漫談電腦網路:網路層 —— 重點:IP協議與互聯網路由選擇協議
- 2022 年 11 月 30 日
- 筆記
- 漫談電腦網路, 電腦網路
面試答不上?計網很枯燥? 聽說你學習 計網 每次記了都會忘? 不妨抽時間和我一起多學學它 深入淺出,用你的空閑時間來探索電腦網路的硬核知識!
深入淺出,用你的空閑時間來探索電腦網路的硬核知識!
部落客的上篇連載文章《初識影像處理技術》
影像處理技術:數字影像分割 —— 影像分割、邊界分割(邊緣檢測)、區域分割 – slowlydance2me – 部落格園 (cnblogs.com)
漫談電腦網路 連載的其他章節:
1.漫談電腦網路:概述 —— 從起源開始到分層協議結構,初識究竟什麼是電腦網路? – slowlydance2me – 部落格園 (cnblogs.com)
2.漫談電腦網路:物理層 —– 雙絞線&光纖?,從最底層開始了解電腦網路 – slowlydance2me – 部落格園 (cnblogs.com)
3.漫談電腦網路:數據鏈路層 —– 數據鏈路路在何方? –從點對點數據傳輸 到 “廣泛撒網,重點捕獲”的區域網 – slowlydance2me – 部落格園 (cnblogs.com)
前言:
2022/11/27
眾所周知,電腦網路在程式設計師的學習以及面試中佔據十分重要的位置,同時它也是我們開啟互聯網世界的鑰匙 。
。
因此,從今天(11/27)開始更新《漫談電腦網路》一文,讀者們可以跟著部落客一起深入淺出,了解電腦網路知識,學習電腦網路的應用。
部落客仍在不斷學習進步中,在本文中對於電腦網路的理解與認識尚淺,如有錯誤之處煩請批評指正。
如有疑問歡迎評論區留言。
正文分割線:
今天更新!11/29
漫談電腦網路:第四章-網路層
老規矩我們先來看看網路層在電腦網路體系結構中的位置

4.1 網路層的幾個重要概念
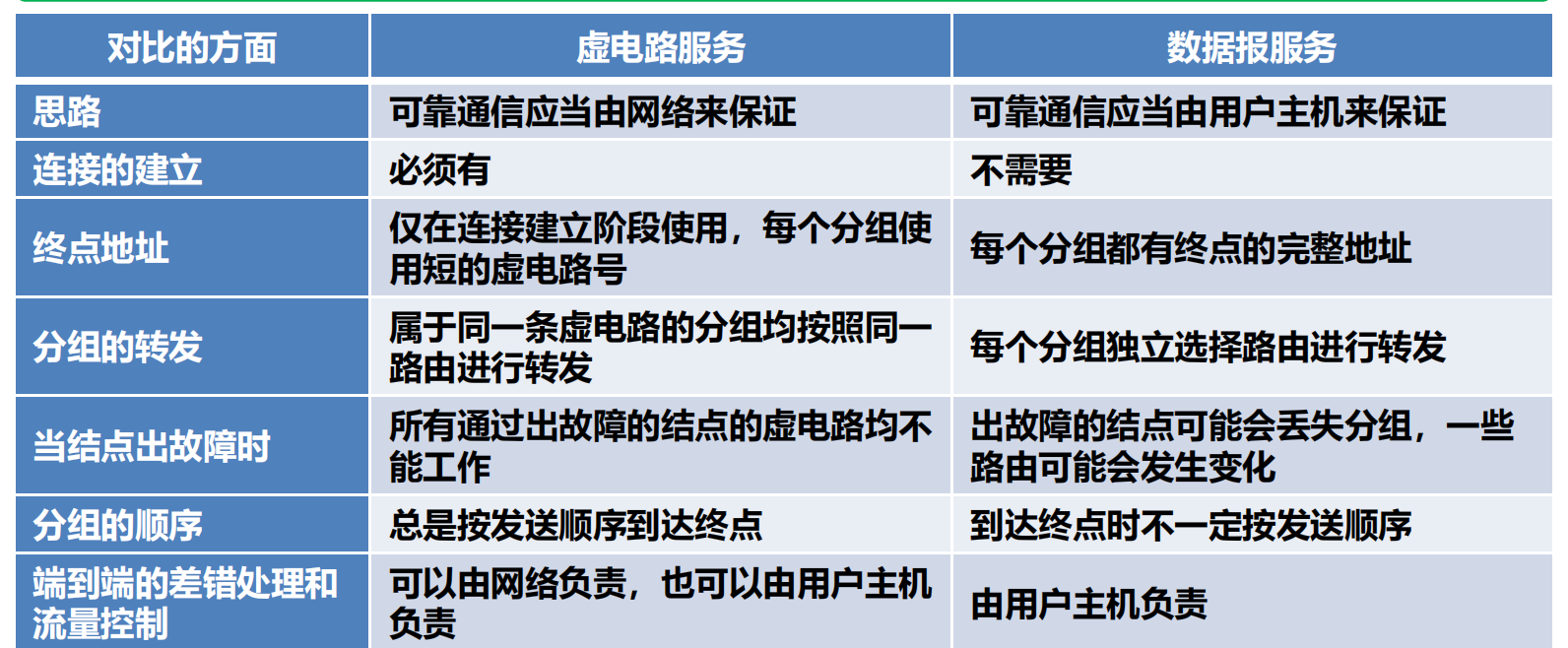
4.1.1 網路層提供的兩種服務
在網路層一開始的定義中有這兩種爭論:
爭論:
網路層應該向運輸層提供怎樣的服務?面向連接還是無連接?
在電腦通訊中,可靠交付應當由誰來負責?是網路還是端系統?
這兩種爭論分別對應以下這兩種觀點:
2 種觀點:
面向連接的可靠交付。
無連接的、盡最大努力交付的數據報服務,不提供服務品質的承諾。
接下來,讓我們分別來了解一下這兩種觀點:
一種觀點:讓網路負責可靠交付
電腦網路模仿電信網路,使用面向連接的通訊方式。
通訊之前先建立虛電路 VC (Virtual Circuit) (即連接),以保證雙方通訊所需的一切網路資源。
如果再使用可靠傳輸的網路協議,可使所發送的分組無差錯按序到達終點,不丟失、不重複。
什麼是虛電路服務?
如圖
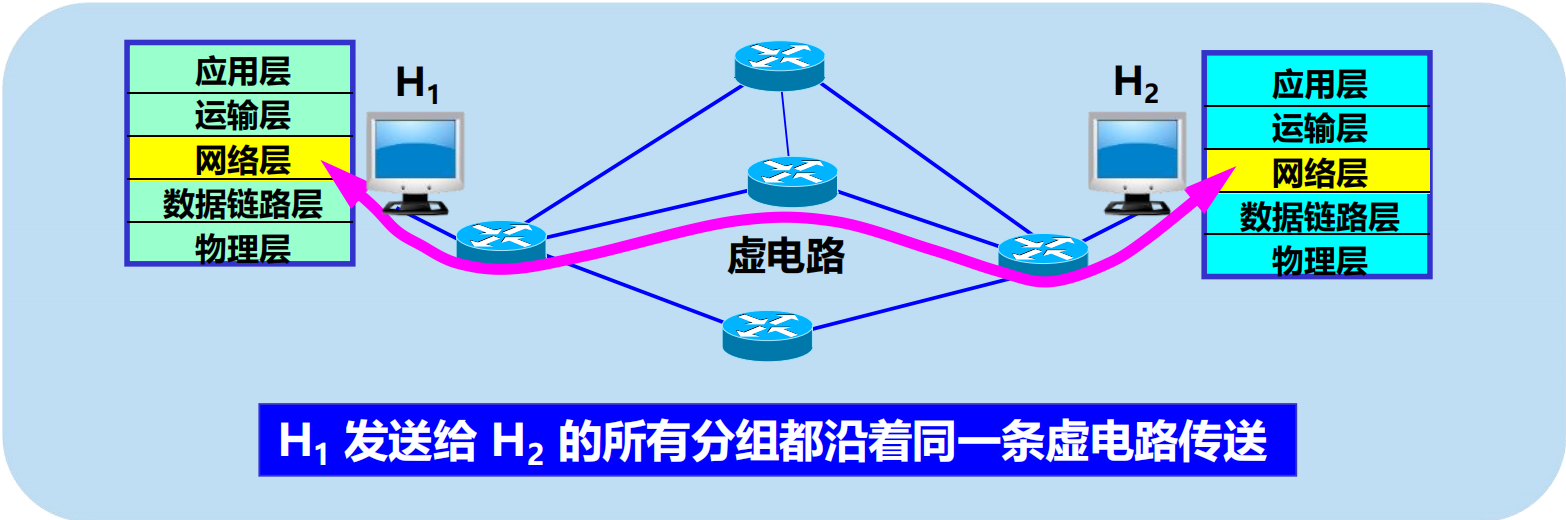
虛電路只是一條邏輯上的連接,分組都沿著這條邏輯連接按照存儲轉發方式傳送,並不是真正建立了一條物理連接
另一種觀點:網路提供數據報服務
互聯網採用的設計思路:
網路層要設計得盡量簡單,向其上層只提供簡單靈活的、無連接的、盡最大努力交付的數據報服務。
網路在發送分組時不需要先建立連接。
每一個分組(即 IP 數據報)獨立發送,與其前後的分組無關(不進行編號)。
網路層不提供服務品質的承諾。即所傳送的分組可能出錯、丟失、重複和失序(不按序到達終點),也不保證分組傳送的時限。
由主機中的運輸層負責可靠的通訊。
數據報服務如圖
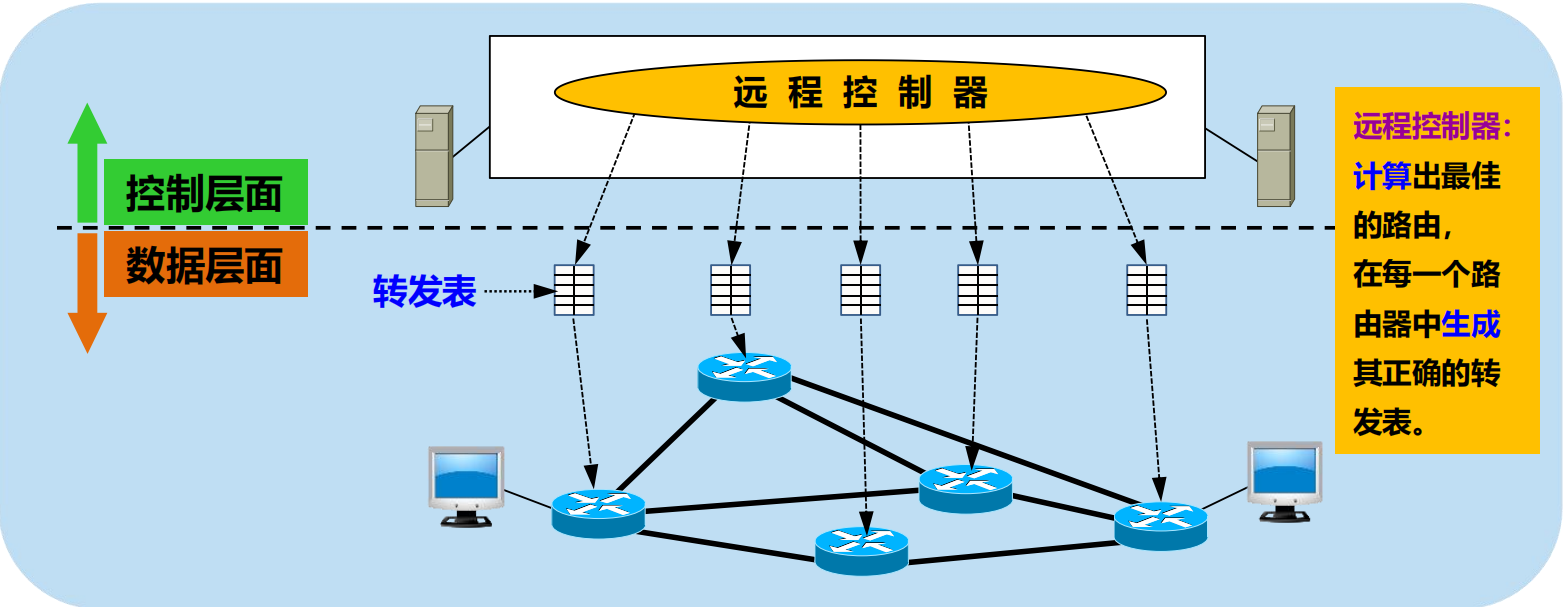
4.1.2 網路層的兩個層面
不同網路中的兩個主機之間的通訊,要經過若干個路由器轉發分組來完成。
在路由器之間傳送的資訊有以下 2 大類:
1. 數據。
2. 路由資訊(為數據傳送服務)。
網路層的 2 個層面:數據層面和控制層面
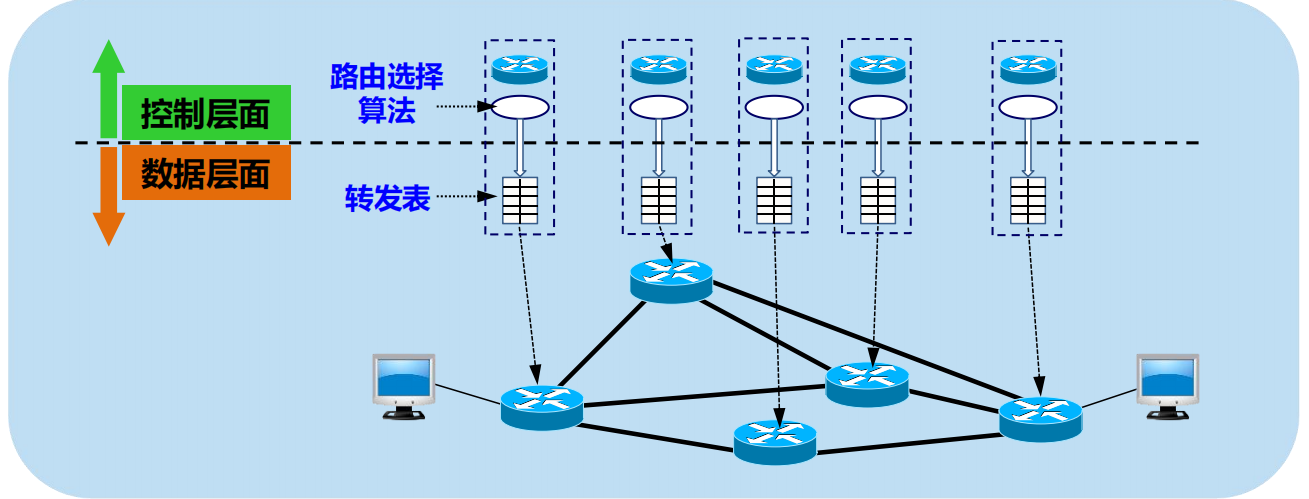
數據層面
• 路由器根據本路由器生成的轉發表,把收到的分組從查找到的對應介面轉發出去。
• 獨立工作。
• 採用硬體進行轉發,快。
控制層面
• 根據路由選擇協議所用的路由演算法計算路由,創建出本路由器的路由表。
• 許多路由器協同工作。
• 採用軟體計算,慢。
軟體定義網路 SDN (Software Defined Network)
4.2 網際協議 IP
與網際協議 IPv4 配套的 3 個協議:
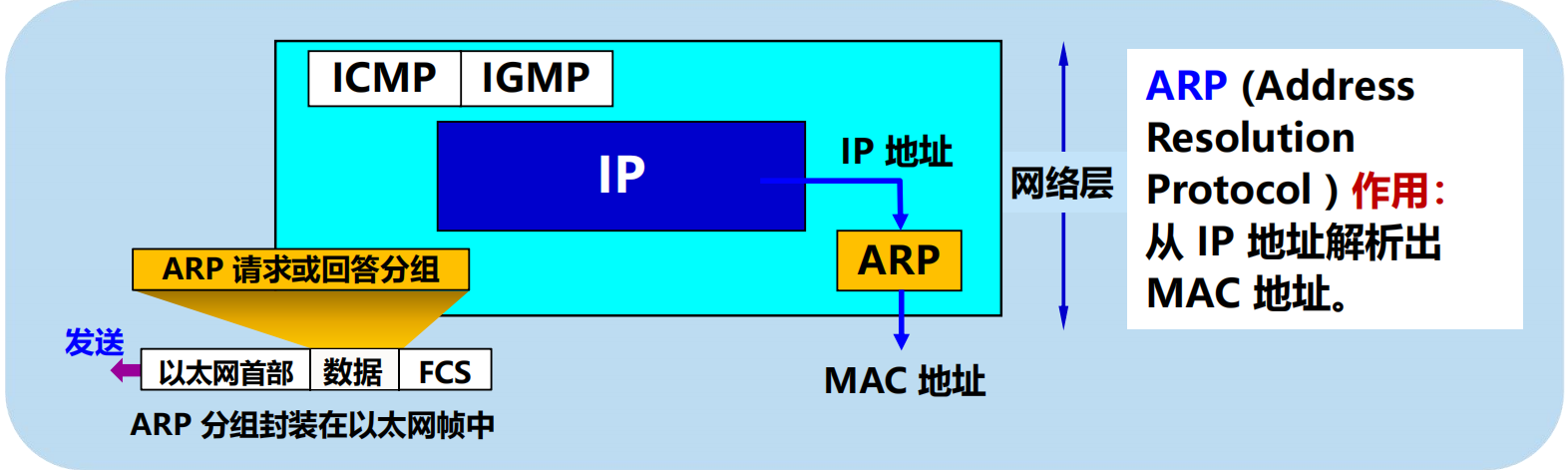
1. 地址解析協議 ARP (Address Resolution Protocol)
2. 網際控制報文協議 ICMP (Internet Control Message Protocol)
3. 網際組管理協議 IGMP (Internet Group Management Protocol)
4.2.1 虛擬互連網路
實現網路互連、互通時需要解決許多問題,如以下「不同」:

如何將異構的網路互相連接起來?
實現異構網路的互連互通方法,哪種好?

使用中間設備進行設備互連
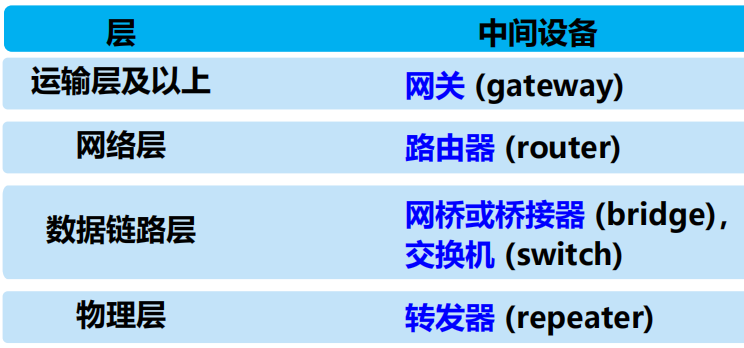
注意:
使用轉發器或網橋不稱為網路互連
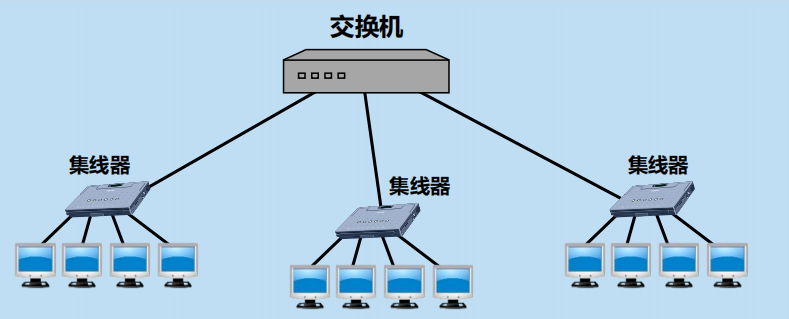
轉發器、網橋或交換機僅把一個網路擴大了,仍然是一個網路
互連網路與虛擬互連網路
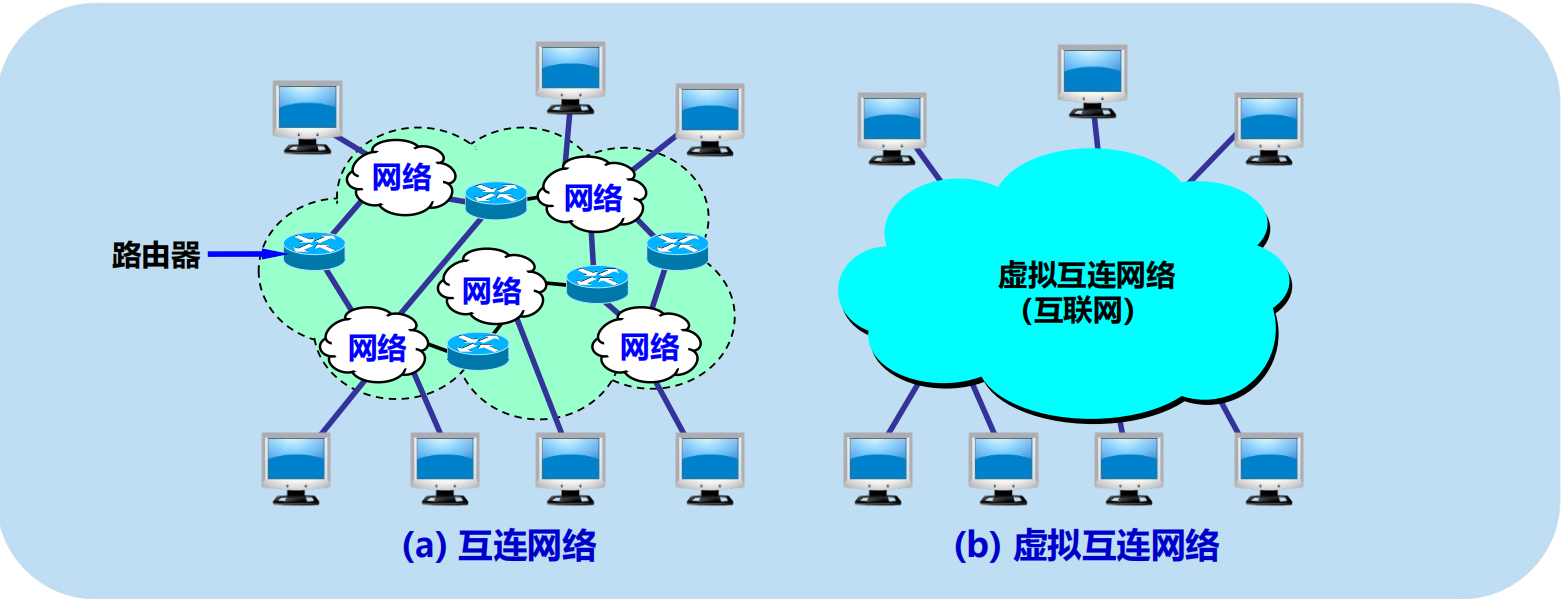
IP 網的概念
IP 網的意義
當互聯網上的主機進行通訊時,就好像在一個網路上通訊一樣,看不見互連的各具體的網路異構細節。
如果在這種覆蓋全球的 IP 網的上層使用 TCP 協議,那麼就是現在的互聯網 (Internet)
4.2.2 IP 地址
在 TCP/IP 體系中,IP 地址是一個最基本的概念。
沒有IP地址,就無法和網上的其他設備進行通訊。
本部分重點
:
1. IP 地址及其表示方法
點分十進位:
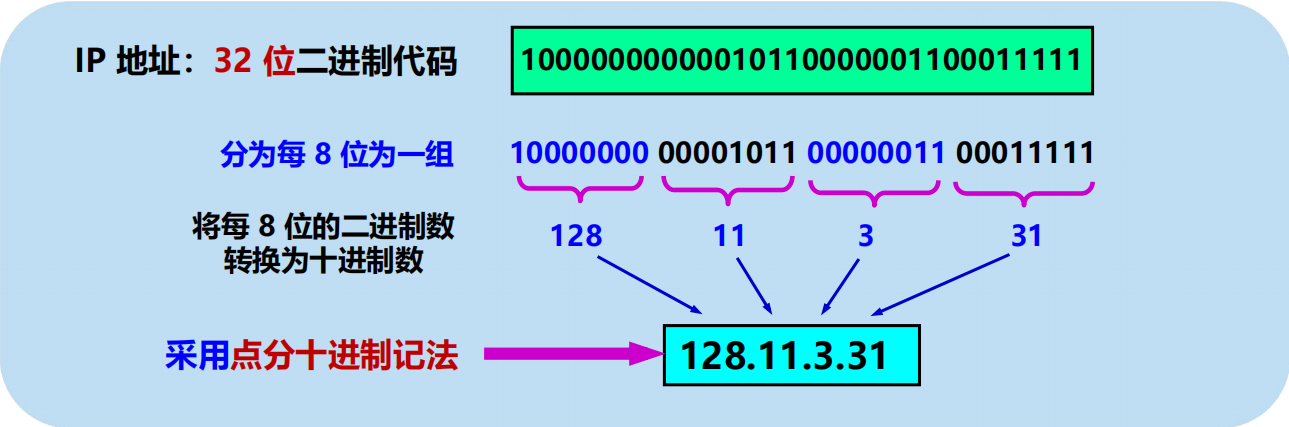
互聯網上的每台主機(或路由器)的每個介面分配一個在全世界唯一的 IP 地址。由互聯網名字和數字分配機構 ICANN (Internet Corporation for AssignedNames and Numbers) 進行分配。
點分十進位舉例:

IP 地址採用 2 級結構
2 級結構
2 個欄位:網路號和主機號

IP地址在整個互聯網範圍內是唯一的。
IP 地址指明了連接到某個網路上的一個主機
2. 分類的 IP 地址

各類 IP 地址的網路號欄位和主機號欄位
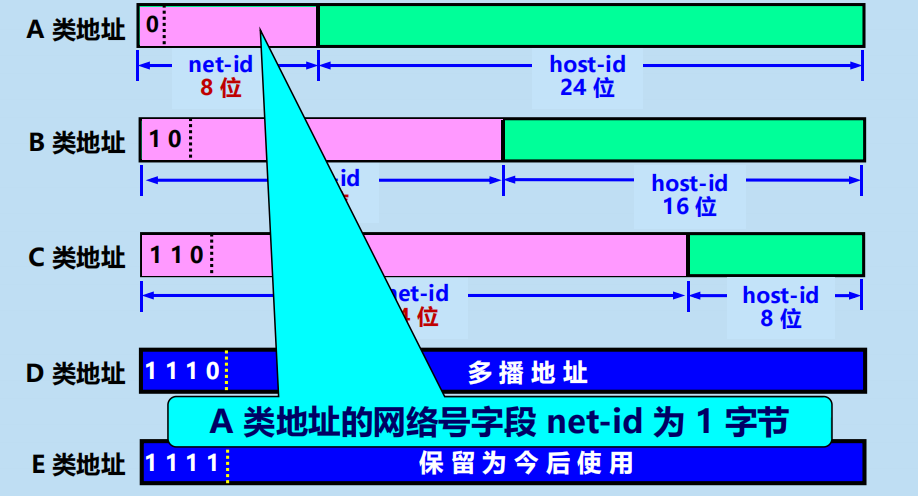
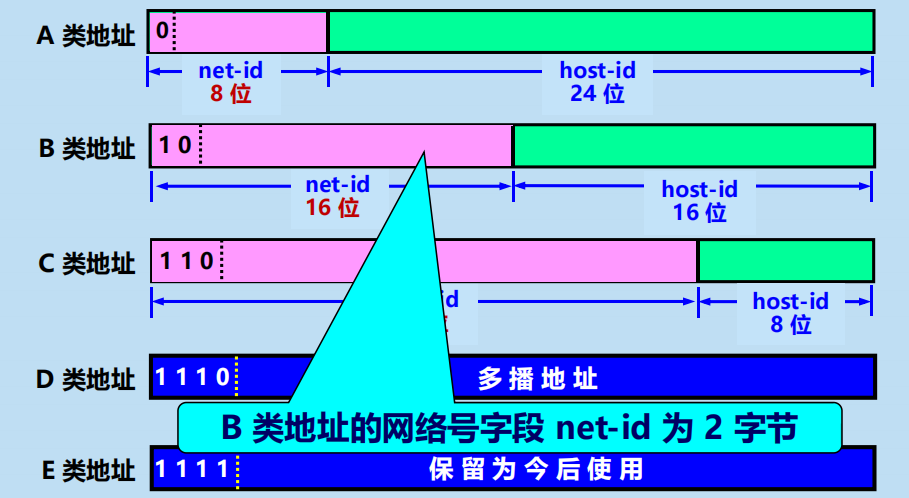

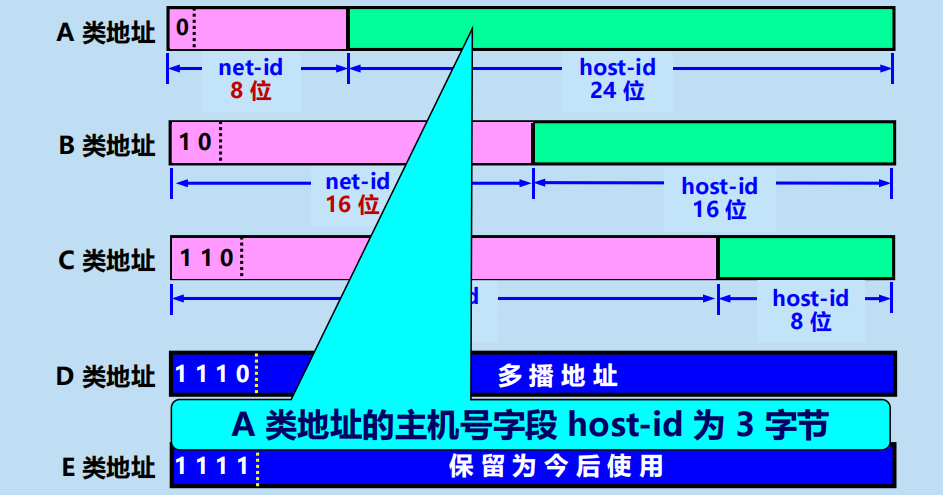

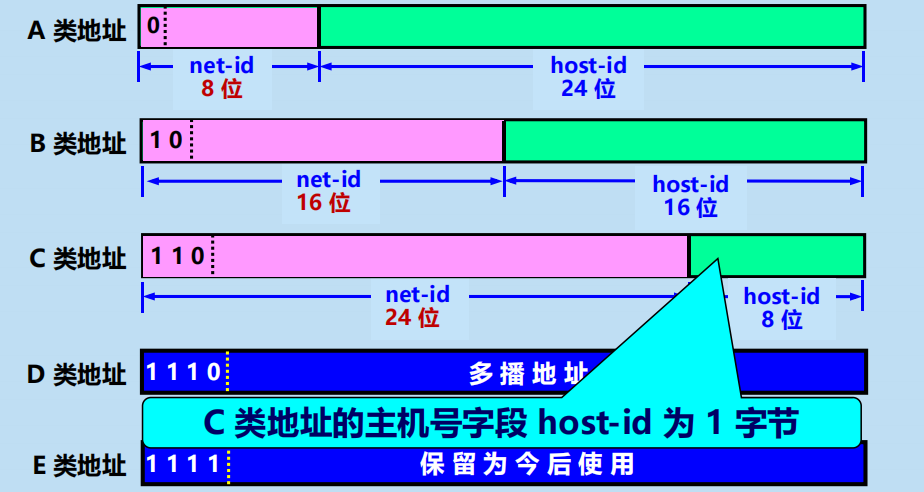
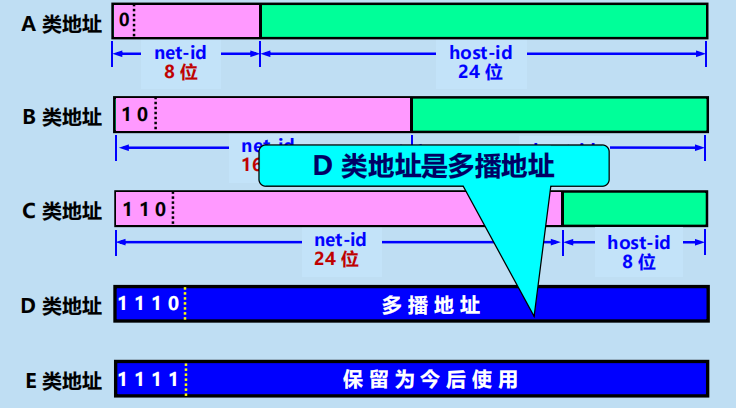
各類 IP 地址的指派範圍:
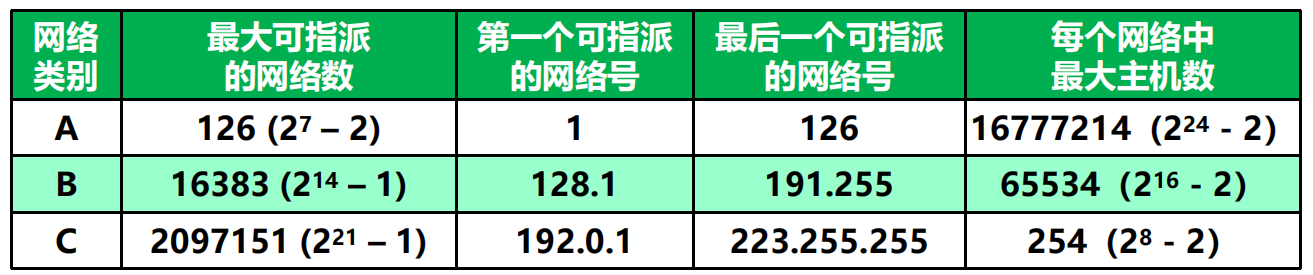

一般不使用的特殊的 IP 地址
分類的 IP 地址的優點和缺點

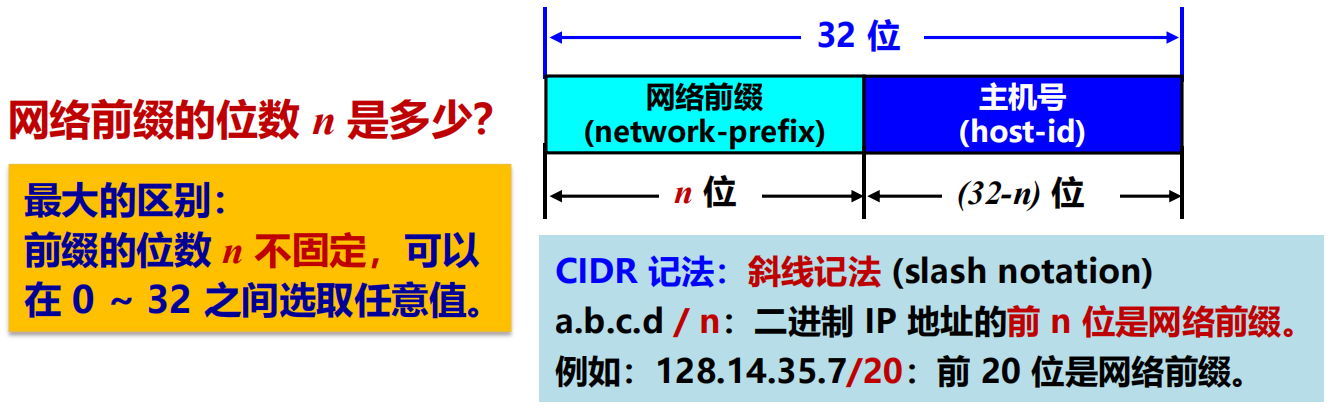
3. 無分類編址 CIDR
CIDR (Classless Inter-Domain Routing) :無分類域間路由選擇。
消除了傳統的 A 類、B 類和 C 類地址以及劃分子網的概念,可以更加有效地分配 IPv4 的地址空間,但無法解決 IP 地址枯竭的問題。
要點:
(1) 網路前綴
2 級結構
(2) 地址塊
CIDR 把網路前綴都相同的所有連續的 IP 地址組成一個 CIDR 地址塊。
一個 CIDR 地址塊包含的 IP 地址數目,取決於網路前綴的位數n。 232-n – 2 個可派地址

