Python 三程三器的那些事
- 2020 年 3 月 10 日
- 筆記
裝飾器
1、什麼是裝飾器
- 裝飾器本質是函數,用來給其他函數添加新的功能
- 特點:不修改調用方式、不修改源程式碼
2、裝飾器的作用
- 裝飾器作用:本質是函數(裝飾其他函數)就是為其他函數添加其他功能
- 裝飾器必須准尋得原則:
- 不能修改被裝飾函數的源程式碼、不能修改被裝飾函數的調用方式
- 實現裝飾器知識儲備:
- 函數即“變數”
- 高階函數
- 嵌套函數 高階函數+潛逃函數=》裝飾器
3、使用高階函數模仿裝飾器功能
1.定義:把一個函數名當做實參傳給另一個函數
2.返回值中包含函數名
3.下面使用高階函數雖然可以實現裝飾器的一些功能,但是違反了裝飾器不能改變調用方式的原則,
以前使用bar()現在將調用方式改編成了test1(bar)就是將bar的函數名當做變數傳給了test1()


#! /usr/bin/env python # -*- coding: utf-8 -*- import time def timer(func): start_time = time.time() func() print '函數執行時間為', time.time() - start_time def test(): print '開始執行test' time.sleep(3) print 'test執行結束' timer(test) ''' 開始執行test test執行結束 函數執行時間為 3.00332999229 '''
改變了調用方式
4.高階函數——不修改高階函數的調用方式增加新的功能(但是無法傳參數)
註:bar = test2(bar) 等價於:@timer重新將函數名bar賦值,將原函數bar的記憶體地址當做實參傳遞該函數test2(),再將test2()賦值給bar
import time def bar(): time.sleep(3) print("in the bar") def test2(func): print(func) return func bar = test2(bar) bar()
不改變調用方式
5.嵌套函數
嵌套函數:在一個函數中嵌套另一個函數,並在函數內部調用
def foo(): print("in the foo") def bar(): print("in the bar") bar() foo()
嵌套函數
4、能夠適應90%的業務需求
- 在裝飾器中 @timer等價於 test1=timer(test1)
- 在timer()函數中返回值是return deco
- 所以timer(test1)作用是將函數test1記憶體地址當做參數傳遞給timer()
- timer() 函數最後將運行後的函數deco記憶體地址作為返回值返回
- test1=timer(test1)作用就是將將deco函數記憶體地址賦值給test1,所以最後運行test1()就相當於運行deco()
- 所以最後調用時給test2()傳入參數就相當於給deco傳入參數
import time def timer(func): #timer(test1) func=test1 def deco(*args,**kwargs): start_time = time.time() func(*args,**kwargs) #run test1 stop_time = time.time() print("running time is %s"%(stop_time-start_time)) return deco @timer # test1=timer(test1) def test1(): time.sleep(3) print("in the test1") @timer def test2(name): print("in the test2",name) test1() test2("tom")
裝飾器1
5、對特定網頁進行身份驗證
import time user,passwd = 'aaa','123' def auth(func): def wrapper(*args,**kwargs): username = input("Username:").strip() password = input("Password:").strip() if user == username and password == passwd: print("User has passed authentication") res = func(*args,**kwargs) #這裡執行func()相當於執行調用的函數如home() return res #為了獲得home()函數返回值,可以將執行結果賦值給res然後返回print(home())結果是"from home"而不是"None"了 else: exit("Invalid username or password") return wrapper def index(): print("welcome to index page") @auth def home(): print("welcome to home page") return "from home" @auth def bbs(): print("welcome to bbs page") index() print(home()) #在這裡調用home()相當於調用wrapper() bbs()
裝飾器2
6、實現對不同網頁不同方式的身份認證
- @auth(auth_type=“local”)程式碼作用
- 在上面的程式碼中使用@auth相當於先將home函數的記憶體地址當做變數傳入auth()函數,執行結果後home()相當於wrapper()
- 而在這裡驗證的時候猶豫@auth(auth_type=”local”)中有()括弧,那麼就相當於將執行auth()函數而且是將auth_type=“local當做參數傳入到auth()函數執行
- 所以outer_wrapper函數也會執行,outer_wrapper函數的執行結果返回的就是wrapper()函數的記憶體地址
- 所以最終結果同樣是執行home()函數就相當於執行wrapper函數
- 但是有所不同的是著這個版本中我們可以在外層的auth函數中傳入新的參數幫組我們根據需求判斷
import time user,passwd = 'aaa','123' def auth(auth_type): print("auth func:",auth_type) def outer_wrapper(func): def wrapper(*args, **kwargs): print("wrapper func args:", *args, **kwargs) if auth_type == "local": username = input("Username:").strip() password = input("Password:").strip() if user == username and passwd == password: print("�33[32;1mUser has passed authentication�33[0m") res = func(*args, **kwargs) # from home print("---after authenticaion ") return res else: exit("�33[31;1mInvalid username or password�33[0m") elif auth_type == "ldap": print("搞毛線ldap,不會。。。。") return wrapper return outer_wrapper def index(): print("welcome to index page") @auth(auth_type="local") # home = wrapper() def home(): print("welcome to home page") return "from home" @auth(auth_type="ldap") def bbs(): print("welcome to bbs page") index() print(home()) #wrapper() bbs()
裝飾器3
#! /usr/bin/env python # -*- coding: utf-8 -*- import time def auth(auth_type): print("auth func:",auth_type) def outer_wrapper(func): def wrapper(*args, **kwargs): print("wrapper func args:", *args, **kwargs) print('運行前') func(*args, **kwargs) print('運行後') return wrapper return outer_wrapper @auth(auth_type="local") # home = wrapper() def home(): print("welcome to home page") return "from home" home()
三級裝飾器簡寫
7、使用閉包實現裝飾器功能
閉包概念:
- 在一個外函數中定義了一個內函數,內函數里運用了外函數的臨時變數,並且外函數的返回值是內函數的引用,這樣就構成了一個閉包
- 一般情況下,在我們認知當中,如果一個函數結束,函數的內部所有東西都會釋放掉,還給記憶體,局部變數都會消失。
- 但是閉包是一種特殊情況,如果外函數在結束的時候發現有自己的臨時變數將來會在內部函數中用到,就把這個臨時變數綁定給了內部函數,然後自己再結束。
#! /usr/bin/env python # -*- coding: utf-8 -*- import time def timer(func): #timer(test1) func=test1 def deco(*args,**kwargs): # # 函數嵌套 start_time = time.time() func(*args,**kwargs) # 跨域訪問,引用了外部變數func (func實質是函數記憶體地址) stop_time = time.time() print "running time is %s"%(stop_time-start_time) return deco # 內層函數作為外層函數返回值 def test(name): print "in the test2",name time.sleep(2) test = timer(test) # 等價於 ==》 @timer語法糖 test("tom") ''' 運行結果: in the test2 tom running time is 2.00302696228 '''
閉包實現裝飾器功能
生成器
1、什麼是生成器
- 生成器就是一個特殊的迭代器
- 一個有yield關鍵字的函數就是一個生成器
- 生成器是這樣一個函數,它記住上一次返回時在函數體中的位置。
- 對生成器函數的第二次(或第 n 次)調用跳轉至該函數中間,而上次調用的所有局部變數都保持不變。
2、定義
- 生成器,即生成一個容器。
- 在Python中,一邊循環,一邊計算的機制,稱為生成器。
- 生成器可以理解為一種數據類型,這種數據類型自動實現了迭代器協議(其他數據類型需要調用自己的內置iter()方法或__iter__()的內置函數),
- 所以,生成器就是一個可迭代對象。
3、生成器哪些場景應用
- 生成器是一個概念,我們平常寫程式碼可能用的並不多,但是python源碼大量使用
- 比如我們tornado框架就是基於 生成器+協程
- 在我們程式碼中使用舉例
- 比如我們要生成一百萬個數據,如果用生成器非常節省空間,用列表浪費大量空間
import time t1 = time.time() g = (i for i in range(100000000)) t2 = time.time() lst = [i for i in range(100000000)] t3 = time.time() print('生成器時間:',t2 - t1) # 生成器時間: 0.0 print('列表時間:',t3 - t2) # 列表時間: 5.821957349777222
4、生成器的作用
- 通過列表生成式,我們可以直接創建一個列表,但是,受到記憶體限制,列表容量肯定是有限的。
- 而且,創建一個包含100萬個元素的列表,不僅佔用很大的存儲空間,如果我們僅僅需要訪問前面幾個元素,那後面絕大多數元素佔用的空間都白白浪費了。
- 所以,如果列表元素可以按照某種演算法推算出來,那我們是否可以在循環的過程中不斷推算出後續的元素呢?
