每天都在用 Map,這些核心技術你知道嗎?
- 2020 年 3 月 18 日
- 筆記
本篇文章站在多執行緒並發安全形度,帶你了解多執行緒並發使用 HashMap 將會引發的問題,深入學習 ConcurrentHashMap ,帶你徹底掌握這些核心技術。
全文摘要:
HashMap核心技術ConcurrentHashMap核心技術- 分段鎖實戰應用
博文地址:https://sourl.cn/r3RVY8
HashMap
HashMap 是我們經常會用到的集合類,JDK 1.7 之前底層使用了數組加鏈表的組合結構,如下圖所示:
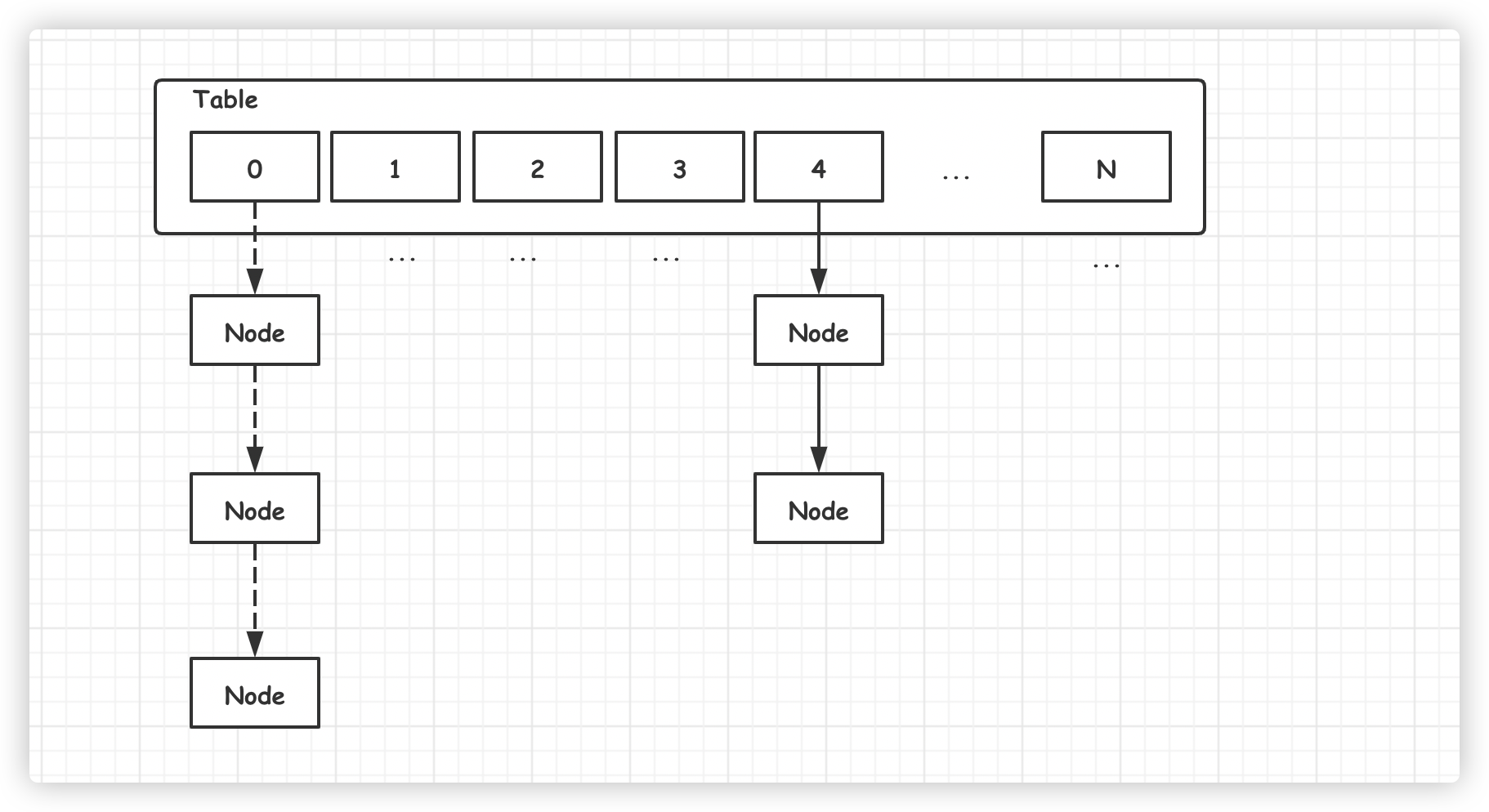
新添加的元素通過取模的方式,定位 Table 數組位置,然後將元素加入鏈表頭部,這樣下次提取時就可以快速被訪問到。
訪問數據時,也是通過取模的方式,定位數組中的位置,然後再遍歷鏈表,依次比較,獲取相應的元素。
如果 HasMap 中元素過多時,可能導致某個位置上鏈表很長。原本 O(1) 查找性能,可能就退化成 O(N),嚴重降低查找效率。
為了避免這種情況,當 HasMap 元素數量滿足以下條件時,將會自動擴容,重新分配元素。
// size:HashMap 中實際元素數量 //capacity:HashMap 容量,即 Table 數組長度,默認為:16 //loadFactor:負載因子,默認為:0.75 size>=capacity*loadFactorHasMap 將會把容量擴充為原來的兩倍,然後將原數組元素遷移至新數組。
