何為記憶體重排序?
- 2020 年 3 月 14 日
- 筆記
前言
我們知道對於我們所編寫的程式碼通過電腦如何順序執行以源程式碼編寫的指令,程式只是處理器自上而下執行的文本文件中列出的操作列表,其實這是錯誤的理解,電腦能夠根據需要更改某些低級操作的順序,尤其是在讀取和寫入記憶體時,出於性能原因,會進行記憶體重排序,記憶體重排序是一種利用指令來進行對應操作,通過這種操作極大地提高了程式的速度,但是,另一方面,它可能對無鎖多執行緒造成嚴重破壞性,本節我們來分析何為重排序。
何為重排序
程式被載入到主記憶體中以便執行,CPU的任務是運行存儲在其中的指令,並在必要時讀取和寫入數據,那麼具體CPU具體是如何操作的呢?獲取指令、解碼從主存儲器中載入所有所需數據的指令、執行指令、將生成的結果寫回並存儲到主記憶體中。現代CPU能夠每納秒執行十條指令,但是需要數十納秒才能從主記憶體中獲取一些數據,與處理器相比,這種類型的記憶體變得非常慢,為了減少載入和存儲操作中的延遲,因此作業系統為CPU配備了一個很小但又非常快的特殊記憶體塊,稱為快取,所以CPU將使用暫存器-快取,高速快取是處理器存儲其最常使用的數據的地方,以避免與主記憶體的緩慢交互,當處理器需要讀取或寫入主記憶體時,它首先檢查該數據的副本在其自己的快取中是否可用,如果是這樣,則處理器直接讀取或寫入高速快取,而不必等待較慢的主記憶體響應,現代的CPU由多個內核組成—執行實際計算的組件,每個內核都有自己的快取塊,該快取塊又連接到主記憶體,如下圖所示:
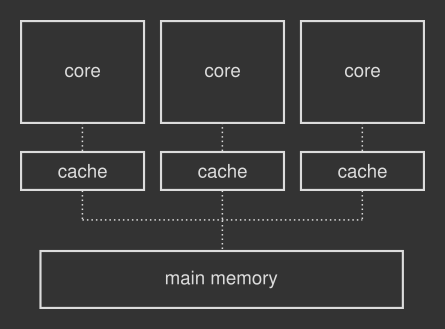
具體地說,解碼模組可以具有一個派遣隊列,在該隊列中,提取的指令將保留,直到其請求的數據從主記憶體載入到快取中或它們的從屬指令完成為止,當一些指令正在等待(或停頓)時,就緒的指令會同時解碼並下推到管道中,如果舊數據尚未在高速快取中,則回寫模組會將存儲請求放入存儲緩衝區中(高速快取控制器按高速快取行存儲和載入數據,每條高速快取行通常大於單個記憶體訪問),並開始處理下一條獨立指令。在將舊數據放入快取後,或者如果它已經在快取中,指令將使用新結果覆蓋快取,最終,新數據將最終根據不同的策略非同步刷新到主記憶體(例如,當必須從高速快取中為新的高速快取行或與其他數據一起以批處理方式處理數據時),總而言之,通過加入快取使電腦運行速度更快, 或者說它可以使處理器始終保持忙碌和高效的狀態,從而幫助處理器因等待主記憶體響應避免浪費不必要的時間。
class ReadWriteDemo { int A = 0; boolean B = false; //CPU1 (thread1) runs this method void writer() { A = 10; B = true; } //CPU2 (thread2) runs this method void reader() { while (!B) continue; System.out.println(A == 10); } }
編寫上述程式碼後,我們會假設write方法將在reader方法執行之前完成,在理想情況下這種假設正確無疑,但是,如果使用CPU暫存器的快取和緩衝,這種假設將可能是錯誤的,例如,如果欄位B已經在高速快取中,而A不在,則B可以早於A存入主記憶體,即使A和B都在高速快取中,B仍有可能早於A存入主記憶體或者A從主記憶體中先載入到B之前或者A在B存儲前載入之前等類似多種可能性結果,簡而言之,將語句在原始程式碼中的排序方式稱為程式順序,單個記憶體引用(載入或存儲)完成的順序稱為執行順序,由於CPU高速快取,緩衝區和推測性執行在指令完成時間上增加了太多的非同步性,因此執行順序不一定與其程式順序相同,這就是CPU中執行重排序的方式。如果程式是單執行緒或者方法writer中的欄位A和B僅由一個執行緒訪問,我們實際上並不用關心重排序,因為方法writer中的兩個存儲區是獨立的,即使兩個存儲被重排序。