設計一個文件系統,需要考慮哪些因素?
- 2020 年 3 月 18 日
- 筆記
文件系統的實現
在對文件有了基本認識之後,現在是時候把目光轉移到文件系統的實現上了。之前用戶關心的一直都是文件是怎樣命名的、可以進行哪些操作、目錄樹是什麼,如何找到正確的文件路徑等問題。而設計人員關心的是文件和目錄是怎樣存儲的、磁碟空間是如何管理的、如何使文件系統得以流暢運行的問題,下面我們就來一起討論一下這些問題。
文件系統布局
文件系統存儲在磁碟中。大部分的磁碟能夠劃分出一到多個分區,叫做磁碟分區(disk partitioning) 或者是磁碟分片(disk slicing)。每個分區都有獨立的文件系統,每塊分區的文件系統可以不同。磁碟的 0 號分區稱為 主引導記錄(Master Boot Record, MBR),用來引導(boot) 電腦。在 MBR 的結尾是分區表(partition table)。每個分區表給出每個分區由開始到結束的地址。系統管理員使用一個稱為分區編輯器的程式來創建,調整大小,刪除和操作分區。這種方式的一個缺點是很難適當調整分區的大小,導致一個分區具有很多可用空間,而另一個分區幾乎完全被分配。
MBR 可以用在 DOS 、Microsoft Windows 和 Linux 作業系統中。從 2010 年代中期開始,大多數新電腦都改用 GUID 分區表(GPT)分區方案。
下面是一個用 GParted 進行分區的磁碟,表中的分區都被認為是 活動的(active)。
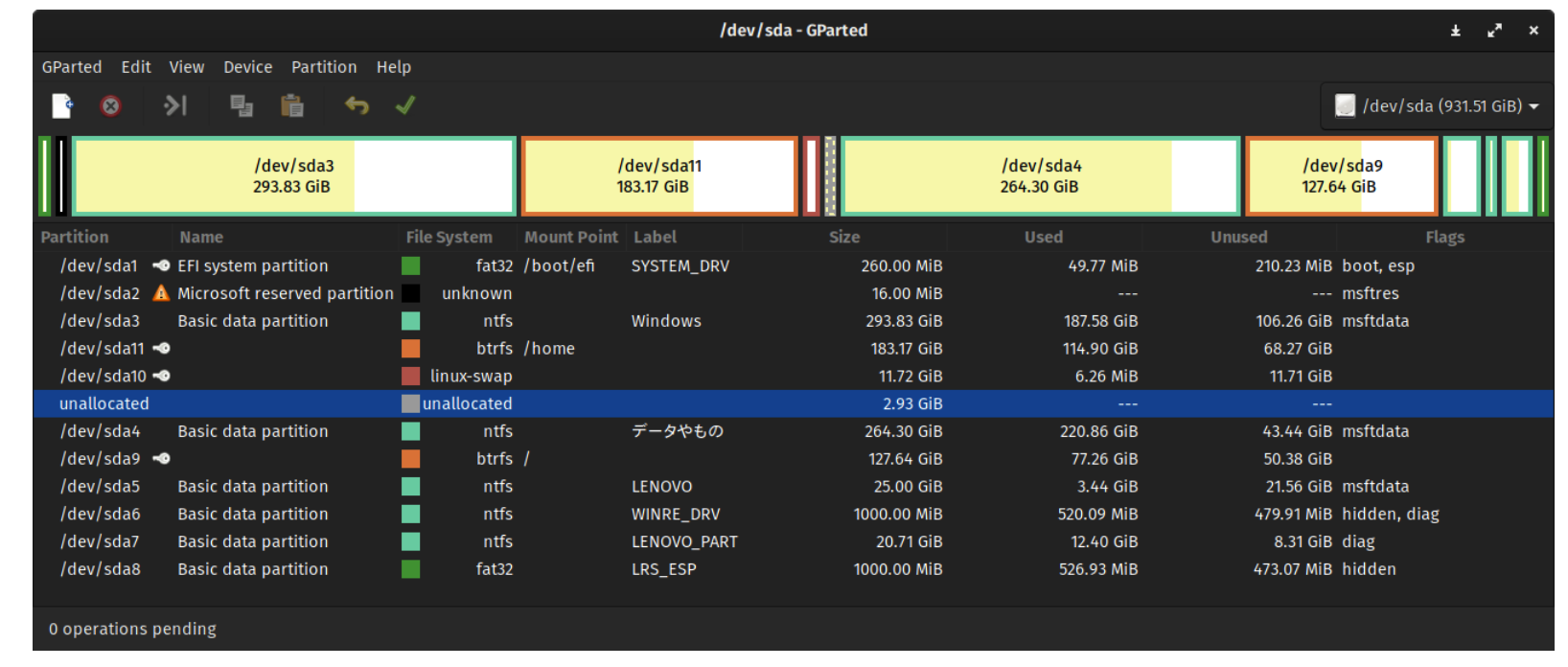
當電腦開始引 boot 時,BIOS 讀入並執行 MBR。
引導塊
MBR 做的第一件事就是確定活動分區,讀入它的第一個塊,稱為引導塊(boot block) 並執行。引導塊中的程式將載入分區中的作業系統。為了一致性,每個分區都會從引導塊開始,即使引導塊不包含作業系統。引導塊佔據文件系統的前 4096 個位元組,從磁碟上的位元組偏移量 0 開始。引導塊可用於啟動作業系統。
在電腦中,引導就是啟動電腦的過程,它可以通過硬體(例如按下電源按鈕)或者軟體命令的方式來啟動。開機後,電腦的 CPU 還不能執行指令,因為此時沒有軟體在主存中,所以一些軟體必須先被載入到記憶體中,然後才能讓 CPU 開始執行。也就是電腦開機後,首先會進行軟體的裝載過程。
重啟電腦的過程稱為
重新引導(rebooting),從休眠或睡眠狀態返回電腦的過程不涉及啟動。
除了從引導塊開始之外,磁碟分區的布局是隨著文件系統的不同而變化的。通常文件系統會包含一些屬性,如下
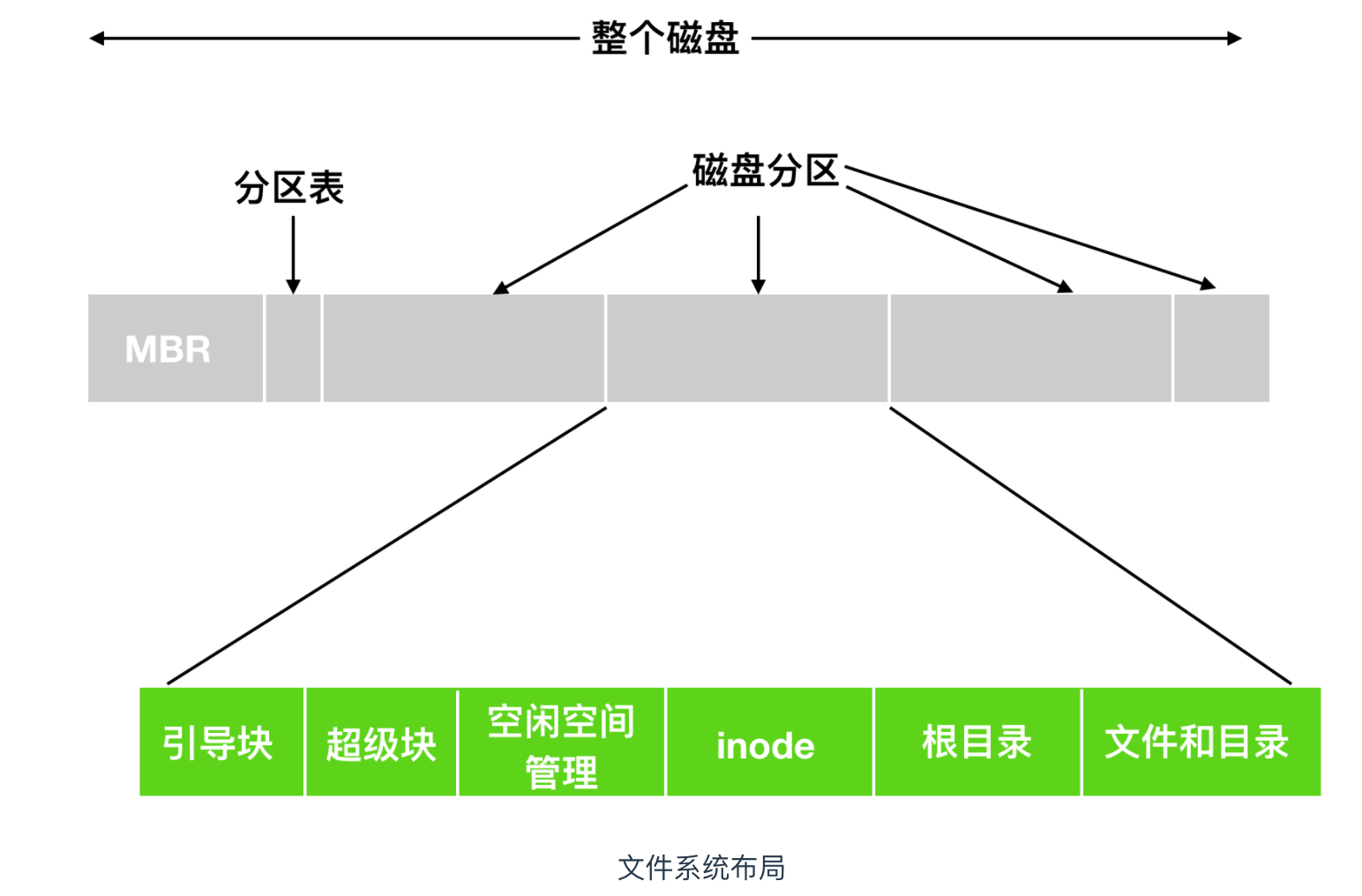
超級塊
緊跟在引導塊後面的是 超級塊(Superblock),超級塊 的大小為 4096 位元組,從磁碟上的位元組偏移 4096 開始。超級塊包含文件系統的所有關鍵參數
- 文件系統的大小
- 文件系統中的數據塊數
- 指示文件系統狀態的標誌
- 分配組大小
在電腦啟動或者文件系統首次使用時,超級塊會被讀入記憶體。
空閑空間塊
接著是文件系統中空閑塊的資訊,例如,可以用點陣圖或者指針列表的形式給出。
