淺談圖資料庫
- 2020 年 4 月 1 日
- 筆記

本文主要討論圖資料庫背後的設計思路、原理還有一些適用的場景,以及在生產環境中使用圖資料庫的具體案例。
從社交網路談起
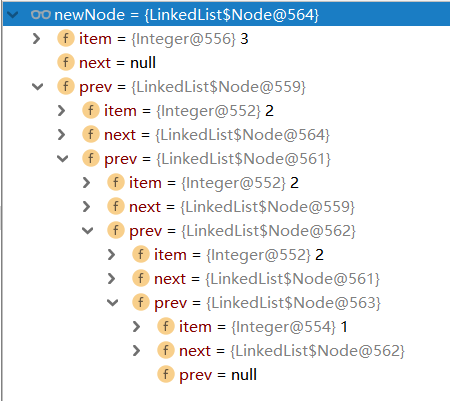
下面這張圖是一個社交網路場景,每個用戶可以發微博、分享微博或評論他人的微博。這些都是最基本的增刪改查,也是大多數研發人員對資料庫做的常見操作。而在研發人員的日常工作中除了要把用戶的基本資訊錄入資料庫外,還需找到與該用戶相關聯的資訊,方便去對單個的用戶進行下一步的分析,比如說:我們發現張三的賬戶里有很多關於 AI 和音樂的內容,那麼我們可以據此推測出他可能是一名程式設計師,從而推送他可能感興趣的內容。
這些數據分析每時每刻都會發生,但有時候,一個簡單的數據工作流在實現的時候可能會變得相當複雜,此外資料庫性能也會隨著數據量的增加而銳減,比如說獲取某管理者下屬三級彙報關係的員工,這種統計查詢在現在的數據分析中是一種常見的操作,而這種操作往往會因為資料庫選型導致性能產生巨大差異。
傳統資料庫的解決思路
傳統資料庫的概念模型及查詢的程式碼
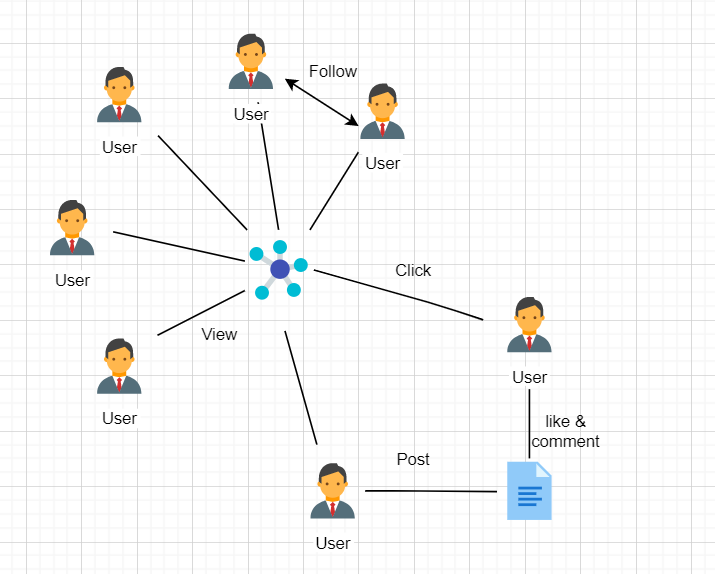
傳統解決上述問題最簡單的方法就是建立一個關係模型,我們可以把每個員工的資訊錄入表中,存在諸如 MySQL 之類的關係資料庫,下圖是最基本的關係模型:
但是基於上述的關係模型,要實現我們的需求,就不可避免地涉及到很多關係資料庫 JOIN 操作,同時實現出來的查詢語句也會變得相當長(有時達到上百行):
(SELECT T.directReportees AS directReportees, sum(T.count) AS count FROM ( SELECT manager.pid AS directReportees, 0 AS count FROM person_reportee manager WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName") UNION SELECT manager.pid AS directReportees, count(manager.directly_manages) AS count FROM person_reportee manager WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName") GROUP BY directReportees UNION SELECT manager.pid AS directReportees, count(reportee.directly_manages) AS count FROM person_reportee manager JOIN person_reportee reportee ON manager.directly_manages = reportee.pid WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName") GROUP BY directReportees UNION SELECT manager.pid AS directReportees, count(L2Reportees.directly_manages) AS count FROM person_reportee manager JOIN person_reportee L1Reportees ON manager.directly_manages = L1Reportees.pid JOIN person_reportee L2Reportees ON L1Reportees.directly_manages = L2Reportees.pid WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName") GROUP BY directReportees ) AS T GROUP BY directReportees) UNION (SELECT T.directReportees AS directReportees, sum(T.count) AS count FROM ( SELECT manager.directly_manages AS directReportees, 0 AS count FROM person_reportee manager WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName") UNION SELECT reportee.pid AS directReportees, count(reportee.directly_manages) AS count FROM person_reportee manager JOIN person_reportee reportee ON manager.directly_manages = reportee.pid WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName") GROUP BY directReportees UNION SELECT depth1Reportees.pid AS directReportees, count(depth2Reportees.directly_manages) AS count FROM person_reportee manager JOIN person_reportee L1Reportees ON manager.directly_manages = L1Reportees.pid JOIN person_reportee L2Reportees ON L1Reportees.directly_manages = L2Reportees.pid WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName") GROUP BY directReportees ) AS T GROUP BY directReportees) UNION (SELECT T.directReportees AS directReportees, sum(T.count) AS count FROM( SELECT reportee.directly_manages AS directReportees, 0 AS count FROM person_reportee manager JOIN person_reportee reportee ON manager.directly_manages = reportee.pid WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName") GROUP BY directReportees UNION SELECT L2Reportees.pid AS directReportees, count(L2Reportees.directly_manages) AS count FROM person_reportee manager JOIN person_reportee L1Reportees ON manager.directly_manages = L1Reportees.pid JOIN person_reportee L2Reportees ON L1Reportees.directly_manages = L2Reportees.pid WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName") GROUP