Zabbix自動發現並監控磁碟IO、報警
- 2020 年 3 月 6 日
- 筆記
本文轉載自: https://www.93bok.com
引言
Zabbix並沒有提供模板來監控磁碟的IO性能,所以我們需要自己來創建一個,由於一台伺服器中磁碟眾多,如果只有一兩台可以手動添加,但服務集群達到幾十那就非常麻煩,因此需要利用自動發現這個功能,自動發現後自動添加對伺服器磁碟的監控,而且添加磁碟後也會自動添加到監控,實現自動化運維的效果,接下來我們就來看看怎麼自動發現磁碟並自動監控磁碟的IO性能,再設置觸發器,IO達到閾值後發出報警
iostat簡介
iostat主要用於監控系統設備的IO負載情況,iostat首次運行時顯示自系統啟動開始的各項統計資訊,之後運行iostat將顯示自上次運行該命令以後的統計資訊。用戶可以通過指定統計的次數和時間來獲得所需的統計資訊。所以在使用iostat監控系統IO負載的時候,不要直接iostat取結果,而是iostat -dxkt 1 2取結果,否則得到的數據根本不正確
iostat安裝
yum -y install sysstatiostat常用參數說明 -c #僅顯示CPU統計資訊.與-d選項互斥. -d #僅顯示磁碟統計資訊.與-c選項互斥. -k #以K為單位顯示每秒的磁碟請求數,默認單位塊. -t #在輸出數據時,列印搜集數據的時間. -V #列印版本號和幫助資訊. -x #輸出擴展資訊.iostat命令輸出說明
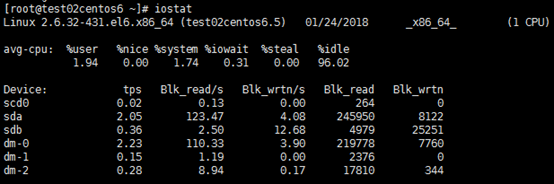
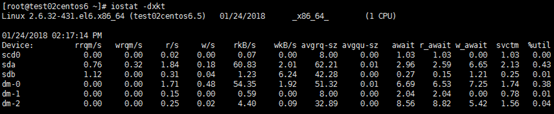
圖一
avg-cpu段:
%user: 在用戶級別運行所使用的CPU的百分比. %nice: nice操作所使用的CPU的百分比. %sys: 在系統級別(kernel)運行所使用CPU的百分比. %iowait: CPU等待硬體I/O時,所佔用CPU百分比. %idle: CPU空閑時間的百分比.Device段:
tps: 每秒鐘發送到的I/O請求數. Blk_read /s: 每秒讀取的block數. Blk_wrtn/s: 每秒寫入的block數. Blk_read: 讀入的block總數. Blk_wrtn: 寫入的block總數.圖二
rrqm/s:每秒讀請求被合併次數 wrqm/s:每秒寫請求被合併次數 r/s:每秒完成的讀次數 w/s:每秒完成的寫次數 rkB/s:每秒讀數據量(kb) wkB/s:每秒寫數據量(kb) avgrq-sz:平均每次IO請求的扇區大小 avgqu-sz:平均每次IO請求的隊列長度(越短越好) await:平均每次IO請求等待時間(毫秒),一般的系統IO等待時間應該低於5ms,如果大於10ms就比較大了。這個時間包括了隊列時間和服務時間,也就是說,一般情況下,await大於svctm,它們的差值越小,則說明隊列時間越短,反之差值越大,隊列時間越長,說明系統出了問題。 r_await:讀的平均耗時(毫秒) w_await:寫入平均耗時(毫秒) svctm:平均每次IO請求處理時間(毫秒),如果svctm的值與await很接近,表示幾乎沒有I/O等待,磁碟性能很好,如果await的值遠高於svctm的值,則表示I/O隊列等待太長,系統上運行的應用程式將變慢。 %util:IO隊列非空比例,該參數暗示了設備的繁忙程度。一般地,如果該參數是100%表示設備已經接近滿負荷運行了一、在被監控端上編寫自動發現和監控磁碟IO腳本
