Centos7部署k8s[v1.16]高可用[keepalived]集群
- 2020 年 4 月 2 日
- 筆記
實驗目的
一般情況下,k8s集群中只有一台master和多台node,當master故障時,引發的事故後果可想而知。
故本文目的在於體現集群的高可用,即當集群中的一台master宕機後,k8s集群通過vip的轉移,又會有新的節點被選舉為集群的master,並保持集群的正常運作。
因本文體現的是master節點的高可用,為了實現效果,同時因資源條件限制,故總共採用4台伺服器完成本次實驗,3台master,1台node。
看到這也需有人有疑惑,總共有4台機器的資源,為啥不能2台master呢?這是因為通過kubeadm部署的集群,當中的etcd集群默認部署在master節點上,3節點方式最多能容忍1台伺服器宕機。如果是2台master,當中1台宕機了,直接導致etcd集群故障,以至於k8s集群異常,這些基礎環境都over了,vip漂移等高可用也就在白瞎。
環境說明
基本資訊
# 主機列表
10.2.2.137 master1
10.2.2.166 master2
10.2.2.96 master3
10.2.3.27 node0
# 軟體版本
docker version:18.09.9
k8s version:v1.16.4
架構資訊
本文採用kubeadm方式搭建集群,通過keepalived的vip策略實現高可用,架構圖如下:
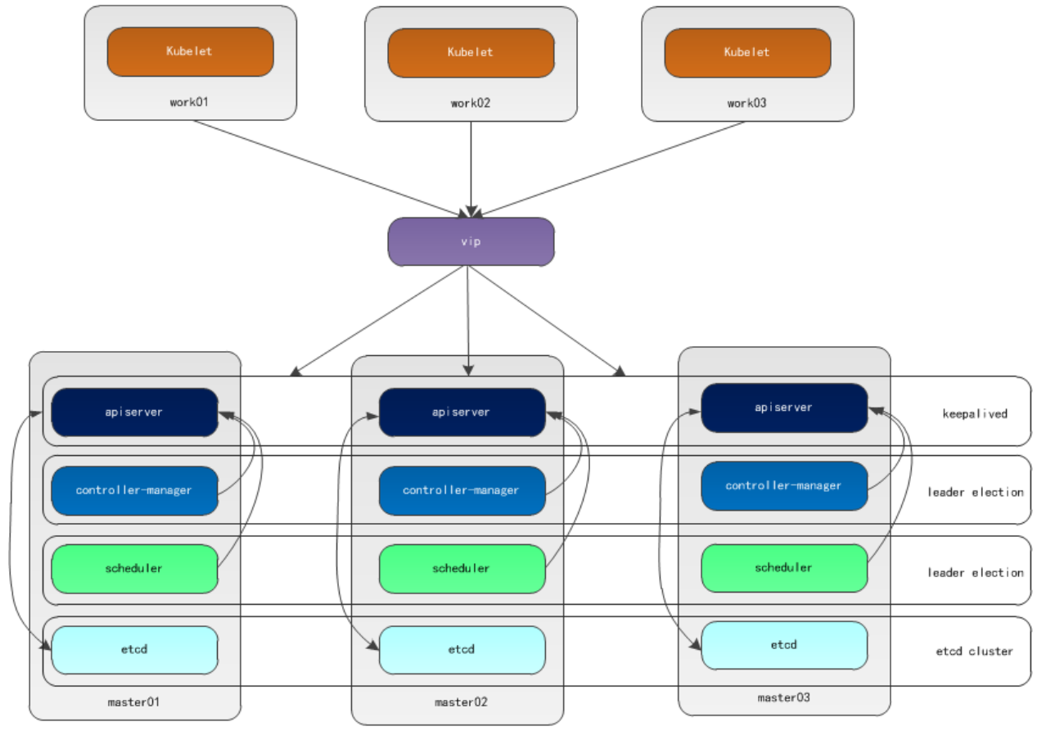
# 主備模式高可用架構說明

a)apiserver通過keepalived實現高可用,當某個節點故障時觸發vip轉移;
b)controller-manager和scheduler在k8s內容通過選舉方式產生領導者(由leader-elect選型控制,默認為true),同一時刻集群內只有一個scheduler組件運行;
c)etcd在kubeadm方式實現集群時,其在master節點會自動創建etcd集群,來實現高可用,部署的節點為奇數,3節點方式最多容忍一台機器宕機。
環境準備
說明
1、大多數文章都是一步步寫命令寫步驟,而對於有部署經驗的人來說覺得繁瑣化了,故本文大部分伺服器shell命令操作都將集成到腳本;
2、本文相關shell腳本地址: https://gitee.com/kazihuo/k8s-install-shell
3、所有要加入到k8s集群的機器都執行本部分操作。
操作
a)將所有伺服器修改成對應的主機名,master1示例如下;
# hostnamectl set-hostname master1 #重新登錄後顯示新設置的主機名
b)配置master1到master2、master3免密登錄,本步驟只在master1上執行;
[root@master1 ~]# ssh-keygen -t rsa # 一路回車
[root@master1 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub [email protected]
[root@master1 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub [email protected]
c)腳本實現環境需求配置;
# sh set-prenv.sh


#!/bin/bash #==================================================== # Author: LuoMuRui # Blog: https://www.cnblogs.com/kazihuo # Create Date: 2020-04-02 # Description: System environment configuration. #==================================================== # Stop firewalld firewall-cmd --state #查看防火牆狀態 systemctl stop firewalld.service #停止firewall systemctl disable firewalld.service #禁止firewall開機啟動 # Close selinux getenforce #查看selinux狀態 setenforce 0 #臨時關閉selinux sed -i 's/^ *SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config #永久關閉(需重啟系統) # Set localhost's dns cat >> /etc/hosts << EOF 