void transfer(Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; for (Entry<K,V> e : table) { while(null != e) { Entry<K,V> next = e.next; if (rehash) { e.hash = null == e.key ? 0 : hash(e.key); } int i = indexFor(e.hash, newCapacity); // 以下程式碼導致死鏈的產生 e.next = newTable[i]; // 插入到鏈表頭結點, newTable[i] = e; e = next; } } }舊數組元素遷移到新數組時,依舊採用『頭插入法』,這樣將會導致新鏈表元素的逆序排序。
多執行緒並發擴容的情況下,鏈表可能形成死鏈(環形鏈表)。一旦有任何查找元素的動作,執行緒將會陷入死循環,從而引發 CPU 使用率飆升。
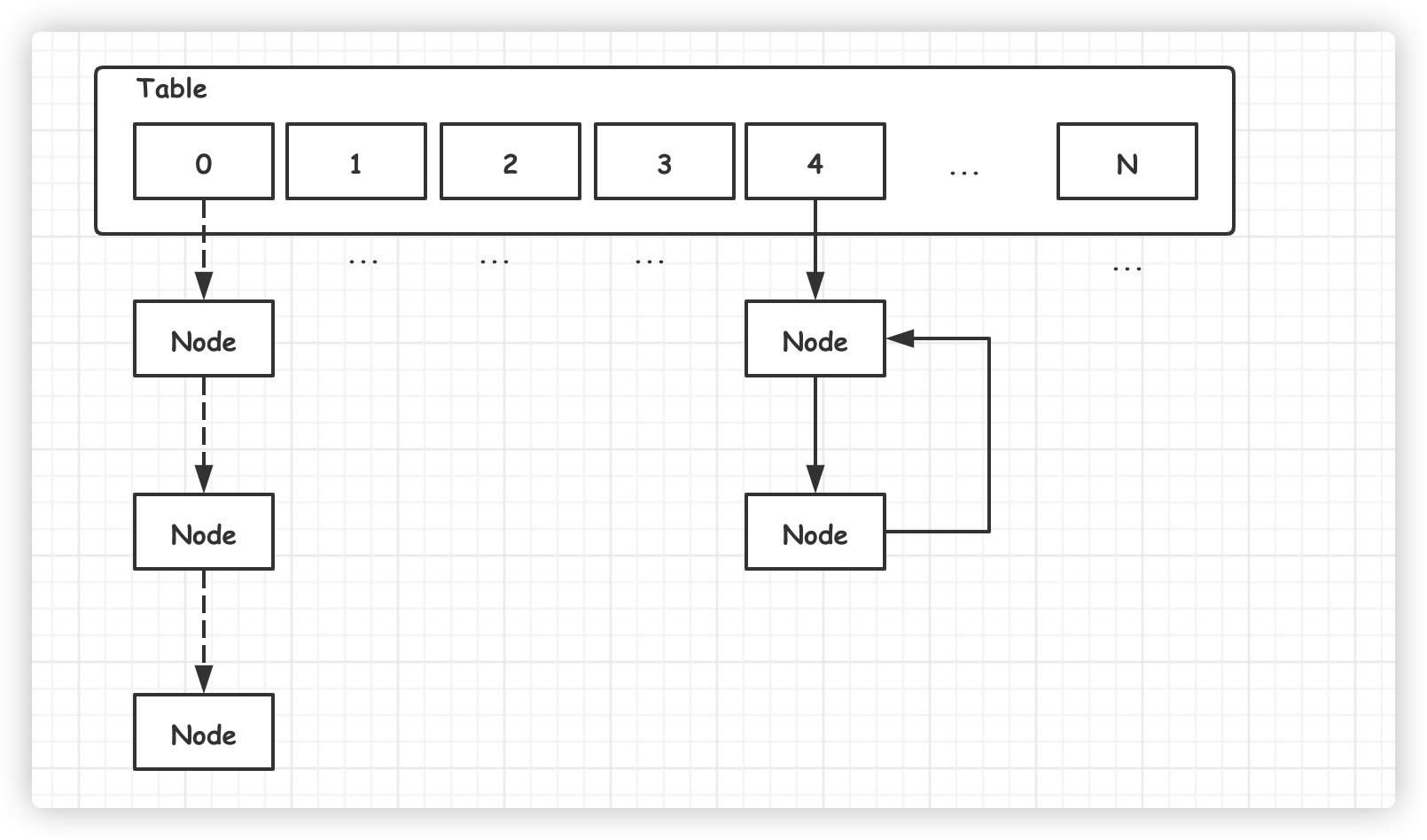
網上詳細分析死鏈形成的過程比較多,這裡就不再詳細解釋,大家感興趣可以閱讀以下@陳皓的文章。
文章地址:https://coolshell.cn/articles/9606.html
JDK1.8 改進方案
JDK1.8 HashMap 底層結構進行徹底重構,使用數組加鏈表/紅黑樹方式這種組合結構。
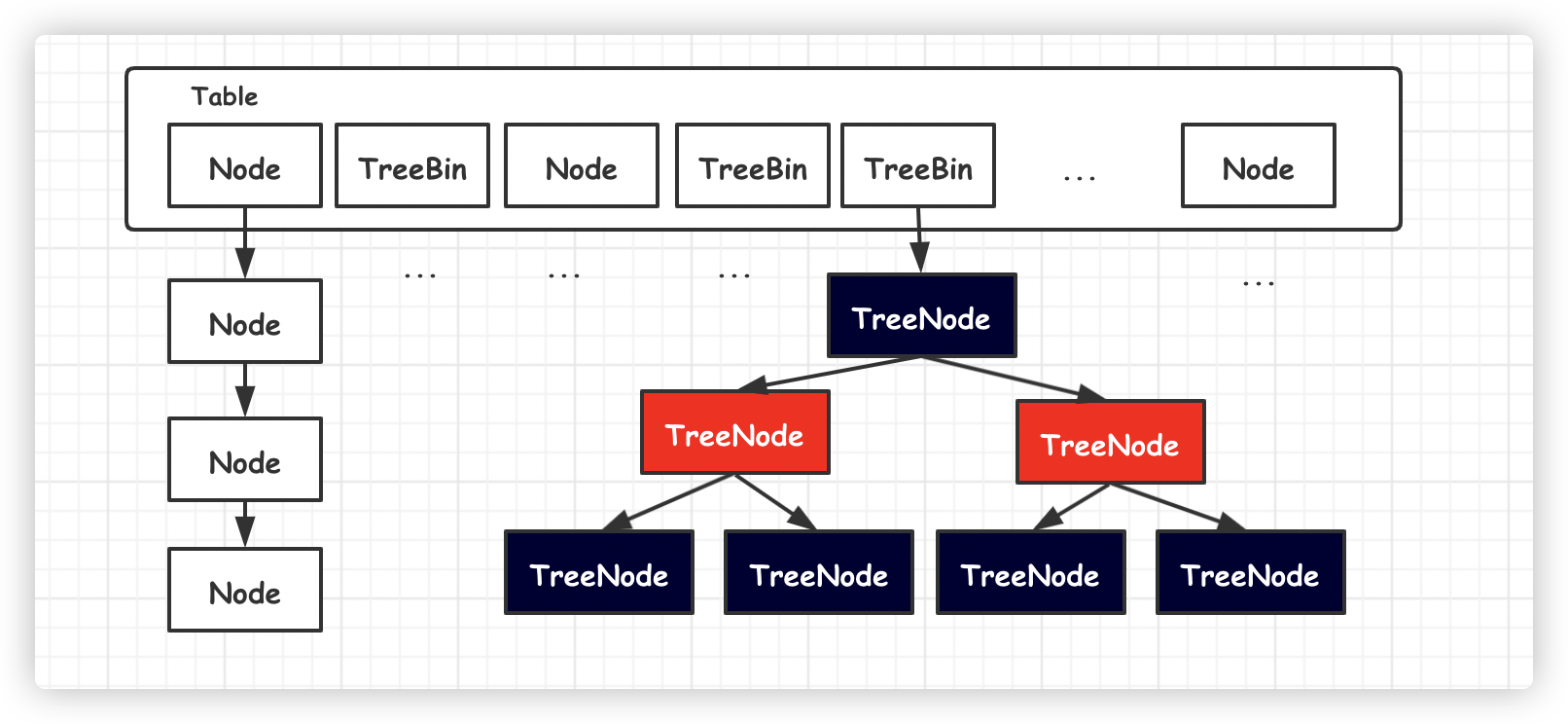
新元素依舊通過取模方式獲取 Table 數組位置,然後再將元素加入鏈表尾部。一旦鏈表元素數量超過 8 之後,自動轉為紅黑樹,進一步提高了查找效率。
面試題:為什麼這裡使用紅黑樹?而不是其他二叉樹呢?
