NLP實踐!文本語法糾錯模型實戰,搭建你的貼身語法修改小助手 ⛵
- 2022 年 11 月 30 日
- 筆記
- GECToR, nlp, NLP實戰通關指南 ⛵ 文本&語音項目實操大全, Transformer, 人工智慧, 深度學習, 深度學習實戰通關指南 ⛵ 頂級「煉丹師」案例驅動成長之路, 自然語言處理, 語法糾錯模型, 語言模型

💡 作者:韓信子@ShowMeAI
📘 深度學習實戰系列://www.showmeai.tech/tutorials/42
📘 自然語言處理實戰系列://www.showmeai.tech/tutorials/45
📘 本文地址://showmeai.tech/article-detail/399
📢 聲明:版權所有,轉載請聯繫平台與作者並註明出處
📢 收藏ShowMeAI查看更多精彩內容
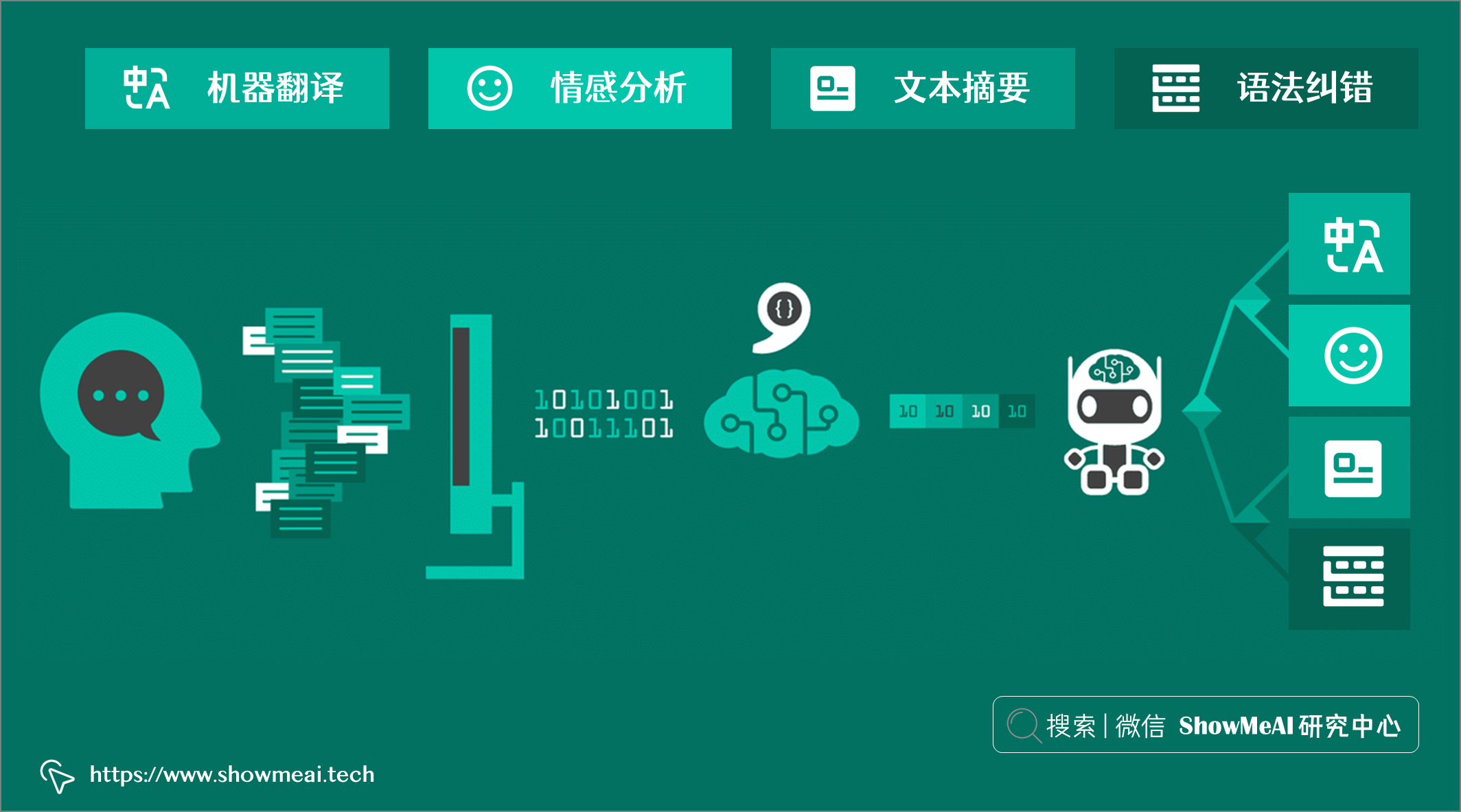
自然語言處理(NLP)技術可以完成文本數據上的分析挖掘,並應用到各種業務當中。例如:
- 機器翻譯(Machine Translation),接收一種語言的輸入文本並返回目標語言的輸出文本(包含同樣的含義)。
- 情感分析(Sentiment Analysis),接收文本數據,判定文本是正面的、負面的還是中性的等。
- 文本摘要(Text Summarization),接收文本輸入並將它們總結為更精鍊的文本語言輸出。
輸入文本的品質會很大程度影響這些業務場景的模型效果。因此,在這些文本數據到達機器翻譯、情感分析、文本摘要等下游任務之前,我們要盡量保證輸入文本數據的語法正確性。
語法糾錯(Grammatical Error Correction)是一個有非常廣泛使用的應用場景,有2種典型的模型方法:
- ① 序列到序列(seq2seq)模型:它最早被使用在機器翻譯引擎中,將給定語言翻譯成同一種語言,這種映射方法同樣可以用來做語法糾錯(例如📘Yuan 和 Briscoe,2014)。
- ② 序列標註模型:輸入文本被標註然後映射回更正的內容(例如📘Malmi 等人,2019)。