BitMap 點陣圖或者 Bit vector 位向量
點陣圖或位向量是一系列位或位的集合,其中每個位對應一個磁碟塊,該位可以採用兩個值:0和1,0表示已分配該塊,而1表示一個空閑塊。下圖中的磁碟上給定的磁碟塊實例(分配了綠色塊)可以用16位的點陣圖表示為:0000111000000110。

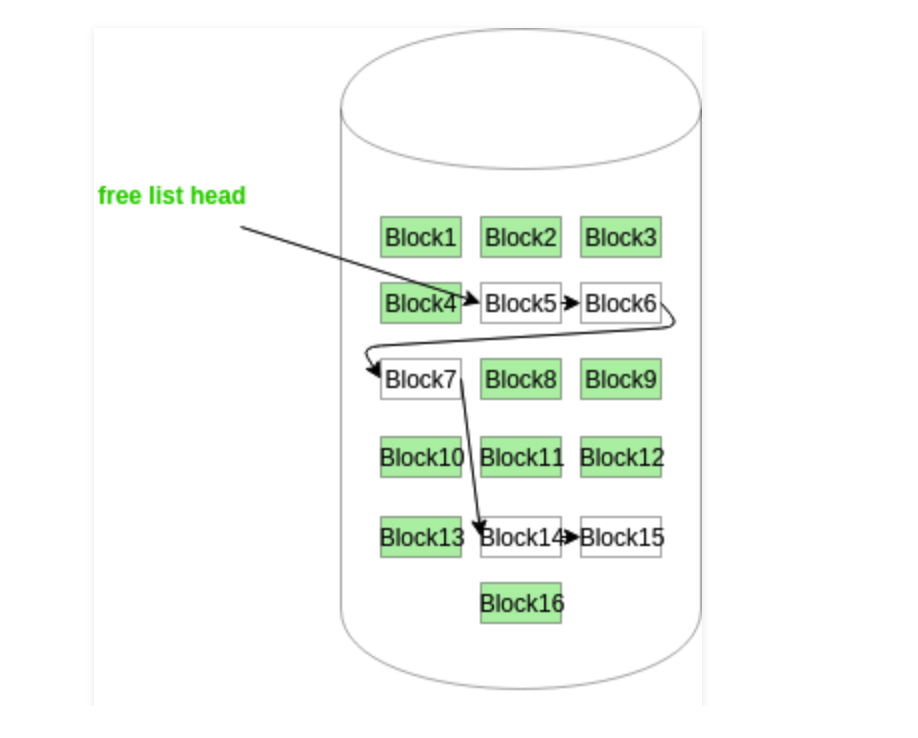
使用鏈表進行管理
在這種方法中,空閑磁碟塊鏈接在一起,即一個空閑塊包含指向下一個空閑塊的指針。第一個磁碟塊的塊號存儲在磁碟上的單獨位置,也快取在記憶體中。
碎片
這裡不得不提一個叫做碎片(fragment)的概念,也稱為片段。一般零散的單個數據通常稱為片段。 磁碟塊可以進一步分為固定大小的分配單元,片段只是在驅動器上彼此不相鄰的文件片段。如果你不理解這個概念就給你舉個例子。比如你用 Windows 電腦創建了一個文件,你會發現這個文件可以存儲在任何地方,比如存在桌面上,存在磁碟中的文件夾中或者其他地方。你可以打開文件,編輯文件,刪除文件等等。你可能以為這些都在一個地方發生,但是實際上並不是,你的硬碟驅動器可能會將文件中的一部分存儲在一個區域內,另一部分存儲在另外一個區域,在你打開文件時,硬碟驅動器會迅速的將文件的所有部分匯總在一起,以便其他電腦系統可以使用它。

inode
然後在後面是一個 inode(index node),也稱作索引節點。它是一個數組的結構,每個文件有一個 inode,inode 非常重要,它說明了文件的方方面面。每個索引節點都存儲對象數據的屬性和磁碟塊位置
有一種簡單的方法可以找到它們 ls -lai 命令。讓我們看一下根文件系統:

inode 節點主要包括了以下資訊
- 模式/許可權(保護)
- 所有者 ID
- 組 ID
- 文件大小
- 文件的硬鏈接數
- 上次訪問時間
- 最後修改時間
- inode 上次修改時間
文件分為兩部分,索引節點和塊。一旦創建後,每種類型的塊數是固定的。你不能增加分區上 inode 的數量,也不能增加磁碟塊的數量。
緊跟在 inode 後面的是根目錄,它存放的是文件系統目錄樹的根部。最後,磁碟的其他部分存放了其他所有的目錄和文件。
文件的實現
最重要的問題是記錄各個文件分別用到了哪些磁碟塊。不同的系統採用了不同的方法。下面我們會探討一下這些方式。分配背後的主要思想是有效利用文件空間和快速訪問文件 ,主要有三種分配方案
- 連續分配
- 鏈表分配
- 索引分配
連續分配
最簡單的分配方案是把每個文件作為一連串連續數據塊存儲在磁碟上。因此,在具有 1KB 塊的磁碟上,將為 50 KB 文件分配 50 個連續塊。
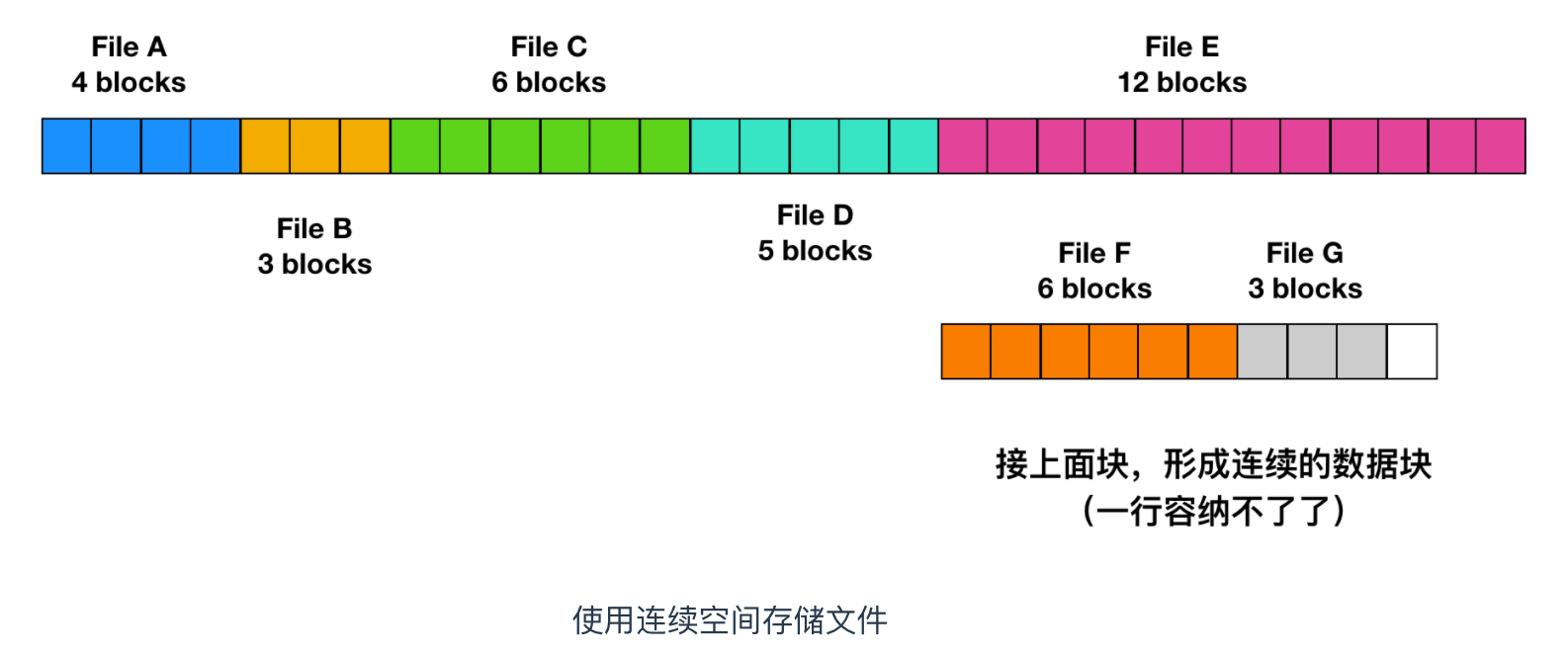
上面展示了 40 個連續的記憶體塊。從最左側的 0 塊開始。初始狀態下,還沒有裝載文件,因此磁碟是空的。接著,從磁碟開始處(塊 0 )處開始寫入佔用 4 塊長度的記憶體 A 。然後是一個佔用 6 塊長度的記憶體 B,會直接在 A 的末尾開始寫。