- 這樣就不必創建完整的list,從而節省大量的空間。在Python中,這種一邊循環一邊計算的機制,稱為生成器:generator。
- 要創建一個generator,有很多種方法,第一種方法很簡單,只要把一個列表生成式的[]改成(),就創建了一個generator:
print( [i*2 for i in range(10)] ) #列表生成式: [0, 2, 4, 6, 8, 10, 12, 14, 16, 18] print( (i*2 for i in range(10)) ) #生 成 器: <generator object <genexpr> at 0x005A3690>
- 我們可以直接列印出list的每一個元素,但我們怎麼列印出generator的每一個元素呢?
- 如果要一個一個列印出來,可以通過next()函數獲得generator的下一個返回值:
g = (i*2 for i in range(10)) print( g.__next__() ) # 0 print( g.__next__() ) # 2
5、生成器工作原理
- 生成器是這樣一個函數,它記住上一次返回時在函數體中的位置。
- 對生成器函數的第二次(或第 n 次)調用跳轉至該函數中間,而上次調用的所有局部變數都保持不變。
- 生成器不僅“記住”了它數據狀態;生成器還“記住”了它在流控制構造(在命令式編程中,這種構造不只是數據值)中的位置。
- 生成器是一個函數,而且函數的參數都會保留。
- 迭代到下一次的調用時,所使用的參數都是第一次所保留下的,即是說,在整個所有函數調用的參數都是第一次所調用時保留的,而不是新創建的
6、yield生成器運行機制
- 在Python中,yield就是這樣的一個生成器。
- 當你問生成器要一個數時,生成器會執行,直至出現 yield 語句,生成器把yield 的參數給你,之後生成器就不會往下繼續運行。
- 當你問他要下一個數時,他會從上次的狀態開始運行,直至出現yield語句,把參數給你,之後停下。如此反覆
- 在python中,當你定義一個函數,使用了yield關鍵字時,這個函數就是一個生成器
- 它的執行會和其他普通的函數有很多不同,函數返回的是一個對象,而不是你平常所用return語句那樣,能得到結果值。如果想取得值,那得調用next()函數
- 每當調用一次迭代器的next函數,生成器函數運行到yield之處,返回yield後面的值且在這個地方暫停,所有的狀態都會被保持住,直到下次next函數被調用,或者碰到異常循環退出。
def fib(max_num): a,b = 1,1 while a < max_num: yield b a,b=b,a+b g = fib(10) #生成一個生成器:[1,2, 3, 5, 8, 13] print(g.__next__()) #第一次調用返回:1 print(list(g)) #把剩下元素變成列表:[2, 3, 5, 8, 13]
yield實現fib數
7、yield實現單執行緒下的並發效果
- yield相當於 return 返回一個值,並且記住這個返回的位置,下次迭代時,程式碼從yield的下一條語句開始執行。
- send() 和next()一樣,都能讓生成器繼續往下走一步(下次遇到yield停),但send()能傳一個值,這個值作為yield表達式整體的結果
def consumer(name): print("%s 準備吃包子啦!" %name) while True: baozi = yield print("包子[%s]來了,被[%s]吃了!" %(baozi,name)) c = consumer("Tom") c.__next__() b1 = "韭菜餡包子" c.send(b1) # c.send(b1)作用: # c.send()的作用是給yied的傳遞一個值,並且每次調用c.send()的同時自動調用一次__next__ '''運行結果: Tom 準備吃包子啦! 包子[韭菜餡包子]來了,被[Tom]吃了! '''
一次調用
import time def consumer(name): print("%s 準備吃包子啦!" %name) while True: baozi = yield print("包子[%s]來了,被[%s]吃了!" %(baozi,name)) def producer(name): c = consumer('A') c2 = consumer('B') c.__next__() c2.__next__() print("老子開始準備做包子啦!") for i in range(10): time.sleep(1) print("做了2個包子!") c.send(i) c2.send(i) producer("alex") '''運行結果: A 準備吃包子啦! B 準備吃包子啦! 老子開始準備做包子啦! 做了2個包子! 包子[0]來了,被[A]吃了! 包子[0]來了,被[B]吃了! 做了2個包子! 包子[1]來了,被[A]吃了! 包子[1]來了,被[B]吃了! 做了2個包子! 包子[2]來了,被[A]吃了! 包子[2]來了,被[B]吃了! 做了2個包子! 包子[3]來了,被[A]吃了! 包子[3]來了,被[B]吃了! 做了2個包子! 包子[4]來了,被[A]吃了! 包子[4]來了,被[B]吃了! 做了2個包子! 包子[5]來了,被[A]吃了! 包子[5]來了,被[B]吃了! '''
for 循環調用
迭代器
1、什麼是迭代器
- 迭代器是訪問集合內元素的一種方法
- 總是從集合內第一個元素訪問,直到所有元素都被訪問過結束,當調用 __next__而元素返回會引發一個,StopIteration異常
- 有兩個方法:_iter_ _next_
- _iter_ : 返回迭代器自身
- _next_: 返回下一個元素
2、定義:
- 迭代器是訪問集合內元素的一種方式。迭代器對象從集合的第一個元素開始訪問,直到所有的元素都被訪問一遍後結束。
3、迭代器和可迭代對象
- 凡是可作用於
for循環的對象都是可迭代的(Iterable)類型; - 凡是可作用於
next()函數的對象都是迭代器(Iterator)類型,它們表示一個惰性計算的序列; - 集合數據類型如
list、dict、str等是可迭代的但不是迭代器,不過可以通過iter()函數獲得一個Iterator對象。 - Python的
for循環本質上就是通過不斷調用next()函數實現的 - 總結: 一個實現了__iter__方法的對象是可迭代的,一個實現next方法的對象是迭代器
4、迭代器的兩個方法
- 迭代器僅是一容器對象,它實現了迭代器協議。它有兩個基本方法
- __next__方法:返回容器的下一個元素
- __iter__方法:返回迭代器自身
- 迭代器是訪問集合內元素的一種方式。迭代器對象從集合的第一個元素開始訪問,直到所有的元素都被訪問一遍後結束。
- __iter__方法會返回一個迭代器(iterator),所謂的迭代器就是具有next方法的對象。
- 在調用next方法時,迭代器會返回它的下一個值,如果next方法被調用,但迭代器中沒有值可以返就會引發一個StopIteration異常
a = iter([1,2,]) #生成一個迭代器 print(a.__next__()) print(a.__next__()) print(a.__next__()) #在這一步會引發 “StopIteration” 的異常
5、判斷是迭代器和可迭代對象
註:列表,元組,字典是可迭代的但不是迭代器
from collections import Iterable print(isinstance([],Iterable)) #True print(isinstance({},Iterable)) #True print(isinstance((),Iterable)) #True print(isinstance("aaa",Iterable)) #True print(isinstance((x for x in range(10)),Iterable)) #True
相關程式碼
6、列表不是迭代器,只有生成器是迭代器
from collections import Iterator t = [1,2,3,4] print(isinstance(t,Iterator)) #False t1 = iter(t) print(isinstance(t1,Iterator)) #True
相關程式碼
7、自定義迭代器
#! /usr/bin/env python # -*- coding: utf-8 -*- class MyRange(object): def __init__(self, n): self.idx = 0 self.n = n def __iter__(self): return self def next(self): if self.idx < self.n: val = self.idx self.idx += 1 return self.n[val] else: raise StopIteration() l = [4,5,6,7,8] obj = MyRange(l) print obj.next() # 4 print obj.next() # 5 print obj.next() # 6
自定義迭代器
8、迭代器與生成器
#! /usr/bin/env python # -*- coding: utf-8 -* l = [1,2,3,4,5] # 列表是一個可迭代對象,不是一個迭代器 print dir(l) # 所以 l 中有 __iter__() 方法,沒有 __next__()方法 iter_obj = l.__iter__() # __iter__()方法返回迭代器對象本身(這個迭代器對象就會有 next 方法了) print '###################################n' print iter_obj.next() # 1 print iter_obj.next() # 2 print iter_obj.next() # 3
相關程式碼
進程與執行緒的簡介
1、什麼是進程(process)?(進程是資源集合)
2、進程是資源分配的最小單位( 記憶體、cpu、網路、io)
3、一個運行起來的程式就是一個進程
- 什麼是程式(程式是我們存儲在硬碟里的程式碼)
- 硬碟(256G)、記憶體條(8G)
- 當我們雙擊圖標,打開程式的時候,實際上就是通過I/O操作(讀寫)記憶體條裡面
- 記憶體條就是我們所指的資源
CPU分時
- CPU比你的手速快多了,分時處理每個執行緒,但是由於太快然你覺得每個執行緒都是獨佔cpu
- cpu是計算,只有時間片到了,獲取cpu,執行緒真正執行
- 當你想使用 網路、磁碟等資源的時候,需要cpu的調度
