深度學習與人類語言處理-語音識別(part2)
- 2020 年 3 月 18 日
- 筆記
上節回顧深度學習與人類語言處理-語音識別(part1),這節課我們將學習如何將seq2seq模型用在語音識別
LAS

那我們來看看LAS的Encoder,Attend,Decoder分別是什麼
Listen
Listen是一個典型的Encoder結構,輸入為聲學特徵({x^1,x^2,…,x^T}),輸出和輸入長度相同,是對聲學特徵的高階表示,({h^1,h^2,…,h^T}).
我們希望Encoder可以做到以下兩件事:
- 提取輸入的內容資訊
- 移除不同說話者之間的差異,去掉噪音
那Encoder怎麼做呢?可以用RNN、CNN、self-attention
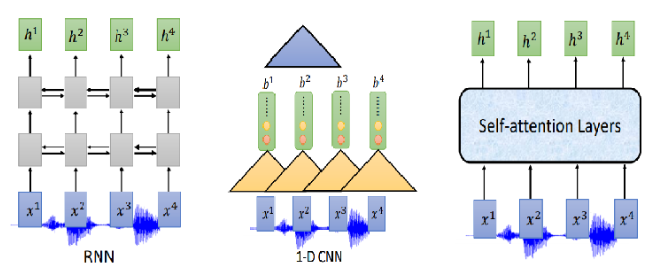
通常我們需要對聲音訊號進行下取樣,為什麼呢?當然是聲音訊號太長了,1s的聲音訊號就有100個向量(上節聲學特徵部分講過),而且相鄰的訊號之間的差異不是特別大,下取樣可以幫助我們有效的進行訓練。下圖是關於RNN的兩個下取樣方法
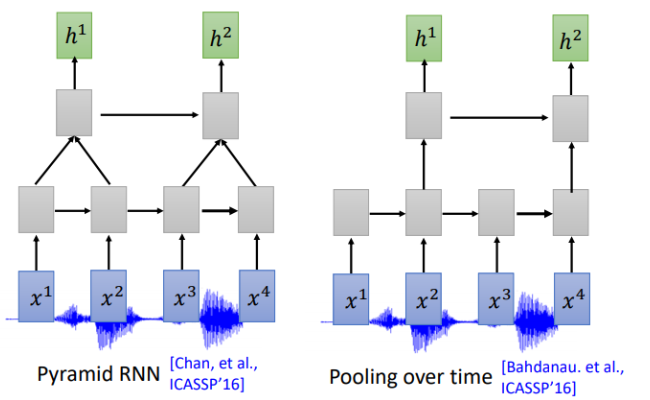
Pyramid RNN將下層每兩個隱狀態加起來作為下一層,實踐證明這種方法還是很有效的。Pooling over time 和Pyramid RNN 很像,不同沒有加起來,直接每兩個隱狀態取一次作為下層輸入。
那CNN和self-attention是不是也可以用類似的下取樣呢?答案是肯定的。對於CNN常用的變形是TDNN (Time-delay DNN),不同於傳統的CNN做卷積操作時會考慮範圍內所有的輸入,TDNN相當於只讓部分參與了運算,提高效率。
同樣,對於self-attention,在機器翻譯等任務中每一個位置的輸入會看過序列中所有的輸入,但是在語音識別中,序列實在太長了,Truncated Self-attention 就是讓每一個位置的輸入只看窗口範圍內的其他輸入,窗口大小是一個可以調節的參數,例如可以只看未來4個,看以前的30個。

