證明與計算(7): 有限狀態機(Finite State Machine)
- 2020 年 4 月 1 日
- 筆記

什麼是有限狀態機(Finite State Machine)?
什麼是確定性有限狀態機(deterministic finite automaton, DFA )?
什麼是非確定性有限狀態機(nondeterministic finite automaton, NDFA, NFA)?
[1] wiki-en: Finite state machine
[2] wiki-zh-cn: Finite state machine
[3] brilliant: finite-state-machines
上面的這3個地址里的介紹已經寫的很好了。第3個地址的是一個簡約的FSM介紹,比較實用,而且基本上能讓你區分清楚DFA和NFA。但是本文還是嘗試比較清楚的梳理清楚它們之間的來龍去脈。
0x02 Deterministic finite automaton, DFA
簡單說,DFA包含的是5個重要的部分:
- (Q) = 一個有限狀態集合
- (Sigma) = 一個有限的非空輸入字符集
- (delta) = 一系列的變換函數
- (q_0) = 開始狀態
- (FF) = 接受狀態集合
在有限狀態機的圖裡面,有幾個約定:
- 一個圓圈表示非接受狀態
- 兩個圓圈表示接受狀態
- 箭頭表示狀態轉移
- 箭頭上的字元表示輸入字元
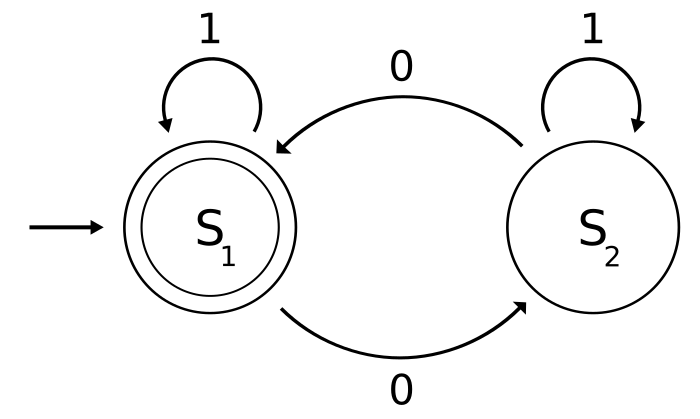
例如下面兩個DFA的圖示:
DFA圖1([3]):
https://upload.wikimedia.org/wikipedia/commons/thumb/9/9d/DFAexample.svg/700px-DFAexample.svg.png

DFA圖2:
https://swtch.com/~rsc/regexp/fig0.png

DFA的特徵是,每個狀態,輸入一個新字元,都有一個唯一的輸出狀態。
例如,DFA圖1和圖2的每個(S_i)在遇到0或者1時輸出的狀態時唯一的。
在DFA圖1中,可以詳細看下買個參數是什麼([3]):
- Q = ({s_1, s_2})
- (Sigma) = {0,1}
- (q_0) = (s_1)
* F = {s_1}
特別的,我們看下轉換函數集合,實際上可以用一個表格來表示([3]):
| 當前狀態 | 輸入狀態|輸出狀態| |
|---|---|
| s1 | 1 |
| s1 | 0 |
| s2 | 1 |
| s2 | 0 |
0x03 Nondeterministic finite automaton, NDFA, NFA
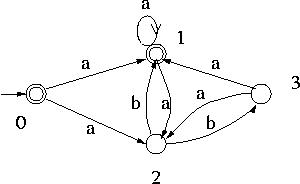
那麼,NFA和DFA的區別是什麼呢?下面兩個NFA的圖示:
NFA圖1:
https://ds055uzetaobb.cloudfront.net/brioche/uploads/zgipUhyx8b-ndfa2.png?width=2400