- 進程具有獨立的記憶體空間,所以沒有辦法相互通訊
進程如何通訊
- 進程queue(父子進程通訊)
- pipe(同一程式下兩個進程通訊)
- managers(同一程式下多個進程通訊)
- RabbitMQ、redis等(不同程式間通訊)
為什麼需要進程池
- 一次性開啟指定數量的進程
- 如果有十個進程,有一百個任務,一次可以處理多少個(一次性只能處理十個)
- 防止進程開啟數量過多導致伺服器壓力過大
2、定義:進程是資源分配最小單位
- 當一個可執行程式被系統執行(分配記憶體資源)就變成了一個進程
- 程式並不能單獨運行,只有將程式裝載到記憶體中,系統為它分配資源才能運行,這種執行的程式就稱之為進程
- 程式和進程的區別就在於:程式是指令的集合,它是進程運行的靜態描述文本;進程是程式的一次執行活動,屬於動態概念
- 在多道編程中,我們允許多個程式同時載入到記憶體中,在作業系統的調度下,可以實現並發地執行。
- 進程的出現讓每個用戶感覺到自己獨享CPU,因此,進程就是為了在CPU上實現多道編程而提出的。
- 進程之間有自己獨立的記憶體,各進程之間不能相互訪問
- 創建一個新執行緒很簡單,創建新進程需要對父進程進行複製
- 多道編程: 在電腦記憶體中同時存放幾道相互獨立的程式,他們共享系統資源,相互穿插運行
- 單道編程: 電腦記憶體中只允許一個的程式運行
3、進程並發性:
- 在一個系統中,同時會存在多個進程被載入到記憶體中,同處於開始到結束之間的狀態
- 對於一個單CPU系統來說,程式同時處於運行狀態只是一種宏觀上的概念
- 他們雖然都已經開始運行,但就微觀而言,任意時刻,CPU上運行的程式只有一個
- 由於作業系統分時,讓每個進程都覺得自己獨佔CPU等資源
- 註:如果是多核CPU(處理器)實際上是可以實現正在意義的同一時間點有多個執行緒同時運行
4、執行緒並發性:
- 作業系統將時間劃分為很多時間段,儘可能的均勻分配給每一個執行緒。
- 獲取到時間片的執行緒被CPU執行,其他則一直在等待,所以微觀上是走走停停,宏觀上都在運行。
- 多核CPU情況:
- 如果你的程式的執行緒數少於CPU的核心數,且系統此時沒有其他進程同時運行,那麼這個程式的每個執行緒會享有一個CPU,
- 當同時運行的執行緒數多於CPU核心數時,CPU會採用一定的調度演算法每隔一段時間就將這些執行緒調入或調出CPU
- 以確保每個執行緒都能分享一部分CPU時間,實現多執行緒並發。
- 多核CPU情況:
5、有了進程為什麼還要執行緒?
1.進程優點:
- 提供了多道編程,讓我們感覺我們每個人都擁有自己的CPU和其他資源,可以提高電腦的利用率
2. 進程的兩個重要缺點
- 進程只能在一個時間干一件事,如果想同時干兩件事或多件事,進程就無能為力了。
- 進程在執行的過程中如果阻塞,即使進程中有些工作不依賴於輸入的數據,也將無法執行(例如等待輸入,整個進程就會掛起)。
- 例如,我們在使用qq聊天, qq做為一個獨立進程如果同一時間只能幹一件事,那他如何實現在同一時刻 即能監聽鍵盤輸入、又能監聽其它人給你發的消息
- 你會說,作業系統不是有分時么?分時是指在不同進程間的分時呀
- 即作業系統處理一會你的qq任務,又切換到word文檔任務上了,每個cpu時間片分給你的qq程式時,你的qq還是只能同時干一件事呀
6、什麼是執行緒(thread)(執行緒是作業系統最小的調度單位)
- 定義:
- 執行緒是作業系統調度的最小單位
- 它被包含在進程之中,是進程中的實際運作單位
- 進程本身是無法自己執行的,要操作cpu,必須創建一個執行緒,執行緒是一系列指令的集合
- 執行緒是作業系統能夠進行運算調度的最小單位。它被包含在進程之中,是進程中的實際運作單位
- 一條執行緒指的是進程中一個單一順序的控制流,一個進程中可以並發多個執行緒,每條執行緒並行執行不同的任務
- 無論你啟多少個執行緒,你有多少個cpu, Python在執行的時候會淡定的在同一時刻只允許一個執行緒運行
- 進程本身是無法自己執行的,要操作cpu,必須創建一個執行緒,執行緒是一系列指令的集合
- 所有在同一個進程里的執行緒是共享同一塊記憶體空間的,不同進程間記憶體空間不同
- 同一個進程中的各執行緒可以相互訪問資源,執行緒可以操作同進程中的其他執行緒,但進程僅能操作子進程
- 兩個進程想通訊,必須要通過一個中間代理
- 對主執行緒的修改可能回影響其他子執行緒,對主進程修改不會影響其他進程因為進程間記憶體相互獨立,但是同一進程下的執行緒共享記憶體
7、進程和執行緒的區別
- 啟動一個執行緒比啟動一個進程快,運行速度沒有可比性。
- 先有一個進程然後才能有執行緒。
- 進程包含執行緒
- 執行緒共享記憶體空間
- 進程記憶體是獨立的(不可互相訪問)
- 進程可以生成子進程,子進程之間互相不能互相訪問(相當於在父級進程克隆兩個子進程)
- 在一個進程裡面執行緒之間可以交流。兩個進程想通訊,必須通過一個中間代理來實現
- 創建新執行緒很簡單,創建新進程需要對其父進程進行克隆。
- 一個執行緒可以控制或操作同一個進程裡面的其它執行緒。但進程只能操作子進程。
- 父進程可以修改不影響子進程,但不能修改。
- 執行緒可以幫助應用程式同時做幾件事
8、進程和程式的區別
- 程式只是一個普通文件,是一個機器程式碼指令和數據的集合,所以,程式是一個靜態的實體
- 而進程是程式運行在數據集上的動態過程,進程是一個動態實體,它應創建而產生,應調度執行因等待資 源或事件而被處於等待狀態,因完成任務而被撤消
- 進程是系統進行資源分配和調度的一個獨立單位
- 一個程式對應多個進程,一個進程為多個程式服務(兩者之間是多對多的關係)
- 一個程式執行在不同的數據集上就成為不同的進程,可以用進程式控制制塊來唯一地標識每個進程
多執行緒
Python多執行緒編程中常用方法:
- join()方法:如果一個執行緒或者在函數執行的過程中調用另一個執行緒,並且希望待其完成操作後才能執行,那麼在調用執行緒的時就可以使用被調執行緒的join方法join([timeout]) timeout:可選參數,執行緒運行的最長時間
- isAlive()方法:查看執行緒是否還在運行
- getName()方法:獲得執行緒名
- setDaemon()方法:主執行緒退出時,需要子執行緒隨主執行緒退出,則設置子執行緒的setDaemon()
GIL全局解釋器鎖:
- 在python全局解釋器下,保證同一時間只有一個執行緒運行
- 防止多個執行緒都修改數據
執行緒鎖(互斥鎖):
- GIL鎖只能保證同一時間只能有一個執行緒對某個資源操作,但當上一個執行緒還未執行完畢時可能就會釋放GIL,其他執行緒就可以操作了
- 執行緒鎖本質把執行緒中的數據加了一把互斥鎖
- mysql中共享鎖 & 互斥鎖
- mysql共享鎖:共享鎖,所有執行緒都能讀,而不能寫
- mysql排它鎖:排它,任何執行緒讀取這個這個數據的權利都沒有
- 加上執行緒鎖之後所有其他執行緒,讀都不能讀這個數據
- 有了GIL全局解釋器鎖為什麼還需要執行緒鎖
- 因為cpu是分時使用的
1、執行緒2種調用方式:直接調用, 繼承式調用
import threading import time def sayhi(num): # 定義每個執行緒要運行的函數 print("running on number:%s" % num) time.sleep(3) #1、target=sayhi :sayhi是定義的一個函數的名字 #2、args=(1,) : 括弧內寫的是函數的參數 t1 = threading.Thread(target=sayhi, args=(1,)) # 生成一個執行緒實例 t2 = threading.Thread(target=sayhi, args=(2,)) # 生成另一個執行緒實例 t1.start() # 啟動執行緒 t2.start() # 啟動另一個執行緒 print(t1.getName()) # 獲取執行緒名 print(t2.getName())
直接調用
import threading import time class MyThread(threading.Thread): def __init__(self,num): threading.Thread.__init__(self) self.num = num def run(self):#定義每個執行緒要運行的函數 print("running on number:%s" %self.num) time.sleep(3) if __name__ == '__main__': t1 = MyThread(1) t2 = MyThread(2) t1.start() t2.start()
繼承式調用
2、for循環同時啟動多個執行緒
- 說明:下面利用for循環同時啟動50個執行緒並行執行,執行時間是3秒而不是所有執行緒執行時間的總和
import threading import time def sayhi(num): #定義每個執行緒要運行的函數 print("running on number:%s" %num) time.sleep(3) for i in range(50): t = threading.Thread(target=sayhi,args=('t-%s'%i,)) t.start()
for循環啟動多個執行緒
3、t.join(): 實現所有執行緒都執行結束後再執行主執行緒
- 說明:在4中雖然可以實現50個執行緒同時並發執行,但是主執行緒不會等待子執行緒結束在這裡我們可以使用t.join()指定等待某個執行緒結束的結果
import threading import time start_time = time.time() def sayhi(num): #定義每個執行緒要運行的函數 print("running on number:%s" %num) time.sleep(3) t_objs = [] #將進程實例對象存儲在這個列表中 for i in range(50): t = threading.Thread(target=sayhi,args=('t-%s'%i,)) t.start() #啟動一個執行緒,程式不會阻塞 t_objs.append(t) print(threading.active_count()) #列印當前活躍進程數量 for t in t_objs: #利用for循環等待上面50個進程全部結束 t.join() #阻塞某個程式 print(threading.current_thread()) #列印執行這個命令進程 print("----------------all threads has finished.....") print(threading.active_count()) print('cost time:',time.time() - start_time)
