Aleax prize (開放域聊天系統比賽)2018冠軍論文閱讀筆記
- 2020 年 3 月 28 日
- 筆記
原文地址:https://m.media-amazon.com/images/G/01/mobile-apps/dex/alexa/alexaprize/assets/pdf/2018/Gunrock.pdf
Abstract
Gunrock是一種社交機器人,旨在讓用戶參與開放域的對話。我們使用大規模的用戶交互數據來迭代地改進了我們的機器人,使其更具能力和人性化。在2018年Alexa獎的半決賽期間,我們的系統進行了40,000多次對話。我們開發了一個上下文感知的分層對話框管理器,以處理各種用戶行為,例如主題切換和問題解答。此外,我們設計了一個健壯的三步自然語言理解模組,其中包括句子分割和自動語音識別(ASR)錯誤校正等技術。此外,我們通過添加韻律語音合成來改善系統的人像性。
1 Introdiction
對話系統研究中的一大挑戰是培訓和測試具有大量用戶的對話系統。大多數研究人員以前在眾包平台上通過付費給參與者以模擬用戶來培訓和評估他們的系統[27]。但是,以這種方式訓練和評估的系統在直接部署為實際產品時會產生不穩定的結果。亞馬遜Alexa prize提供了一個吸引大量志願用戶與社交對話系統互動的平台。在45天的評估期內,我們平均每天獲得500多次對話。在整個開發過程中,我們總共收集了487,314次會話。我們的系統需要處理大量的不同用戶。由於人類已經習慣了彼此的交流方式,因此大多數用戶可能會將其人與人之間的交流行為方式和期望轉移到與系統的交互中。因此,模仿是提高會話系統性能的一種可能方法。Gunrock模仿自然的人與人之間的對話,並具有涵蓋各種社會話題的能力,這些話題可以就特定和流行的話題進行深入的交流。
一、新的三相自然語言理解通道
我們在開放領域的口語理解,對話管理和語言生成方面做出了許多貢獻。開放域口語理解中的兩個主要挑戰包括ASR(自動語音識別)錯誤和實體歧義。我們設計了一種新穎的三相自然語言理解(NLU)管道來解決這些障礙。儘管用戶可以一口氣說出幾個句子,但ASR可以對句子進行解碼,但不能像文本輸入一樣提供標點符號。我們的NLU首先將複雜的輸入分解為較小的部分,以降低理解的複雜性。然後,在這些小片段上執行各種NLP技術以提取資訊,包括命名實體,對話意圖和情感。最後,我們還利用上下文和語音資訊來解決共同引用,ASR錯誤和實體歧義。
二、分層對話管理器
們還設計了一個基於堆棧的分層對話管理器,以處理用戶之間的多種對話。對話管理器首先使用從NLU獲得的資訊,對用戶請求哪個主題(例如電影)做出高層決策。然後,系統激活處理該主題的特定於域的主題對話框模組。在每個主題對話框模組中,我們都有一個預定義的對話流,用於使用戶參與更詳細和全面的對話。為了適應各種用戶行為並保持對話的連貫性,系統可以隨時跳入和跳出,以回答事實和個人問題。此外,可以使用在不同域特定主題對話框模組之間創建的隧道來容納用戶的意圖切換。
三、應用SSML使語句更類人
為了創建更生動的類人互動,我們使用Amazon的語音合成標記語言(SSML)(例如“ aha”)創建了韻律效果庫。通過用戶訪談,我們發現人們對這些韻律效果和感嘆詞認為該系統聽起來更自然。
2 Related Work
