線性降維:主成分分析原理及模擬
- 2020 年 3 月 15 日
- 筆記
鶯嘴啄花紅溜,燕尾點波綠皺。
指冷玉笙寒,吹徹小梅春透。
依舊,依舊,人與綠楊俱瘦。
——《如夢令·春景》 秦觀
更多精彩內容請關注微信公眾號 「優化與演算法」
1、背景
隨著資訊技術的發展,數據量呈現爆照式增長,高維海量數據給傳統的數據處理方法帶來了嚴峻的挑戰,因此,開發高效的數據處理技術是非常必要的。數據降維是解決維度災難的一種有效方法,之所以對數據進行降維是因為:
- 在原始的高維空間中,包含有冗餘資訊以及噪音資訊,在實際應用例如影像識別中造成了誤差,降低了準確率;而通過降維,我們希望減少冗餘資訊所造成的誤差,提高識別(或其他應用)的精度。
- 希望通過降維演算法來尋找數據內部的本質結構特徵。
主成分分析(Principal Component Analysis,PCA)是一種常見的線性降維方法,廣泛應用於影像處理、人臉識別、數據壓縮、訊號去噪等領域。
2、演算法思想與原理
設原數據大小為 (Ntimes M) ,經過PCA降維後的數據大小為 (N times K),其中 (K<M)。
PCA的中心思想是:將高維數據投影到具有最大方差的低維空間中。
2.1 從不同角度理解PCA
PCA原理可以從不同角度來理解:
- 從空間變換的角度來看,這裡我們把 (N) 稱為數據維度,(M) 稱為原子個數,因此,PCA也可以直白的理解為將 (N) 維空間中相關性較大的 (M) 個原子組成的空間壓縮成相關性最小的 (K) 個原子組成的空間。
- 從分類的角度來看,這裡我們把 (N) 稱為樣本數量,(M) 稱為樣本類數,因此,PCA也可以普通的理解為將 (M) 個樣本類別重新整理成具有最大區分度的 (K) 個類別。