由於 JDK1.8 鏈表採用『尾插入』法,從而避免並發擴容情況下鏈表形成死鏈的可能。
那麼 HashMap 在 JDK1.8 版本就是並發安全的嗎?
其實並沒有,多執行緒並發的情況,HashMap 可能導致丟失數據。
下面是一段 JDK1.8 測試程式碼:
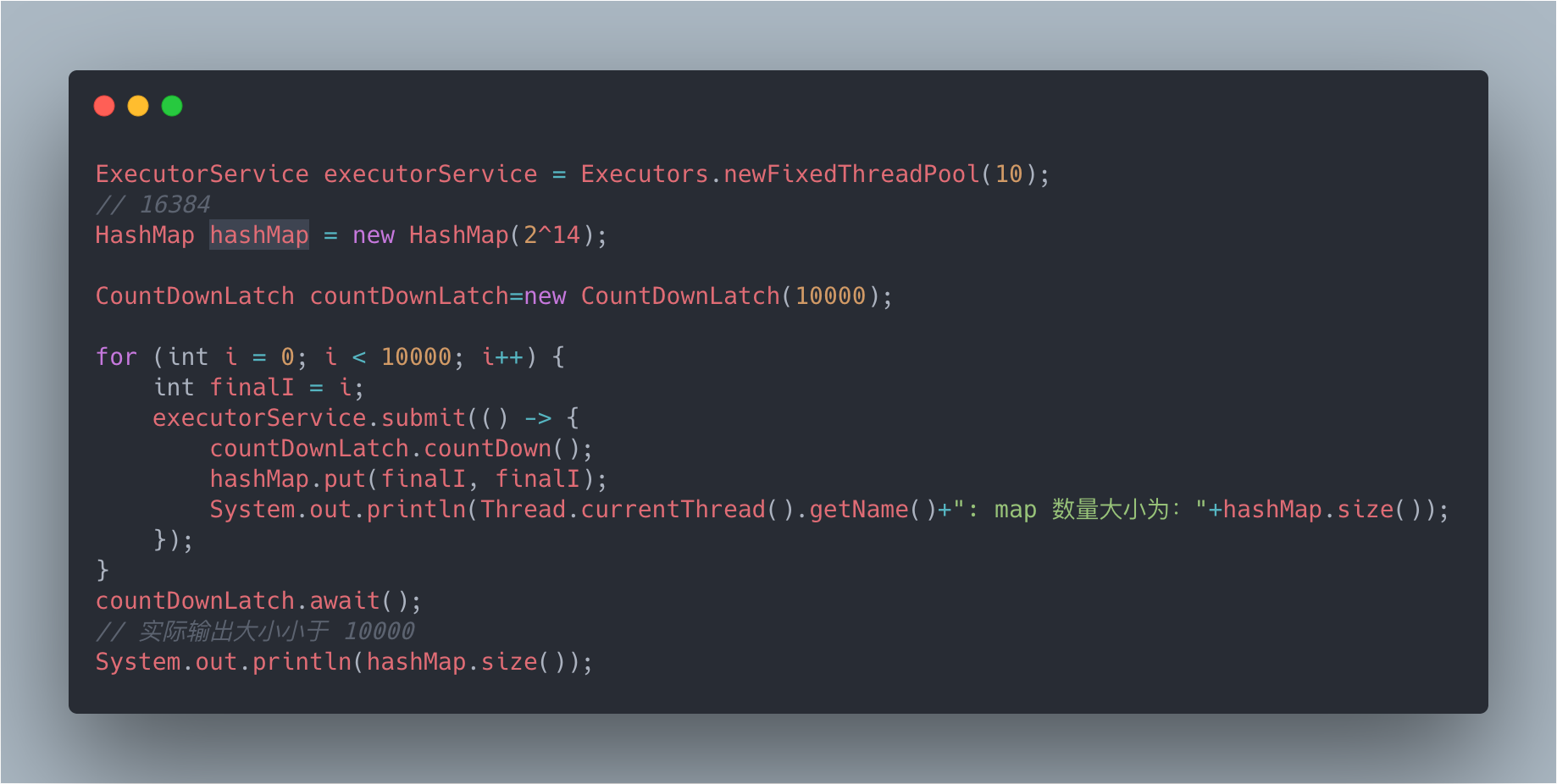
在我的電腦上輸出如下,數據發生了丟失:
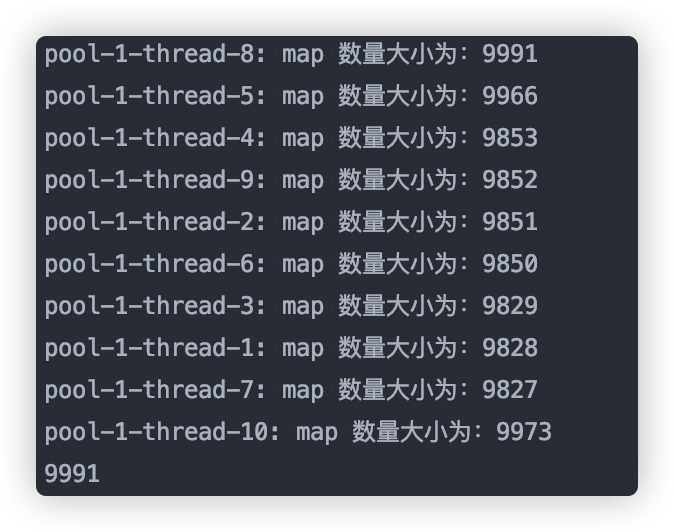
從源碼出發,並發過程數據丟失的原因有以下幾點:
並發賦值時被覆蓋
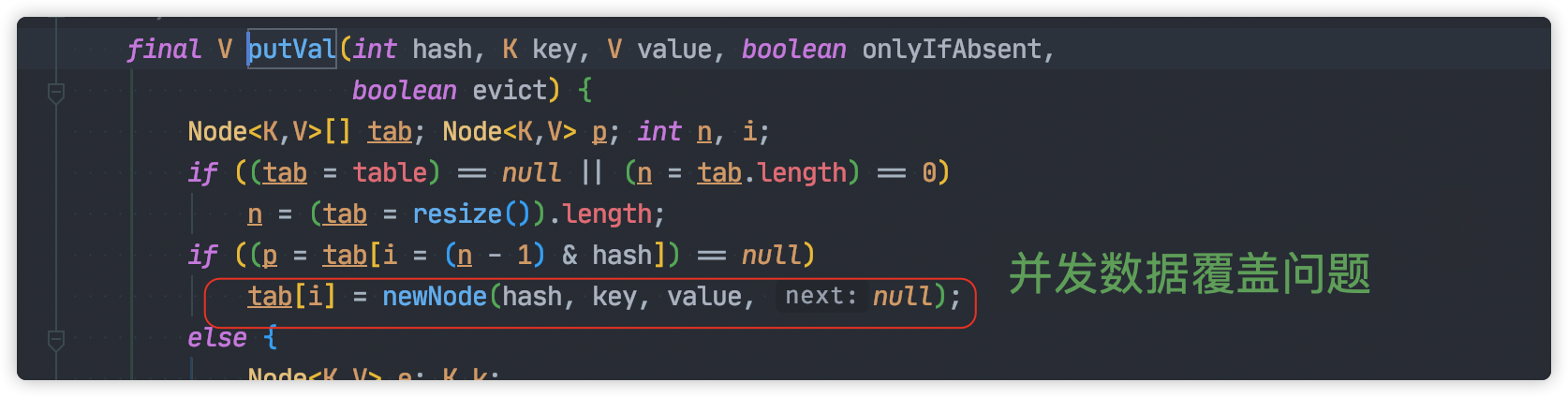
並發的情況下,一個執行緒的賦值可能被另一個執行緒覆蓋,這就導致對象的丟失。
size 計算問題

每次元素增加完成之後,size 將會加 1。這裡採用 ++i方法,天然的並發不安全。
對象丟失的問題原因可能還有很多,這裡只是列舉兩個比較的明顯的問題。
當然 JDK1.7 中也是存在數據丟失的問題,問題原因也比較相似。
一旦發生死鏈的問題,機器 CPU 飆升,通過系統監控,我們可以很容易發現。
但是數據丟失的問題就不容易被發現。因為數據丟失環節往往非常長,往往需要系統運行一段時間才可能出現,而且這種情況下又不會形成臟數據。只有出現一些詭異的情況,我們才可能去排查,而且這種問題排查起來也比較困難。
SynchronizedMap
對於並發的情況,我們可以使用 JDK 提供 SynchronizedMap 保證安全。
SynchronizedMap 是一個內部類,只能通過以下方式創建實例。
Map m = Collections.synchronizedMap(new HashMap(...));SynchronizedMap 源碼如下:
