MySQL對JSON類型UTF-8編碼導致中文亂碼探討
- 2020 年 3 月 30 日
- 筆記
前言
繼上文發表之後,結合評論意見並親自驗證最終發現是編碼的問題,但是對於字元編碼還是有點不解,於是乎,有了本文,我們來學習字元編碼,在學習的過程中,我發現對於MySQL中JSON類型的編碼導致數據中文出現亂碼還有可深挖之處,接下來我們來分析一下,若有錯誤之處,還請批評指出。
字元編碼
評論中指出任何不在基本多文本平面的Unicode字元,都無法使用MySQL的utf8字符集存儲,包括Emoji 表情(Emoji 是一種特殊的Unicode 編碼,常見於IOS和Android 手機上)和很多不常用的漢字,以及任何新增的 Unicode 字元等等(utf8的缺點),然而啥是多文本平面,詳情維基百科《https://en.wikipedia.org/wiki/Plane_(Unicode)》。首先我們了解下什麼是Unicode,Unicode是通用字符集,它是一種標準,該標準在一處定義了編寫在電腦上使用的大多數活動語言所需的所有字元,它的目標是成為並且在很大程度上已經是已編碼的所有其他字符集的超集。在電腦或網路中的文本我們通過字元組成,字元代表字母、標點符號或其他符號。不同的組織收集了不同的字符集並為其創建了編碼-一個字符集可能僅覆蓋基於拉丁語的西歐語言(不包括保加利亞或希臘等歐盟國家),另一個可能覆蓋特定的遠東語言(例如(例如日語),其他語言可能是以特殊方式設計的,代表世界上某處其他語言的眾多語言之一。但是我們並不能保證應用程式將支援所有編碼,也不能保證給定的編碼將滿足我們代表給定語言的所有需求,另外,通常不可能在同一網頁或資料庫中組合不同的編碼,因此使用“傳統”編碼方法來支援多語言頁面通常非常困難,所以Unicode協會提供了一個大的,單位元組字符集,旨在包括所有需要的世界上任何書寫系統,包括古老的腳本(如楔形文字,哥特式和埃及的象形文字)的字元,所以統一字元編碼,將其作為Web和作業系統體系結構的基礎,並且得到所有主要Web瀏覽器和應用程式的支援。當前的Unicode字元分為17組編排,每組被稱之為一個平面(Plane),所以將字元劃分為0-16號的平面,而每平面擁有65536(即216)個程式碼點即範圍區間在0x000到0xFFFF之間,而0號平面就是基本多語言平面(BMP:Basic Mutiingual Plane)。在基本多文本平面上針對每一種文字或者其補充或者其擴展都給出了一個編碼範圍,比如拉丁文【0000-007F】,拉丁文-補充【0080-00FF】等等。說了這麼多,我們只需要記住一點即可:在Unicode字符集中前65536個程式碼點構成了基本多語言平面簡稱BMP,BMP中包含了大多常用的字元,另外Unicode字符集還包含了一百萬個其他程式碼點的位置空間,我們稱之為補充字元。我們需要區分字符集、編碼字符集和編碼的概念,字符集或字元串包含可能用於特定目的的字符集,它是支援電腦上的西歐語言所需的字符集,與電腦完全無關,而編碼字符集是一組用於該唯一的號碼被分配給每個字元的字元,有時候我們將編碼字符集也可稱作為程式碼頁,編碼字符集的單位稱為程式碼點,程式碼點值表示字元在編碼字符集中的位置。例如,Unicode編碼字符集中字母á的程式碼點為十進位225,十六進位表示法為0xE1。而字元編碼反映編碼字符集被映射到用於在電腦操縱位元組的方式。一個字符集可以有多種編碼,許多字元編碼標準,例如ISO 8859系列中定義的標準,都為給定字元使用單個位元組,並且編碼是對編碼字符集中字元標量位置的直接映射。例如,ISO 8859-1編碼字符集中的字母A在第65個字元位置(從零開始),並且使用值為65的位元組進行編碼並以此在電腦中表示,對於ISO 8859-1而言,這將永遠不會再改變,但是,對於Unicode,事情並沒有如此簡單,儘管Unicode編碼字符集中字母á的程式碼點始終為225(十進位),但在UTF-8中,它在電腦中由兩個位元組表示,換句話說,在此字元的編碼字符集值和編碼值之間不是簡單的一對一映射,另外,在Unicode中,針對同一字元可以有多種編碼的方式。例如,字母á可以用一種編碼形式的兩個位元組表示,而用另一種編碼形式的四個位元組表示。可以與Unicode一起使用的編碼形式稱為UTF-8,UTF-16和UTF-32。
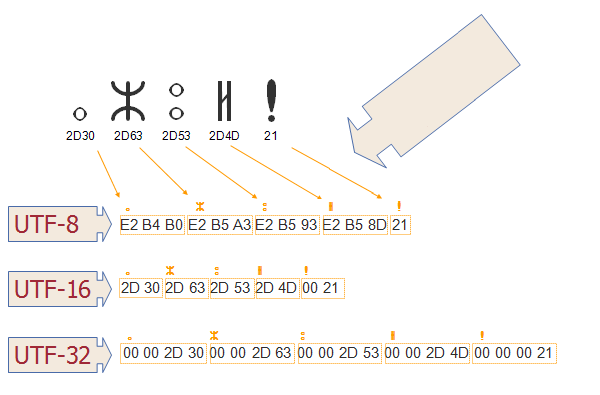
UTF-8使用1個位元組表示ASCII集中的字元,使用2個位元組表示其他幾個字母塊中的字元,使用3個位元組表示BMP的其餘部分,補充字元使用4個位元組。UTF-16對BMP中的任何字元使用2個位元組,對補充字元使用4個位元組。UTF-32對所有字元使用4個位元組。基本多語言平面對應程式碼點存儲的是常用字元,上述針對不同字元在其對應程式碼點,然後計算出該字元的16進位的字元串,舉個栗子,將【好】字進行UTF-8編碼看看該字元的位元組值和位元組數,如下:
var bytes = Encoding.UTF8.GetBytes("好"); var hexString = BitConverter.ToString(bytes);

