機器學習 – LSTM應用之sequence generation
- 2020 年 3 月 10 日
- 筆記
- 概述
LSTM在機器學習上面的應用是非常廣泛的,從股票分析,機器翻譯 到 語義分析等等各個方面都有它的用武之地,經過前面的對於LSTM結構的分析,這一節主要介紹一些LSTM的一個小應用,那就是sequence generation。其實sequence generation本事也是對一些應用的統稱,例如: 讓機器學習音樂後然後讓機器根據學習的模型自己創造音樂(製作人快要失業啦。。。。),讓機器學習某種語言然後讓這個學習到的模型自己產生Word來說話,等等。這其實本質是一種one-to-many的LSTM網路結構。這一節內容主要就是講解這一種網路結構的應用。
- Sequence generation的網路結構分析
在咱們實際實施並且寫程式碼之前,咱們首要的任務是如何搭建一個sequence generation的網路結構。一個sequence generation的網路結構其實也是分為兩個部分,第一部分是encoding (modeling),也就是咱們建模的網路,它是一個many-to-many的網路結構;第二部分是decoding的過程,它是一個one-to-many的結構。那麼具體這個網路結構是什麼樣呢?咱們看看下面的圖片
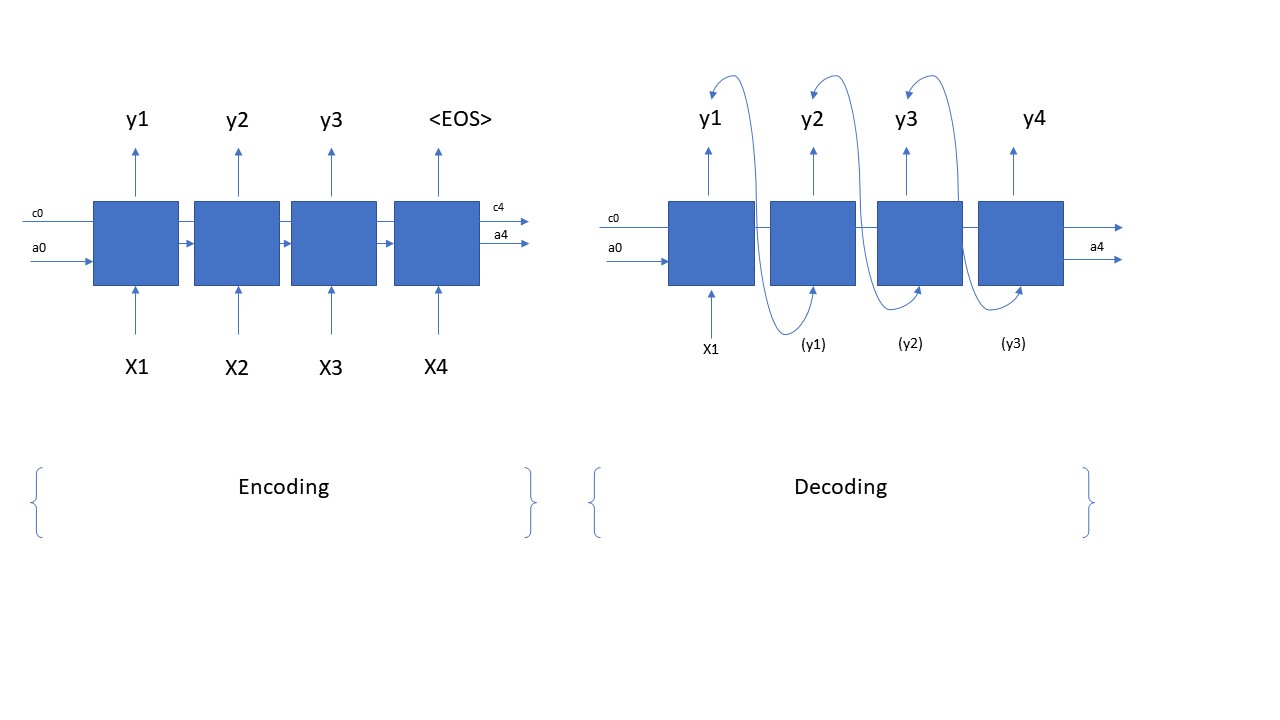
上面的圖片展示的就是一個sequence generation從encoding到decoding的全過程和結構。在咱們的這個應用中,咱們的encoding中每一個time step的輸入是一個文字,輸出則是相應輸入的後一個字,這些數據都來自於咱們的training data;等到咱們訓練完成後,咱們將訓練得來的LSTM cell來構建一個decoding網路,就是咱們只輸入一個單詞,它根據咱們的之前學習的model,來自動的預測咱們要說什麼話,是不是很cool??當然啦,在encoding階段,咱們的LSTM具體有多少的time steps,是根據咱們的input data的shape來決定的;在decoding階段具體有多少的time step則是由咱們自己來決定的, 咱們需要用一個for loop來決定咱們在decoding階段的time steps。從上圖,咱們也可以很明顯的看出在decoding的時候,咱們只有一個輸入X,後面time step的輸入則都是前一個time step的輸出。上面就是怎麼sequence generation的一個整體的結構。那麼就下來,咱們就分析一些它的程式碼,看看咱們如何用程式碼來實現上面的網路結構。
- Sequence generation 程式碼分析
從上面的分析,咱們可以看出sequence generation是由兩個部分組成,那麼自然咱們程式碼也肯定得分成兩部分來實現上圖中的網路結構,那麼接下來咱們來看看第一步,就是如何用Python來實現encoding的結構,程式碼如下所示,咱們看著程式碼來慢慢分析:
#define shared variables
n_a=64 n_values = 78 # dimensions of out single input reshapor = keras.layers.Reshape((1, n_values)) # Used in Step 2.B of djmodel(), below LSTM_cell = keras.layers.LSTM(n_a, return_state = True) # Used in Step 2.C, return_state muset be set densor = keras.layers.Dense(n_values, activation='softmax') # Used in Step 2.D
#multiple inputs (X, a, c), we have to use functional Keras, other than sequential APIs def create_model(Tx, n_a, n_values): """ Implement the model Arguments: Tx -- length of the sequence in a corpus n_a -- the number of activations used in our model n_values -- number of unique values in the music data Returns: model -- a keras instance model with n_a activations """ # Define the input layer and specify the shape X = keras.Input(shape=(Tx, n_values))#input omit the batch_size dimension, X is still 3 dimensiones (with batch_size dimension). # Define the initial hidden state a0 and initial cell state c0 a0 = keras.Input(shape=(n_a,), name='a0') c0 = keras.Input(shape=(n_a,), name='c0') a = a0 c = c0 # Step 1: Create empty list to append the outputs while you iterate outputs = [] # Step 2: Loop for t in range(Tx): # Step 2.A: select the "t"th time step vector from X. x = keras.layers.Lambda(lambda x: X[:,t,:])(X) # Step 2.B: Use reshapor to reshape x to be (1, n_values) (≈1 line) #因為LSTM layer默認的輸入的dimension是 (batch_size, Tx, n_values),其中batch_size是省略的, 即是(Tx, n_values)。如果是(Tx,n_values)的話,LSTM()會默認循環Tx次,因而,咱們將它reshape成(1,n_values),它就不會循環了。 x = reshapor(x) # Step 2.C: Perform one step of the LSTM_cell a, _, c = LSTM_cell(x, initial_state=[a,c]) # Step 2.D: Apply densor to the hidden state output of LSTM_Cell out = densor(a) #out's shape is (m,1,n_values) # Step 2.E: add the output to "outputs" outputs.append(out) # Step 3: Create model instance model = keras.Model(inputs=[X,a0,c0],outputs=outputs) return model
從上面的程式碼,咱們可以看出,首先咱們得定義一些shared variable,例如a, c的dimension, LSTM_cell, 等等這些,這些變數在咱們的model中無論是encoding還是decoding都是公用的,並不是說一個LSTM layer就含有很多個LSTM_cell,這是錯誤的理解(雖然咱們圖片上面是這麼畫的,但這是為了方便大家理解才畫了很多個LSTM_cell,實際是同一個LSTM_cell, 希望不要誤解)。首先咱們構建這個網路需要的參數有,Tx = time_steps; n_a = a,c的vector的dimension;以及n_values = 咱們每一個輸入的vector的dimension。因為咱們的網路有三處輸入,分別是X, a, c, 所以咱們要先定義這三處輸入,並且設定它們的shape, 注意在設定它們的shape的時候,是不需要有batch_size的;隨後咱們來到for loop中,首先提取每一個time step的input value, 即上面程式碼中Lambda layer所做的事兒,然後因為咱們提取的是每一個time step的值,每一個time step, LSTM只會循環一次,所以咱們還是得把它reshape到(1,n_values); 隨後咱們將處理好的input value傳遞給LSTM_cell,並且返回hidden state a, 和memory cell c, 最後經過一個dense layer計算咱們的輸出,並且將每一步的輸出裝進outputs這個list中。這就是構建咱們的encoding網路的整個步驟。那麼既然咱們分析了上面encoding的階段,完成了對咱們LSTM的訓練過程並且得到了咱們想要的LSTM, 那麼接下來咱們看一看咱們的decoding過程,即如何用訓練得到的LSTM來generate(predict)咱們的sequence啦,咱們還是看下面的程式碼,然後慢慢分析
def sequence_inference_model(LSTM_cell, n_values = 78, n_a = 64, Ty = 100): """ Uses the trained "LSTM_cell" and "densor" from model() to generate a sequence of values. Arguments: LSTM_cell -- the trained "LSTM_cell" from model(), Keras layer object densor -- the trained "densor" from model(), Keras layer object n_values -- integer, number of unique values n_a -- number of units in the LSTM_cell Ty -- integer, number of time steps to generate Returns: inference_model -- Keras model instance """ # Define the input of your model with a shape (it is a one-to-many structure, the input shape is (1,n_values)) x0 = keras.Input(shape=(1, n_values)) # Define