端到端的方式提高了對話性能。但是,這些方法都存在不連貫和不通用的問題[29]。為了解決這些問題,一些研究將基於規則的方法與端到端的方法相結合[19]。還有一些學者利用個人的技巧和知識圖譜[6]。這種方法的組合增強了用戶體驗並延長了對話時間,但是,它們在適應新領域時不靈活,並且無法有效地處理與意見相關的請求。我們的Gunrock採用了最新的實踐,並強調動態的用戶對話。該系統充分利用跨不同域和隧道的連接數據集,在主題對話模組之間無縫轉換。從用戶收集的數據除了用於NLU和自然語言生成(NLG)之外,我們還使用這些數據集訓練了模型。
3 Architecture
我們利用了Amazon Conversational Bot Toolkit建立系統架構。該工具包提供了一個zero-effort的擴展框架,使開發人員可以專註於構建用戶友好的機器人。基於事件驅動的系統在AWS Lambda function(亞馬遜雲伺服器)之上實現,當用戶向機器人發送請求時將觸發該系統。 Cobot基礎設施還具有一個狀態管理器介面,該介面將用戶數據和對話框狀態資訊都存儲到DynamoDB(資料庫)。我們還利用Redis(遠程字典服務)和Amazon新發布的圖形資料庫Neptune來構建內部系統的知識庫。在本節中,我們重點討論每個系統組件。
3.1 System Overview
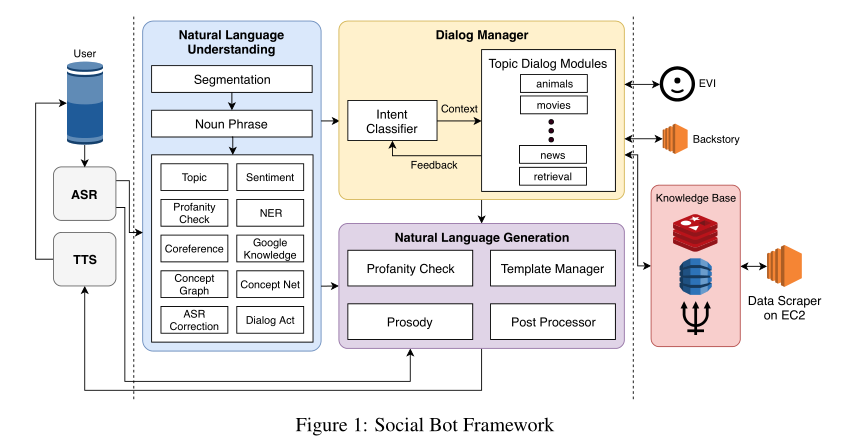
圖1描述了bot對話系統框架。通過亞馬遜提供的ASR提供用戶話語,利用TTS由文本轉換成語音。因此我們的系統主要處理文本的輸入和輸出。由於某些情況可能會產生較長的延遲。例如,如果我們檢測到ASR結果中的置信度得分較低,則會生成提示,要求用戶直接重複或澄清。通過ASR之後,用戶輸入將由多個NLU組件處理,例如Amazon工具包服務和對話行為檢測器。我們使用Amazon Offensive Speech Classifier工具包來檢測令人反感的內容。如果內容顯示出不良的跡象,我們會告知用戶該主題的不適當之處,並建議其他主題繼續對話。
NLU流程涉及三個步驟。首先,將輸入語音分為多個句子,然後檢測名詞短語。最後,名詞短語將由圖1所示的幾個NLP組件進一步分析。在3.3節中,我們將詳細討論NLU組件。在對話框管理器中,意圖分類器用於將不同的用戶意圖定向到相應的主題對話框模組。它們涵蓋了幾個特定的主題,包括電影,運動,動物等。
每個主題對話框模組都有其自己的對話框流,使用戶可以靈活地進行更深入的對話。所有主題對話框模組都使用Amazon的EVI服務來回答事實問題,並通過背景故事來回答與Bot角色相關的問題,例如您最喜歡的顏色是什麼?此外,我們使用Amazon EC2實例11從不同來源抓取數據並將其存儲在我們的知識庫中。來自NLU的所有資訊以及上下文資訊都用於確定適當的主題對話框模組,該模組調用NLG生成響應。 NLG系統使用模板管理器來集中系統的響應模板。為了確保響應的適當性,我們包括褻瀆檢查程式以提取響應的內容。 NLG中還包括一個後處理器,用於修改原始主題對話框模組的響應。最後,我們使用Amazon SSML格式化響應的韻律。在以下小節中,我們將詳細描述主要的系統塊。
3.2 Automatic Speech Recognition
在用戶語音通過NLU之前,我們的系統會根據ASR總體置信度得分和每個單詞的置信度得分來預設輸入語音,以解決和處理ASR錯誤。我們根據置信度得分範圍定義三個ASR錯誤響應:
•臨界範圍:如果總體置信度得分和每個單詞的置信度得分低於0.1,系統將直接中斷整個管道,並要求用戶重複或重述其話語或要求。
•警告範圍:如果總體置信度得分低於0.4但不在臨界範圍內,則允許其通過ASR校正,這將在3.3.5節中討論。
