機器學習 – 命名實體識別之Hidden Markov Modelling
- 2020 年 3 月 28 日
- 筆記
- 概述
命名實體識別在NLP的應用中也是非常廣泛的,尤其是是information extraction的領域。Named Entity Recognition(NER) 的應用中,最常用的一種演算法模型是隱式馬可夫模型(Hidden Markov Modelling)- HMM。本節內容主要是通過介紹HMM的原理,以及應用HMM來做一個NER的實例演示。
- HMM原理解析
在解釋HMM的原理之前,先引用幾個HMM的基本概念,第一個是就是隱式狀態,在本文中用H表示; 第二個就是顯式狀態,在本文中用大寫的英文字母O表示。咱們的HMM的中,就是根據咱們的顯式狀態O來計算隱式狀態H的概率的問題,其中在HMM中有一個基本的前提條件,那就是每一個time step的隱式狀態只跟它前一步的的隱式狀態有關。具體是什麼意思呢,大家看我下面的一幅圖片,結合這幅圖片來給大家解釋
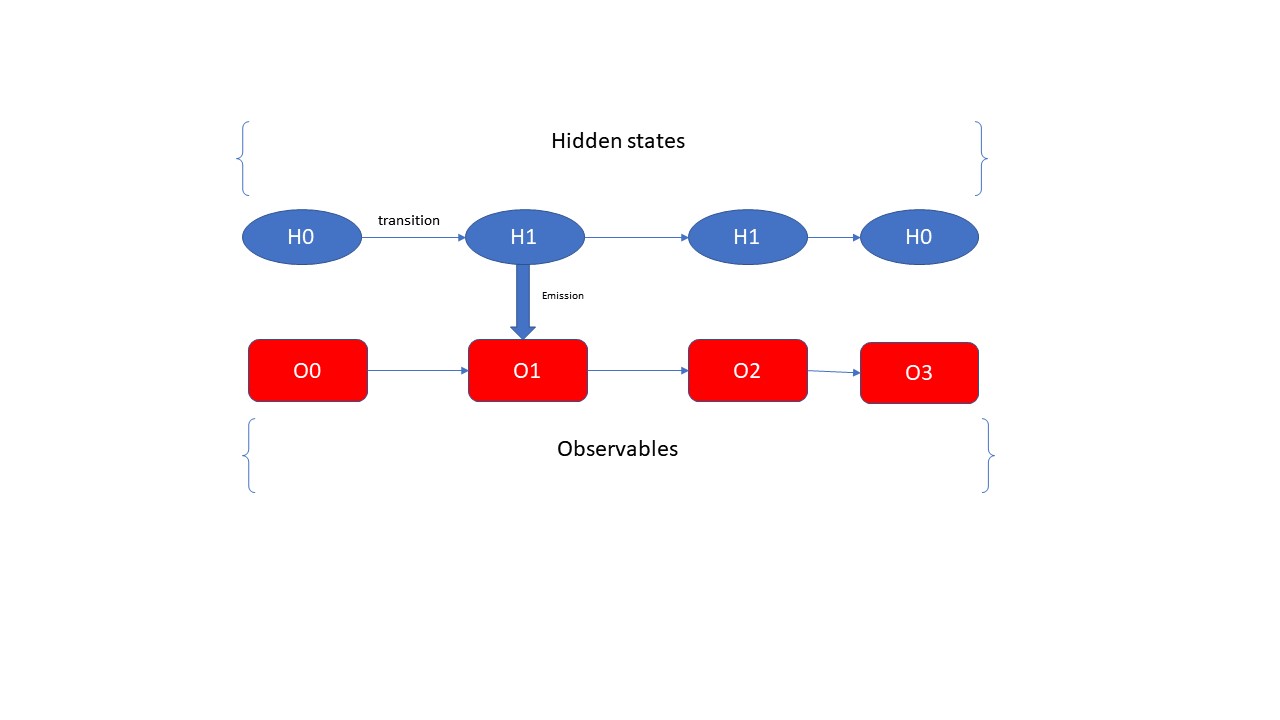
首先observables是大家能直接得到的資訊,例如一個句子“小李和王二在天津旅遊”,這個就是一個observable的sequence,是咱們能夠直接得到的資訊;那麼咱們如何才能夠得到這句話背後所包含的隱式sequences呢?這就是咱們的HMM所要解決的問題了。從上圖可以看出hidden states之間是通過transition matrix來連接的,這裡咱們也可以很好的看出來每一步的hidden state僅僅是由前一步的hidden state來確定的;hidden state和observable之間是通過emission matrix來連接的,即在給定的hidden state的情況的,指向每一個observable的概率是多少。這麼說的有點抽象,那麼咱們通過下面的圖片來展示這個transition matrix和emission matrix
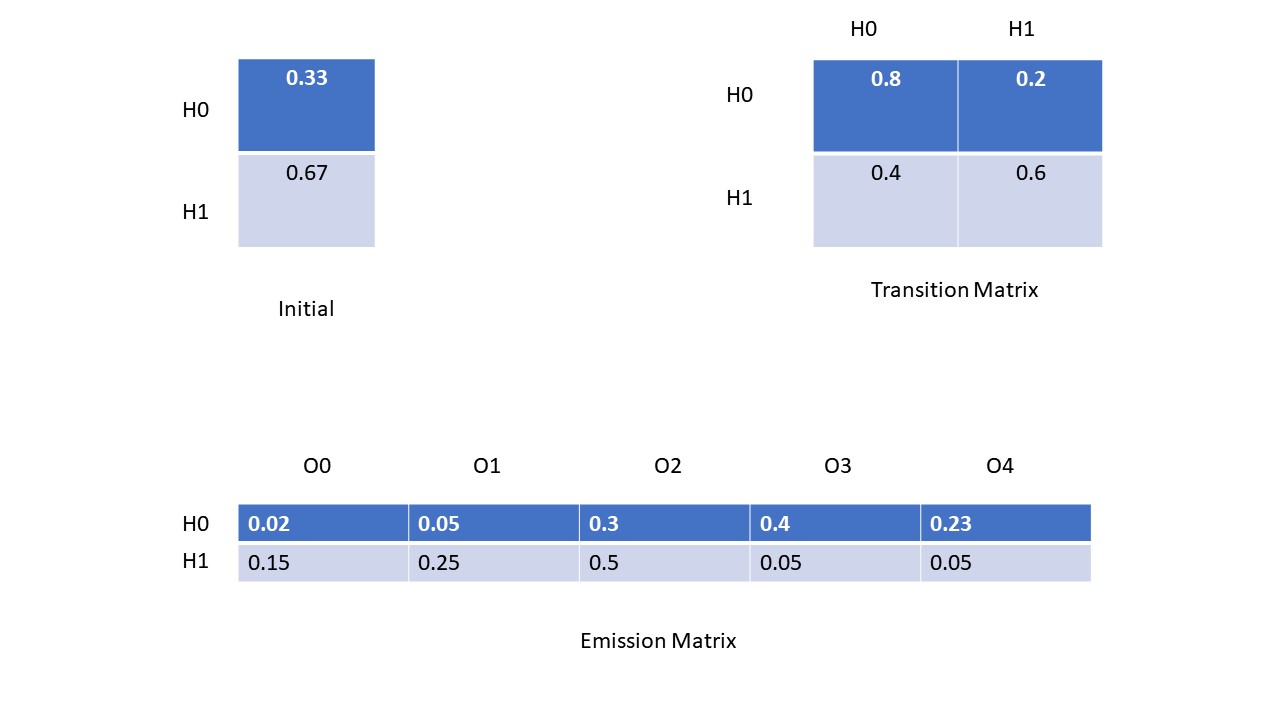
