高性能MySQL之鎖詳解
- 2020 年 3 月 7 日
- 筆記
一、背景
MySQL裡面的鎖大致可以分成全局鎖、表級鎖和行鎖三類。資料庫鎖的設計的初衷是處理並發問題。我們知道多用戶共享資源的時候,就有可能會出現並發訪問的時候,資料庫就需要合理的控制資源的訪問規則,因此,鎖就應運而生了,它主要用來實現這些訪問規則的重要數據結構。
二、全局鎖
顧名思義,全局鎖就是對整個資料庫實例加鎖,可以通過命令 Flush tables with read lock (FTWRL)對整個資料庫實例子加鎖。讓整個庫處於只讀狀態的時候,可以使用這個命令,之後其他執行緒的以下語句會被阻塞:數據更新語句(數據的增刪改)、數據定義語句(包括建表、修改表結構等)和更新類事務的提交語句。
全局鎖有一個經典的使用場景就是做全庫邏輯備份,也就是說吧整個資料庫的每個表都用select 出來存成文本。以前有一種做法是通過FTWRL確保不會有其他執行緒對資料庫做更新,然後對整個庫做備份。注意,在備份過程中整個庫完全處於只讀狀態。
你此時是不是覺得很危險?
如果你在主庫上備份,那麼在備份期間都不能執行更新,業務基本上就得停擺;
如果你在從庫上備份,那麼備份期間從庫不能執行主庫同步過來的binlog,會導致主從延遲。
看上去確實很危險,但是我們細想一下,備份為什麼要加鎖呢?如果我們不加鎖又會出現什麼問題呢?
假設你現在要維護京東的購買系統,關注的是用戶賬戶餘額表和用戶商品表。
現在發起一個邏輯備份。假設備份期間,有一個用戶,他購買了一件商品,業務邏輯里就要扣掉他的餘額,然後往已購商品裡面加上一件商品。
如果時間順序上是先備份賬戶餘額表(u_account),然後用戶購買,然後備份用戶商品表(u_course),會怎麼樣呢?你可以看一下這個圖:
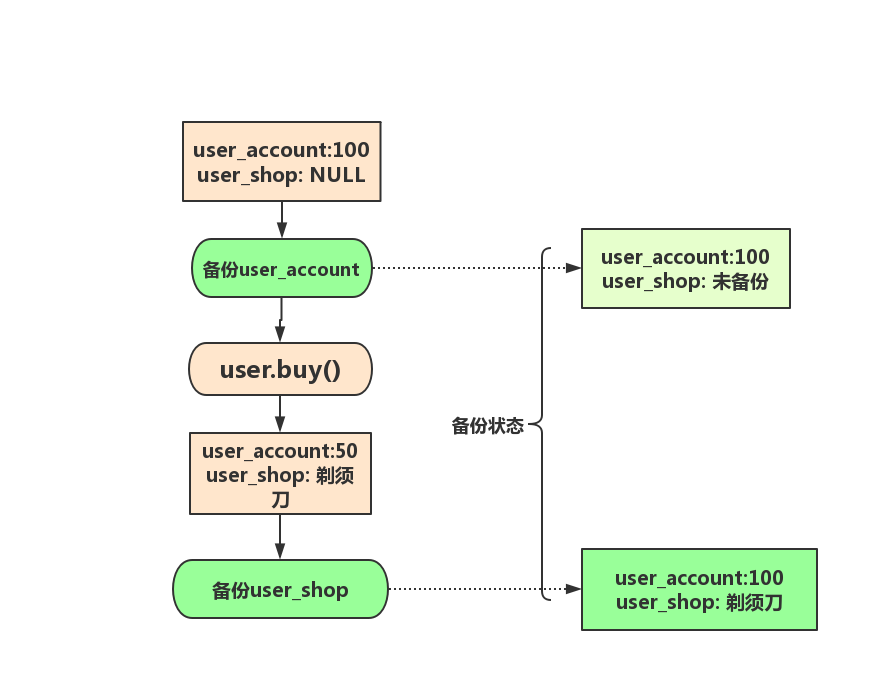
從上圖可以看到用戶的數據狀態是“賬戶餘額沒扣,但是用戶商品裡面已經多了一件商品”。如果後面用這個備份來恢複數據的話,用戶居然發現自己自己賬戶居然無端端的多了50塊,站在公司角度,你收拾包袱走人吧。但是用戶也別高興,如果備份表的順序反過來,先備份用戶商品表再備份賬戶餘額表,又可能會出現什麼結果呢?