注意每個文件都會在新的文件塊開始寫,所以如果文件 A 只佔用了 3 又 1/2 個塊,那麼最後一個塊的部分記憶體會被浪費。在上面這幅圖中,總共展示了 7 個文件,每個文件都會從上個文件的末尾塊開始寫新的文件塊。
連續的磁碟空間分配有兩個優點。
-
第一,連續文件存儲實現起來比較簡單,只需要記住兩個數字就可以:一個是第一個塊的文件地址和文件的塊數量。給定第一個塊的編號,可以通過簡單的加法找到任何其他塊的編號。
-
第二點是讀取性能比較強,可以通過一次操作從文件中讀取整個文件。只需要一次尋找第一個塊。後面就不再需要尋道時間和旋轉延遲,所以數據會以全頻寬進入磁碟。
因此,連續的空間分配具有實現簡單、高性能的特點。
不幸的是,連續空間分配也有很明顯的不足。隨著時間的推移,磁碟會變得很零碎。下圖解釋了這種現象
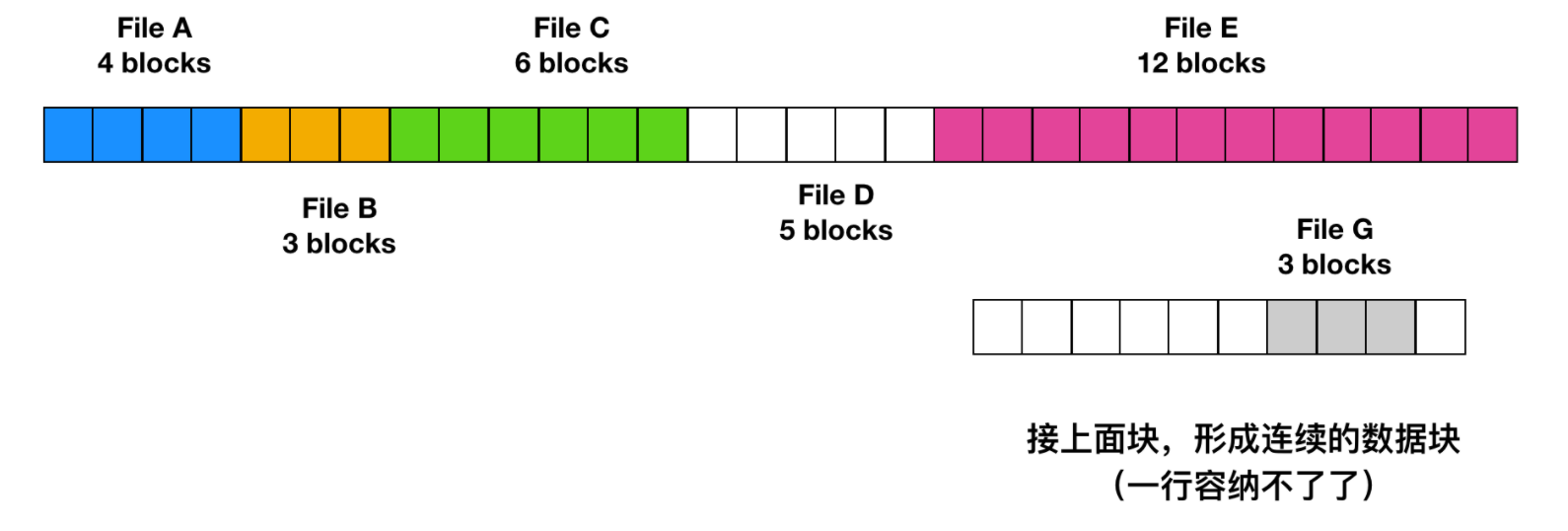
這裡有兩個文件 D 和 F 被刪除了。當刪除一個文件時,此文件所佔用的塊也隨之釋放,就會在磁碟空間中留下一些空閑塊。磁碟並不會在這個位置擠壓掉空閑塊,因為這會複製空閑塊之後的所有文件,可能會有上百萬的塊,這個量級就太大了。
剛開始的時候,這個碎片不是問題,因為每個新文件都會在之前文件的結尾處進行寫入。然而,磁碟最終會被填滿,因此要麼壓縮磁碟、要麼重新使用空閑塊的空間。壓縮磁碟的開銷太大,因此不可行;後者會維護一個空閑列表,這個是可行的。但是這種情況又存在一個問題,為空閑塊匹配合適大小的文件,需要知道該文件的最終大小。
想像一下這種設計的結果會是怎樣的。用戶啟動 word 進程創建文檔。應用程式首先會詢問最終創建的文檔會有多大。這個問題必須回答,否則應用程式就不會繼續執行。如果空閑塊的大小要比文件的大小小,程式就會終止。因為所使用的磁碟空間已經滿了。那麼現實生活中,有沒有使用連續分配記憶體的介質出現呢?
CD-ROM 就廣泛的使用了連續分配方式。
CD-ROM(Compact Disc Read-Only Memory)即只讀光碟,也稱作只讀存儲器。是一種在電腦上使用的光碟。這種光碟只能寫入數據一次,資訊將永久保存在光碟上,使用時通過光碟驅動器讀出資訊。

然而 DVD 的情況會更加複雜一些。原則上,一個 90分鐘 的電影能夠被編碼成一個獨立的、大約 4.5 GB 的文件。但是文件系統所使用的 UDF(Universal Disk Format) 格式,使用一個 30 位的數來代表文件長度,從而把文件大小限制在 1 GB。所以,DVD 電影一般存儲在 3、4個連續的 1 GB 空間內。這些構成單個電影中的文件塊稱為擴展區(extends)。
就像我們反覆提到的,歷史總是驚人的相似,許多年前,連續分配由於其簡單和高性能被實際使用在磁碟文件系統中。後來由於用戶不希望在創建文件時指定文件的大小,於是放棄了這種想法。但是隨著 CD-ROM 、DVD、藍光光碟等光學介質的出現,連續分配又流行起來。從而得出結論,技術永遠沒有過時性,現在看似很老的技術,在未來某個階段可能又會流行起來。
鏈表分配
第二種存儲文件的方式是為每個文件構造磁碟塊鏈表,每個文件都是磁碟塊的鏈接列表,就像下面所示