BY directReportees ) AS T GROUP BY directReportees) UNION (SELECT L2Reportees.directly_manages AS directReportees, 0 AS count FROM person_reportee manager JOIN person_reportee L1Reportees ON manager.directly_manages = L1Reportees.pid JOIN person_reportee L2Reportees ON L1Reportees.directly_manages = L2Reportees.pid WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName") ) 這種 glue 程式碼對維護人員和開發者來說就是一場災難,沒有人想寫或者去調試這種程式碼,此外,這類程式碼往往伴隨著嚴重的性能問題,這個在之後會詳細討論。
傳統關係資料庫的性能問題
性能問題的本質在於數據分析面臨的數據量,假如只查詢幾十個節點或者更少的內容,這種操作是完全不需要考慮資料庫性能優化的,但當節點數據從幾百個變成幾百萬個甚至幾千萬個後,資料庫性能就成為了整個產品設計的過程中最需考慮的因素之一。
隨著節點的增多,用戶跟用戶間的關係,用戶和產品間的關係,或者產品和產品間的關係都會呈指數增長。
以下是一些公開的數據,可以反映數據、數據和數據間關係的一些實際情況:
- 推特:用戶量為 5 億,用戶之間存在關注、點贊關係
- 亞馬遜:用戶量 1.2 億,用戶和產品間存在購買關係
- AT&T(美國三大運營商之一): 1 億個號碼,電話號碼間可建立通話關係
如下表所示,開源的圖數據集往往有著上千萬個節點和上億的邊的數據:
| Data set name | nodes | edges |
|---|---|---|
| YahooWeb | 1.4 Billion | 6 Billion |
| Symantec Machine-File Graph | 1 Billion | 37 Billion |
| 104 Million | 3.7 Billion | |
| Phone call network | 30 Million | 260 Million |
在數據量這麼大的場景中,使用傳統 SQL 會產生很大的性能問題,原因主要有兩個:
- 大量 JOIN 操作帶來的開銷:之前的查詢語句使用了大量的 JOIN 操作來找到需要的結果。而大量的 JOIN 操作在數據量很大時會有巨大的性能損失,因為數據本身是被存放在指定的地方,查詢本身只需要用到部分數據,但是 JOIN 操作本身會遍歷整個資料庫,這樣就會導致查詢效率低到讓人無法接受。
- 反向查詢帶來的開銷:查詢單個經理的下屬不需要多少開銷,但是如果我們要去反向查詢一個員工的老闆,使用表結構,開銷就會變得非常大。表結構設計得不合理,會對後續的分析、推薦系統產生性能上的影響。比如,當關係從_老闆 -> 員工 _變成 用戶 -> 產品,如果不支援反向查詢,推薦系統的實時性就會大打折扣,進而帶來經濟損失。
下表列出的是一個非官方的性能測試(社交網路測試集,一百萬用戶,每個大概有 50 個好友),體現了在關係資料庫里,隨著好友查詢深度的增加而產生的性能變化:
| levels | RDBMS execution time(s) |
|---|---|
| 2 | 0.016 |
| 3 | 30.267 |
| 4 | 1543.595 |
傳統資料庫的常規優化策略
策略一:索引
索引:SQL 引擎通過索引來找到對應的數據。
常見的索引包括 B- 樹索引和哈希索引,建立表的索引是比較常規的優化 SQL 性能的操作。B- 樹索引簡單地來說就是給每個人一個可排序的獨立 ID,B- 樹本身是一個平衡多叉搜索樹,這個樹會將每個元素按照索引 ID 進行排序,從而支援範圍查找,範圍查找的複雜度是 O(logN) ,其中 N 是索引的文件數目。