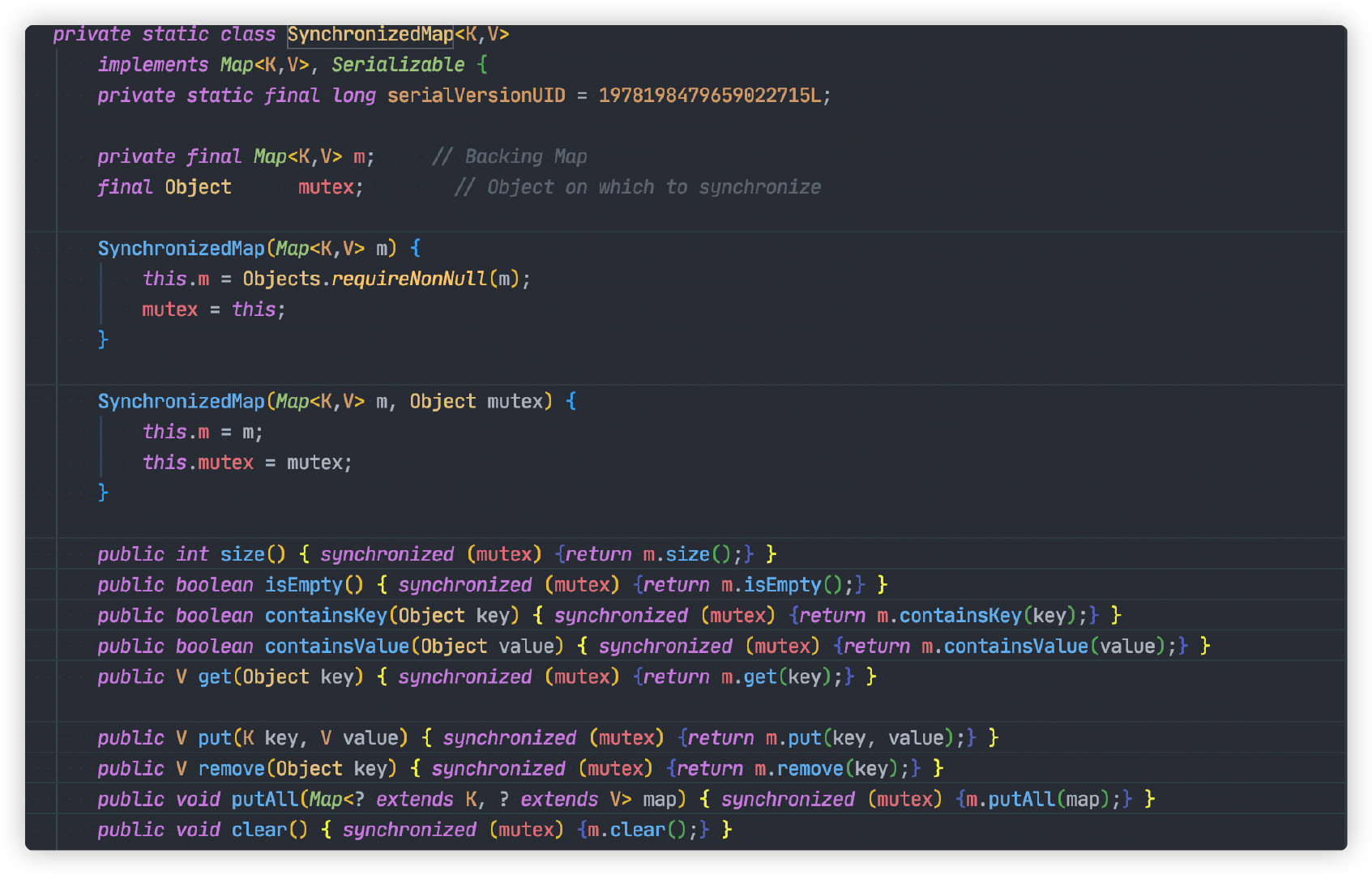
每個方法內將會使用 synchronized 關鍵字加鎖,從而保證並發安全。
由於多執行緒共享同一把鎖,導致同一時間只允許一個執行緒讀寫操作,其他執行緒必須等待,極大降低的性能。
並且大多數業務場景都是讀多寫少,多執行緒讀操作本身並不衝突,SynchronizedMap 極大的限制讀的性能。
所以多執行緒並發場景我們很少使用 SynchronizedMap 。
ConcurrentHashMap
既然多執行緒共享一把鎖,導致性能下降。那麼設想一下我們是不是多搞幾把鎖,分流執行緒,減少鎖衝突,提高並發度。
ConcurrentHashMap 正是使用這種方法,不但保證並發過程數據安全,又保證一定的效率。
JDK1.7
JDK1.7 ConcurrentHashMap 數據結構如下所示:
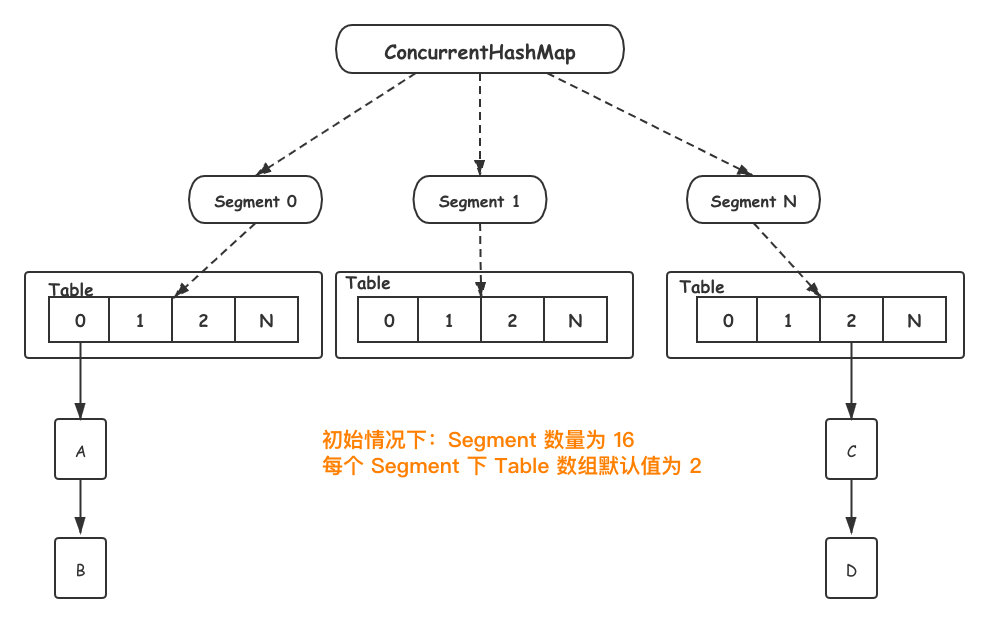
Segament 是一個ConcurrentHashMap內部類,底層結構與 HashMap 一致。另外Segament 繼承自 ReentrantLock,類圖如下:
當新元素加入 ConcurrentHashMap 時,首先根據 key hash 值找到相應的 Segament。接著直接對 Segament 上鎖,若獲取成功,後續操作步驟如同 HashMap。
由於鎖的存在,Segament 內部操作都是並發安全,同時由於其他 Segament 未被佔用,因此可以支援 concurrencyLevel 個執行緒安全的並發讀寫。
size 統計問題
