深入理解分散式鎖
- 2019 年 10 月 5 日
- 筆記
為什麼需要分散式鎖
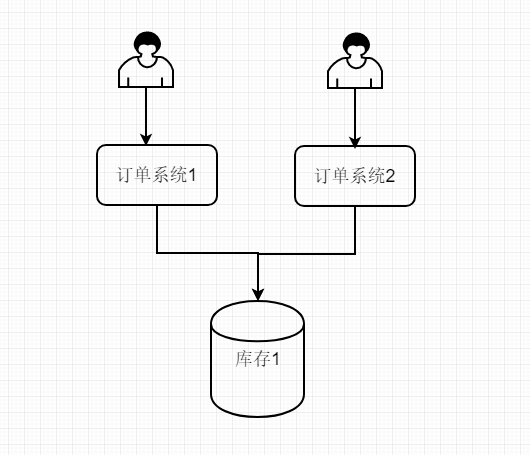
如上圖,在分散式系統中,訂單模組為了迎戰高並發,訂單服務被橫向拆分,拆分成了不同的進程,就像上圖,兩個人同時訪問訂單服務,然後訂單系統1和訂單系統2共用一個Mysql當成資料庫,經過他們查詢發現僅有一件商品,所以他們自個認為都可以下單
如果不加鎖限制,可能會出現庫存減為負數的情況
怎麼辦呢?
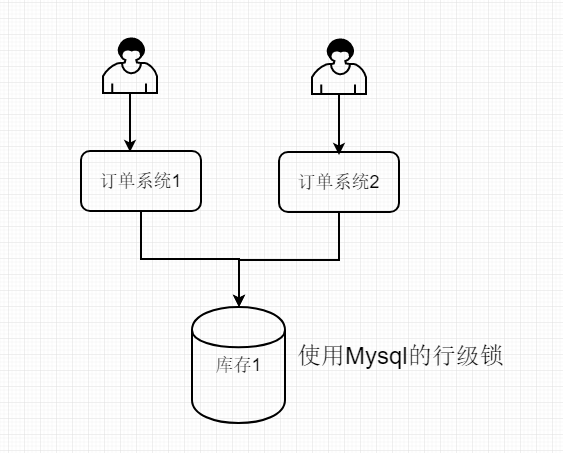
如上圖
mysql自帶行級鎖,可以考慮使用它的行級鎖,可以保證數據的安全,但是不足之處也跟著來了,使用MySql的行級鎖,系統的中壓力就全部集中在mysql,那mysql就是系統吞吐量的瓶頸了,系統的吞吐量也會收到mysql的限制
可以使用分散式鎖
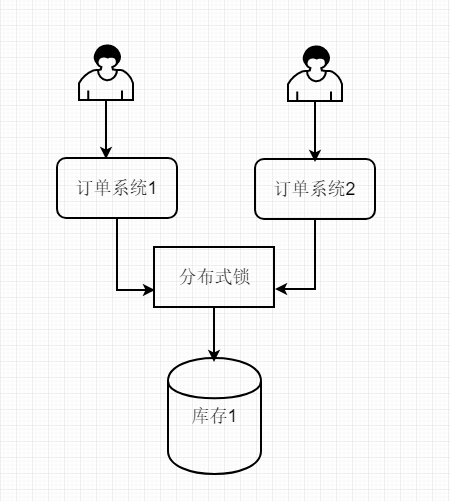
如上圖,分散式鎖將系統的壓力從mysql上面轉移到自己身上來
什麼是分散式鎖
一句話,分散式鎖是實現有序調度不同的進程,解決不同進程之間相互干擾的問題的技術手段
分散式鎖的應具備的條件
- 在分散式系統環境下,分散式鎖在同一個時間僅能被同一個進程訪問
- 高可用的獲取/釋放鎖
- 高性能的獲取/釋放鎖
- 具備鎖的重入性
- 具備鎖的失效機制,防止死鎖
- 具備非阻塞鎖的特性,即使沒有獲取鎖也能直接返回結果
分散式鎖的實現有哪些
- mechache: 利用mechache的add命令,改命令是原子性的操作,只有在key 不存在的情況下,才能add成功,也就意味著執行緒拿到了鎖
- Redis: 和Mechache的實現方法相似,利用redis的setnx命令,此命令同樣是原子性的操作,只有在key不存在的情況下,add成功
- zookeeper利用他的順序臨時節點,來實現分散式鎖和等待隊列,zookeeper的設計初衷就是為了實現分散式微服務的
使用Redis實現分散式鎖的思路
- 先去redis中使用setnx(商品id,數量) 得到返回結果
- 這裡的數量無所謂,它的作用就是告訴其他服務,我加上了鎖
- 發現redis中有數量,說明已經可以加鎖了
- 發現redis中沒有數據,說明已經獲得到了鎖
- 解鎖: 使用redis的 del商品id
- 鎖超時, 設置exprie 生命周期,如30秒, 到了指定時間,自定解鎖
三個致命問題
- 非原子性操作
- setnx
- 宕機
- expire
因為 setnx和expire不是原子性的,要麼都成功要麼都失敗, 一旦出現了上面的情況,就會導致死鎖出現
redis提供了原子性的操作 set ( key , value , expire)
- 誤刪鎖
- 假如我們的鎖的生命事件是30秒,結果我在30s內沒操作完,但是鎖被釋放了
- jvm2拿到了鎖進行操作
- jvm1 操作完成使用del,結果把jvm2 的鎖刪除了
解決方法, 在刪除之前,判斷是不是自己的鎖
redis提供了原子性的操作 set ( key ,threadId, expire)
- 超時為完成任務
增加一個守護執行緒,當快要超時,但是任務還沒執行完成,就增加鎖的時間
使用ZooKeeper實現分散式鎖的思路
使用ZooKeeper的臨時順序節點