- 從訊號表示的角度來看,這裡我們把 (N) 稱為單個訊號長度,(M) 稱為訊號數量,因此,PCA也可以粗略的理解為將 (M) 個很相似的訊號通過適當的投影(或者說變換映射)用 (K) 個訊號來簡單的表示原來的。就比如說一隻貓的叫聲為「喵喵喵~」,另一隻貓的叫聲也為「喵喵喵~」,雖然他們的叫聲會存在一定的差異,但是對於人類來說幾乎是一樣的,這兩隻貓發出的聲音訊號可以直接用一個訊號來表示。
- 從特徵提取的角度來說,這裡我們把 (N) 稱為數據維度,(M) 稱為特徵數量,因此,PCA也可以近似的理解為將數據集中 (M) 個特徵用 (K) 個特徵來表示,其中去掉的 (M-K) 個特徵是無關緊要的。
2.2 PCA直觀思想
為了方便理解,下面以一個具體實例來說明PCA的這種思想。
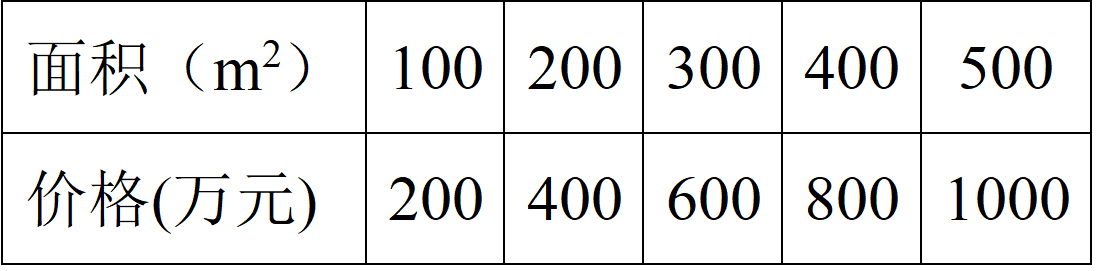
假設某地的房子面積和總價在理想情況下符合如下正比關係:
 |
這些數據在二維平面中可以表示為:
 |
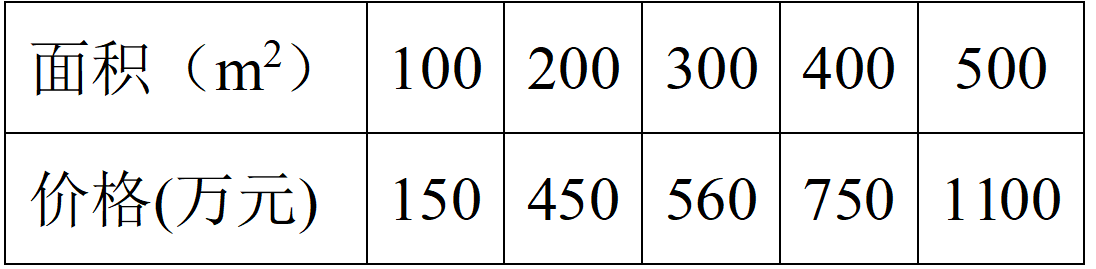
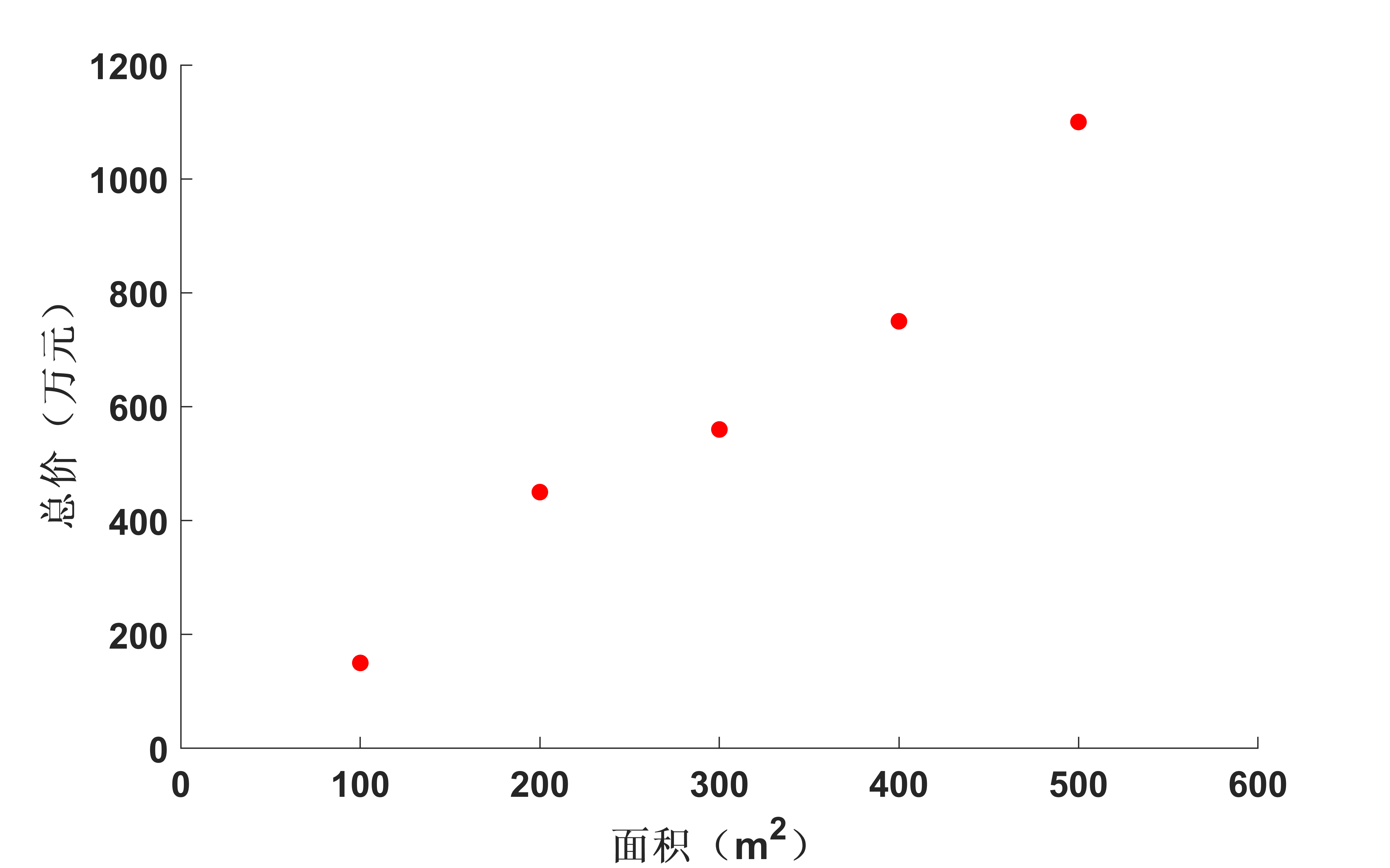
然而在實際中並非如此,由於各種原因總會產生一些波動,有可能會是如表2所示的關係。
 |
同樣的,這些數據在二維平面中可以表示為:
 |
若把表一中的數據當作一個矩陣來看,就變成:
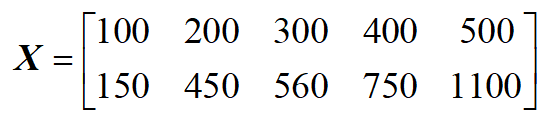 |
從表1中的數據來看,在理想情況下,房子面積和總價符合正比關係,也就是說房子面積和總價具有很大的相關性,若把它當成一個 (2times 5) 的矩陣的話,它的秩為1,這說明用表1中的10個數據來描述房子面積和總價的這種關係顯得有些冗餘,我們只需要一行數據((5)個)就可以描述清楚這種關係。在實際情況中,表2中的兩行數據雖然不滿足完全的正比關係,但是它們也非常接近正比關係,因此,他們之間的相關性也是非常大的。那麼我們如何將 (bf{X}) 中的數據用一行數(也就是從二維降到一維)來表示呢?由前面相關性分析可知,應該是要進行「去相關性」操作,也就是要使兩行數據通過一個變換,使其相關性變小。
