數據挖掘入門系列教程(四點五)之Apriori演算法
- 2020 年 3 月 17 日
- 筆記
數據挖掘入門系列教程(四點五)之Apriori演算法
Apriori(先驗)演算法關聯規則學習的經典演算法之一,用來尋找出數據集中頻繁出現的數據集合。如果看過以前的部落格,是不是想到了這個跟數據挖掘入門系列教程(一)之親和性分析這篇部落格很相似?Yes,的確很相似,只不過在這篇部落格中,我們會更加深入的分析如何尋找可靠有效的親和性。並在下一篇部落格中使用Apriori演算法去分析電影中的親和性。這篇主要是介紹Apriori演算法的流程。
頻繁(項集)數據的評判標準
這個在數據挖掘入門系列教程(一)之親和性分析這篇部落格曾經提過,但在這裡再重新詳細的說一下。
何如判斷一個數據是否是頻繁?按照我們的想法,肯定是數據在數據集中出現次數的越多,則代表著這個數據出現的越頻繁。
值得注意的是:在這裡的數據可以是一個數據,也可以是多個數據 (項集)。
以下面這張圖為例子,這張圖每一列代表商品是否被購買(1代表被購買,0代表否),每一行代表一次交易記錄:
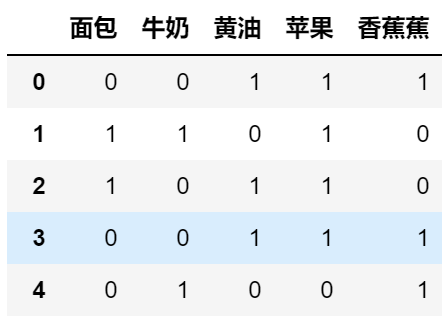
常用的評估標準由支援度、置信度、和提升度三個:
支援度(support):
支援度就是數據在數據集中出現的次數(也可以是次數佔總數據集的比重),或者說其在數據集中出現的概率:
下面的公式以所佔比例來說明:
[ begin{split} & 如果是一個數據X,則其支援度為:\ & support(X) = P(X) = frac{num(X)}{num(ALL)} \ & 如果數據是一個數據項集(X,Y),則支援度為:\ & support(X,Y) = P(X,Y) = frac{num(XY)}{num(ALL)}\ & 如果數據是一個數據項集(X,Y,Z),則支援度為:\ & support(X,Y,Z) = P(X,Y,Z) = frac{num(XYZ)}{num(ALL)}\ & (X,Y,Z代表的是X,Y,Z同時出現的次數) end{split} ]
以上面的交易為例:
我們來求 (黃油,蘋果) 的支援度:
(黃油,蘋果) 在第0,2,3中通過出現了,一共是5條數據,因此(support(黃油,蘋果) = frac{3}{5} = 0.6)
一般來說,支援度高的不一定數據頻繁,但是數據頻繁的一定支援度高
置信度(confidence):
置信度代表的規則應驗的準確性,也就是一個數據出現後,另外一個數據出現的概率,也就是條件概率。(以購買為例,就是已經購買Y的條件下,購買X的概率)公式如下:
[ begin{split} & 設分析的數據是X,Y,則X對Y的置信度為:\ & confidence(X Leftarrow Y) = P(X|Y) = frac{P(XY)}{P(Y)} \ & 設分析的數據是X,Y,Z,則X對Y和Z的置信度為:\ & confidence(X Leftarrow YZ) = P(X|YZ) = frac{P(XYZ)}{P(YZ)} \ end{split} ]
還是以 (黃油,蘋果) 為例子,計算黃油對蘋果的置信度:(confidence(黃油Leftarrow蘋果) = frac{3}{4} = 0.75)。
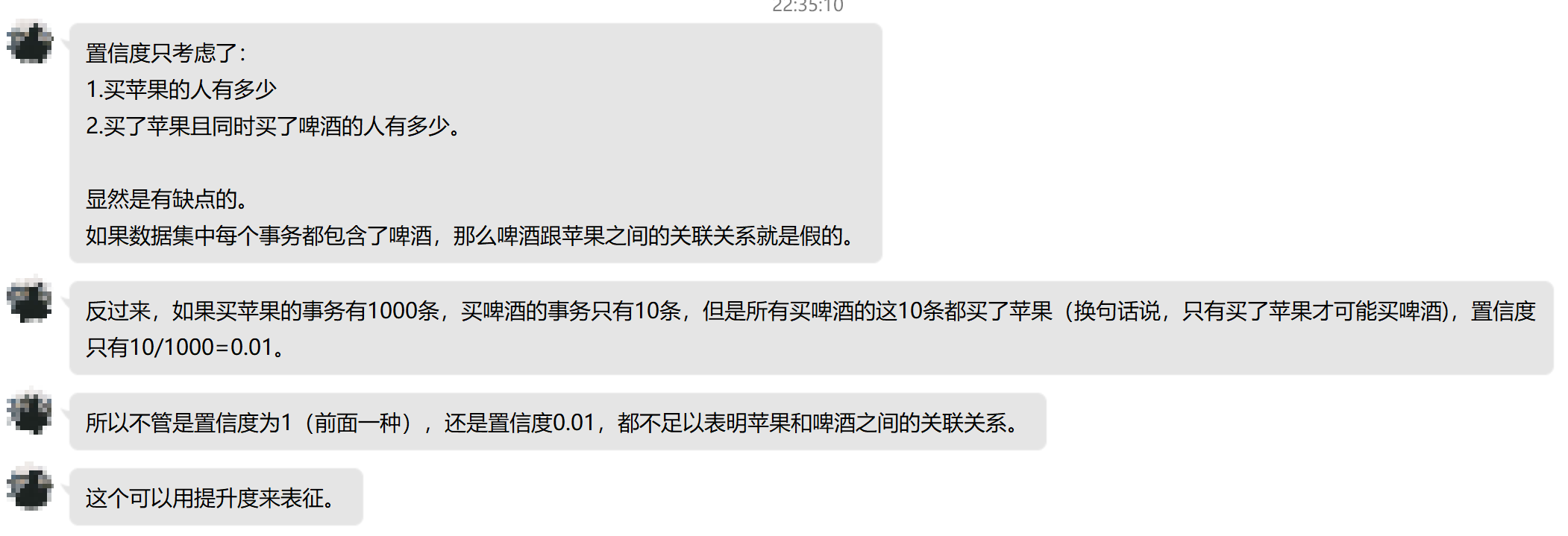
但是置信度有一個缺點,那就是它可能會扭曲關聯的重要性。因為它只反應了Y的受歡迎的程度。如果X的受歡迎程度也很高的話,那麼confidence也會很大。下面是數據挖掘蔣少華老師的一段為什麼我們需要使用提升度的話:
提升度(Lift):
提升度表示在含有Y的條件下,同時含有X的概率,同時考慮到X的概率,公式如下:
[ begin{equation} begin{aligned} Lift(X Leftarrow Y) &= frac{support(X,Y)}{support(X) times support(Y)} &= frac{P(X,Y)}{P(X) times P(Y)}\ & = frac{P(X|Y)}{P(X)}\ & = frac{confidenc(XLeftarrow Y)}{P(X)} end{aligned} end{equation} ]
在提升度中,如果(Lift(X Leftarrow Y) = 1)則表示X,Y之間相互獨立,沒有關聯(因為(P(X|Y) = P(X))),如果(Lift(X Leftarrow Y) > 1)則表示(X Leftarrow Y)則表示(X Leftarrow Y)是有效的強關聯(在購買Y的情況下很可能購買X);如果(Lift(X Leftarrow Y) < 1)則表示(X Leftarrow Y)則表示(X Leftarrow Y)是無效的強關聯。
一般來說,我們如何判斷一個數據集中數據的頻繁程度時使用提升度來做的。
Apriori 演算法流程
說完評判標準,接下來我們說一下演算法的流程(來自參考1)。
Apriori演算法的目標是找到最大的K項頻繁集。這裡有兩層意思,首先,我們要找到符合支援度標準(置信度or提升度)的頻繁集。但是這樣的頻繁集可能有很多。第二層意思就是我們要找到最大個數的頻繁集。比如我們找到符合支援度的頻繁集AB和ABE,那麼我們會拋棄AB,只保留ABE,因為AB是2項頻繁集,而ABE是3項頻繁集。