雖然 seq2seq 神經機器翻譯方法已被證明可以實現最先進的性能(例如📘Vaswani 等人,2017 年),但它仍然存在某些缺點,例如:1)推理和生成輸出需要很長時間;2)訓練需要大量數據;3)與非神經架構相比,模型的神經架構使得對結果的解釋具有挑戰性(例如📘Omelianchuk 等人,2020 年)等。為了克服這些缺點,我們在本文中討論並應用更新的方法:使用 Transformer 編碼器的序列標註器。
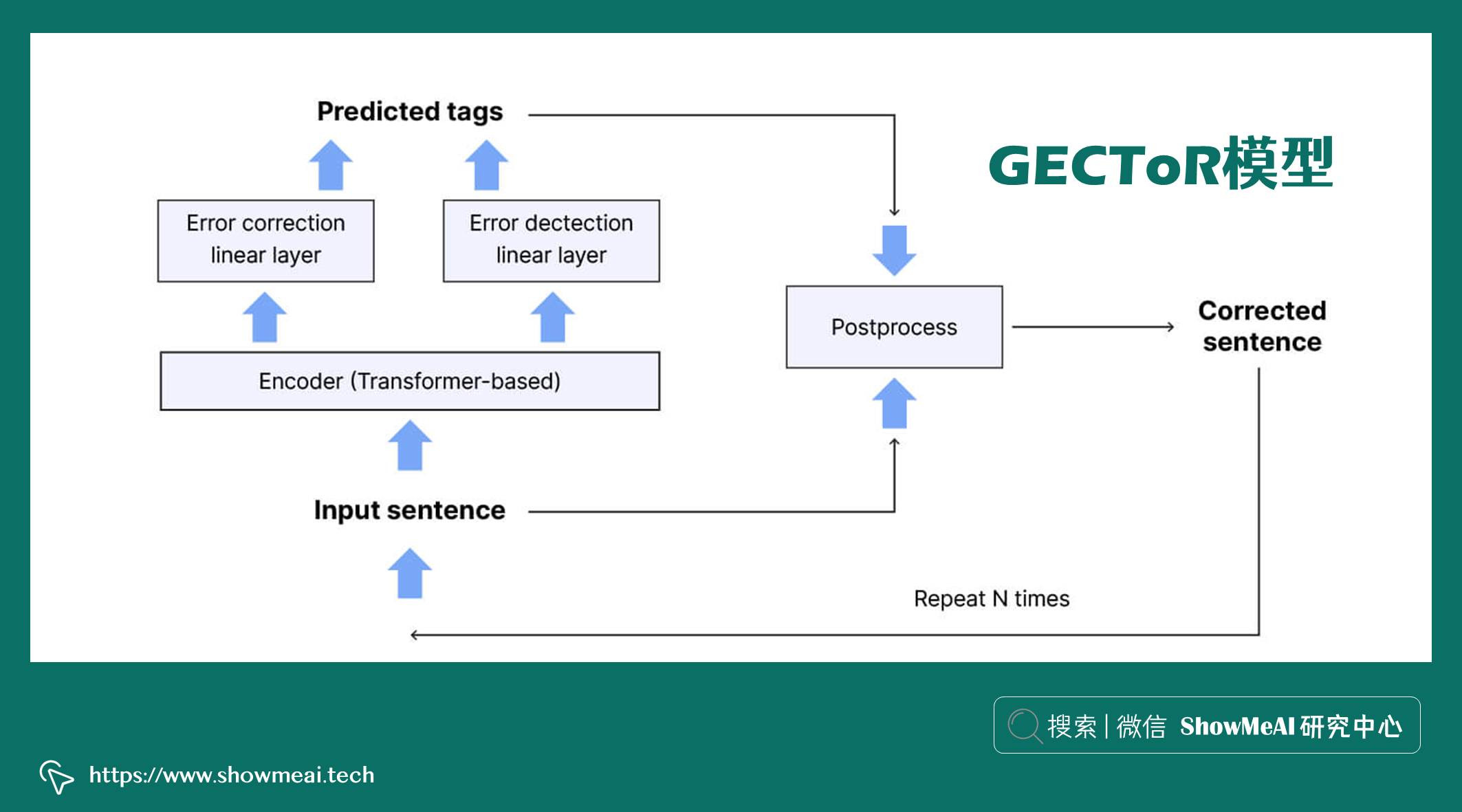
📘Omelianchuk, et al., 2020 中提出的 📘GECToR 模型,是非常優秀的文本糾錯模型。它對 Transformer seq2seq 進行微調,Transformer 的引入極大改善了 seq2seq 模型的推理時間問題,並且可以在較小的訓練數據的情況下實現更好的效果。
在後續的內容中,ShowMeAI將演示使用這個庫來實現糾正給定句子中語法錯誤的方案,我們還會創建一個可視化用戶介面來將這個AI應用產品化。
💡 語法糾錯程式碼全實現
整個語法糾錯程式碼實現包含3個核心步驟板塊:
- 準備工作:此步驟包括工具庫設定、下載預訓練模型、環境配置。
- 模型實踐:實現並測試語法糾錯模型。
- 用戶介面:創建用戶介面以產品化和提高用戶體驗
💦 準備工作
我們先使用以下命令將 GitHub 中的程式碼複製到我們本地,這是 GECToR 模型對應的實現:
git clone //github.com/grammarly/gector.git
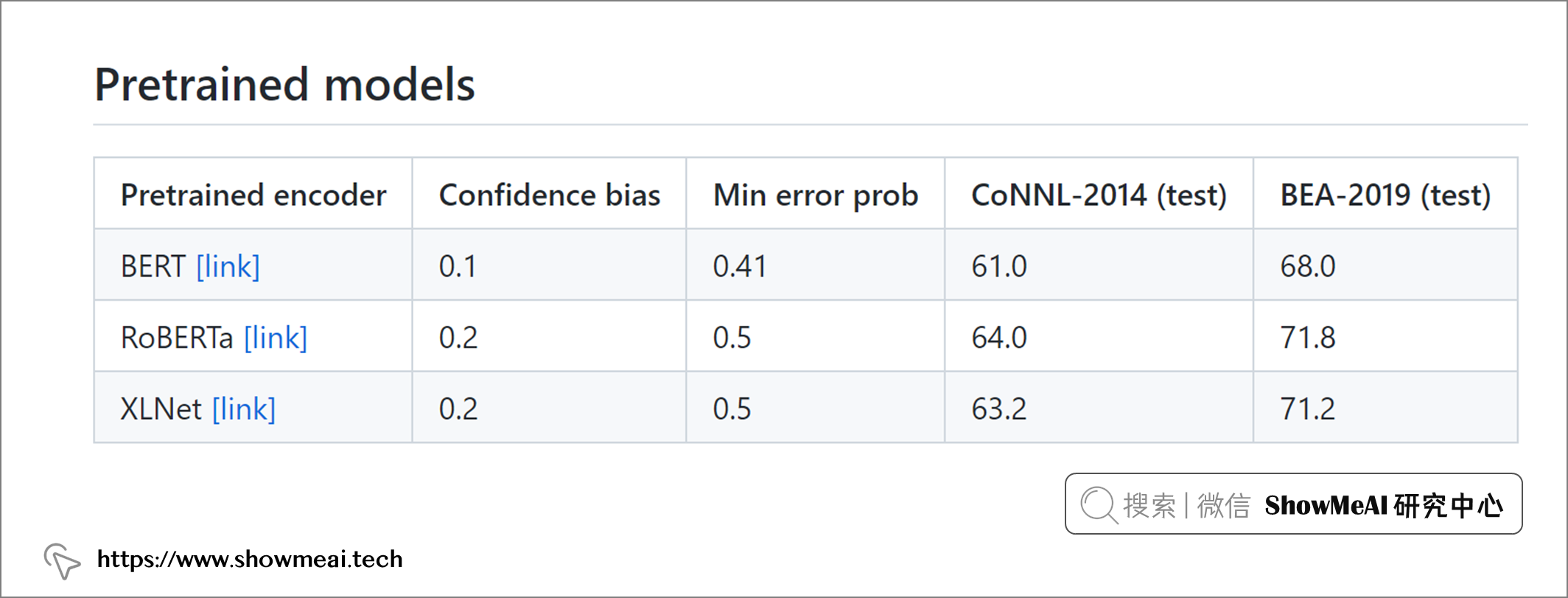
GECToR 提供了3種預訓練模型。我們在這裡使用 📘RoBERTa 作為預訓練編碼器的模型,它在現有模型中具有最高總分最好的表現。我們使用以下命令下載預訓練模型:
wget //grammarly-nlp-data-public.s3.amazonaws.com/gector/roberta_1_gectorv2.th
下載完畢後,我們把下載的模型權重移動到gector目錄,以便後續使用:
mv roberta_1_gectorv2.th ./gector/gector
接下來,我們切換到gector文件夾下:
cd ./gector
gector對其他工具庫有依賴,因此我們將使用以下命令安裝這些依賴:
pip install -r requirements.txt
💦 模型實踐