NFA圖2:
https://swtch.com/~rsc/regexp/fig2.png

NFA的特徵是,和DFA相比:
- 每個狀態,輸入一個新字元,可能有多個不同的輸出狀態。
- 每個狀態,可以接受空輸入字元,用符號(epsilon)表示。
例如NFA圖2里,s2接受輸入字元b之後,可能是s1,也可能是s3。而在NFA圖1里,初始字元可以接受空輸入(epsilon),不消耗任何字元,轉換為b或者e狀態,並且還是個多路分支。
0x04 Regular Expression
[4] wiki-en: Regex Expression
[5] wiki-zh-cn: Regex Expression
[6] Regular Expression Matching Can Be Simple And Fast
正則表達式和DFA/NFA的關係是什麼?我們先看看正則表達式本身。[4]和[5]的wiki里列出了很多正則的表達式符號,但是不如文章[6]簡潔實用。
首先,任何通配符都必須有逃逸字元。正則表達式的逃逸字元是,例如+不表示通配符,而表示的是匹配+字元。
其次,實際上根據[6],正則表達式最重要的通配符就是三個:
e*表示0個或多個ee+表示1個或多個ee?表示0個或1個e
最後,根據[6],正則表達式最基礎的組合方式也就是三個:
e1e2表示e1和e2的拼接e1|e2表示e1或者e2e1(e2e3)表示分組,括弧里的優先順序更高,和括弧在四則運算表達式里的作用一樣
這裡特別提一下,如果上述里的e替換成了一個集合,那麼e*會變成{e1,e2}*,這個叫做集合{e1,e2}的克林閉包(Kleene closure, Kleene operator, Kleene star),下面的兩個wiki介紹了它們的定義:
[7] wiki-en: Kleene closure
[8] wiki-zh-cn: 克林閉包
它的定義是遞歸方式的,令目標集合是V:
- $V_{0}={epsilon }$
- (V_1) = V
- (V_{i+1} = { wv : w ∈ V_i and v ∈ V } for each i > 0.)
從而,V的克林閉包如下:
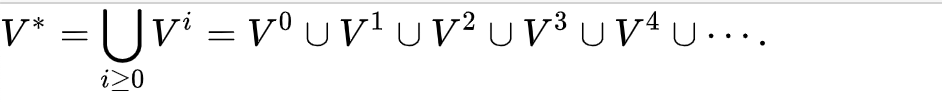
一個克林閉包的例子如下:
{"ab", "c"}* = {ε, "ab", "c", "abab", "abc", "cab", "cc", "ababab", "ababc", "abcab", "abcc", "cabab", "cabc", "ccab", "ccc", …}.
從而,也可以定義克林正閉包(Kleene Plus):
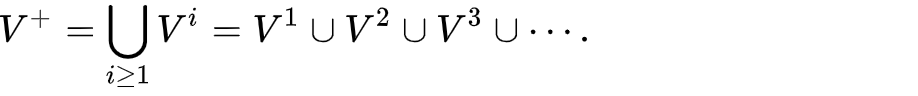
一個克林正閉包的例子如下:
{"a", "b", "c"}+ = { "a", "b", "c", "aa", "ab", "ac", "ba", "bb", "bc", "ca", "cb", "cc", "aaa", "aab", …}.
0x05 Regular Expression 2 NFA
根據文章[4],正則表達式的三個重要的通配符,可以通過如下的方式轉換為對應的NFA,這裡用[s]表示非接受狀態,用[[s]] 表示接受狀態:
表達式 e:
[s]--e--> 表達式 e1e2:
[s]--e1-->[]--e2--> 表達式 e1|e2:
--e1--> / [s] --e2--> 表達式 e?,可以看到它等價於e|(epsilon)
--e--> / [s] ------> 表達式 e*,上半部分本來有輸出箭頭,但是既然它能立刻繞回去上一個狀態(轉N圈),就可以直接從下半部分的箭頭出去
--e-- / | [s] <--- ------> 表達式 e+,我們可以看成是它的等價形式ee*,那麼就是
--e-- / | --e-->[s] <--- ------> 但是我們可以簡化下,把分支上半部分(遇到一個輸入e,合併到左側,因為左側也是表示輸入e然後到狀態[]:
---- ↓ | --e-->[s] ------> 有了這些基本的轉換規則,就可以把正則表達式轉換為NFA,這幾個圖最好自己動手畫一下,不動手可能還是沒有實際的感覺。
0x06 NFA 2 DFA
由於NFA的定義是DFA的超集,一個DFA可以直接看做是一個NFA。
那麼,NFA是否可以轉化為DFA呢?
當然可以,很顯然,對比DFA和NFA的區別,有兩點要做到:
- 需要消滅所有的空輸入 (epsilon)
- 需要合併那些同一個字元的多路分支為一個分支,為了這點,轉換後的DFA的每個狀態是由NFA的狀態構成的集合,例如{a,b}作為一個整體構成轉換後的DFA的一個狀態
[9] nfa-2-dfa example
我們先看一個實際的例子[9],直接手工體驗下這個轉換過程:
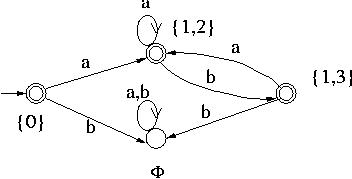
DFA圖3:
https://www.cs.odu.edu/~toida/nerzic/390teched/regular/fa/figures/nfa-dfa1.jpg