雖然 ConcurrentHashMap 引入分段鎖解決多執行緒並發的問題,但是同時引入新的複雜度,導致計算 ConcurrentHashMap 元素數量將會變得複雜。
由於 ConcurrentHashMap 元素實際分布在 Segament 中,為了統計實際數量,只能遍歷 Segament數組求和。
為了數據的準確性,這個過程過我們需要鎖住所有的 Segament,計算結束之後,再依次解鎖。不過這樣做,將會導致寫操作被阻塞,一定程度降低 ConcurrentHashMap性能。
所以這裡對 ConcurrentHashMap#size 統計方法進行一定的優化。
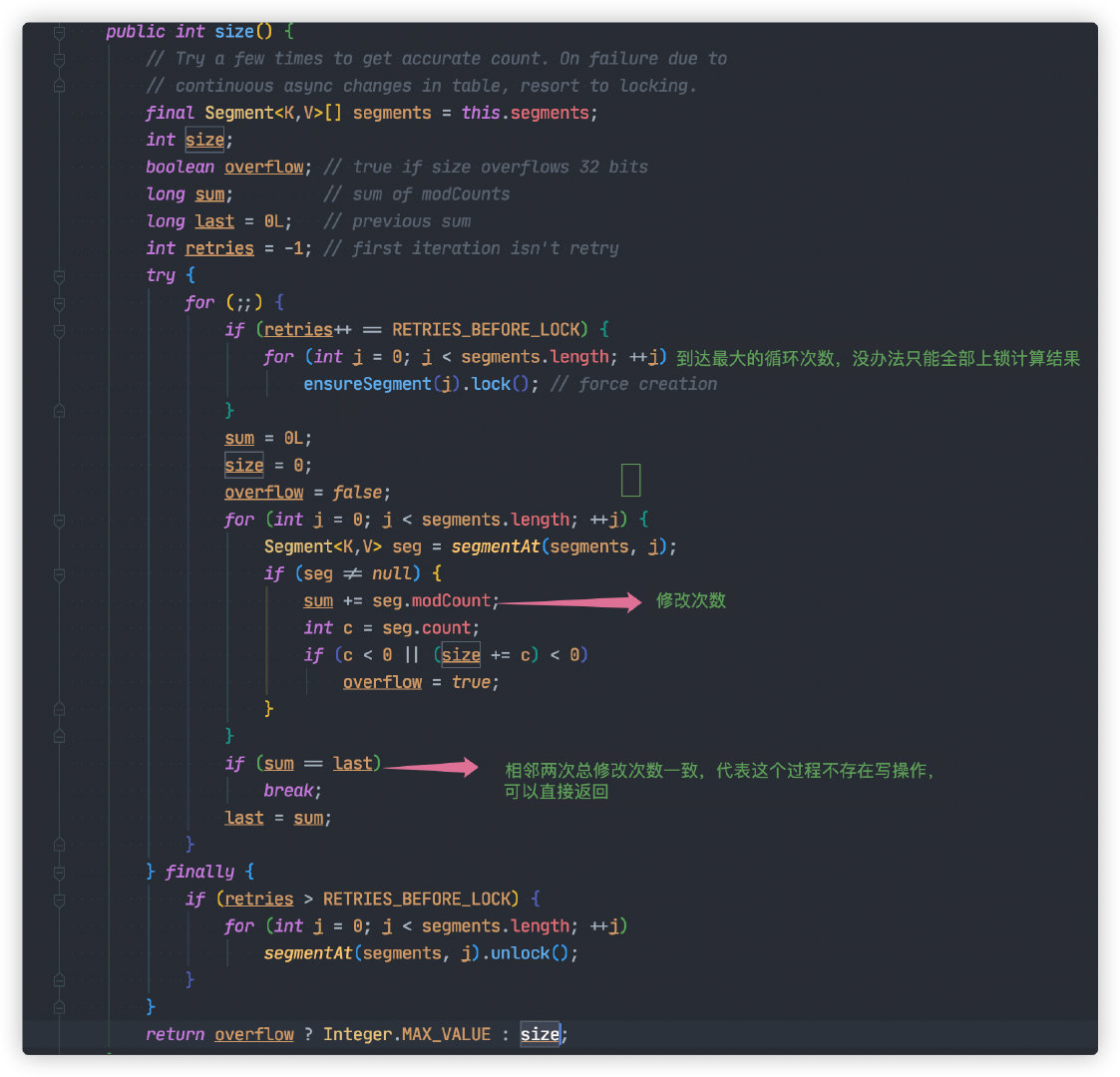
Segment 每次被修改(寫入,刪除),都會對 modCount(更新次數)加 1。只要相鄰兩次計算獲取所有的 Segment modCount 總和一致,則代表兩次計算過程並無寫入或刪除,可以直接返回統計數量。
如果三次計算結果都不一致,那沒辦法只能對所有 Segment 加鎖,重新計算結果。
這裡需要注意的是,這裡求得 size 數量不能做到 100% 準確。這是因為最後依次對 Segment 解鎖後,可能會有其他執行緒進入寫入操作。這樣就導致返回時的數量與實際數不一致。
不過這也能被接受,總不能因為為了統計元素停止所有元素的寫入操作。
性能問題
想像一種極端情況的,所有寫入都落在同一個 Segment中,這就導致ConcurrentHashMap 退化成 SynchronizedMap,共同搶一把鎖。

JDK1.8 改進方案
JDK1.8 之後,ConcurrentHashMap 取消了分段鎖的設計,進一步減鎖衝突的發生。另外也引入紅黑樹的結構,進一步提高查找效率。
數據結構如下所示:
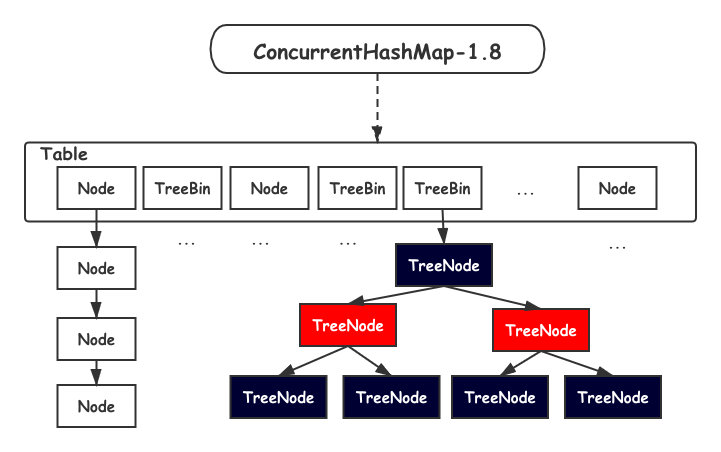
Table 數組的中每一個 Node 我們都可以看做一把鎖,這就避免了 Segament 退化問題。
另外一旦 ConcurrentHashMap 擴容, Table 數組元素變多,鎖的數量也會變多,並發度也會提高。
寫入元素源碼比較複雜,這裡可以參考下面流程圖。
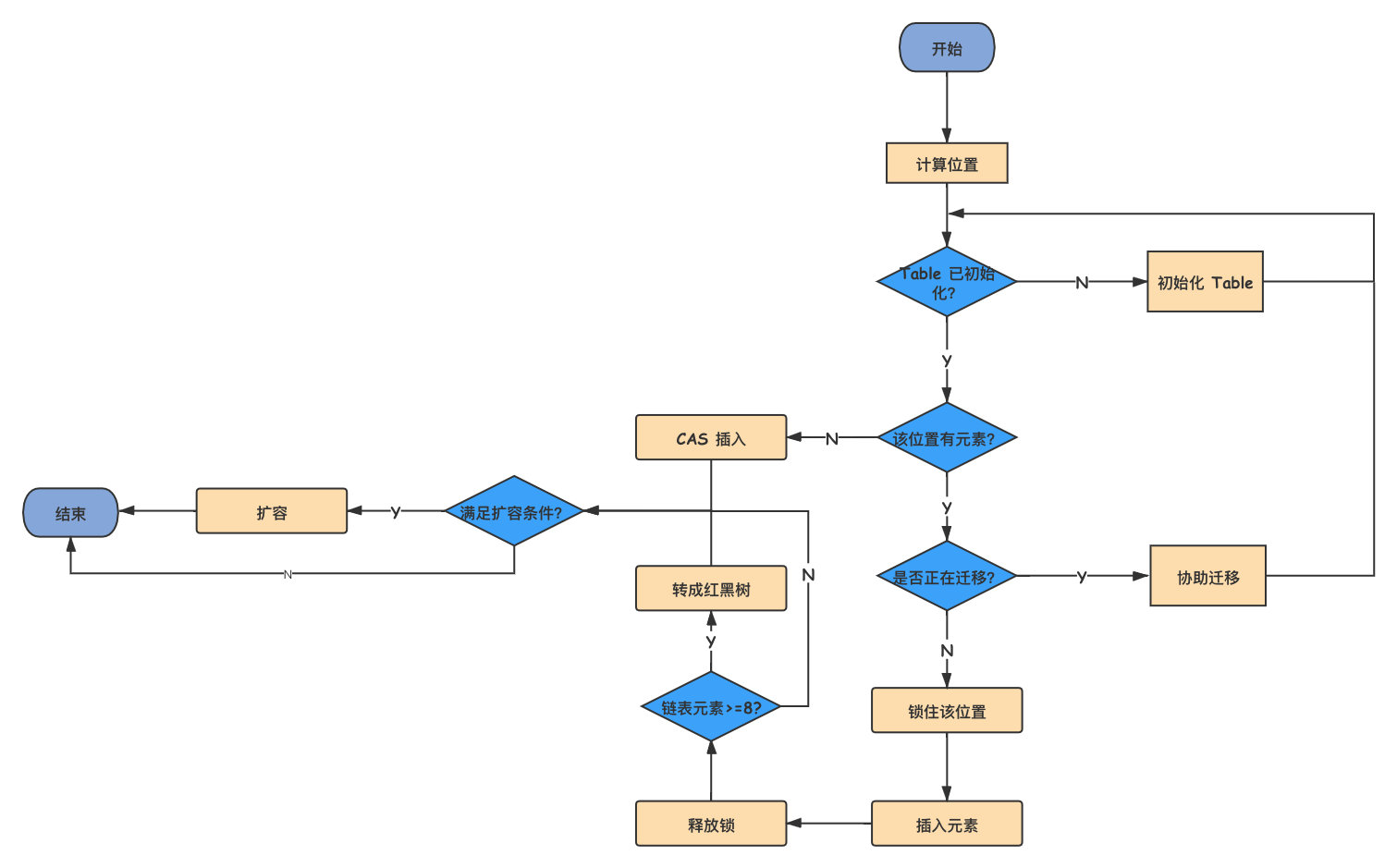
總的來說,JDK1.8 使用 CAS 方法加 synchronized 方式,保證並發安全。
size 方法優化
JDK1.8 ConcurrentHashMap#size 統計方法還是比較簡單的:
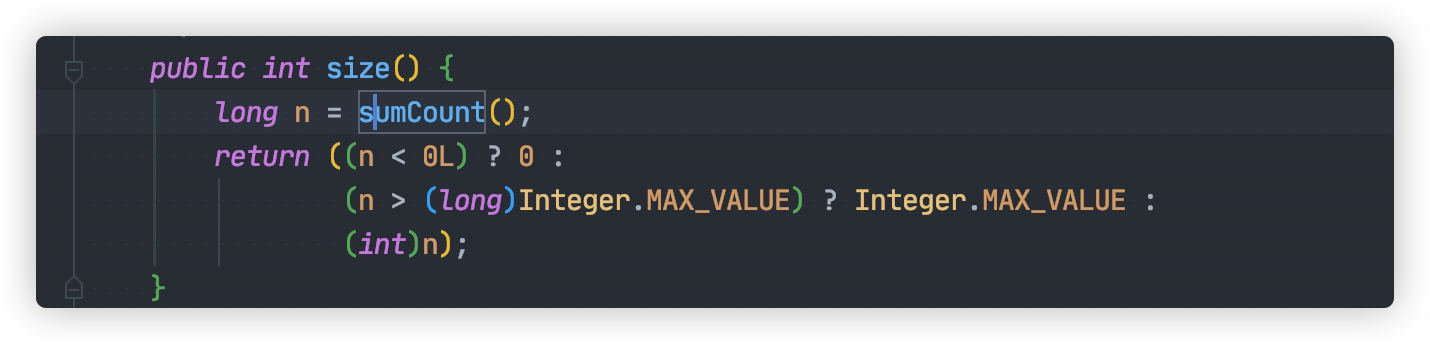
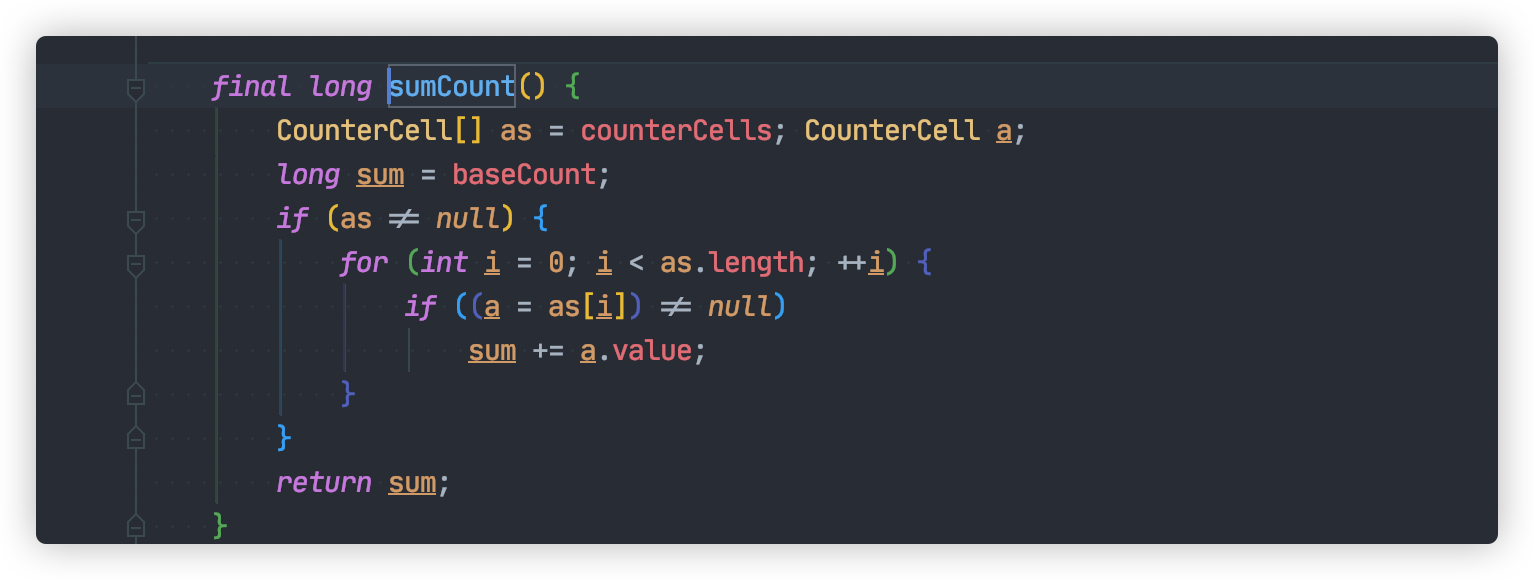
這個方法我們需要知道兩個重要變數:
baseCountCounterCell[] counterCells
baseCount 記錄元素數量的,每次元素元素變更之後,將會使用 CAS方式更新該值。
如果多個執行緒並發增加新元素,baseCount 更新衝突,將會啟用 CounterCell,通過使用 CAS 方式將總數更新到 counterCells 數組對應的位置,減少競爭。
如果 CAS 更新 counterCells 數組某個位置出現多次失敗,這表明多個執行緒在使用這個位置。此時將會通過擴容 counterCells方式,再次減少衝突。
通過上面的努力,統計元素總數就變得非常簡單,只要計算 baseCount 與 counterCells總和,整個過程都不需要加鎖。