現在我們已經做好所有準備工作了,可以開始使用工具庫。總共有下述步驟:
- 導入工具包
- 構建模型實例
- 在有語法錯誤的句子上測試模型,以查看輸出
① she are looking at sky
為此,我們將使用以下句子『she are looking at sky』。
# 導入工具庫
from gector.gec_model import GecBERTModel
# 構建模型實例
model = GecBERTModel(vocab_path = "./data/output_vocabulary", model_paths = ["./gector/roberta_1_gectorv2.th"])
# 需要糾錯的句子
sent = 'she are looking at sky'
# 存儲處理結果
batch = []
batch.append(sent.split())
final_batch, total_updates = model.handle_batch(batch)
updated_sent = " ".join(final_batch[0])
print(f"Original Sentence: {sent}\n")
print(f"Updated Sentence: {updated_sent}")
結果:

模型的糾錯結果非常準確!有以下變化:
- 句首將
she大寫為She - 將
are更改為is,以使she和is主謂一致 - 在
sky之前添加the - 在句子末尾加句號
.
② she looks at sky yesterday whil brushed her hair
剛才的句子語法比較簡單,讓我們看看複雜場景,比如混合時態下模型的表現如何。
# 添加複雜句子
sent = 'she looks at sky yesterday whil brushed her hair'
# 存儲糾錯後的句子
batch = []
batch.append(sent.split())
final_batch, total_updates = model.handle_batch(batch)
updated_sent = " ".join(final_batch[0])
print(f"Original Sentence: {sent}\n")