但是索引並不能解決所有的問題,如果文件更新頻繁或者有很多重複的元素,就會導致很大的空間損耗,此外索引的 IO 消耗也值得考慮,索引 IO 尤其是在機械硬碟上的 IO 讀寫性能上來說非常不理想,常規的 B- 樹索引消耗四次 IO 隨機讀,當 JOIN 操作變得越來越多時,硬碟查找更可能發生上百次。
策略二:快取
快取:快取主要是為了解決有具有空間或者時間局域性數據的頻繁讀取帶來的性能優化問題。一個比較常見的使用快取的架構是 lookaside cache architecture。下圖是之前 Facebook 用 Memcached + MySQL 的實例(現已被 Facebook 自研的圖資料庫 TAO 替代):
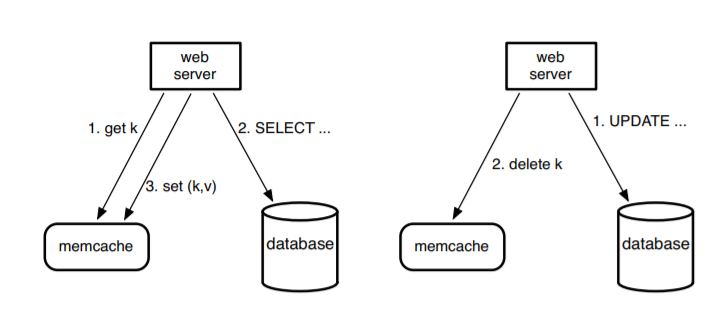
在架構中,設計者假設用戶創造的內容比用戶讀取的內容要少得多,Memcached 可以簡單地理解成一個分散式的支援增刪改查的哈希表,支援上億量級的用戶請求。基本的使用流程是當客戶端需讀數據時,先查看一下快取,然後再去查詢 SQL 資料庫。而當用戶需要寫入數據時,客戶端先刪除快取中的 key,讓數據過期,再去更新資料庫。但是這種架構有幾個問題:
- 首先,鍵值快取對於圖結構數據並不是一個好的操作語句,每次查詢一條邊,需要從快取里把節點對應的邊全部拿出來;此外,當更新一條邊,原來的所有依賴邊要被刪除,繼而需要重新載入所有對應邊的數據,這些都是並發的性能瓶頸,畢竟實際場景中一個點往往伴隨著幾千條邊,這種操作帶來的時間、記憶體消耗問題不可忽視。
- 其次,數據更新到數據讀取有一個過程,在上面架構中這個過程需要主從資料庫跨域通訊。原始模型使用了一個外部標識來記錄過期的鍵值對,並且非同步地把這些讀取的請求從只讀的從節點傳遞到主節點,這個需要跨域通訊,延遲相比直接從本地讀大了很多。(類似從之前需要走幾百米的距離而現在需要走從北京到深圳的距離)
使用圖結構建模
上述關係型資料庫建模失敗的主要原因在於數據間缺乏內在的關聯性,針對這類問題,更好的建模方式是使用圖結構。
假如數據本身就是表格的結構,關係資料庫就可以解決問題,但如果你要展示的是數據與數據間的關係,關係資料庫反而不能解決問題了,這主要是在查詢的過程中不可避免的大量 JOIN 操作導致的,而每次 JOIN 操作卻只用到部分數據,既然反覆 JOIN 操作本身會導致大量的性能損失,如何建模才能更好的解決問題呢?答案在點和點之間的關係上。
點、關聯關係和圖數據模型
在我們之前的討論中,傳統資料庫雖然運用 JOIN 操作把不同的錶鏈接了起來,從而隱式地表達了數據之間的關係,但是當我們要通過 A 管理 B,B 管理 A 的方式查詢結果時,表結構並不能直接告訴我們結果。
如果我們想在做查詢前就知道對應的查詢結果,我們必須先定義節點和關係。
節點和關係先定義是圖資料庫和別的資料庫的核心區別。打個比方,我們可以把經理、員工表示成不同的節點,並用一條邊來代表他們之前存在的管理關係,或者把用戶和商品看作節點,用購買關係建模等等。而當我們需要新的節點和關係時,只需進行幾次更新就好,而不用去改變表的結構或者去遷移數據。
根據節點和關聯關係,之前的數據可以根據下圖所示建模:
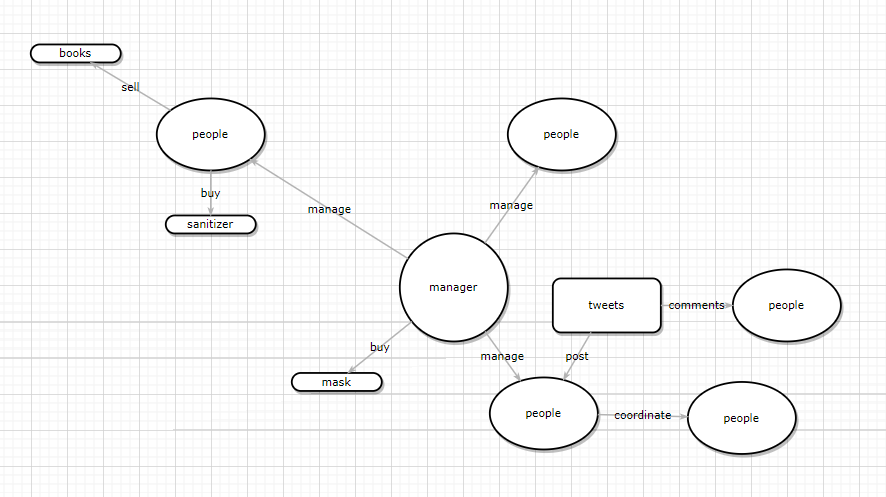
通過圖資料庫 Nebula Graph 原生 nGQL 圖查詢語言進行建模,參考如下操作:
-- Insert People INSERT VERTEX person(ID, name) VALUES 1:(2020031601, 『Jeff』); INSERT VERTEX person(ID, name) VALUES 2:(2020031602, 『A』); INSERT VERTEX person(ID, name) VALUES 3:(2020031603, 『B』); INSERT VERTEX person(ID, name) VALUES 4:(2020031604, 『C』); -- Insert edge INSERT EDGE manage (level_s, level_end) VALUES 1 -> 2: ('0', '1') INSERT EDGE manage (level_s, level_end) VALUES 1 -> 3: ('0', '1') INSERT EDGE manage (level_s, level_end) VALUES 1 -> 4: ('0', '1') 而之前超長的 query 語句也可以通過 Cypher / nGQL 縮減成短短的 3、4 行程式碼。
下面為 nGQL 語句
GO FROM 1 OVER manage YIELD manage.level_s as start_level, manage._dst AS personid | GO FROM $personid OVER manage where manage.level_s < start_level + 3 YIELD SUM($$.person.id) AS TOTAL, $$.person.name AS list 下面為 Cypher 版本
MATCH (boss)-[:MANAGES*0..3]->(sub), (sub)-[:MANAGES*1..3]->(personid) WHERE boss.name = 「Jeff」 RETURN sub.name AS list, count(personid) AS Total 從近百行程式碼變成 3、4 行程式碼可以明顯地看出圖資料庫在數據表達能力上的優勢。
圖資料庫性能優化
圖資料庫本身對高度連接、結構性不強的數據做了專門優化。不同的圖資料庫根據不同的場景也做了針對性優化,筆者在這裡簡單介紹以下幾種圖資料庫,BTW,這些圖資料庫都支援原生圖建模。
Neo4j
Neo4j 是最知名的一種圖資料庫,在業界有微軟、ebay 在用 Neo4j 來解決部分業務場景,Neo4j 的性能優化有兩點,一個是原生圖數據處理上的優化,一個是運用了 LRU-K 快取來快取數據。
原生圖數據處理優化
我們說一個圖資料庫支援原生圖數據處理就代表這個資料庫有能力去支援 index-free adjacency。
index-free adjancency 就是每個節點會保留連接節點的引用,從而這個節點本身就是連接節點的一個索引,這種操作的性能比使用全局索引好很多,同時假如我們根據圖來進行查詢,這種查詢是與整個圖的大小無關的,只與查詢節點關聯邊的數目有關,如果用 B 樹索引進行查詢的複雜度是 O(logN),使用這種結構查詢的複雜度就是 O(1)。當我們要查詢多層數據時,查詢所需要的時間也不會隨著數據集的變大而呈現指數增長,反而會是一個比較穩定的常數,畢竟每次查詢只會根據對應的節點找到連接的邊而不會去遍歷所有的節點。
主存快取優化
在 2.2 版本的 Neo4j 中使用了 LRU-K 快取,這種快取簡而言之就是將使用頻率最低的頁面從快取中彈出,青睞使用頻率更高的頁面,這種設計保證在統計意義上的快取資源使用最優化。
JanusGraph
JanusGraph 本身並沒有關注於去實現存儲和分析,而是實現了圖資料庫引擎與多種索引和存儲引擎的介面,利用這些介面來實現數據和存儲和索引。JanusGraph 主要目的是在原來框架的基礎上支援圖數據的建模同時優化圖數據序列化、圖數據建模、圖數據執行相關的細節。JanusGraph 提供了模組化的數據持久化、數據索引和客戶端的介面,從而更方便地將圖數據模型運用到實際開發中。
此外,JanusGraph 支援用 Cassandra、HBase、BerkelyDB 作為存儲引擎,支援使用 ElasticSearch、Solr 還有 Lucene 進行數據索引。