那當然是後面用這個備份來恢複數據的話,用戶居然發現自己賬戶的錢被扣了,但是卻沒有買到剃鬚刀。也就是說,不加鎖的話,備份系統備份的得到的庫不是一個邏輯時間點,這個視圖是邏輯不一致的。這是時候你肯定想道我前面文章所講的講事務隔離,其實是有一個方法能夠拿到一致性視圖的。
是的,毫無疑問 就是在可重複讀隔離界別下開啟一個事務能夠拿到一致性視圖。
官方自帶的邏輯備份工具是mysqldump。當mysqldump使用參數–single-transaction的時候,導數據之前就會啟動一個事務,來確保拿到一致性視圖。而由於MVCC的支援,這個過程中數據是可以正常更新的。
既然有那麼好用的功能,為什麼還需要FTWRL去做備份呢?
一致性讀是好,但是不要忘記一點,前提就是引擎要支援這個隔離級別。比如,對於MyISAM這種不支援事務的引擎,如果備份過程中有更新,總是只能取到最新的數據,那麼就破壞了備份的一致性。這時候FTWRL命令了就派上用場了。
因此,single-transaction方法只可以用於所有的表使用事務引擎的庫。如果有的表使用了不支援事務的引擎,那麼備份就只能通過FTWRL方法。這就是為什麼InnoDB比myISAM普及的原因之一。
到這裡,你也許會會想到,為什麼我們不用set global readonly=true 的命令讓全庫處於只讀的狀態呢?
注意,這是生產上嚴厲禁止的,主要有如下兩個原因:
1.在某些系統中,readonly的值會被用來做其他邏輯,比如用來判斷一個庫是主庫還是備庫。毫無疑問修改global變數的方式影響面更大。
2.在異常處理機制上存在差異。如果執行FTWRL命令之後由於客戶端發生異常斷開,那麼MySQL會自動釋放這個全局鎖,整個庫回到可以正常更新的狀態。而將整個庫設置為readonly之後,如果客戶端發生異常,則資料庫就會一直保持readonly狀態,這樣會導致整個庫長時間處於不可寫狀態,很容易造成生產事故。
三、表級別的鎖
MySQL裡面表級別的鎖有兩種:一種是表鎖,一種是元數據鎖(meta data lock,MDL)。
表鎖的語法是 lock tables … read/write。與FTWRL類似,可以用unlock tables主動釋放鎖,也可以在客戶端斷開的時候自動釋放。需要注意,lock tables語法除了會限制別的執行緒的讀寫外,也限定了本執行緒接下來的操作對象。舉個例子, 如果在某個執行緒A中執行lock tables t1 read, t2 write; 這個語句,則其他執行緒寫t1、讀寫t2的語句都會被阻塞。同時,執行緒A在執行unlock tables之前,也只能執行讀t1、讀寫t2的操作。連寫t1都不允許,自然也不能訪問其他表。