•安全範圍:對於其他情況,我們將其定義為安全範圍並直接使用ASR結果。我們還會處理用戶的意料之外的意圖,例如投訴或不完整的話語。在這種情況下,我們意識到僅提供資訊作為響應會導致不良的用戶體驗
3.3 Nature Language Understanding
Alexa Skills Kit(ASK)[12]為NLU提供了話題分類,情緒分析,褻瀆檢查和NER(命名實體識別)。我們添加了一個句子分割模型,將用戶的輸入分成語義單元,並對每個語義單元執行NLU。提取名詞短語後,我們實現了(命名)實體識別,共同引用,ASR校正和對話行為檢測,以支援語言理解。我們按照NLU管道的順序介紹每種模型的技術細節(第3.1節)。
3.3.1 Sentence Segmentation
我們訓練了一種分割模型,以將語音分成具有完整語義含義的較小片段。我們使用康奈爾電影語料庫[5]訓練了序列模型[24],該序列包含304,713個對話輪和23,760個手動標記的語音(7月29日至7月31日)作為驗證集。通過為句子中的中斷添加特殊標記來對數據進行預處理。例如,“Alexa that is cool what do you think of the Avengers”被細為
“Alexa <BRK> that is cool <BRK>what do you think of the Avengers <BRK>”
3.3.2 Noun Phrase Extraction(名詞短語提取)
我們使用了Stanford CoreNLP選區解析器[15]從輸入句子中提取名詞短語和局部名詞短語(解析樹的葉級)。我們過濾了一些停用詞(例如全部),並將其餘詞視為其他NLU模組和選擇策略的關鍵字。在以後的工作中,我們計劃使用依賴性解析器來識別主語和賓語,以防出現多個名詞短語。
3.3.3 Entity Recognition(實體識別)
•Google知識圖譜12:我們使用Google知識圖查詢名詞短語以生成詳細描述,置信度得分並將結果快取到Redis。我們還將描述映射到我們擁有的模組。例如,名詞短語“古墓麗影”的標籤“影片遊戲系列”具有很高的置信度,因此我們可以將其映射到我們的遊戲模組。此外,我們提取了多個標籤以消除名詞短語的歧義(例如“古墓麗影”也可以是電影)。因此,當存在多個具有高置信度得分的標籤時,考慮上下文。
•Microsoft概念圖13:我們還使用Microsoft概念圖對名詞短語進行分類。與Google知識圖相比,它提供了更通用的類別,可用於分配模組。
•ASR校正:除了使用知識圖來獲取實體之外,我們還使用ASR校正器,這將在3.3.5節中詳細介紹。這對於同音詞(聽起來相同但拼寫不同的詞)非常重要。模糊搜索將更可能打出具有相似拼寫的片語,但由於語音識別,可能導致選擇不正確。使用語音查找匹配項可以提高特定域中NER的準確性。
該部分將以上三種技術並行應用
3.3.4 Coreference Resolution(共指解析:在一短文本內多個表達段指向現實世界中的同一個實體)
Stanford CoreNLP和NeuralCoref 14的最新模型已針對非會話數據進行了訓練,因此無法很好地用於回指解析中的對話。
因此,我們將來自請求和NERs的名詞短語以及來自系統響應的詳細描述存儲到用戶屬性中根據用戶指的是什麼(例如,人或事件,男性還是女性),我們提供相應的共同推薦解決方案。根據請求,我們分別將來自用戶的名詞短語和來自我們的響應的NER優先考慮。在以後的工作中,我們計劃考慮更多的上下文,並訓練一個模型,該模型可以在定義好的優先順序之外的選定單詞列表中進行確認。