數學裡通常用方差和協方差來描述數據的相關性,方差定義如下:
[Var({bf{x}}) = frac{1}{N}sumlimits_{i = 1}^N {{{left( {{x_i} – E({bf{x}})} right)}^2}} ]
其中 (E({bf{x}}) = frac{1}{N}sumlimits_{i = 1}^N {left( {{x_i}} right)})為向量 (bf{x}) 的期望。
很明顯,方差是描述一個向量(維度)內數據的分散程度(相關性)的度量,若如果數據是像表3一樣的矩陣形式呢?那麼就用協方差來描述數據之間的相關性:
[Cov( bf{x},bf{y}) = frac{1}{N}sum ^{N}_{i=1}( x_{i} -E(bf{x}))( y_{i} -E(bf{y})) =E[( bf{x}-E(bf{x}))( bf{y}-E(bf{y}))]
數量高於2個的 (N) 維數據通常用協方差矩陣來表示:
[ bf{C} =begin{pmatrix} cov(bf{x},bf{x}) & cov( bf{x},bf{y})\ cov( bf{y},bf{x}) & cov( bf{y},bf{y}) end{pmatrix}]
假設數據已經經過中心化處理,數據矩陣 (bf{X}) 的協方差矩陣就可以寫成:
[ bf{C_{bf{X}}} =begin{pmatrix} cov(bf{X}_{1},bf{X}_{1}) & cov(bf{X}_{1},bf{X}_{2})\ cov( bf{X}_{2},bf{X}_{1}) & cov( bf{X}_{2},bf{X}_{2}) end{pmatrix}]
其中,(bf{X}_{1}) 和 (bf{X}_{2}) 分別為 (bf{X}) 的第一行和第二行。
在這個例子中,協方差具體表示什麼意義呢?