在還沒有出現更細粒度的鎖的時候,表鎖是最常用的處理並發的方式。而對於InnoDB這種支援行鎖的引擎,一般不使用lock tables命令來控制並發,畢竟鎖住整個表的影響面還是太大,影響並發性。
另一類表級的鎖是MDL(metadata lock)。MDL不需要顯式使用,在訪問一個表的時候會被自動加上。當對一個表做增刪改查操作的時候,加MDL讀鎖;當要對錶做結構變更操作的時候,加MDL寫鎖。你可以想像一下,如果一個查詢正在遍歷一個表中的數據,而執行期間另一個執行緒對這個表結構做變更,刪了一列,那麼查詢執行緒拿到的結果跟表結構對不上,肯定是不行的。因此,在MySQL 5.5版本中引入了MDL。
我們知道讀鎖之間不互斥,因此你可以有多個執行緒同時對一張表增刪改查。但是讀寫鎖之間、寫鎖之間是互斥的,用來保證變更表結構操作的安全性。因此,如果有兩個執行緒要同時給一個表加欄位,其中一個要等另一個執行完才能開始執行。
請注意,很多人在MDL鎖稍微不注意就會掉入這個坑裡:給一個小表加個欄位,最後導致整個庫掛了。我們都知道給一個表加欄位,或者修改欄位,或者加索引,需要掃描全表的數據。在對大表操作的時候,你肯定會特別小心,以免對線上服務造成影響。而實際上,即使是小表,操作不慎也會出問題。我們來看一下下面的操作序列,假設表t是一個小表。
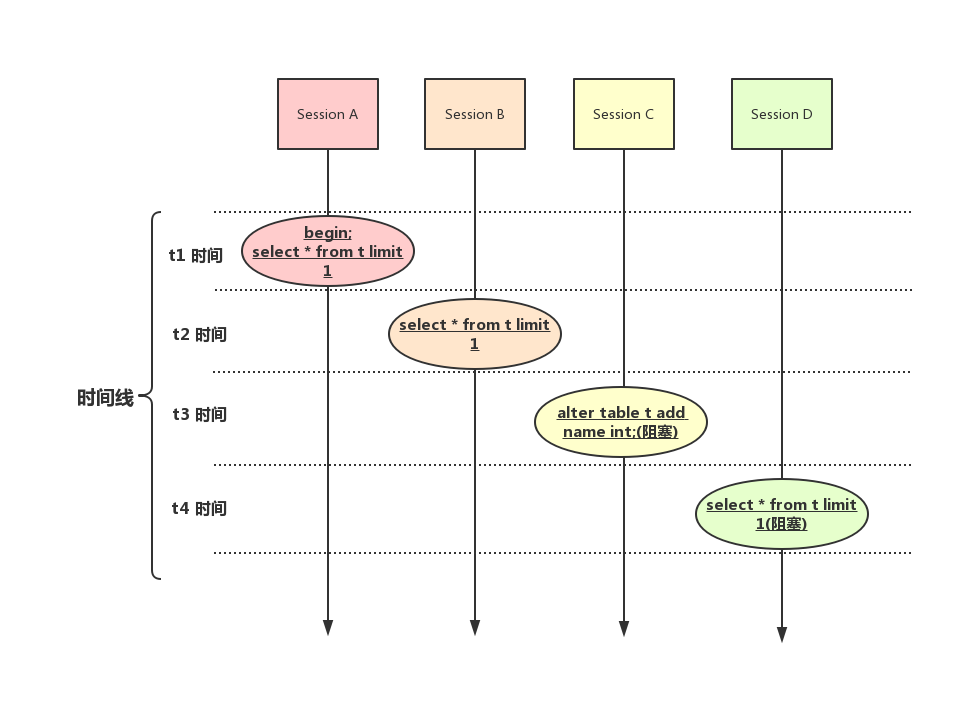
如上圖所示,會話A 先啟動,這時候會對錶t 加 MDL讀鎖。會話 B也是MDL讀鎖,我們知道,通過上面的知識知道,MDL讀鎖之前是不互斥的,因此可以正常執行。
接著會話C會被阻塞,為什麼會被阻塞呢?結合上面的知識,我們知道會話 A的MDL讀鎖還沒有釋放,而會話 C需要MDL寫鎖,因此只能被阻塞。如果只有會話 C自己被阻塞也就還好,細想一下之後所有要在表t上新申請MDL讀鎖的請求也會被會話 C阻塞。通過前面的知識,我們知道所有對錶的增刪改查操作都需要先申請MDL讀鎖,就都被鎖住,等於這個表現在完全不可讀寫了。如果某個表上存在頻繁的語句查詢,而且客戶端有重試這個機制在,超時後會再起一個新會話再請求的話,這個庫的執行緒很快就會爆滿。這就是為什麼即使是小表,操作不慎,最後導致整個庫掛了。我們現在知道了事務中的MDL鎖,在語句執行開始時申請,但是語句結束後並不會馬上釋放,而會等到整個事務提交後再釋放。
基於上面的分析,我們來討論一個問題,如何安全地給小表加欄位?