t.join() 主執行緒等待子執行緒
4、setDaemon(): 守護執行緒,主執行緒退出時,需要子執行緒隨主執行緒退出
import threading import time start_time = time.time() def sayhi(num): #定義每個執行緒要運行的函數 print("running on number:%s" %num) time.sleep(3) for i in range(50): t = threading.Thread(target=sayhi,args=('t-%s'%i,)) t.setDaemon(True) #把當前執行緒變成守護執行緒,必須在t.start()前設置 t.start() #啟動一個執行緒,程式不會阻塞 print('cost time:',time.time() - start_time)
守護執行緒
- 註:因為剛剛創建的執行緒是守護執行緒,所以主執行緒結束後子執行緒就結束了,運行時間不是3秒而是0.01秒
5、GIL鎖和用戶鎖(Global Interpreter Lock 全局解釋器鎖)
- 全局解釋器鎖:保證同一時間僅有一個執行緒對資源有操作許可權
- 作用:在一個進程內,同一時刻只能有一個執行緒通過GIL鎖 被CUP調用,切換條件:I/O操作、固定時間(系統決定)
- 說明:python多執行緒中GIL鎖只是在CPU操作時(如:計算)才是串列的,其他都是並行的,所以比串列快很多
- 為了解決不同執行緒同時訪問同一資源時,數據保護問題,而產生了GIL
- GIL在解釋器的層面限制了程式在同一時間只有一個執行緒被CPU實際執行,而不管你的程式里實際開了多少條執行緒
- 為了解決這個問題,CPython自己定義了一個全局解釋器鎖,同一時間僅僅有一個執行緒可以拿到這個數據
- python之所以會產生這種不好的狀況是因為python啟用一個執行緒是調用作業系統原生執行緒,就是C介面
- 但是這僅僅是CPython這個版本的問題,在PyPy,中就沒有這種缺陷
- 用戶鎖:執行緒鎖(互斥鎖Mutex) :當前執行緒還未操作完成前其他所有執行緒都無法對其操作,即使已經釋放了GIL鎖
- 在有GIL鎖時為何還需要用戶鎖
- GIL鎖只能保證同一時間只能有一個執行緒對某個資源操作,但當上一個執行緒還未執行完畢時可能就會釋放GIL,其他執行緒就可以操作了
- 執行緒鎖的原理
- 當一個執行緒對某個資源進行CPU計算的操作時加一個執行緒鎖,只有當前執行緒計算完成主動釋放鎖,其他執行緒才能對其操作
- 這樣就可以防止還未計算完成,釋放GIL鎖後其他執行緒對這個資源操作導致混亂問題
import time import threading lock = threading.Lock() #1 生成全局鎖 def addNum(): global num #2 在每個執行緒中都獲取這個全局變數 print('--get num:',num ) time.sleep(1) lock.acquire() #3 修改數據前加鎖 num -= 1 #4 對此公共變數進行-1操作 lock.release() #5 修改後釋放
用戶鎖使用舉例
在有GIL的情況下執行 count = count + 1 會出錯原因解析,用執行緒鎖解決方法
# 1)第一步:count = 0 count初始值為0 # 2)第二步:執行緒1要執行對count加1的操作首先申請GIL全局解釋器鎖 # 3)第三步:調用作業系統原生執行緒在作業系統中執行 # 4)第四步:count加1還未執行完畢,時間到了被要求釋放GIL # 5)第五步:執行緒1釋放了GIL後執行緒2此時也要對count進行操作,此時執行緒1還未執行完,所以count還是0 # 6)第六步:執行緒2此時拿到count = 0後也要對count進行加1操作,假如執行緒2執行很快,一次就完成了 # count加1的操作,那麼count此時就從0變成了1 # 7)第七步:執行緒2執行完加1後就賦值count=1並釋放GIL # 8)第八步:執行緒2執行完後cpu又交給了執行緒1,執行緒1根據上下文繼續執行count加1操作,先拿到GIL # 鎖,完成加1操作,由於執行緒1先拿到的數據count=0,執行完加1後結果還是1 # 9)第九步:執行緒1將count=1在次賦值給count並釋放GIL鎖,此時連個執行緒都對數據加1,但是值最終是1
報錯原因分析
- 使用執行緒鎖解決上面問題的原理
- 在GIL鎖中再加一個執行緒鎖,執行緒鎖是用戶層面的鎖
- 執行緒鎖就是一個執行緒在對數據操作前加一把鎖,防止其他執行緒複製或者操作這個數據
- 只有這個執行緒對數據操作完畢後才會釋放這個鎖,其他執行緒才能操作這個數據
- 定義一個執行緒鎖非常簡單只用三步
1 >> lock = threading.Lock() #定義一把鎖 2 >> lock.acquire() #對數據操作前加鎖防止數據被另一執行緒操作 3 >> lock.release() #對數據操作完成後釋放鎖
6、死鎖
- 死鎖定義:
- 兩個以上的進程或執行緒在執行過程中,因爭奪資源而造成的一種互相等待的現象若無外力作用,它們都將無法推進去。
- 死鎖舉例:
- 啟動5個執行緒,執行run方法,假如thread1首先搶到了A鎖,此時thread1沒有釋放A鎖,緊接著執行程式碼mutexB.acquire(),搶到了B鎖,
- 在搶B鎖時候,沒有其他執行緒與thread1爭搶,因為A鎖沒有釋放,其他執行緒只能等待
- thread1執行完func1函數,然後執行func2函數,此時thread1拿到B鎖,然後執行time.sleep(2),此時不會釋放B鎖
- 在thread1執行func2的同時thread2開始執行func1獲取到了A鎖,然後繼續要獲取B鎖
- 不幸的是B鎖還被thread1佔用,thread1佔用B鎖時還需要同時獲取A鎖才能向下執行,但是此時發現A鎖已經被thread2暫用,這樣就死鎖了
from threading import Thread,Lock import time mutexA=Lock() mutexB=Lock() class MyThread(Thread): def run(self): self.func1() self.func2() def func1(self): mutexA.acquire() print('�33[41m%s 拿到A鎖�33[0m' %self.name) mutexB.acquire() print('�33[42m%s 拿到B鎖�33[0m' %self.name) mutexB.release() mutexA.release() def func2(self): mutexB.acquire() print('�33[43m%s 拿到B鎖�33[0m' %self.name) time.sleep(2) mutexA.acquire() print('�33[44m%s 拿到A鎖�33[0m' %self.name) mutexA.release() mutexB.release() if __name__ == '__main__': for i in range(2): t=MyThread() t.start() # 運行結果:輸出下面結果後程式卡死,不再向下進行了 # Thread-1 拿到A鎖 # Thread-1 拿到B鎖 # Thread-1 拿到B鎖 # Thread-2 拿到A鎖
產生死鎖程式碼
7、遞歸鎖:lock = threading.RLock() 解決死鎖問題
- 遞歸鎖的作用是同一執行緒中多次請求同一資源,但是不會參數死鎖。
- 這個RLock內部維護著一個Lock和一個counter變數,counter記錄了acquire的次數,從而使得資源可以被多次require。
- 直到一個執行緒所有的acquire都被release,其他的執行緒才能獲得資源。
from threading import Thread,Lock,RLock import time mutexA=mutexB=RLock() class MyThread(Thread): def run(self): self.f1() self.f2() def f1(self): mutexA.acquire() print('%s 拿到A鎖' %self.name) mutexB.acquire() print('%s 拿到B鎖' %self.name) mutexB.release() mutexA.release() def f2(self): mutexB.acquire() print('%s 拿到B鎖' % self.name) time.sleep(0.1) mutexA.acquire() print('%s 拿到A鎖' % self.name) mutexA.release() mutexB.release() if __name__ == '__main__': for i in range(5): t=MyThread() t.start() # 下面是運行結果:不會產生死鎖 # Thread-1 拿到A鎖 # Thread-1 拿到B鎖 # Thread-1 拿到B鎖 # Thread-1 拿到A鎖 # Thread-2 拿到A鎖 # Thread-2 拿到B鎖 # Thread-2 拿到B鎖 # Thread-2 拿到A鎖 # Thread-4 拿到A鎖 # Thread-4 拿到B鎖 # Thread-4 拿到B鎖 # Thread-4 拿到A鎖 # Thread-3 拿到A鎖 # Thread-3 拿到B鎖 # Thread-3 拿到B鎖 # Thread-3 拿到A鎖 # Thread-5 拿到A鎖 # Thread-5 拿到B鎖 # Thread-5 拿到B鎖 # Thread-5 拿到A鎖
如果使用RLock代替Lock,則不會發生死鎖
8、Semaphore(訊號量)
- 互斥鎖 同時只允許一個執行緒更改數據,而Semaphore是同時允許一定數量的執行緒更改數據
- 比如廁所有3個坑,那最多只允許3個人上廁所,後面的人只能等裡面有人出來了才能再進去
- 作用就是同一時刻允許運行的執行緒數量
# import threading,time # def run(n): # semaphore.acquire() # time.sleep(1) # print("run the thread: %sn" %n) # semaphore.release() # # if __name__ == '__main__': # semaphore = threading.BoundedSemaphore(5) #最多允許5個執行緒同時運行 # for i in range(22): # t = threading.Thread(target=run,args=(i,)) # t.start() # # while threading.active_count() != 1: # pass #print threading.active_count() # else: # print('----all threads done---') # 程式碼結果說明:這裡可以清晰看到運行時0-4是同時運行的沒有順序,而且是前五個, # 表示再semaphore這個訊號量的定義下程式同時僅能執行5個執行緒
訊號量舉例
