五分鐘學後端技術:如何學習Redis、memcache等常用快取技術
- 2020 年 3 月 27 日
- 筆記
原創聲明
本文作者:黃小斜
轉載請務必在文章開頭註明出處和作者。
本文思維導圖
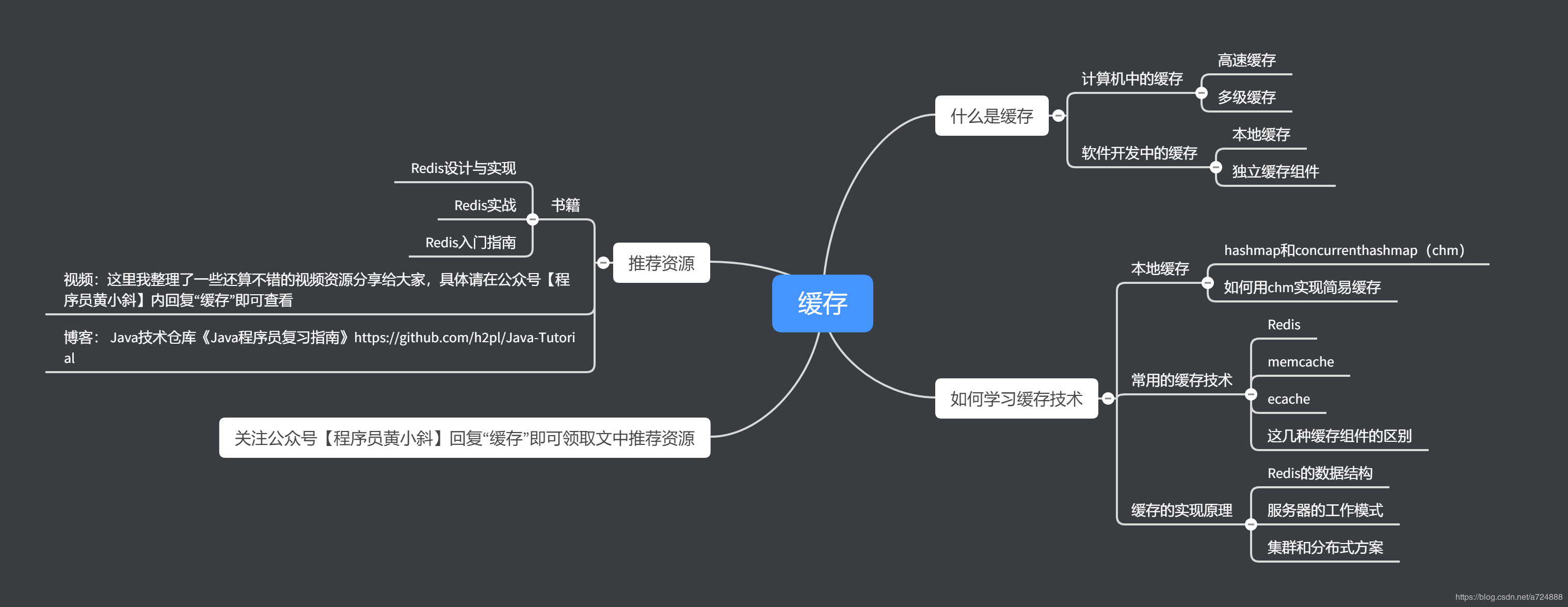
什麼是快取
電腦中的快取
做後端開發的同學,想必對快取都不會陌生了,平時我們可能會使用Redis,MemCache這類快取組件,或者是本地快取,來實現一些後端的應用。
那麼,嚴格來說,到底什麼才是快取呢,先來看看百度百科的定義。
快取(cache),原始意義是指訪問速度比一般隨機存取存儲器(RAM)快的一種高速存儲器,通常它不像系統主存那樣使用DRAM技術,而使用昂貴但較快速的SRAM技術。快取的設置是所有現代電腦系統發揮高性能的重要因素之一。
最早,「快取」一詞是用來指代電腦硬體中的高速快取,因為CPU和記憶體的運算速度差距過大,如果CPU直接和記憶體交互的話,會浪費掉CPU的大量運算時間,於是有了高速快取,來為這兩個速度差距甚遠的組件做中介。
具體的工作原理是,CPU要取數據的時候,先找高速快取要,由於它們倆的速度差距並不大,所以CPU不會損失掉太多性能,如果數據就在快取中,那麼就直接在快取里取,否則則到記憶體去取,取完之後還要留在高速快取中,以便於下次CPU要使用時無需再到記憶體中去取。
其實,高速快取還可以分為一級快取,二級快取和三級快取等,每往下一級,速度也就越慢,價格也越低,畢竟,成本是我們不得不考慮的因素,要不然一切硬體都上頂配,就不需要討論軟體的優化了。
除了高速快取外,其實還有硬碟快取、網路快取等作業系統自身實現的快取,目的也是為了在兩個運算速度不同的組件之間建立一個橋樑,並且,快取中的數據往往都是局部數據,又稱熱點數據,這部分數據經常被使用,因此更具有被快取的價值
軟體開發中的快取
上面講了一些關於電腦中已有的快取,那麼,我們平時在程式碼開發中用的快取又是什麼東西呢?好像不太一樣啊。
相信大家都聽過Redis,這是業界最流行的快取組件之一,不妨看看它是如何被定義的。
redis是一個key-value存儲系統。和Memcached類似,它支援存儲的value類型相對更多,包括string(字元串)、list(鏈表)、set(集合)、zset(sorted set –有序集合)和hash(哈希類型)。這些數據類型都支援push/pop、add/remove及取交集並集和差集及更豐富的操作,而且這些操作都是原子性的。
在此基礎上,redis支援各種不同方式的排序。與memcached一樣,為了保證效率,數據都是快取在記憶體中。區別的是redis會周期性的把更新的數據寫入磁碟或者把修改操作寫入追加的記錄文件,並且在此基礎上實現了master-slave(主從)同步。
根據上文的描述,我們可以看出,Redis是一個K/V的存儲系統,並且它是把數據快取在記憶體中的,大家都知道,記憶體比硬碟的速度要快得多,而我們平時經常使用的資料庫,本質上還是基於硬碟IO來工作的,每次讀寫資料庫都要經過硬碟的IO操作。
所以,讀寫資料庫的耗時要比讀記憶體要慢得多,剛剛我們說了,CPU讀寫記憶體和高速快取的速度差異也很大,所以,這裡Redis和高速快取扮演了同一個角色,只不過一個是硬體,一個是軟體,一個連接的是記憶體和CPU,另一個連接的是磁碟和記憶體。
除了Redis以外,還有很多快取組件比如memcache也是基於這種方式來實現的,通過快取資料庫的熱點數據,來提高應用的訪問速率,在後端開發中是非常常見的一種技術應用。