print(f"Updated Sentence: {updated_sent}")
結果:

在這個句子中我們來看一下糾錯模型做了什麼:
- 句首將
she大寫為She - 將
looks改為looked,與yesterday一致 - 在
sky之前添加the - 將缺失的字母添加到
while - 將
brushed改為brushing,這是while之後的正確格式
不過這裡有一點大家要注意,模型的另外一種糾錯方式是將yesterday更改為today,對應的時態就不需要用過去式。但這裡模型決定使用過去時態。
③ she was looking at sky later today whil brushed her hair
現在讓我們再看一個例子:
# 添加複雜句子
sent = 'she was looking at sky later today whil brushed her hair'
# 糾錯及存儲
batch = []
batch.append(sent.split())
final_batch, total_updates = model.handle_batch(batch)
updated_sent = " ".join(final_batch[0])
print(f"Original Sentence: {sent}\n")
print(f"Updated Sentence: {updated_sent}")
結果:

我們發現了一種邊緣情況,在這種情況下,模型無法識別正確的動詞時態。更新後的句子是『She was looking at the sky later today while brushing her hair』,我們讀下來感覺這句是將來時(今天晚點),而模型糾正後的句子是過去時。
我們想一想,為什麼這句對模型比以前更具挑戰性呢?答案是later today用兩個詞暗示時間,這需要模型具有更深層次的上下文意識。如果沒有later這個詞,我們會有一個完全可以接受的句子,如下所示:

在這種情況下,today可能指的是今天早些時候(即過去),糾錯後的語法完全可以接受。但在原始示例中,模型未將later today識別為表示將來時態。
💦 用戶介面