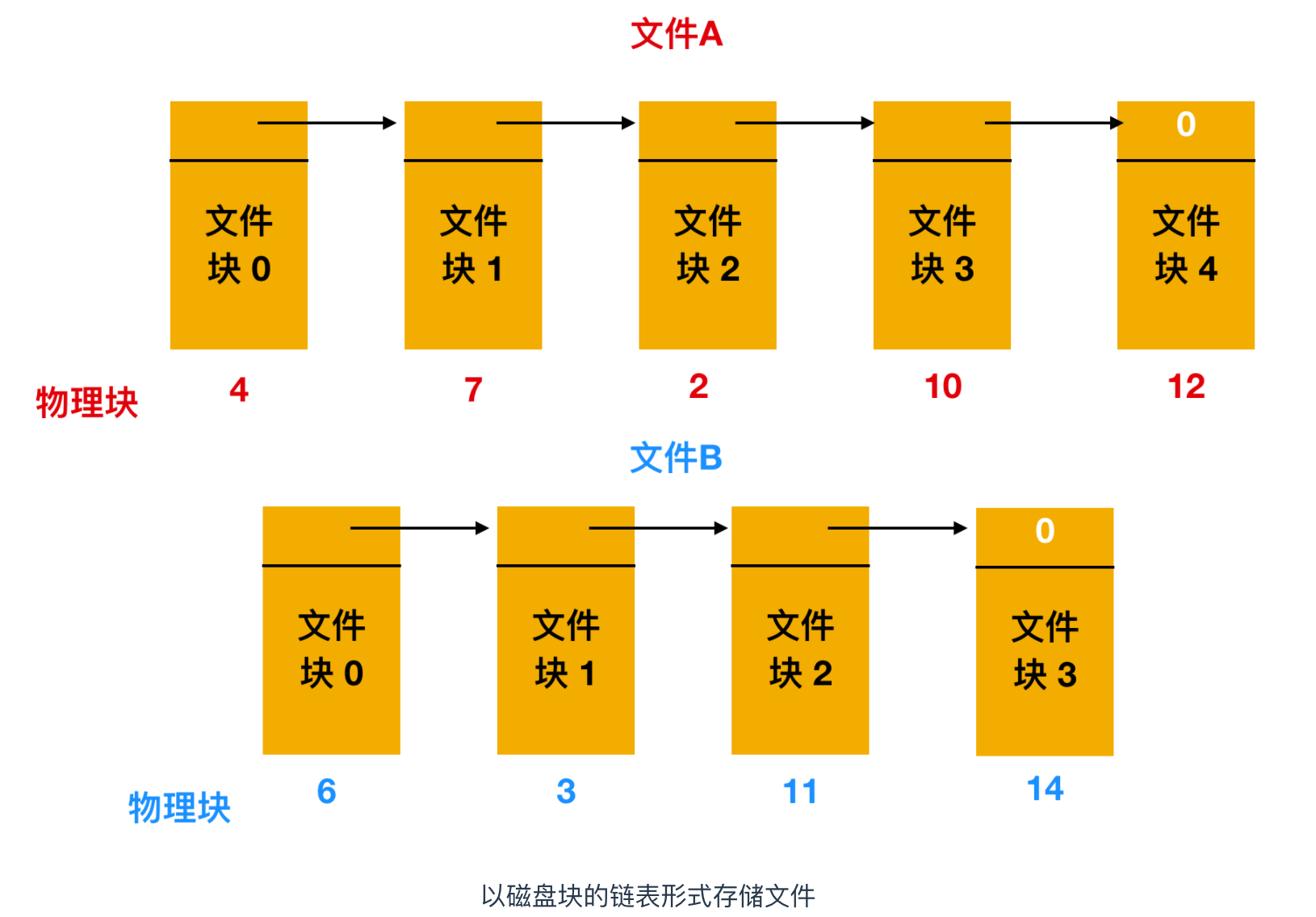
每個塊的第一個字作為指向下一塊的指針,塊的其他部分存放數據。如果上面這張圖你看的不是很清楚的話,可以看看整個的鏈表分配方案
與連續分配方案不同,這一方法可以充分利用每個磁碟塊。除了最後一個磁碟塊外,不會因為磁碟碎片而浪費存儲空間。同樣,在目錄項中,只要存儲了第一個文件塊,那麼其他文件塊也能夠被找到。
另一方面,在鏈表的分配方案中,儘管順序讀取非常方便,但是隨機訪問卻很困難(這也是數組和鏈表數據結構的一大區別)。
還有一個問題是,由於指針會佔用一些位元組,每個磁碟塊實際存儲數據的位元組數並不再是 2 的整數次冪。雖然這個問題並不會很嚴重,但是這種方式降低了程式運行效率。許多程式都是以長度為 2 的整數次冪來讀寫磁碟,由於每個塊的前幾個位元組被指針所使用,所以要讀出一個完成的塊大小資訊,就需要當前塊的資訊和下一塊的資訊拼湊而成,因此就引發了查找和拼接的開銷。
使用記憶體表進行鏈表分配
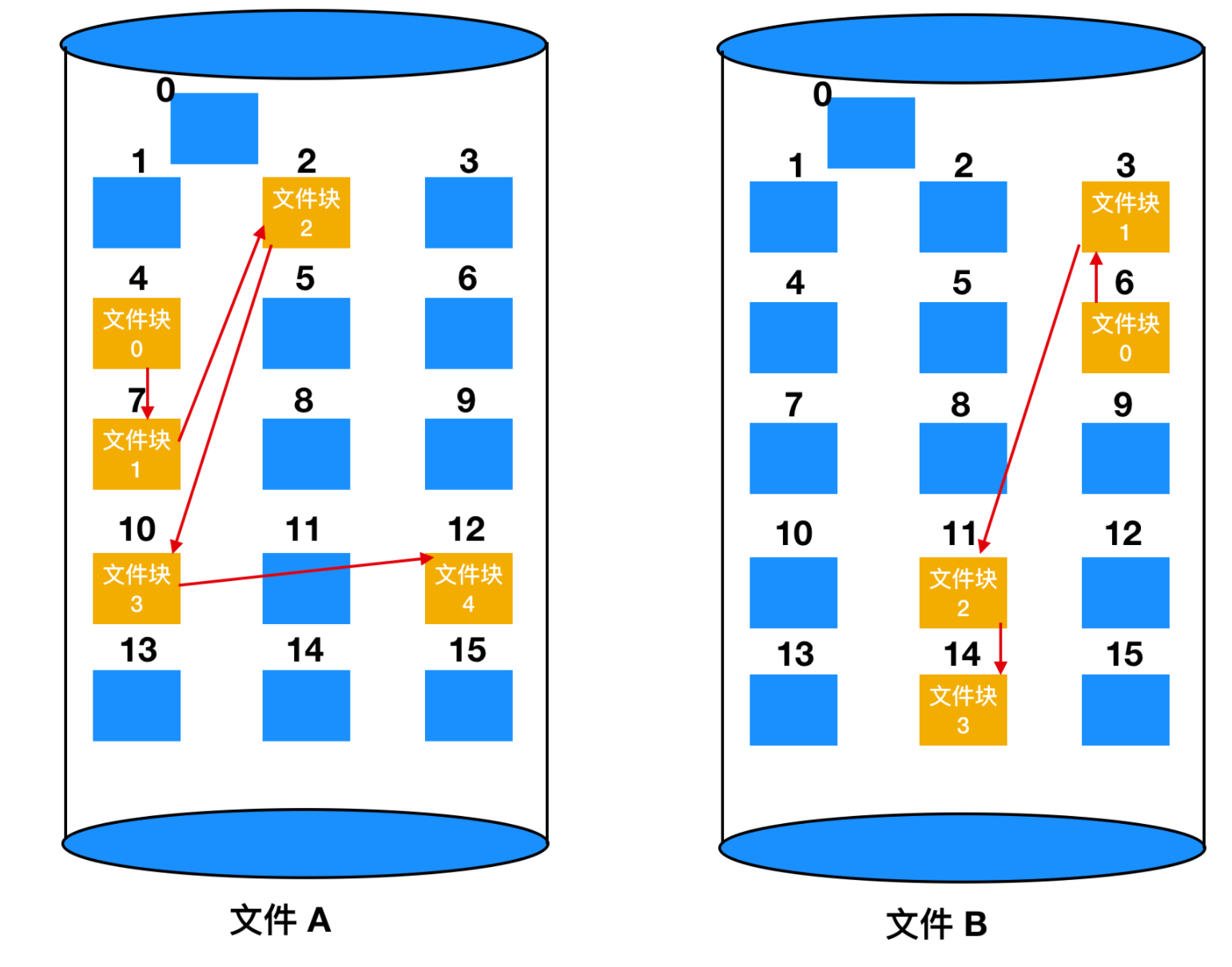
由於連續分配和鏈表分配都有其不可忽視的缺點。所以提出了使用記憶體中的表來解決分配問題。取出每個磁碟塊的指針字,把它們放在記憶體的一個表中,就可以解決上述鏈表的兩個不足之處。下面是一個例子

上圖表示了鏈表形成的磁碟塊的內容。這兩個圖中都有兩個文件,文件 A 依次使用了磁碟塊地址 4、7、 2、 10、 12,文件 B 使用了6、3、11 和 14。也就是說,文件 A 從地址 4 處開始,順著鏈表走就能找到文件 A 的全部磁碟塊。同樣,從第 6 塊開始,順著鏈走到最後,也能夠找到文件 B 的全部磁碟塊。你會發現,這兩個鏈表都以不屬於有效磁碟編號的特殊標記(-1)結束。記憶體中的這種表格稱為 文件分配表(File Application Table,FAT)。
使用這種組織方式,整個塊都可以存放數據。進而,隨機訪問也容易很多。雖然仍要順著鏈在記憶體中查找給定的偏移量,但是整個鏈都存放在記憶體中,所以不需要任何磁碟引用。與前面的方法相同,不管文件有多大,在目錄項中只需記錄一個整數(起始塊號),按照它就可以找到文件的全部塊。
這種方式存在缺點,那就是必須要把整個鏈表放在記憶體中。對於 1TB 的磁碟和 1KB 的大小的塊,那麼這張表需要有 10 億項。。。每一項對應於這 10 億個磁碟塊中的一塊。每項至少 3 個位元組,為了提高查找速度,有時需要 4 個位元組。根據系統對空間或時間的優化方案,這張表要佔用 3GB 或 2.4GB 的記憶體。FAT 的管理方式不能較好地擴展並應用於大型磁碟中。而這正是最初 MS-DOS 文件比較實用,並仍被各個 Windows 版本所安全支援。
inode
最後一個記錄各個文件分別包含哪些磁碟塊的方法是給每個文件賦予一個稱為 inode(索引節點) 的數據結構,每個文件都與一個 inode 進行關聯,inode 由整數進行標識。
下面是一個簡單例子的描述。
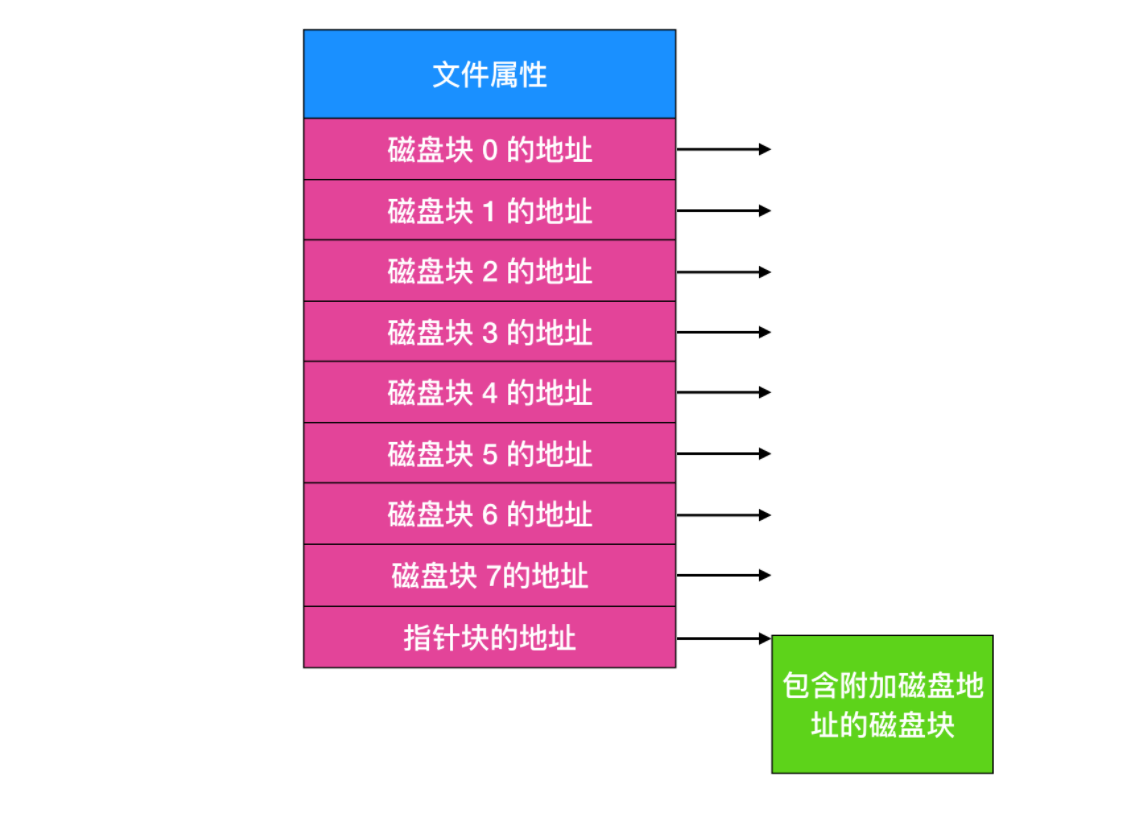
給出 inode 的長度,就能夠找到文件中的所有塊。