如何學習快取技術
作為一個後端開發工程師,不懂快取是不行的,即使你天天做的是CRUD,至少也要會使用本地快取吧。
另外,面試的時候經常也會有快取方面的問題,簡單點的,可能就讓你說一說Redis的基礎和實現原理,複雜點的,會結合場景,問你快取可能引發的一些問題,又或者,分散式場景下的快取如何設計。
從會使用到了解原理,再到學習進階的用法,學習快取和學習其他技術一樣,需要先易後難,現在就讓我們一起來看看,如何搞定快取這個難纏的小妖精吧。
本地快取chm
第一次接觸快取,其實是我在學習hashmap的時候,hashmap本身就是一個KV的鍵值對對象,和咱們剛剛說的Redis似乎有點像,那麼,如何讓hashmap真正變成一個快取呢,其實也不難。
實際上,很多本地快取就是直接用concurrenthashmap來實現的,注意,這裡用的是支援並發的concurrenthashmap,這因為啊,快取對象是可以支援多個執行緒同時訪問的,如果出現同時put好的情況,就有可能出現異常,於是,使用concurrenthashmap就可以避免這種問題。
為了方便起見,後面對於concurrenthashmap簡稱chm。chm不僅可以保證對其訪問是執行緒安全的,而且比直接用synchronized等關鍵字要更加高效靈活。
那麼,chm實現快取的原理是什麼呢?首先,在應用中,快取的本質就是把一些經常出現的數據存在記憶體中,而Java的記憶體又可以分為堆記憶體和棧記憶體,快取對象自然是要放在堆記憶體中了。
所以它是一個類里的一個成員變數,比如這樣。
private Map<String, CacheObj> CACHE_OBJECT_MAP = new ConcurrentHashMap<>(); 但是這樣使用快取有一個問題,這個成員變數屬於實例,如果實例沒有初始化或者是被回收,那麼這個快取對象也就跟著消失了,那肯定是不行的,畢竟快取的生命周期應該和應用本身一樣長,另外,這個快取對象還可能被修改,比如我可以在程式碼里隨便操作一下,讓它 = null,或者是重新初始化一下,那一樣也是不被允許的。
所以,標準的chm本地快取應該是這樣被初始化的。
private static final Map<String, CacheObj> CACHE_OBJECT_MAP = new ConcurrentHashMap<>(); 靜態變數保證它一直存在於堆記憶體中,而final關鍵字修飾可以讓它不會被重新初始化或者指向其他對象。
接下來的事情就簡單了,你只要使用get和put方法就可以了。
當然,這只是最基礎的本地快取實現,還可以實現成LRU快取,搞各種騷操作,這裡我們不再具體討論,網上有很多demo,可以自行去參考。
常用快取組件實戰
除了本地快取之外,我們還應該去了解一些常用的快取技術,比如Redis、memcache這類快取組件,還有類似Ecache這類的Java快取框架。
這類成熟的快取技術,更加值得我們學習和使用,它們一般都能提供各個場景下的先進解決方案,比如如何處理熱點數據,如何進行分散式部署,實現高可用,如何進行數據同步,主從複製,以及實現分散式鎖、分散式ID生成器等各個場景的應用。
有一個面試題相信大家都遇到過,那就是問你redis和memcache的區別,我們不妨通過這個面試題來了解一下,到底它們都有些什麼特點。
Redis不僅支援簡單的k/v類型的數據,同時還支援list、set、zset(sorted set)、hash等數據結構的存儲,使得它擁有更廣闊的應用場景。
