爬蟲&Selenium&ChromeDriver
- 2020 年 4 月 1 日
- 筆記
一、Selenium
- selenium是什麼
Selenium [1] 是一個用於Web應用程式測試的工具。Selenium測試直接運行在瀏覽器中,就像真正的用戶在操作一樣。支援的瀏覽器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。
在python爬蟲可以簡單的理解為:Selenium就是模仿人使用瀏覽器
-
如何下載或者是安裝selenium
cmd進入win終端,輸入命令
pip install selenium
二、ChromeDriver
-
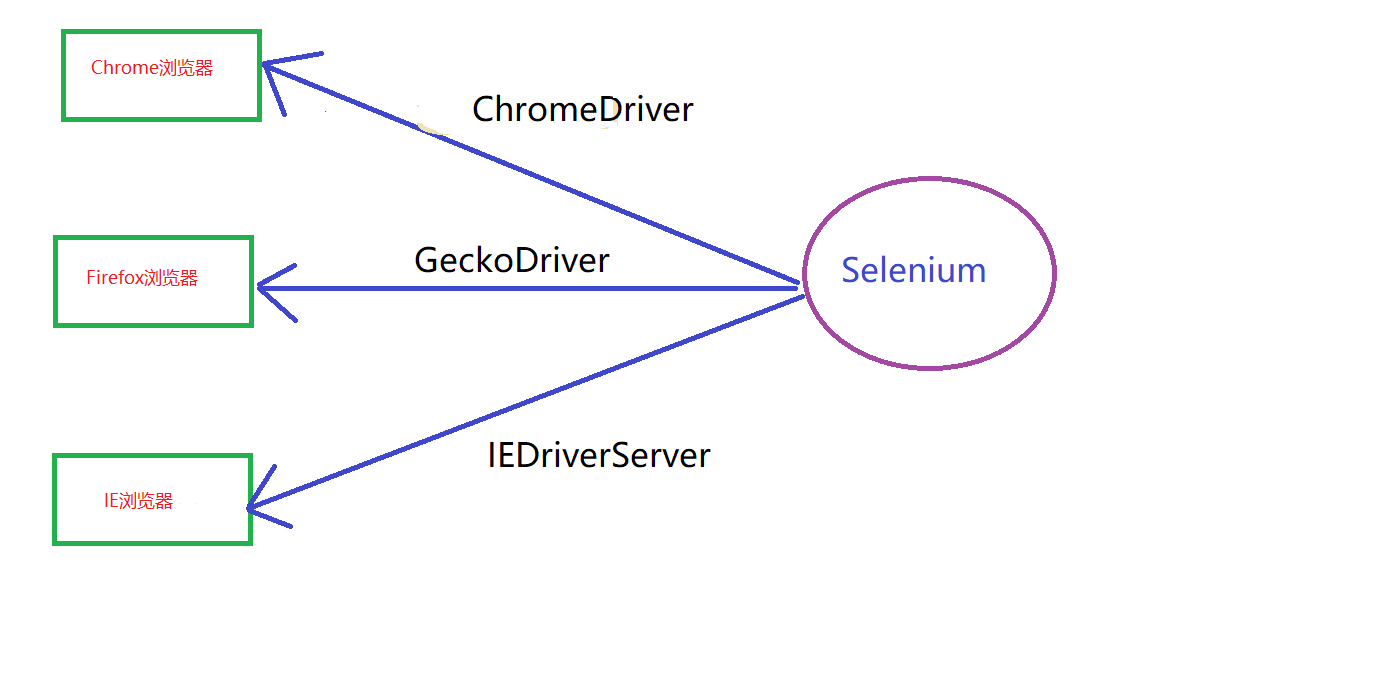
ChromeDrive是什麼