到此我們大概了解完了字元編碼,接下來我們再次回到上一節的問題,上一節將我姓名作為JSON存儲到資料庫中去,但是最終獲取數據時,將出現亂碼,因為其表編碼為utf8,最終將表編碼修改為utf8mb4才好使,為啥utf8就不行呢?通過上述對utf8的定義最多可以有4個位元組,支援補充字元,所以MySQL根本就沒有實現標準的utf8編碼,換句話說只是部分實現了utf8編碼,MySQL中的utf8又名為utf8mb3,也就是一個字元最多可通過3個位元組表示且包含BMP字元,而不包含補充字元。所以無論是我的姓還是名雖然是3個位元組,但是並非常用BMP字元導致。但是針對列類型為JSON類型,事實是對於獲取中文真的會亂碼嗎?上文我用到的MySQL版本為5.7+,如下:

接下來我們利用MySQL 8.0再來進行測試發現不會亂碼,創建類和表配置編碼如下:

public class t1 { public int id { get; set; } public string jdoc { get; set; } }


static void Main(string[] args) { SetDialect(Dialect.MySQL); var con = new MySqlConnection(@"Server=localhost;Database=user;Uid=root;Pwd=root;"); var id = con.Insert(new t1() { jdoc = JsonConvert.SerializeObject(new { Data = "汪鵬" }) }); var result = con.QueryFirstOrDefault<t1>("select * from t1 where id = @id", new { id }); Console.ReadKey(); }

隨著移動端的興起,有了表情的出現,所以從MySQL 5.5.3開始,引入utf8mb4字符集每個字元最多可使用4個位元組,支援補充字元,對於BMP字元,utf8 [utf8mb3]和utf8mb4具有相同的存儲特徵:相同的程式碼值,相同的編碼,相同的長度,對於補充字元,utf8 [utf8mb3]根本無法存儲該字元,而utf8mb4需要4個位元組來存儲它,由於utf8 [utf8mb3]根本無法存儲字元,因此在utf8 [utf8mb3]列中沒有任何補充字元。接下來我們在針對JSON類型配置為utf8編碼的情況下,我們來插入表情,此時會發現也是可以的。我們是可以獲取對應字元的位元組數,比如如下哭笑不得的表情為4個位元組:
var emotion = Encoding.UTF8.GetByteCount("?");


其實針對JSON類型獲取數據亂碼的情況早就有人提出過相關bug,詳見地址《https://bugs.mysql.com/bug.php?id=81677》,不過官方一直沒有任何回復,至少通過上述測試出來的結果對於utf8存儲表情也可以,到底具體情況咋回事,我們還是看看8.0版本以對utf8編碼描述為準,詳情請見《https://dev.mysql.com/doc/refman/8.0/en/charset-unicode.html》,對於utf8編碼的描述依然還是最多可存儲3個位元組,如下:

別忘記,還有注意:utf8[utf8mb3]字符集已被棄用,並會在將來的MySQL版本中移除,請改用utf8mb4,儘管utf8當前是utf8mb3的別名,但在某些時候utf8將成為對utf8mb4的引用,為避免對utf8的含義含糊不清,請考慮為字符集引用顯式指定utf8mb4而不是utf8。所以到此我們已明了,針對8.0版本中的utf8編碼雖說最多可支援3個位元組,但是,會將utf8成為utf8mb4的引用,如此就不難理解為何上述將表配置為utf8編碼時,對於JSON類型的不在常用BMP字元進行數據存儲和表情皆沒問題。
總結
通過此文對utf8編碼的JSON類型的數據出現中文亂碼的問題的學習才算告一段落, 原來版本問題使得utf8存在對utf8mb4編碼的引用,知其然,知其所以然,嗯,大概是這麼個道理。發表部落格的好處就在這裡,沒有批評和指正,哪來的更進一步呢。