在應用方面,可以用兩種方式與 JanusGraph 進行交互:
- 將 JanusGraph 變成應用的一部分進行查詢、快取,並且這些數據交互都是在同一台 JVM 上執行,但數據的來源可能在本地或者在別的地方。
- 將 JanusGraph 作為一個服務,讓客戶端與服務端分離,同時客戶端提交 Gremlin 查詢語句到伺服器上執行對應的數據處理操作。
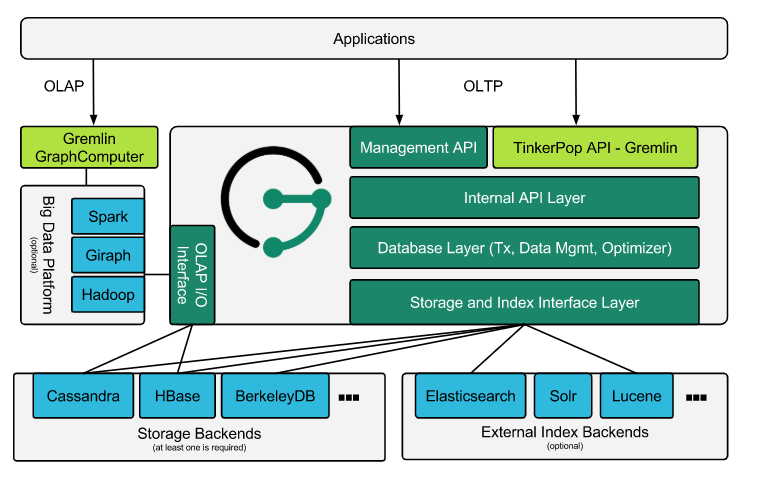
Nebula Graph
下面簡單地介紹了一下 Nebula Graph 的系統設計。
使用 KV 對來進行圖數據處理
Nebula Graph 使用了 vertexID + TagID 作為鍵在不同的 partition 間存儲 in-key 和 out-key 相關的數據,這種操作可以確保在大規模集群上的高可用,使用分散式的 partition 和 sharding 也增加了 Nebula Graph 的吞吐量和容錯的能力。
Shared-noting 分散式存儲層
Storage Service 採用 shared-nothing 的分散式架構設計,每個存儲節點都有多個本地 KV 存儲實例作為物理存儲。Nebula 採用多數派協議 Raft 來保證這些 KV 存儲之間的一致性(由於 Raft 比 Paxo 更簡潔,我們選用了 Raft)。在 KVStore 之上是圖語義層,用於將圖操作轉換為下層 KV 操作。
圖數據(點和邊)通過 Hash 的方式存儲在不同 partition 中。這裡用的 Hash 函數實現很直接,即 vertex_id 取余 partition 數。在 Nebula Graph 中,partition 表示一個虛擬的數據集,這些 partition 分布在所有的存儲節點,分布資訊存儲在 Meta Service 中(因此所有的存儲節點和計算節點都能獲取到這個分布資訊)。
無狀態計算層
每個計算節點都運行著一個無狀態的查詢計算引擎,而節點彼此間無任何通訊關係。計算節點僅從 Meta Service 讀取 meta 資訊,以及和 Storage Service 進行交互。這樣設計使得計算層集群更容易使用 K8s 管理或部署在雲上。
計算層的負載均衡有兩種形式,最常見的方式是在計算層上加一個負載均衡(balance),第二種方法是將計算層所有節點的 IP 地址配置在客戶端中,這樣客戶端可以隨機選取計算節點進行連接。
每個查詢計算引擎都能接收客戶端的請求,解析查詢語句,生成抽象語法樹(AST)並將 AST 傳遞給執行計劃器和優化器,最後再交由執行器執行。
圖資料庫是當今的趨勢
在當今,圖資料庫收到了更多分析師和諮詢公司的關注
Graph analysis is possibly the single most effective competitive differentiator for organizations pursuing data-driven operations and decisions after the design of data capture. ————–Gartner
「Graph analysis is the true killer app for Big Data.」 ——————–Forrester
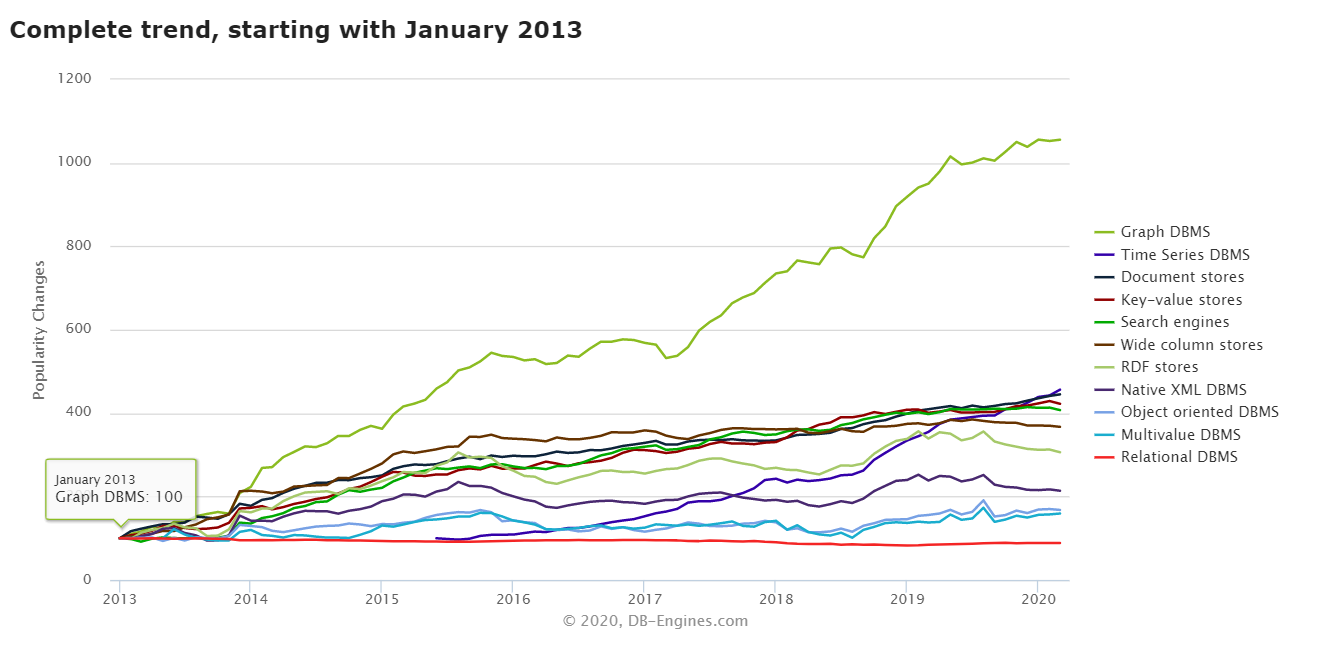
同時圖資料庫在 DB-Ranking 上的排名也呈現出上升最快的趨勢,可見需求之迫切:
圖資料庫實踐:不僅僅是社交網路
Netflix 雲資料庫的工程實踐
Netflix 採用了JanusGraph + Cassandra + ElasticSearch 作為自身的圖資料庫架構,他們運用這種架構來做數字資產管理。
節點表示數字產品比如電影、紀錄片等,同時這些產品之間的關係就是節點間的邊。
當前的 Netflix 有大概 2 億的節點,70 多種數字產品,每分鐘都有上百條的 query 和數據更新。