1、創建zabbix腳本存放目錄
mkdir -p /etc/zabbix/scripts2、編寫自動發現磁碟腳本
vim /etc/zabbix/scripts/disk_discovery.sh #!/bin/bash ############################################################ # $Name: disk_discovery.sh # $Function: DISK DISCOVERY # $Author: Mr.nong # $organization: nongziyi.xin # $Create Date: 2018/1/25 # $Description: Monitor DISK DISCOVERY ############################################################ disk_array=(`grep -E "(vd[a-z]$|sd[a-z]$)" /proc/partitions | awk '{print $4}'`) length=${#disk_array[@]} printf "{n" printf 't'""data":[" for ((i=0;i<$length;i++)) do printf 'ntt{' printf ""{#DISK_NAME}":"${disk_array[$i]}"}" if [ $i -lt $[$length-1] ];then printf ',' fi done printf "nt]n" printf "}n"3、編寫監控磁碟IO腳本
vim /etc/zabbix/scripts/disk_io.sh #!/bin/bash ############################################################ # $Name: disk_io.sh # $Function: DISK IO # $Author: Mr.nong # $organization: nongziyi.xin # $Create Date: 2018/1/25 # $Description: Monitor DISK IO ############################################################ Device=$1 DISK=$2 case $DISK in #每秒讀請求被合併次數 rrqm_s) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $2}' ;; #每秒寫請求被合併次數 