首先我們要解決長事務,事務不提交,就會一直占著MDL鎖。在MySQL的information_schema 庫的 innodb_trx 表中,你可以查到當前執行中的事務。如果你要做DDL變更的表剛好有長事務在執行,要考慮先暫停DDL,或者kill掉這個長事務。
但考慮一下這個場景。如果你要變更的表是一個熱點表,雖然數據量不大,但是上面的請求很頻繁,而你不得不加個欄位,你該怎麼做呢?
這時候kill可能未必管用,因為新的請求馬上就來了。比較理想的機制是,在alter table語句裡面設定等待時間,如果在這個指定的等待時間裡面能夠拿到MDL寫鎖最好,拿不到也不要阻塞後面的業務語句,先放棄。之後開發人員或者DBA再通過重試命令重複這個過程。MariaDB已經合併了AliSQL的這個功能,所以這兩個開源分支目前都支援DDL NOWAIT/WAIT n這個語法。
ALTER TABLE tbl_name NOWAIT add column ... ALTER TABLE tbl_name WAIT N add column ...
接下來聊聊InnoDB的行鎖,以及如何通過減少鎖衝突來提升業務並發度。為什麼我不講解基於MyISAM的呢?,大家別忘了我們前面提到的MyISAM引擎就不支援行鎖。不支援行鎖意味著並發控制只能使用表鎖,對於這種引擎的表,同一張表上任何時刻只能有一個更新在執行,這就會影響到業務並發度。InnoDB是支援行鎖的,這也是MyISAM被InnoDB替代的重要原因之一。
那什麼是行鎖呢?見其名知其意,行鎖主要是針對資料庫表中行記錄的鎖,舉個通熟易懂的例子,比如事務A更新一行,與此同時,事務B 也要要更新同一行,則必須等事務A的操作完成後才能進行更新。
我這裡為什麼要講這些概念性東西呢?很簡單,如果我們對概念的理解不透徹,進行生產的時候,一不小心就導致程式出現一些非預期的行為。就好比如二階段鎖。
接下來通過一個例子講解二階段鎖的注意事項,例子如下:

從上圖可以看到,按照時間的順序操作,事務執行update 語句時,會發什麼事情呢?上圖的 id 是表T的主鍵。
這問題主要看事務A在執行完兩條update 後,擁有哪些鎖,在什麼時候釋放鎖。很明顯事務B 的update 會被阻塞,知道事務A執行commit提交時候後,事務B才能繼續執行。因為事務A持有的兩個記錄的行鎖,都是commit 的時候才釋放的。
因此,在InnoDB事務中,行鎖是在需要的時候才加上的,但並不是不需要了就立刻釋放,而是要等到事務結束時才釋放。這個就是兩階段鎖協議。
我們知道這個設定,有什麼用呢?貌似對於我們使用事務有什麼幫助呢?
還是很有幫助的,例如,如果你的事務中需要鎖多個行,要把最可能造成鎖衝突、最可能影響並發度的鎖盡量往後放。如果你此時負責實現一個在線交易的購物平台,用戶A在某東上購買了一部手機,這個過程主要涉及一下幾個操作:
1.從用戶A賬戶中扣除手機的價錢;
2.給某東的賬戶餘額增加這部手機的價錢;
3.記錄一條交易日誌。
這個操作過程,為了保證交易的原子性,必然要把這三個操作放在一個事務中的,我們需要update 兩條記錄,並且insert 一條記錄,那麼我們如何安排這三個語句在事務中的順序呢?