ASR錯誤對NLU品質有很大影響。 ASK通過合併每個單詞的置信度得分和語言模型生成的得分,從而提供總體ASR置信度得分。總體分數表明正確識別整個話語的可能性。但是,當置信度得分較低時,有兩種類型的誤報可能會觸發錯誤處理,以表示ASR錯誤。第一個是在訓練數據中不經常看到提到的單詞時,因此單詞的權重較低。誤報的另一個實例是同音詞,即使用戶重複他們的請求,ASR也無法捕獲。因此我使用double metaphone演算法。我們還根據觀察結果在具有某些模式的單詞上添加了三級編碼如果來自ASR的總體置信度低於某個閾值(設置為0.4),我們通過將名詞短語的變音位程式碼與知識庫的變音位程式碼進行匹配來提出候選詞。
3.3.6 Dialog Act Prediction
NLU中的每個分段語句都與一個對話行為相關聯。對話行為是給定對話上下文即意見,陳述的對話中的功能。我們訓練了LSTM和CNN模型來預測對話行為。前者使用2層的Bi-LSTM模型,使用fastText進行預訓練,輸入層大小為300,隱藏層大小為500。後者使用2層的CNN模型,也使用fastText進行預訓練,卷積核大小為3×3 將其應用在 SWDA數據集(經過處理)上 。我們還在預訓時通過練嵌入ELMo [17]和遞歸卷積神經網路模型[13]來優化模型。
3.3.7 Topic Expansion
除了要求用戶共享更多資訊並將資訊存儲在我們的資料庫中作為學習過程之外,我們還可以討論類似的話題。例如,如果用戶想談論汽車,我們可以從ConceptNet檢索不同汽車類型的列表(例如Volvo)。因此,在詢問了用戶喜歡的汽車類型並對對話行為分類的輸入進行評論之後(例如,如果用戶正在講故事,觀點或提出問題),我們可以擴展到Volvo並從我們的資訊庫中提取相關資訊。、
3.4 Dialog Management
我們創建了一個兩級分層對話框管理器來處理用戶的對話。高級系統將利用NLU的輸出為每個用戶請求選擇最佳主題對話框模組。之後,低級系統將激活此主題對話框模組以生成響應。
3.4.1 High-Level System Dialog Management
系統首先根據NLU輸出識別用戶意圖,然後與每個子模組的回饋相結合,高級對話管理器決定哪個子模組應處理用戶話語。
Intent Classifier(意圖分類器):我們基於通用Alexa獎品聊天數據集(CAPC)定義了三個級別的用戶意圖,CAPC是2017年Alexa獎競賽中收集的匿名人機對話數據集。我們首先處理社交聊天域系統的請求,例如“播放音樂”,“設置溫度”,“開燈”等。對於這些請求,由於我們的社交機器人無法執行任務,因此系統會向用戶解釋如何退出社交模式,以便他們隨後可以使用Alexa內置功能。
Dialog Module Selector(對話框模組選擇器):我們的對話模組選擇器首先選擇一個主題對話模組,該模組負責響應意圖分類器檢測到的主題意圖。為了保持響應的一致性,選定的模組在生成響應後會向系統提供一個稱為“ propose_continue”的訊號。如果將其設置為“繼續”,我們將為用戶的下一次發聲選擇此模組。如果將其設置為“ UNCLEAR”,則僅當我們無法檢測到任何其他主題時才選擇此模組。如果將其設置為“停止”,則表示它無法處理用戶的其他請求,我們的系統不會在下一輪選擇此模組。
3.4.2 Low Level Dialog Management
我們構建了兩個API,分別是Backstory和EVI,以回答有關聊天機器人的一般事實和背景問題。