attention
LAS的attention和機器翻譯中的attention並沒有什麼不同,文獻中提到了兩種attention計算方法,dot-product attention 和additive attention
- dot-product attention
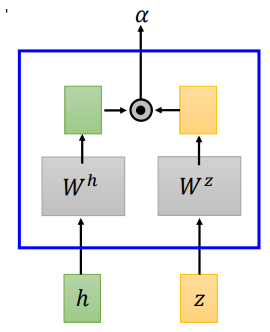
dot-product attention 將輸入(h)和(z)經過矩陣(W^h、W^z)轉換,將轉換結果進行點積,得到(alpha)
- additive attention
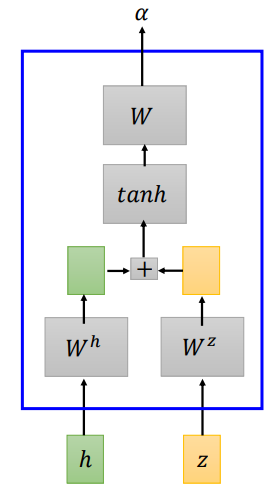
additive attention 將輸入(h)和(z)經過矩陣(W^h、W^z)轉換,將轉換結果相加,經過一個線性變換得到(alpha)
我們來看看LAS的attention具體怎麼做的
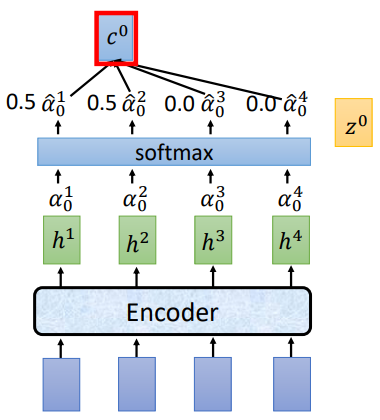
將(z^0)分別和(h^1,h^2,h^3,h^4)做attention運算得到(alpha ^1 _ 0,alpha ^2 _ 0,alpha ^3 _ 0,alpha ^4 _ 0),經過softmax歸一化,再將歸一化後的結果和(h^i)相乘求和得到 (c^0),將 (c^0)作為Decoder部分的輸入
舉個栗子:
講過attention計算和softmax歸一化後,得到的(hat{alpha_0})為[0.5,0.5,0.0,0.0],(c^0 = sumhat{alpha}^i_0h^i=0.5h^1+0.5h^2).
Spell
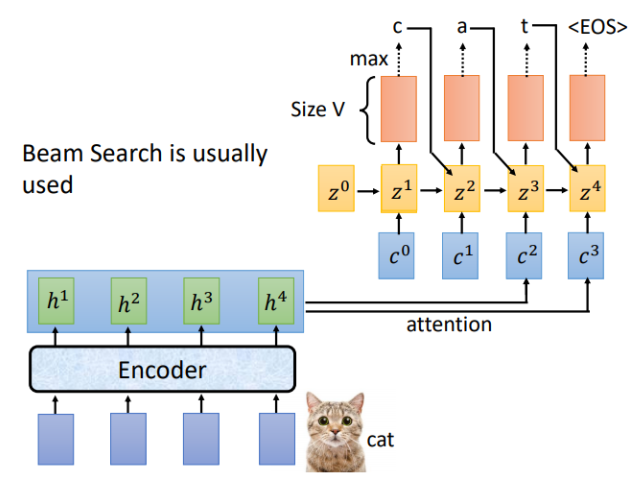
LAS的Listen對應Encoder,Spell對應的就是Decoder,假設Encoder的輸入為「cat",Decoder的每一個時間步對應的輸出就是辭彙表中每個詞的分布,通常會選概率最大的那個作為輸出。