目標是找到對應的NFA的5個部分,有2個是現成的,剩下3個:
- 狀態集合Q
- x 輸入字符集合E,這個保持不變
- x 初始狀態q0,這個保持不變
- 轉移函數集合(delta)
- 輸出狀態集合F
第1輪,考慮DFA里的Q第1個元素{}
- 初始化Q={}
- NFA的初始狀態是0,我們把
{0}這個集合,作為一個元素,加入Q,從而:- Q={ {0} }
- NFA里,下一個輸入a後可以是狀態1,也可以是狀態2,也就是(delta)(0, a) = {1, 2}。因此,對應的DFA里:
- Q={ {0},{1,2} }
- (delta)({0}, a) = {1, 2}
- NFA里,(delta)(0, b) = {},因此空集被加入到DFA的Q里:
- Q = { {},{0},{1,2} }
- (delta)({0}, a) = {1, 2}, (delta)({0}, b) = {}
第2輪,考慮DFA里Q的第2個元素{1,2}
- 此時{1,2}在DFA的Q里,考慮從{1,2}這個元素出發會到哪裡
- NFA里,(delta)(1, a) = {1, 2}, (delta)(2, a) = {},從而
- DFA里新增 (delta)({1,2}, a) = {1,2}, Q 則保持不動:
- Q = { {},{0},{1,2} }
- (delta)({0}, a) = {1, 2}, (delta)({0}, b) = {}, (delta)({1,2}, a) = {1,2}
- DFA里新增 (delta)({1,2}, a) = {1,2}, Q 則保持不動:
- NFA里(delta)(1, b) = {}, (delta)(2, b) = {1,3},從而
- DFA里新增 (delta)({1,2}, b) = {1,3}, Q 新增{1,3}:
- Q = { {},{0},{1,2},{1,3} }
- (delta)({0}, a) = {1, 2}, (delta)({0}, b) = {}, (delta)({1,2}, a) = {1,2}, (delta)({1,2}, b) = {1,3}
- DFA里新增 (delta)({1,2}, b) = {1,3}, Q 新增{1,3}:
第3輪,考慮DFA里Q的新增元素{1,3}
- NFA里,(delta)(1, a) = {1, 2}, (delta)(3, a) = {1, 2}
- DFA新增(delta)({1,3}, a) = {1, 2}, Q 則保持不動
- Q = { {},{0},{1,2},{1,3} }
- (delta)({0}, a) = {1, 2}, (delta)({0}, b) = {}, (delta)({1,2}, a) = {1,2}, (delta)({1,2}, b) = {1,3}, (delta)({1,3}, a) = {1, 2}
- DFA新增(delta)({1,3}, a) = {1, 2}, Q 則保持不動
- NFA里,(delta)(1, b) = {}, (delta)(3, b) = {}
- DFA新增(delta)({1,3}, b) = {}, Q 則保持不動
- Q = { {},{0},{1,2},{1,3} }
- (delta)({0}, a) = {1, 2}, (delta)({0}, b) = {}, (delta)({1,2}, a) = {1,2}, (delta)({1,2}, b) = {1,3}, (delta)({1,3}, a) = {1, 2}, (delta)({1,3}, b) = {}
- DFA新增(delta)({1,3}, b) = {}, Q 則保持不動
- 沒有新的狀態,結束,由於0和1是NFA的接受狀態,Q裡面有含有0和1的狀態是DFA的接受狀態,也就是F={ {0}, {1,2}, {1,3} }
至此,整個轉換結束,對應的DFA:
- 狀態集合:Q = { {},{0},{1,2},{1,3} }
- 轉移函數:(delta)({0}, a) = {1, 2}, (delta)({0}, b) = {}, (delta)({1,2}, a) = {1,2}, (delta)({1,2}, b) = {1,3}, (delta)({1,3}, a) = {1, 2}, (delta)({1,3}, b) = {}
- 輸出狀態集合:F={ {0}, {1,2}, {1,3} }
則轉換後的DNA如圖:
https://www.cs.odu.edu/~toida/nerzic/390teched/regular/fa/figures/dfa1.jpg