二進位程式碼表示:10000000 00001110 0010*
地址與地址塊識別規範

(3) 地址掩碼
又稱為子網掩碼 (subnet mask)。
位數:32 位。
目的:讓機器從 IP 地址迅速算出網路地址。
由一連串 1 和接著的一連串 0 組成,而 1 的個數就是網路前綴的長度。

默認地址掩碼
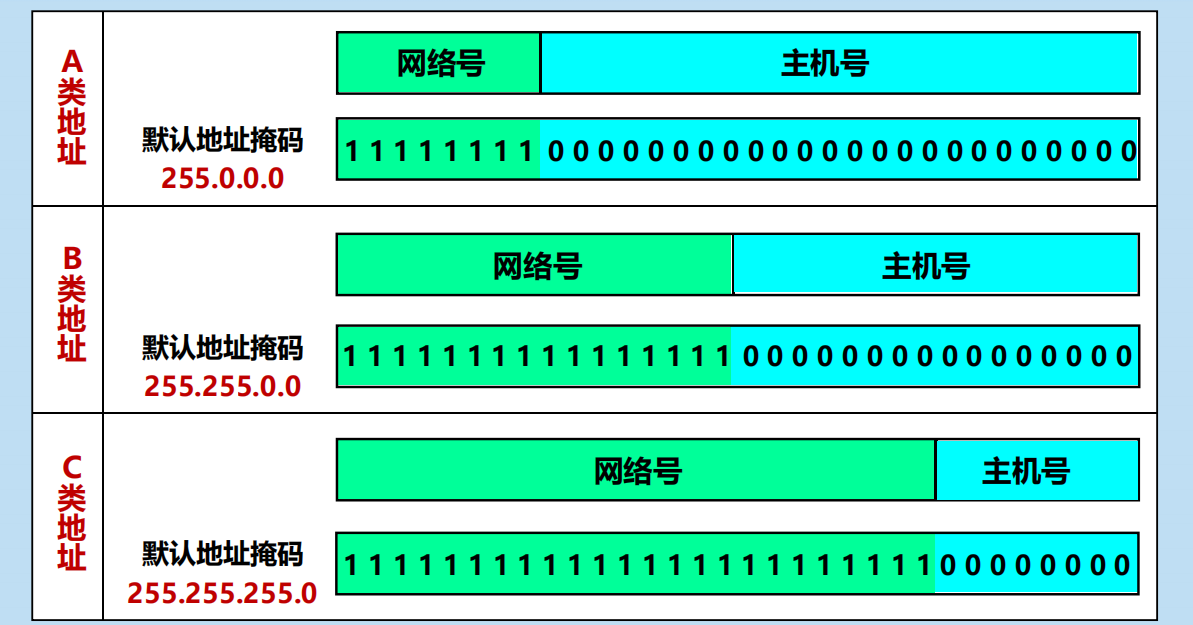
網路地址 = (二進位的 IP 地址) AND (地址掩碼)
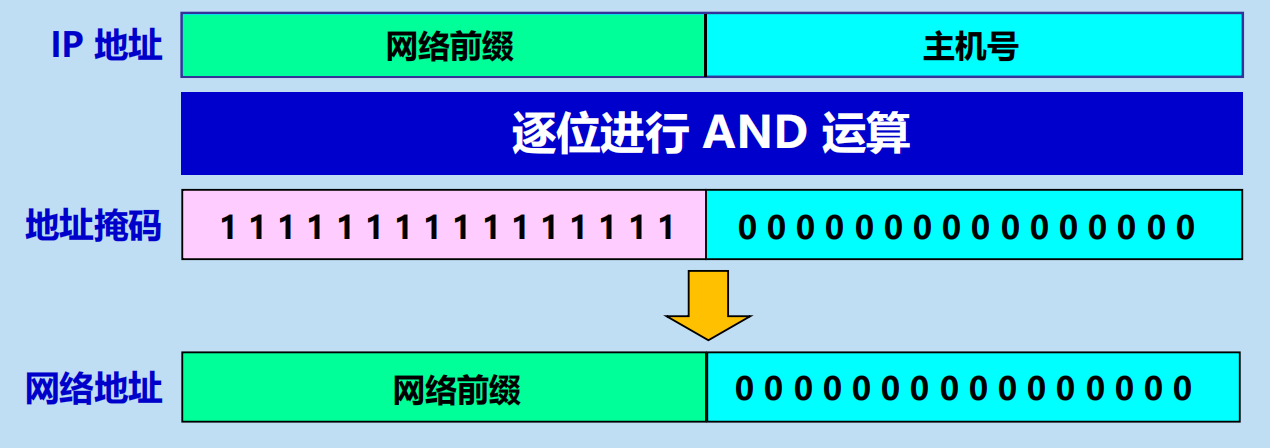
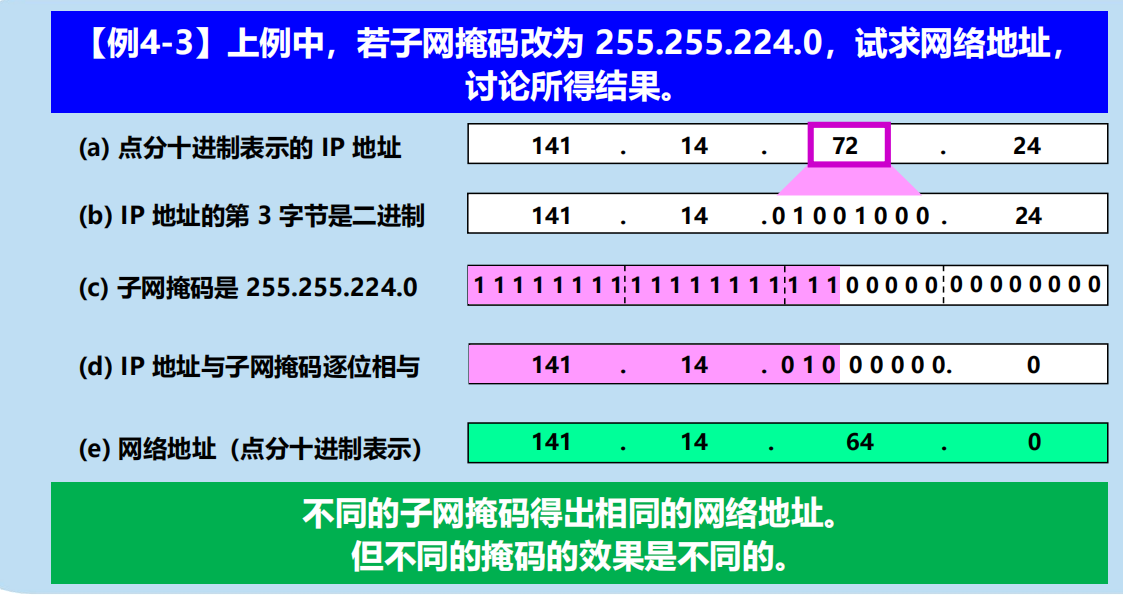
例題:

補充:
常用的 CIDR 地址塊
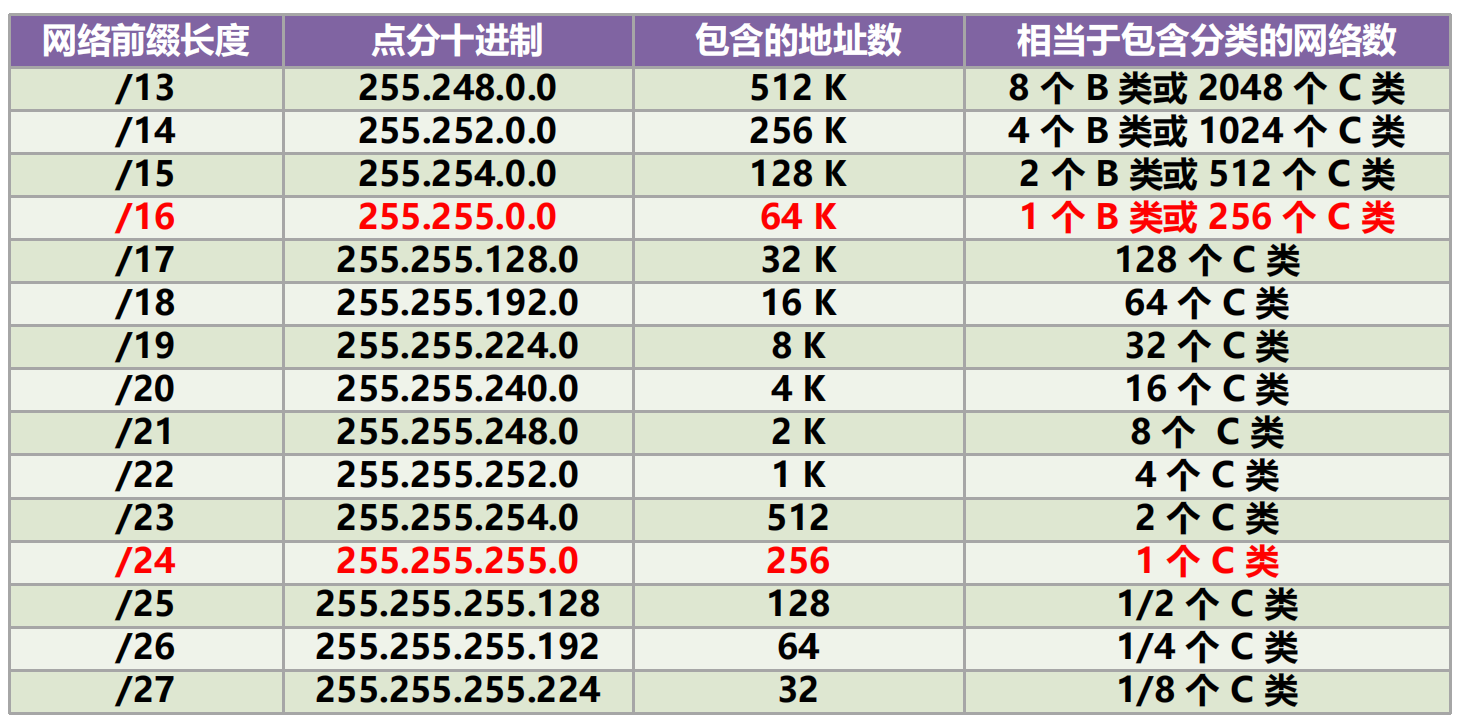
構造超網
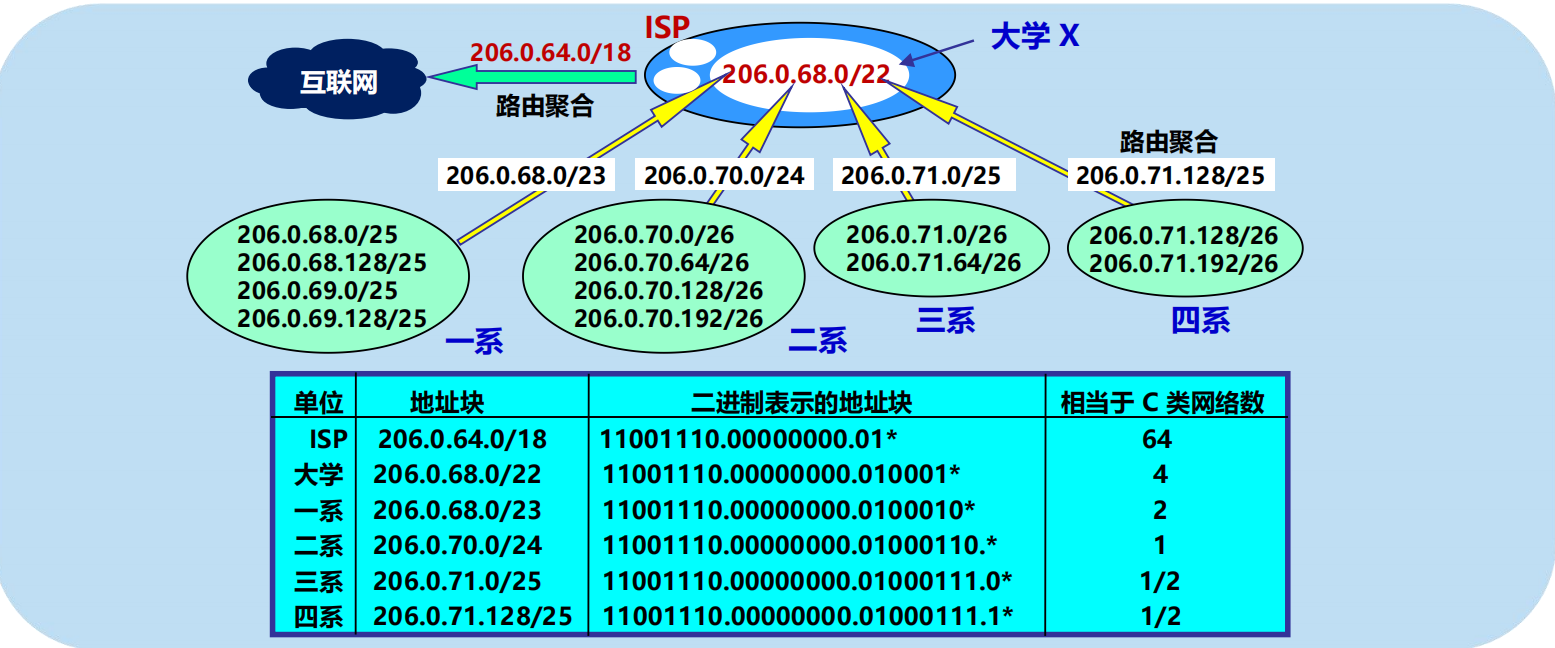
每一個 CIDR 地址塊中的地址數一定是 2 的整數次冪。

上圖中除最後幾行外,CIDR 地址塊都包含了多個 C 類地址(是一個 C 類地址的 2n 倍,n 是整數)。
因此在文獻中有時稱 CIDR 編址為「構造超網」 。
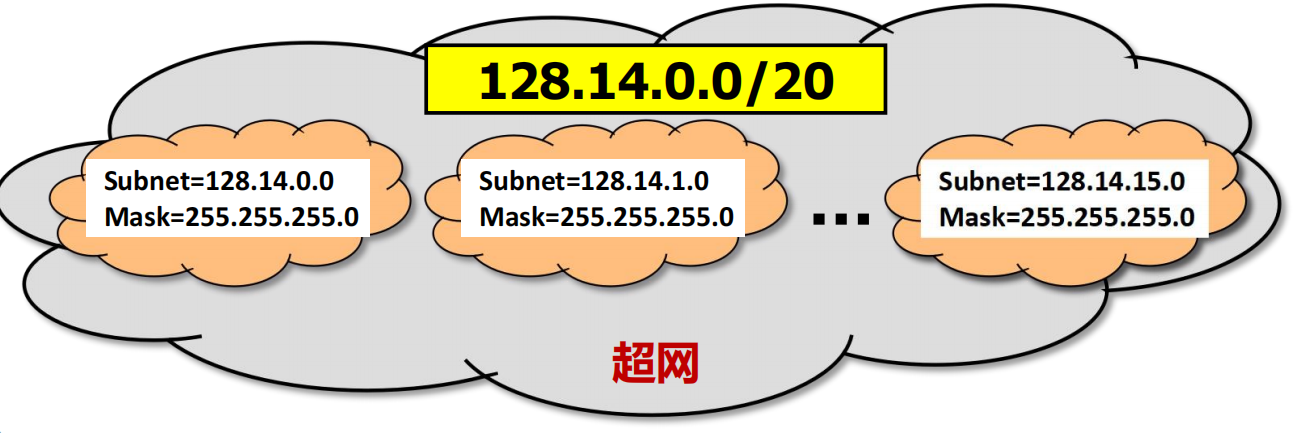
三個特殊的 CIDR 地址塊

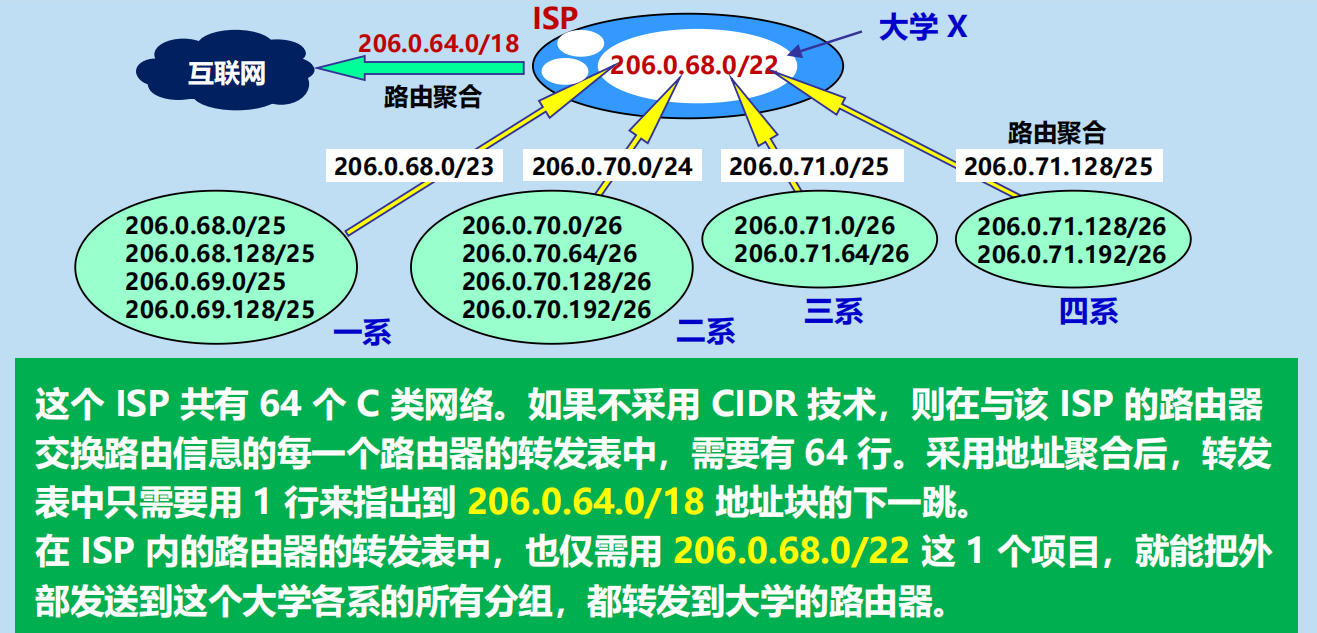
路由聚合 (route aggregation)
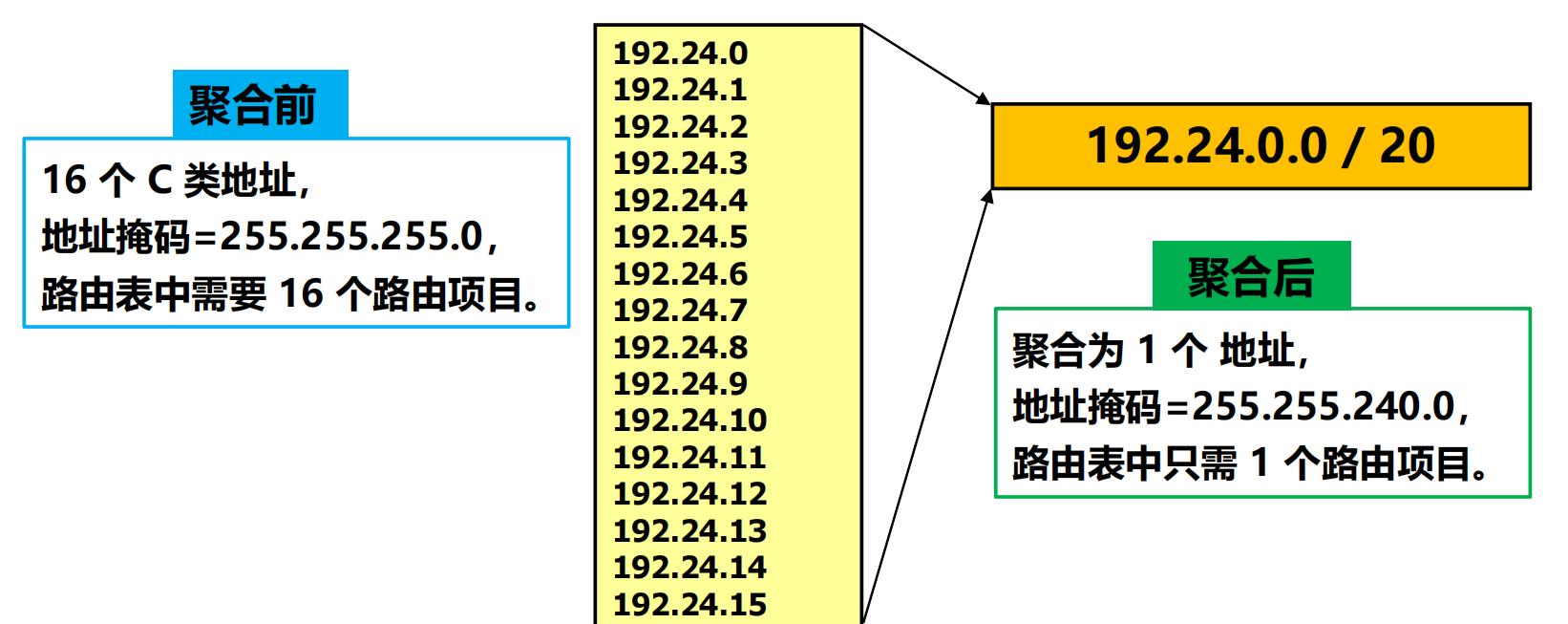
CIDR 地址塊劃分舉例
4. IP 地址的特點
(1) 每個 IP 地址都由網路前綴和主機號兩部分組成。
IP 地址是一種分等級的地址結構。
方便了 IP 地址的分配和管理。
實現路由聚合,減小了轉發表所佔的存儲空間,以及查找轉發表的時間。
(2) IP 地址是標誌一台主機(或路由器)和一條鏈路的介面。
當一台主機同時連接到兩個網路上時,該主機就必須同時具有兩個相應的 IP
地址,其網路號必須是不同的。這種主機稱為多歸屬主機 (multihomed host)。
一個路由器至少應當連接到兩個網路,因此一個路由器至少應當有兩個不同的 IP 地址。
(3) 轉發器或交換機連接起來的若干個區域網仍為一個網路
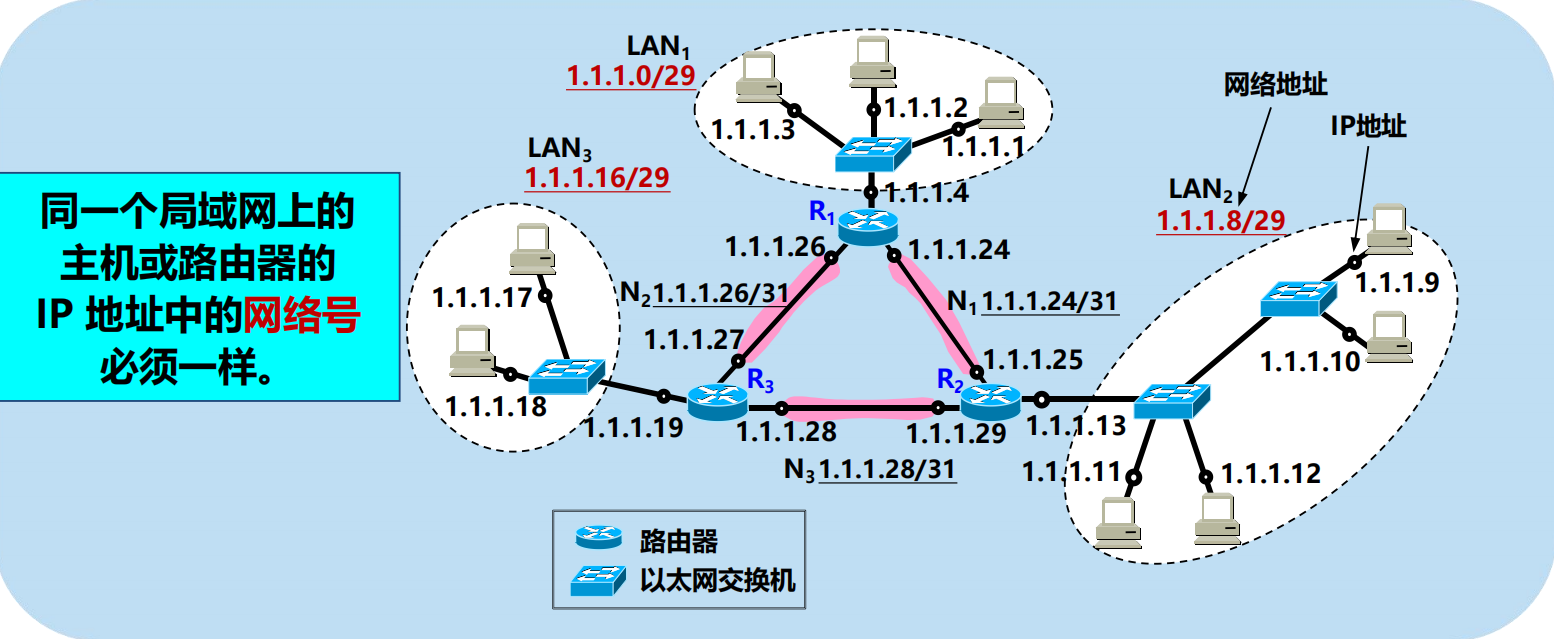
按照互聯網的觀點,一個網路(或子網)是指具有相同網路前綴的主機的集合。
轉發器或交換機連接起來的若干個區域網都具有同樣的網路號,它們仍為一個網路。
具有不同網路號的區域網必須使用路由器進行互連。
(4) 在 IP 地址中,所有分配到網路前綴的網路都是平等的。
互聯網同等對待每一個 IP 地址,不管是範圍很小的區域網,還是可能覆蓋很大地理範圍的廣域網
4.2.3 IP 地址與 MAC 地址
IP 地址
• 虛擬地址、軟體地址、邏輯地址。
• 網路層和以上各層使用。
• 放在 IP 數據報的首部。
MAC 地址
• 固化在網卡上的 ROM 中。
• 硬體地址、物理地址。
• 數據鏈路層使用。
• 放在 MAC 幀的首部』
IP 地址與 MAC 地址的區別
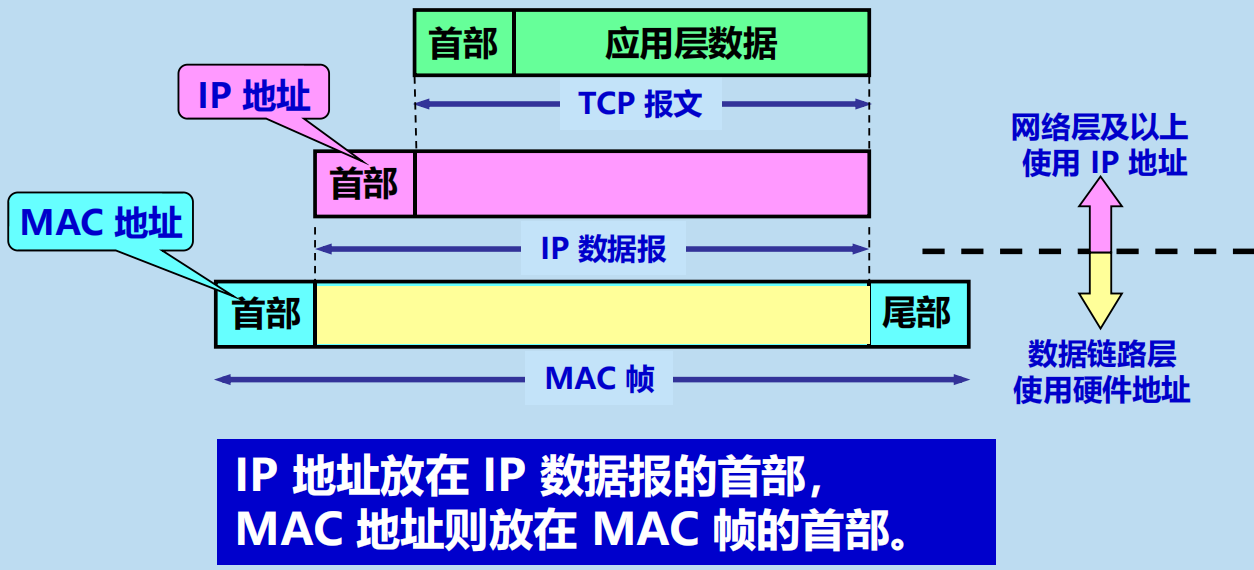

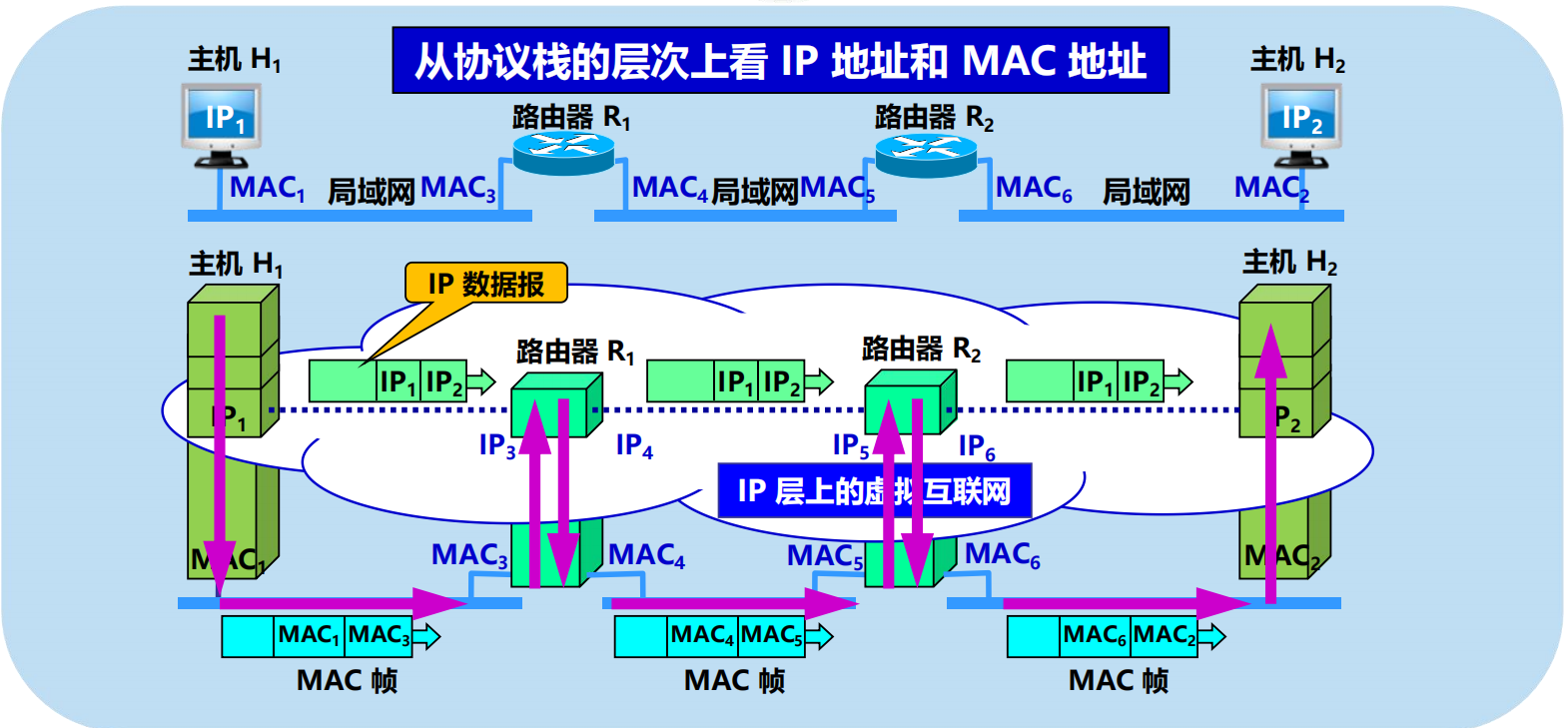
不同層次、不同區間使用的源地址和目的地址
儘管互連在一起的網路的 MAC 地址體系各不相同,但 IP 層抽象的互聯網卻屏蔽了下層這些很複雜的細節。
只要我們在網路層上討論問題,就能夠使用統一的、抽象的 IP 地址研究主機和主機或路由器之間的通訊。
問題:
主機或路由器怎樣知道應當在 MAC 幀的首部填入什麼樣的 MAC 地址?下一節告訴你答案
4.2.4 地址解析協議 ARP
實現 IP 通訊時使用了兩個地址:
1. IP 地址(網路層地址)
2. MAC 地址(數據鏈路層地址)
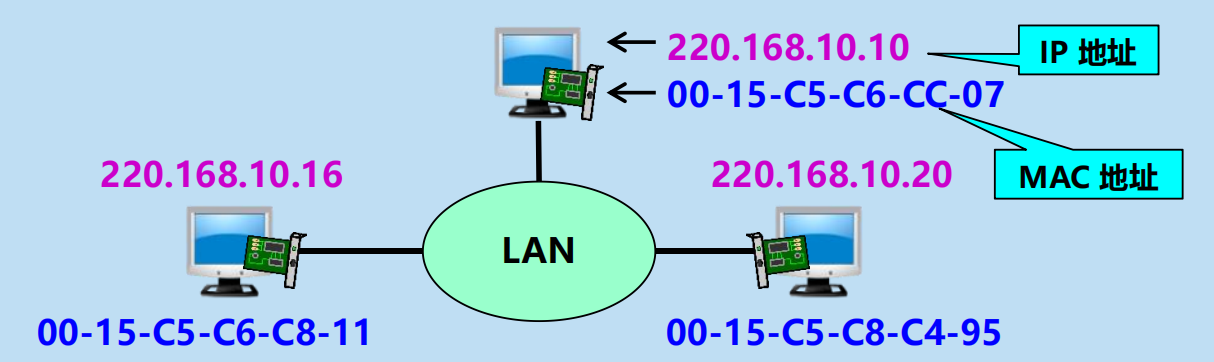
問題:已經知道了一個機器(主機或路由器)的 IP 地址,如何找出其相應的 MAC 地址?
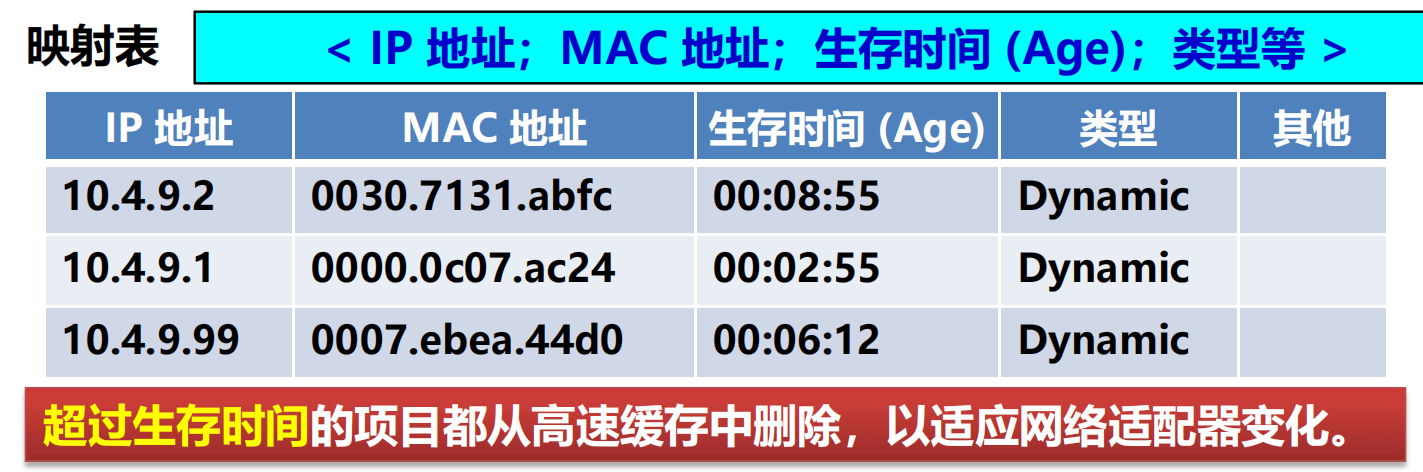
ARP 高速快取 (ARP cache)
存放 IP 地址到 MAC 地址的映射表。
映射表動態更新(新增或超時刪除)。
ARP 工作流程
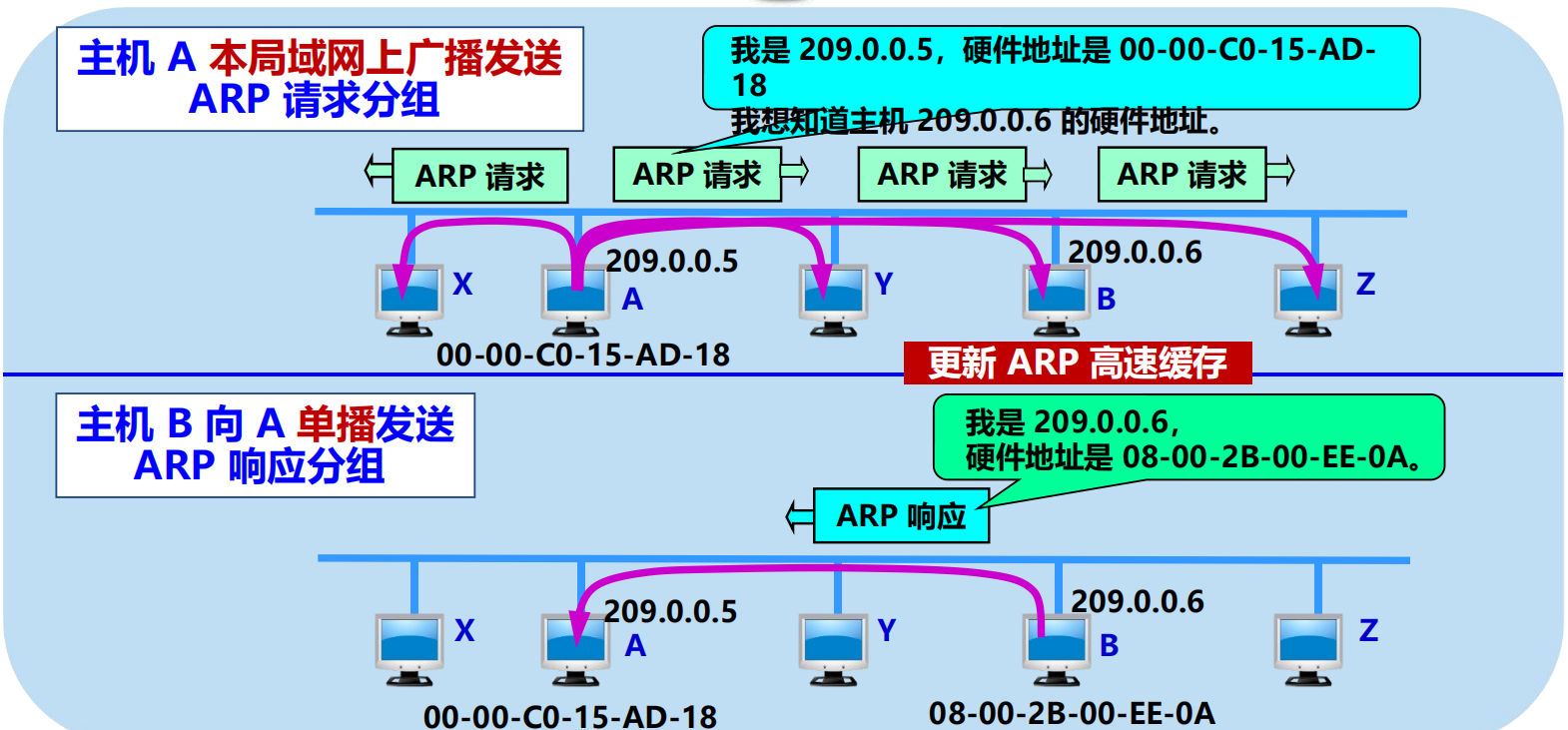
當主機 A 欲向本區域網上的某個主機 B 發送 IP 數據報時:

ARP 查找 IP 地址對應的 MAC地址
本區域網上廣播發送 ARP 請求(路由器不轉發 ARP 請求)。
ARP 請求分組:包含發送方硬體地址 / 發送方 IP 地址 / 目標方硬體地址(未知時填 0) / 目標方 IP 地址。
單播 ARP 響應分組:包含發送方硬體地址 / 發送方 IP地址 / 目標方硬體地址 / 目標方 IP 地址。
ARP 分組封裝在乙太網幀中傳輸。

ARP 高速快取的作用
存放最近獲得的 IP 地址到 MAC 地址的綁定。
減少 ARP 廣播的通訊量。
為進一步減少 ARP 通訊量,主機 A 在發送其 ARP 請求分組時,就將自己的 IP 地址到 MAC 地址的映射寫入 ARP 請求分組。
當主機 B 收到 A 的 ARP 請求分組時,就將主機 A 的 IP 地址及其對應的 MAC 地址映射寫入主機 B 自己的 ARP 高速快取中。不必再發送 ARP 請求。
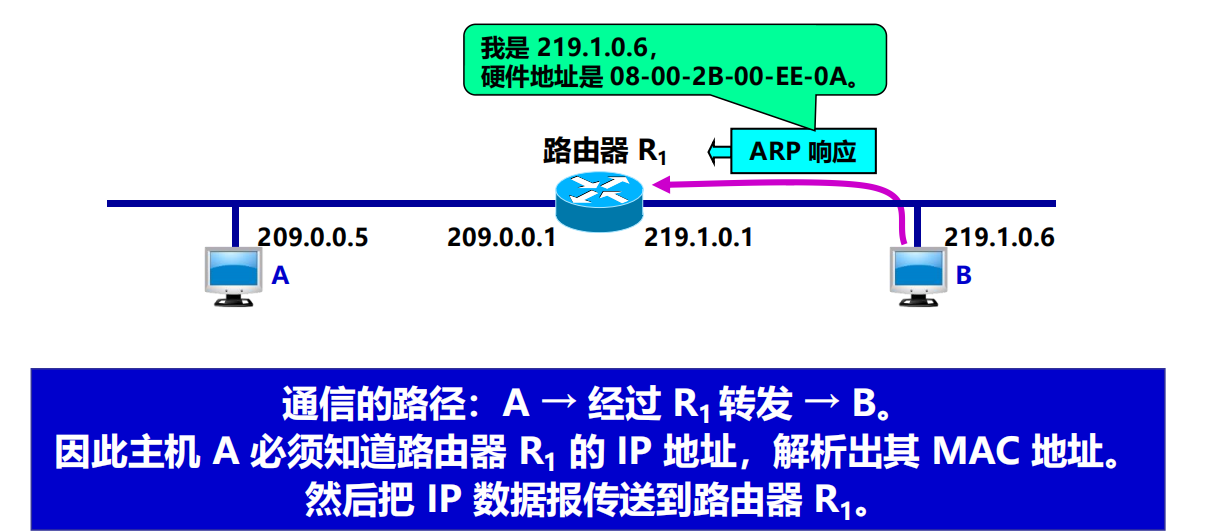
2 台主機不在同一個區域網上怎麼辦?

過程演示如下



使用 ARP 的四種典型情況
1. 發送方是主機,要把 IP 數據報發送到本網路上的另一個主機。這時用 ARP 找到目的主機的硬體地址。
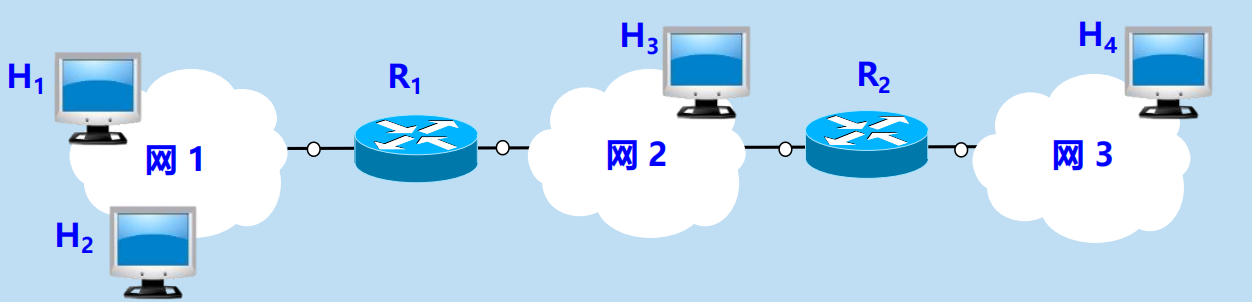
2. 發送方是主機,要把 IP 數據報發送到另一個網路上的一個主機。這時用 ARP 找到本網路上的一個路由器的硬體地址。剩下的工作由這個路由器來完成。
3. 發送方是路由器,要把 IP 數據報轉發到本網路上的一個主機。這時用 ARP 找到目的主機的硬體地址。
4. 發送方是路由器,要把 IP 數據報轉發到另一個網路上的一個主機。這時用 ARP 找到本網路上另一個路由器的硬體地址。剩下的工作由這個路由器來完成。
靈魂拷問:為什麼要使用兩種地址:IP 地址和 MAC 地址?
不同網路不同的 MAC 地址。MAC 地址之間的轉換非常複雜。
對乙太網 MAC 地址進行定址也是極其困難的。
IP 編址把這個複雜問題解決了。
連接到互聯網的主機只需各自擁有一個唯一的 IP 地址,它們之間的通訊就像連接在同一個網路上那樣簡單方便,即使必須多次調用 ARP 來找到 MAC 地址,但這個過程都是由電腦軟體自動進行的,對用戶來說是看不見的。
因此,在虛擬的 IP 網路上用 IP 地址進行通訊非常方便。
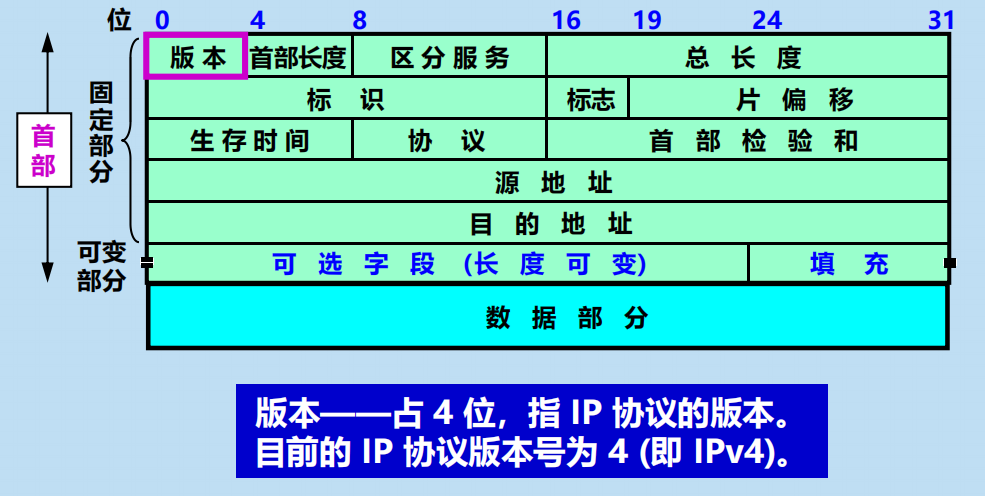
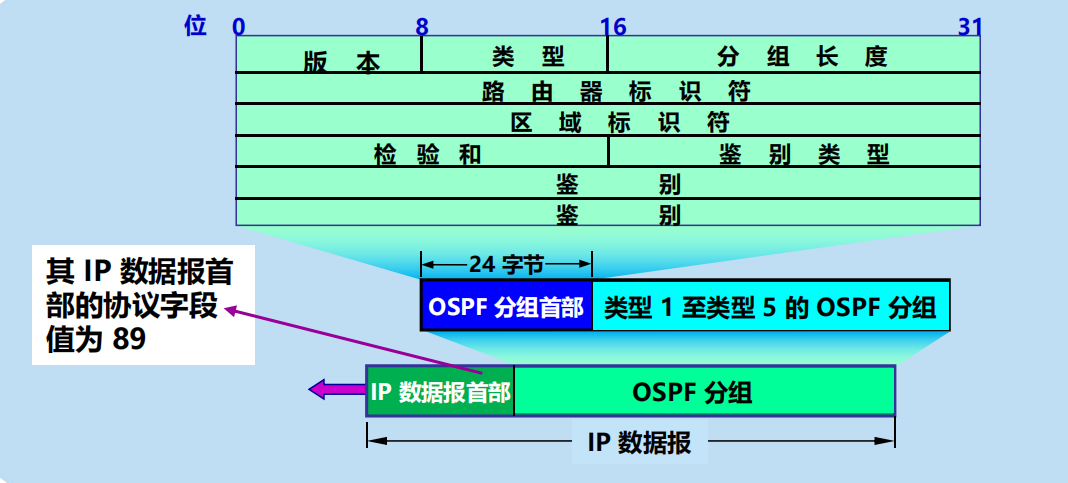
4.2.5 IP 數據報的格式
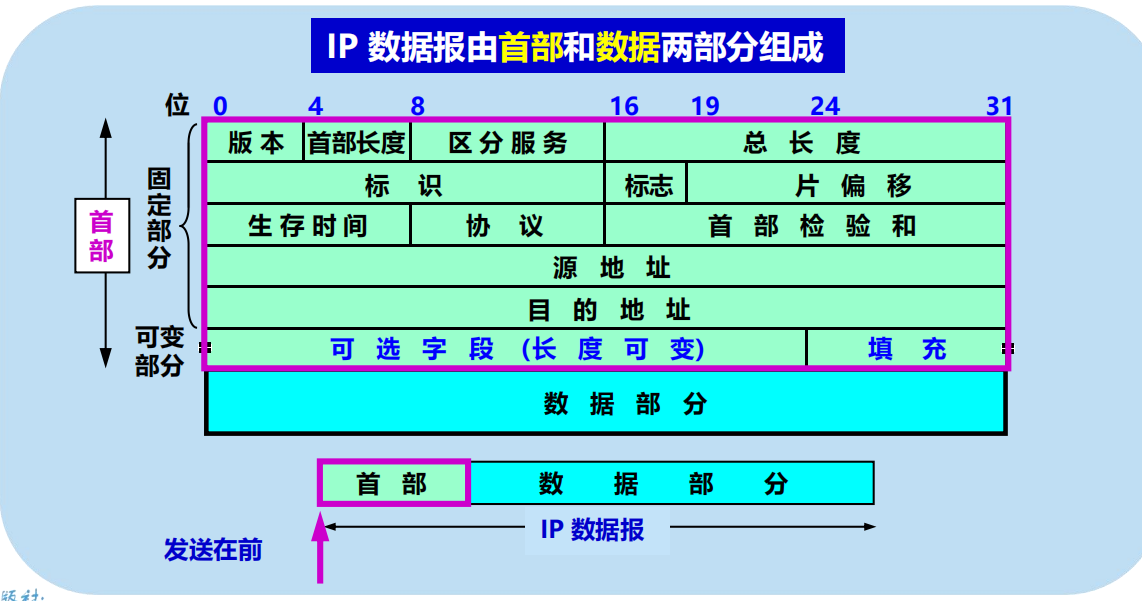
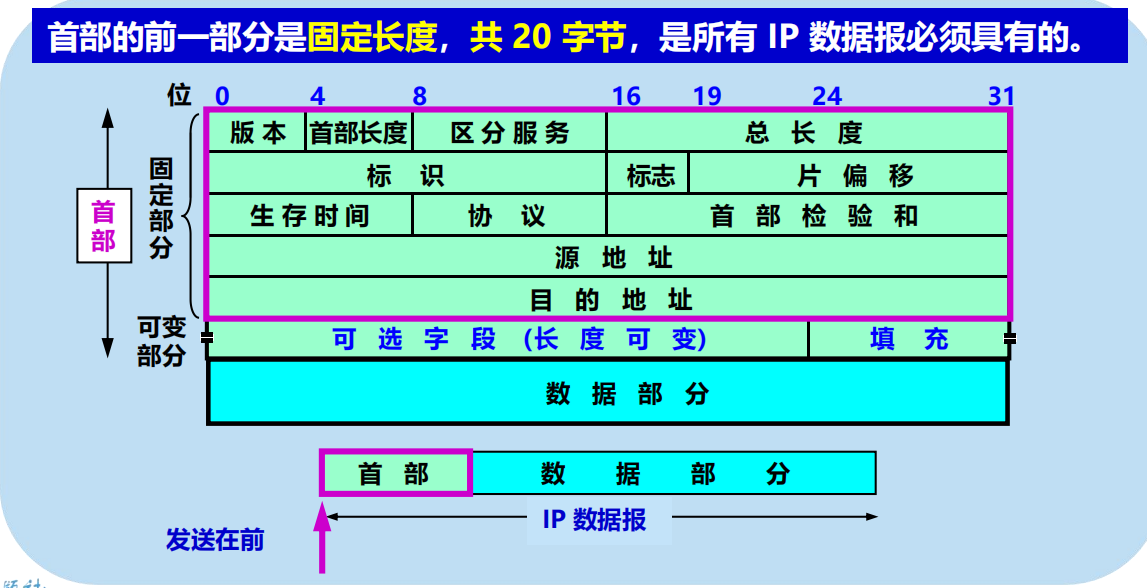
IP 數據報首部的固定部分中的各欄位
如圖




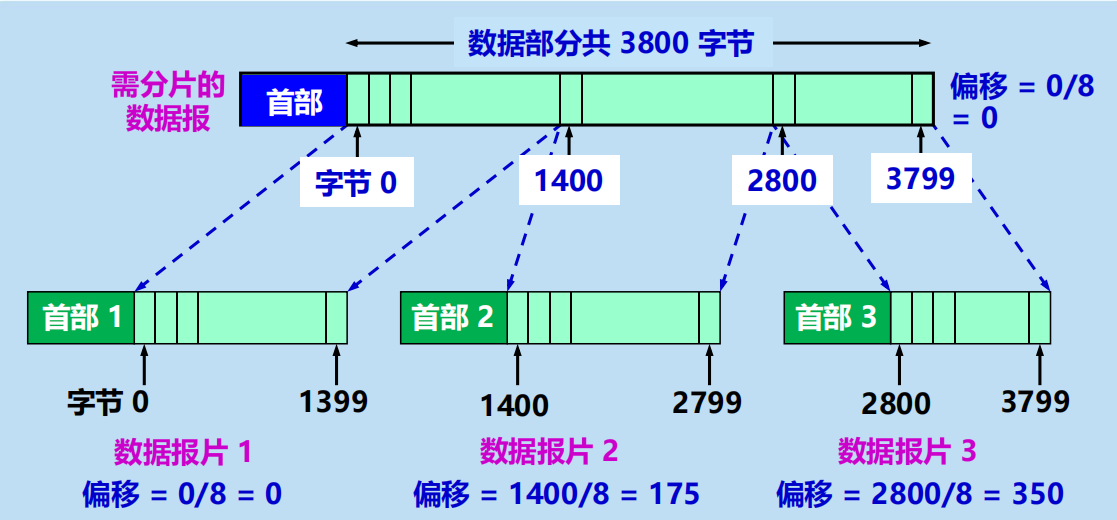
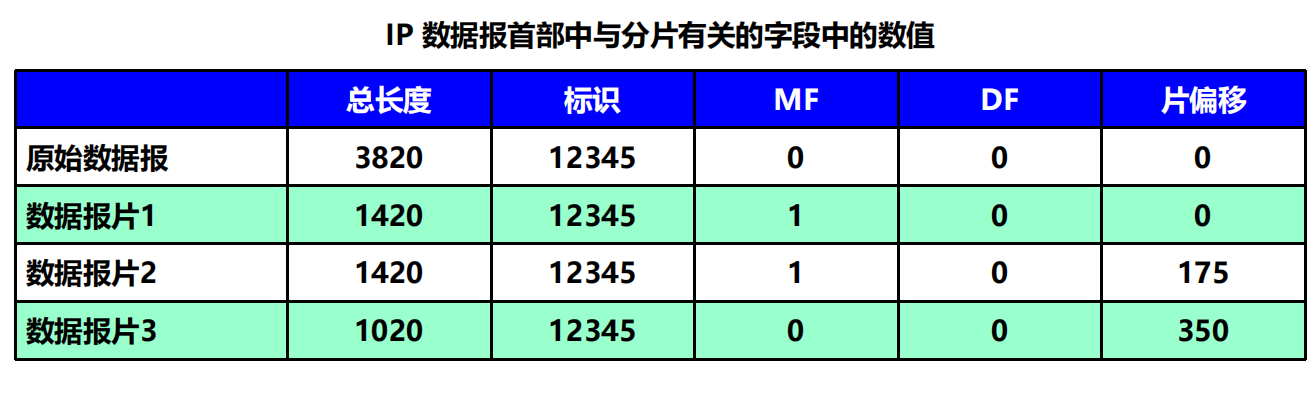
【例4-1】 IP 數據報分片


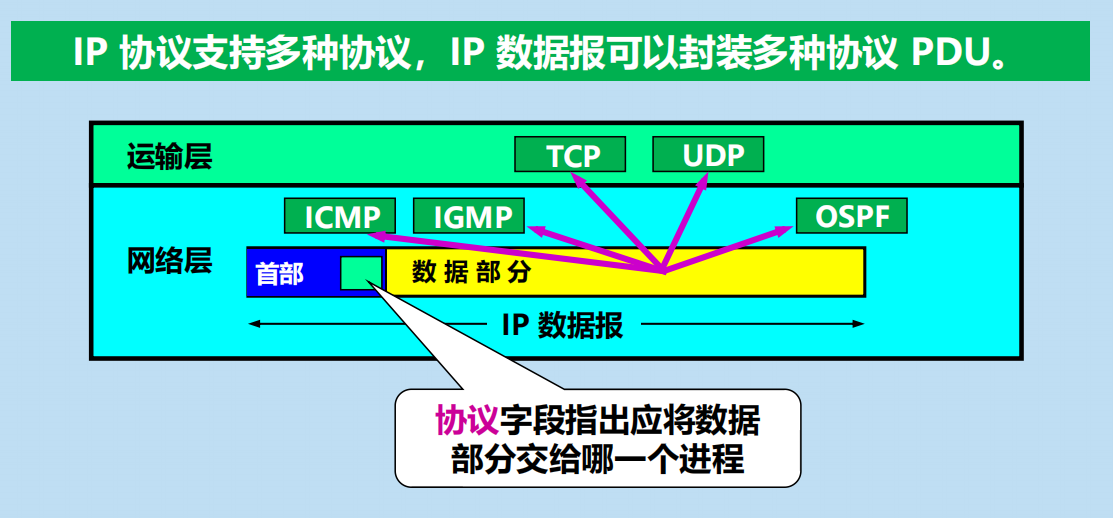
IP 協議支援多種協議,IP 數據報可以封裝多種協議 PDU。
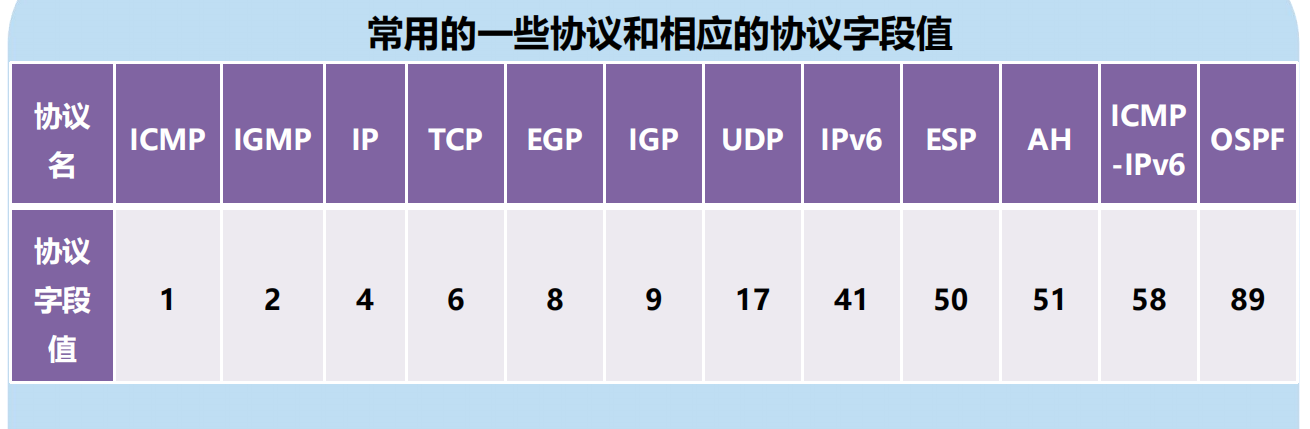
常用的一些協議和相應的協議欄位值