剛才是用(z^0)計算得到(c^0),現在我們用(z^1)進行運算,重複attention過程,就得到了(c^1),對應的結果如下

完整的Spell流程如下,通常輸出結果會用束搜索(beam search),有關beam search 的內容可以自行了解。
Trainging
訓練過程有一個重要的不同就是Teacher Forcing。剛才在Spell部分我們說到,一個時刻的輸入其實有三個部分((c^1,z^0,o^0)),當前位置的attention結果context向量,上一時刻的隱狀態,以及上一時刻的預測輸出。但是在training階段,我們會將(o^0)換成真實的上一時刻的輸出。假如(t_0)預測的輸出為(x),實際應該輸出(c),我們會將(c)作為下一時刻的輸入。這就是Teacher Forcing
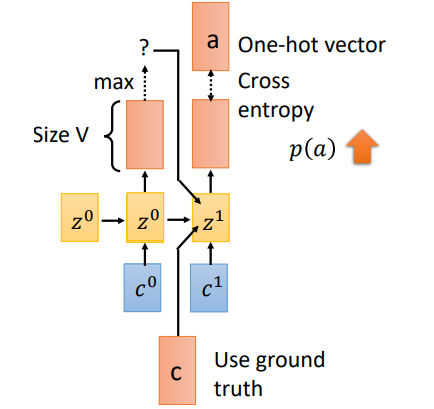
那為什麼需要Teacher forcing呢?我們來看看如果使用上一時刻預測的輸出作為輸入會發生什麼
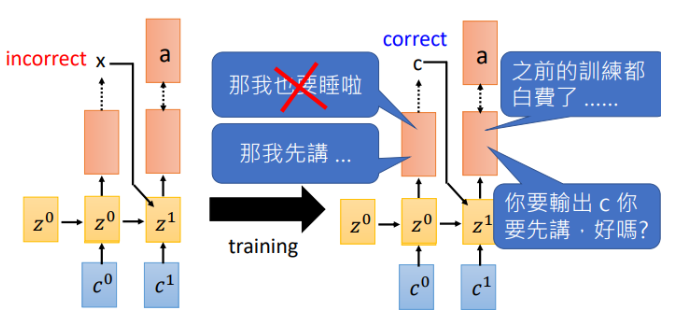
假如在(t_0)輸出了(x),下一時刻機器就會學習在輸入為(x)時我需要輸出(a),然而等到訓練的一定回合時,(t_0)可以做出正確的預測了,告訴機器輸入(c)需要輸出(a),此刻機器已經懵了,剛才不是說(x)對應(a)嗎,那之前的訓練就白費了。就開始互掐了。。。
- back to attention
我們在回到之前的attention操作,attention計算得到的context被用於下一時刻的輸入(左圖),現在還有另一種attention架構,將context直接用於當前時刻的輸入(右圖)
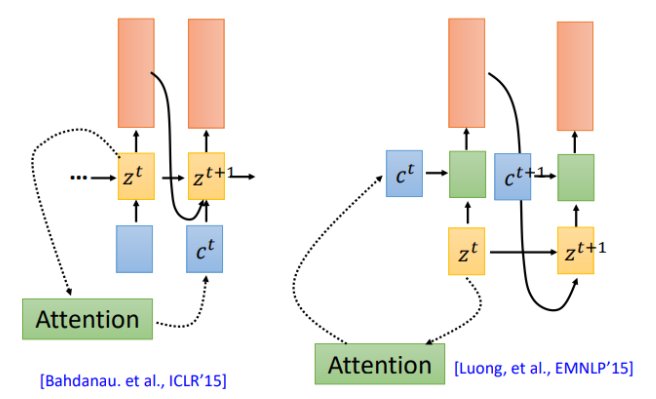
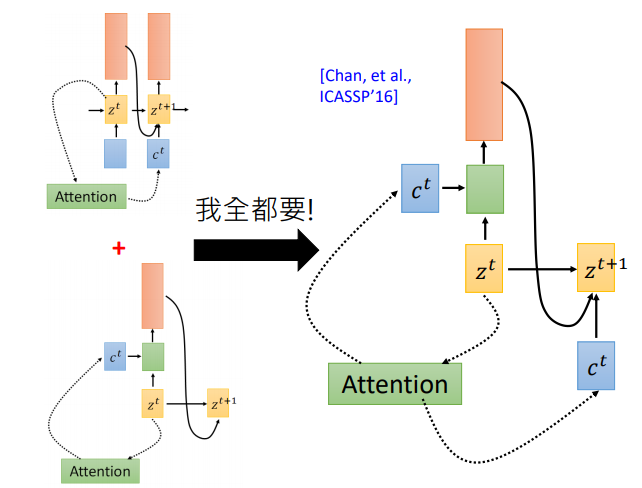
那麼哪一種更有效呢?該用那個呢。第一篇使用seq2seq做語音識別的論文說:我全都要。context向量即作用於當前位置,也作用於下一位置
使用Attention作語音識別真的好嗎?
有點殺雞用牛刀的感覺!為好么呢,我們知道用attention的seq2seq模型首先用在機器翻譯上,在翻譯任務中,輸入和輸出沒有一致的對應關係,需要attention自己尋找對應的那個詞。但是對語音來說輸入輸出是對應的,有人提出了location-aware attention
LAS —Does it work?
剛開始的時候LAS其實打不過傳統模型,後來隨著訓練集的增加以及各種trick,LAS已經很厲害了。可以看到剛開始的時候,打不過傳統模型,2018年google在12500小時的訓練集上訓練,最終打敗了傳統模型,並沒有使用location-aware attention,而且最重要的是模型變小了,從原來的7.2G變成0.4G

那LAS還有什麼問題呢?
LAS採用經典的Encoder和Decoder架構,也就是說,只有在完整的聽完一句話之後模型才會輸出,那如果我們希望機器在聽到聲音的同時就輸出怎麼做呢?我們下節課再講。