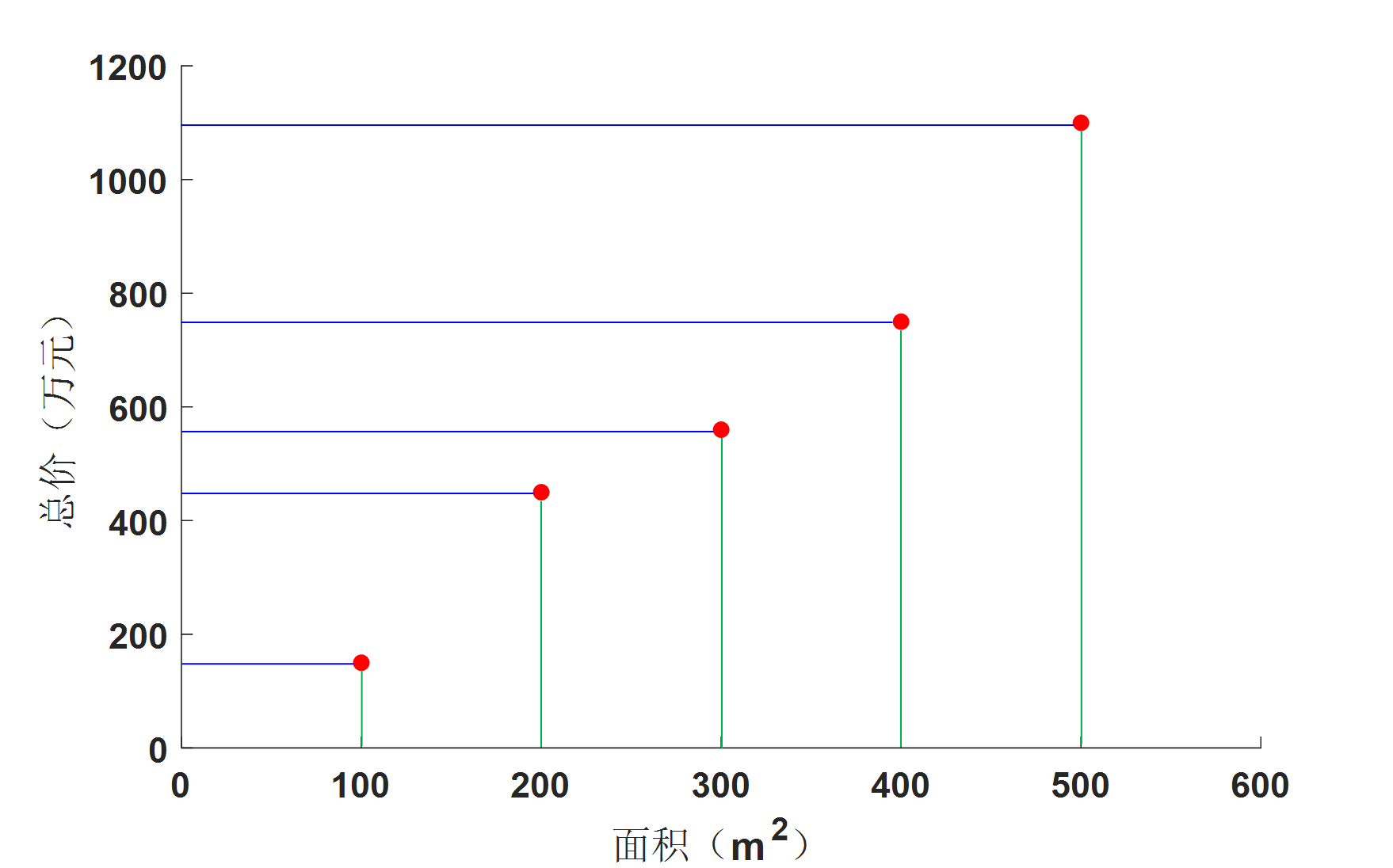 |
如圖3所示,將各個數據點分別對橫軸和縱軸做投影,其中綠色線與橫軸的交點為數據在橫軸上的投影,藍線與縱軸的交點為數據在縱軸上的投影。那麼橫軸上交點的分散程度(方差)就對應了 (bf{C}) 中的 (cov(bf{x},bf{x})),而縱軸上的交點的分散程度就對應了 (bf{C}) 中的 (cov(bf{y},bf{y}))。(cov( bf{y},bf{x}) 則表示 (bf{x}) 和 (bf{y}) 之間的相關程度。
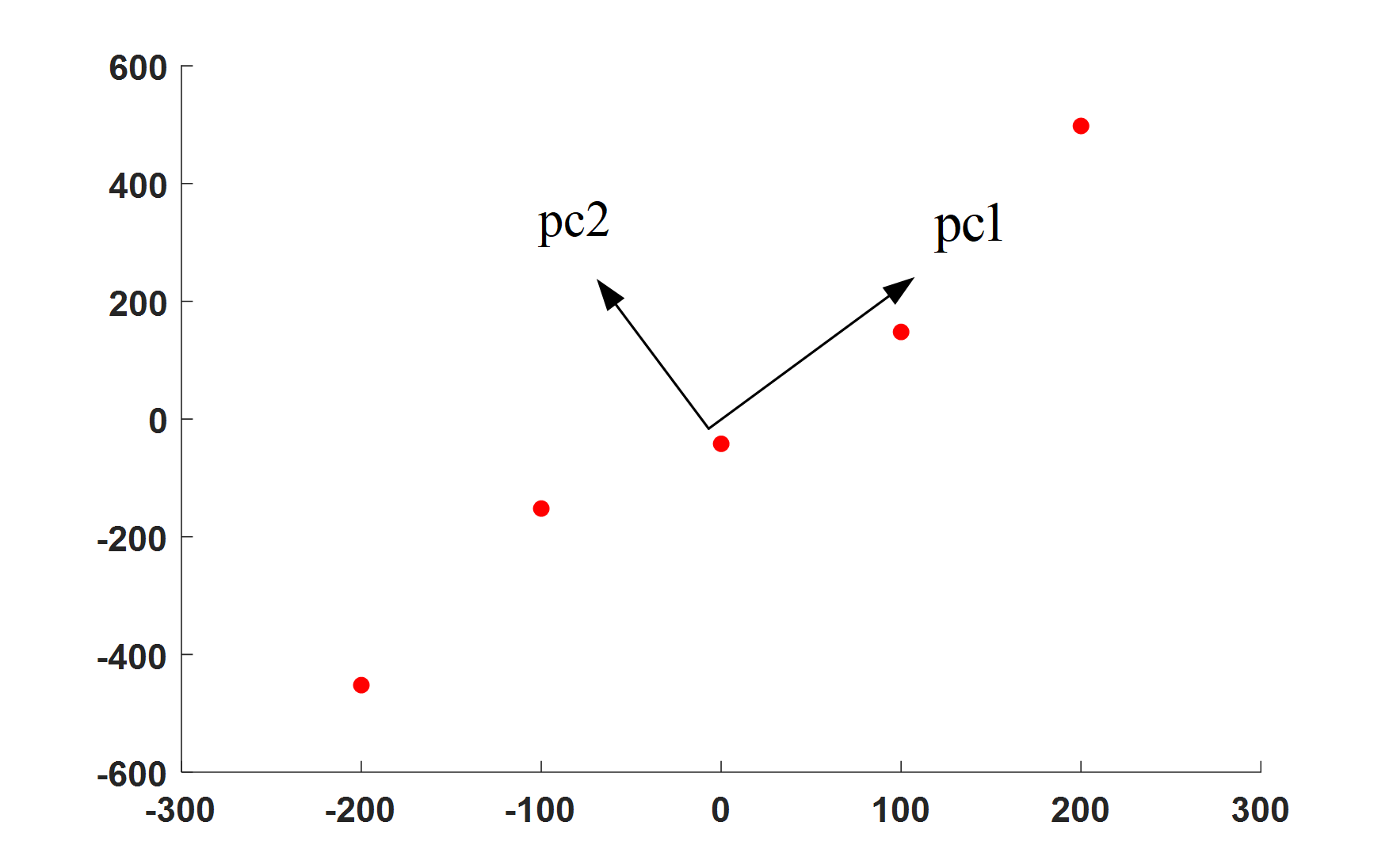
那麼由PCA的中心思想:將高維數據投影到具有最大方差的低維空間中,我們就可以知道只要將數據投影到方差最大的低維((K) 維)空間中就行,那麼如何找到方差最大的低維空間呢?如圖4所示,數據不僅可以投影到橫軸和縱軸,還可以360度旋轉,投影到任何直線(1維空間)上,對於圖4中的 (pc1) 方向和 (pc2) 方向,可以直觀的看出來肯定要投影到 (pc1) 方向要好一點,因為投影之後的數據點更分散。
數據投影到一個維度越分散在一定程度上就說明兩類數據的相關性越小,這就指導我們一條思路:只需要將 (bf{C_{bf{X}}}) 中的兩個協方差 (cov(bf{X}_{1},bf{X}_{2})) 和 (cov(bf{X}_{2},bf{X}_{1})) 變成0就可以了,這就意味著將 (bf{C_{bf{X}}}) 變成對角矩陣就行了。
 |
我們發現 (bf{C_{bf{X}}}) 是一個對稱矩陣,自然就會想到特徵值分解。
(bf{C_{bf{X}}}) 是 (bf{M}) 階對稱矩陣,則必有正交矩陣 (bf{P})使得:
({{bf{P}}^{ – 1}}{{bf{C}}_{bf{X}}}{bf{P}} = {{bf{P}}^{rm T}}{{bf{C}}_{bf{X}}}{bf{P}} = {bf{Lambda }})
其中 (bf{Lambda }) 是以 (bf{C_{bf{X}}}) 的 (bf{M}) 個特徵值為對角元
因此我們只要找到這個正交矩陣 (bf{P}) 和它對應的特徵值,然後取前 (K) 個最大的特徵值及其對應的特徵向量就可以了,這實際上就是進行特徵值分解:
[{{bf{C}}_{bf{X}}} = {{bf{P}}^{rm T}}{bf{Lambda P}}]
當然也可以通過奇異值分解來解決問題:
[{{bf{C}}_{bf{X}}} = {bf{USigma V}}]
經過奇異值分解後得到的 (bf{Sigma}) 中最大的 (K) 個奇異值及其對應的 (bf{U}) 中的 (K) 個列向量組成的矩陣就是變換矩陣。如果用右奇異矩陣 (bf{U}) 的話就是對 (bf{X}) 的列進行降維了。
求協方差矩陣 ({{bf{C}}_{bf{X}}} = {{bf{X}}}{bf{X}^{rm T}}) (這裡實際上是散度矩陣,是協方差矩陣的 (N-1) 倍)的複雜度為 (Oleft( {M{N^2}} right)),當數據維度過大時,還是很耗時的,此時用奇異值分解有一定的優勢,比如有一些SVD的實現演算法可以先不求出協方差矩陣也能求出右奇異矩陣 (bf{V}),也就是說,PCA演算法可以不用做特徵分解而是通過SVD來完成,這個方法在樣本量很大的時候很有效。