wrqm_s) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $3}' ;; #每秒完成的讀次數 r_s) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $4}' ;; #每秒完成的寫次數 w_s) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $5}' ;; #每秒讀數據量(kb) rkb_s) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $6}' ;; #每秒寫數據量(kb) wkb_s) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $7}' ;; #平均每次IO請求的扇區大小 avgrq_sz) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $8}' ;; #平均每次IO請求的隊列長度(越短越好) avgqu_sz) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $9}' ;; #平均每次IO請求等待時間(毫秒) await) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $10}' ;; #讀的平均耗時(毫秒) r_await) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $11}' ;; #寫入平均耗時(毫秒) w_await) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $12}' ;; #平均每次IO請求處理時間(毫秒) svctm) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $13}' ;; #IO隊列非空比例 util) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $14}' ;; esac 4、給予腳本執行許可權
chmod +x /etc/zabbix/scripts/disk_*5、編輯zabbix_agentd的配置文件支援自定義腳本
vim /etc/zabbix/zabbix_agentd.conf UnsafeUserParameters=16、編輯zabbix_agentd的配置文件添加zabbix配置文件目錄
vim /etc/zabbix/zabbix_agentd.conf Include=/etc/zabbix/zabbix_agentd.conf.d/7、創建disk_io的key文件