相對於在記憶體中使用表的方式而言,這種機制具有很大的優勢。即只有在文件打開時,其 inode 才會在記憶體中。如果每個 inode 需要 n 個位元組,最多 k 個文件同時打開,那麼 inode 佔有總共打開的文件是 kn 位元組。僅需預留這麼多空間。
這個數組要比我們上面描述的 FAT(文件分配表) 佔用的空間小的多。原因是用於保存所有磁碟塊的鏈接列表的表的大小與磁碟本身成正比。如果磁碟有 n 個塊,那麼這個表也需要 n 項。隨著磁碟空間的變大,那麼該表也隨之線性增長。相反,inode 需要節點中的數組,其大小和可能需要打開的最大文件個數成正比。它與磁碟是 100GB、4000GB 還是 10000GB 無關。
inode 的一個問題是如果每個節點都會有固定大小的磁碟地址,那麼文件增長到所能允許的最大容量外會發生什麼?一個解決方案是最後一個磁碟地址不指向數據塊,而是指向一個包含額外磁碟塊地址的地址,如上圖所示。一個更高級的解決方案是:有兩個或者更多包含磁碟地址的塊,或者指向其他存放地址的磁碟塊的磁碟塊。Windows 的 NTFS 文件系統採用了相似的方法,所不同的僅僅是大的 inode 也可以表示小的文件。
NTFS 的全稱是
New Technology File System,是微軟公司開發的專用系統文件,NTFS 取代 FAT(文件分配表) 和HPFS(高性能文件系統),並在此基礎上進一步改進。例如增強對元數據的支援,使用更高級的數據結構以提升性能、可靠性和磁碟空間利用率等。
目錄的實現
文件只有打開後才能夠被讀取。在文件打開後,作業系統會使用用戶提供的路徑名來定位磁碟中的目錄。目錄項提供了查找文件磁碟塊所需要的資訊。根據系統的不同,提供的資訊也不同,可能提供的資訊是整個文件的磁碟地址,或者是第一個塊的數量(兩個鏈表方案)或 inode的數量。不過不管用那種情況,目錄系統的主要功能就是 將文件的 ASCII 碼的名稱映射到定位數據所需的資訊上。
與此關係密切的問題是屬性應該存放在哪裡。每個文件系統包含不同的文件屬性,例如文件的所有者和創建時間,需要存儲的位置。一種顯而易見的方法是直接把文件屬性存放在目錄中。有一些系統恰好是這麼做的,如下。
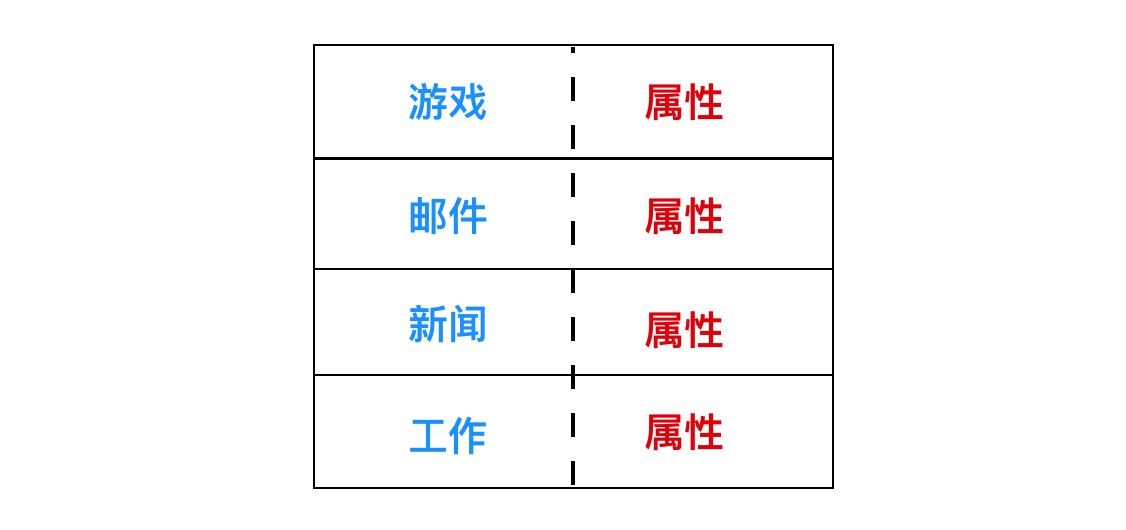
在這種簡單的設計中,目錄有一個固定大小的目錄項列表,每個文件對應一項,其中包含一個固定長度的文件名,文件屬性的結構體以及用以說明磁碟塊位置的一個或多個磁碟地址。
對於採用 inode 的系統,會把 inode 存儲在屬性中而不是目錄項中。在這種情況下,目錄項會更短:僅僅只有文件名稱和 inode 數量。這種方式如下所示
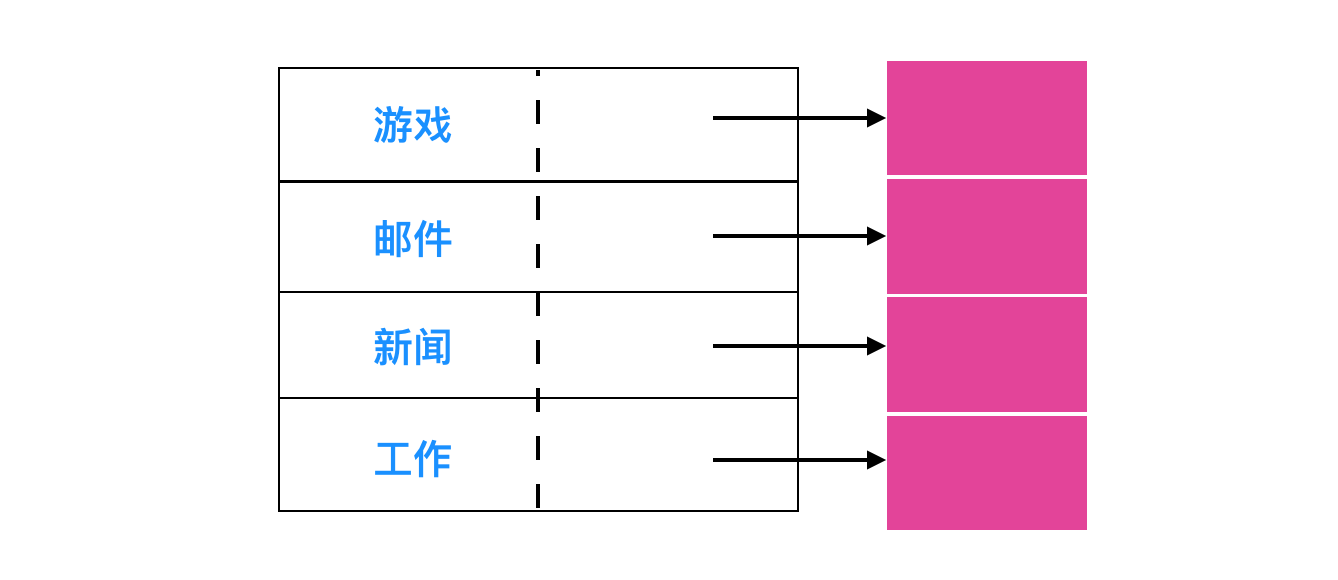
到目前為止,我們已經假設文件具有較短的、固定長度的名字。在 MS-DOS 中,具有 1 – 8 個字元的基本名稱和 1 – 3 個字元的可拓展名稱。在 UNIX 版本 7 中,文件有 1 – 14 個字元,包括任何拓展。然而,幾乎所有的現代作業系統都支援可變長度的擴展名。這是如何實現的呢?