但是,如果程式為多執行緒,那麼可能需要考慮執行順序,例如,CPU1執行方法writer,而CPU2執行方法reader,由於執行緒使用共享的主記憶體進行通訊,並且由於CPU快取一致性協議,快取對訪問是透明的,因此當從記憶體中載入數據時,如果從未從任何CPU載入過數據,則從主記憶體中獲取,如果該CPU擁有數據,則為來自另一個CPU的高速快取,如果擁有數據,則為來自其自身的高速快取,如果CPU1無序執行方法writer,則上述列印出false,即使CPU1按照程式順序執行了方法writer,列印結果仍有可能為false,因為CPU2可以在執行while語句時之前執行列印結果,因為從邏輯上講,在完成while語句之後才應該列印結果(這稱為控制依賴),但是,CPU2可以自由地先推測性地執行列印結果,一般來講,當CPU看到諸如if或while語句之類的分支時,直到該分支指令完成之前,它才知道在哪裡獲取下一條指令,但是,如果它等待分支指令而又找不到足夠的獨立指令,則會降低CPU性能,因此,CPU1可以根據其預測推測性地執行列印結果,稍後可以批准其預測路徑正確時,它將提交執行,在reader方法情況下,這意味著在列印結果之後,CPU1在while語句中找到了B == true,由於CPU並不知道我們關心A和B的執行順序,因此必須使用所謂的記憶體屏障來告知它們順序必須使用同步構造以強制執行的排序語義。如果兩個CPU都引用相同的記憶體位置,說明它們具有數據依賴性,則沒有一個CPU將對存儲的給定操作進行重排序,否則將違反程式語義,基於以上分析,我們得出結論:單執行緒程式在順序化語義as-if-serial下運行,重排序的效果僅對多執行緒程式可見(或者一個執行緒中的重新排序僅對其他執行緒可見/對其他執行緒很重要),當CPU本質上執行給不了我們實際想要的排序語義時,程式必須使用同步機制。
指令調度說明
只要編譯器不違反程式語義(這裡的編譯指代的是JIT編譯器)就可以自由地根據其優化對程式碼進行物理或邏輯重新排序,現代編譯器具有許多強大的程式碼轉換,如下:
public class Main { public static void main(String[] args) { int A = 10; int B = A + 10; int C = 20; } }
假設編譯器通過複雜的分析發現A不在快取中,而C在快取中,因此,A=10將觸發多周期長的數據載入,而C=20則可以在單個周期內完成,編譯器可以直接跳過對A=10和B=A+10直接執行C=20,以將停頓減少1,如果編譯器可以找到更多獨立的指令,則可以通過減少更多的停頓來進行相同的重排序。由上述我們知道在單核電腦上,硬體記憶體的重排序並不是問題,執行緒是作業系統控制的軟體結構,CPU僅接收連續的存儲指令流,它們仍然可以重排序,但是要遵循一個基本規則:給定內核的記憶體訪問在該內核中似乎是在程式中編寫的,因此,可能會發生記憶體重排序,但前提是它不會破壞最終結果。接下來我們再來看一個例子(源於java並發實戰)
public class UnsafeLazyInitialization { private static Resource resource; public static Resource getInstance() { if (resource == null) resource = new Resource(); return resource; } }
如上使用先檢查後操作模式實例化Resource,不用多講,很有可能兩個執行緒可以在該方法中同時到達,都將resource視為null並初始化變數。這裡還涉及到我們上一節所講解的部分初始化對象問題,導致對象無法正確安全發布,當我們初始化一個對象具體會進行5步操作:分配記憶體、創建對象、使用默認值初始化欄位(比如int、boolean等)、運行構造函數、將對象的引用分配給變數,但是這裡在進行第4步操作之前就運行第5步操作,所以getInstance方法將返回一個非空但不一致的對象(具有未初始化欄位)的引用。但是上述方法也很有可能返回null,因為JMM對此允許, 要了解為什麼這樣做是可行的,我們需要詳細分析讀寫,並評估它們之間是否存在事先發生聯繫(happens-before),我們將上述程式碼進行如下重寫,以清楚地顯示讀取和寫入:

public class UnsafeLazyInitialization { private static Resource resource; public static Resource getInstance() { Resource temp = resource; if (resource == null) resource = temp = new Resource(); return temp; } }
通過聲明一個Resource的臨時變數temp,此時在執行緒1和執行緒2都為null,接下來將在執行緒1中為null,而在執行緒2中不為null,因為它已由執行緒1初始化,最終執行緒1返回實例,而執行緒2返回null。
總結
本節我們詳細講解了重排序的概念以及引入重排序的原因,下一節我們進入到記憶體模型,感謝您的閱讀,我們下節見。