此外,Netflix 也把圖資料庫運用在了授權、分散式追蹤、可視化工作流上。比如可視化 Git 的 commit,jenkins 部署這些工作。
Adobe 的技術迭代
一般而言,新技術往往在開始的時候大都不被大公司所青睞,圖資料庫並沒有例外,大公司本身有很多的遺留項目,而這些項目本身的用戶體量和使用需求又讓這些公司不敢冒著風險來使用新技術去改變這些處於穩定的產品。Adobe 在這裡做了一個迭代新技術的例子,用 Neo4j 圖資料庫替換了舊的 NoSQL Cassandra 資料庫。
這個被大改的系統名字叫 Behance,是 Adobe 在 15 年發布的一個內容社交平台,有大概 1 千萬的用戶,在這裡人們可以分享自己的創作給百萬人看。
這樣一個巨大的遺留系統本來是通過 Cassandra 和 MongoDB 搭建的,基於歷史遺留問題,系統有不少的性能瓶頸不得不解決。
MongoDB 和 Cassandra 的讀取性能慢主要因為原先的系統設計採用了 fan-out 的設計模式——受關注多的用戶發表的內容會單獨分發給每個讀者,這種設計模式也導致了網路架構的大延遲,此外 Cassandra 本身的運維也需要不小的技術團隊,這也是一個很大的問題。
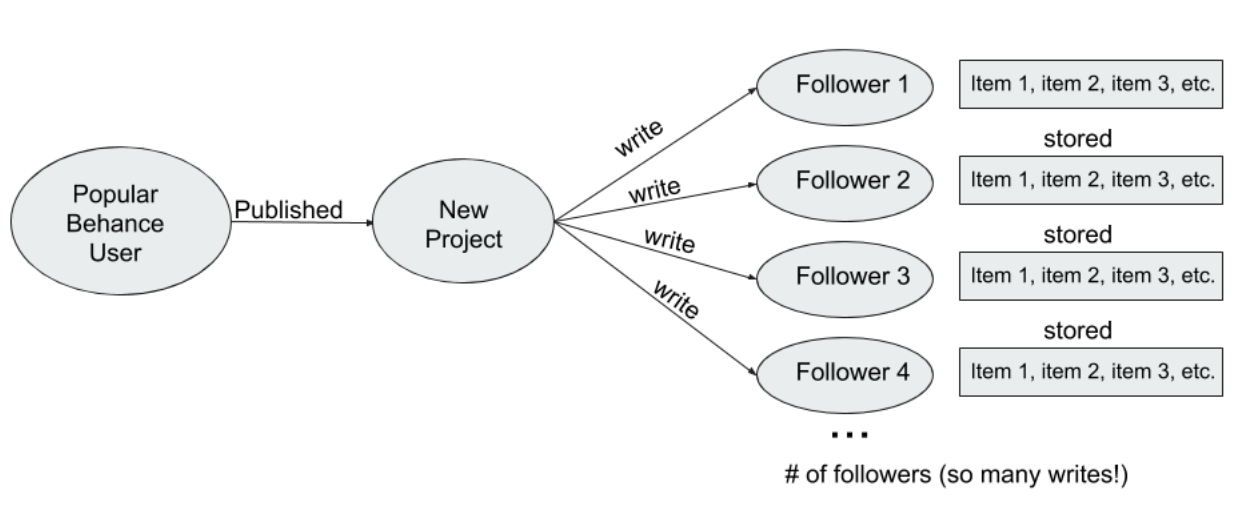
在這裡為了搭建一個靈活、高效、穩定的系統來提供消息 feeding 並最小化數據存儲的規模,Adobe 決定遷移原本的 Cassandra 資料庫到 Neo4j 圖資料庫。
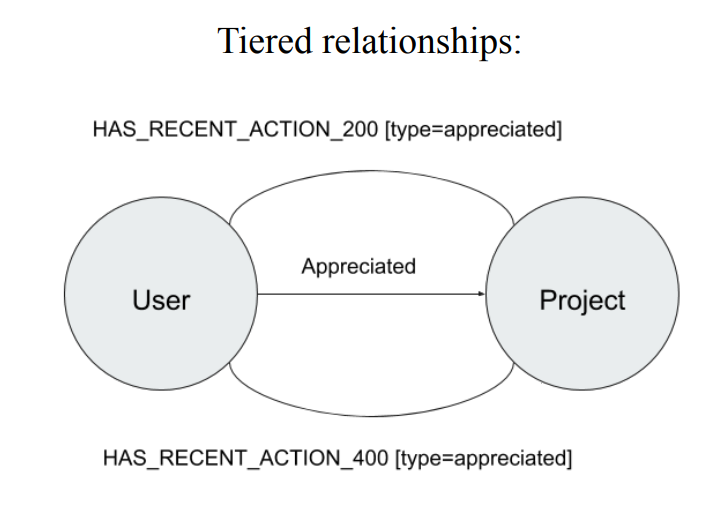
在 Neo4j 圖資料庫中採用一種所謂的 Tiered relationships 來表示用戶之間的關係,這個邊的關係可以去定義不同的訪問狀態,比如:僅部分用戶可見,僅關注者可見這些基本操作。
數據模型如圖所示
使用這種數據模型並使用 Leader-follower 架構來優化讀寫,這個平台獲得了巨大的性能提升:
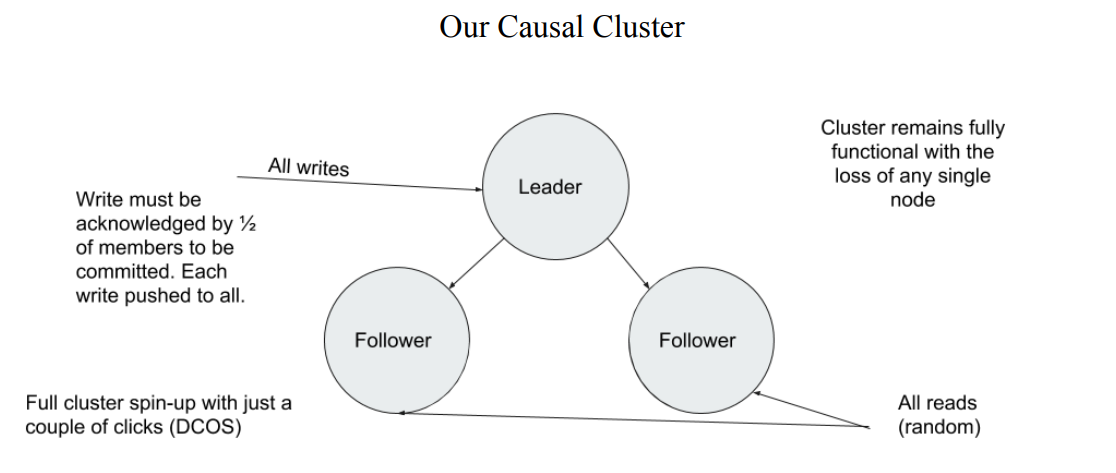
- 運維需求的時長在使用了 Neo4j 以後下降了 300%。
- 存儲需求降低了 1000 倍, Neo4j 僅需 50G 存儲數據, 而 Cassandra 需要 50TB。
- 僅僅需要 3 個服務實例就可以支援整個伺服器的流暢運行,之前則需要 48 個。
- 圖資料庫本身就提供了更高的可擴展性。
結論
在當今的大數據時代,採用圖資料庫可以用小成本在原有架構上獲得巨大的性能提升。圖資料庫不僅僅可以在 5G、AI、物聯網領域發揮巨大的推動作用,同時也可以用來重構原本的遺留系統。
雖然不同的圖資料庫可能有著截然不同的底層實現,但這些都完全支援用圖的方式來構建數據模型從而讓不同的組件之間相互聯繫,從我們之前的討論來看,這一種數據模型層次的改變會極大地簡化很多日常數據系統中所面臨的問題,增大系統的吞吐量並且降低運維的需求。
圖資料庫的介紹就到此為止了,如果你對圖資料庫 Nebula Graph 有任何想法或其他要求,歡迎去 GitHub:https://github.com/vesoft-inc/nebula issue 區向我們提 issue 或者前往官方論壇:https://discuss.nebula-graph.io/ 的 Feedback 分類下提建議 ?;加入 Nebula Graph 交流群,請聯繫 Nebula Graph 官方小助手微訊號:NebulaGraphbot
Reference
- [1] An Overview Of Neo4j And The Property Graph Model Berkeley, CS294, Nov 2015 https://people.eecs.berkeley.edu/~istoica/classes/cs294/15/notes/21-neo4j.pdf