10.2.2.137 master1 10.2.2.166 master2 10.2.2.96 master3 10.2.3.27 node0 EOF # Disable swap swapoff -a #臨時禁用 sed -i.bak '/swap/s/^/#/' /etc/fstab #永久禁用 # Kernel parameter modification # k8s網路使用flannel,該網路需要設置內核參數bridge-nf-call-iptables=1,修改這個參數需要系統有br_netfilter模組 lsmod |grep br_netfilter # 查看模組 modprobe br_netfilter # 臨時新增 # 永久新增模組 cat > /etc/rc.sysinit << EOF #!/bin/bash for file in /etc/sysconfig/modules/*.modules ; do [ -x $file ] && $file done EOF cat > /etc/sysconfig/modules/br_netfilter.modules << EOF modprobe br_netfilter EOF chmod 755 /etc/sysconfig/modules/br_netfilter.modules cat <<EOF > /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 EOF sysctl -p /etc/sysctl.d/k8s.conf # Set the yum of k8s cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF yum clean all && yum -y makecache
set-prenv.sh
軟體安裝
docker安裝
說明:所有節點都執行本部分操作!
# sh install-docker.sh
#!/bin/bash #==================================================== # Author: LuoMuRui # Blog: https://www.cnblogs.com/kazihuo # Create Date: 2020-04-02 # Description: Install docker. #==================================================== # Install dependency package yum install -y yum-utils device-mapper-persistent-data lvm2 # Add repo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo # Looking the version of docker yum list docker-ce --showduplicates | sort -r # Install docker yum install docker-ce-18.09.9 docker-ce-cli-18.09.9 containerd.io -y # Mirror acceleration & change Cgroup Driver # 修改cgroupdriver是為了消除告警:[WARNING IsDockerSystemdCheck]: detected “cgroupfs” as the Docker cgroup driver. The recommended driver is “systemd”. Please follow the guide at https://kubernetes.io/docs/setup/cri/ cat > daemon.json <<EOF { "registry-mirrors": ["https://registry.docker-cn.com"], "exec-opts": ["native.cgroupdriver=systemd"] } EOF # Start && enable systemctl daemon-reload systemctl start docker systemctl enable docker docker --version # Others yum -y install bash-completion source /etc/profile.d/bash_completion.sh
install-docker.sh
keepalived安裝
說明:三台master節點執行本部分操作!