有了這個手工操作的經驗,上面這個例子裡面,反覆做一個動作:
- 得到一個新的DFA元素,例如{1,2}
- 考慮它接受一個輸入,例如b,分別
- 考慮狀態1接受b的轉移狀態集合,{}
- 考慮狀態2接受b的轉移狀態集合, {1,3}
- 因此,{1,2}接受b後,轉換到{1,3}
太啰嗦了,我們做一些簡化:
- 把轉換後的DFA的元素標記為大寫字母,例如T={1,2}, U={1,3};
- 把上面這個操作過程寫成一個函數:move(T,b)
- 那麼上面這個過程就是:
move(T,b)=U - 這個過程就是表示找到所有T里的元素在NFA里經過輸入b後能直接到達的狀態的集合U
進一步,如果在NFA里,某個s狀態經過空轉換(epsilon)能到達的集合,我們標記為(epsilon)-closure(s)。
例如:
-----> [1] / [0] ------> [2] 那麼,(epsilon)-closure(0) = {1,2}
進一步
---->[3] / -----> [1]----->[4] / [0] ------> [2] 那麼,(epsilon)-closure(0) = {1,2,3,4}
這麼看來,(epsilon)閉包是不是很形象。
有了(epsilon)-closure(s),我們當然可以對DFA里的T的每個元素做(epsilon)-closure,於是就可以定義:
- (epsilon)-closure(T) = T里所有元素ti的(epsilon)-closure(ti)的並集。
那麼,我們上面的手工操作move(T,a),之後,如果對應的NFA里也有(epsilon),我們要達到最開始的轉換NFA到DFA的兩個目標之一:
- 需要消滅所有的空輸入 (epsilon)
我們就需要對上面討論過的這個過程做升級:
- 找到所有T里的元素在NFA里經過輸入b後能直接到達的狀態的集合U
也就是去掉直接兩個字,升級成:
- 找到所有T里的元素在NFA里經過輸入b後能到達的狀態的集合U
實際上,通過上面的討論,經過燒腦,是可以理解到這個過程就是一個複合動作:
- (epsilon)-closure(move(T,b))
於是,再經過燒腦,我們可以得到NFA轉換成DFA的子集構造法(subset construction)演算法:
- T0=(epsilon)-closure(q0); DFAState={}, DFAState[T0]=false; DFATransitioin={};
- 其中q0是NFA的初始狀態
- 賦值為false,表示它還沒有被標記
- 開始循環
- 取出Q里的一個沒有標記的元素,例如T。DFAState[T]=true立刻標記它,表示處理過了。
- 如果都標記了,退出循環
- 對輸入的每個字元a
- 計算U=(epsilon)-closure(move(T,a))
- 如果U不在DFAState裡面,就加入:DFAState[U]=false;
- 加入轉換函數:DFATransitioin[T,a]=U
- 繼續循環
- 取出Q里的一個沒有標記的元素,例如T。DFAState[T]=true立刻標記它,表示處理過了。
從而,正則表達式可以轉成NFA,再進一步轉成DFA,實際上NFA轉成NFA後,最糟的情況,原來需要n個狀態,DFA需要2^n個狀態(因為n個狀態的冪子集的每個元素都可能是DFA的接受狀態)。
為了加深印象,可以在這個在線工具里輸入正則表達式直接看到對應的NFA和DFA的結果:
[10] Regex => NFA => DFA – CyberZHG
0x07 Use State Machines
由於從Regex Expression到NFA到DFA,裡面有一個地方是輸入是用字元串的字元表示。會讓人以為只有正則表達式需要DFA和NFA。
而實際上,我們可以在任何需要使用狀態轉換的地方用NFA和DFA。很自然的,需要考慮這些概念:
- 有哪些狀態?應該定義哪些狀態?例如一個操作最簡單的有Init/UnInit兩種狀態。
- 輸入是什麼?程式里的輸入是「行為」,可能是用戶點擊,也可能是某個事件到達,在這些場景,你需要抽象這些輸入,可以看成不同的「字元」,也可以根據它們需要轉換的狀態,看成是同一個「字元」。
- 輸出是什麼?當然是另外一個狀態了。
- 跟正則表達式什麼關係?
- 看法1: 沒有關係,我們只關心狀態轉換是否是在允許的操作內,如果不是就是程式出現某種「未定義」行為,直接報錯。這是消除Bugly的良方。
- 看法2: 一個由某些輸入字元構成的字元串,表示了由UI操作、事件構成的操作序列,如果匹配,則表示這些操作集合是合法的,否則就是中間某個步驟是「未定義的」。
如何更好的寫一個DFA構成的狀態機程式碼?這裡有一個Unity3D框架里的狀態機的開發解釋,很清晰的構架:
[11] Unity3D里的FSM(Finite State Machine)有限狀態機
下面我們看一個例子,在實踐上,如何設計狀態機的轉換。
首先,經過考慮,設計一組狀態:
- S={INIT,STARTING, PLAYING, STOP, ERROR}
其次,考慮每個狀態可以到達哪些狀態:
- INIT -> [ STARTING ], 初始狀態可以到達開始中
- STARTING -> [PLAYING, ERROR],開始中狀態可以到達遊玩中或者出錯
- PLAYING -> [STOP, ERROR], 遊玩中可以到達停止或出錯
- ERROR -> [STOP],出錯狀態,做好出錯處理後停止
- STOP -> [INIT],結束狀態應該可以重置成初始化狀態
因此,考慮初始和停止狀態:
- 初始狀態:INIT
- 停止狀態集合:[STOP]
那麼,可以逆向計算每個狀態允許的前置狀態集合(enableStates):
- INIT: [STOP]
- STARTING: [INIT]
- PLAYING: [STARTING]
- STOP: [PLAYING, ERROR]
- ERROR: [STARTING, PLAYING]
練習題1:在這個狀態轉換中,Q、E、(Sigma),q_0, F 分別是什麼?
練習題2:它是DFA,還是NFA?
練習題3:如果是NFA,它有空輸入轉換么?
練習題4:如果是NFA,試下轉成DFA?
練習題5:畫出NFA/DFA的轉換圖。
實踐中,我們會按需寫如下的狀態轉換函數,程式碼只是示例:
function EnterState(toState, onPreEnter, onAction, onPostEnter){ const fromState = this.state; if(enableStates[fromState].includes(toState)){ onPreEnter(fromState, toState); this.state = toState; onPreEnter(fromState, toState); return true; }else{ // log return false; } } 實際上,如果考慮輸入字元後,可以做一個更完備的版本:
function enableToState(fromState, context){ // 把context轉換成抽象的字元 const c = convertToAplha(fromState, context); // 根據fromState和c找到對應的可能輸出集合 const toState = DFATransitioin(fromState, c); return toState; } function EnterState(toState, onPreEnter, onAction, onPostEnter){ const fromState = this.state; if(enableToState(fromState, context).includes(toState)){ onPreEnter(fromState, toState); this.state = toState; onPreEnter(fromState, toState); return true; }else{ // log return false; } } 根據實際需要,可以做的簡單,也可以做的細緻,不同層度上保證程式的正確性。但是實際上,狀態機在網路協議的開發中比較常見,例如經典的TCP狀態轉換圖:
[13] rfc-793:TRANSMISSION CONTROL PROTOCOL