這個和JDBC類似,就是Selenium操作Chrome瀏覽器的驅動。同理Selenium操作Firefox瀏覽器就需要geckodriver,操作IE瀏覽器需要IEDriverServer驅動。
-
如何下載或者安裝ChromeDriver
注意:ChromeDriver要和自己使用的chrome版本一致
注意:ChromeDriver要和自己使用的chrome版本一致
注意:ChromeDriver要和自己使用的chrome版本一致2.1 查詢自己chrome的版本
地址欄輸入:
chrome://version/
比如我的是:80.0.3987.149
2.2 下載ChromeDriver
地址欄:
https://npm.taobao.org/mirrors/chromedriver/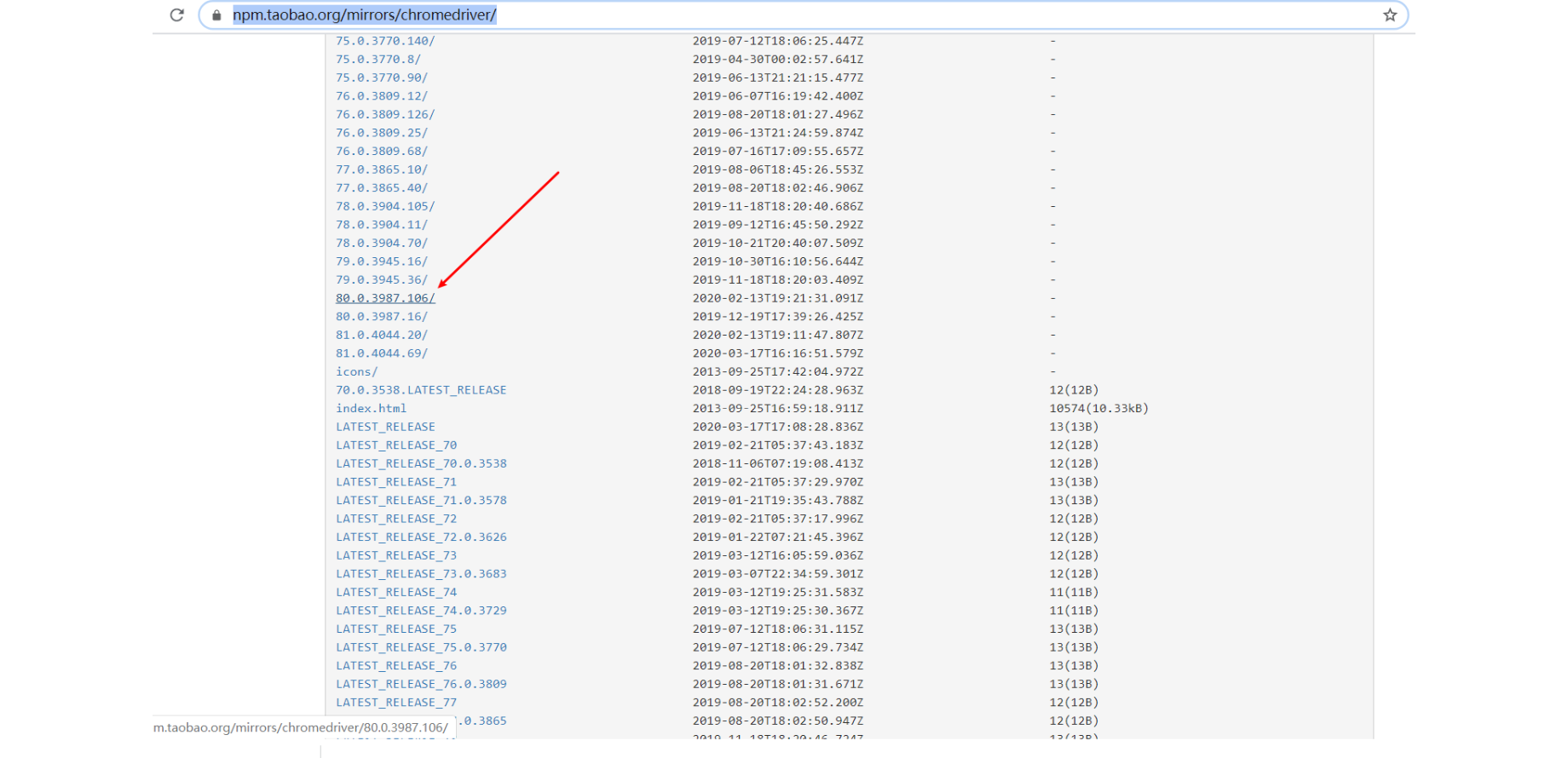
這裡可能有人要問,不是最後一位不一樣嗎?