9、events總共就只有四個方法
1. event.set() : # 設置標誌位 2. event.clear() : # 清除標誌位 3. event.wait() : # 等待標誌被設定 4. event.is_set() : # 判斷標誌位是否被設定
import time,threading event = threading.Event() #第一:寫一個紅綠燈的死循環 def lighter(): count = 0 event.set() #1先設置為綠燈 while True: if count > 5 and count <10: #2改成紅燈 event.clear() #3把標誌位清了 print("red light is on.....") elif count > 10: event.set() #4再設置標誌位,變綠燈 count = 0 else: print("green light is on.....") time.sleep(1) count += 1 #第二:寫一個車的死循環 def car(name): while True: if event.is_set(): #設置了標誌位代表綠燈 print("[%s] is running"%name) time.sleep(1) else: print('[%s] sees red light, waiting......'%name) event.wait() print('[%s] green light is on,start going.....'%name) light = threading.Thread(target=lighter,) light.start() car1 = threading.Thread(target=car,args=("Tesla",)) car1.start()
events(紅綠燈例子)
進程
- 多執行緒和多進程各自應用場景
- I/O操作不佔用CPU(從硬碟,網路讀入數據等)
- 計算佔用CPU,這種情況最好不用多執行緒
- python多執行緒不適合CPU密集型的任務,適合I/O密集型的任務
- python的多進程適合CPU密集型任務
- 一次性起多個進程,並在進程中調用執行緒
import multiprocessing,time,threading #3 被多執行緒調用的函數 def thread_run(): print(threading.get_ident()) #列印執行緒id號 time.sleep(2) #2 被多進程調用的函數,以及在這個函數中起一個進程 def run(name): time.sleep(2) print("hello",name) t = threading.Thread(target=thread_run,) #在進程調用的函數中啟用一個執行緒 t.start() #1 一次性啟動多個進程 if __name__ == '__main__': for i in range(10): p = multiprocessing.Process(target=run,args=('bob %s'%i,)) #啟用一個多執行緒 p.start()
一次性起多個進程,並在進程中調用執行緒
- 進程間互相訪問數據的三種方法
- 注:不同進程間記憶體是不共享的,所以互相之間不能訪問對方數據
- 在父進程中定義隊列q,使用父進程啟用一個子進程,子進程中無法操作父進程的q
from multiprocessing import Process import queue import threading def f(): q.put([42, None, 'hello']) if __name__ == '__main__': q = queue.Queue() #1 在父進程中定義一個隊列實例q # p = threading.Thread(target=f,) #在執行緒程中就可以相互訪問,執行緒中記憶體共享 p = Process(target=f,) #2 在父進程中起一個子進程 p,在子進程中使用父進程的q會報錯 p.start() print(q.get()) p.join()
子進程無法訪問父進程數據舉例
- 利用Queues實現父進程到子進程(或子進程間)的數據傳遞
-
- 我們以前學的queue是執行緒queue.Queue()只有在同一個進程的執行緒間才能訪問
- 如果兩個進程間想要通訊必須要使用進程Queue,用法和多執行緒的相同
- queue.Queue()是執行緒q不可以傳遞給子進程,但是Queue是進程q,父進程會將進程q克隆了一份給子進程
- 既然是兩個q為什麼在子進程中在q中放入一個數據在父進程中可以取出來呢? 其實原因是這樣的:
- 子進程向q中放入數據的時候,用pickle序列化將數據放到一個中間地方(翻譯),翻譯又把子進程放
- 入的數據用pickle反序列化給父進程,父進程就可以訪問這個q了,這樣就實現了進程間的數據通訊了
- 在多執行緒中兩個執行緒可以修改同一份數據,而Queue僅僅實現了進程間的數據傳遞
from multiprocessing import Process, Queue def f(qq): # 將符進程中的q傳遞過來叫qq qq.put([42, None, 'hello']) # 此時子進程就可以使用符進程中的q if __name__ == '__main__': q = Queue() # 使用Queue()在父進程中定義一個隊列實例q p = Process(target=f, args=(q,)) # 在父進程中起一個子進程 p,將父進程剛定義的q傳遞給子進程p p.start() print(q.get()) p.join() # 運行結果: [42, None, 'hello']
Queues實現父子進程間傳遞數據
- 使用管道pipe實現兩個進程間數據傳遞
- 說明:其實pip實現進程間通訊就好像一條電話線一樣,一個在電話線這頭髮送,一個在電話線那頭接收
from multiprocessing import Process, Pipe def f(conn): conn.send([42, None, 'hello']) # 3 子進程發送數據,就像socket一樣 print("son process recv:", conn.recv()) conn.close() if __name__ == '__main__': parent_conn, child_conn = Pipe() # 1 生成一個管道實例,實例一生成就會生成兩個返回對象,一個是管道這頭,一個是管道那頭 p = Process(target=f, args=(child_conn,)) # 2 啟動一個子進程將管道其中一頭傳遞給子進程 p.start() print(parent_conn.recv()) # 4 父進程收消息 # prints "[42, None, 'hello']" parent_conn.send('i am parent process') p.join() # 運行結果: # [42, None, 'hello'] # son process recv: i am parent process
pip實現進程間通訊
- Managers實現很多進程間數據共享
-
- 說明:manager實質和Queue一樣,啟用是個執行緒其實就是將字典或者列表copy十份
from multiprocessing import Process, Manager import os def f(d, l): d[1] = '1' # 是個進程對字典放入的是同一個值,所以看上去效果不明顯 l.append(os.getpid()) # 將這是個進程的進程id放入列表中 if __name__ == '__main__': with Manager() as manager: # 1 將Manager()賦值給manager d = manager.dict() # 2 定義一個可以在多個進程間可以共享的字典 l = manager.list(range(5)) # 3 定義一個可以在多個進程間可以共享的列表,默認寫五個數據 p_list = [] for i in range(10): # 生成是個進程 p = Process(target=f, args=(d, l)) # 將剛剛生成的可共享字典和列表傳遞給子進程 p.start() p_list.append(p) for res in p_list: res.join() print(d) print(l)
managers實現進程間數據共享
- 進程之間需要鎖的原因
- 說明:雖然每個進程是獨立運行的,但是他們共享同一塊螢幕,如果大家都在螢幕打數據就會打亂了
from multiprocessing import Process, Lock def f(l, i): l.acquire() #一個進程要列印數據時先鎖定 print('hello world', i) l.release() #列印完畢後就釋放這把鎖 if __name__ == '__main__': lock = Lock() #先生成一把鎖 for num in range(5): Process(target=f, args=(lock, num)).start() # 運行結果: # hello world 4 # hello world 0 # hello world 2 # hello world 3 # hello world 1
進程鎖
- 進程池
- 進程池的作用就是限制同一時間可以啟動進程的=數量
- 進程池內部維護一個進程式列,當使用時,則去進程池中獲取一個進程,如果進程池序列中沒有可供使用的進那麼程式就會等待,直到進程池中有可用進程為止。
- 進程池中有兩個方法:
- apply: 多個進程非同步執行,一個一個的執行
- apply_async: 多個進程同步執行,同時執行多個進程
