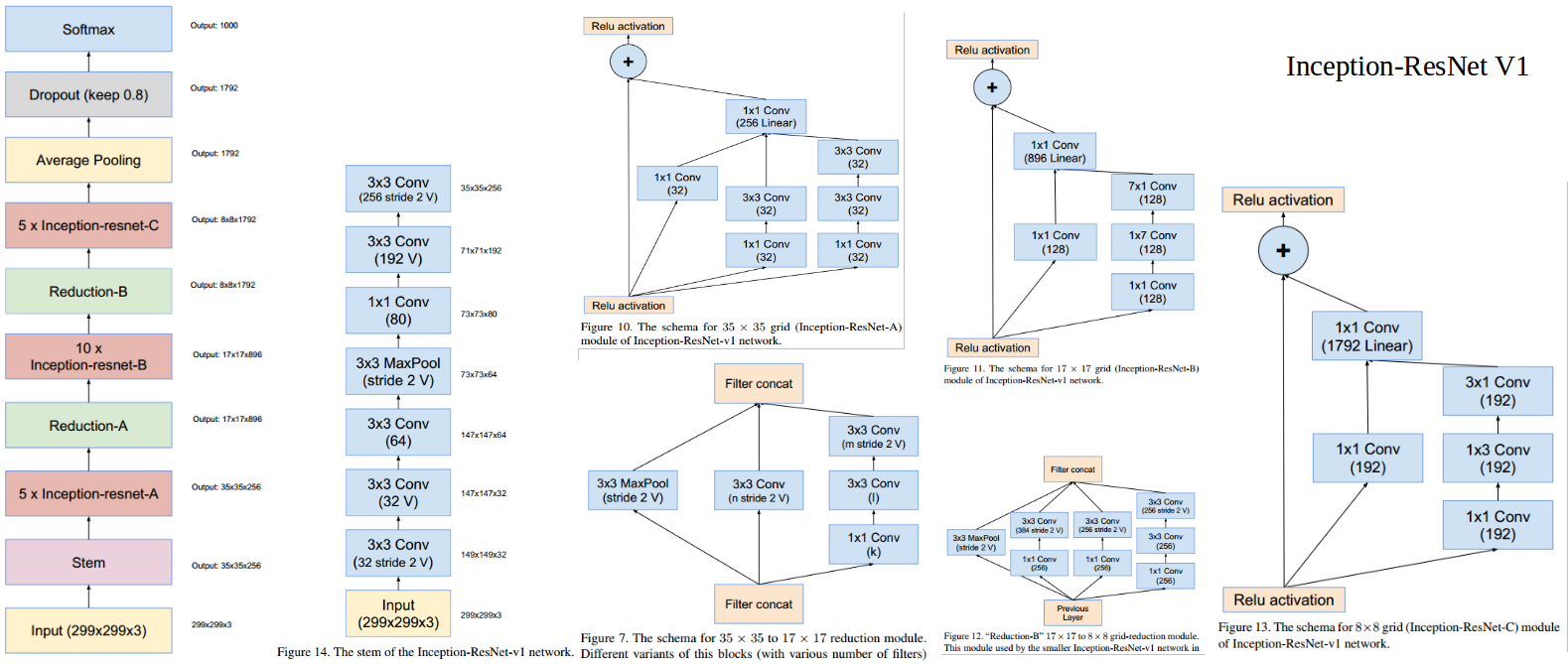
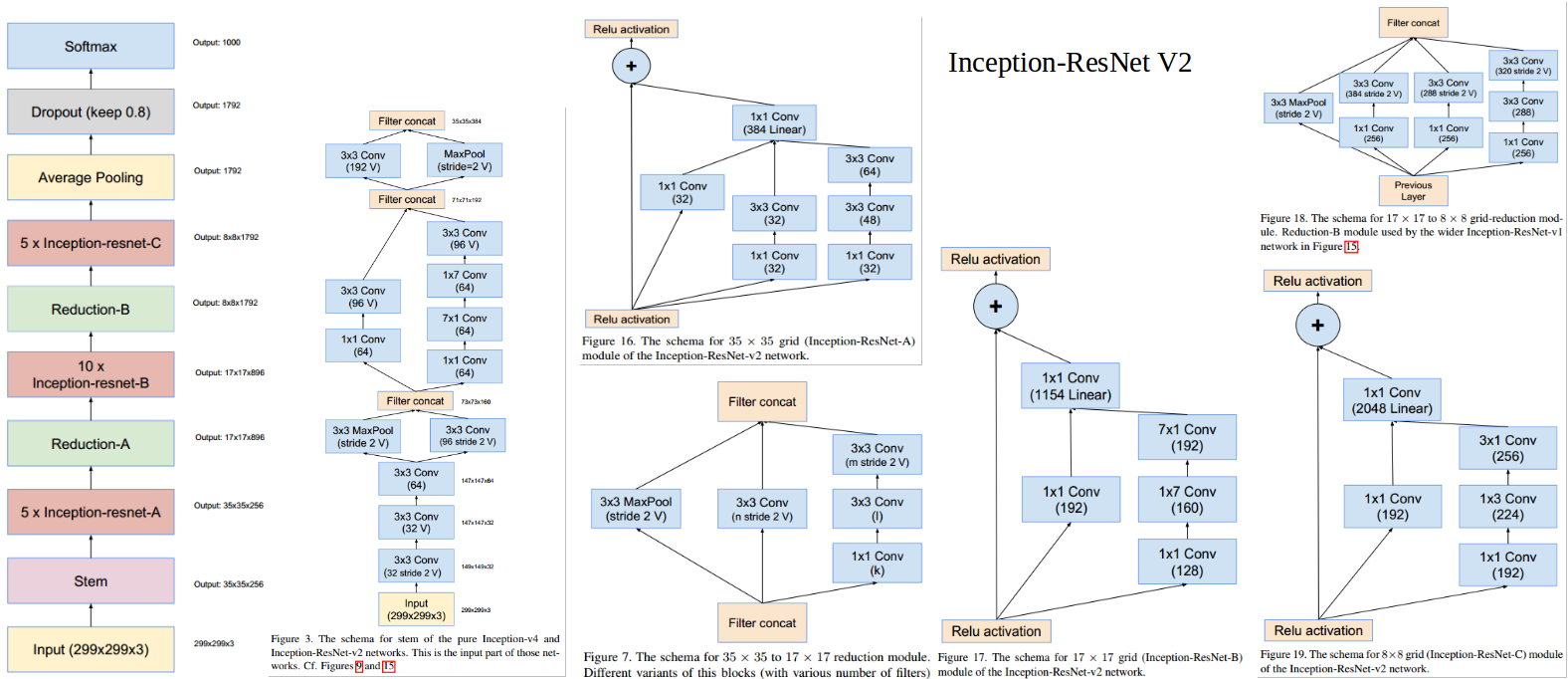
以上。
參考
- GoogLeNet, Inception-V1: Going Deeper with Convolutions
- Batch Normalization, BN-Inception: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- Inception-V2, V3: Rethinking the Inception Architecture for Computer Vision
- Inception-V4, Inception-ResNet and the Impact of Residual Connections on Learning