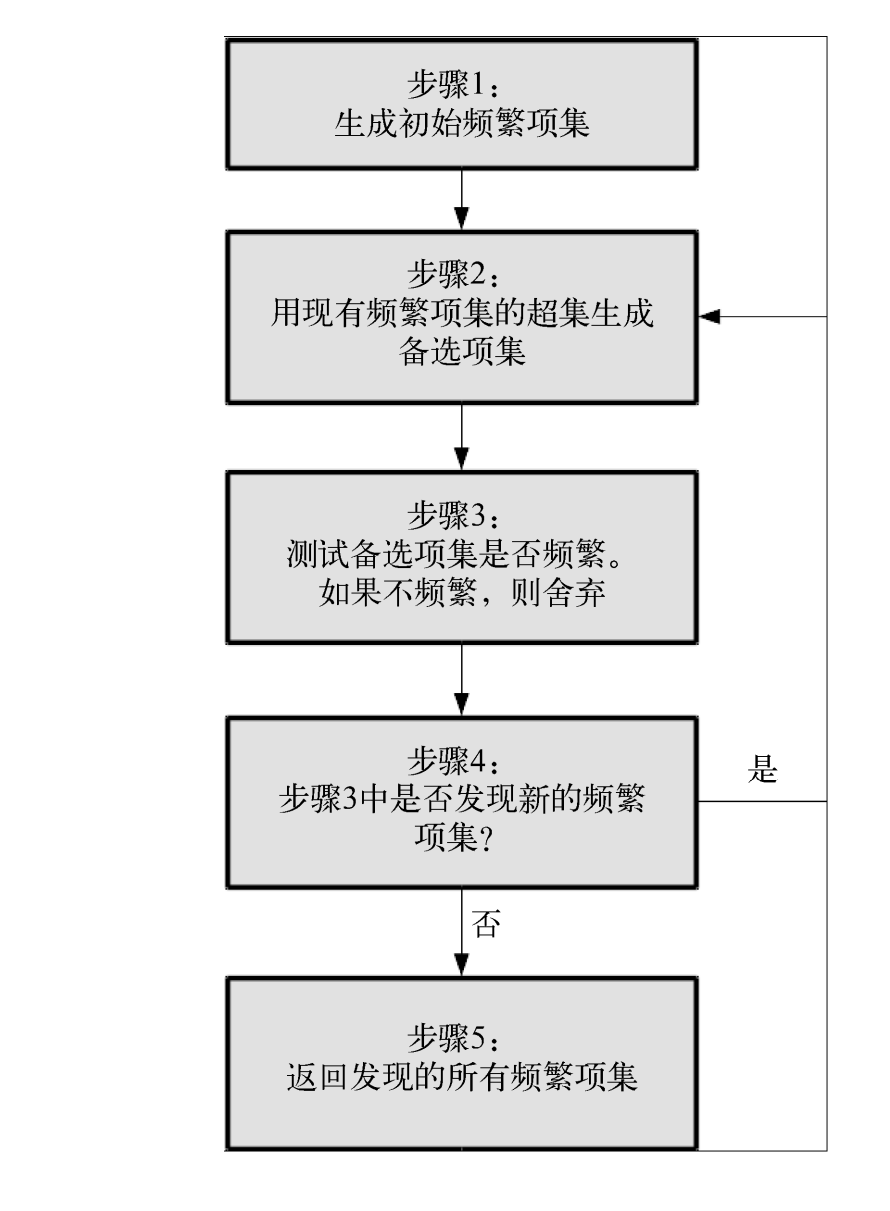
演算法的流程圖如下(圖來自《Python數據挖掘入門與實踐》):
下面是一個具體的例子來介紹(圖源不知道來自哪裡,很多部落格都在用),這個例子是以support作為評判標準,在圖中(C_n)代表的是備選項集,L代表的是被剪掉後的選項集,(Min support = 50%)代表的是最小符合標準的支援度(大於它則表示頻繁)。
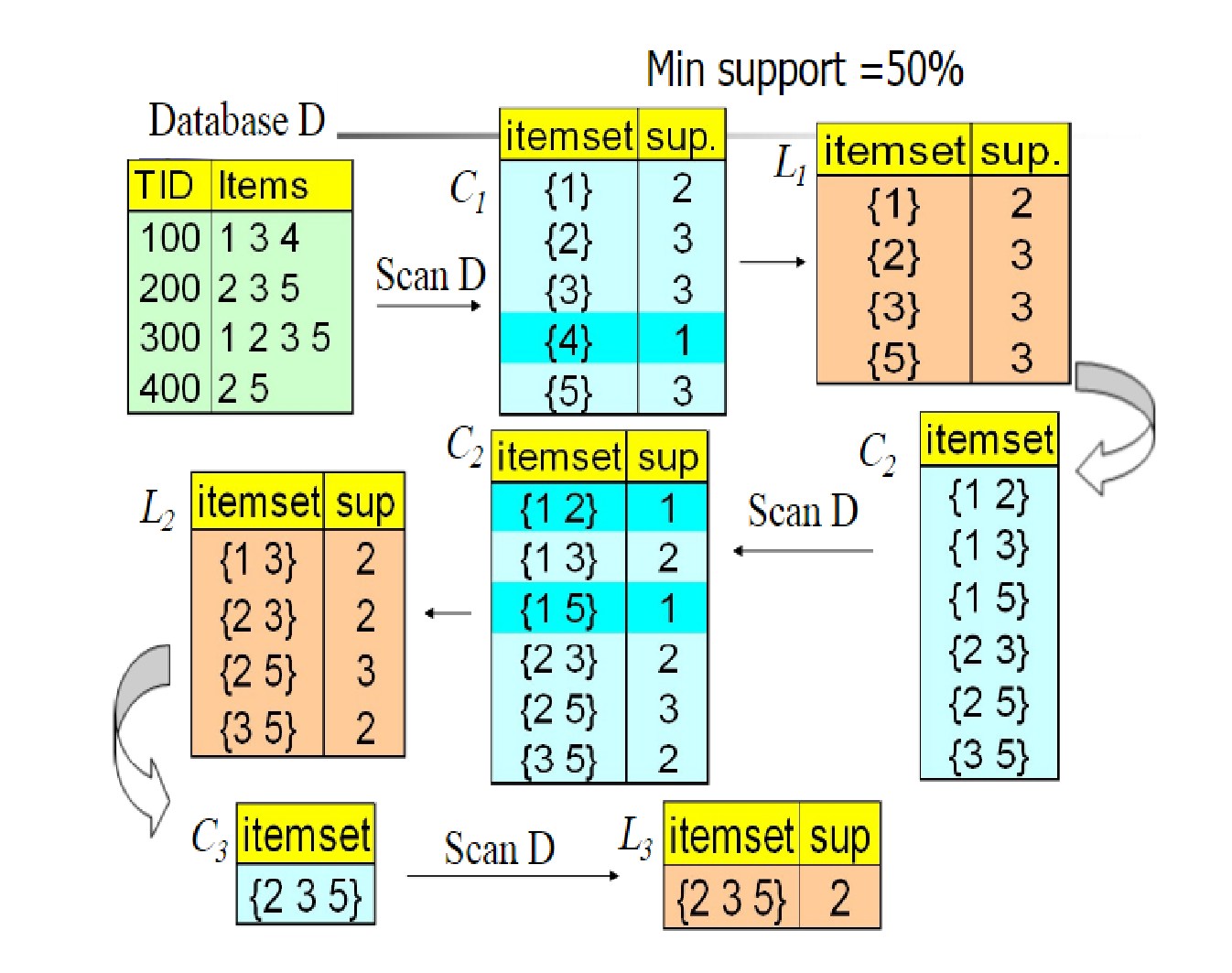
這個例子的影像還是滿生動的,很容易看的懂。下面就簡單的解釋一下:
首先我們有數據集D,然後生成數據項(K =1)的備選項集(C_1),然後去除(support_n < Min support)的數據項,得到(L_1),然後又生成數據項(K =2)的備選項集(C_2),然後又去除(support_n < Min support)的數據項。進行遞歸,直到無法發現新的頻繁項。
結尾
總的來說,Apriori演算法不是很難,演算法的流程也很簡單,而它的核心在於如何構建一個有效的評判標準,support?confidence?Lift?or others?但是它也有一些缺點:每次遞歸都需要產生大量的備選項集,如果數據集很大的話,怎麼辦?重複的掃描數據集……
在下一篇部落格中,我將介紹如何使用Apriori演算法對電影的數據集進行分析,然後找出之間的相關關係。
參考
- Apriori演算法原理總結
- Association Rules and the Apriori Algorithm: A Tutorial
- 《Python數據挖掘入門與實踐》
- 數據挖掘蔣少華老師