from multiprocessing import Process,Pool import time,os def foo(i): time.sleep(2) print("in the process",os.getpid()) #列印子進程的pid return i+100 def call(arg): print('-->exec done:',arg,os.getpid()) if __name__ == '__main__': pool = Pool(3) #進程池最多允許5個進程放入進程池 print("主進程pid:",os.getpid()) #列印父進程的pid for i in range(10): #用法1 callback作用是指定只有當Foo運行結束後就執行callback調用的函數,父進程調用的callback函數 pool.apply_async(func=foo, args=(i,),callback=call) #用法2 串列 啟動進程不在用Process而是直接用pool.apply() # pool.apply(func=foo, args=(i,)) print('end') pool.close() #關閉pool pool.join() #進程池中進程執行完畢後再關閉,如果注釋,那麼程式直接關閉。
進程池
殭屍進程
- 殭屍進程定義
- 殭屍進程產生的原因就是父進程產生子進程後,子進程先於父進程退出
- 但是父進程由於種種原因,並沒有處理子進程發送的退出訊號,那麼這個子進程就會成為殭屍進程。
- 用python寫一個殭屍進程
#!/usr/bin/env python #coding=utf8 import os, sys, time #產生子進程 pid = os.fork() if pid == 0: #子進程退出 sys.exit(0) #父進程休息30秒 time.sleep(30) # 先產生一個子進程,子進程退出,父進程休息30秒,那就會產生一個殭屍進程
defunct.py
[root@linux-node4 ~]# ps -ef| grep defunct root 110401 96083 0 19:11 pts/2 00:00:00 python defunct.py root 110402 110401 0 19:11 pts/2 00:00:00 [python] <defunct> root 110406 96105 0 19:11 pts/3 00:00:00 grep --color=auto defunct
ps -ef| grep defunct 在linux下查看殭屍進程
協程(Coroutine)
1、什麼是協程(進入上一次調用的狀態)
- 協程,又稱微執行緒,纖程,協程是一種用戶態的輕量級執行緒。
- 執行緒的切換會保存到CPU的棧里,協程擁有自己的暫存器上下文和棧,
- 協程調度切換時,將暫存器上下文和棧保存到其他地方,在切回來的時候,恢復先前保存的暫存器上下文和棧
- 協程能保留上一次調用時的狀態(即所有局部狀態的一個特定組合),每次過程重入時,就相當於進入上一次調用的狀態
- 協程最主要的作用是在單執行緒的條件下實現並發的效果,但實際上還是串列的(像yield一樣)
2、協程的好處
- 無需執行緒上下文切換的開銷(可以理解為協程切換就是在不同函數間切換,不用像執行緒那樣切換上下文CPU)
- 不需要多執行緒的鎖機制,因為只有一個執行緒,也不存在同時寫變數衝突
- 用法:最簡單的方法是多進程+協程,既充分利用多核,又充分發揮協程的高效率,可獲得極高的性能。
3、協程缺點
- 無法利用多核資源:協程的本質是個單執行緒,它不能同時將 單個CPU 的多個核用上,協程需要和進程配合才能運行在多CPU上
- 執行緒阻塞(Blocking)操作(如IO時)會阻塞掉整個程式
4、使用yield實現協程相同效果
import time import queue def consumer(name): print("--->starting eating baozi...") while True: new_baozi = yield # 只要遇到yield程式就返回,yield還可以接收數據 print("[%s] is eating baozi %s" % (name, new_baozi)) time.sleep(1) def producer(): r = con.__next__() # 直接調用消費者的__next__方法 r = con2.__next__() # 函數裡面有yield第一次加括弧調用會變成一個生成器函數不執行,運行next才執行 n = 0 while n < 5: n += 1 con.send(n) # send恢復生成器同時並傳遞一個值給yield con2.send(n) print("�33[32;1m[producer]�33[0m is making baozi %s" % n) if __name__ == '__main__': con = consumer("c1") con2 = consumer("c2") p = producer()
yield模擬實現協程效果
5、協程為何能處理大並發1:Greenlet遇到I/O手動切換
- 協程之所以快是因為遇到I/O操作就切換(最後只有CPU運算)
- 這裡先演示用greenlet實現手動的對各個協程之間切換
- 其實Gevent模組僅僅是對greenlet的再封裝,將I/O間的手動切換變成自動切換
from greenlet import greenlet def test1(): print(12) #4 gr1會調用test1()先列印12 gr2.switch() #5 然後gr2.switch()就會切換到gr2這個協程 print(34) #8 由於在test2()切換到了gr1,所以gr1又從上次停止的位置開始執行 gr2.switch() #9 在這裡又切換到gr2,會再次切換到test2()中執行 def test2(): print(56) #6 啟動gr2後會調用test2()列印56 gr1.switch() #7 然後又切換到gr1 print(78) #10 切換到gr2後會接著上次執行,列印78 gr1 = greenlet(test1) #1 啟動一個協程gr1 gr2 = greenlet(test2) #2 啟動第二個協程gr2 gr1.switch() #3 首先gr1.switch() 就會去執行gr1這個協程
Greenlet遇到I/O手動切換
6、協程為何能處理大並發2:Gevent遇到I/O自動切換
- Gevent 是一個第三方庫,可以輕鬆通過gevent實現並發同步或非同步編程
- 在gevent中用到的主要模式是Greenlet, 它是以C擴展模組形式接入Python的輕量級協程
- Greenlet全部運行在主程式作業系統進程的內部,但它們被協作式地調度。
- Gevent原理是只要遇到I/O操作就會自動切換到下一個協程
7、Gevent實現簡單的自動切換小例子
- 註:在Gevent模仿I/O切換的時候,只要遇到I/O就會切換,哪怕gevent.sleep(0)也要切換一次
import gevent def func1(): print('�33[31;1m第一次列印�33[0m') gevent.sleep(2) # 為什麼用gevent.sleep()而不是time.sleep()因為是為了模仿I/O print('�33[31;1m第六次列印�33[0m') def func2(): print('�33[32;1m第二次列印�33[0m') gevent.sleep(1) print('�33[32;1m第四次列印�33[0m') def func3(): print('�33[32;1m第三次列印�33[0m') gevent.sleep(1) print('�33[32;1m第五次列印�33[0m') gevent.joinall([ # 將要啟動的多個協程放到event.joinall的列表中,即可實現自動切換 gevent.spawn(func1), # gevent.spawn(func1)啟動這個協程 gevent.spawn(func2), gevent.spawn(func3), ]) # 運行結果: # 第一次列印 # 第二次列印 # 第三次列印 # 第四次列印 # 第五次列印 # 第六次列印
Gevent實現簡單的自動切換小例子
8、使用Gevent實現並發下載網頁與串列下載網頁時間比較
from urllib import request import gevent,time from gevent import monkey monkey.patch_all() #把當前程式所有的I/O操作給我單獨做上標記 def f(url): print('GET: %s' % url) resp = request.urlopen(url) data = resp.read() print('%d bytes received from %s.' % (len(data), url)) #1 並發執行部分 time_binxing = time.time() gevent.joinall([ gevent.spawn(f, 'https://www.python.org/'), gevent.spawn(f, 'https://www.yahoo.com/'), gevent.spawn(f, 'https://github.com/'), ]) print("並行時間:",time.time()-time_binxing) #2 串列部分 time_chuanxing = time.time() urls = [ 'https://www.python.org/', 'https://www.yahoo.com/', 'https://github.com/', ] for url in urls: f(url) print("串列時間:",time.time()-time_chuanxing) # 註:為什麼要在文件開通使用monkey.patch_all() # 1. 因為有很多模組在使用I / O操作時Gevent是無法捕獲的,所以為了使Gevent能夠識別出程式中的I / O操作。 # 2. 就必須使用Gevent模組的monkey模組,把當前程式所有的I / O操作給我單獨做上標記 # 3.使用monkey做標記僅用兩步即可: 第一步(導入monkey模組): from gevent import monkey 第二步(聲明做標記) : monkey.patch_all()
並行串列時間比較
- 說明:monkey.patch_all()猴子修補程式作用
-
- 用過gevent就會知道,會在最開頭的地方gevent.monkey.patch_all();
- 作用是把標準庫中的thread/socket等給替換掉.這樣我們在後面使用socket的時候可以跟平常一樣使用,無需修改任何程式碼,但是它變成非阻塞的了.