上面的圖片展示了HMM所需要的一些matrix,咱們的一個個分析。首先initial matrix是咱們根據語義集中的每一條數據的第一個hidden state計算出來的;transition matrix是根據咱們訓練的語言集中的所有的隱式狀態的計算出來的,例如咱們統計出所有的H0-》H0和H0-》H1的個數,然後除以總數,得出的分別就是H0-》H0和H0-》H1的概率,同理得出其他的Transition Matrix的其他的概率。Emission Matrix也是根據咱們訓練的語義集中的數據計算出來的,它的步驟是統計出所有H0-》O0,O1, O2,O3,O4的個數,然後除以總數,得到的就是H0這個hidden state分別對應的所有的顯式狀態的概率, 同理也可以計算出其他的emission matrix的值。這就是得出Initial Matrix, Transition Matrix, 和 Emission Matrix的方法和步驟。從咱們的語義集中得出了這些數據過後,咱們就通過Vertibi演算法來根據observable sequence計算了咱們的Hidden state sequences。
- Vertibi 演算法
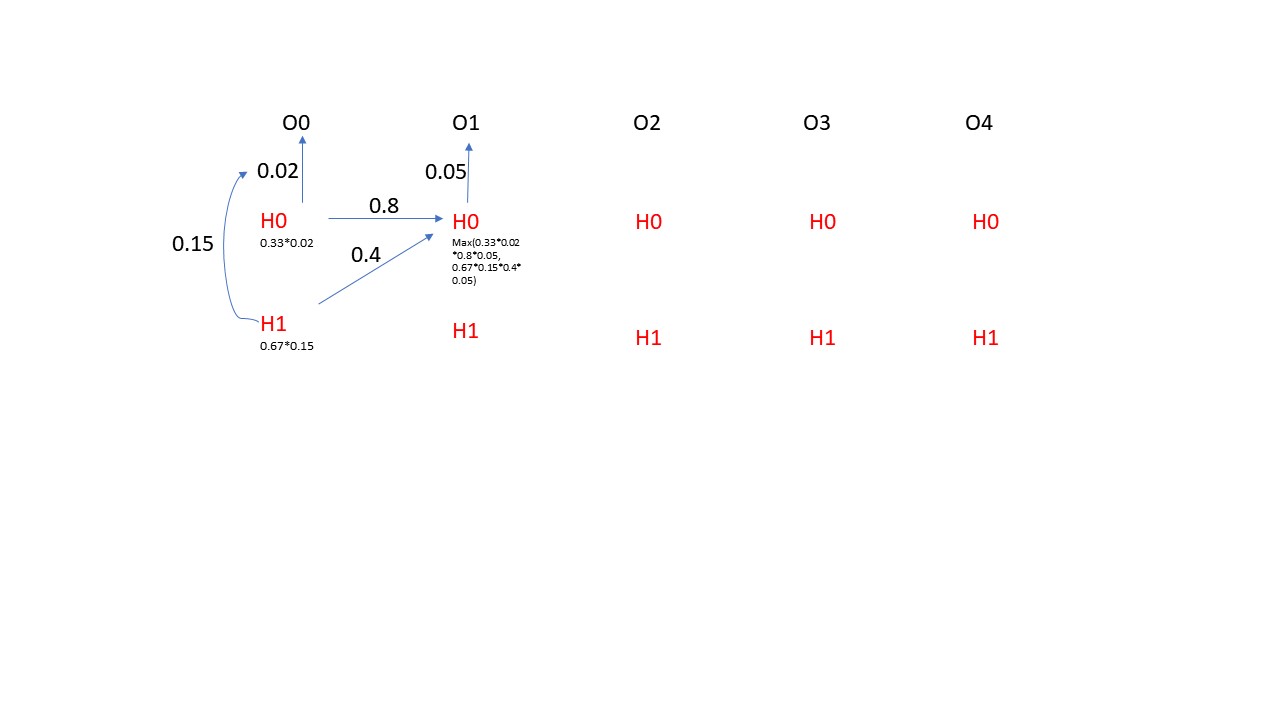
Vertibi演算法是一種動態路徑規劃的演算法,它能動態的規劃處最優的路徑。具體在咱們NER的應用中,它能夠根據咱們的上面計算出來的Transition matrix, Initial Matrix和Emmsion Matrix來規劃處咱們的最優的隱式狀態的sequence, 其實這裡就是尋找P(H0H1H2H3H4H5………..)最大值的一種方法,這裡需要注意的一個點就是局部的最優並不一定能得出全局最優的結論,這是因為每一步的隱式狀態的概率並不僅僅收到當前這一步的顯式狀態的影響,還受到它前一步的隱式狀態的影響。下面咱們來用一個小實例來展示一下Vertibi的演算法,為了方便,咱們只展示一步哈,請看下圖所示
- 隱式馬可夫演算法和維特比演算法的程式碼演示
上面的部分都是分析隱式馬可夫演算法和維特比演算法的原理,那麼接下來咱們具體看看它們在NER中的應用以及實際的程式碼演示,這裡我用一個在NLP中的實例來演示這兩種演算法。假設我們有一個語義集,咱們根據訓練數據來計算好markov的matrix,然後應用維特比演算法來抽取句子中的人名的資訊出來。這在NLP中是一個非常常用的案例,那咱們首先來看看計算Initial maxtrix和Transition Matrix的程式碼部分