在下一步,我們將製作一個web介面,通過用戶介面把它產品化並改善用戶體驗:
# 創建一個函數,對於輸入的句子進行語法糾錯並返回結果
def correct_grammar(sent):
batch = []
batch.append(sent.split())
final_batch, total_updates = model.handle_batch(batch)
updated_sent = " ".join(final_batch[0])
return updated_sent
我們找一個句子測試這個函數,確保它能正常工作和輸出結果。
sent = 'she looks at sky yesterday whil brushed her hair'
print(f"Original Sentence: {sent}\n")
print(f"Updated Sentence: {correct_grammar(sent = sent)}")
結果:

接下來我們將添加一個可視化用戶介面。我們使用 📘Gradio 來完成這個環節,它是一個開源 Python 工具庫,可以快捷創建 Web 應用程式,如下所示。
# 在命令行運行以安裝gradio
pip install gradio
安裝Gradio後,我們繼續導入和創建用戶介面,如下所示:
# 導入Gradio
import gradio as gr
# 構建一個demo實例
demo = gr.Interface(fn = correct_grammar, inputs = gr.Textbox(lines = 1, placeholder = 'Add your sentence here!'), outputs = 'text')
# 啟動demo
demo.launch()
結果我們得到如下的介面:
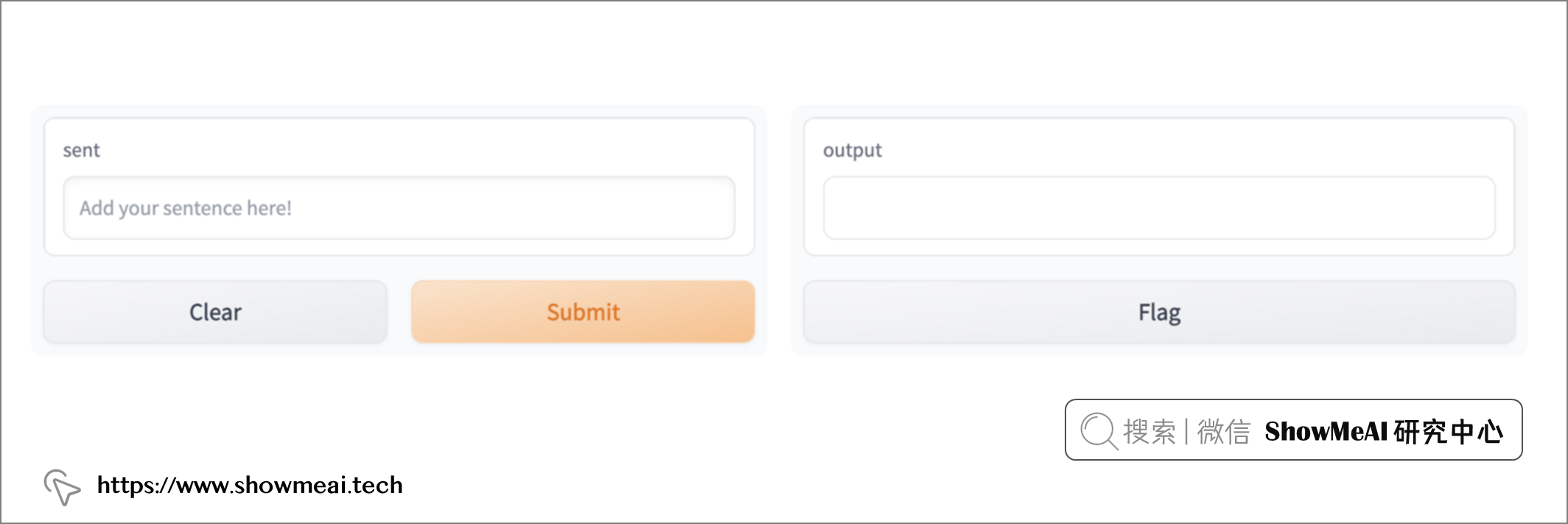
我們可以在 web 介面中再次測試我們的句子啦!我們只需在左側的框中鍵入待糾錯的句子,然後按 Submit(提交)。接錯後的結果將顯示在右側的框中,如下所示:
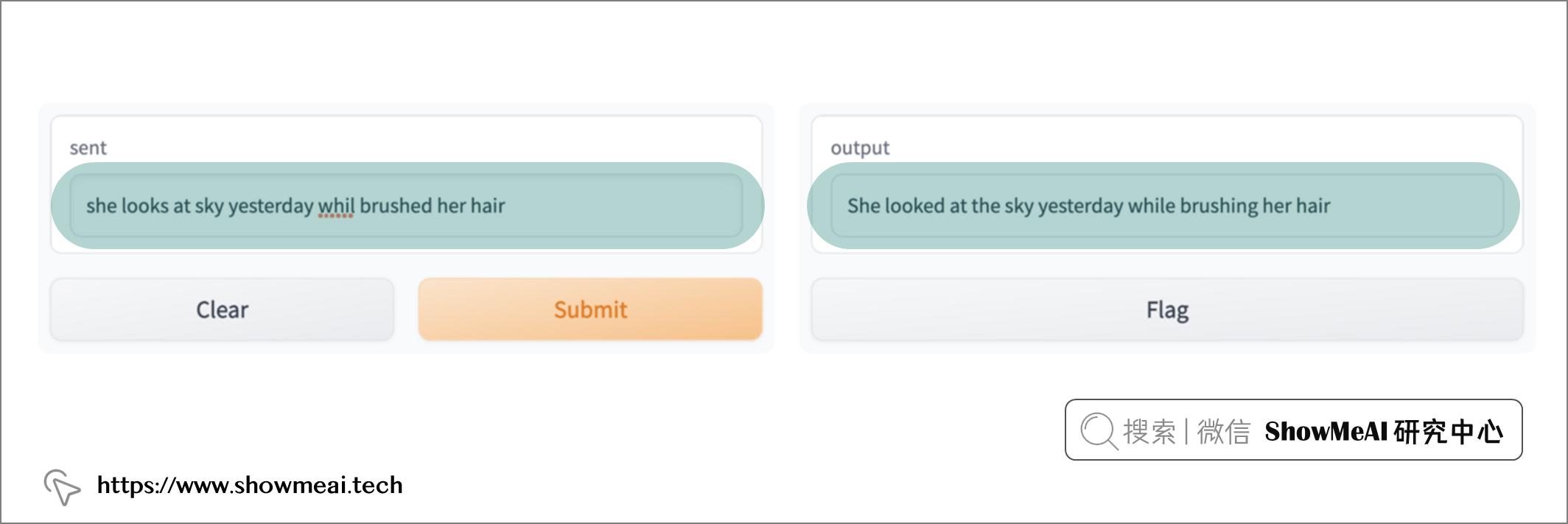
非常順利,你也快來測試一下吧!
💡 總結
