《面試經典系列》- MySQL資料庫存儲引擎
- 2020 年 3 月 29 日
- 筆記
一、MySQL有多少種存儲引擎?
在MySQL5之後,支援的存儲引擎有十多個,但是我們常用的就那麼幾種,而且,默認支援的也是 InnoDB。
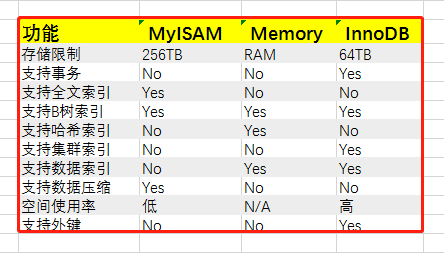
通過命令:show engines g,我們可以查看到當前資料庫可以支援的存儲引擎有哪些。MySQL默認支援了9種,其中,有3種是我們最常見的。如下圖:
二、你們項目中使用MySQL的搜索引擎是哪個?為什麼要用這個?
我們使用的是 InnoDB。
1、InnoDB
InnoDB是默認的資料庫存儲引擎,主要特點有:
a、可以自動增長列,方法是:auto_increment。
b、支援事務。默認的事務隔離級別是可重複讀,通過MVCC(並發版本控制)來實現。
c、使用的鎖粒度為行級鎖,可以支援更高的並發。
d、支援外鍵約束;外鍵約束其實降低了表的查詢速度,但是增加了表之間的耦合度。
e、配合一些熱備工具可以支援在線熱備份。
f、在 InnoDB 中存著緩衝管理,通過緩衝池,將索引和數據全部快取起來,加快查詢的速度;
g、對於 InnoDB 類型的表,其數據的物理組織形式是聚簇表。所有的數據按照主鍵來組織,數據和索引放在一塊,都位於B+樹的葉子節點上。
當然,InnoDB 的存儲表和索引也有下面兩種形式:
(1)使用共享表空間存儲:所有的表和索引存放在同一個表空間中。
(2)使用多表空間存儲:表結構放在frm文件,數據和索引放在IBD文件中。分區表的話,每個分區對應單獨的IBD文件,分區表的定義可以查看我的其他文章。使用分區表的好處在於提升查詢效率。
對於InnoDB來說,最大的特點在於支援事務。但是這是以損失效率來換取的。
2、MyISAM
使用這個存儲引擎,每個 MyISAM 在磁碟上存儲形成3個文件:
a、frm文件:存儲表的定義數據;
b、MYD文件:存放表具體記錄的數據;
c、MYI文件:存儲索引;
frm 和 MYI 可以存放在不同的目錄下。MYI 文件用來存儲索引,但僅保存記錄所在頁的指針,索引的結構是B+樹結構。
下面這張圖就是MYI文件保存的機制:
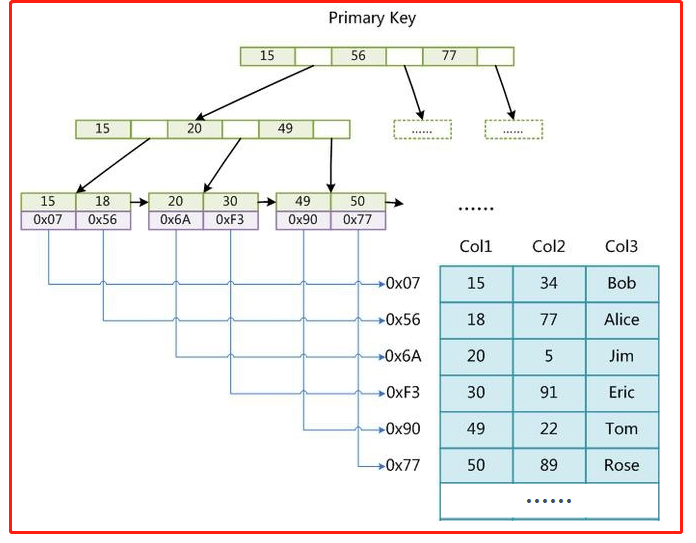
從這張圖可以發現,這個存儲引擎通過MYI的B+樹結構來查找記錄頁,再根據記錄頁查找記錄。並且支援全文索引、B樹索引和數據壓縮。
支援數據的類型也有三種:
(1)靜態固定長度表
這種方式的優點在於存儲速度非常快,容易發生快取,而且表發生損壞後也容易修復。缺點是占空間。這也是默認的存儲格式。
(2)動態可變長表
優點是節省空間,但是一旦出錯恢復起來比較麻煩。
(3)壓縮表
上面說到支援數據壓縮,說明肯定也支援這個格式。在數據文件發生錯誤時候,可以使用check table工具來檢查,而且還可以使用repair table工具來恢復。
有一個重要的特點那就是不支援事務,但是這也意味著他的存儲速度更快,如果你的讀寫操作允許有錯誤數據的話,只是追求速度,可以選擇這個存儲引擎。
3、Memory
將數據存在記憶體,為了提高數據的訪問速度,每一個表實際上和一個磁碟文件關聯。文件是frm。
(1)支援的數據類型有限制,比如:不支援TEXT和BLOB類型,對於字元串類型的數據,只支援固定長度的行,VARCHAR會被自動存儲為CHAR類型;
(2)支援的鎖粒度為表級鎖。所以,在訪問量比較大時,表級鎖會成為MEMORY存儲引擎的瓶頸;
(3)由於數據是存放在記憶體中,一旦伺服器出現故障,數據都會丟失;
(4)查詢的時候,如果有用到臨時表,而且臨時表中有BLOB,TEXT類型的欄位,那麼這個臨時表就會轉化為MyISAM類型的表,性能會急劇降低;
(5)默認使用hash索引。
(6)如果一個內部表很大,會轉化為磁碟表。
在這裡只是給出3個常見的存儲引擎。使用哪一種引擎需要靈活選擇,一個資料庫中多個表可以使用不同引擎以滿足各種性能和實際需求,使用合適的存儲引擎,將會提高整個資料庫的性能
三、你們資料庫中單表最大的數據量有多少?查詢時有什麼問題?你們怎麼處理的?
優化:1、分庫分表(阿里開發規範里,單表數據量超過500W或超過2GB,才推薦分庫分表。);2、索引優化;