數據報每經過一個路由器,路由器都要重新計算一下首部檢驗和


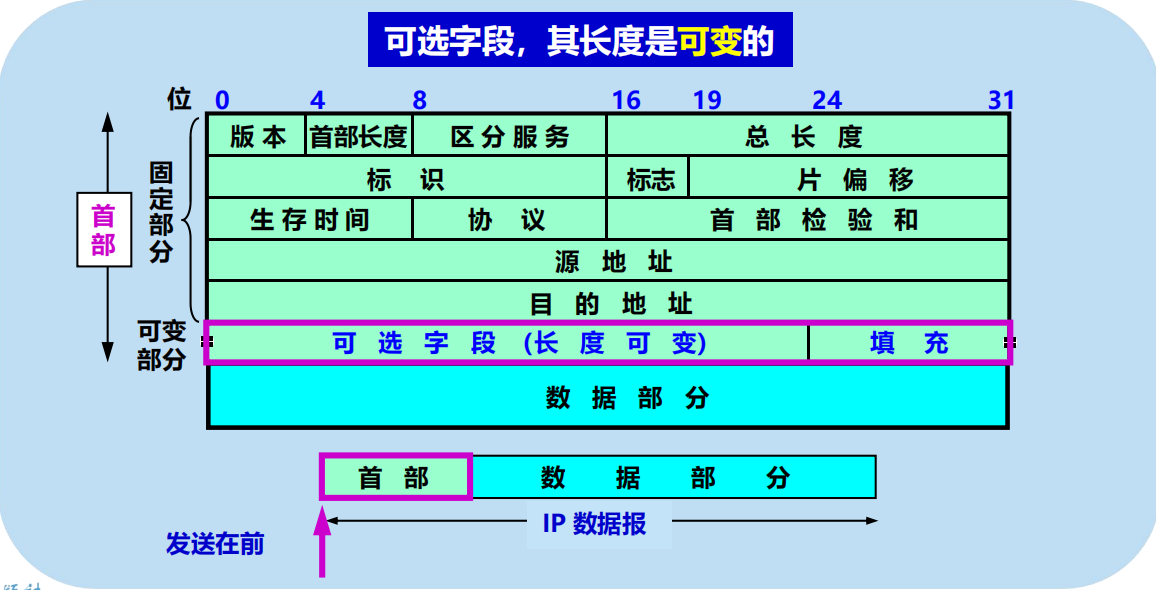
IP 數據報首部的可變部分
IP 首部的可變部分就是一個選項欄位,用來支援排錯、測量以及安全等措施,內容很豐富。
長度可變:從 1 個位元組到 40 個位元組不等,取決於所選擇的項目。
增加了 IP 數據報的功能,但這同時也使得 IP 數據報的首部長度成為可變的,增加了每一個路由器處理數據報的開銷。
實際上這些選項很少被使用。
重點在這裡
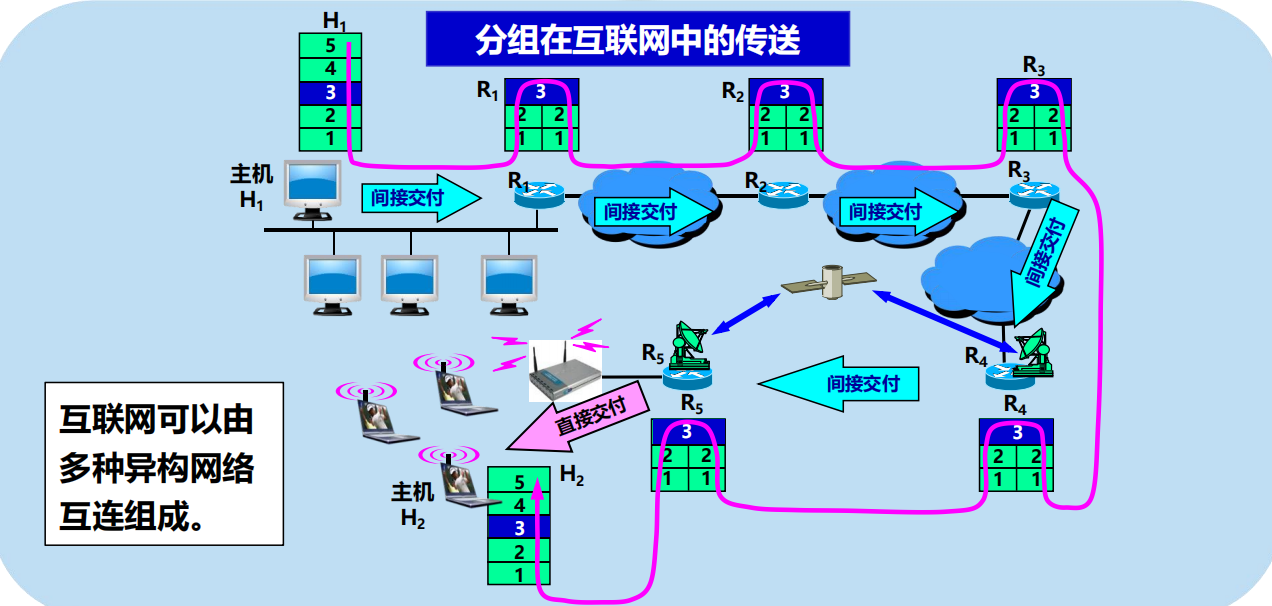
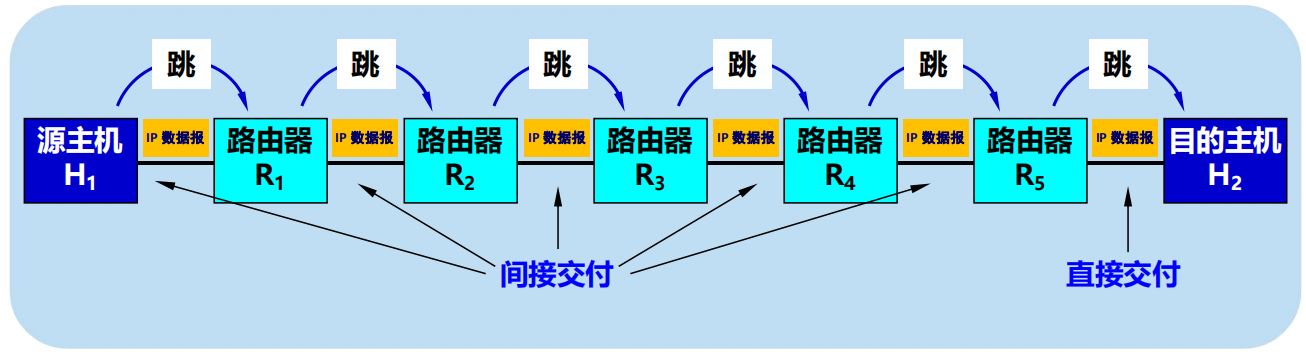
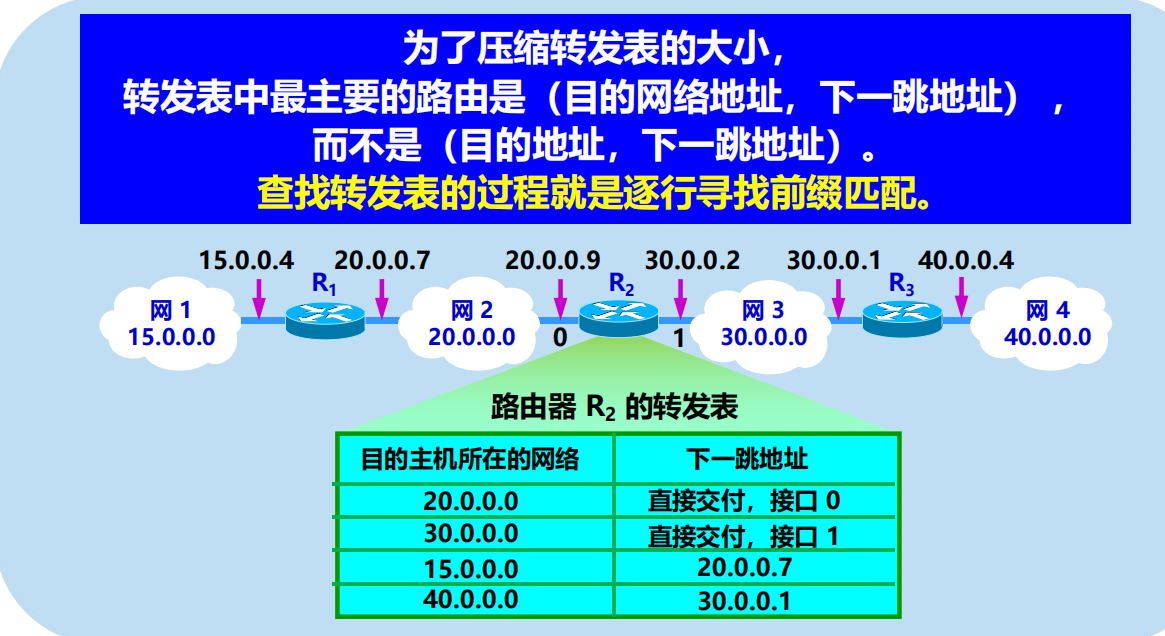
4.3 IP 層轉發分組的過程
4.3.1 基於終點的轉發
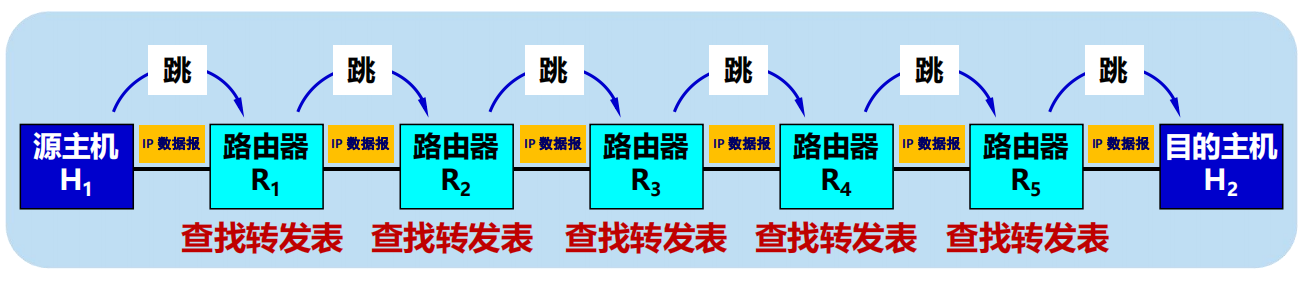
l 分組在互聯網中是逐跳轉發的。
l 基於終點的轉發:基於分組首部中的目的地址傳送和轉發。
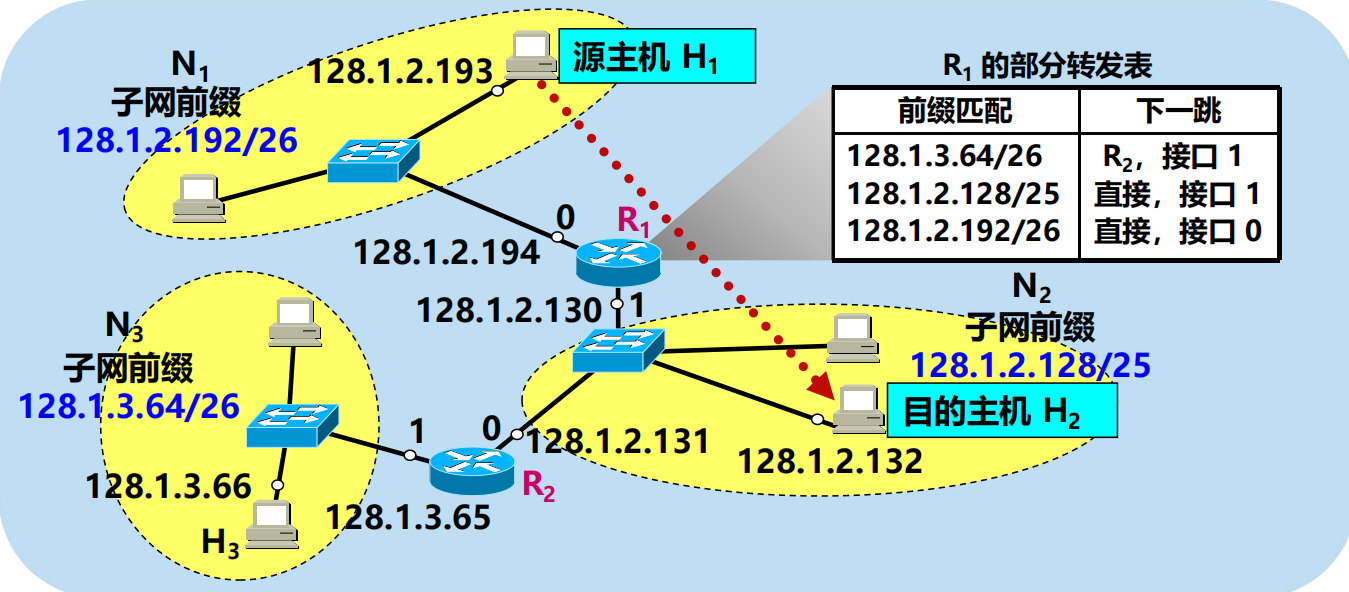
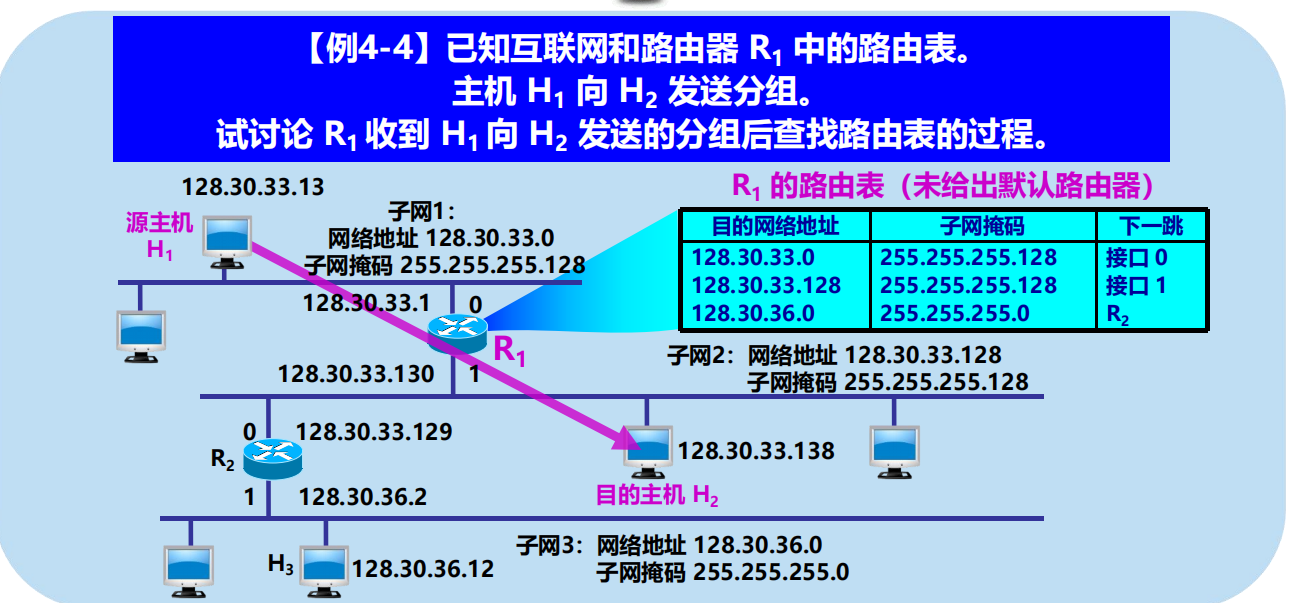
問:主機 H1 發送出的、目的地址是 128.1.2.132 的分組是如何轉發的?
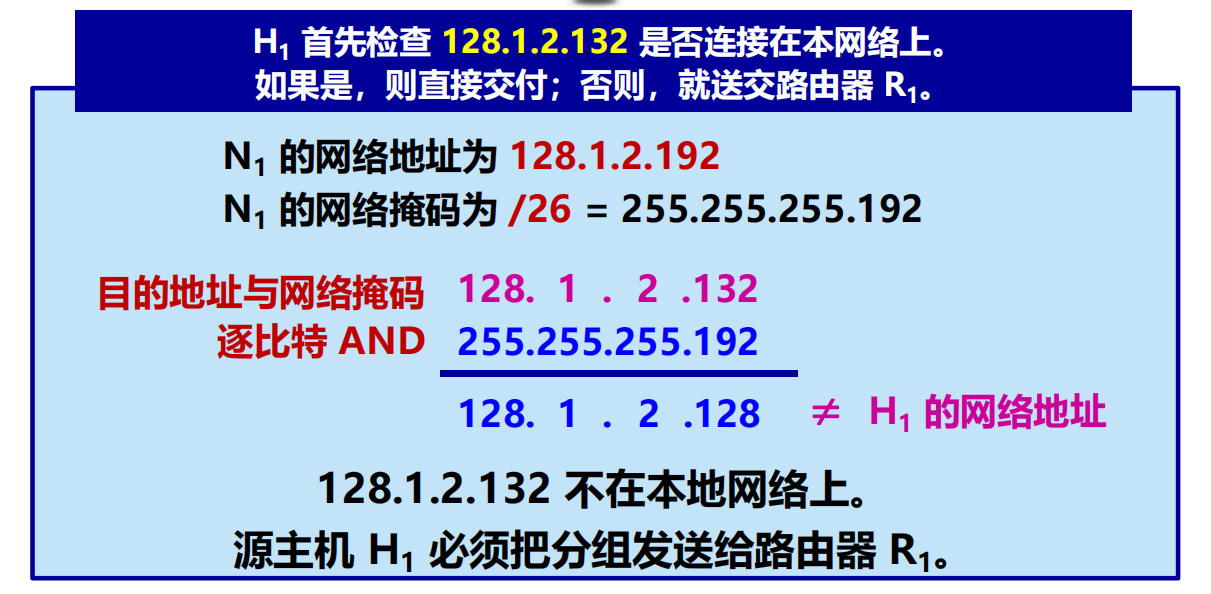
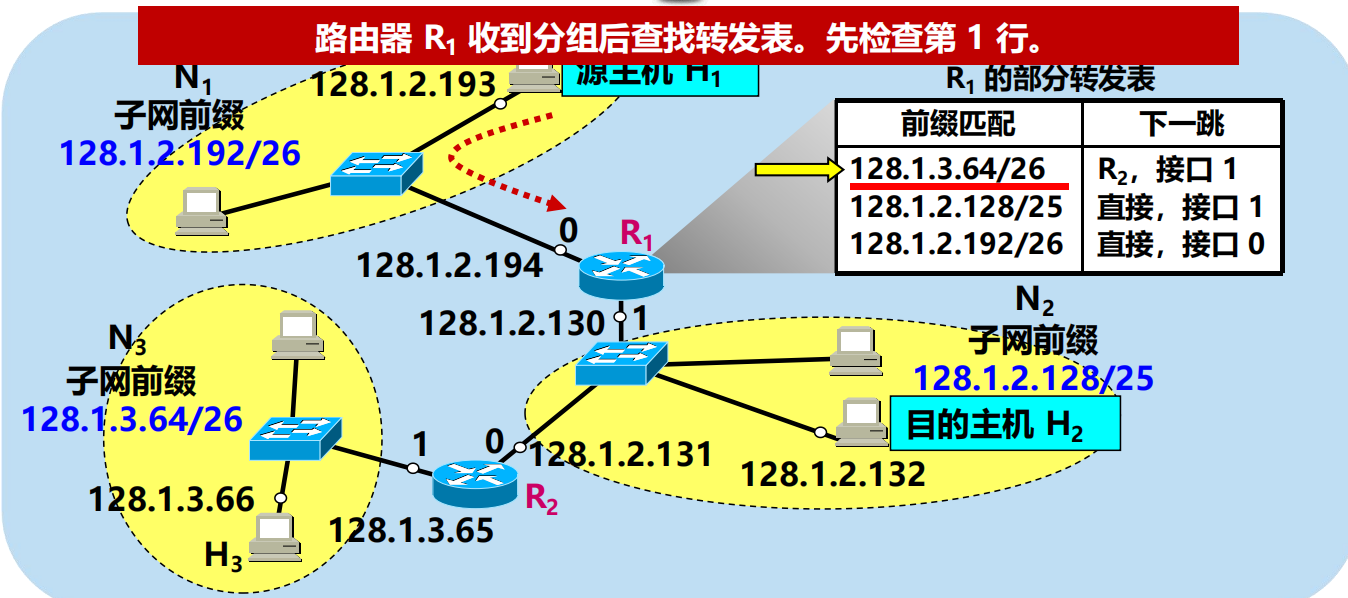
128.1.2.132 AND 255.255.255.192 = 128.1.2.128 不匹配!
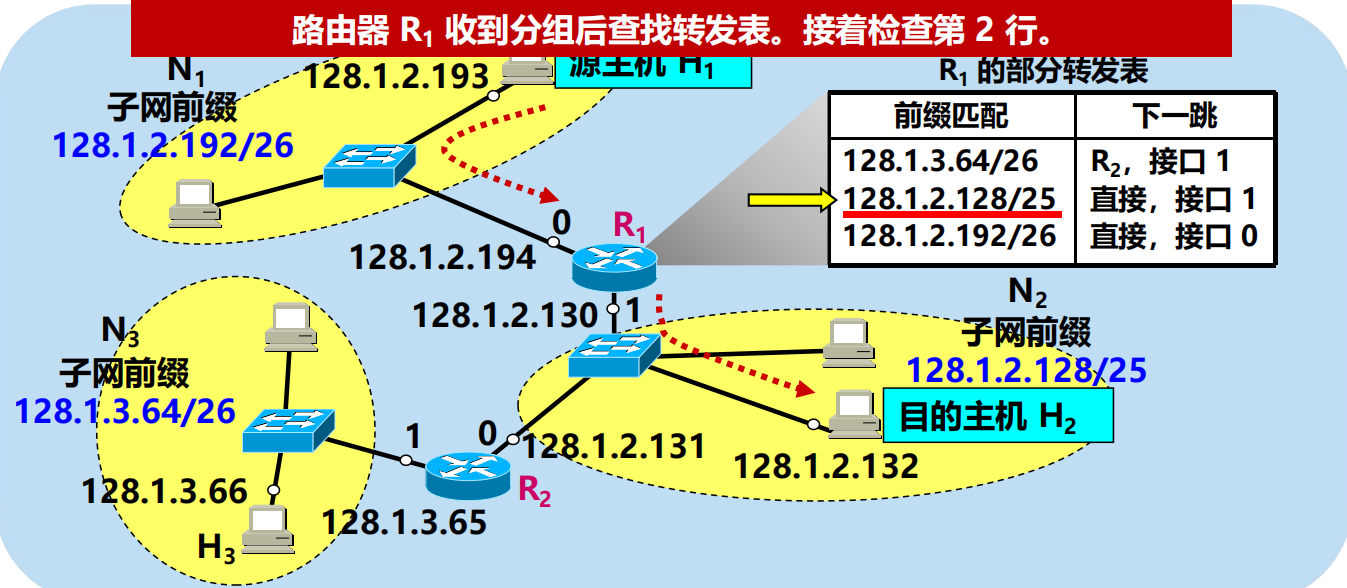
128.1.2.132 AND 255.255.255.128 = 128.1.2.128 匹配!
進行分組的直接交付(通過路由器 R1 的介面 1)。
4.3.2 最長前綴匹配
使用 CIDR 時,在查找轉發表時可能會得到不止一個匹配結果。
最長前綴匹配 (longest-prefix matching) 原則:選擇前綴最長的一個作為匹配的前綴。
網路前綴越長,其地址塊就越小,因而路由就越具體。
可以把前綴最長的排在轉發表的第 1 行。
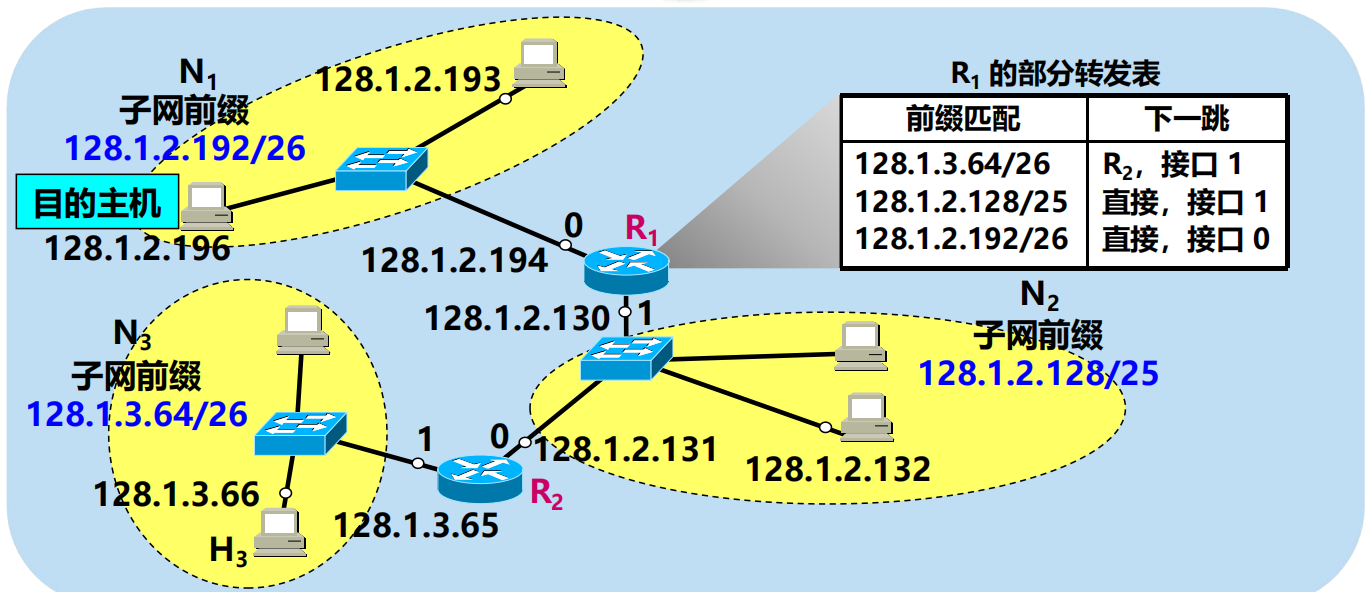
問:路由器 R1 如何轉發目的地址是 128.1.2.196 的分組?
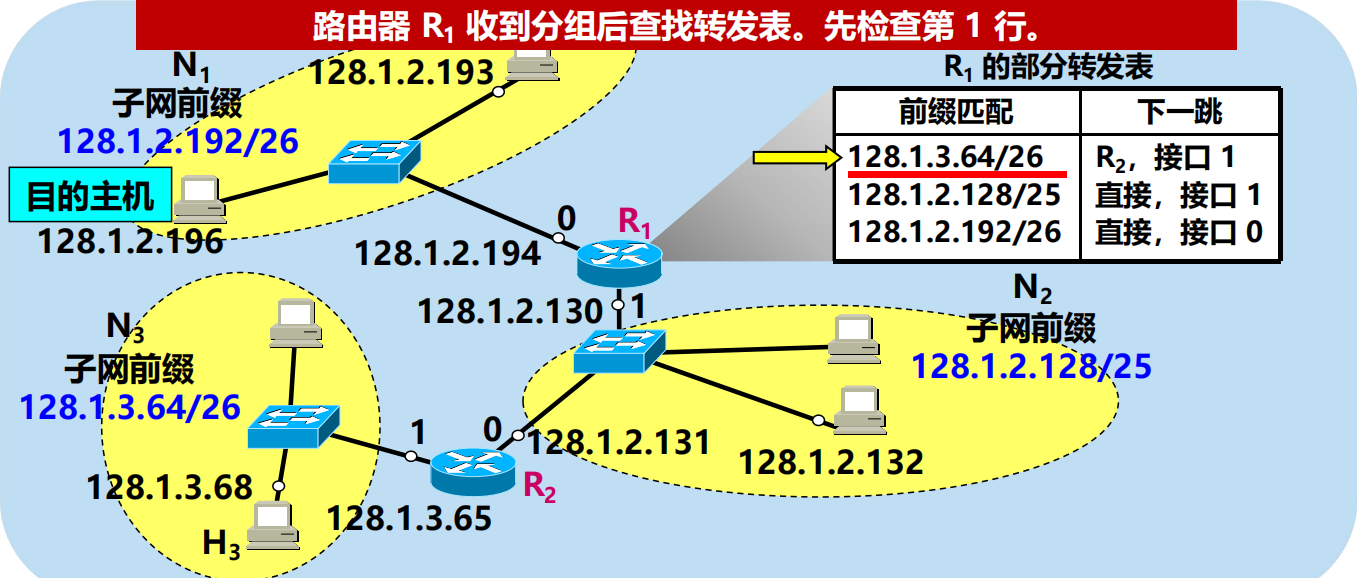
128.1.2.196 AND 255.255.255.192 = 128.1.2.192 不匹配!
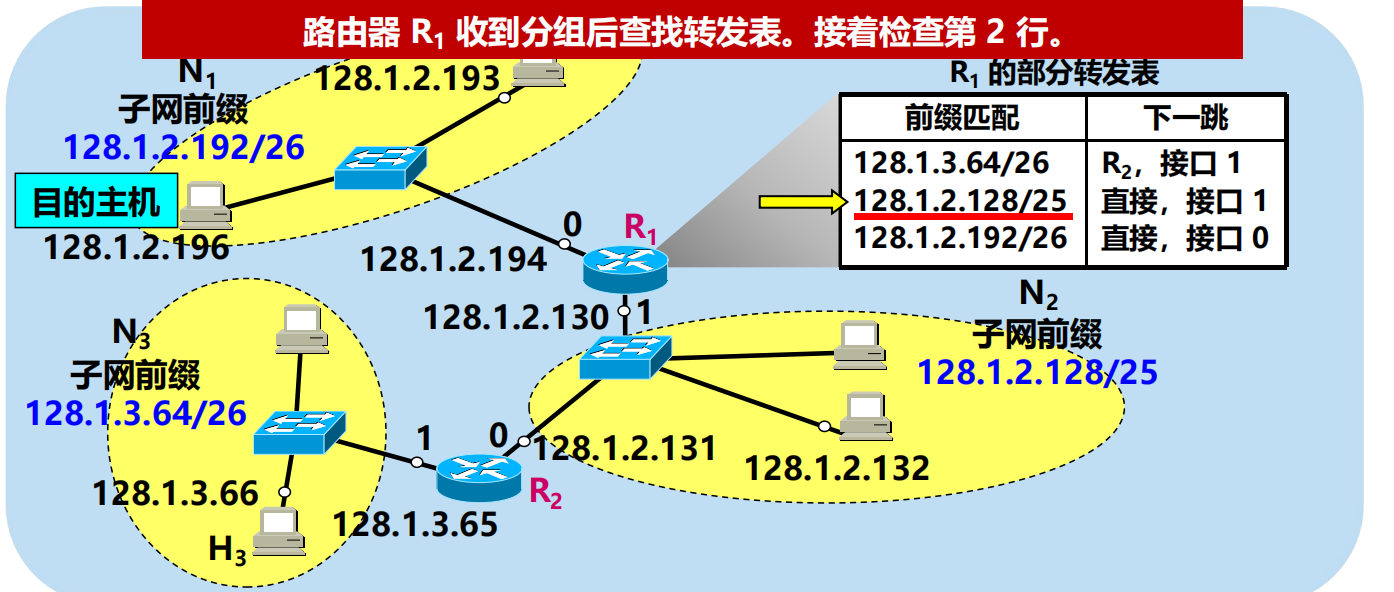
128.1.2.196 AND 255.255.255.128 = 128.1.2.128 匹配!
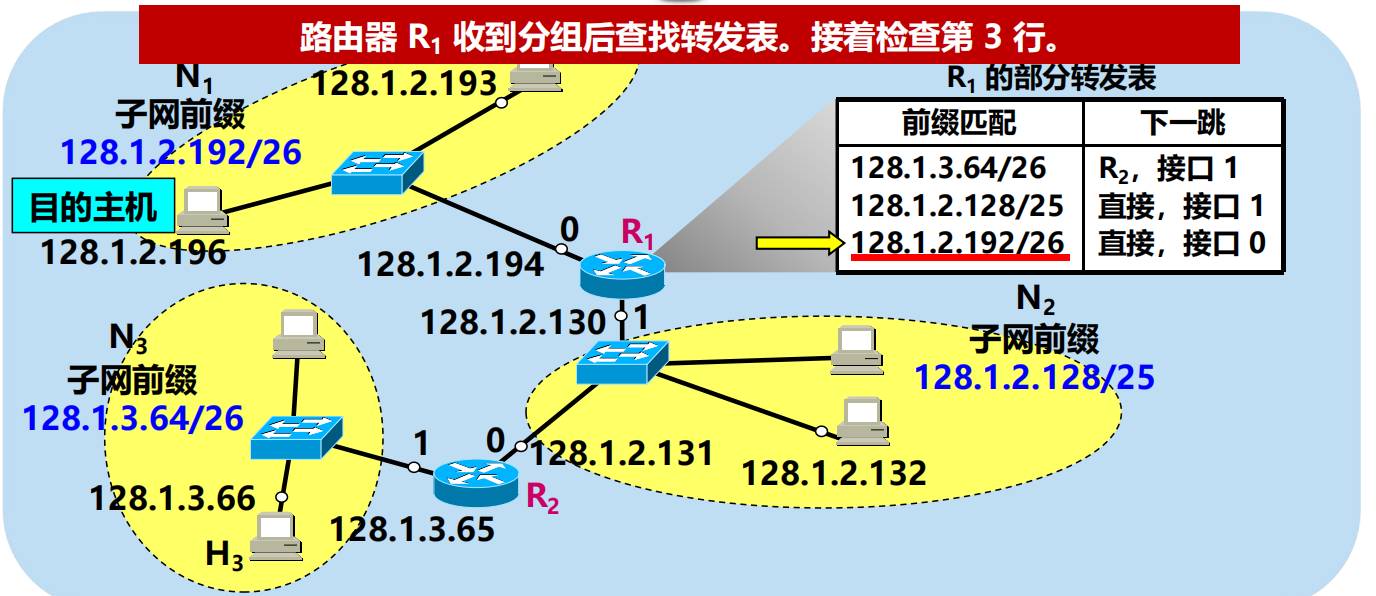
128.1.2.196 AND 255.255.255.192 = 128.1.2.192 匹配!
問題:R1 從哪個介面向外轉發分組?


網路前綴越長,其地址塊就越小,路由就越具體(more specific)
可以把前綴最長的排在轉發表的第 1 行,以加快查表
轉發表中的 2 種特殊的路由
主機路由 (host route)
又叫做特定主機路由。
是對特定目的主機的 IP 地址專門指明的一個路由。
網路前綴就是 a.b.c.d/32
放在轉發表的最前面。
默認路由 (default route)
不管分組的最終目的網路在哪裡,都由指定的路由器 R 來處理
用特殊前綴 0.0.0.0/0 表示。
默認路由舉例
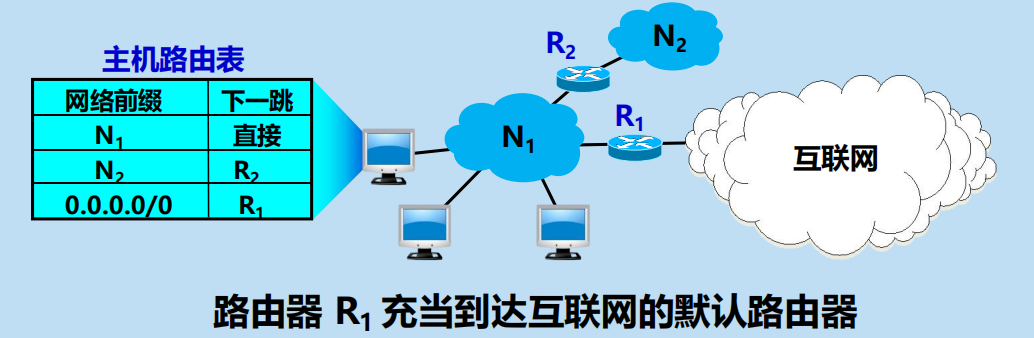
只要目的網路不是 N1 和 N2,就一律選擇默認路由,把 IP 數據報先間接交付默認路由器 R1,讓 R1 再轉發給下一個路由器。
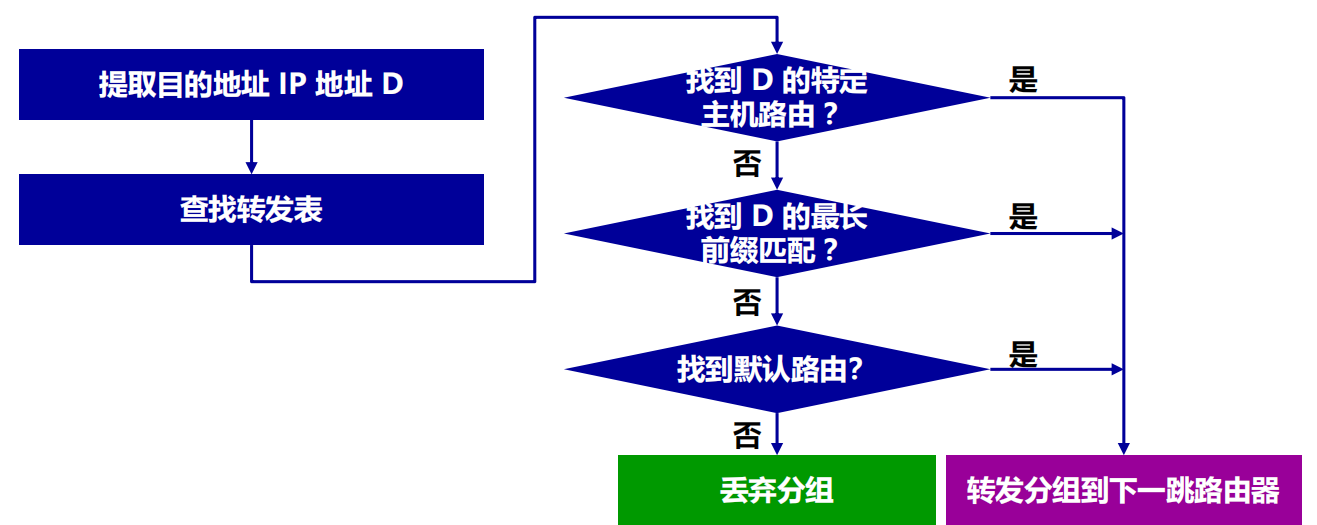
路由器分組轉發演算法
4.3.3 使用二叉線索查找轉發
二叉線索 (binary trie):一種特殊結構的樹,可以快速在轉發表中找到匹配的葉節點。
從二叉線索的根節點自頂向下的深度最多有 32 層,每一層對應於IP 地址中的一位。
為簡化二叉線索的結構,可以用唯一前綴 (unique prefix) 來構造二叉線索。
為了提高二叉線索的查找速度,廣泛使用了各種壓縮技術。
用 5 個唯一前綴構成的二叉線索



(補充)4.3*劃分子網
4.3.1 劃分子網
1. 從兩級 IP 地址到三級 IP 地址
在 ARPANET 的早期,IP 地址的設計確實不夠合理:
(1) IP 地址空間的利用率有時很低。
(2) 給每一個物理網路分配一個網路號會使路由表變得太大因而使網路
性能變壞。
(3) 兩級的 IP 地址不夠靈活
三級 IP 地址
從 1985 年起在 IP 地址中又增加了一個「子網號欄位」 ,使兩級的P 地址變成為三級的 IP 地址。
這種做法叫做劃分子網 (subnetting) 。
劃分子網已成為互聯網的正式標準協議。
劃分子網的基本思路
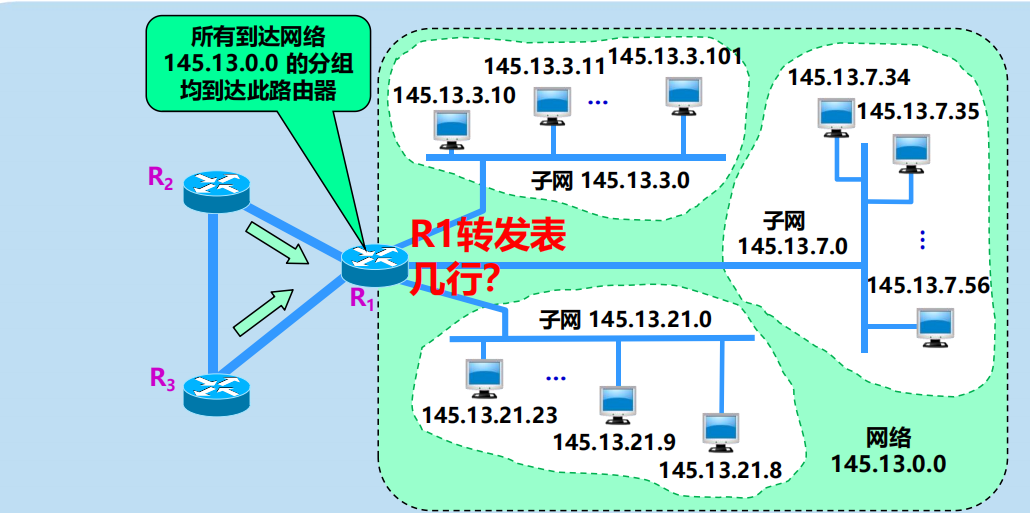
劃分子網純屬一個單位內部的事情。單位對外仍然表現為沒有劃分子網的網路。
從主機號借用若干個位作為子網號 subnet-id,而主機號 host-id也就相應減少了若干個位。
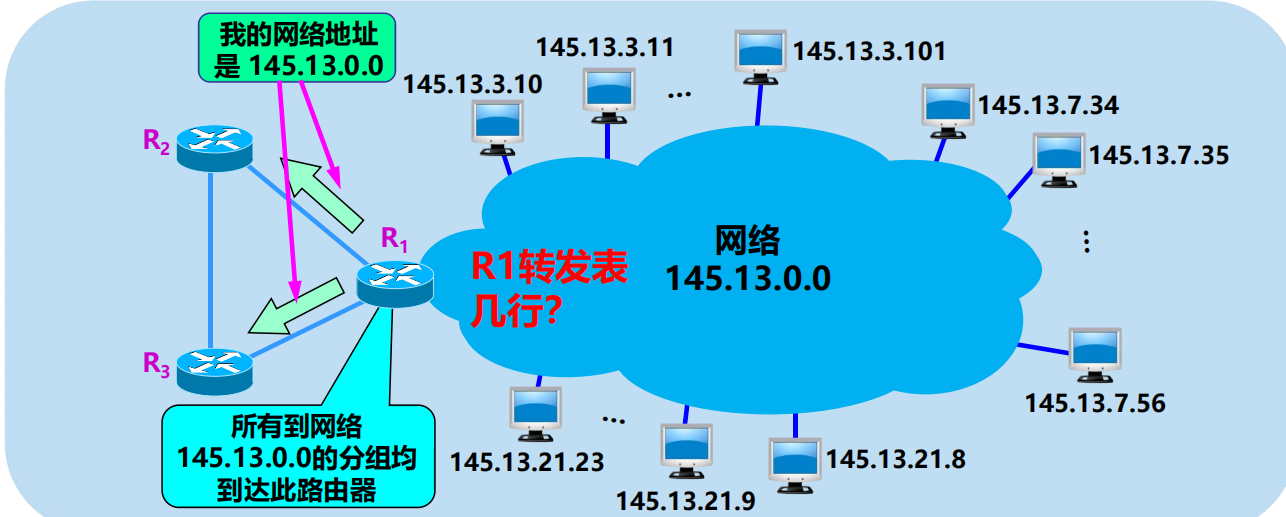
凡是從其他網路發送給本單位某個主機的 IP 數據報,仍然是根據 IP數據報的目的網路號 net-id,先找到連接在本單位網路上的路由器。
然後此路由器在收到 IP 數據報後,再按目的網路號 net-id 和子網號 subnet-id 找到目的子網。
最後就將 IP 數據報直接交付目的主機。
一個未劃分子網的 B 類網路145.13.0.0
劃分為三個子網後對外仍是一個網路
劃分子網後變成了三級結構
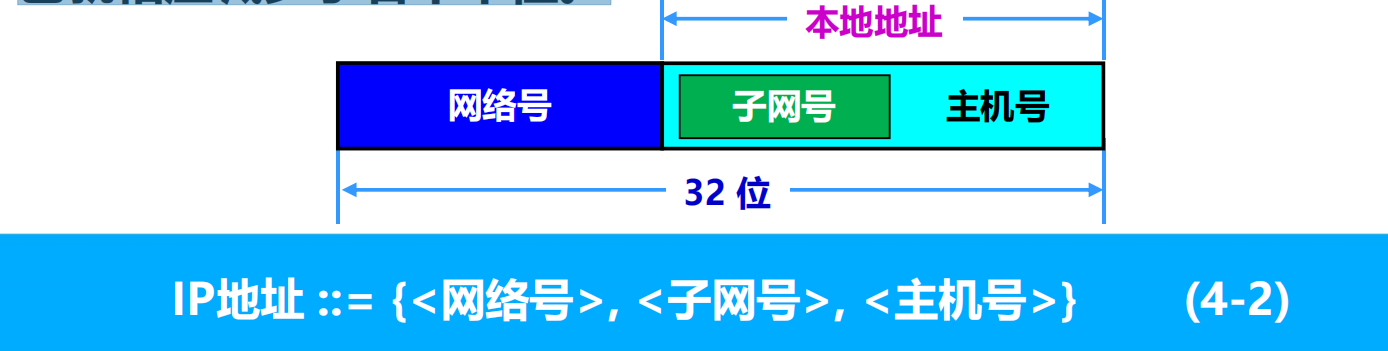
當沒有劃分子網時,IP 地址是兩級結構。
劃分子網後 IP 地址就變成了三級結構。
劃分子網只是把 IP 地址的主機號 host-id 這部分進行再劃分,而不改變 IP 地址原來的網路號 net-id。
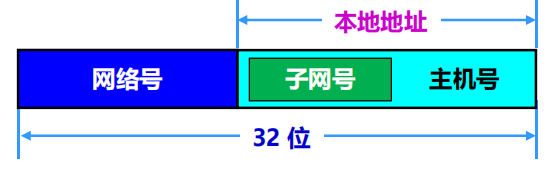
劃分子網後變成了三級結構的優點
優點
1. 減少了 IP 地址的浪費
2. 使網路的組織更加靈活
3. 更便於維護和管理
劃分子網純屬一個單位內部的事情,對外部網路透明,對外仍然表現為沒有劃分子網的一個網路。
子網掩碼
從一個 IP 數據報的首部並無法判斷源主機或目的主機所連接的網路是否進行了子網劃分。
使用子網掩碼 (subnet mask) 可以找出 IP 地址中的子網部分。
規則:
子網掩碼長度 = 32 位
子網掩碼左邊部分的一連串 1,對應於網路號和子網號
子網掩碼右邊部分的一連串 0,對應於主機號
IP 地址的各欄位和子網掩碼