在這篇文章中,我們實踐了語法糾錯模型。我們使用公開可用的 GECToR 庫來實現一個預訓練的語法糾錯模型,在一些錯誤的句子上對其進行測試,發現該模型的適用場景和局限性(需要提高的地方),最後我們構建了一個可視化介面把文本糾錯產品化。
參考資料
- 📘 Grammatical error correction using neural machine translation://aclanthology.org/N16-1042/
- 📘 Encode, Tag, Realize: High-Precision Text Editing://aclanthology.org/D19-1510/
- 📘 Attention Is All You Need://arxiv.org/abs/1706.03762
- 📘 GECToR – Grammatical Error Correction: Tag, Not Rewrite://aclanthology.org/2020.bea-1.16/
- 📘 GECToR模型的GitHub頁面://github.com/grammarly/gector
- 📘 RoBERTa的GitHub頁面://github.com/facebookresearch/fairseq/blob/main/examples/roberta/README.md
- 📘 Gradio的GitHub頁面://github.com/gradio-app/gradio
推薦閱讀
- 🌍 數據分析實戰系列 ://www.showmeai.tech/tutorials/40
- 🌍 機器學習數據分析實戰系列://www.showmeai.tech/tutorials/41
- 🌍 深度學習數據分析實戰系列://www.showmeai.tech/tutorials/42
- 🌍 TensorFlow數據分析實戰系列://www.showmeai.tech/tutorials/43
- 🌍 PyTorch數據分析實戰系列://www.showmeai.tech/tutorials/44
- 🌍 NLP實戰數據分析實戰系列://www.showmeai.tech/tutorials/45
- 🌍 CV實戰數據分析實戰系列://www.showmeai.tech/tutorials/46