9、通過gevent自己實現單執行緒下的多socket並發
import gevent from gevent import socket,monkey #下面使用的socket是Gevent的socket,實際測試monkey沒用 # monkey.patch_all() def server(port): s = socket.socket() s.bind(('0.0.0.0',port)) s.listen(5) while True: cli,addr = s.accept() gevent.spawn(handle_request,cli) def handle_request(conn): try: while True: data = conn.recv(1024) print('recv:',data) conn.send(data) if not data: conn.shutdown(socket.SHUT_WR) except Exception as e: print(e) finally: conn.close() if __name__=='__main__': server(8001)
server端
import socket HOST = 'localhost' # The remote host PORT = 8001 # The same port as used by the server s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((HOST, PORT)) while True: msg = bytes(input(">>:"),encoding="utf8").strip() if len(msg) == 0:continue s.sendall(msg) data = s.recv(1024) print('Received', repr(data)) s.close()
client端
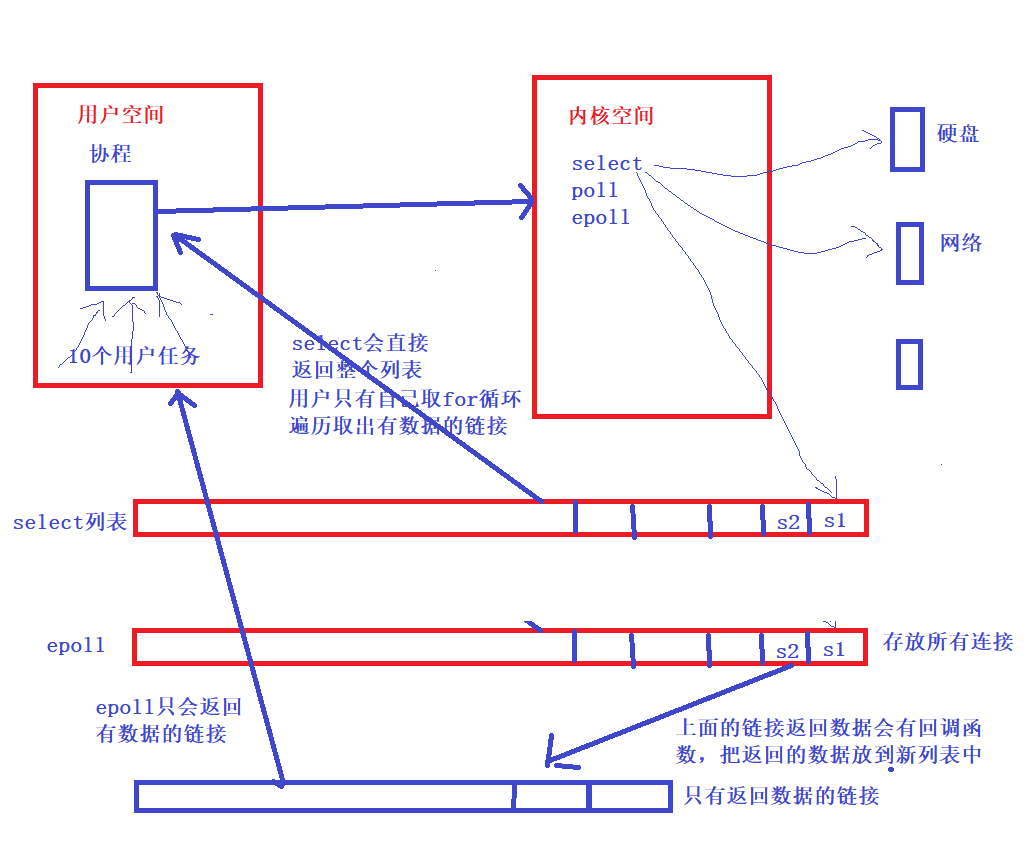
10、協程本質原理
- 協程1通過os去讀一個file,這個時候就是一個io操作,在調用os的介面前,就會有一個列表
- 協程1的這個操作就會被註冊到這個列表中,然後就切換到其他協程去處理;
- 等待os拿到要讀file後,也會把這個文件句柄放在這個列表中
- 然後等待在切換到協程1的時候,協程1就可以直接從列表中拿到數據,這樣就可以實現不阻塞了
- epoll返回給協程的任務列表在內核態,協程在用戶態,用戶態協程是不能直接訪問內核態的任務列表的,所以需要拷貝整個內核態的任務列表到用戶態,供協程去訪問和查詢
11、epoll處理 I/O 請求原理
- epoll() 中內核則維護一個鏈表,epoll_wait 直接檢查鏈表是不是空就知道是否有文件描述符準備好了。
- 在內核實現中 epoll 是根據每個 sockfd 上面的與設備驅動程式建立起來的回調函數實現的。
- 某個 sockfd 上的事件發生時,與它對應的回調函數就會被調用,來把這個 sockfd 加入鏈表,其他處於“空閑的”狀態的則不會。
- epoll上面鏈表中獲取文件描述,這裡使用記憶體映射(mmap)技術, 避免了複製大量文件描述符帶來的開銷
- 記憶體映射(mmap):記憶體映射文件,是由一個文件到一塊記憶體的映射,將不必再對文件執行I/O操作
12、select處理協程
- 拷貝所有的文件描述符給協程,不論這些任務的是否就緒,都會被返回
- 那麼協程就只能for循環去查找自己的文件描述符,也就是任務列表,select的兼容性非常好,支援linux和windows
13、select、epool、pool
- I/O的實質是什麼?