而Memcached唯一支援的數據類型是字元串string,非常適合快取只讀數據,因為字元串不需要額外的處理。
Redis最大的亮點是支援數據持久化,它在運行的時候可以將數據備份在磁碟中,斷電或重啟後,快取數據可以再次載入到記憶體中,只要Redis配置的合理,基本上不會丟失數據。
這一點很要命,memcache不持久話數據,萬一斷電了就裂開。
Memcache在並發場景下,能用cas保證一致性,而Redis事務支援比較弱,只能保證事務中的每個操作連續執行。
雖然Redis支援事務而memcache不支援,但是memcache對並非的支援不亞於Redis。
性能方面,Redis在讀操作和寫操作上是略領先Memcached的。
Memcached的記憶體管理不像Redis那麼複雜,元數據metadata更小,相對來說額外開銷就很少。
對於制度數據來說,即使沒有數據備份也沒什麼關係,但是如果存在讀寫,那麼顯然memcache是不合適的,整體來看,Redis還是略勝一籌。
Redis這類快取組件其實是通過C/S方式部署服務的,而另一種快取組件ecache,則是直接集成,快取的數據就放在JVM里,有點類似於我們的本地快取,其實ecache還應用在hibernate中,所以很多時候我們都是在不知情的情況下就已經使用了cache。
當然了,ecache這類快取的數據放在JVM,要共享起來的話就比較麻煩了,特別是需要應用在分散式場景的時候,實現起來是比較複雜的。
快取的實現原理
相信你在看了本地快取那一部分的時候,會覺得快取實現起來也沒什麼難度啊,一個hashmap就搞定了。
實際上,快取的實現要考慮的問題還很多,就拿Redis來說,使用什麼樣的數據結構來存儲數據就是很重要的一個問題,我們當然希望用盡量小的空間來存盡量多的數據,同時還要提升快取CRUD的效率。
Redis中支援多種數據結構,比如字元串、數組、字典(map)以及列表、set、有序set等,別看這些數據結構很簡單,但是作者實現起來都花了不少功夫。
往往一個結構有多種底層實現,目的就是為了壓縮空間,提高效率。有興趣的朋友可以看下這篇文章
Redis數據結構的底層實現https://blog.csdn.net/Future_LL/article/details/88525004
除了數據結構之外,Redis本身的實現也耐人尋味,比如,Redis的服務端和客戶端是怎麼設計的,另外,Redis是單執行緒工作的,為什麼要這麼設計,還有Redis的事務是如何實現的,這些內容都值得我們一一去學習了解。
另外還有一些進階的內容,比如Redis的部署方案,通常包括主從部署、集群方案、HA方案等等,Redis官方也有Redis-cluster的高可用集群方案。Redis也常常用於分散式鎖,分散式ID生成器,而這些技術的背後,其實都有很多值得我們深挖的點。
時間關係,我們今天就講到這裡,對於快取和Redis的學習,就從這篇文章開始吧。
部落格
Java技術倉庫《Java程式設計師複習指南》
https://github.com/h2pl/Java-Tutorial
整合全網優質Java學習內容,幫助你從基礎到進階系統化複習Java
面試指南
全網最熱的Java面試指南,共200多頁,非常實用,不管是用於複習還是準備面試都是不錯的。
在公眾號【Java技術江湖】回復「PDF」即可免費領取。
寫在最後
如果覺得本文對你有幫助的話,請你也不要吝嗇你的「好看」哈,轉發朋友圈就是對我最大的支援啦,你們的支援是對我最大的鼓勵。
對本系列文章有什麼建議和意見,也歡迎留言告訴我,期待你的回饋。