答:的卻,但是我估計只要前三位相同應該都可以的。有興趣的同學可以試一下哈
點擊進去,下載對應的OS版本,比如我的是win電腦,我就下載第三個。
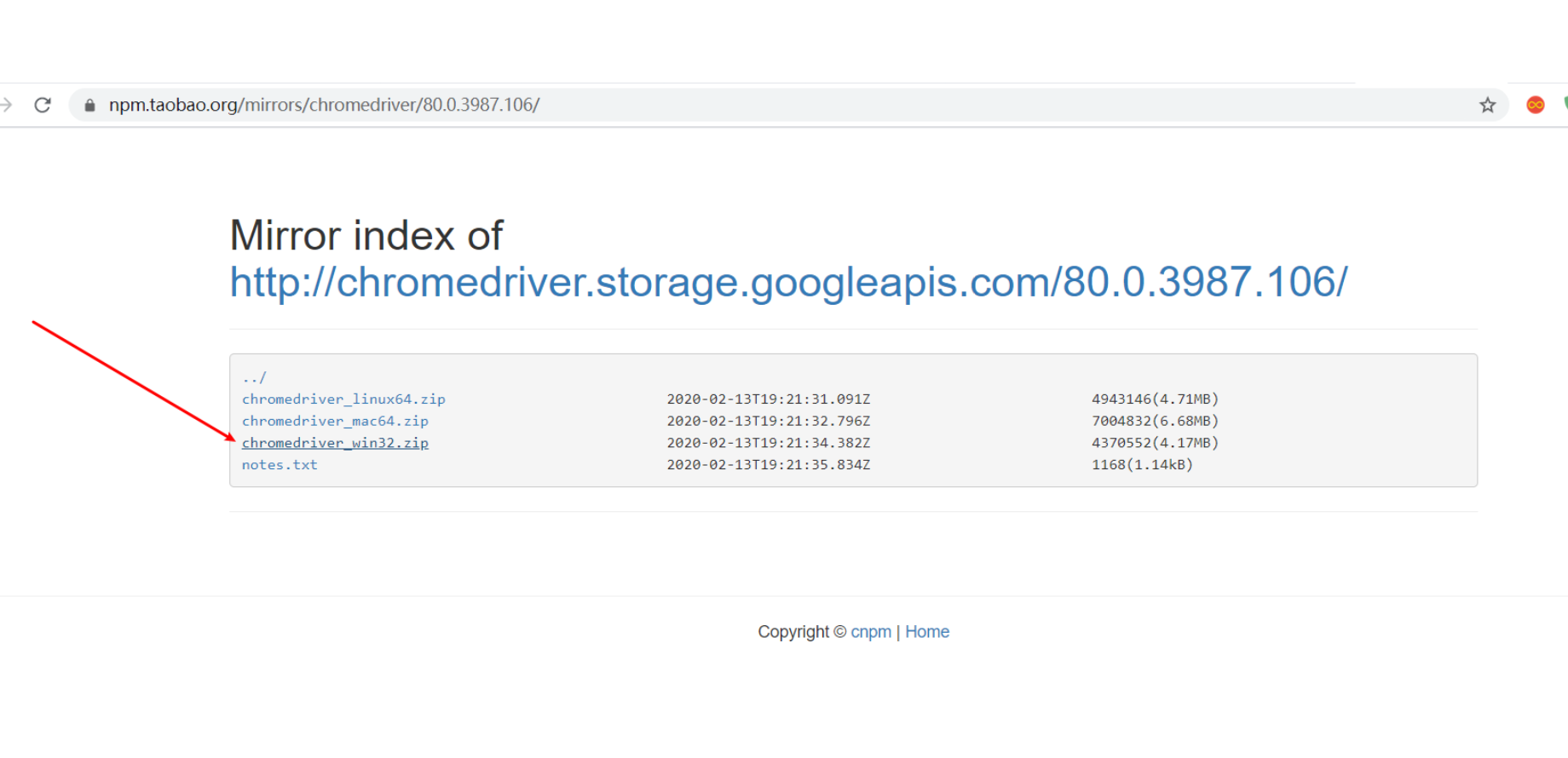
2.3 下載好之後,解壓,把chromedriver.exe放到任意位置都可以。但是有要求:
- 路徑上不能有中文
- 存放的路徑不需要特殊許可權
這樣就可以了,接下來我們來測試一下。
三、測試
-
直接看程式碼
from selenium import webdriver #導入必要的庫 #功能需求:模仿人類使用搜索框進行搜索 # 業務分析:在搜索框中輸入「關鍵字」,點擊「百度一下」或者是「回車」 #chromedriver.exe的存放路徑 driver_path=r"C:Program Files (x86)GoogleChromeApplicationchromedriver.exe" # 通過webdriver對象的Chrome方法【不同的瀏覽器對應不同的方法】,獲取到chromedriver.exe driver = webdriver.Chrome(executable_path=driver_path) # 訪問百度 driver.get("http://www.baidu.com") # 根據頁面的id值定位到搜索框的 input_tag = driver.find_element_by_id("kw") #假如我們搜索「java」 input_tag.send_keys("java") # 根據頁面id獲取到「百度一下」按鈕 submit_btn = driver.find_element_by_id("su") #這個方法其實就是模仿人們點擊「百度一下」按鈕或者是「回車」 submit_btn.click() -
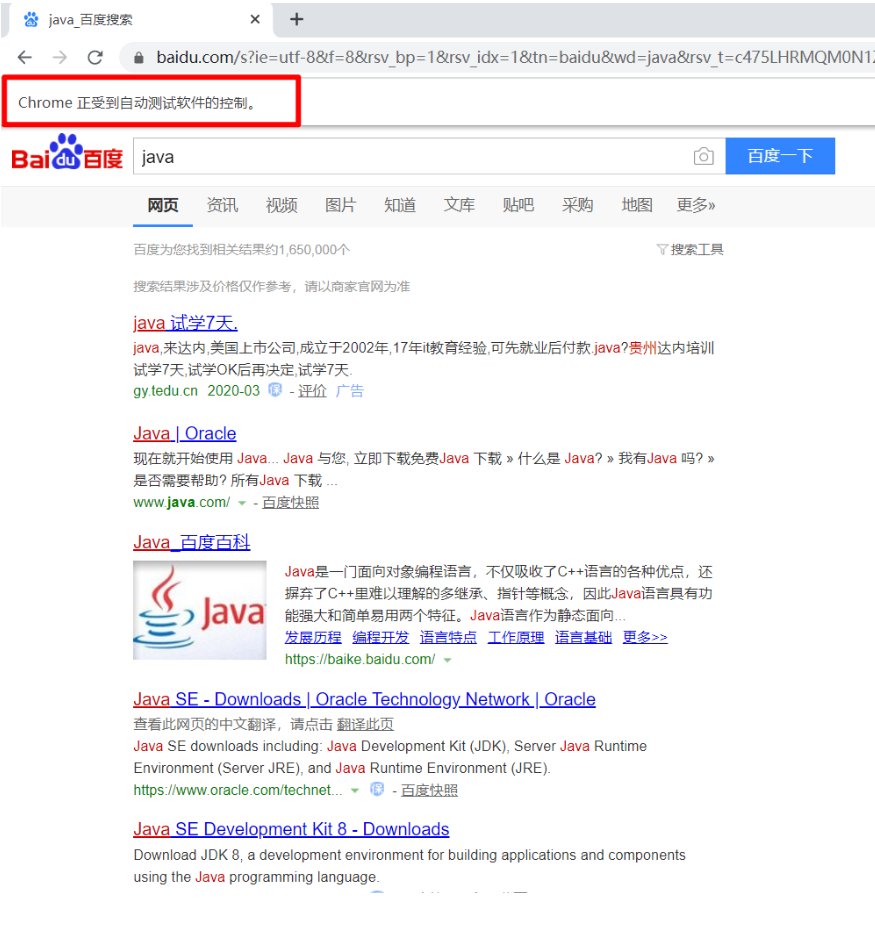
運行程式碼。它會自動打開瀏覽器並自動輸入「java」,並回車。
-
看效果
四、為什麼要用它——Selenium
答:因為有很多網站的數據都是非同步請求(Ajax)載入數據的,我們直接爬取是獲取不到數據的。因此我們使用selenium爬取返回來的頁面是已經經過瀏覽器解析好的頁面,我們再通過使用Xpath、bs4等,就可以爬取自己想要的數據了。