至於為什麼協方差矩陣經過特徵值(奇異值)分解後前 (K) 個最大特徵值對應的分量就是方差最大的 (K) 維空間呢?這裡給出一個簡單的理解方法,數學證明就不貼出來了。(K) 個特徵值與(K) 個特徵向量構成了一個 (K) 維空間,而特徵值正是衡量每一維空間所佔的分量的,特徵值越大,說明這一維度所包含的資訊量越大,權重就越大。前 (K) 個最大特徵值組成的空間當然是權重最大的,從而矩陣 (bf{X}) 投影到這 (K) 維空間中足夠分散,也就是說方差足夠大。
2.3 PCA的理論推導
這裡引用一下
這裡是引用主成分分析(PCA)原理總結這篇部落格的證明。



2.4 PCA實例求解
還是以某地房子面積與總價的問題作為例子來總結PCA演算法步驟。
步驟1. 數據去中心化:
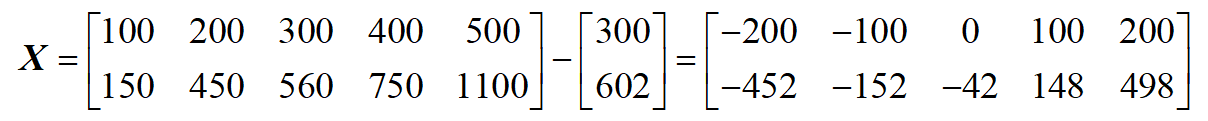
步驟2:計算散度矩陣(協方差矩陣)
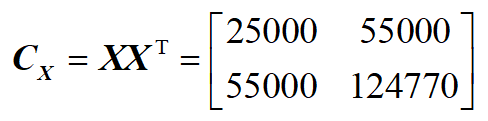
步驟3:對協方差矩陣進行特徵值(奇異值分解):
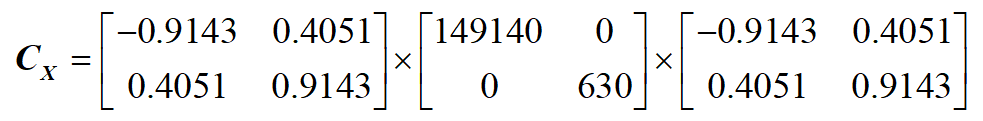
步驟4:取最大的 (K) 個特徵值與特徵向量構成一個 變換矩陣 (bf{P}_K)(這裡 (K=1)):
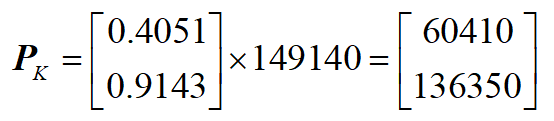
步驟5:將原始數據投影到 (K) 維空間:
[{bf{Y}} = {bf{P}}_K^{rm T}{bf{X}}]
我們可以看到最後結果,那條投影線跟我們直觀感受的一樣:
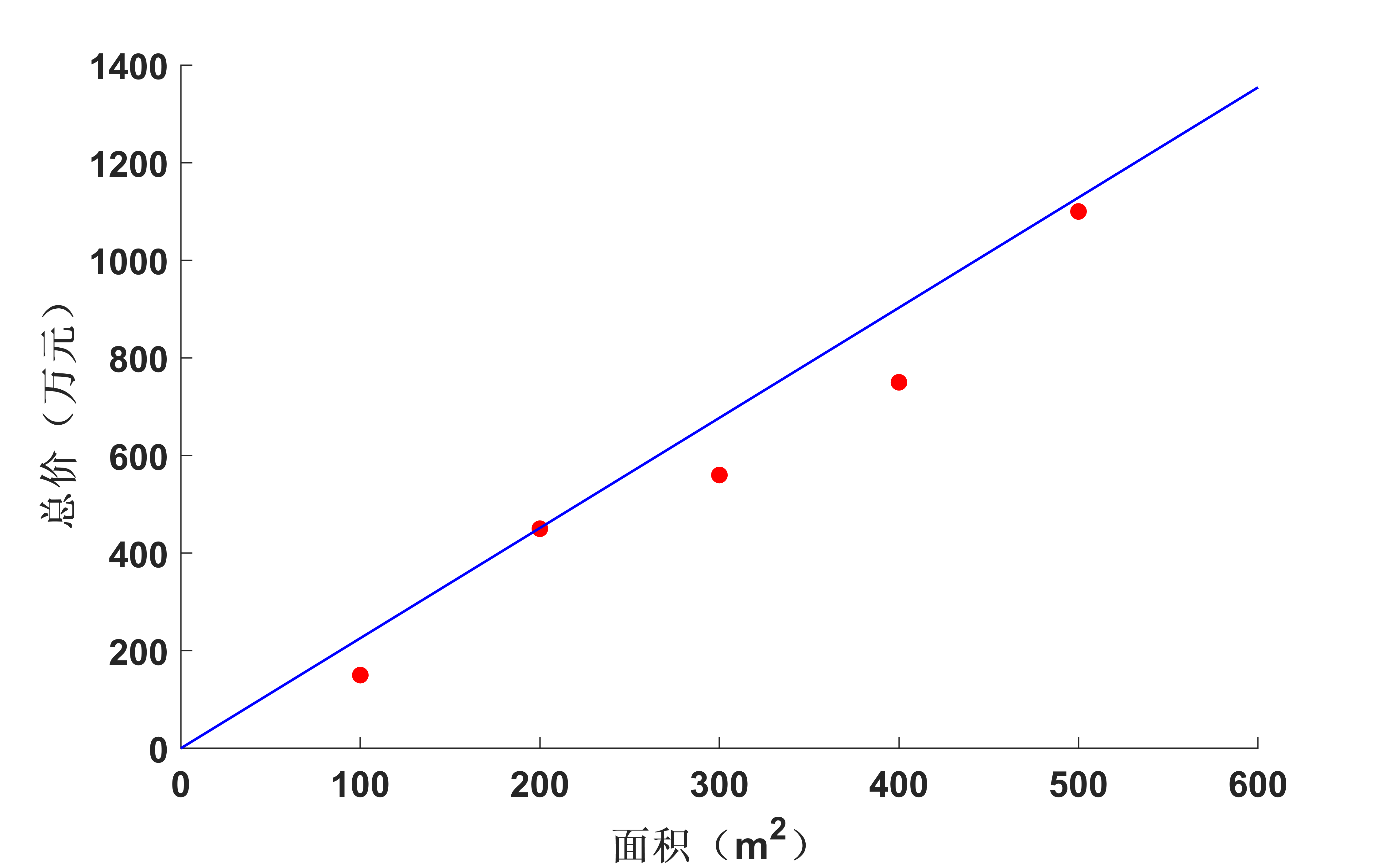
3. PCA的應用
PCA在特徵工程、電腦視覺、人臉識別、去噪等領域有很廣泛的應用。這裡僅僅測試一下PCA在影像壓縮上的效果。matlab程式碼如下:
function [P,r] = fun_pca(X,K) % 輸入: % X:經過中心化處理的數據 % K: 需要降低到的維度 % 輸出: % P: 投影矩陣 % r:前K個奇異值占所有奇異值的比 Cov = X*X'; [u,s] = svd(Cov) ; P = u(:,1:K) ; s = diag(s) ; r = sum(abs(s(1:K)))/sum(abs(s)) ; endPCA for image compression clear img = imread('xinhuan.jpg'); img = im2double(img); K=50; % 保留主成分個數 img_matrix = [img(:,:,1),img(:,:,2),img(:,:,3)] ; % 將RGB三通道影像合併成一個矩陣 img_matrix_mean = img_matrix - mean(img_matrix) ; % 求均值 Proj = fun_pca(img_matrix_mean,K) ; % 用PCA演算法獲得投影矩陣P img_K = Proj'*img_matrix_mean ; % 壓縮到K維後的影像 %% 影像重建 img_rec = Proj*img_K ; % 影像解壓縮 img_rec = img_rec + mean(img_matrix) ; % 重建後的影像加上均值 c_n = size(img_matrix,2)/3 ; img_rec = cat(3,img_rec(:,1:c_n),img_rec(:,c_n+1:2*c_n),img_rec(:,2*c_n+1:end)) ; figure(1) subplot(1,2,1) imshow(img),title('原圖') subplot(1,2,2) imshow(img_rec),title(strcat('壓縮後的影像(', '奇異值數量:10)'))SVD