最簡單的方式是給予文件名一個長度限制,比如 255 個字元,然後使用上圖中的設計,並為每個文件名保留 255 個字元空間。這種處理很簡單,但是浪費了大量的目錄空間,因為只有很少的文件會有那麼長的文件名稱。所以,需要一種其他的結構來處理。
一種可選擇的方式是放棄所有目錄項大小相同的想法。在這種方法中,每個目錄項都包含一個固定部分,這個固定部分通常以目錄項的長度開始,後面是固定格式的數據,通常包括所有者、創建時間、保護資訊和其他屬性。這個固定長度的頭的後面是一個任意長度的實際文件名,如下圖所示
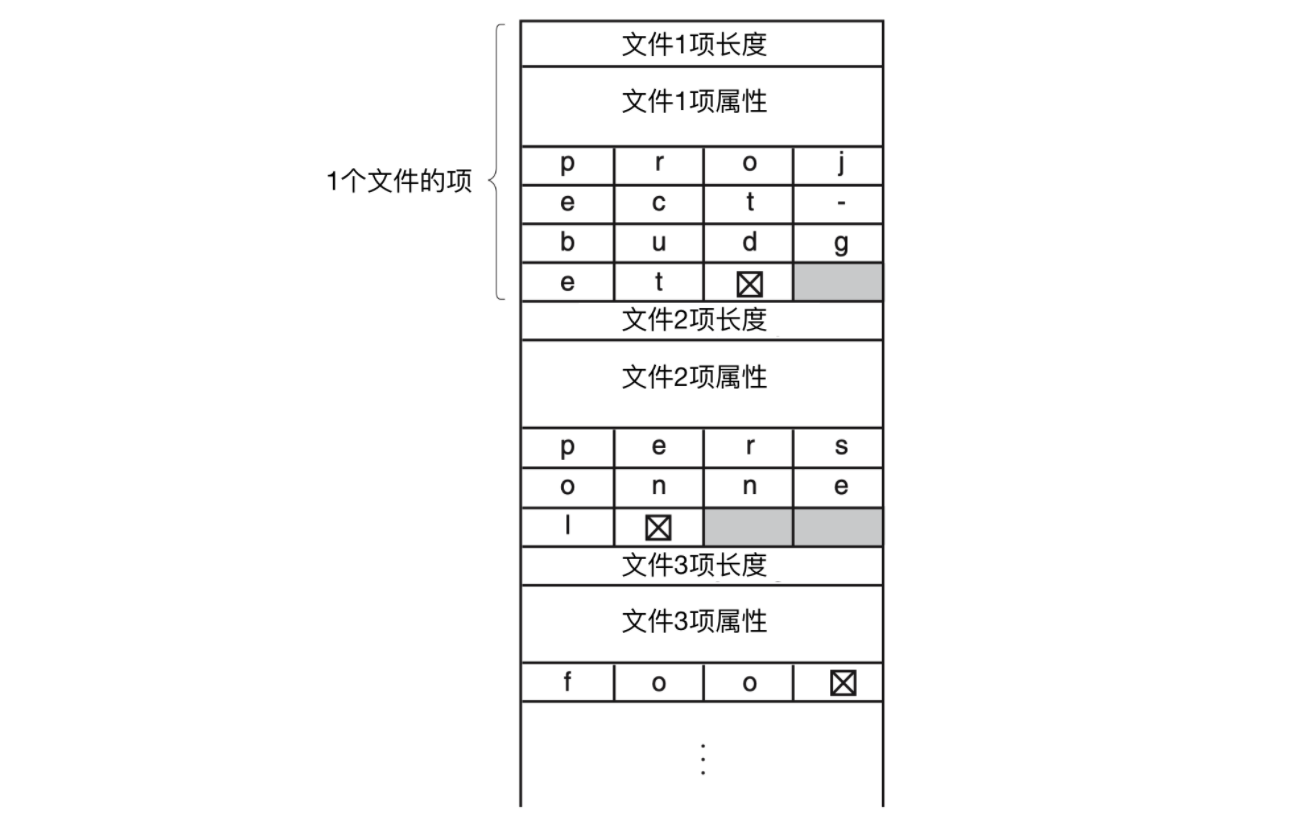
上圖是 SPARC 機器使用正序放置。
處理機中的一串字元存放的順序有
正序(big-endian)和逆序(little-endian)之分。正序存放的就是高位元組在前低位元組在後,而逆序存放的就是低位元組在前高位元組在後。
這個例子中,有三個文件,分別是 project-budget、personnel 和 foo。每個文件名以一個特殊字元(通常是 0 )結束,用矩形中的叉進行表示。為了使每個目錄項從字的邊界開始,每個文件名被填充成整數個字,如下圖所示

這個方法的缺點是當文件被移除後,就會留下一塊固定長度的空間,而新添加進來的文件大小不一定和空閑空間大小一致。
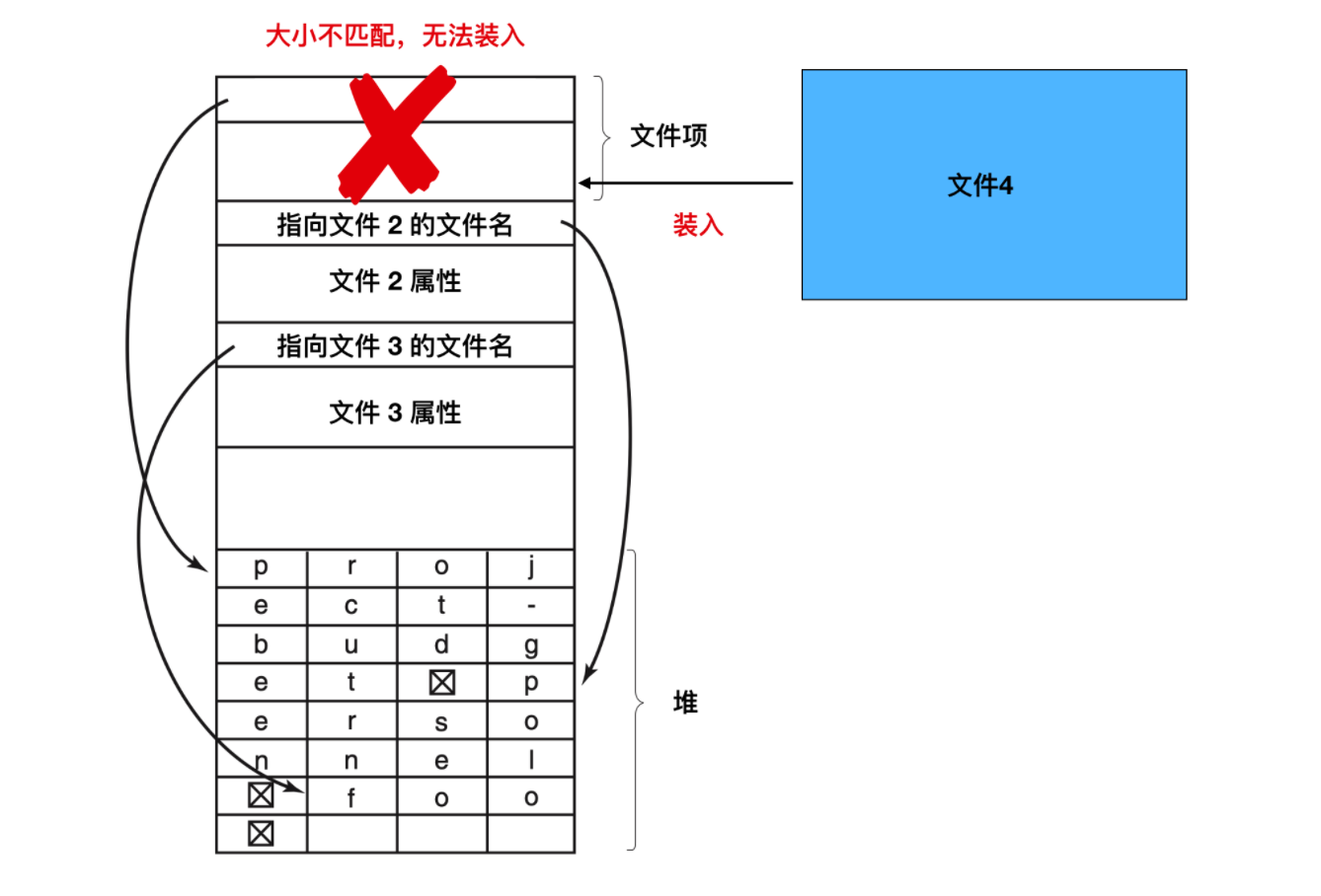
這個問題與我們上面探討的連續磁碟文件的問題是一樣的,由於整個目錄在記憶體中,所以只有對目錄進行緊湊拼接操作才可節省空間。另一個問題是,一個目錄項可能會分布在多個頁上,在讀取文件名時可能發生缺頁中斷。
處理可變長度文件名字的另外一種方法是,使目錄項自身具有固定長度,而將文件名放在目錄末尾的堆棧中。如上圖所示的這種方式。這種方法的優點是當目錄項被移除後,下一個文件將能夠正常匹配移除文件的空間。當然,必須要對堆進行管理,因為在處理文件名的時候也會發生缺頁異常。
到目前為止的所有設計中,在需要查找文件名時,所有的方案都是線性的從頭到尾對目錄進行搜索。對於特別長的目錄,線性搜索的效率很低。提高文件檢索效率的一種方式是在每個目錄上使用哈希表(hash table),也叫做散列表。我們假設表的大小為 n,在輸入文件名時,文件名被散列在 0 和 n – 1 之間,例如,它被 n 除,並取餘數。或者對構成文件名字的字求和或類似某種方法。
無論採用哪種方式,在添加一個文件時都要對與散列值相對應的散列表進行檢查。如果沒有使用過,就會將一個指向目錄項的指針指向這裡。文件目錄項緊跟著哈希表後面。如果已經使用過,就會構造一個鏈表(這種構造方式是不是和 HashMap 使用的數據結構一樣?),鏈表的表頭指針存放在表項中,並通過哈希值將所有的表項相連。
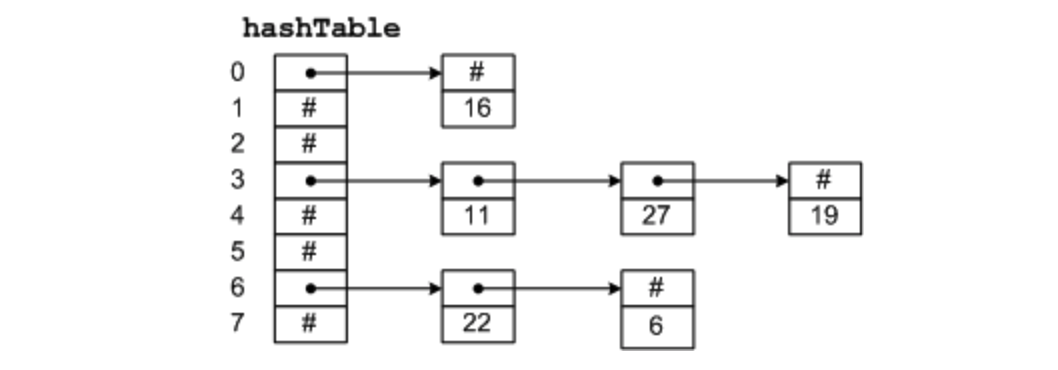
查找文件的過程和添加類似,首先對文件名進行哈希處理,在哈希表中查找是否有這個哈希值,如果有的話,就檢查這條鏈上所有的哈希項,查看文件名是否存在。如果哈希不在鏈上,那麼文件就不在目錄中。
使用哈希表的優勢是查找非常迅速,缺點是管理起來非常複雜。只有在系統中會有成千上萬個目錄項存在時,才會考慮使用散列表作為解決方案。