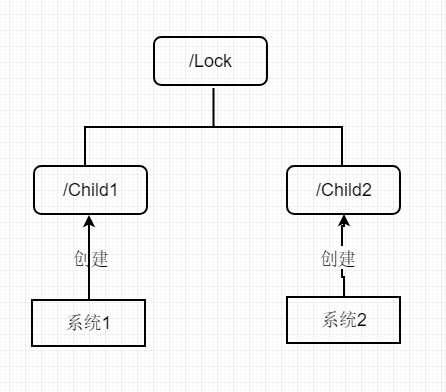
系統1和系統2在執行業務邏輯之前都需要先獲取到鎖,然後他們就是/Lock節點下創建臨時順序節點,序號最小的節點的創建者視為獲取到了鎖,可以進行其他業務操作,當它執行完成後,將這個節點刪除掉視為釋放了鎖
釋放鎖後如何通知其他節點呢?
使用ZK的watcher回調機制, 讓後一個節點對它的前一個臨時順序節點綁定watcher,當有事務性操作時發生回調,進而判斷出自己剛才創建的節點是不是最小的,如果是說明自己拿到了鎖
臨時順序節點保證了系統不會因為某台機器掛掉而出現死鎖的情況
嘗試加鎖的方法如下:
public boolean tryLock() { String path = LOCKNAME + "/zk_"; try { // todo 判斷父節點存在否, 不存在就先創建 // 創建臨時順序節點 currentNode.set(zooKeeper.get().create(path, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL)); // 獲取指定的根節點下所有的 臨時順序節點 List<String> names = zooKeeper.get().getChildren(LOCKNAME, false); // 獲取到的是子節點的 pathName Collections.sort(names); String minName = names.get(0); if (currentNode.get().equals(LOCKNAME + "/" + minName)) { return true; } else { // 監聽前一個節點 int currentNodeIndex = names.indexOf(currentNode.get().substring(currentNode.get().lastIndexOf("/")+1)); // 當前節點的前一個節點的名字 String preNodeName = names.get(currentNodeIndex - 1); // 阻塞 CountDownLatch countDownLatch = new CountDownLatch(1); zooKeeper.get().exists(LOCKNAME + "/" + preNodeName, new Watcher() { @Override public void process(WatchedEvent event) { // 監聽當前節點的刪除事件 if (Event.EventType.NodeDeleted.equals(event.getType())) { countDownLatch.countDown(); } } }); // 在countDownLatch減完之前,會阻塞在這裡等待 countDownLatch.await(); return true; } } catch (Exception e) { e.printStackTrace(); } // 按理說應該在監聽的回調裡面返回true,但是在這個回調裡面返回不了true,現在就使用countDownLatch,回調的時候去改變countDownLatch的值 return true; }