for image compression clear img = imread('xinhuan.jpg'); img = im2double(img); K = 10 ; for i = 1:3 [u,s,v] = svd(img(:,:,i)) ; s = diag(s) ; r = sum(abs(s(1:K)))/sum(abs(s)) ; s = diag(s(1:K)) ; W(:,:,i) = u(:,1:K)*s*v(:,1:K)' ; end figure(1) subplot(2,2,1) imshow(img),title('原圖') subplot(2,2,2) imshow(P),title(strcat('壓縮後的影像(', '奇異值數量:10)'))奇異值分解影像壓縮:
 |
PCA影像壓縮:
 |
從圖5和圖6基本看不出來PCA和SVD壓縮影像有多大區別,其特徵值貢獻比差異很大確不能說明什麼問題,影像重建品質可以使用峰值信噪比(PSNR)來評價,感興趣的可以去試一試。
4. 討論
PCA的主要優點有:
1)僅僅需要以方差衡量資訊量,不受數據集以外的因素影響。
2)各主成分之間正交,可消除原始數據成分間的相互影響的因素。
3)計算方法簡單,主要運算是特徵值分解,易於實現。
PCA演算法的主要缺點有:
1)主成分各個特徵維度的含義具有一定的模糊性,不如原始樣本特徵的解釋性強。
2)方差小的非主成分也可能含有對樣本差異的重要資訊,因降維丟棄可能對後續數據處理有影響。
更多精彩內容請關注訂閱號優化與演算法和加入QQ討論群1032493483獲取更多資料