如果此時還有另外一個用戶B在某東上買了一本Java,那麼兩個事務中衝突的部門必然是語句 2 了,因為它們要更新某東賬戶的餘額,需要更改同一行數據。
根據兩階段鎖協議,不論你怎樣安排語句順序,所有的操作需要的行鎖都是在事務提交的時候才釋放的。所以,如果你把語句2安排在最後,比如按照3、1、2這樣的順序,必然某東餘額這一行的鎖時間就最少。這就最大程度地減少了事務之間的鎖等待,提升了並發度。
雖然餘額這一行的行鎖在一個事務中不會停留很長時間,但是並不能完全解決問題。
下面再舉個例子,如果某東 6.18活動,低價預售所有的商品,活動剛開始的時候,你發現你的資料庫突然就掛了,那麼此時你進行排查問題,top 命令等一系列操作,於是看到CPU 幾乎百分百,但是整個資料庫每秒就執行不到2000個事務(這裡我只是假設的呀,我也不知道某東的具體情況,不要抬杠,哈哈)。到這裡,就必須說說死鎖和死鎖的檢測了。
四、死鎖和死鎖檢測
當並發系統中不同執行緒出現循環資源依賴,涉及的執行緒都在等待別的執行緒釋放資源時,就會導致這幾個執行緒都進入無限等待的狀態,稱為死鎖。接下來用行鎖舉個例子。
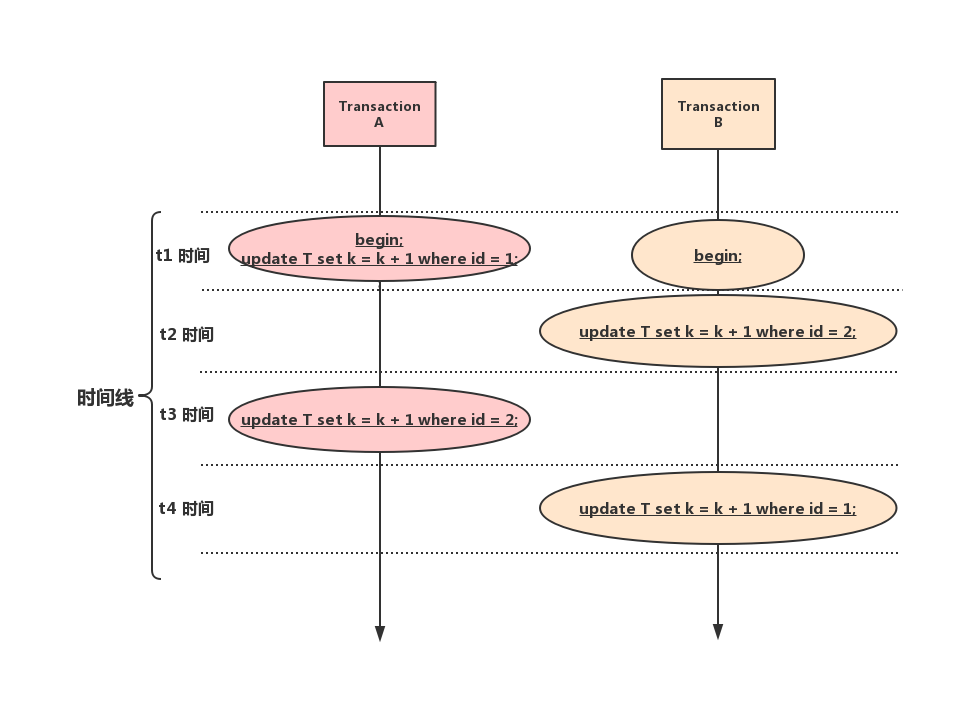
從上圖可以看到,事務A在等待事務B釋放id=2的行鎖,而事務B在等待事務A釋放id=1的行鎖。 事務A和事務B在互相等待對方的資源釋放,就是進入了死鎖狀態。
當出現死鎖以後,有兩種策略:
- 一種策略是,直接進入等待,直到超時。這個超時時間可以通過參數innodb_lock_wait_timeout來設置。在InnoDB中,innodb_lock_wait_timeout的默認值是50s,意味著如果採用第一個策略,當出現死鎖以後,第一個被鎖住的執行緒要過50s才會超時退出,然後其他執行緒才有可能繼續執行。對於在線服務來說,這個等待時間往往是無法接受的。但是,我們又不可能直接把這個時間設置成一個很小的值,比如1s。這樣當出現死鎖的時候,確實很快就可以解開,但如果不是死鎖,而是簡單的鎖等待呢?所以,超時時間設置太短的話,會出現很多誤傷。
- 另一種策略是,發起死鎖檢測,發現死鎖後,主動回滾死鎖鏈條中的某一個事務,讓其他事務得以繼續執行。將參數innodb_deadlock_detect設置為on,表示開啟這個邏輯。所以,正常情況下我們還是要採用第二種策略,即:主動死鎖檢測,而且innodb_deadlock_detect的默認值本身就是on。主動死鎖檢測在發生死鎖的時候,是能夠快速發現並進行處理的,但是它也是有額外負擔的。