# 安裝
# yum -y install keepalived
# 配置
# master1上keepalived配置
[root@master1 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived global_defs { router_id master1 } vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 51 priority 150 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.2.2.6 } }
View Code
# master2上keepalived配置
[root@master2 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived global_defs { router_id master2 } vrrp_instance VI_1 { state BACKUP interface eth0 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.2.2.6 } }
View Code
# master3上keepalived配置
[root@master3 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived global_defs { router_id master3 } vrrp_instance VI_1 { state BACKUP interface eth0 virtual_router_id 51 priority 50 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.2.2.6 } }
View Code
# 啟動
# service keepalived start
# systemctl enable keepalived
# vip查看
[root@master1 ~]# ip a
# 功能功驗
將master1上的keepalived伺服器停止或者master1伺服器關機後,master2上接管vip,同時master2也關機後,master3接管vip。
k8s安裝
說明:所有節點都執行本部分操作!
組件:
kubelet
運行在集群所有節點上,用於啟動Pod和容器等對象的工具
kubeadm
用於初始化集群,啟動集群的命令工具
kubectl
用於和集群通訊的命令行,通過kubectl可以部署和管理應用,查看各種資源,創建、刪除和更新各種組件
# sh install-k8s.sh
#!/bin/bash #==================================================== # Author: LuoMuRui # Blog: https://www.cnblogs.com/kazihuo # Create Date: 2020-04-02 # Description: Install the soft of k8s. #==================================================== # Looking the version yum list kubelet --showduplicates | sort -r # Install yum install -y kubelet-1.16.4 kubeadm-1.16.4 kubectl-1.16.4 # Start && enable systemctl enable kubelet && systemctl start kubelet # Bash env echo "source <(kubectl completion bash)" >> ~/.bash_profile source /root/.bash_profile
install-k8s.sh
鏡像下載
說明:所有節點都執行本部分操作!
因中國網路的限制,故從阿里雲鏡像倉庫下載鏡像後本地打回默認標籤名的方式,讓kubeadm在部署集群時能正常使用鏡像。
# sh download-images.sh
#!/bin/bash #==================================================== # Author: LuoMuRui # Blog: https://www.cnblogs.com/kazihuo # Create Date: 2020-04-02 # Description: Download images. #==================================================== url=registry.cn-hangzhou.aliyuncs.com/loong576 version=v1.16.4 images=(`kubeadm config images list --kubernetes-version=$version|awk -F '/' '{print $2}'`) for imagename in ${images[@]} ; do docker pull $url/$imagename docker tag $url/$imagename k8s.gcr.io/$imagename docker rmi -f $url/$imagename done
download-images.sh
master初始化
初始化操作
[root@master1 ~]# cat kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta2 kind: ClusterConfiguration kubernetesVersion: v1.16.4 apiServer: certSANs: - 10.2.2.6 controlPlaneEndpoint: "10.2.2.6:6443" networking: podSubnet: "10.244.0.0/16"
[root@master01 ~]# kubeadm init –config=kubeadm-config.yaml
# 初始化成功後末尾顯示kubeadm join的資訊,記錄下來;
You can now join any number of control-plane nodes by copying certificate authorities and service account keys on each node and then running the following as root: kubeadm join 10.2.2.6:6443 --token 2ccecd.v72vziyzdfnbr46u --discovery-token-ca-cert-hash sha256:eb92768acb748d722ef7d97bc60751a375b67b12a46c7a7232c54cdb378d2e61 --control-plane Then you can join any number of worker nodes by running the following on each as root: kubeadm join 10.2.2.6:6443 --token 2ccecd.v72vziyzdfnbr46u --discovery-token-ca-cert-hash sha256:eb92768acb748d722ef7d97bc60751a375b67b12a46c7a7232c54cdb378d2e61
# 初始化失敗後可重新初始化
# kubeadm reset
# rm -rf $HOME/.kube/config
添加環境變數
echo “export KUBECONFIG=/etc/kubernetes/admin.conf” >> ~/.bash_profile
source ~/.bash_profile
安裝flannel插件