有限狀態機很有用,可是為什麼大部分程式設計師平常寫程式沒用到它呢?
[12] Why Developers Never Use State Machines
We seem to shy away from state machines due to misunderstanding of their complexity and/or an inability to quantify the benefits. But, there is less complexity than you would think and more benefits than you would expect as long you don』t try to retrofit a state machine after the fact. So next time you have an object that even hints at having a 「status」 field, just chuck a state machine in there, you』ll be glad you did.
這篇文章分析了可能的原因:「高估了它的複雜,以及低估了它的好處」,我覺的很有道理,特別是我發現在UI項目里使用嚴格的狀態機管理狀態後,程式的問題更容易被trace,也更能保證程式正確之後,我發現狀態機確實好用。
0x08 How using good theory leads to good programs?
而在這篇介紹Thompson NFA的文章里,作者的兩段話很有意思:
[6] Regular Expression Matching Can Be Simple And Fast
Historically, regular expressions are one of computer science’s shining examples of how using good theory leads to good programs. They were originally developed by theorists as a simple computational model, but Ken Thompson introduced them to programmers in his implementation of the text editor QED for CTSS. Dennis Ritchie followed suit in his own implementation of QED, for GE-TSS. Thompson and Ritchie would go on to create Unix, and they brought regular expressions with them. By the late 1970s, regular expressions were a key feature of the Unix landscape, in tools such as ed, sed, grep, egrep, awk, and lex.
Today, regular expressions have also become a shining example of how ignoring good theory leads to bad programs. The regular expression implementations used by today’s popular tools are significantly slower than the ones used in many of those thirty-year-old Unix tools.
這值得我們思考,程式是什麼?
–end–



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}