你可以想像一下這個過程:每當一個事務被鎖的時候,就要看看它所依賴的執行緒有沒有被別人鎖住,如此循環,最後判斷是否出現了循環等待,也就是死鎖。
那如果是我們上面說到的所有事務都要更新同一行的場景呢?
每個新來的被堵住的執行緒,都要判斷會不會由於自己的加入導致了死鎖,這是一個時間複雜度是O(n)的操作。假設有1000個並發執行緒要同時更新同一行,那麼死鎖檢測操作就是100萬這個量級的。雖然最終檢測的結果是沒有死鎖,但是這期間要消耗大量的CPU資源。因此,你就會看到CPU利用率很高,但是每秒卻執行不了幾個事務。
根據上面的分析,我們來討論一下,怎麼解決由這種熱點行更新導致的性能問題呢?問題的癥結在於,死鎖檢測要耗費大量的CPU資源。
第一種方法就是如果你能確保這個業務一定不會出現死鎖,可以臨時把死鎖檢測關掉。但是這種操作本身帶有一定的風險,因為業務設計的時候一般不會把死鎖當做一個嚴重錯誤,畢竟出現死鎖了,就回滾,然後通過業務重試一般就沒問題了,這是業務無損的。而關掉死鎖檢測意味著可能會出現大量的超時,這是業務有損的。
另一個思路是控制並發度。根據上面的分析,你會發現如果並發能夠控制住,比如同一行同時最多只有10個執行緒在更新,那麼死鎖檢測的成本很低,就不會出現這個問題。一個直接的想法就是,在客戶端做並發控制。但是,你會很快發現這個方法不太可行,因為客戶端很多。我見過一個應用,有600個客戶端,這樣即使每個客戶端控制到只有5個並發執行緒,匯總到資料庫服務端以後,峰值並發數也可能要達到3000。
因此,這個並發控制要做在資料庫服務端。如果你有中間件,可以考慮在中間件實現;如果從MySQL 源碼上修改,基本思路就是,對於相同行的更新,在進入引擎之前排隊。這樣在InnoDB內部就不會有大量的死鎖檢測工作了。
那麼我們能不能從設計上優化這個問題呢?
你可以考慮通過將一行改成邏輯上的多行來減少鎖衝突。還是以某東賬戶為例,可以考慮放在多條記錄上,比如10個記錄,某東的賬戶總額等於這10個記錄的值的總和。這樣每次要給某東賬戶加金額的時候,隨機選其中一條記錄來加。這樣每次衝突概率變成原來的1/10,可以減少鎖等待個數,也就減少了死鎖檢測的CPU消耗。
這個方案看上去是無損的,但其實這類方案需要根據業務邏輯做詳細設計。如果賬戶餘額可能會減少,比如退貨邏輯,那麼這時候就需要考慮當一部分行記錄變成0的時候,程式碼要有特殊處理。