(IP 地址) AND (子網掩碼) =網路地址
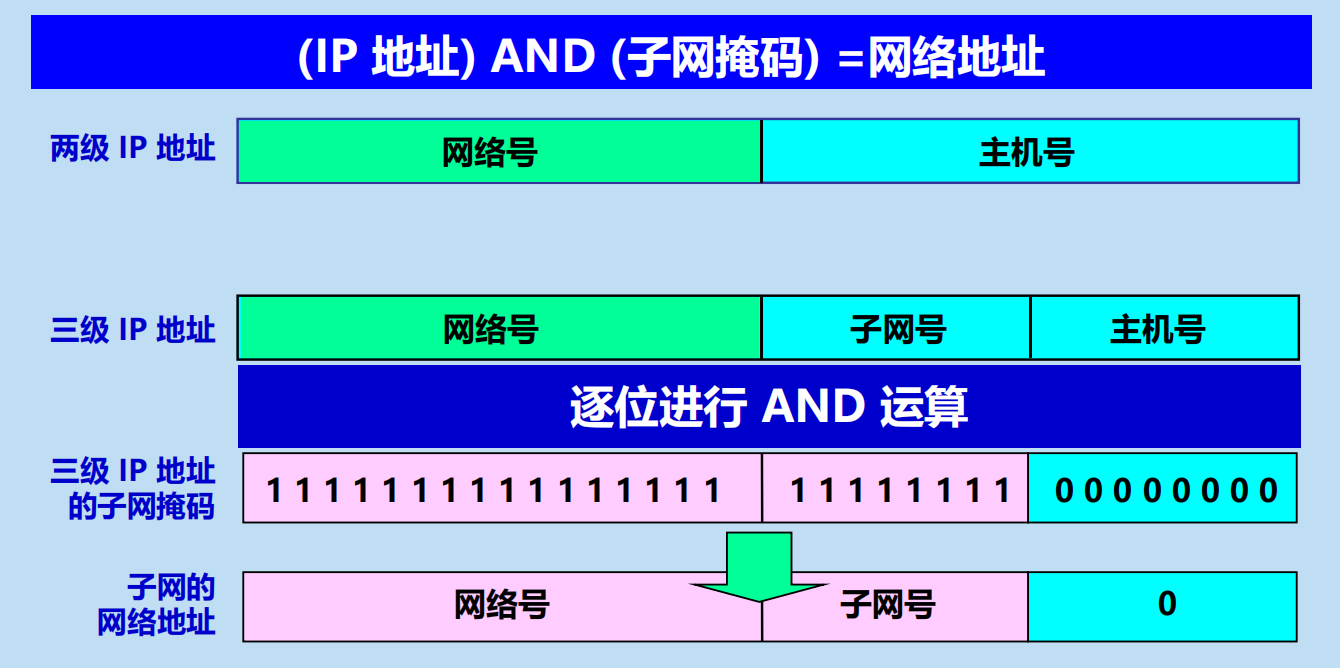
默認子網掩碼

子網掩碼是一個重要屬性子網掩碼是一個網路或一個子網的重要屬性。
路由器在和相鄰路由器交換路由資訊時,必須把自己所在網路(或子網)的子網掩碼告訴相鄰路由器。
路由器的路由表中的每一個項目,除了要給出目的網路地址外,還必須同時給出該網路的子網掩碼。
若一個路由器連接在兩個子網上,就擁有兩個網路地址和兩個子網掩
碼。
子網劃分方法:
有固定長度子網和變長子網兩種子網劃分方法。
在採用固定長度子網時,所劃分的所有子網的子網掩碼都是相同的。
雖然根據已成為互聯網標準協議的 RFC 950 文檔,子網號不能為全 1或全 0,但隨著無分類域間路由選擇 CIDR 的廣泛使用,現在全 1 和全 0 的子網號也可以使用了,但一定要謹慎使用,確認你的路由器所用的路由選擇軟體是否支援全 0 或全 1 的子網號這種較新的用法。
l 劃分子網增加了靈活性,但卻減少了能夠連接在網路上的主機總數
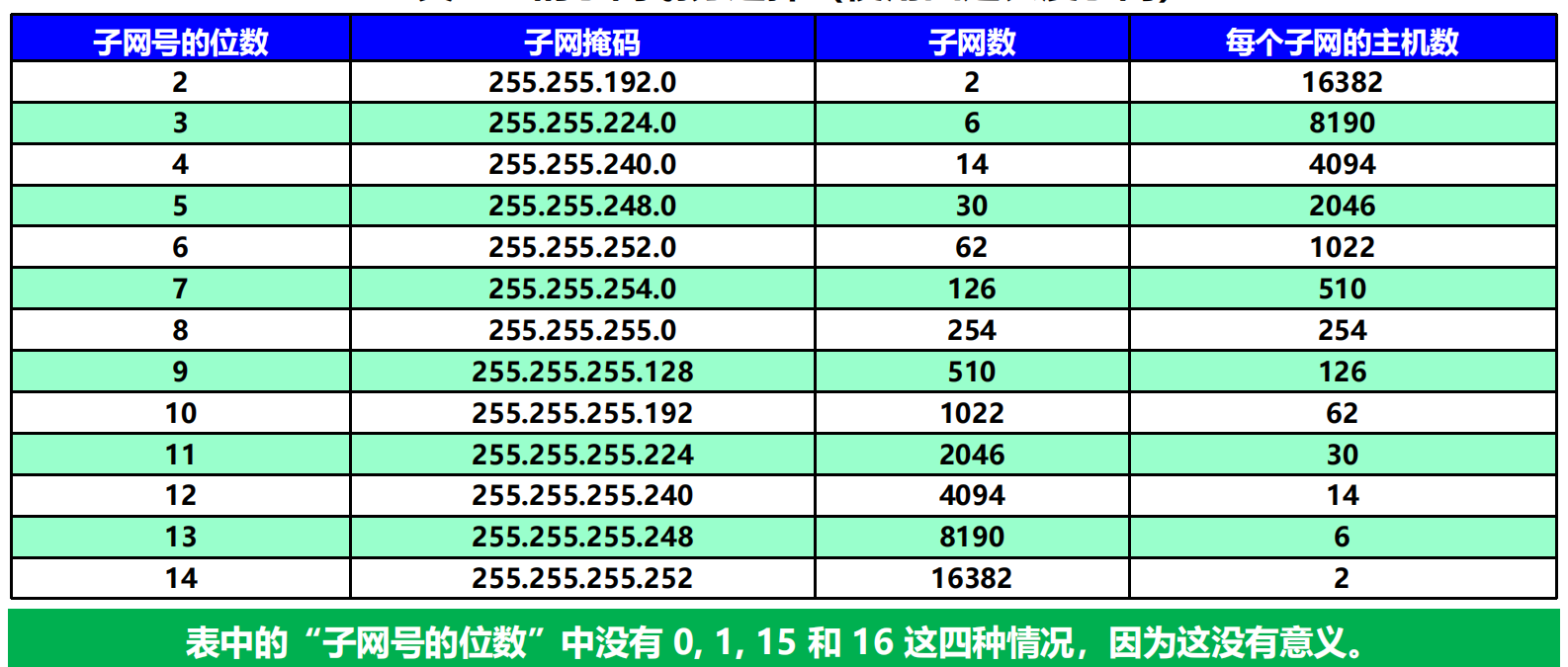
B 類地址的子網劃分選擇(使用固定長度子網
4.3.2 使用子網時分組的轉發
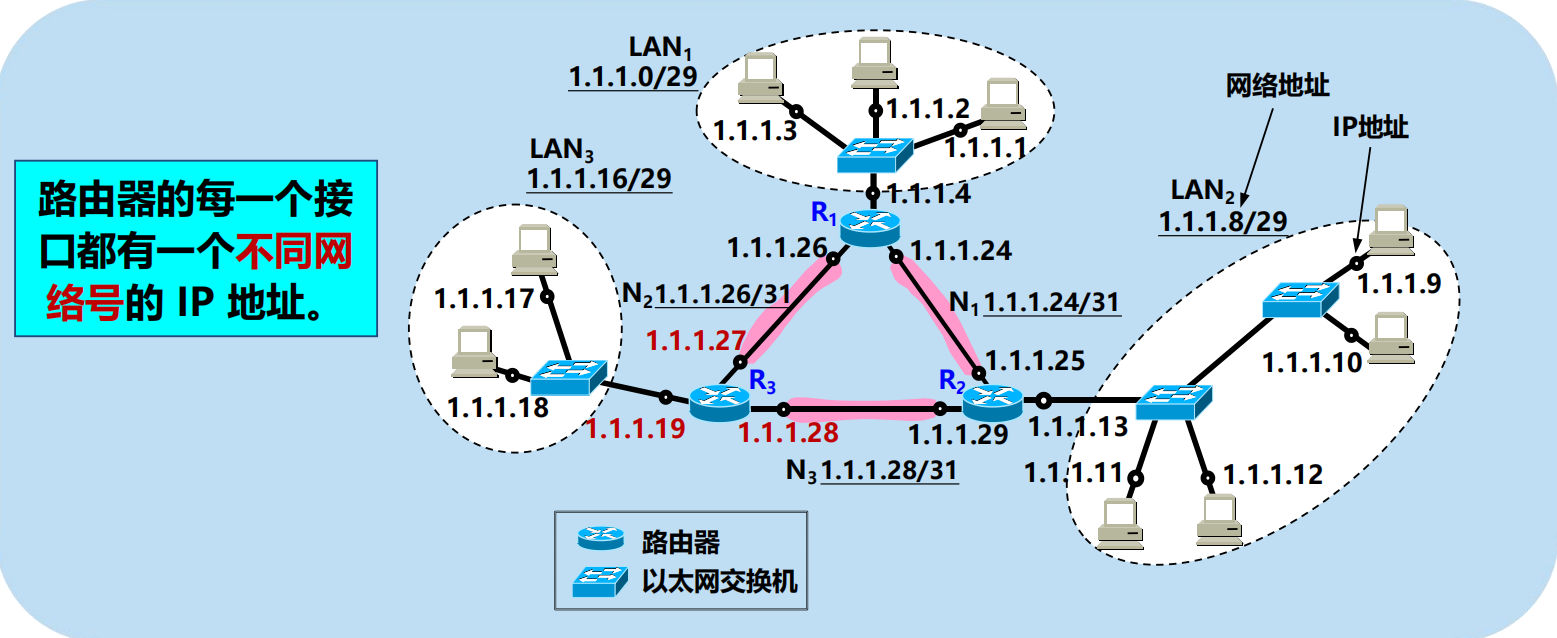
在不劃分子網的兩級 IP 地址下,從 IP 地址得出網路地址是個很簡單的事。
但在劃分子網的情況下,從 IP 地址卻不能唯一地得出網路地址來,這是因為網路地址取決於那個網路所採用的子網掩碼,但數據報的首部並沒有提供子網掩碼的資訊。
因此分組轉發的演算法也必須做相應的改動。
1.在劃分子網情況下路由器轉發分組的演算法從收到的分組的首部提取目的 IP 地址 D。
2. 先用各網路的子網掩碼和 D 逐位相「與」,看是否和相應的網路地址匹配。若
匹配,則將分組直接交付。否則就是間接交付,執行(3)。
3. 若路由表中有目的地址為 D 的特定主機路由,則將分組傳送給指明的下一跳路由器;否則,執行 (4)。
4. 對路由表中的每一行,將子網掩碼和 D 逐位相「與」。若結果與該行的目的網路地址匹配,則將分組傳送給該行指明的下一跳路由器;否則,執行 (5)。
5. 若路由表中有一個默認路由,則將分組傳送給路由表中所指明的默認路由器;否則,執行 (6)。
6. 報告轉發分組出錯
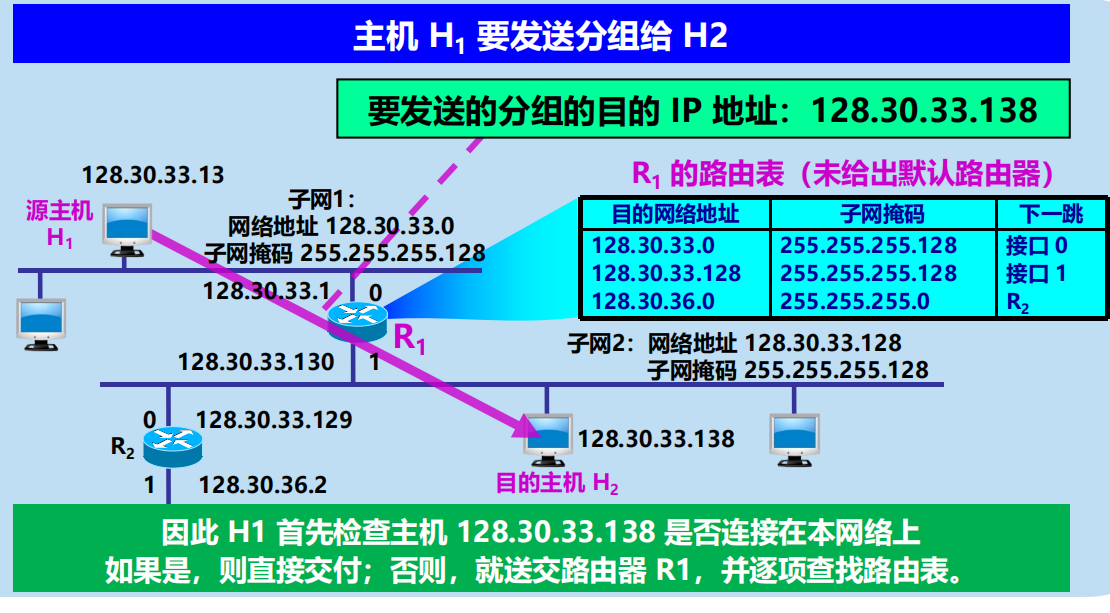
主機 H1 首先將本子網的子網掩碼 255.255.255.128
與分組的 IP 地址 128.30.33.138 逐比特相與」(AND 操作)

因此 H1 必須把分組傳送到路由器 R1然後逐項查找路由表
4.4 網際控制報文協議 ICMP
ICMP (Internet Control Message Protocol) 允許主機或路由器報告差錯情況和提供有關異常情況的報告。
ICMP 是互聯網的標準協議。
但 ICMP 不是高層協議,而是IP 層的協議。
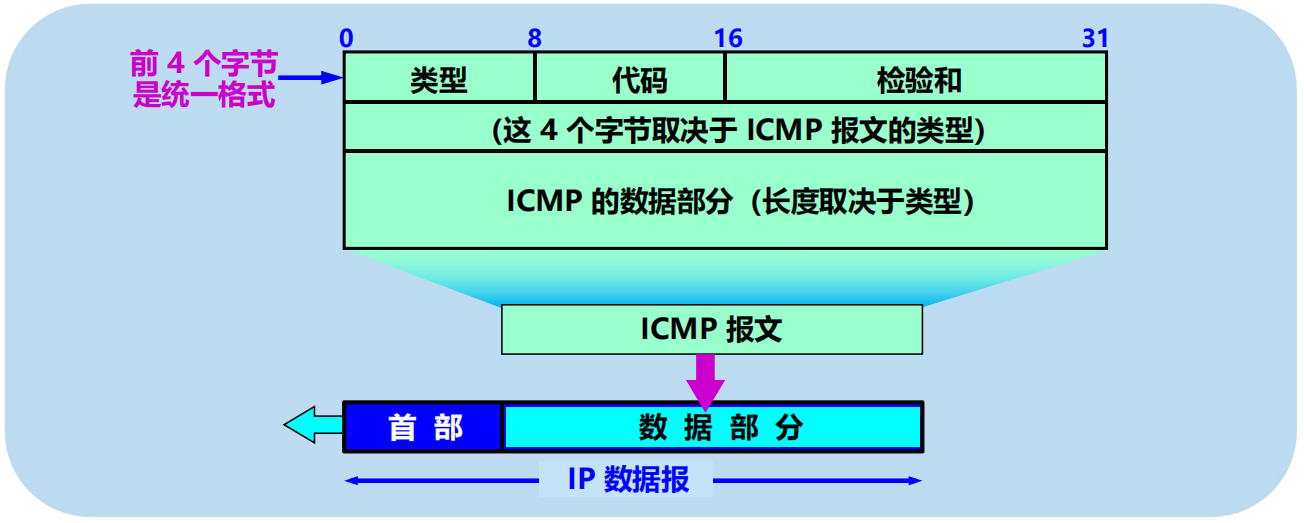
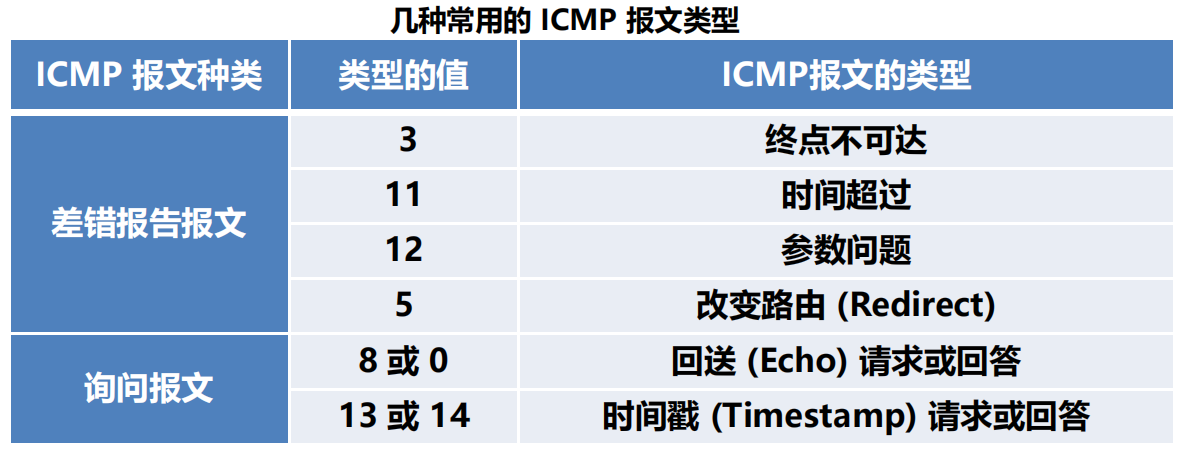
4.4.1 ICMP 報文的種類
2 種:差錯報告報文,詢問報文。
幾種常用的 ICMP 報文類型
ICMP 差錯報告報文的數據欄位的內容
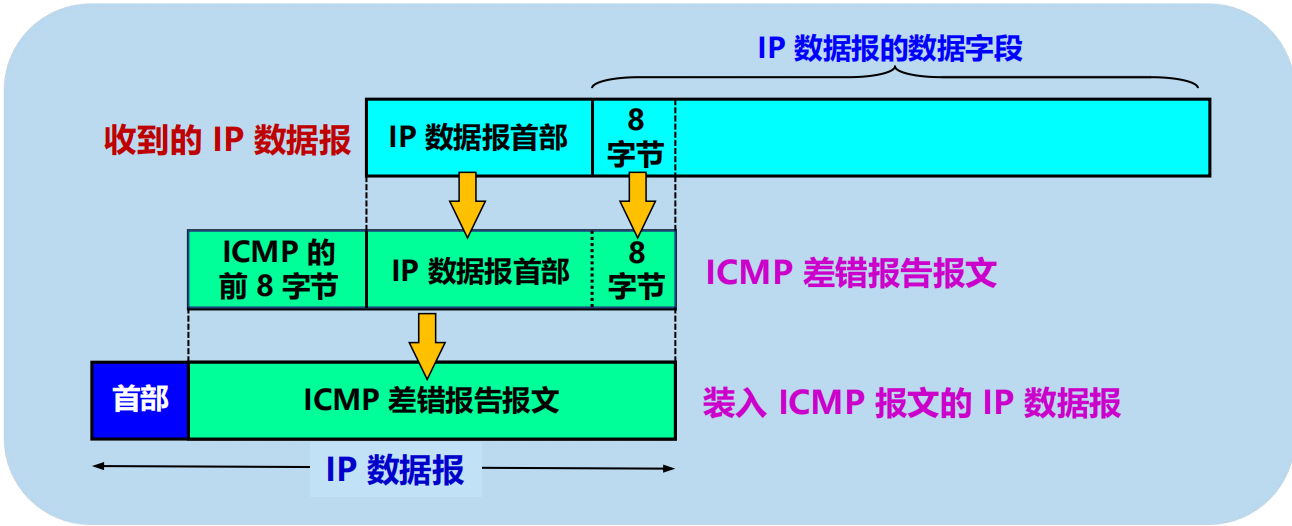
不應發送 ICMP 差錯報告報文的幾種情況
對 ICMP 差錯報告報文不再發送 ICMP 差錯報告報文。
對第一個分片的數據報片的所有後續數據報片都不發送 ICMP 差錯報告報文。
對具有多播地址的數據報都不發送 ICMP 差錯報告報文。
對具有特殊地址(如127.0.0.0 或 0.0.0.0)的數據報不發送 ICMP差錯報告報文。
ICMP 詢問報文
(1) 回送請求和回答
由主機或路由器向一個特定的目的主機發出的詢問。
收到此報文的主機必須給源主機或路由器發送 ICMP 回送回答報文。
這種詢問報文用來測試目的站是否可達,以及了解其有關狀態。
(2) 時間戳請求和回答:
請某台主機或路由器回答當前的日期和時間。
時間戳回答報文中有一個 32 位的欄位,其中寫入的整數代表從1900 年 1 月 1 日起到當前時刻一共有多少秒。
時間戳請求與回答可用於時鍾同步和時間測量。
4.4.2 ICMP 的應用舉例
PING (Packet InterNet Groper)
用來測試兩個主機之間的連通性。
使用了 ICMP 回送請求與回送回答報文。
是應用層直接使用網路層 ICMP 的例子,沒有通過運輸層的 TCP或 UDP。
例如:
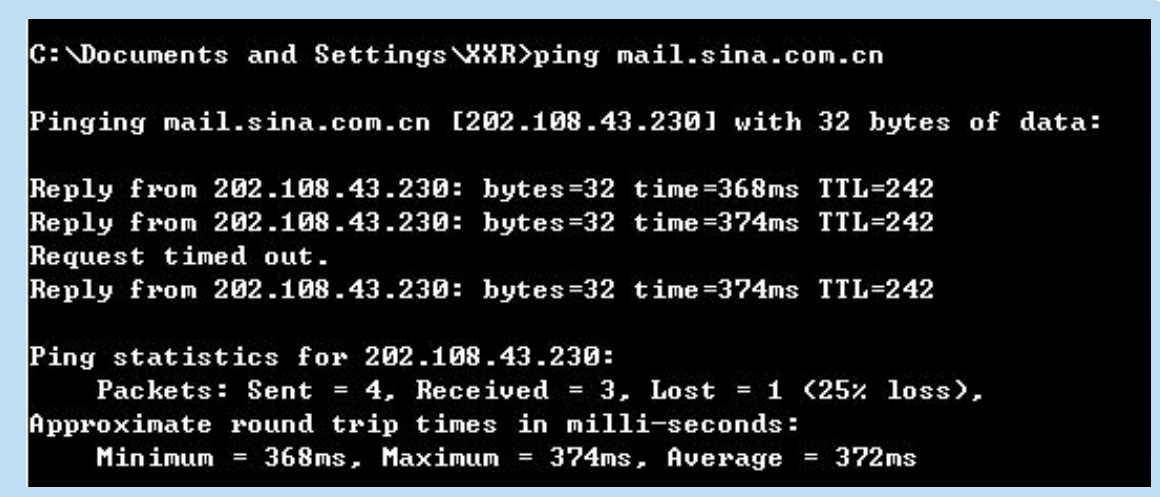
用 PING 測試郵件伺服器 mail.sina.com.cn 的連通性
Traceroute
這是UNIX作業系統中名字。在 Windows 作業系統中這個命令是 tracert。
用來跟蹤一個分組從源點到終點的路徑。
它利用 IP 數據報中的 TTL 欄位、ICMP 時間超過差錯報告報文和
ICMP 終點不可達差錯報告報文實現對從源點到終點的路徑的跟蹤。
例如
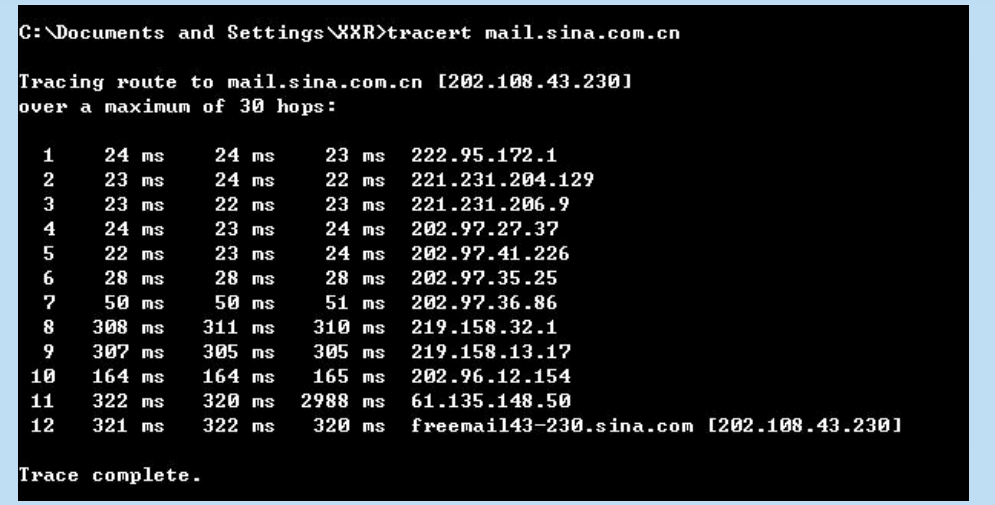
用 tracert 命令獲得到新浪網的郵件伺服器 mail.sina.com.cn 的路由資訊
4.5 IPv6
IP 是互聯網的核心協議。
IPv4 地址耗盡問題:
到 2011 年 2 月,IANA IPv4 的 32 位地址已經耗盡。
各地區互聯網地址分配機構也相繼宣布地址耗盡。
中國在 2014 – 2015 年也逐步停止了向新用戶和應用分配 IPv4地址。
根本解決措施:採用具有更大地址空間的新版本的 IP,即 IPv6。
4.5.1 IPv6 的基本首部
IPv6 仍支援無連接的傳送。
將協議數據單元 PDU 稱為分組 (packet) 。
主要變化(1/2):
1. 更大的地址空間。 將地址從 IPv4 的 32 位 增大到了 128 位。
2. 擴展的地址層次結構。可以劃分為更多的層次。
3. 靈活的首部格式。定義了許多可選的擴展首部。
4. 改進的選項。允許數據報包含有選項的控制資訊,其選項放在有效載荷中。
5.允許協議繼續擴充。更好地適應新的應用。
6.支援即插即用(即自動配置)。不需要使用 DHCP。
7.支援資源的預分配。支援實時視像等要求保證一定的頻寬和時延的應用。
8.IPv6 首部改為 8 位元組對齊。首部長度必須是 8 位元組的整數倍。
4.5.2 IPv6 的地址
由兩大部分組成:
1. 基本首部 (base header)
2. 有效載荷 (payload)。有效載荷也稱為凈負荷。有效載荷允許有零個或多個擴展首部 (extension header),再後面是數據部分。
如圖
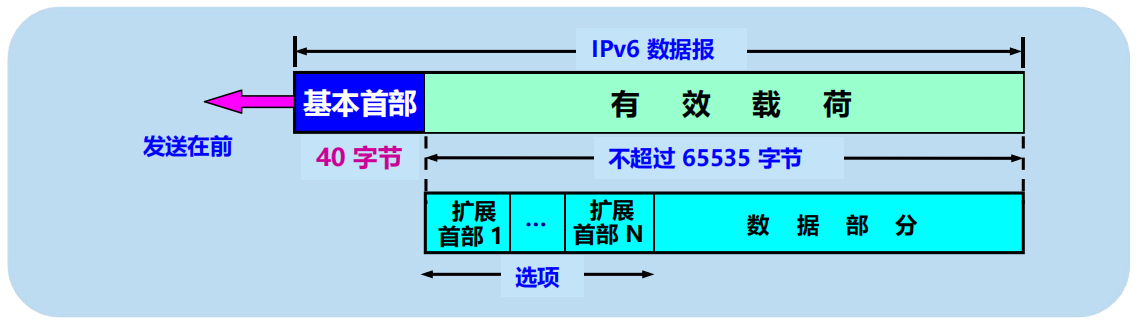
IPv6 數據報的基本首部
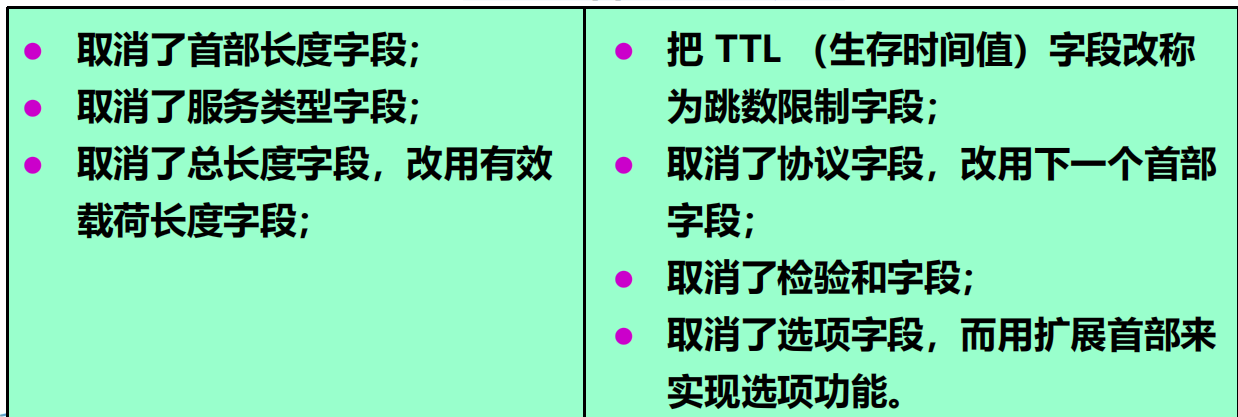
首部長度:固定的 40 位元組,稱為基本首部。
首部欄位數:只有 8 個。
IPv6 對首部的主要更改
基本首部每一個欄位的意義:
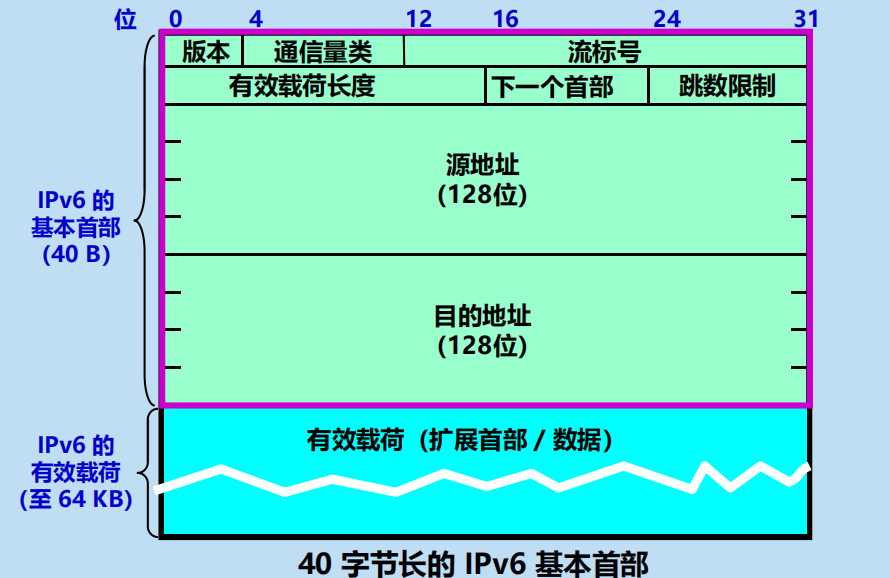
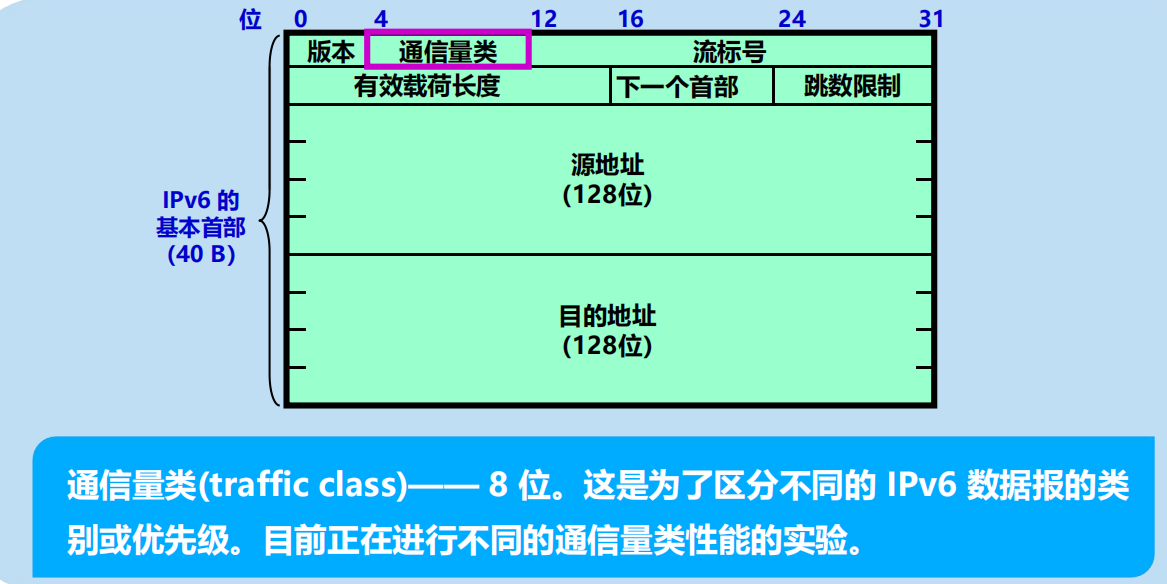
通訊量類(traffic class)
流標號(flow label)
流標號(flow label)—— 20 位。 「流」是互聯網路上從特定源點到特定終點的一系列數據報, 「流」所經過的路徑上的路由器都保證指明的服務品質。所有屬於同一個流的數據報都具有同樣的流標號。
有效載荷長度(payload length)
有效載荷長度(payload length)—— 16 位。它指明 IPv6 數據報除基本首部以外的位元組數(所有擴展首部都算在有效載荷之內),其最大值是 64 KB。
下一個首部(next header)
下一個首部(next header)—— 8 位。相當於 IPv4 的協議欄位或可選欄位。
跳數限制(hop limit)—— 8 位。
跳數限制(hop limit)—— 8 位。源站在數據報發出時即設定跳數限制。路由器在轉發數據報時將跳數限制欄位中的值減 1。當跳數限制的值為零時,就要將此數據報丟棄。
源地址—— 128 位。
源地址—— 128 位。是數據報的發送站的 IP 地址。
目的地址—— 128 位。
目的地址—— 128 位。是數據報的接收站的 IP 地址。
IPv6 的六種擴展首部
逐跳選項
路由選擇
分片
鑒別
封裝安全有效載荷
目的站選項
三種基本類型(目的地址):
1. 單播 (unicast):傳統的點對點通訊。
2. 多播 (multicast):一點對多點的通訊。
3. 任播 (anycast):IPv6 增加的一種類型。任播的終點是一組電腦,但數據報在交付時只交付其中的一個。通常是按照路由演算法得出的距離最近的一個。
節點與介面
IPv6 將實現 IPv6 的主機和路由器均稱為節點。
一個節點可能有多個與鏈路相連的介面。
IPv6 地址是分配給節點上介面的。
1. 一個具有多個介面的節點可以有多個單播地址。
2. 其中的任何一個地址都可以當作到達該節點的目的地址。
冒號十六進位記法
在 IPv6 中,每個地址占 128 位,地址空間大於 3.4 1038 。
使用冒號十六進位記法(colon hexadecimal notation, 簡寫為 colonhex)(為何?):16 位的值用十六進位值表示,各值之間用冒號分隔。