•Backstory: 這項服務旨在檢索對與聊天機器人的背景和偏好有關的問題的答案,例如“您最喜歡的運動是什麼”。我們使用Google的通用句子編碼器[4]嵌入用戶的問題和我們預先定義的問題。然後,我們獲取與該問題相對應的答案,該問題與用戶的問題的餘弦距離最接近,作為響應。對於每個問題,“背景故事”模組還可以處理用戶的進一步請求,例如“您為什麼喜歡籃球?”。
•EVI:亞馬遜提供的服務。它可以回答一些事實性問題,例如“勒布朗·詹姆斯(Lebron James)多大?”。如果沒有相應答案,EVI將返回“我對此沒有意見”或“我不知道”。另外,由於有時它會直接返回Alexa技能鏈接,因此我們對結果進行後處理,而不是直接返回。
3.5 Knowledge Base
我們的知識庫由按主題存儲在DynamoDB表中的統一數據集組成。數據集來自Reddit,Twitter時刻,辯論意見,IMDB,Spotify等。通過檢測匹配的實體將數據集統一在知識圖中。我們利用亞馬遜的圖形資料庫Neptune建立實體與Gremlin查詢語言23之間的關係以遍歷它們。
• Factual Content
Reddit:我們每天從各種子Reddit中收集大量事件。檢索到的子目錄包括:科學,技術,政治,令人振奮的新聞,新聞,世界新聞,商業新聞,財經新聞,體育,娛樂,時尚新聞,健康,音樂新聞,TIL,ShowerThoughts,旅行。
Twitter:Gunrock中的Twitter時刻旨在幫助用戶實時了解世界上正在談論的話題。隨著事件的發生,Gunrock能夠談論電影,書籍,政治,音樂,名人等。
常規資訊:有關電影和音樂的常規資訊,我們使用IMDB資料庫轉儲“ One Million Playlist dataset”數據集。 該數據集使Gunrock能夠過渡到播放列表中的相關藝術家,並了解流行歌曲和藝術家。我們還利用TMDB API和Goodreads API分別檢測電影和書名。
•關於意見內容
– Twitter Opinions 我們在Twitter Moment中附帶了意見。 Gunrock有機會參與實時事件,使對話更加有趣和有趣。
–Debate Opinions Gunrock嘗試使用通用句子編碼器將陳述和意見與71,000多個主題和460,000個意見進行匹配[4]。當辯論主題識別的置信度很高,並且在普遍意見共識下,Gunrock將直接回答主題或用戶意見。對於觀點分歧在40-60分之間的有爭議主題,我們要求用戶發表意見,並解釋說Gunrock仍在形成自己的觀點。這提供了一個機會,可以輕而易舉地解決兩極分化的問題,同時在整個用戶之間積累共識。
我們使用OpenIE(開放域知識抽取工具) [1]來統一我們的知識圖。它可以自動從純文本中提取源實體和目標實體之間的二進位關係。這些關係在圖形資料庫中抽象,並且實體之間的所有事件都存儲在DynamoDB中。使用V ADER情感[8](基於規則的情感識別方法)為每個事件分配一個情感分數,這是處理推文和Reddit帖子的理想選擇。該情感分數用作知識圖的遍歷權重。
3.6 Natural Language Generation (NLG)
我們系統的自然語言生成模組是基於模板的。它選擇一個手動設計的模板,並使用對話框管理器從知識庫中檢索到的資訊填充特定的位置。模板管理器模組避免重複響應,並生成具有多種表面形式的響應。