a0, c0, initial hidden state for the decoder LSTM a0 = keras.Input(shape=(n_a,), name='a0') c0 = keras.Input(shape=(n_a,), name='c0') a = a0 c = c0 x = x0 # Step 1: Create an empty list of "outputs" to later store your predicted values (≈1 line) outputs = [] # Step 2: Loop over Ty and generate a value at every time step for t in range(Ty): # Step 2.A: Perform one step of LSTM_cell a, _, c = LSTM_cell(x, initial_state=[a, c]) # Step 2.B: Apply Dense layer to the hidden state output of the LSTM_cell out = densor(a) # Step 2.C: Append the prediction "out" to "outputs". out.shape = (None, 78) outputs.append(out) # Step 2.D: Select the next value according to "out", and set "x" to be the one-hot representation of the # selected value, which will be passed as the input to LSTM_cell on the next step. We have provided # the line of code you need to do this. x = keras.layers.Lambda(one_hot)(out) # Step 3: Create model instance with the correct "inputs" and "outputs" inference_model = keras.Model(inputs=[x0, a0, c0], outputs=outputs) return inference_model
inference_model = sequence_inference_model(LSTM_cell, densor, n_values = 78, n_a = 64, Ty = 50)
inference_model.summary()
x_initializer = np.zeros((1, 1, 78))
a_initializer = np.zeros((1, n_a))
c_initializer = np.zeros((1, n_a))
pred = inference_model.predict([x_initializer, a_initializer, c_initializer])
這個inference model就是根據上面的訓練來的LSTM來predict的,它共用了上面訓練得來的的LSTM中的參數weights 和bias, 根據輸入的一個詞x0來預測後面來輸出哪些值,具體輸出多少個值也是根據用戶設定的Ty來決定,當然啦,咱們還可以更加精細化的管理咱們的輸出,例如如果遇到EOS,咱們直接停止輸出。咱們即使有了前面的LSTM,但是因為結構的不同,咱們還是得先去構建一個新的inference model,即重新要搭建一個decoding的結構。從decoding的結構咱們可以看出來,咱們的輸入還是有三個,即x0,a0,c0。這裡有比encoding簡單的地方就是咱們不需要再去reshape那麼的輸入了,咱們的輸入都是標準的shape,即分別是(batch_size, Tx, n_values), (batch_size, n_a), (batch_size, n_a),咱們直接輸入進去並且輸入到Lstm和densor中就可以,不需要進行一些shape方面的配置了,其次這裡有一點個encoding不一樣的,就是需要將每一個time step的輸出當做下個time step的輸入, 即上面程式碼中的x=tf.keras.Lambda(one_hot)(out)。 因為這是一個inference model,所以咱們也不需要重新fitting啦,可以直接調用它的predict方法就可以predict啦。
- 總結
對於sequence generation相關的應用呢,咱們首先要在腦海中找到這個pattern,即它是有2部分組成的,一個encoding,一個decoding;然後用encoding來訓練模型,用decoding來predict模型。對於輸入的input layer,一定要注意並且理解他們input data的shape,一定要一致性;對於一起share的變數一定要理解,例如LSTM_cell, densor 等,他們都是構成這個LSTM模型的最基本的但願,都是share的,並不是每一個time step都有獨立的entity。如果對於以上的步驟和內容都理解的話,對於sequence generation相關的應用就都可以套用上面的模式進行實現,唯一需要改動的就是一下dimension值。