兩個技術:零壓縮,點分十進位記法的後綴。
零壓縮
零壓縮 (zero compression):一串連續的零可以用一對冒號取代。
如:
FF05:0:0:0:0:0:0:B3
可壓縮為:
FF05::B3
舉例:

注意:在任一地址中,只能使用一次零壓縮。
點分十進位記法的後綴
結合使用點分十進位記法的後綴在 IPv4 向 IPv6 的轉換階段特別有用。
例如:0:0:0:0:0:0:128.10.2.1 -> ::128.10.2.1
CIDR 的斜線表示法仍然可用,但取消了子網掩碼。
例如:60 位的前綴 12AB00000000CD3 可記為:
12AB:0000:0000:CD30:0000:0000:0000:0000/60
或 12AB::CD30:0:0:0:0/60 (零壓縮)
或 12AB:0:0:CD30::/60 (零壓縮)

IPv6 地址分類

IPv6 單播地址的劃分方法

4.5.3 從 IPv4 向 IPv6 過渡
方法:逐步演進,向後兼容。
向後兼容:IPv6 系統必須能夠接收和轉發 IPv4 分組,並且能夠為 IPv4 分組選擇路由。
兩種過渡策略:
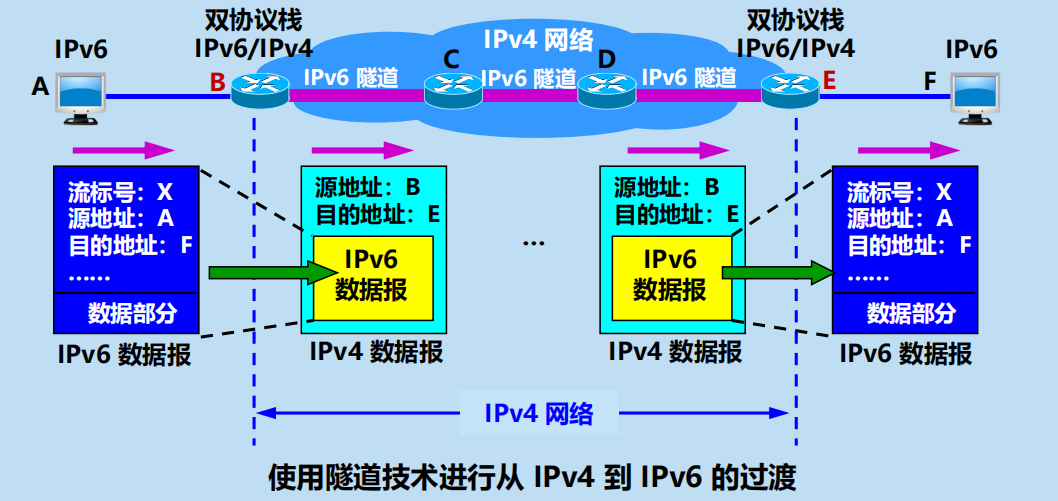
1. 使用雙協議棧
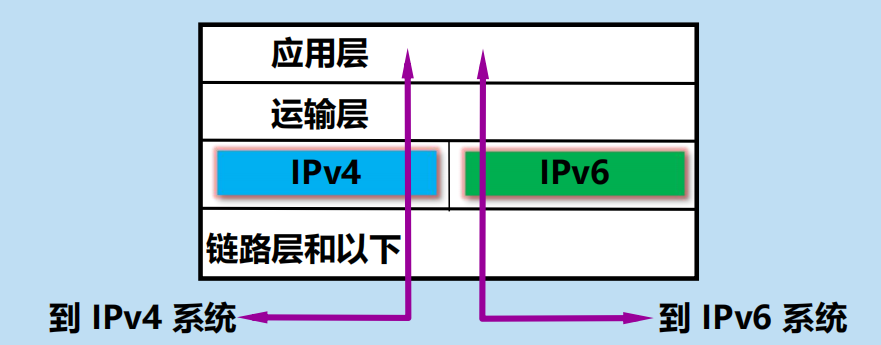
Pv6/IPv4 雙協議棧主機(或路由器)
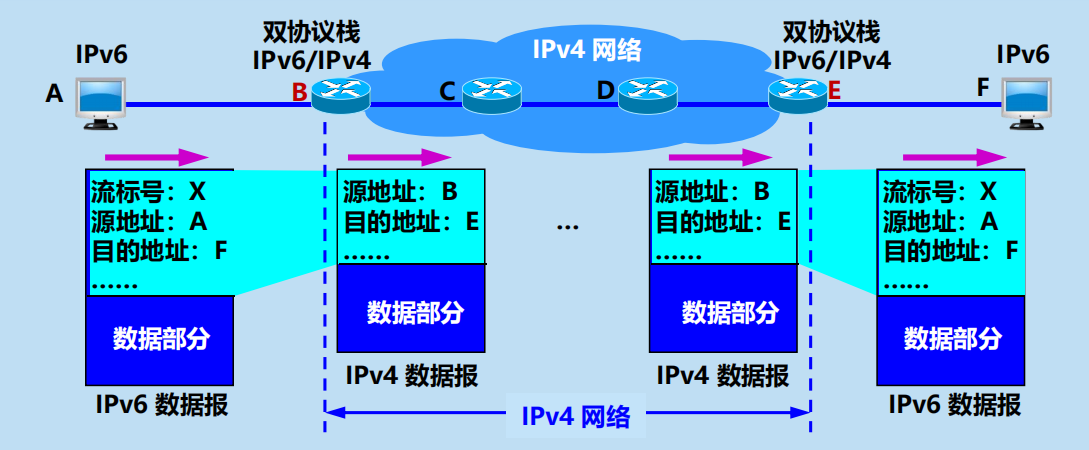
使用雙協議棧進行從 IPv4 到 IPv6 的過渡
2. 使用隧道技術
4.5.4 ICMPv6
IPv6 也需要使用 ICMP 來回饋一些差錯資訊。新的版本稱為 ICMPv6。

新舊版本中的網路層的比較
ICMPv6 報文的分類
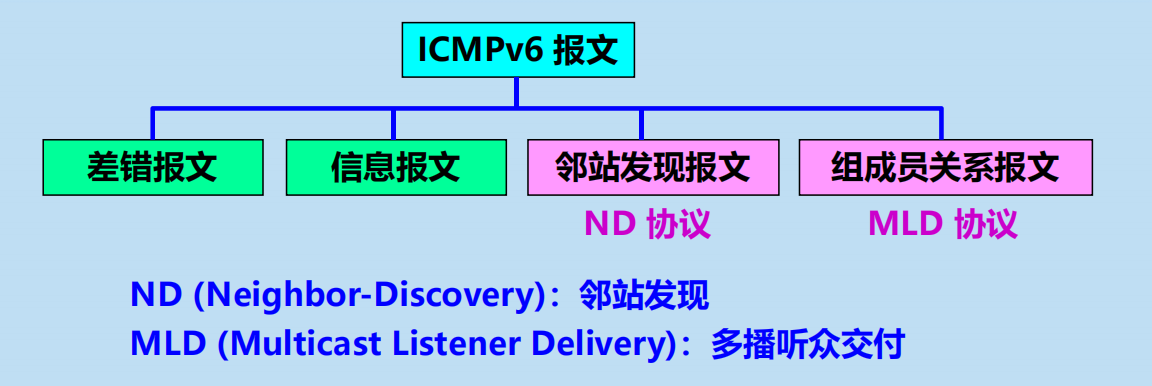
重點在這裡
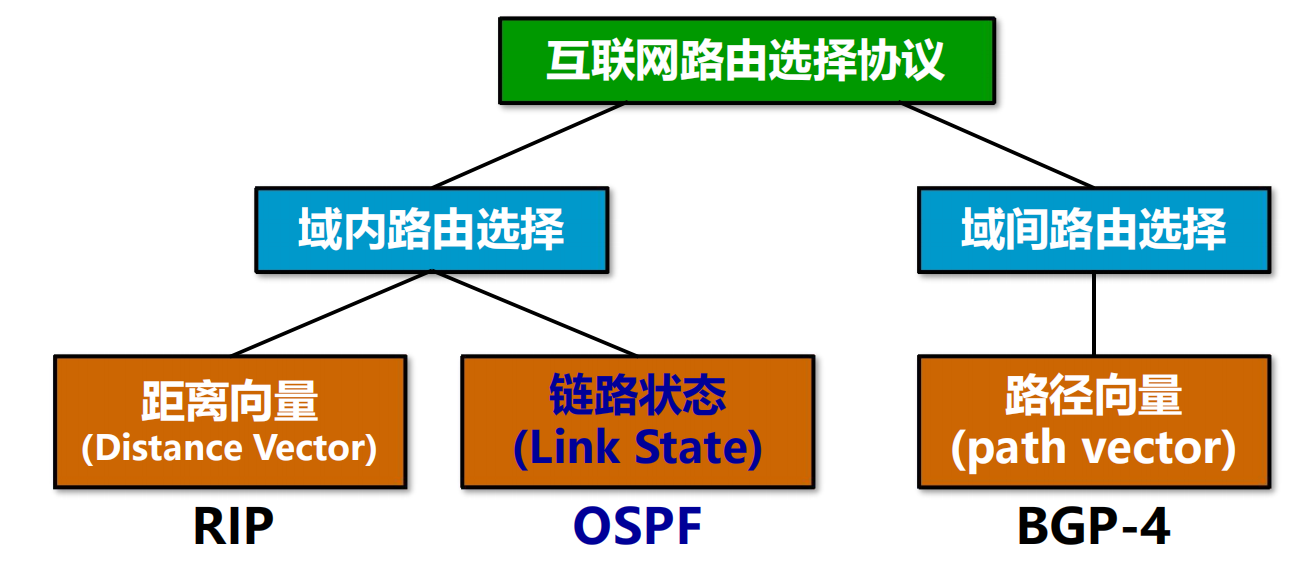
4.6 互聯網的路由選擇協議
4.6.1 有關路由選擇協議的幾個基本概念
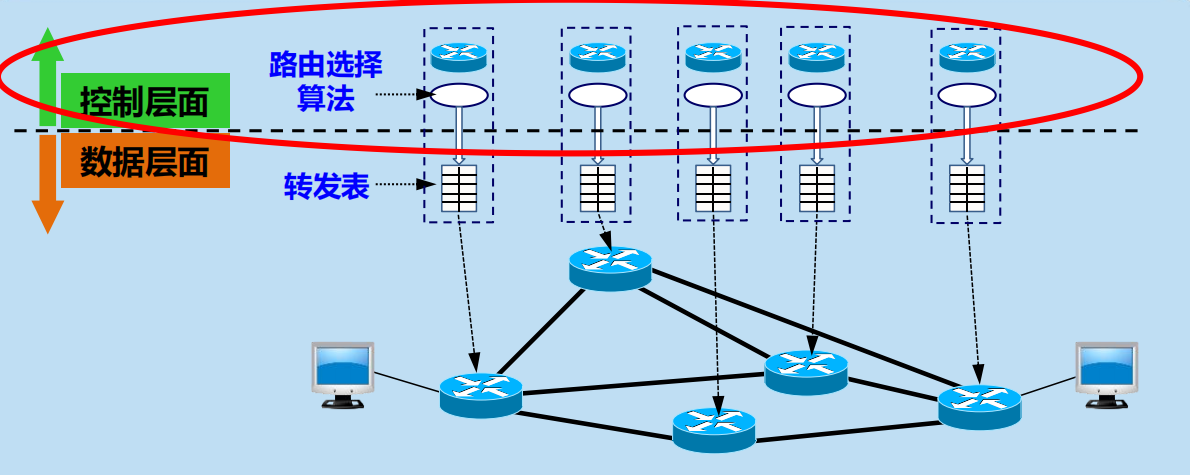
路由選擇協議屬於網路層控制層面的內容
1. 理想的路由演算法

關於「最佳路由」
• 不存在一種絕對的最佳路由演算法。
• 所謂「最佳」只能是相對於某一種特定要求下得出的較為合理的選擇而已。
路由選擇非常複雜
• 需要所有節點共同協調工作的。
• 環境不斷變化,而這種變化有時無法事先知道。
• 當網路發生擁塞時,很難獲得所需的路由選擇資訊。
路由演算法分類(動態&自適應 / 靜態&非自適應)

分層次的路由選擇協議
互聯網:
採用自適應的(即動態的)、分散式路由選擇協議。
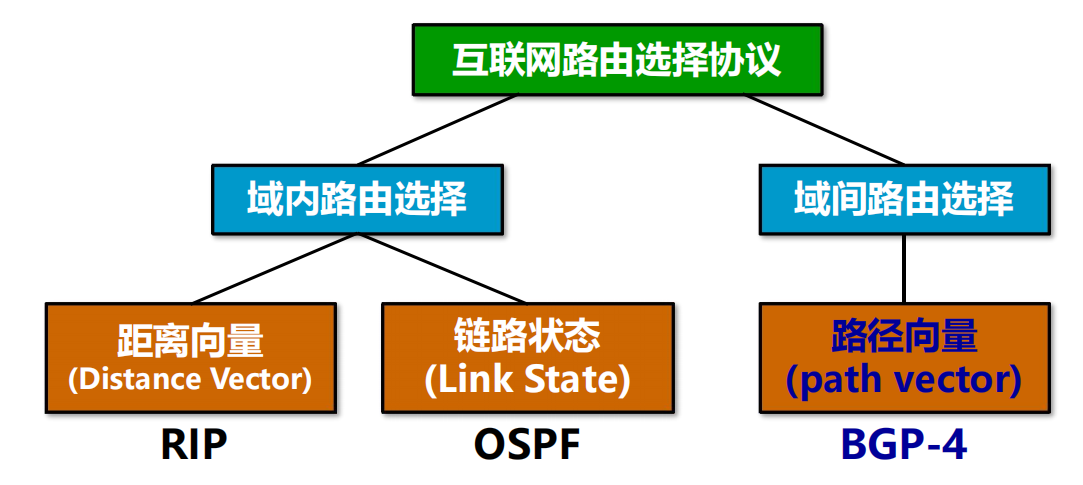
把整個互聯網劃分為許多較小的自治系統 AS,採用分層次的路由選擇協議。
分為 2 個層次:
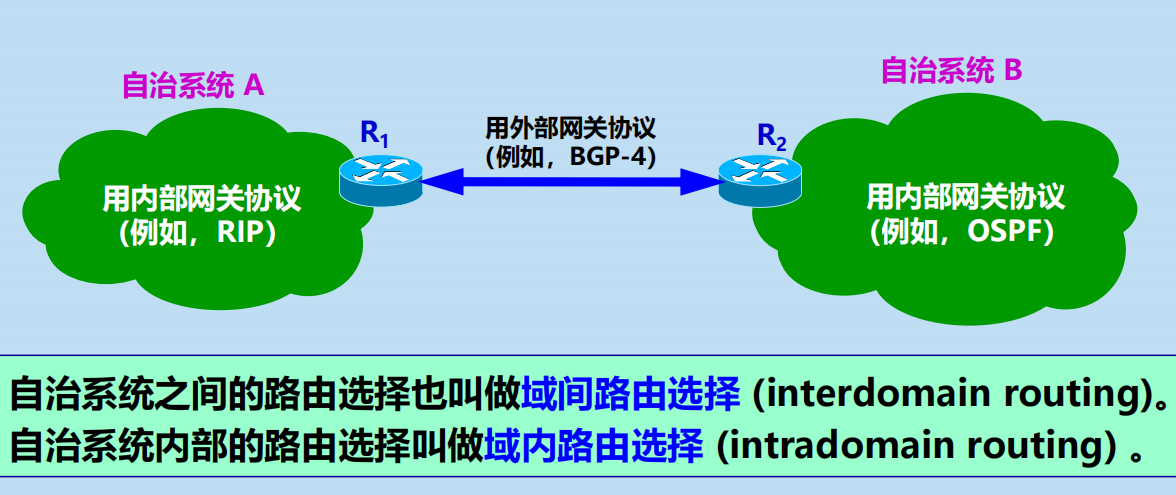
自治系統之間的路由選擇 或 域間路由選擇 (interdomain routing);
自治系統內部的路由選擇 或 域內路由選擇 (intradomain routing);
自治系統 AS (Autonomous System)
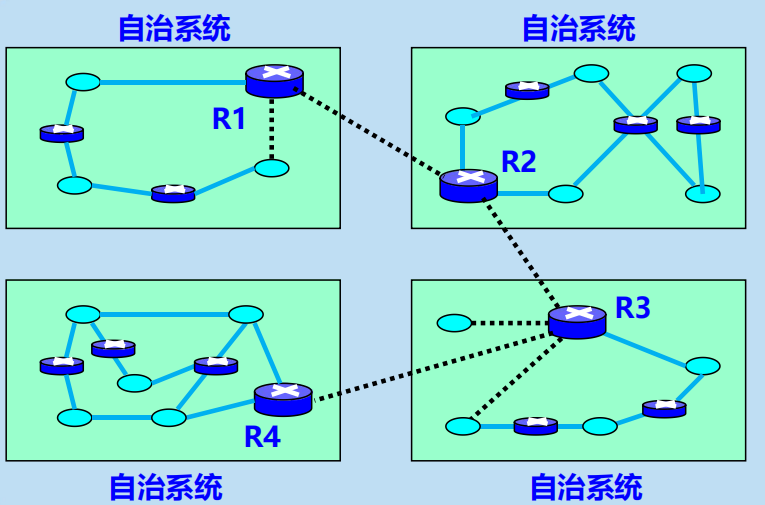
自治系統 AS :
是在單一技術管理下的許多網路、IP地址以及路由器,而這些路由器使用一種自治系統內部的路由選擇協議和共同的度量。每一個 AS 對其他 AS 表現出的是一個單一的和一致的路由選擇策略
2 大類路由選擇協議 (內部 IGP / 外部 EGP)
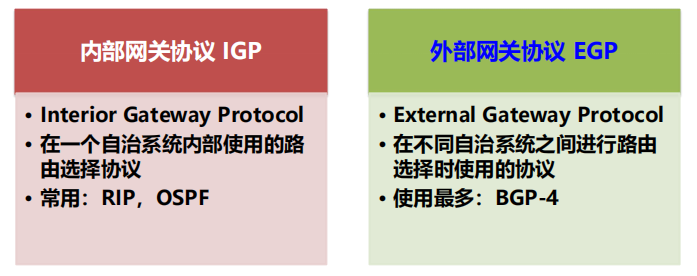
自治系統和內部網關協議、外部網關協議
4.6.2 內部網關協議 RIP
協議 RIP 的工作原理
路由資訊協議 RIP (Routing Information Protocol) 是一種分散式的、基於距離向量的路由選擇協議。
互聯網的標準協議。
最大優點:簡單。
要求網路中的每個路由器都要維護從它自己到其他每一個目的網路的距離記錄
RIP「距離」的定義
路由器到直接連接的網路的距離 = 1。
路由器到非直接連接的網路的距離 = 所經過的路由器數 + 1。
RIP 協議中的「距離」也稱為「跳數」(hop count),每經過一個路由器,跳數就加 1。
舉例
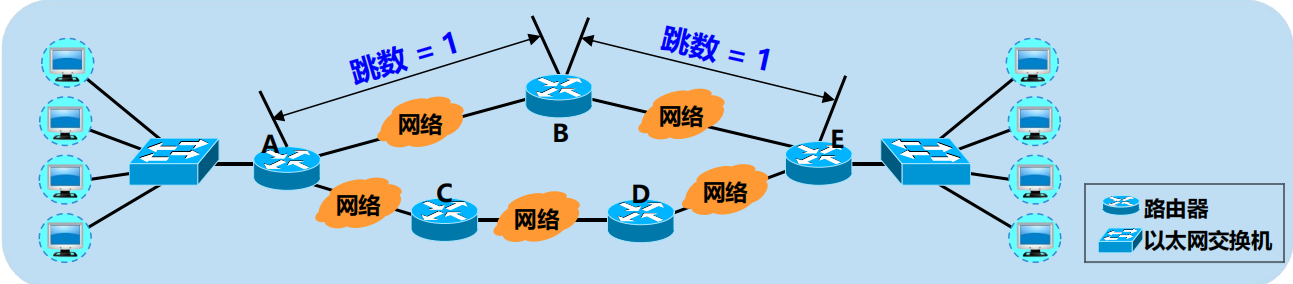
路由 A-B-E 的距離 = 2,路由 A-C-D-E 的距離 = 3。
好路由 = 「距離短」的路由。最佳路由 = 「距離最短」的路由。
一條路徑最多只能包含 15 個路由器。
「距離」的最大值為 16 時即相當於不可達。
RIP 不能在兩個網路之間同時使用多條路由,只選擇距離最短」的路由。
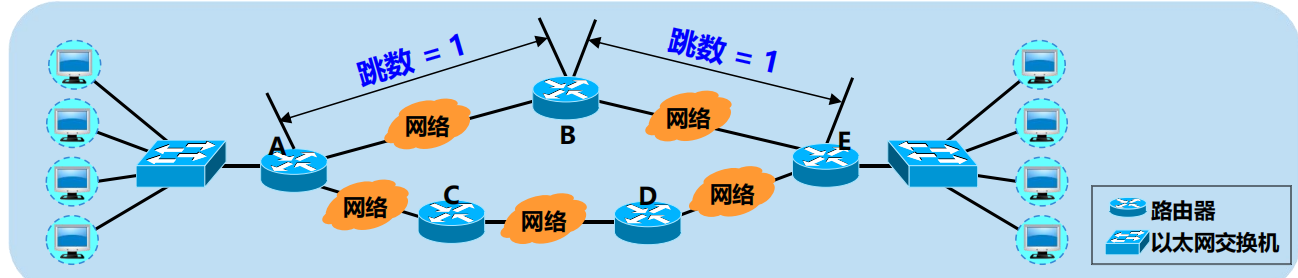
路由 A-B-E 的距離 = 2,路由 A-C-D-E 的距離 = 3。 最佳路由為 A-B-E。
RIP 協議的三個特點
1. 僅和相鄰路由器交換資訊。
2. 交換的資訊是當前本路由器所知道的全部資訊,即自己的路由表。
3. 按固定時間間隔交換路由資訊,例如,每隔 30 秒。當網路拓撲發生變化時,路由器也及時向相鄰路由器通告拓撲變化後的路由資訊。
路由表的建立
路由器在剛剛開始工作時,路由表是空的。
然後,得到直接連接的網路的距離(此距離定義為 1)。
之後,每一個路由器也只和數目非常有限的相鄰路由器交換並更新路由資訊。
經過若干次更新後,所有的路由器最終都會知道到達本自治系統中任何一個網路的最短距離和下一跳路由器的地址。
RIP 協議的收斂 (convergence) 過程較快。 「收斂」就是在自治系統中所有的結點都得到正確的路由選擇資訊的過程。
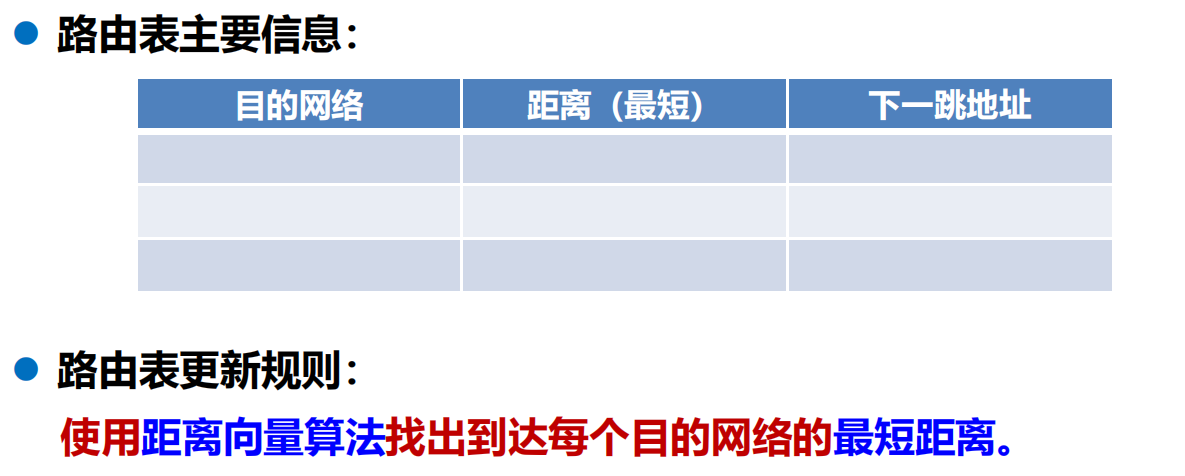
路由表主要資訊和更新規則
距離向量演算法
對每個相鄰路由器(假設其地址為 X)發送過來的 RIP 報文,路由器:
(1) 修改 RIP 報文中的所有項目(即路由):把「下一跳」欄位中的地址都改為 X,並把所有的「距離」欄位的值加 1。
(2) 對修改後的 RIP 報文中的每一個項目,重複以下步驟:
若路由表中沒有目的網路N,則把該項目添加到路由表中。否則
若路由表中網路 N 的下一跳路由器為 X,則用收到的項目替換原路由表中的項目。否則
若收到項目中的距離小於路由表中的距離,則用收到項目更新原路由表中的項目。否則什麼也不做。
(3) 若 3 分鐘還未收到相鄰路由器的更新路由表,則把此相鄰路由器記為不可達路由器,即將距離置為 16(表示不可達)。
(4) 返回。
演算法基礎:Bellman-Ford 演算法(或 Ford-Fulkerson 演算法)。
演算法要點:
設 X 是結點 A 到 B 的最短路徑上的一個結點。
若把路徑 A→B 拆成兩段路徑 A→X 和 X→B,則每一段路徑 A→X 和 X→B 也都分別是結點 A 到 X 和結點 X 到 B 的最短路徑。
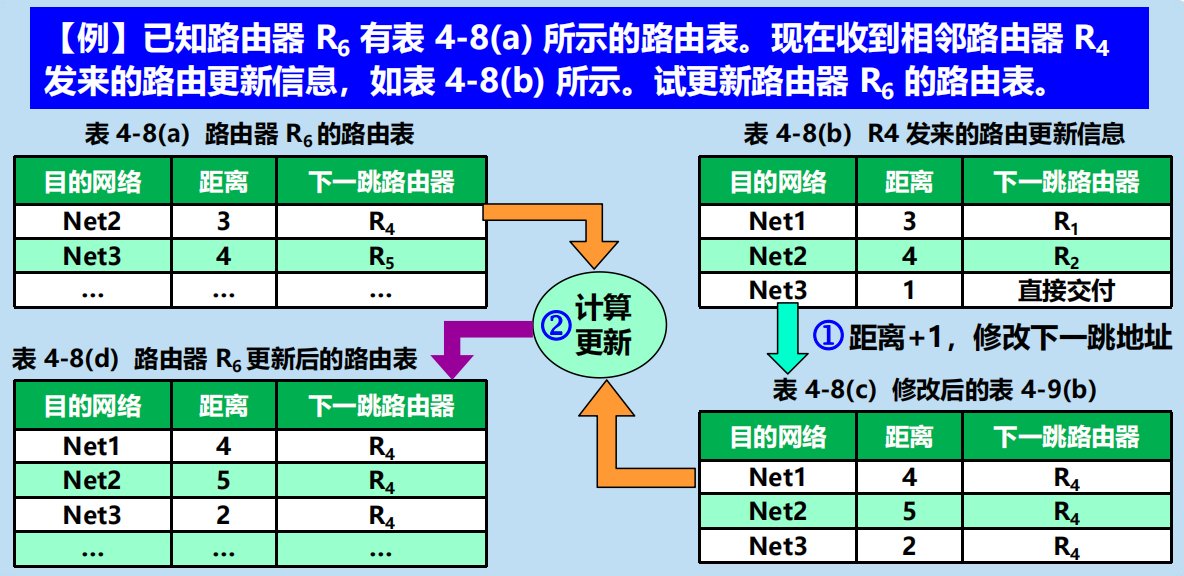
例題1:
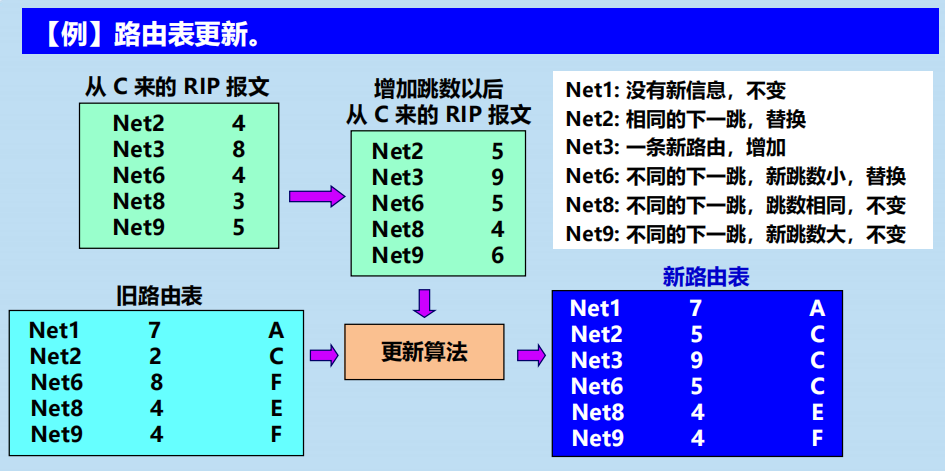
例題2:
RIP2 報文
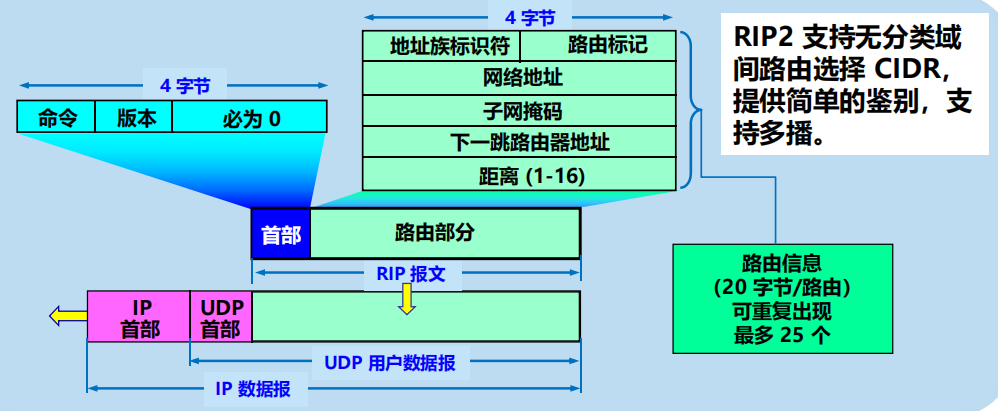
RIP2 的報文用使用 UDP 傳送(使用 UDP 埠 520)。
組成:首部和路由 2 個部分。
路由部分:由若干個路由資訊組成。每個路由資訊共 20 個位元組。
地址族標識符(又稱為地址類別)欄位用來標誌所使用的地址協議。
路由標記填入自治系統的號碼。
後面為具體路由,指出某個網路地址、該網路的子網掩碼、下一跳路由器地址以及到此網路的距離。
一個 RIP 報文最多可包括 25 個路由,因而 RIP 報文的最大長度是4+20 x25=504 位元組。如超過,必須再用一個 RIP 報文來傳送。
RIP2 具有簡單的鑒別功能。
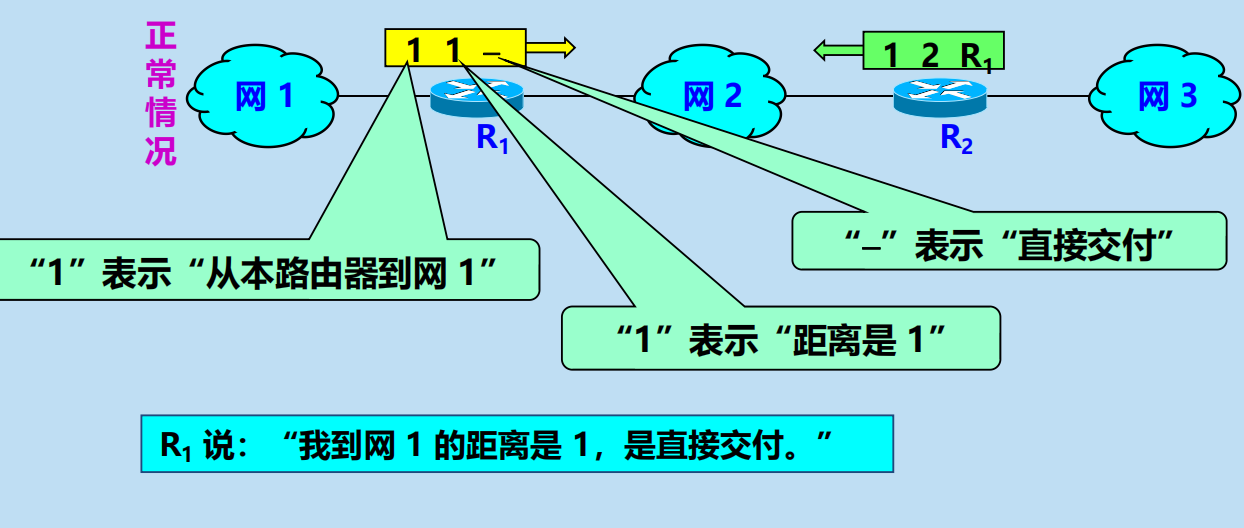
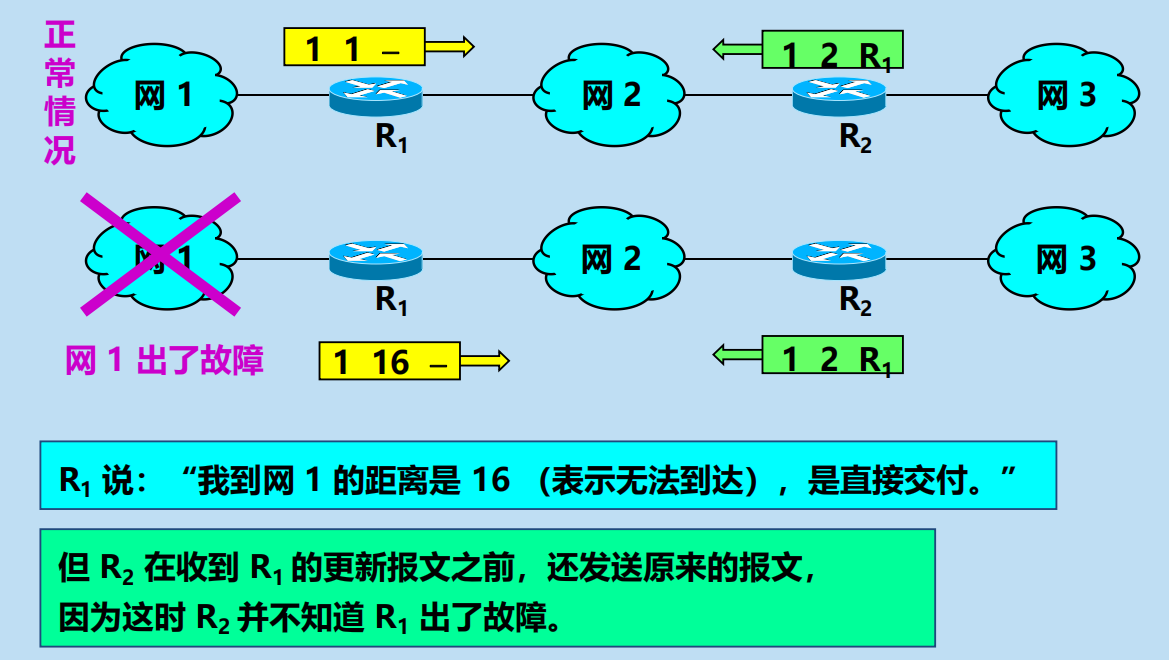
RIP 協議特點(壞事不出門,好事傳千里)
RIP 協議特點:好消息傳播得快,壞消息傳播得慢。
問題:壞消息傳播得慢(慢收斂)。
導致:
當網路出現故障時,要經過比較長的時間才能將此資訊(壞消息)傳送到所有的路由器。
例如:

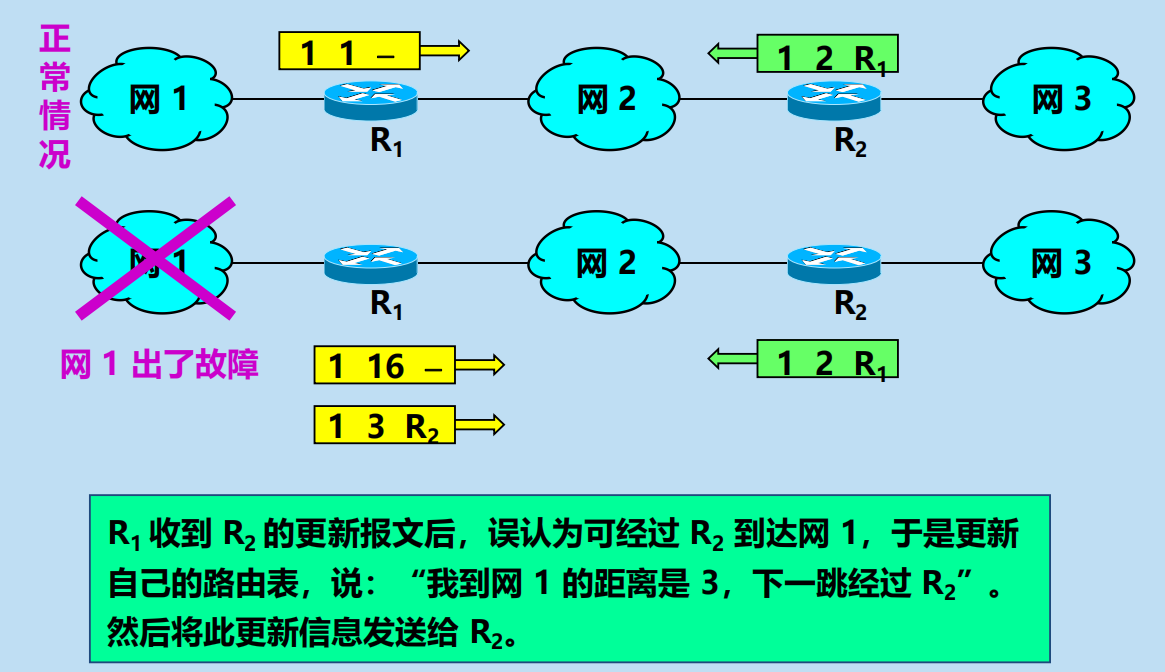
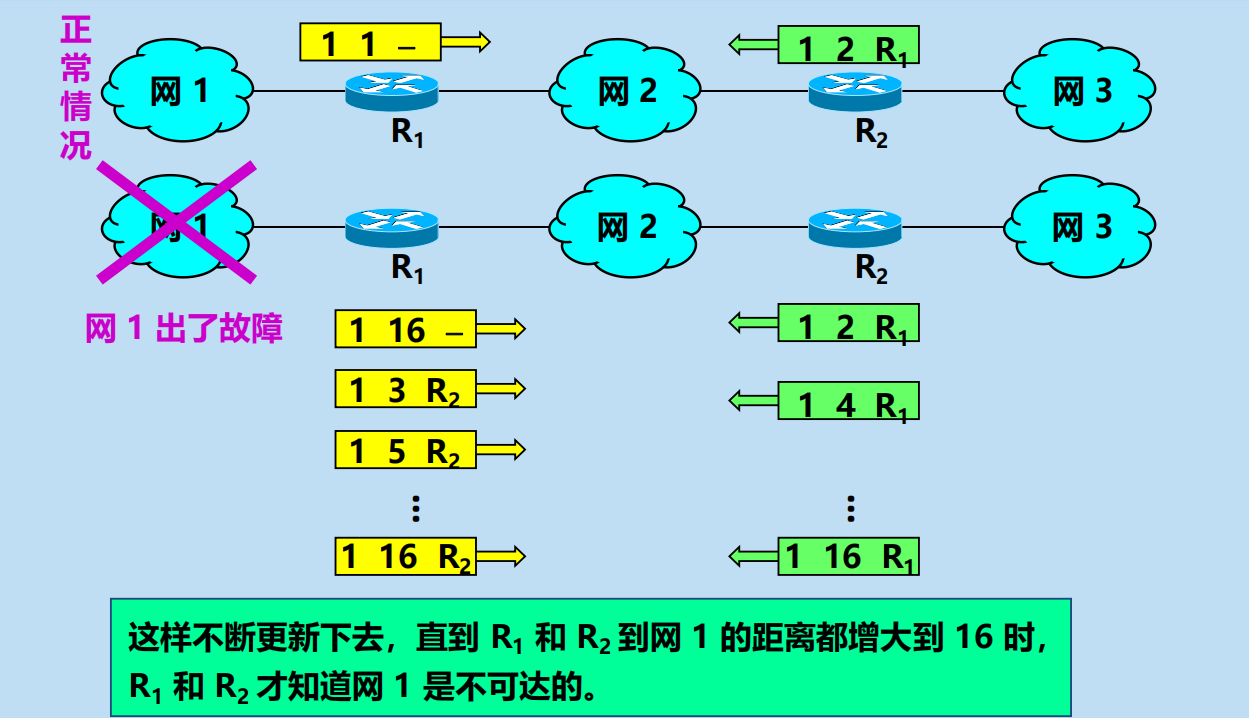
這就是好消息傳播得快,而壞消息傳播得慢。這是 RIP 的一個主要缺點。
RIP 協議的優缺點
優點:
1. 實現簡單,開銷較小。
缺點:
1. 網路規模有限。最大距離為 15(16 表示不可達)。
2. 交換的路由資訊為完整路由表,開銷較大。
3. 壞消息傳播得慢,收斂時間過長。
4.6.3 內部網關協議 OSPF
l 開放最短路徑優先 OSPF (Open Shortest Path First)是為克服RIP 的缺點在 1989 年開發出來的。
l 原理很簡單,但實現很複雜。
l 使用了 Dijkstra 提出的最短路徑演算法 SPF。
l 採用分散式的鏈路狀態協議 (link state protocol)。
l 現在使用 OSPFv2。
三個主要特點
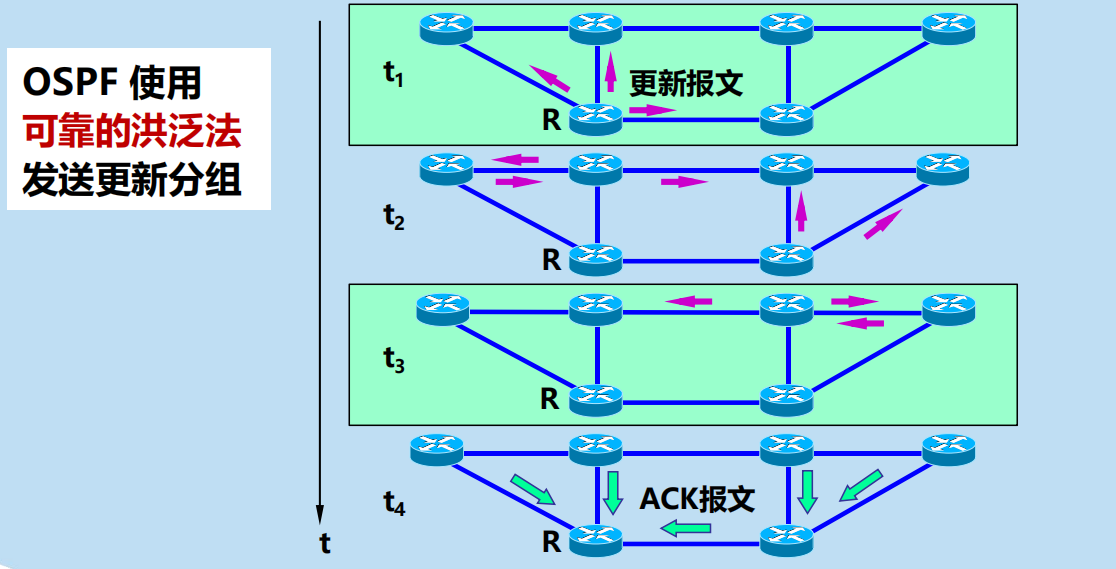
採用洪泛法 (flooding),向本自治系統中所有路由器發送資訊。
發送的資訊是與本路由器相鄰的所有路由器的鏈路狀態,但這只是路由器所知道的部分資訊。
鏈路狀態(網路拓撲結構):說明本路由器都和哪些路由器相鄰,以及該鏈路的度量 (metric)。
當鏈路狀態發生變化或每隔一段時間(如30分鐘),路由器才用洪
泛法向所有路由器發送此資訊
鏈路狀態資料庫 (link-state database)
每個路由器最終都能建立。
全網的拓撲結構圖。
在全網範圍內是一致的(這稱為鏈路狀態資料庫的同步)。
每個路由器使用鏈路狀態資料庫中的數據構造自己的路由表(例如,使用Dijkstra的最短路徑路由演算法)。
鏈路狀態資料庫能較快地進行更新,使各個路由器能及時更新其路由表。
重要優點:OSPF 更新過程收斂速度快。
OSPF 將自治系統劃分為兩種不同的區域 (area)
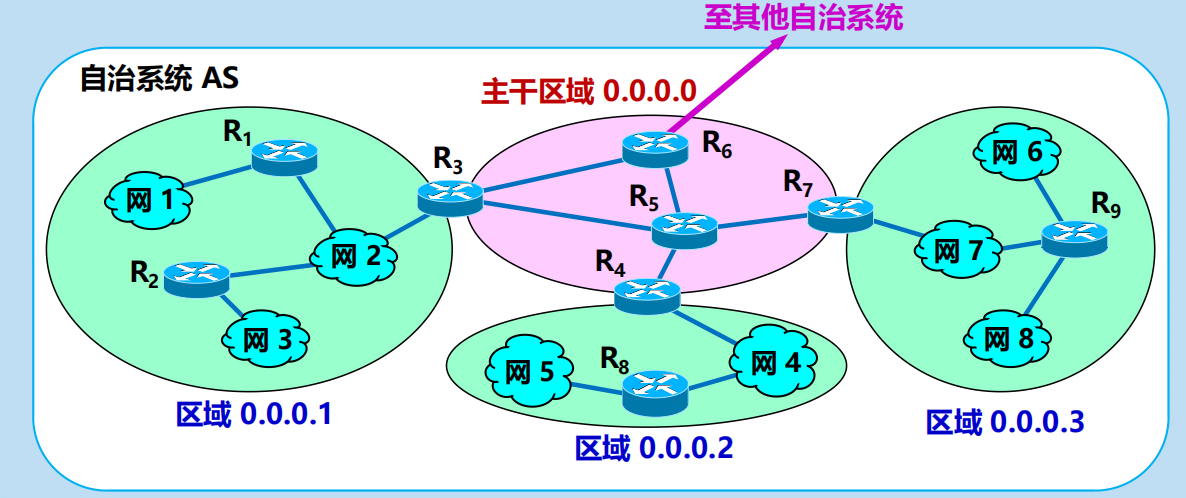
主幹區域 (backbone area) 標識符= 0.0.0.0,作用=用來連通其他下層區域。
OSPF 中的路由器:區域邊界路由器 ABR (area border router)
OSPF 中的路由器:主幹路由器 BR (backbone router)
OSPF 中的路由器:自治系統邊界路由器 ASBR (AS border router)
劃分區域優點和缺點
分層次劃分區域的好處:使每一個區域內部交換路由資訊的通訊量大大減小,因而使 OSPF 協
議能夠用於規模很大的自治系統中。
優點:
減少了整個網路上的通訊量。
減少了需要維護的狀態數量。
缺點:
交換資訊的種類增多了。
使 OSPF 協議更加複雜了
劃分區域的其他特點
對於不同類型的業務可計算出不同的路由。
可實現多路徑間的負載均衡(load balancing)。
所有在 OSPF 路由器之間交換的分組都具有鑒別的功能。
支援可變長度的子網劃分和無分類編址 CIDR。
32 位的序號,序號越大狀態就越新。全部序號空間在 600 年內不會產生重複號。
OSPF 的五種分組類型
1. 問候 (Hello) 分組。
2. 資料庫描述 (Database Description) 分組。
3. 鏈路狀態請求 (Link State Request) 分組。
4. 鏈路狀態更新 (Link State Update) 分組。
5. 鏈路狀態確認 (Link State Acknowledgment)分組。
OSPF 分組用 IP 數據報傳送
OSPF 工作過程
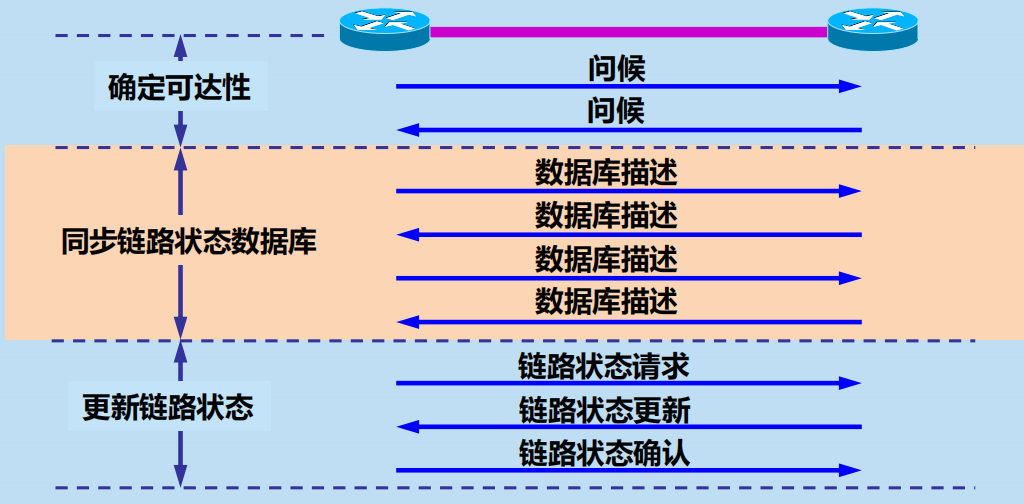
1,確定鄰站可達。
相鄰路由器每隔 10 秒鐘要交換一次問候分組。
若有 40 秒鐘沒有收到某個相鄰路由器發來的問候分組,則可認為該相鄰路由器是不可達的。
2,同步鏈路狀態資料庫。
同步:指不同路由器的鏈路狀態資料庫的內容是一樣的。
兩個同步的路由器叫做完全鄰接的 (fully adjacent) 路由器。
不是完全鄰接的路由器:它們雖然在物理上是相鄰的,但其鏈路狀態資料庫並沒有達到一致。
3,更新鏈路狀態。
只要鏈路狀態發生變化,路由器就使用鏈路狀態更新分組,採用可靠的洪泛法向全網更新鏈路狀態。
為確保鏈路狀態資料庫與全網的狀態保持一致,OSPF 還規定:每隔一段時間,如 30 分鐘,要刷新一次資料庫中的鏈路狀態。
OSPF 鏈路狀態只涉及相鄰路由器,與整個互聯網的規模並無直接關係,
因此當互聯網規模很大時,OSPF 協議要比距離向量協議 RIP 好得多。
OSPF 沒有「壞消息傳播得慢」的問題,收斂數度快。
指定的路由器 DR
多點接入的區域網採用了指定的路由器 DR (designated router)的方法,使廣播的資訊量大大減少。
指定的路由器代表該區域網上所有的鏈路向連接到該網路上的各路由器發送狀態資訊。
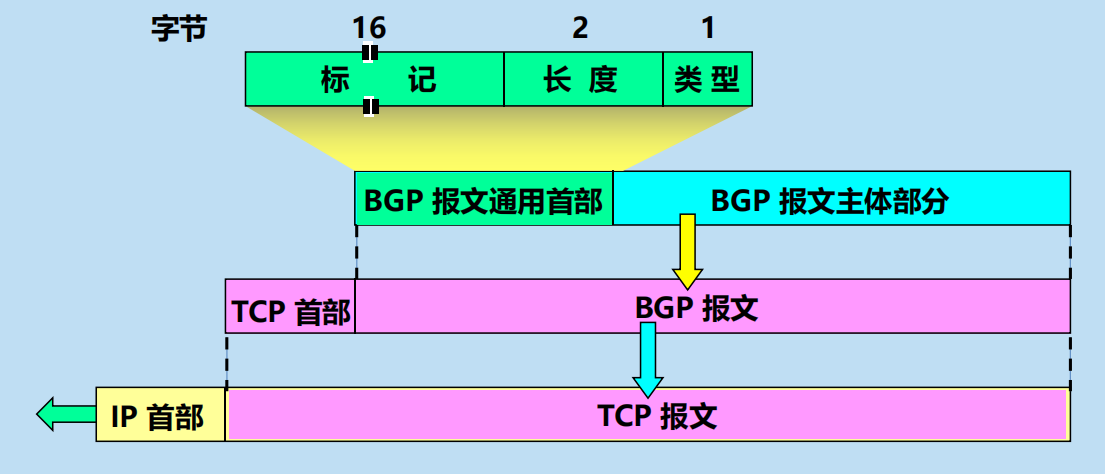
4.6.4 外部網關協議 BGP
BGP 是不同自治系統的路由器之間交換路由資訊的協議。
BGP 較新版本是 2006 年 1 月發表的 BGP-4(BGP 第 4 個版本),即 RFC 4271 ~ 4278。
可以將 BGP-4 簡寫為 BGP。
協議 BGP 的主要特點
用於自治系統 AS 之間的路由選擇。
只能是力求選擇出一條能夠到達目的網路且比較好的路由(不能兜圈子),而並非要計算出一條最佳路由。
1. 互聯網的規模太大,使得自治系統AS之間路由選擇非常困難。
2. 自治系統AS之間的路由選擇必須考慮有關策略。
採用了路徑向量 (path vector) 路由選擇協議。
BGP 發言者 (BGP speaker)
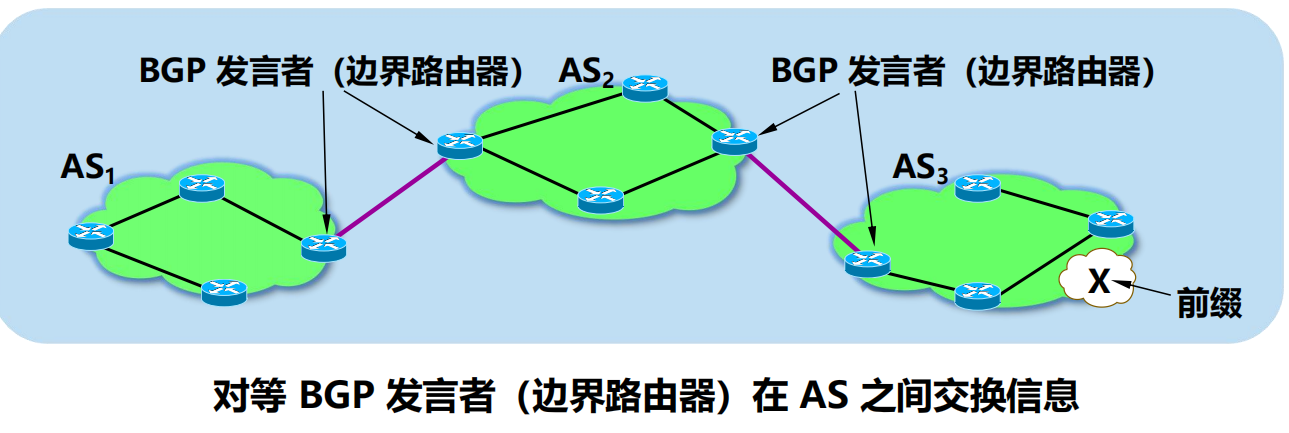
(外)eBGP 連接和(內) iBGP 連接

在 AS 之間, BGP 發言者在半永久性 TCP 連接(埠號為179)上建立 BGP 會話(session)。這種連接又稱為 eBGP 連接。
在 AS 內部,任何相互通訊的兩個路由器之間必須有一個邏輯連接(也使用 TCP 連接)。AS 內部所有的路由器之間的通訊是全連通的。這種連接常稱為 iBGP 連接。
eBGP (external BGP) 連接:運行 eBGP 協議,在不同 AS 之間交換路由資訊。
iBGP (internal BGP) 連接:運行 iBGP 協議, 在 AS 內部的路由器之間交換 BGP 路由資訊。
IGP、iBGP 和 eBGP 的關係
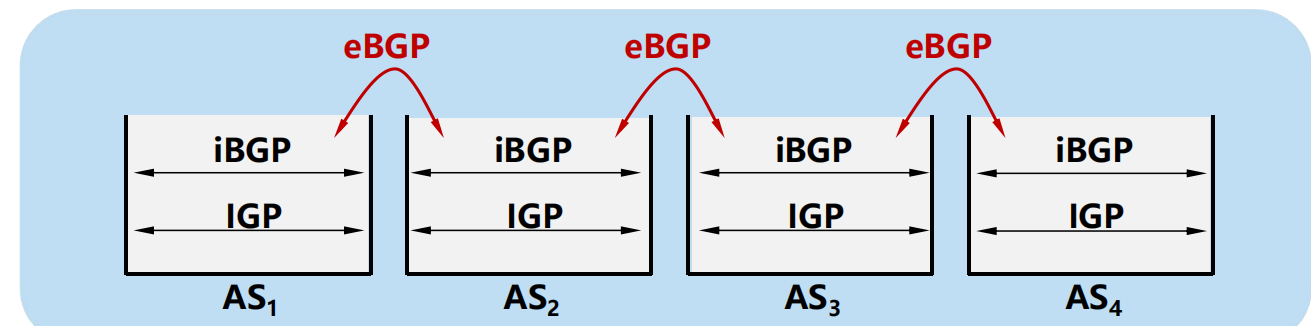
在 AS 內部運行:
內部網關協議 IGP(可以是協議 OSPF 或 RIP)。
協議 iBGP。
在 AS 之間運行:
協議 eBGP。
eBGP 和 iBGP 的異同
同一個協議 BGP(使用的報文類型、使用的屬性、使用的狀態機等都完全一樣)。
但它們在通報前綴時採用的規則不同:(由外到內可以,由內到位也可以,內到內不行)
在 eBGP 連接的對等端得知的前綴資訊,可以通報給一個 iBGP連接的對等端。反過來也是可以的。
但從 iBGP 連接的對等端得知的前綴資訊,則不能夠通報給另一個 iBGP 連接的對等端。
舉例:
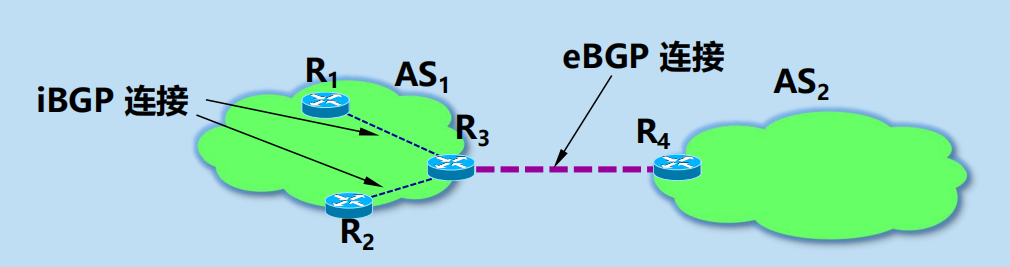
R3 從 eBGP 連接的對等端 R4 得到的前綴資訊可以通報給 iBGP 連接的對等端 R1 或 R2。
R3 從 iBGP 連接的對等端 R1 和 R2 得到的前綴資訊可以通報給 eBGP 連接的對等端 R4。
但 R3 從 iBGP 連接的對等端 R1 得到的前綴資訊不允許再通報給另一個 iBGP 連接的對等端 R2。
BGP 路由資訊
BGP 路由 = [ 前綴, BGP屬性 ] = [ 前綴, AS-PATH, NEXT-HOP ]
前綴:指明到哪一個子網(用 CIDR 記法表示)。
BGP 屬性:最重要的兩個屬性是
自治系統路徑 AS-PATH
下一跳 NEXT-HOP。
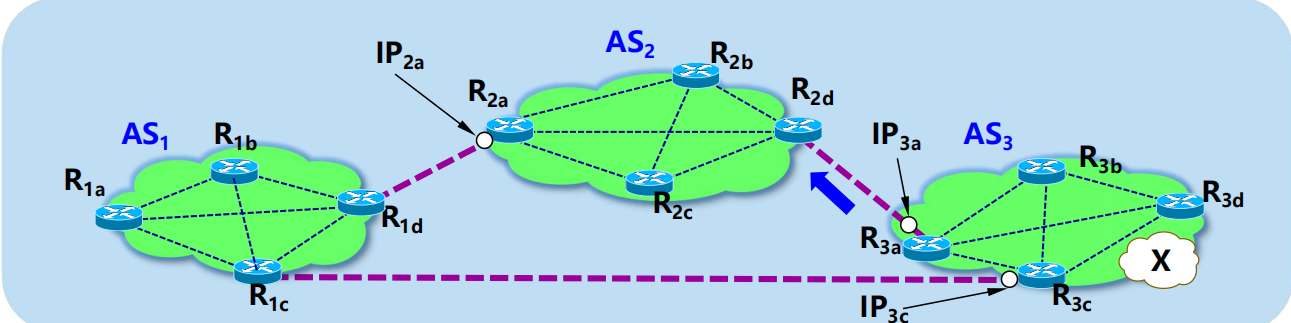
AS2 可經 IP3a 到前綴 X 的路由 = [前綴, AS-PATH, NEXT-HOP] = [X, AS3, IP3a]
路由 1:AS1 可經 IP2a 到前綴 X 的路由 = [前綴, AS-PATH, NEXT-HOP] = [X, AS2 AS3 , IP2a]
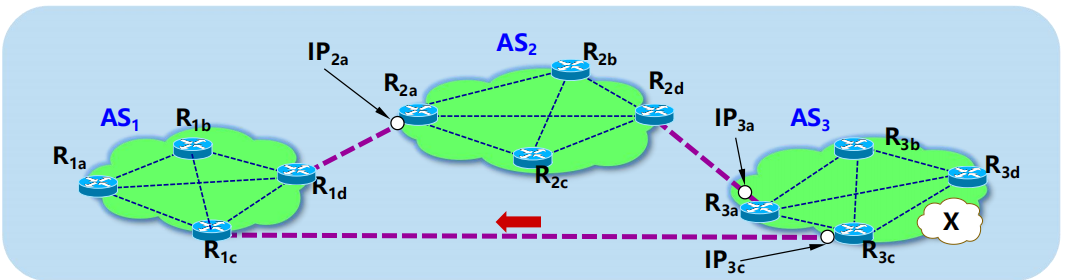
路由2:AS1 可經 IP3c 到前綴 X 的路由 = [前綴, AS-PATH, NEXT-HOP] = [X, AS3, IP3c]
路由器 R1a 的轉發表中,沿 BGP 路由 1 到達前綴 X 的項目是:
(匹配前綴X,下一跳路由器 R1b)或(匹配前綴X,轉發介面 0)。
三種不同的自治系統 AS
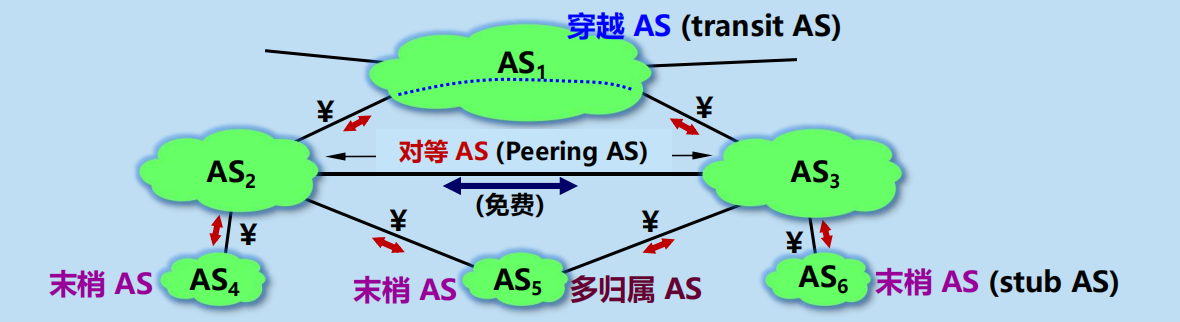
末梢 AS:不會把來自其他 AS 的分組再轉發到另一個 AS。必須向所連接的 AS 付費。
多歸屬 AS (multihomed AS):同時連接到兩個或兩個以上的 AS。增加連接的可靠性。
穿越 AS:為其他 AS 有償轉發分組。
對等 AS:經過事先協商的兩個 AS,彼此之間的發送或接收分組都不收費。
問:BGP 路由如何避免兜圈子?
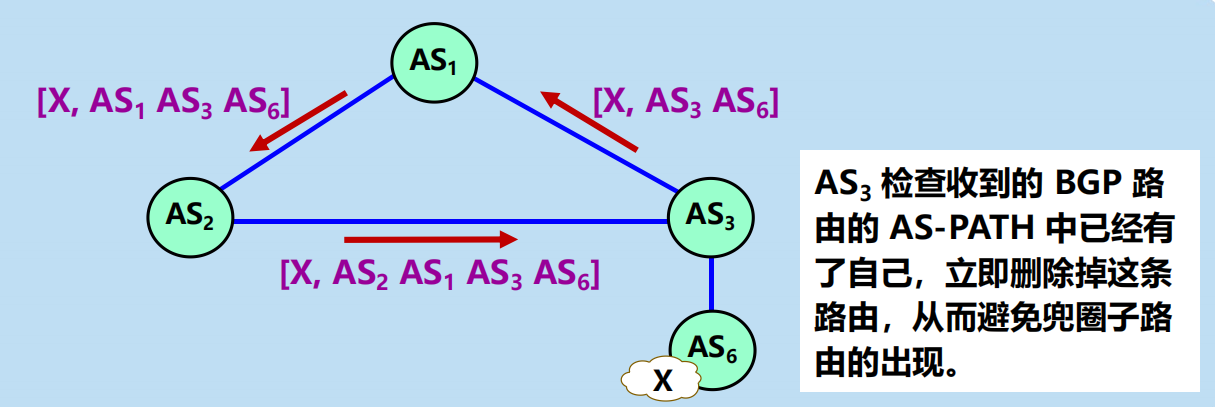
請記住:在屬性 AS-PATH 中,不允許出現相同的 AS 號。
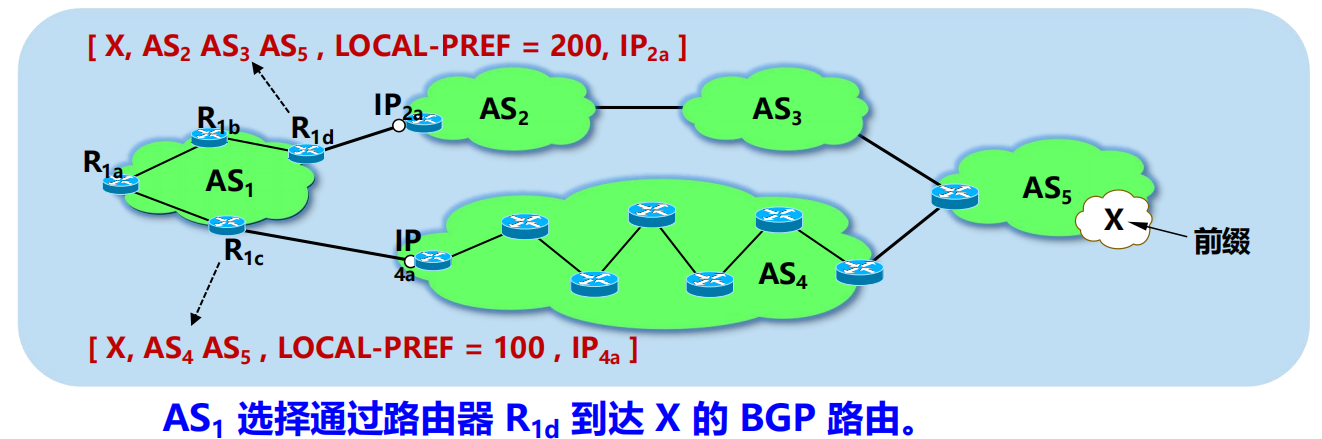
BGP 的路由選擇