- [2] several original data sources from talk made by Duen Horng (Polo) Chau ( Geogia tech ) www.selectscience.net www.phonedog.com、www.mediabistro.com www.practicalecommerce.com/
- [3] Graphs / Networks Basics, how to build & store graphs, laws, etc. Centrality, and algorithms you should know Duen Horng (Polo) Chau(Georgia tech)
- [4] Graph databases, 2nd Edition: New Oppotunities for Connected Data
- [5] R. Nishtala, H. Fugal, S. Grimm, M. Kwiatkowski, H. Lee, H. C.Li, R. McElroy, M. Paleczny, D. Peek, P. Saab, D. Stafford, T. Tung, and V. Venkataramani. Scaling Memcache at Facebook.In Proceedings of the 10th USENIX conference on Networked
Systems Design and Implementation, NSDI, 2013. - [6] Nathan Bronson, Zach Amsden, George Cabrera, Prasad Chakka, Peter Dimov Hui Ding, Jack Ferris, Anthony Giardullo, Sachin Kulkarni, Harry Li, Mark Marchukov Dmitri Petrov, Lovro Puzar, Yee Jiun Song, Venkat Venkataramani TAO: Facebook’s Distributed Data Store for the Social Graph USENIX 2013
- [7] Janus Graph Architecture https://docs.janusgraph.org/getting-started/architecture/
- [8] Nebula Graph Architecture — A Bird’s View https://nebula-graph.io/en/posts/nebula-graph-architecture-overview/
- [9] database engine trending https://db-engines.com/en/ranking_categories
- [10] Netflix Content Data Management talk https://www.slideshare.net/RoopaTangirala/polyglot-persistence-netflix-cde-meetup-90955706#86
- [11] Harnessing the Power of Neo4j for Overhauling Legacy Systems at Adobe https://neo4j.com/graphconnect-2018/session/overhauling-legacy-systems-adobe
推薦閱讀
作者有話說:Hi,我是 Johhan。目前在 Nebula Graph 實習,研究和實現大型圖資料庫查詢引擎和存儲引擎組件。作為一個圖資料庫及開源愛好者,我在部落格分享有關資料庫、分散式系統和 AI 公開可用學習資源。