# wget https://raw.githubusercontent.com/coreos/flannel/2140ac876ef134e0ed5af15c65e414cf26827915/Documentation/kube-flannel.yml
# kubectl apply -f kube-flannel.yml
control plane節點加入
證書分發
# master1將認證文件同步到其他master節點
[root@master1 ~]# sh cert-others-master.sh
USER=root CONTROL_PLANE_IPS="master2 master3" #CONTROL_PLANE_IPS="master2 master3" for host in ${CONTROL_PLANE_IPS}; do scp /etc/kubernetes/pki/ca.crt "${USER}"@$host: scp /etc/kubernetes/pki/ca.key "${USER}"@$host: scp /etc/kubernetes/pki/sa.key "${USER}"@$host: scp /etc/kubernetes/pki/sa.pub "${USER}"@$host: scp /etc/kubernetes/pki/front-proxy-ca.crt "${USER}"@$host: scp /etc/kubernetes/pki/front-proxy-ca.key "${USER}"@$host: scp /etc/kubernetes/pki/etcd/ca.crt "${USER}"@$host:etcd-ca.crt # Quote this line if you are using external etcd scp /etc/kubernetes/pki/etcd/ca.key "${USER}"@$host:etcd-ca.key done
View Code
# master2和master3節點配置證書
[root@master2 ~]# sh cert-set.sh
[root@master3 ~]# sh cert-set.sh
mv /${USER}/ca.crt /etc/kubernetes/pki/ mv /${USER}/ca.key /etc/kubernetes/pki/ mv /${USER}/sa.pub /etc/kubernetes/pki/ mv /${USER}/sa.key /etc/kubernetes/pki/ mv /${USER}/front-proxy-ca.crt /etc/kubernetes/pki/ mv /${USER}/front-proxy-ca.key /etc/kubernetes/pki/ mv /${USER}/etcd-ca.crt /etc/kubernetes/pki/etcd/ca.crt # Quote this line if you are using external etcd mv /${USER}/etcd-ca.key /etc/kubernetes/pki/etcd/ca.key
View Code
others master加入集群
# master2和master3加入集群,下文以master2為示例,master3按部就班即可;
[root@master2 ~]# kubeadm join 10.2.2.6:6443 –token 2ccecd.v72vziyzdfnbr46u
–discovery-token-ca-cert-hash sha256:eb92768acb748d722ef7d97bc60751a375b67b12a46c7a7232c54cdb378d2e61
–control-plane
[root@master2 ~]# scp master1:/etc/kubernetes/admin.conf /etc/kubernetes/
[root@master2 ~]# echo “export KUBECONFIG=/etc/kubernetes/admin.conf” >> ~/.bash_profile && source .bash_profile
集群節點查看
# kubectl get nodes
NAME STATUS ROLES AGE VERSION master1 Ready master 20h v1.16.4 master2 Ready master 20h v1.16.4 master3 Ready master 19h v1.16.4
node節點加入
加入操作
[root@node0 ~]# kubeadm join 10.2.2.6:6443 –token 2ccecd.v72vziyzdfnbr46u
–discovery-token-ca-cert-hash sha256:eb92768acb748d722ef7d97bc60751a375b67b12a46c7a7232c54cdb378d2e61
節點查看
# kubectl get nodes
NAME STATUS ROLES AGE VERSION node0 Ready <none> 18h v1.16.4 master1 Ready master 20h v1.16.4 master2 Ready master 20h v1.16.4 master3 Ready master 19h v1.16.4
集群功能驗證
操作
# 關機master1,模擬宕機
[root@master1 ~]# init 0
# vip飄到master2
[root@master2 ~]# ip a |grep ‘2.6’
inet 10.2.2.6/32 scope global eth0
# 組件controller-manager和scheduler發生遷移
# kubectl get endpoints kube-controller-manager -n kube-system -o yaml |grep holderIdentity
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity":"master3_885468ec-f9ce-4cc6-93d6-235508b5a130","leaseDurationSeconds":15,"acquireTime":"2020-04-01T10:15:28Z","renewTime":"2020-04-02T06:02:46Z","leaderTransitions":8}'
# kubectl get endpoints kube-scheduler -n kube-system -o yaml |grep holderIdentity
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity":"master2_cf16fd61-0202-4610-9a27-3cd9d26b4141","leaseDurationSeconds":15,"acquireTime":"2020-04-01T10:15:25Z","renewTime":"2020-04-02T06:03:09Z","leaderTransitions":9}'
# 集群創建pod,依舊正常使用
# cat nginx.yaml
apiVersion: apps/v1 kind: Deployment metadata: name: nginx-test spec: selector: matchLabels: app: nginx replicas: 3 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:latest
# kubectl apply -f nginx.yaml
# kubectl get pods

結論
1、集群中3個master節點,無論哪個節點宕機,都不影響集群的正常使用;
2、當集群中3個master節點有2個故障,則造成etcd集群故障,直接影響集群,導致異常!