#計算初始hidden state的概率和transition matrix def calculate_initial_and_transition_matrix(self): for dictionary in self.text_corpus: for i, tag in enumerate(dictionary["tags"][:-1]): if i == 0: self.pi[self.tag_index[tag]]+=1 current_tag = self.tag_index[tag] next_tag = self.tag_index[dictionary["tags"][i+1]] self.transition[current_tag, next_tag] += 1 self.transition /= np.sum(self.transition, axis = 1, keepdims = True) self.pi /= np.sum(self.pi) self.pi[self.pi == 0] = 1e-8 self.transition[self.transition == 0] = 1e-8 return self.pi, self.transition
其次咱們來看一下計算emission matrix的程式碼部分
def calculate_emmision_matrix(self): for dictionary in self.text_corpus: for word, tag in zip(dictionary["text"], dictionary["tags"]): self.emmision_matrix[self.tag_index[tag],self.dataloader.tokenizer.texts_to_sequences(word)[0][0]] += 1 self.emmision_matrix /= np.sum(self.emmision_matrix, keepdims = True, axis= 1) self.emmision_matrix[self.emmision_matrix == 0] = 1e-8 return self.emmision_matrix
根據咱們的訓練數據咱們得出了這些matrix的值,根據這些matrix的值,咱們就可以根據輸入的一句話(顯式狀態)來計算出這一句話中哪些字是人名(隱式狀態)了,並且將這些人名資訊提取出來了。這裡咱們不用實際的手動的實現vertibi演算法了,TensorFlow已經幫助咱們實現好了,咱們不需要再重複造輪子了,這裡咱們需要引進一下TensorFlow probability這個框架了,具體的看下面的程式碼展示
import tensorflow_probability as tfp import tensorflow as tf tfd = tfp.distributions initial_distribution = tfd.Categorical(probs=pi) transition_maxtrix = tfd.Categorical(probs=transition) observation_matrix = tfd.Categorical(probs = emmision) model = tfd.HiddenMarkovModel(initial_distribution=initial_distribution, transition_distribution=transition_maxtrix, observation_distribution=observation_matrix, num_steps=11) test_string = "小明和老王去河邊釣魚了" temps = [data_handler.calculator.word_index[index] for index in list(test_string)] tag_sequence = model.posterior_mode(observations=temps) reversed_tag_index = {value:key for key,value in data_handler.calculator.tag_index.items()} tags = [reversed_tag_index[index] for index in tag_sequence.numpy()] print(tags)
上面就是根據咱們的matrix(initial_distribution, transition_matrix, observation_matrix),還有顯示狀態(test_string),tfp根據vertibi演算法幫助咱們計算出來隱式狀態的sequence(tag_sequence)。這就是NER在NLP的應用中常用的一個實例。