仔細回味一下,counterCells 也是通過類似分段鎖思想,減少多執行緒競爭。
分段鎖實戰應用
ConcurrentHashMap 通過使用分段鎖的設計方式,降低鎖的粒度,提高並發度。我們可以借鑒這種設計,解決某些熱點數據更新問題。
舉個例子,假如現在我們有一個支付系統,用戶每次支付成功,商家的賬戶餘額就會相應的增加。
當大促的時候,非常多用戶同時支付,同一個商家賬戶餘額會被並發更新。
資料庫層面為了保證數據安全,每次更新時將會使用行鎖。同時並發更新的情況,只有一個執行緒才能獲取鎖,更新數據,其他執行緒只能等待鎖釋放。這就很有可能導致其他執行緒餘額更新操作耗時過長,甚至事務超時,餘額更新失敗的。
這就是一個典型的熱點數據更新問題。
這個問題實際原因是因為多執行緒並發搶奪行鎖導致,那如果有多把行鎖,是不是就可以降低鎖衝突了那?
沒錯,這裡我們借鑒 ConcurrentHashMap 分段鎖的設計,在商家的賬戶的下創建多個影子賬戶。
然後每次更新餘額,隨機選擇某個影子賬戶進行相應的更新。
理論上影子賬戶可以創建無數個,這就代表我們可以無限提高並發的能力。
這裡感謝@why 神提出影子賬戶的概念,大家感興趣可以搜索關注,公眾號: why技術

架構設計中引入新的方案,就代表會引入新的複雜度,我們一定要這些問題考慮清楚,綜合權衡設計。
引入影子賬戶雖然解決熱點數據的問題,但是商戶總餘額統計就變得很麻煩,我們必須統計所有子賬戶的餘額。
另外實際的業務場景,商家餘額不只是會增加,還有可能的進行相應的扣減。這就有可能產生商戶總餘額是足夠的,但是選中的影子賬戶的餘額卻不足。
這怎麼辦?這留給大家思考了。不知道各位讀者有沒有碰到這種類似的問題,歡迎留言討論。
大家感興趣的話,後面的文章我們可以詳細聊聊熱點賬戶的解決方案。
總結