vim /etc/zabbix/zabbix_agentd.conf.d/disk_status.conf UserParameter=disk.discovery[*],/etc/zabbix/scripts/disk_discovery.sh UserParameter=disk.io[*],/etc/zabbix/scripts/disk_io.sh $1 $2參數說明: 其中的格式為UserParameter=<key>,<command> <key>:就是在web端添加監控腳本時的key值 <command>:就是該key值對應的執行腳本,也就是腳本執行路徑7、重啟zabbix_agentd服務
service zabbix_agentd restart8、在zabbix server端進行測試
/a01/apps/zabbix/bin/zabbix_get -s 192.168.10.26 -k 'disk.discovery[*]'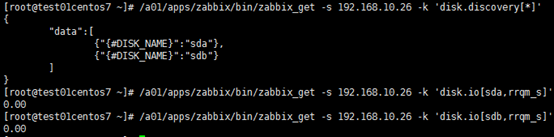
9、到zabbix web前端創建模板
- 「配置」——「模板」——「創建模板」
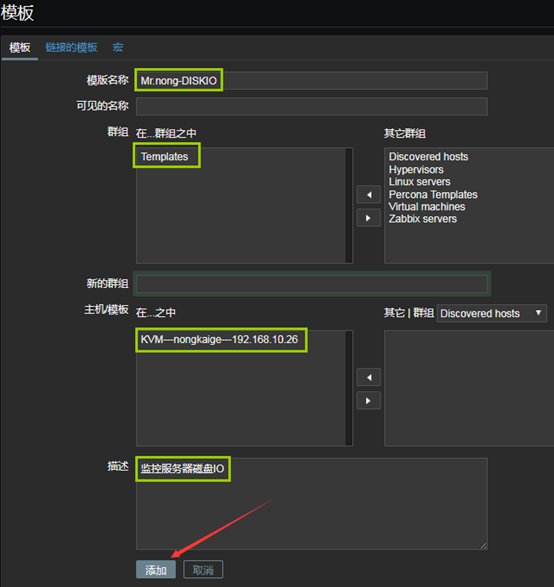
10、創建應用集
- 「配置」——「模板」——「選中模板」——應用集」——「創建應用集」
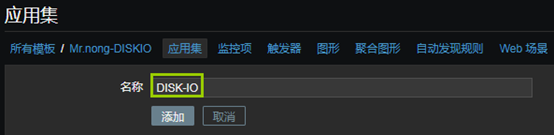
11、創建自動發現規則
- 「配置」——「模板」——「選中模板」——「自動發現規則」——「創建自動發現規則」
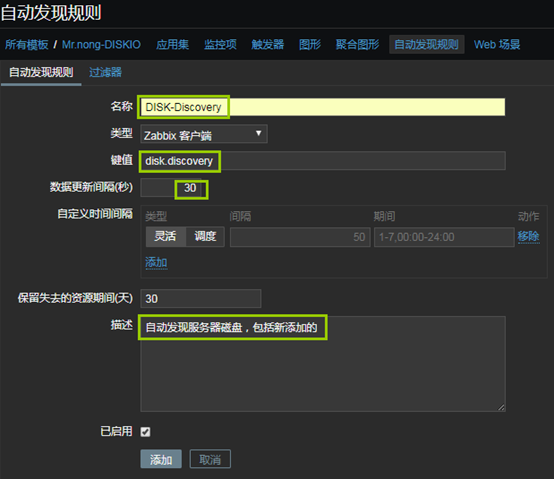
- 上圖中的「數據更新間隔(秒)」可以調整為久一些,因為伺服器添加硬碟不是每天都乾的事,這裡為了後邊驗證效果,我就不修改了
12、創建監控項原型(鍵值[]中的數值必須大寫,否則會報錯如下)
Cannot create item: item with the same key 「diskio.x.[[xxxxxx]] already exists
- 一個一個創建即可,這裡只截圖一個作為參考
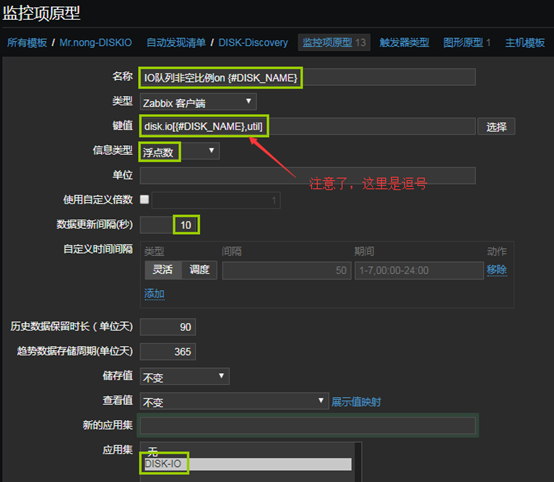
- 創建為完成
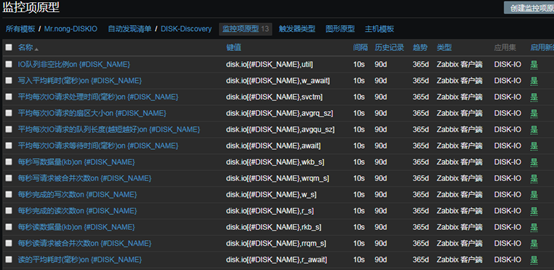
13、創建圖形原型(名稱後邊要帶哪個磁碟的動態名稱,否則會報錯如下)
zabbix3 Cannot create graph: graph with the same name "Disk IO" already exists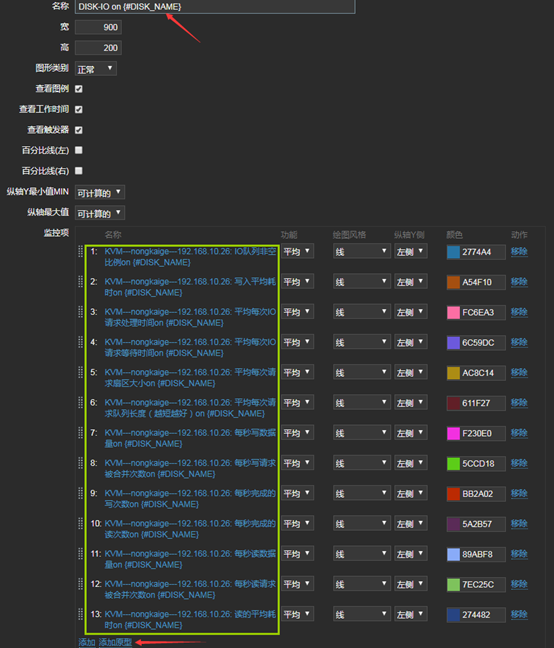
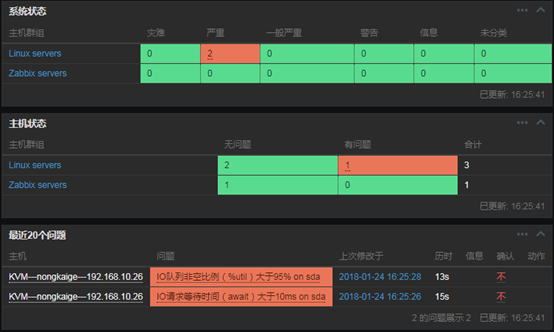
14、查看是否獲取到數據(現在獲取到的數據都是0,稍候我們會進行測試)
- 可以看到有sda和sdb兩塊磁碟被監控到數據了,因為我的這台伺服器有兩塊磁碟
- 「監測中」——「最新數據」——「過濾器」——「應用」
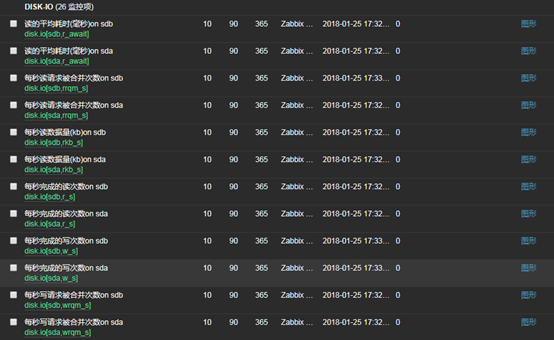