另外一種在大量目錄中加快查找指令目錄的方法是使用快取,快取查找的結果。在開始查找之前,會首先檢查文件名是否在快取中。如果在快取中,那麼文件就能立刻定位。當然,只有在較少的文件下進行多次查找,快取才會發揮最大功效。
共享文件
當多個用戶在同一個項目中工作時,他們通常需要共享文件。如果這個共享文件同時出現在多個用戶目錄下,那麼他們協同工作起來就很方便。下面的這張圖我們在上面提到過,但是有一個更改的地方,就是 C 的一個文件也出現在了 B 的目錄下。
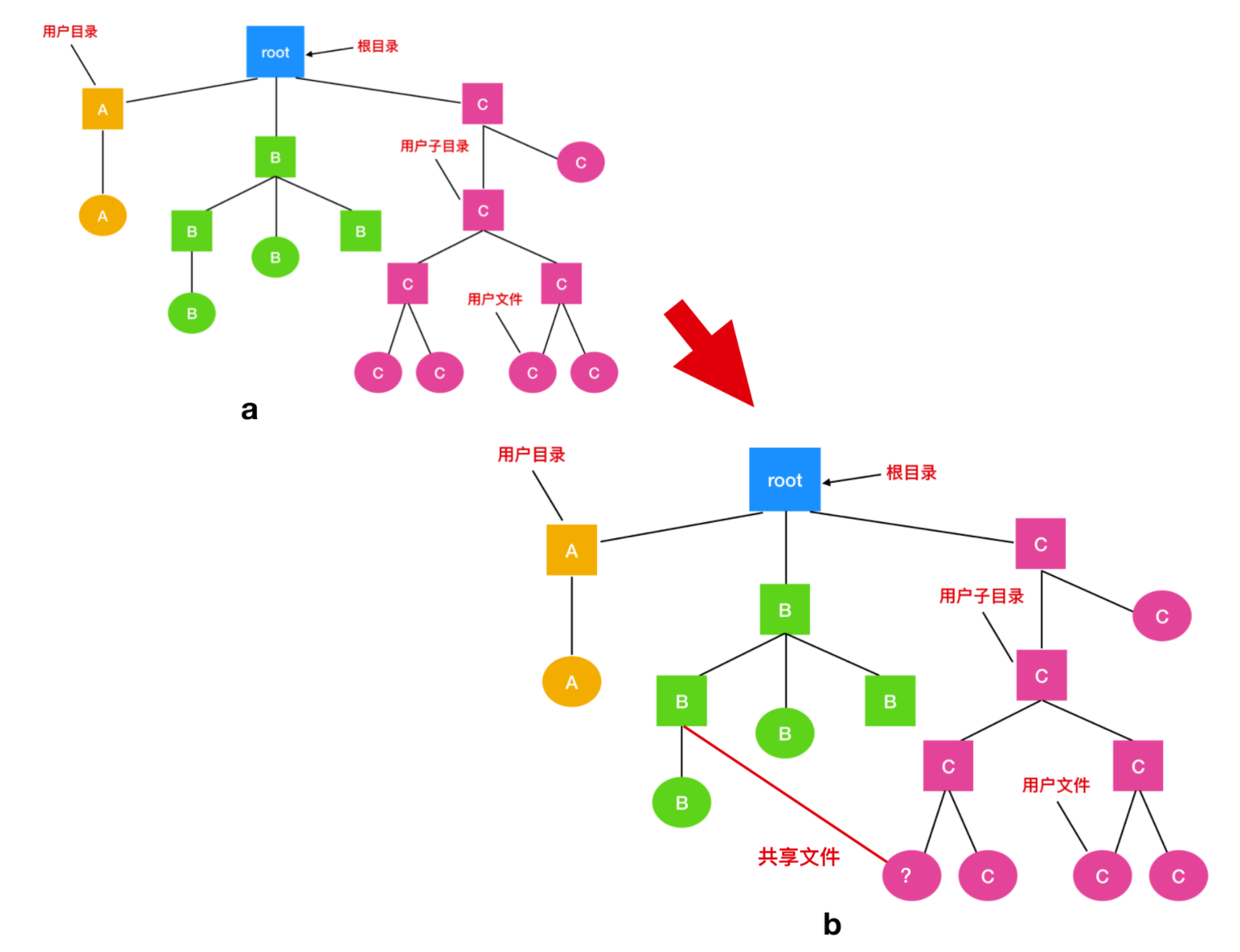
如果按照如上圖的這種組織方式而言,那麼 B 的目錄與該共享文件的聯繫稱為 鏈接(link)。那麼文件系統現在就是一個 有向無環圖(Directed Acyclic Graph, 簡稱 DAG),而不是一棵樹了。
在圖論中,如果一個有向圖從任意頂點出發無法經過若干條邊回到該點,則這個圖是一個
有向無環圖,我們不會在此著重探討關於圖論的東西,大家可以自行 google。
將文件系統組織成為有向無環圖會使得維護複雜化,但也是必須要付出的代價。
共享文件很方便,但這也會帶來一些問題。如果目錄中包含磁碟地址,則當鏈接文件時,必須把 C 目錄中的磁碟地址複製到 B 目錄中。如果 B 或者 C 隨後又向文件中添加內容,則僅在執行追加的用戶的目錄中顯示新寫入的數據塊。這種變更將會對其他用戶不可見,從而破壞了共享的目的。
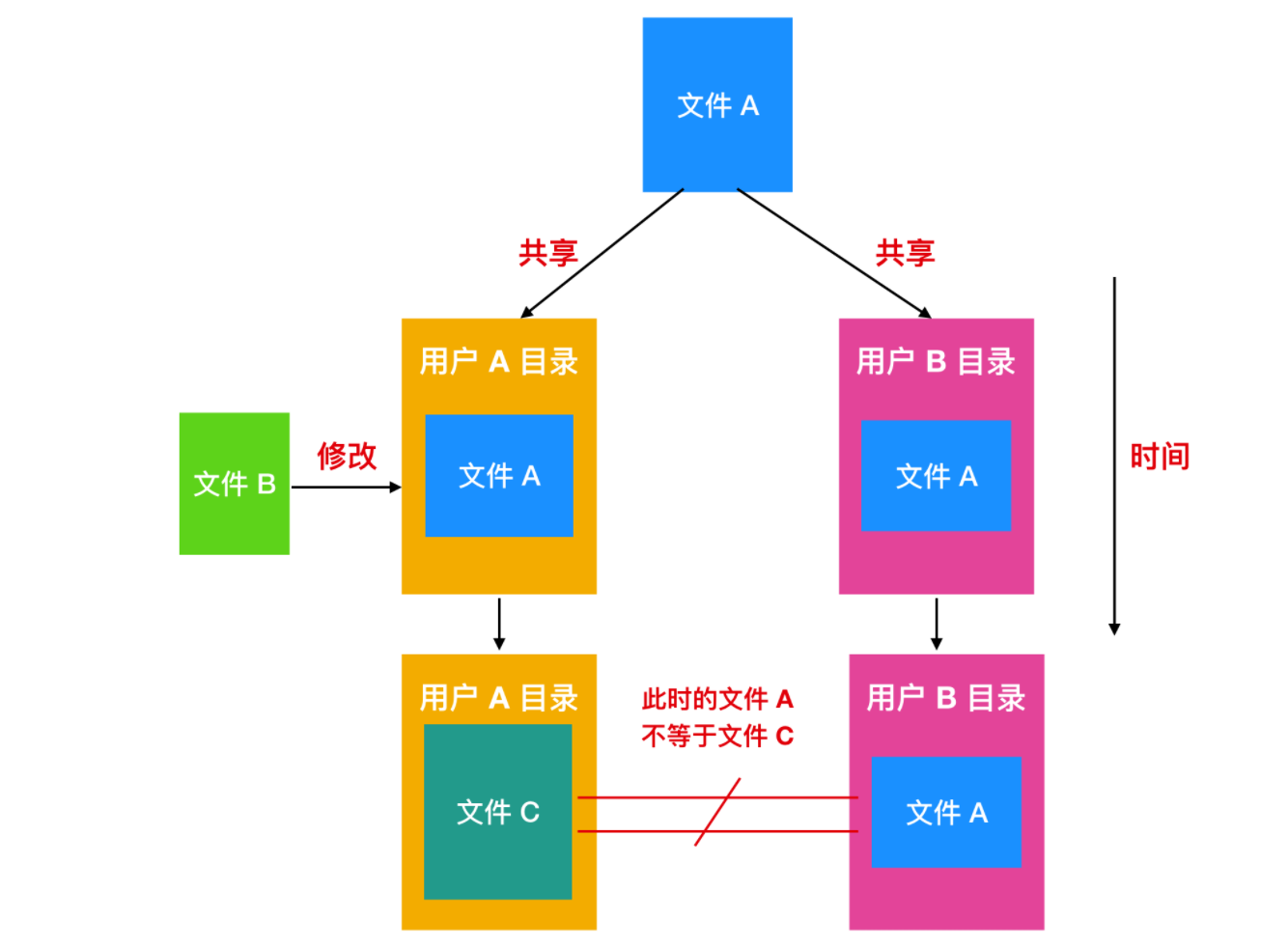
有兩種方案可以解決這種問題。
-
第一種解決方案,磁碟塊不列入目錄中,而是會把磁碟塊放在與文件本身相關聯的小型數據結構中。目錄將指向這個小型數據結構。這是
UNIX中使用的方式(小型數據結構就是 inode)。 -
在第二種解決方案中,通過讓系統建立一個類型為
LINK的新文件,並把該文件放在 B 的目錄下,使得 B 與 C 建立鏈接。新的文件中只包含了它所鏈接的文件的路徑名。當 B 想要讀取文件時,作業系統會檢查 B 的目錄下存在一個類型為 LINK 的文件,進而找到該鏈接的文件和路徑名,然後再去讀文件,這種方式稱為符號鏈接(symbolic linking)。

上面的每一種方法都有各自的缺點,在第一種方式中,B 鏈接到共享文件時,inode 記錄文件的所有者為 C。建立一個鏈接並不改變所有關係,如下圖所示。
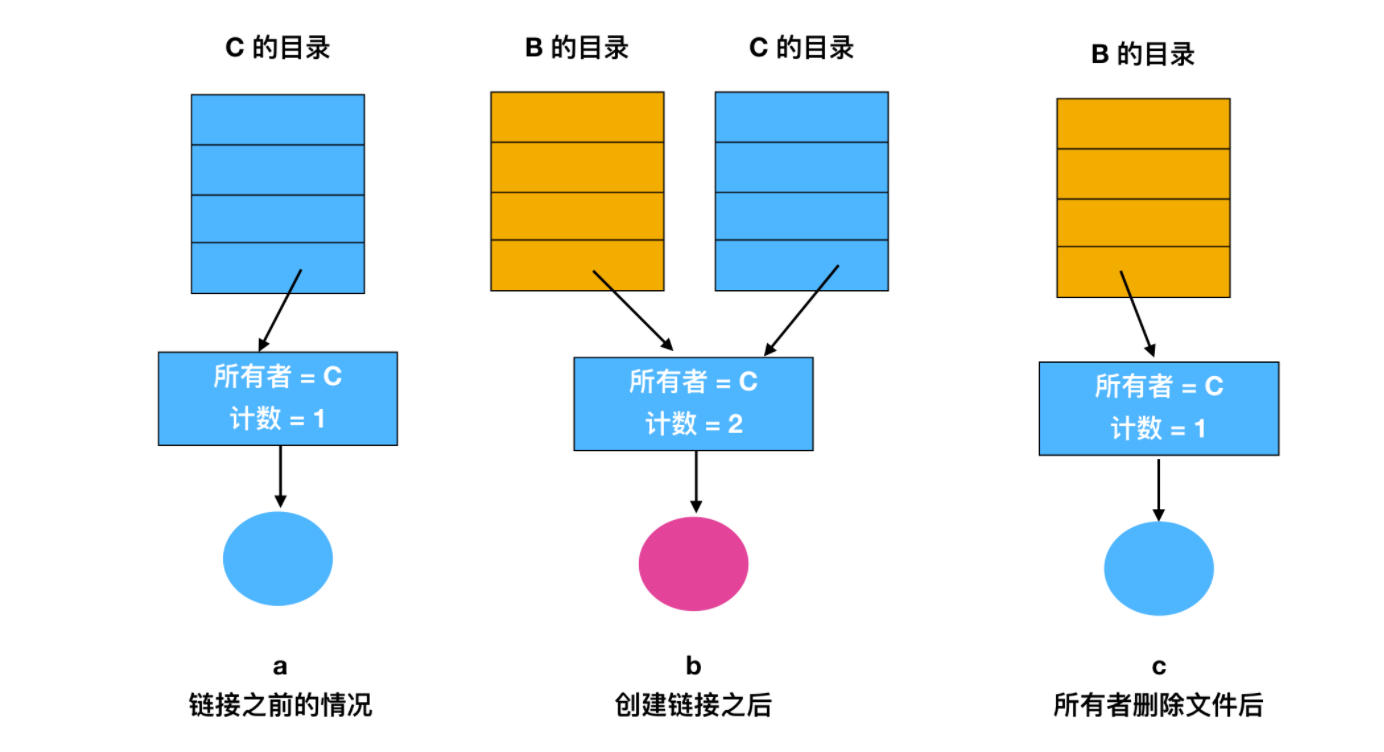
第一開始的情況如圖 a 所示,此時 C 的目錄的所有者是 C ,當目錄 B 鏈接到共享文件時,並不會改變 C 的所有者關係,只是把計數 + 1,所以此時 系統知道目前有多少個目錄指向這個文件。然後 C 嘗試刪除這個文件,這個時候有個問題,如果 C 把文件移除並清除了 inode 的話,那麼 B 會有一個目錄項指向無效的節點。如果 inode 以後分配給另一個文件,則 B 的鏈接指向一個錯誤的文件。系統通過 inode 可知文件仍在被引用,但是沒有辦法找到該文件的全部目錄項以刪除它們。指向目錄的指針不能存儲在 inode 中,原因是有可能有無數個這樣的目錄。