HashMap 在多執行緒並發的過程中存在死鏈與丟失數據的可能,不適合用於多執行緒並發使用的場景的,我們可以在方法的局部變數中使用。
SynchronizedMap 雖然執行緒安全,但是由於鎖粒度太大,導致性能太低,所以也不太適合在多執行緒使用。
ConcurrentHashMap 由於使用多把鎖,充分降低多執行緒並發競爭的概率,提高了並發度,非常適合在多執行緒中使用。
最後小黑哥再提一點,不要一提到多執行緒環境,就直接使用 ConcurrentHashMap。如果僅僅使用 Map 當做全局變數,而這個變數初始載入之後,從此數據不再變動的場景下。建議使用不變集合類 Collections#unmodifiableMap,或者使用 Guava 的 ImmutableMap。不變集合的好處在於,可以有效防止其他執行緒偷偷修改,從而引發一些業務問題。
ConcurrentHashMap 分段鎖的經典思想,我們可以應用在熱點更新的場景,提高更新效率。
不過一定要記得,當我們引入新方案解決問題時,必定會引入新的複雜度,導致其他問題。這個過程一定要先將這些問題想清楚,然後這中間做一定權衡。
參考資料
- 碼出高效 Java 開發手冊
- http://www.jasongj.com/java/concurrenthashmap/
最後說一句(求關注)
看到這裡,點個關注呀,點個讚唄。別下次一定啊,大哥。寫文章很辛苦的,需要來點正回饋。
才疏學淺,難免會有紕漏,如果你發現了錯誤的地方,還請你留言給我指出來,我對其加以修改。
感謝您的閱讀,我堅持原創,十分歡迎並感謝您的關注

歡迎關注我的公眾號:程式通事,獲得日常乾貨推送。如果您對我的專題內容感興趣,也可以關注我的部落格:studyidea.cn