16、在被監控端上模擬磁碟寫入進行測試
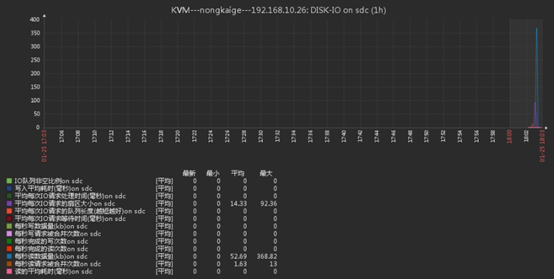
dd if=/dev/zero of=/a.txt bs=8k count=300000017、查看我們創建的圖形
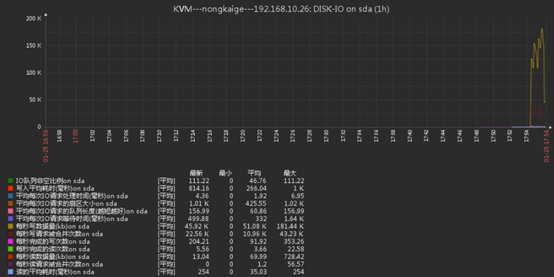
二、新添一塊磁碟,看看是否能自動發現磁碟並監控
- 添加硬碟,分區,格式化過程省略,這裡我添加了一塊5G硬碟,分區格式化之後掛載在/mnt下,添加完之後直接上zabbix web頁面查看是否自己生成影像
三、配置觸發器,達到閾值報警
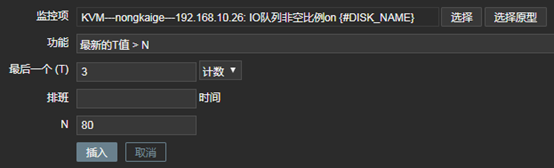
A、IO請求等待時間(await)大於10ms則報警
- 「配置」——「選擇主機」——「自動發現規則」——「觸發器類型」——「創建觸發器原型」
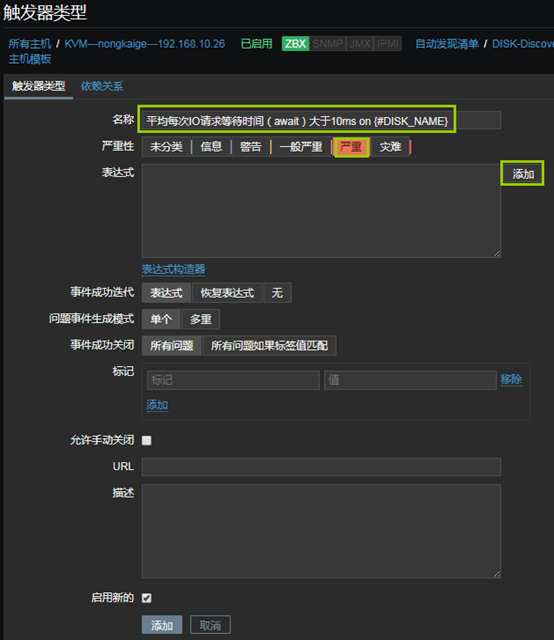
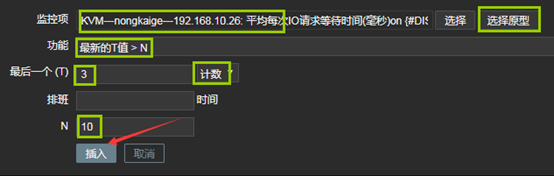
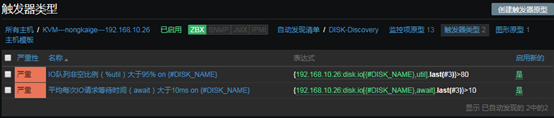
上圖中的參數說明: 1、監控項:定義被監控項的閾值 2、功能:功能說起來比較麻煩,但是並不難理解,我舉個例子,假如設定,一個養雞場的溫度不能低於30度,如果低於30度,則報警;那麼我也可以設定,如果溫度等於30度,我們就報警;或者說,如果溫度高於30度就報警。那到底是低於,等於,還是高於,這得看我們自己怎麼設定。還有就是,我們還可以設定,如果5分鐘前的檢測低於/等於/高於30度,報警;甚至還可以這樣,如果連續10分鐘內獲取的溫度值的平均值都低於/等於/高於30度,報警。那麼在zabbix中,怎樣實現這樣靈活的設定呢,就是通過「功能」欄定義的,比如,最近T次監測或者T分鐘內的監測,養雞場的溫度出現了小於N度的情況,在功能欄中可以選擇「最新的T值<N」。 3、最後一個(T):我們在「功能」中,已經選擇了某種定義,比如「最新的T值<N」,那麼T是以時間為單位呢,還是以次數為單位呢,如果我們想定義「最近的第T次,養雞場的溫度小於30度」,那麼此處需要選擇「計數」。如果我們想要定義「最近T分鐘內,養雞場的溫度小於30度」,那麼此處需要選擇「時間」。 4、排班:如果我們想要定義「最近T分鐘內,養雞場的溫度小於30度」,則「最後一個(T)」需要選擇「時間」,同時在此處指明時間長度,默認單位是秒。 5、N:此處用於設置N的值,比如「最近一次監測的養雞場溫度小於30度」,那麼這裡N就是30。 在本例中,我監控了await這個數值,整個觸發器的意思就是:在最近的3次監測中,await的狀態都大於10,則報警。 B、IO隊列非空比例(%util)大於80%時報警
- 「配置」——「選擇主機」——「自動發現規則」——「觸發器類型」——「創建觸發器原型」
四、再次模擬磁碟寫入,測試會不會觸發到報警
dd if=/dev/zero of=/a.txt bs=8k count=3000000