- I/O的實質是將硬碟中的數據,或收到的數據實現從內核態 copy到 用戶態的過程
- 本文討論的背景是Linux環境下的network IO。
- 比如微信讀取本地硬碟的過程
- 微信進程會發送一個讀取硬碟的請求—-》作業系統
- 只有內核才能夠讀取硬碟中的數據—》數據返回給微信程式(看上去就好像是微信直接讀取)
- 用戶態 & 內核態
- 系統空間分為兩個部分,一部分是內核態,一部分是用戶態的部分
- 內核態:內核態的空間資源只有作業系統能夠訪問
- 用戶態:我們寫的普通程式使用的空間

- select
- 只能處理1024個連接(每一個請求都可以理解為一個連接)
- 不能告訴用戶程式,哪一個連接是活躍的
- pool
- 只是取消了最大1024個活躍的限制
- 不能告訴用戶程式,哪一個連接是活躍的
- epool
- 不僅取消了1024這個最大連接限制
- 而且能告訴用戶程式哪一個是活躍的
Python進程池和執行緒池(ThreadPoolExecutor&ProcessPoolExecutor)
- 簡介 參考官網
- Python標準庫為我們提供了threading和multiprocessing模組編寫相應的多執行緒/多進程程式碼
- 但是當項目達到一定的規模,頻繁創建/銷毀進程或者執行緒是非常消耗資源的,這個時候我們就要編寫自己的執行緒池/進程池,以空間換時間。
- 但從Python3.2開始,標準庫為我們提供了concurrent.futures模組,它提供了ThreadPoolExecutor和ProcessPoolExecutor兩個類,
- 實現了對threading和multiprocessing的進一步抽象,對編寫執行緒池/進程池提供了直接的支援。
- Executor和Future
1. Executor
-
- concurrent.futures模組的基礎是Exectuor,Executor是一個抽象類,它不能被直接使用。
- 但是它提供的兩個子類ThreadPoolExecutor和ProcessPoolExecutor卻是非常有用
- 我們可以將相應的tasks直接放入執行緒池/進程池,不需要維護Queue來操心死鎖的問題,執行緒池/進程池會自動幫我們調度。
2. Future
-
- Future你可以把它理解為一個在未來完成的操作,這是非同步編程的基礎,
- 傳統編程模式下比如我們操作queue.get的時候,在等待返回結果之前會產生阻塞,cpu不能讓出來做其他事情,
- 而Future的引入幫助我們在等待的這段時間可以完成其他的操作。
- ThreadPoolExecutor(執行緒池)
from concurrent.futures import ThreadPoolExecutor import time def return_future_result(message): time.sleep(2) return message pool = ThreadPoolExecutor(max_workers=2) # 創建一個最大可容納2個task的執行緒池 future1 = pool.submit(return_future_result, ("hello")) # 往執行緒池裡面加入一個task future2 = pool.submit(return_future_result, ("world")) # 往執行緒池裡面加入一個task print(future1.done()) # 判斷task1是否結束 time.sleep(3) print(future2.done()) # 判斷task2是否結束 print(future1.result()) # 查看task1返回的結果 print(future2.result()) # 查看task2返回的結果 # 運行結果: # False # 這個False與下面的True會等待3秒 # True # 後面三個輸出都是一起打出來的 # hello # world
使用submit來操作執行緒池/進程池
import concurrent.futures import urllib.request URLS = ['http://httpbin.org', 'http://example.com/', 'https://api.github.com/'] def load_url(url, timeout): with urllib.request.urlopen(url, timeout=timeout) as conn: return conn.read() # We can use a with statement to ensure threads are cleaned up promptly with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor: # Start the load operations and mark each future with its URL # future_to_url = {executor.submit(load_url, url, 60): url for url in URLS} # 這一句相當於下面for循環獲取的字典 future_to_url = {} for url in URLS: future_to_url[executor.submit(load_url,url,60)] = url # {'future對象':'url'} future對象作為key,url作為value for future in concurrent.futures.as_completed(future_to_url): # as_completed返回已經有返回結果的future對象 url = future_to_url[future] # 通過future對象獲取對應的url try: data = future.result() # 獲取future對象的返回結果 except Exception as exc: print('%r generated an exception: %s' % (url, exc)) else: print('%r page is %d bytes' % (url, len(data)))
使用for循環使用執行緒池,並將future對象加入字典中
from concurrent.futures import ThreadPoolExecutor # 創建執行緒池 executor = ThreadPoolExecutor(10) def test_function(num1,num2): return "%s + %s = %s"%(num1,num2,num1+num2) result_iterators = executor.map(test_function,[1,2,3],[5,6,7]) for result in result_iterators: print(result) # 1 + 5 = 6 # 2 + 6 = 8 # 3 + 7 = 10
最簡單map舉例
import concurrent.futures import urllib.request URLS = ['http://httpbin.org', 'http://example.com/', 'https://api.github.com/'] def load_url(url): with urllib.request.urlopen(url, timeout=60) as conn: return conn.read() # We can use a with statement to ensure threads are cleaned up promptly with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor: future_dic = {} for url, data in zip(URLS, executor.map(load_url, URLS)): print('%r page is %d bytes' % (url, len(data))) future_dic[url] = data # {'url':'執行結果'} url作為key,執行結果作為value # 'http://httpbin.org' page is 13011 bytes # 'http://example.com/' page is 1270 bytes # 'https://api.github.com/' page is 2039 bytes
使用map同時獲取多個頁面中的數據
使用執行緒池、進程池、協程向多個url並發獲取頁面數據比較
- 特點:
-
- 進程:啟用進程非常浪費資源
- 執行緒:執行緒多,並且在阻塞過程中無法執行其他任務
- 協程:gevent只用起一個執行緒,當請求發出去後gevent就不管,永遠就只有一個執行緒工作,誰先回來先處理
- 使用for循環串列拿取頁面數據(第四:性能最差)
import requests url_list = [ 'https://www.baidu.com', 'http://dig.chouti.com/', ] for url in url_list: result = requests.get(url) print(result.text)
使用for循環串列拿取頁面數據(效果最差)
- 進程池實現並發(第三)
- 缺點:啟用進程非常浪費資源
import requests from concurrent.futures import ProcessPoolExecutor def fetch_request(url): result = requests.get(url) print(result.text) url_list = [ 'https://www.baidu.com', 'https://www.google.com/', #google頁面會卡住,知道頁面超時後這個進程才結束 'http://dig.chouti.com/', #chouti頁面內容會直接返回,不會等待Google頁面的返回 ] if __name__ == '__main__': pool = ProcessPoolExecutor(10) # 創建執行緒池 for url in url_list: pool.submit(fetch_request,url) # 去執行緒池中獲取一個進程,進程去執行fetch_request方法 pool.shutdown(False)
使用進程池實現並發
- 執行緒池實現並發(第二)
- 缺點: 創建一個新執行緒將消耗大量的計算資源,並且在阻塞過程中無法執行其他任務。
- 例: 比如執行緒池中10個執行緒同時去10個url獲取數據,當數據還沒來時這些執行緒全部都在等待,不做事。
import requests from concurrent.futures import ThreadPoolExecutor def fetch_request(url): result = requests.get(url) print(result.text) url_list = [ 'https://www.baidu.com', 'https://www.google.com/', #google頁面會卡住,知道頁面超時後這個進程才結束 'http://dig.chouti.com/', #chouti頁面內容會直接返回,不會等待Google頁面的返回 ] pool = ThreadPoolExecutor(10) # 創建一個執行緒池,最多開10個執行緒 for url in url_list: pool.submit(fetch_request,url) # 去執行緒池中獲取一個執行緒,執行緒去執行fetch_request方法 pool.shutdown(True) # 主執行緒自己關閉,讓子執行緒自己拿任務執行
使用執行緒池實現並發
from concurrent.futures import ThreadPoolExecutor import requests def fetch_async(url): response = requests.get(url) return response.text def callback(future): print(future.result()) url_list = ['http://www.github.com', 'http://www.bing.com'] pool = ThreadPoolExecutor(5) for url in url_list: v = pool.submit(fetch_async, url) v.add_done_callback(callback) pool.shutdown(wait=True)
多執行緒+回調函數執行
- 協程:微執行緒實現非同步(第一:性能最好)
- 特點 :gevent只用起一個執行緒,當請求發出去後gevent就不管,永遠就只有一個執行緒工作,誰先回來先處理
import gevent import requests from gevent import monkey monkey.patch_all() # 這些請求誰先回來就先處理誰 def fetch_async(method, url, req_kwargs): response = requests.request(method=method, url=url, **req_kwargs) print(response.url, response.content) # ##### 發送請求 ##### gevent.joinall([ gevent.spawn(fetch_async, method='get', url='https://www.python.org/', req_kwargs={}), gevent.spawn(fetch_async, method='get', url='https://www.google.com/', req_kwargs={}), gevent.spawn(fetch_async, method='get', url='https://github.com/', req_kwargs={}), ])
協程:微執行緒實現非同步