所以我們能做的就是刪除 C 的目錄項,但是將 inode 保留下來,並將計數設置為 1 ,如上圖 c 所示。c 表示的是只有 B 有指向該文件的目錄項,而該文件的前者是 C 。如果系統進行記賬操作的話,那麼 C 將繼續為該文件付賬直到 B 決定刪除它,如果是這樣的話,只有到計數變為 0 的時刻,才會刪除該文件。
對於符號鏈接,以上問題不會發生,只有真正的文件所有者才有一個指向 inode 的指針。鏈接到該文件上的用戶只有路徑名,沒有指向 inode 的指針。當文件所有者刪除文件時,該文件被銷毀。以後若試圖通過符號鏈接訪問該文件將會失敗,因為系統不能找到該文件。刪除符號鏈接不會影響該文件。
符號鏈接的問題是需要額外的開銷。必須讀取包含路徑的文件,然後要一個部分接一個部分地掃描路徑,直到找到 inode 。這些操作也許需要很多次額外的磁碟訪問。此外,每個符號鏈接都需要額外的 inode ,以及額外的一個磁碟塊用於存儲路徑,雖然如果路徑名很短,作為一種優化,系統可以將它存儲在 inode 中。符號鏈接有一個優勢,即只要簡單地提供一個機器的網路地址以及文件在該機器上駐留的路徑,就可以連接全球任何地方機器上的文件。
還有另一個由鏈接帶來的問題,在符號鏈接和其他方式中都存在。如果允許鏈接,文件有兩個或多個路徑。查找一指定目錄及其子目錄下的全部文件的程式將多次定位到被鏈接的文件。例如,一個將某一目錄及其子目錄下的文件轉存到磁帶上的程式有可能多次複製一個被鏈接的文件。進而,如果接著把磁帶讀入另一台機器,除非轉出程式具有智慧,否則被鏈接的文件將被兩次複製到磁碟上,而不是只是被鏈接起來。
相關參考:
https://zhuanlan.zhihu.com/p/41358013
https://www.linuxtoday.com/blog/what-is-an-inode.html
https://www.lifewire.com/what-is-fragmentation-defragmentation-2625884
https://www.geeksforgeeks.org/free-space-management-in-operating-system/
https://en.wikipedia.org/wiki/Disk_partitioning
https://en.wikipedia.org/wiki/Master_boot_record
https://en.wikipedia.org/wiki/Booting
https://www.computerhope.com/jargon/f/fileprot.htm
https://en.wikipedia.org/wiki/File_attribute
https://en.wikipedia.org/wiki/Make_(software)
https://www.computerhope.com/jargon/d/director.htm
https://www.computerhope.com/jargon/r/regular-file.htm
https://baike.baidu.com/item/固態硬碟/453510?fr=aladdin
《現代作業系統》第四版
《Modern Operation System》fourth