我們使用OpenIE [1]來統一我們的知識圖。它可以自動從純文本中提取源實體和目標實體之間的二進位關係。這些關係在圖形資料庫中抽象,並且實體之間的所有事件都存儲在DynamoDB中。使用V ADER情感[8]為每個事件分配一個情感分數,這是處理推文和Reddit帖子的理想選擇。該情感分數用作知識圖的遍歷權重。
3.6.1 Template Manager
模板管理器模組存儲並解析系統使用的響應模板。它集中了系統中多個並行對話流組件(例如電影和音樂)中的所有響應模板,確保沒有為響應選擇重複的模板,並允許按模組指定動態地形成模板。使用模板管理器的主要目標之一是避免重複的響應。我們為每個模板設計了多種表面形式,並且模板管理器確保它們是隨機選擇的,並且不會在對話中重複出現。這是通過將使用的模板作為哈希存儲在每個用戶的哈希表中來完成的。例如,我們的電影模組提供了電影有趣的事實,這是通過將從模組資料庫中提取的事實填充到我們預先定義的響應模板中來完成的。
3.6.2 Prosody Synthesis
我們的系統利用Amazon Alexa的語音合成系統進行語音合成。我們使用Amazon SSML格式來增強我們的模板,例如在讀取電話號碼或正確發音同形異義詞和首字母縮寫詞時。另外,我們在10處添加填充符(例如“ whoops”和“ uh-oh”)以及諸如“ Okey dokey ”的標記更像人。我們還會插入暫停符來分解長句子,使它們聽起來更自然,並在開玩笑之前添加它們,以建立用戶的期望。
4 An Example Dialog

表1給出了一個模擬的示例對話。為了吸引用戶,我們的系統以有趣的內容為中心對事實,經驗和觀點進行了交織。事實向用戶提供了有趣的資訊。此外,用戶可以與我們的機器人交流意見和經驗。我們認為擁有觀點和經驗對於使機器人人性化至關重要。我們還發現確認對於用戶參與很重要。對話可以被認為是資訊交換的過程,只有當說話者和聽者相互理解時,對話才會發生。確認會向用戶發送訊號,表明該機器人可以理解,並且還充當隱式接地,使用戶很容易檢測到該機器人被誤解了。為了延長對話時間,我們將系統設計為混合計劃。如果用戶正在請求特定主題或提出問題,我們確保做出適當答覆。如果用戶對當前主題感興趣,則系統將繼續深入研究。同時,我們的系統也可以採取主動。如果用戶沒有明確的意圖或可採取的行動,則我們的系統將提出一個主題或提出相關問題。
5 Conclusion
我們在口語檢測,對話管理和韻律語音合成方面做出了許多貢獻。具體來說,我們提出了一個三相口語理解管道來處理開放域口語理解。分層對話管理器,利用對話上下文來實現靈活的對話流,從而無縫地將事實和觀點交織在一起;韻律語音合成器通過對音調的調整和填充詞插入來構建更自然的響應。
6 Future Work
一、引入推薦系統:我們希望在幾個方面改進我們的系統。我們的目標是根據不同用戶的個人資料(例如性別,個性和主題興趣)來改進建議主題的選擇,從而為每個用戶創建一種適應性和獨特的對話體驗。為了進一步增強每個用戶的獨特對話體驗,我們將構建一個強大的推薦系統,以針對即將到來的事件或有趣的內容針對不同用戶的興趣提供建議。
二、加入強化學習:我們還計劃使用強化學習為子模組選擇和對話內容規劃訓練更好的對話策略。我們希望在用戶要求特定目標的幫助(例如,推薦合適的餐廳或旅遊景點)時,通過社交交流和面向任務的對話來更好地處理案件。
三、辯論子系統:我們還將構建一個數據驅動的意見回答和主題辯論子系統,這將使我們能夠與用戶就熱門主題進行適當的主觀討論。
四、在線學習:我們還將探索在線學習技術,以使我們的系統從與用戶的對話數據中自動學習,尤其是在系統不熟悉的主題上