本地偏好 (local preference) 值最高
AS 跳數最小
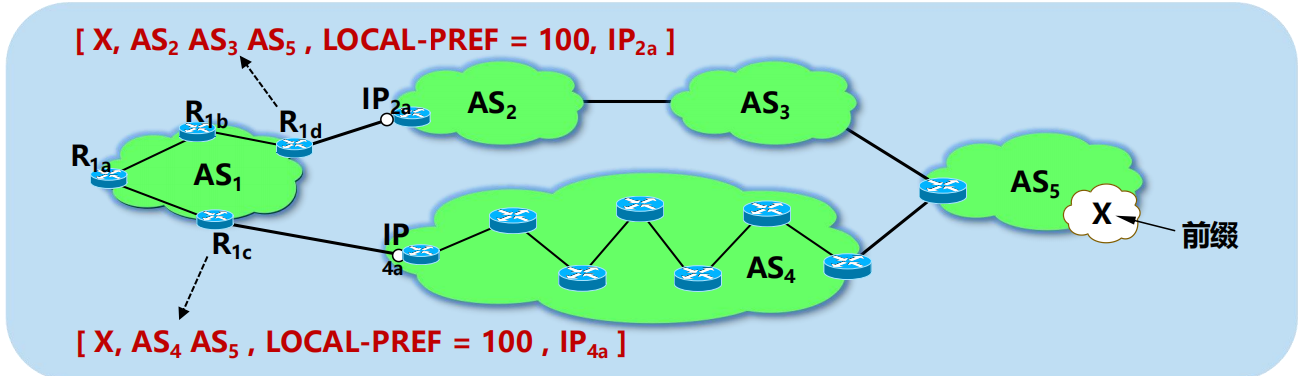
AS1 選擇通過路由器 R1c 到達 X 的 BGP 路由。
但事實上,分組在 AS4 中反而要經過更多次數的轉發。
說明協議 BGP 不存在真正的最佳路由選擇。
熱土豆路由選擇演算法
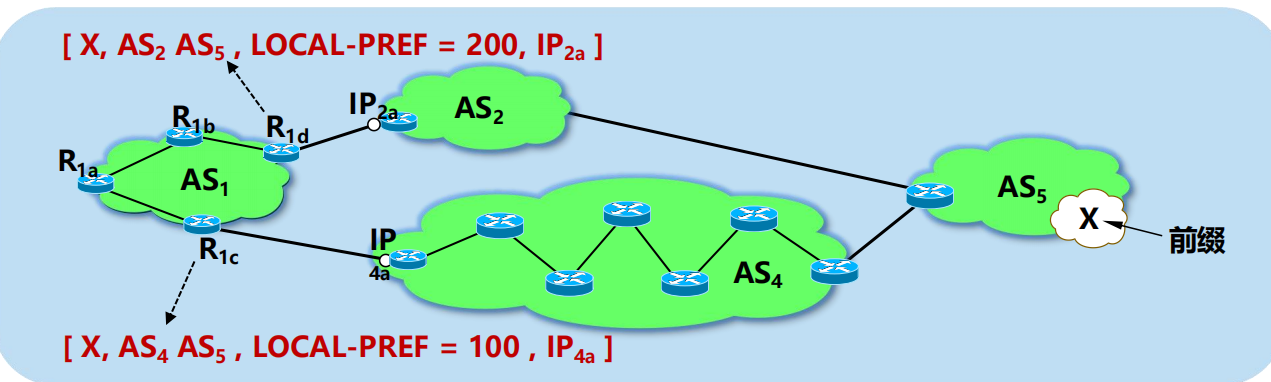
R1a 選擇 R1c 作為離開 AS1 的最佳選擇,其 BGP 轉發表中對應的
項目應當是:(匹配前綴 X,下一跳路由器 R1c)。
R1b 選擇 R1d 作為離開 AS1 的最佳選擇,其 BGP 轉發表中對應的
項目應當是:(匹配前綴 X,下一跳路由器 R1d)。
4.6.5 路由器的構成
路由器工作在網路層,用於互連網路。
是互聯網中的關鍵設備。
路由器的主要工作:轉發分組。
把從某個輸入埠收到的分組,按照分組要去的目的地(即目的網路),把該分組從路由器的某個合適的輸出埠轉發給下一跳路由器。
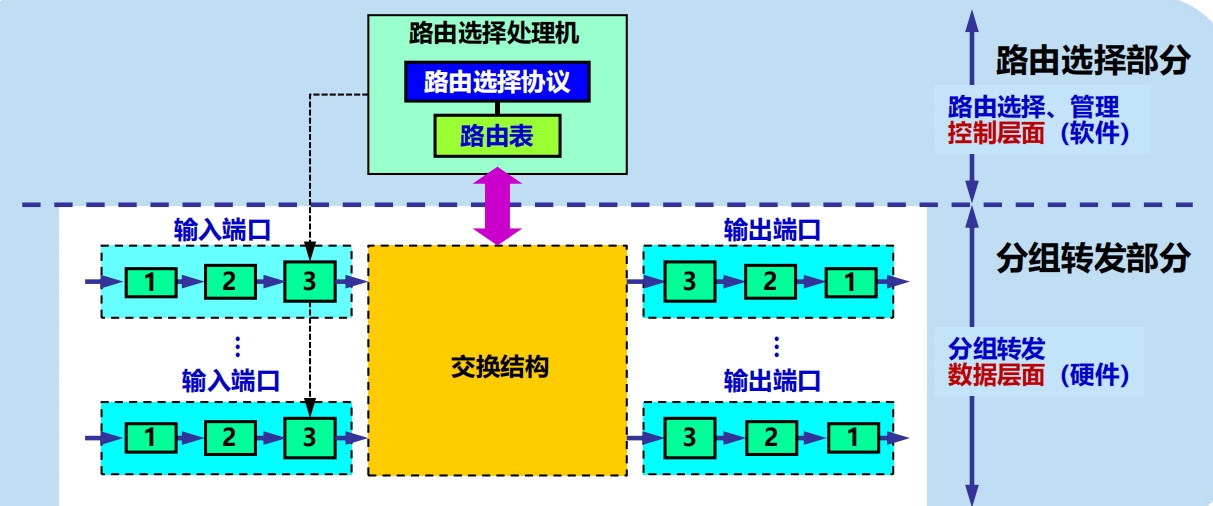
路由器的結構
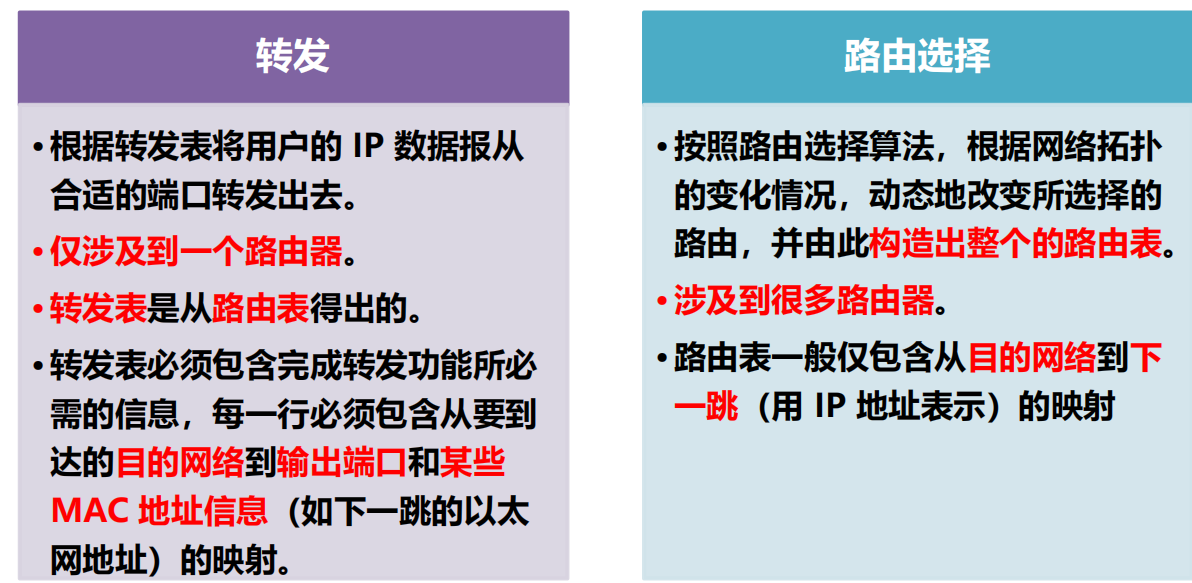
「轉發」和「路由選擇」的區別
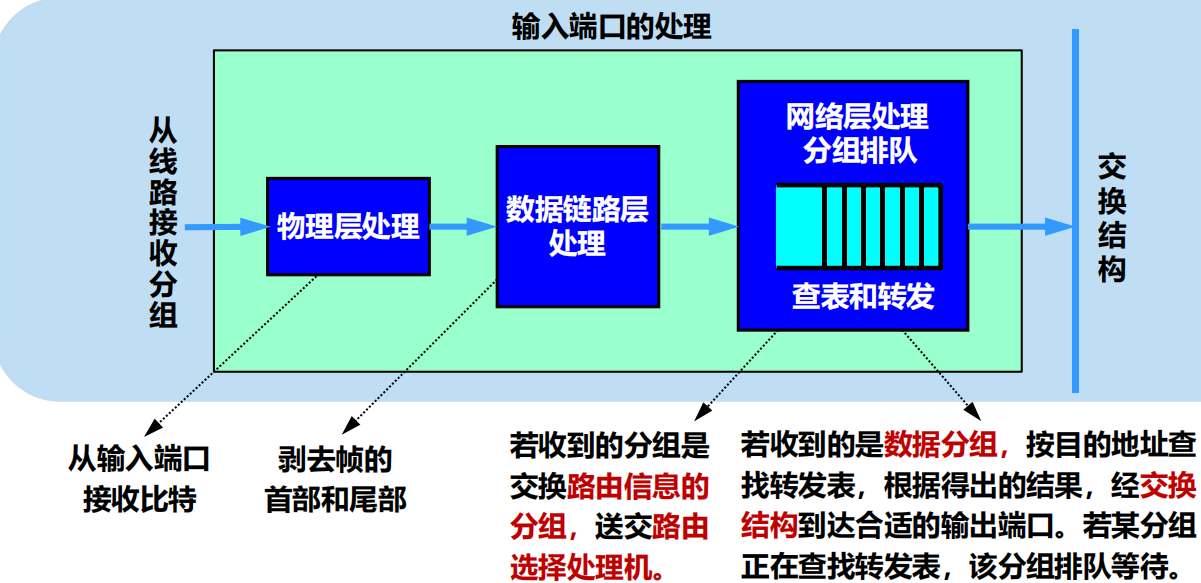
輸入埠對線路上收到的分組的處理
輸出埠將交換結構傳送來的分組發送到線路
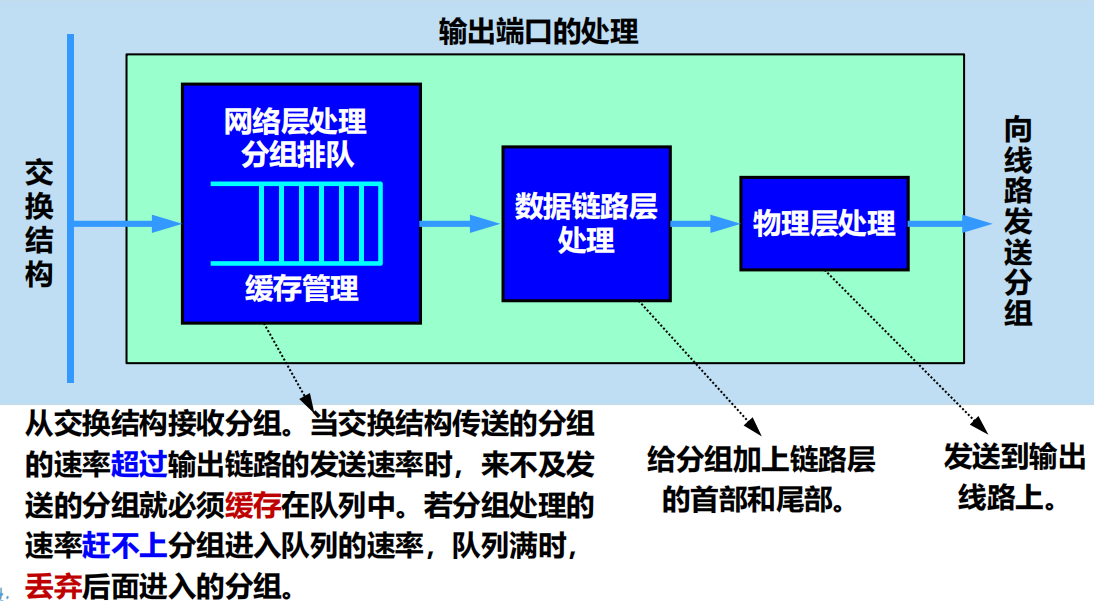
交換結構
常用交換方法有三種:通過存儲器、通過匯流排、通過縱橫交換結構。
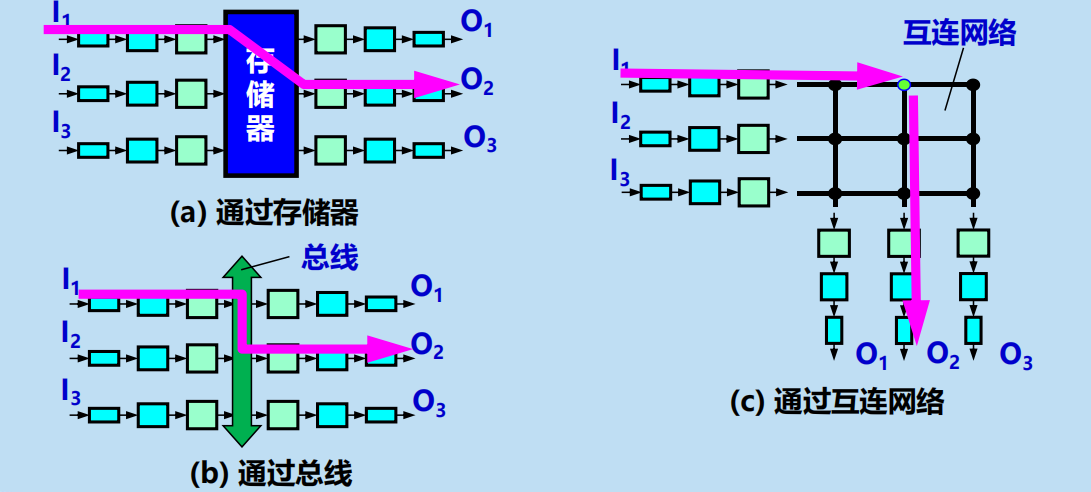
通過存儲器
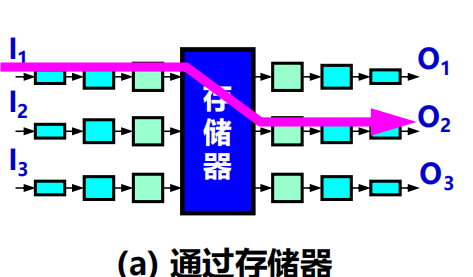
(1) 當路由器的某個輸入埠收到一個分組時,就用中斷方式通知路由選擇處理機。然後分組就從輸入埠複製到存儲器中。
(2) 路由器處理機從分組首部提取目的地址,查找路由表,再將分組複製到合適的輸出埠
的快取中。
(3) 若存儲器的頻寬(讀或寫)為每秒 M 個分組,那麼路由器的交換速率(即分組從輸入埠傳送到輸出埠的速率)一定小於 M/2。
通過匯流排
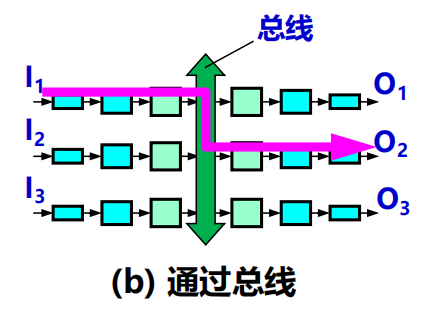
(1) 數據報從輸入埠通過共享的匯流排直接傳送到合適的輸出埠,而不需要路由選擇處
理機的干預。
(2) 當分組到達輸入埠時若發現匯流排忙,則被阻塞而不能通過交換結構,並在輸入埠
排隊等待。
(3)因為每一個要轉發的分組都要通過這一條匯流排,因此路由器的轉發頻寬就受匯流排速率
的限制。
通過縱橫交換結構 (crossbar switch fabric)
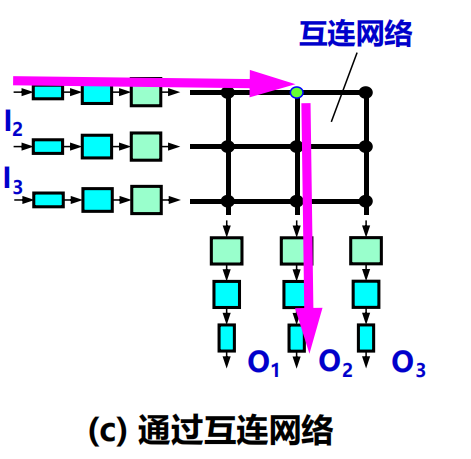
常被稱為互連網路 (interconnection network)。
(1) 它有 2N 條匯流排,控制交叉節點可以使 N 個輸入埠和 N 個輸出埠相連接。
(2) 當輸入埠收到一個分組時,就將它發送到水平匯流排上。
(3) 若通向輸出埠的垂直匯流排空閑,則將垂直匯流排與水平匯流排接通,把該分組轉發到這個輸出埠。
若輸出埠已被佔用,分組在輸入埠排隊等待。
特點:是一種無阻塞的交換結構,分組可以轉發到任何一個輸出埠,只要這個輸出埠沒有被別的
分組佔用。
重點在這裡
4.7 IP 多播
4.7.1 IP 多播的基本概念
1988 年,Steve Deering 首次提出 IP 多播的概念。
多播 (multicast):以前曾譯為組播。
目的:更好地支援一對多通訊。
一對多通訊:一個源點發送到許多個終點。
多播可大大節約網路資源
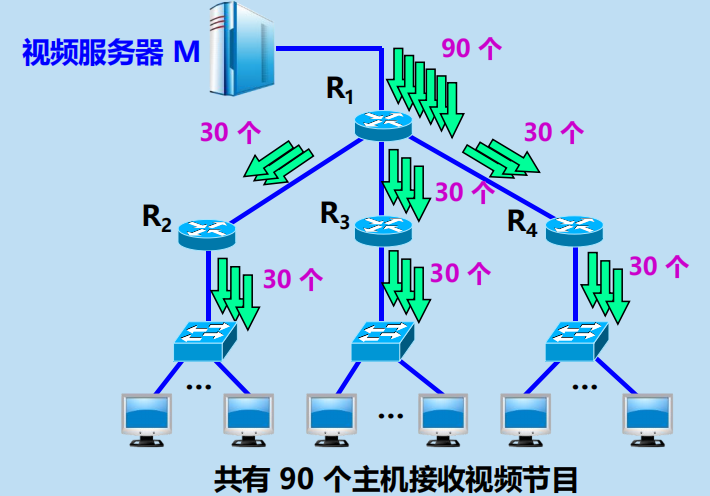
單播
採用單播方式,
向 90 台主機傳送同樣的影片節目需要發送 90 個單播
多播
採用多播方式,只需發送一次到多播組。路由器複製分組。區域網具有硬體多播功能,不需要複製分組。
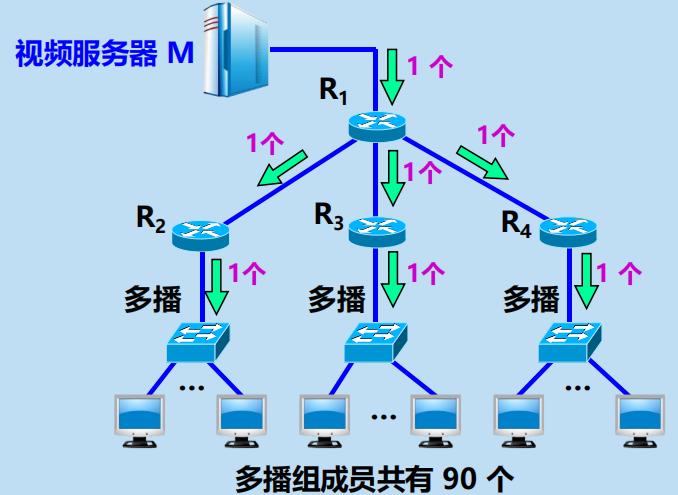
當多播組的主機數很大時(如成千上萬個),採用多播方式就可明顯地減輕網路中各種資源的消耗。
IP 多播
在互聯網上進行多播就叫做 IP 多播。
互聯網範圍的多播要靠路由器來實現。
能夠運行多播協議的路由器稱為多播路由器 (multicast router)。
多播路由器也可以轉發普通的單播 IP 數據報。
從 1992 年起,在互聯網上開始試驗虛擬的多播主幹網 MBONE(Multicast Backbone On the InterNEt)。
多播 IP 地址
在 IP 多播數據報的目的地址需要寫入多播組的標識符。
多播組的標識符就是 IP 地址中的 D 類地址(多播地址)。
地址範圍:224.0.0.0 ~ 239.255.255.255
每一個 D 類地址標誌一個多播組。
多播地址只能用於目的地址,不能用於源地址。
多播數據報
多播數據報和一般的 IP 數據報的區別:
目的地址:使用 D 類 IP 地址。
協議欄位 = 2,表明使用網際組管理協議 IGMP。
盡最大努力交付,不保證一定能夠交付多播組內的所有成員。
對多播數據報不產生 ICMP 差錯報文。在 PING 命令後面鍵入多播地址,將永遠不會收到響應
4.7.2 在區域網上進行硬體多播
互聯網數字分配機構(IANA )擁有的乙太網地址塊的高 24 位為00-00-5E。
TCP/IP 協議使用的乙太網地址塊的範圍是
從 00-00-5E-00-00-00
到 00-00-5E-FF-FF-FF
IANA 只拿出 01-00-5E-00-00-00 到 01-00-5E-7F-FF-FF (223個地址)作為乙太網多播地址。或者說,在 48 位的多播地址中,前25 位都固定不變,只有後 23 位可用作多播。
D 類 IP 地址與乙太網多播地址的映射關係

收到多播數據報的主機,還要在 IP 層對 IP 地址進行過濾,把不是本主機要接收的數據報丟棄。
4.7.3 網際組管理協議 IGMP 和多播路由選擇協議
IP 多播需要兩種協議
網際組管理協議 IGMP (Internet Group Management Protocol)
使多播路由器知道多播組成員資訊(有無成員)。
多播路由選擇協議
使多播路由器協同工作,把多播數據報用最小代價傳送給多播組的所有成員。
IGMP 使多播路由器知道多播組成員資訊
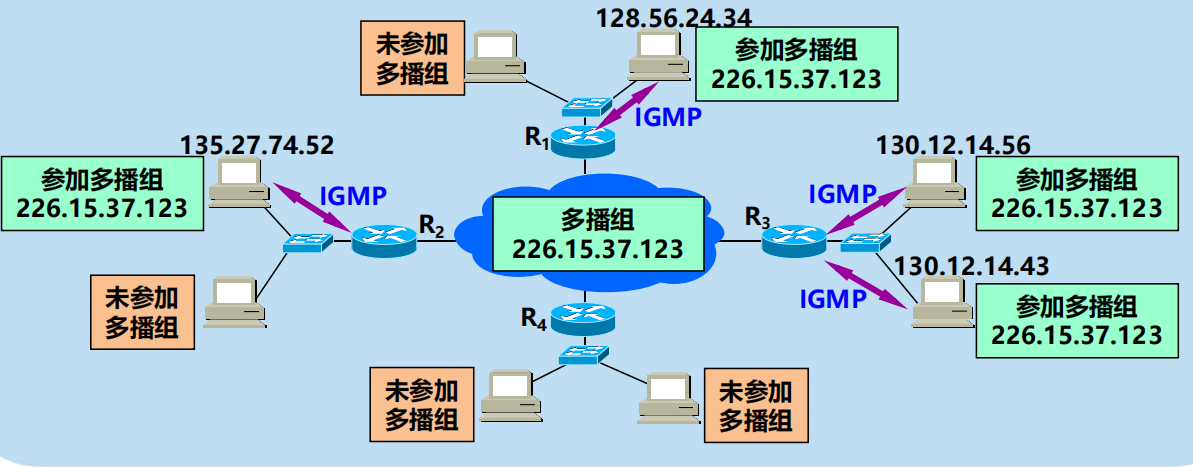
IGMP 協議是讓連接在本地區域網上的多播路由器知道本區域網上是否有主機參加或退出了某個多播組。IGMP 不知道 IP 多播組包含的成員數,也不知道這些成員都分布在哪些網路上。
多播路由選擇協議更為複雜
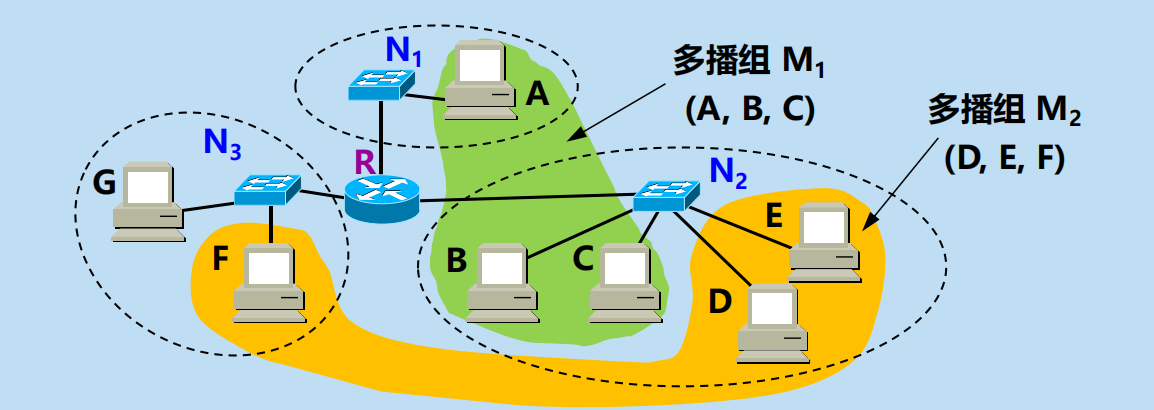
路由器 R 不應當向網路 N3 轉發多播組 M1 的分組,因為網路 N3 上沒有多播組 M1 的成員。
多播轉發必須動態地適應多播組成員的變化(這時網路拓撲並未發生變化),因為每一台主機可以隨時加入或離開一個多播組。
多播路由器在轉發多播數據報時,不能僅僅根據多播數據報中的目的地址,還要考慮這個多播數據報從什麼地方來和要到什麼地方去。
多播數據報可以由沒有加入多播組的主機發出,也可以通過沒有組成員的接入網路。
網際組管理協議 IGMP
1989 年公布的 RFC 1112(IGMPv1)已成為了互聯網的標準協議。
1997 年公布的 RFC 2236(IGMPv2,建議標準)對 IGMPv1 進
行了更新。
2002 年 10 月公布了 RFC 3376(IGMPv3,建議標準)。
IGMP 使用 IP 數據報傳遞其報文
在 IGMP 報文加上 IP 首部構成 IP 數據報。
但 IGMP 也向 IP 提供服務。
因此,不把 IGMP 看成是一個單獨的協議,而是整個網際協議 IP的一個組成部分。
IGMP 工作可分為兩個階段
第一階段:加入多播組。
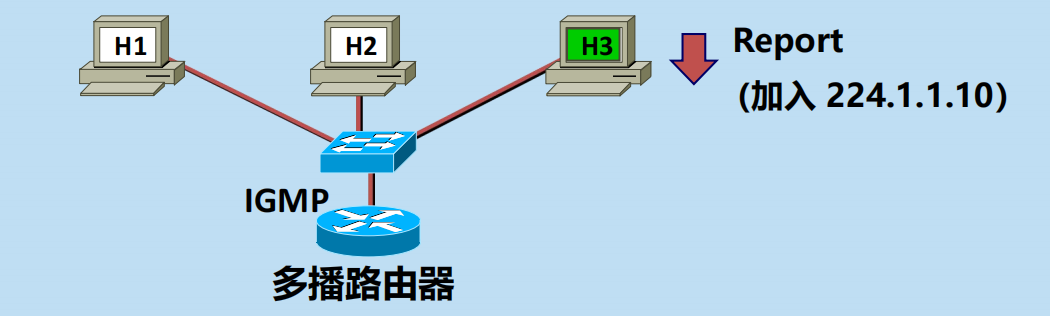
1. 當某個主機加入多播組時,該主機向多播組的多播地址發送 IGMP 報文,聲明自己要成為該組的成員。
2. 本地的多播路由器收到 IGMP 報文後,將組成員關係轉發給互聯網上的其他多播路由器。
第二階段:探詢組成員變化情況。
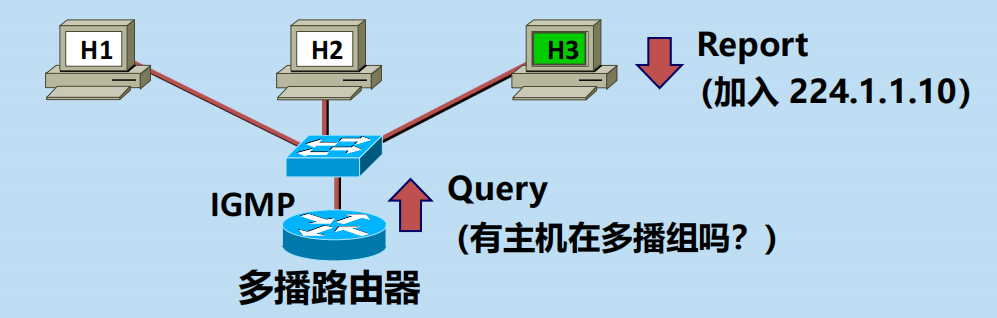
1.本地多播路由器周期性地探詢本地區域網上的主機,以便知道這些主機是否還繼續是組的成員。
2. 只要對某個組有一個主機響應,那麼多播路由器就認為這個組是活躍的。
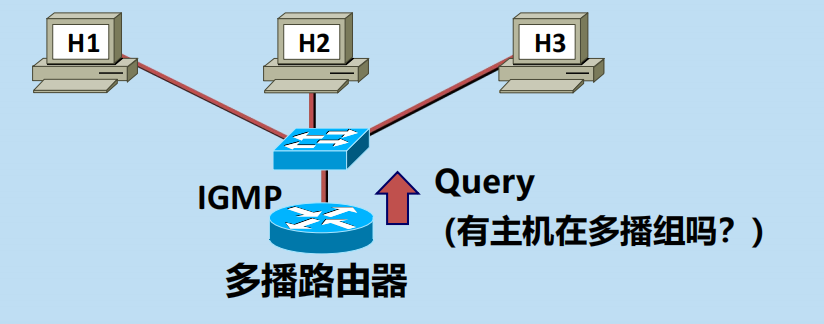
1. 本地多播路由器周期性地探詢本地區域網上的主機,以便知道這些主機是否還繼續是組的成員。
2. 但一個組在經過幾次的探詢後仍然沒有一個主機響應,則不再將該組的成員關係轉發給其他的多播路由器。(不活躍)
IGMP 採用的一些具體措施,以避免增加大量開銷
1.所有通訊都使用 IP 多播。只要有可能,都用硬體多播來傳送。
2.對所有的組只發送一個請求資訊的詢問報文。默認詢問速率是每125 秒發送一次。
3.當同一個網路上連接有多個多播路由器時,能迅速和有效地選擇其中的一個來探詢主機的成員關係
4.分散響應。在 IGMP 的詢問報文中有一個數值 N,它指明一個最長響應時間(默認值為 10 秒)。當收到詢問時,主機在 0 到 N之間隨機選擇發送響應所需經過的時延。若一台主機同時參加了幾
個多播組,則主機對每一個多播組選擇不同的隨機數。對應於最小時延的響應最先發送。
5.採用抑制機制。同一個組內的每一個主機都要監聽響應,只要有本
組的其他主機先發送了響應,自己就不再發送響應了。
多播路由選擇
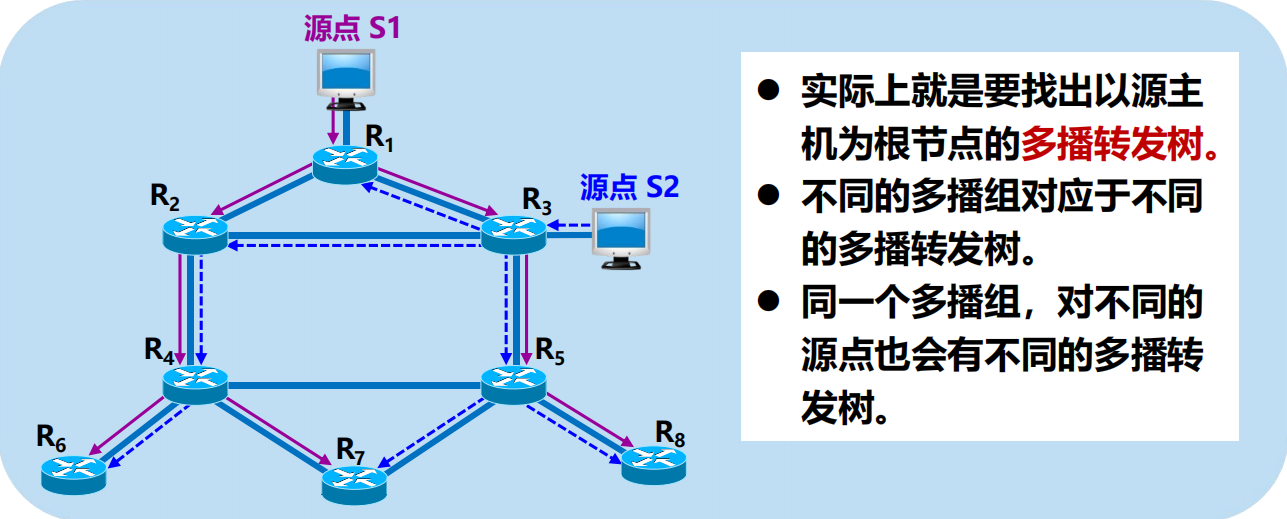
M 個源,N 個多播組,需要 MⅹN 棵以源為根的多播轉發樹。
轉發多播數據報時使用三種方法:
(1) 洪泛與剪除
適合於較小的多播組,所有組成員接入的區域網也是相鄰接的。
開始時,路由器轉發多播數據報使用洪泛的方法(這就是廣播)。
為避免兜圈子,採用反向路徑廣播 RPB (Reverse PathBroadcasting) 的策略。
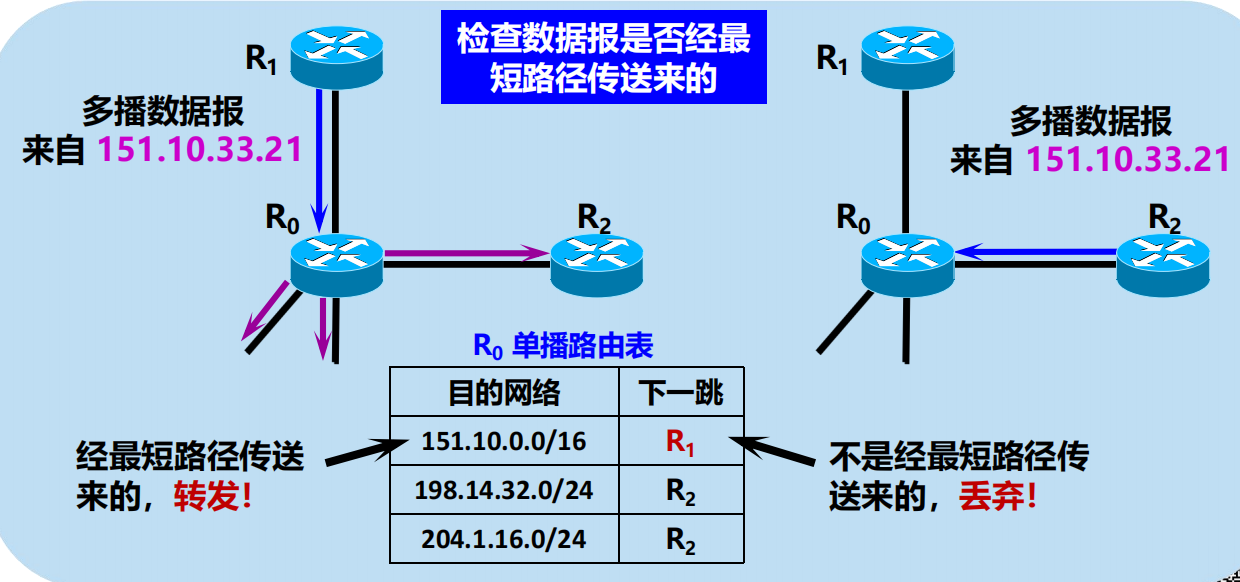
RPB 的要點:檢查,轉發
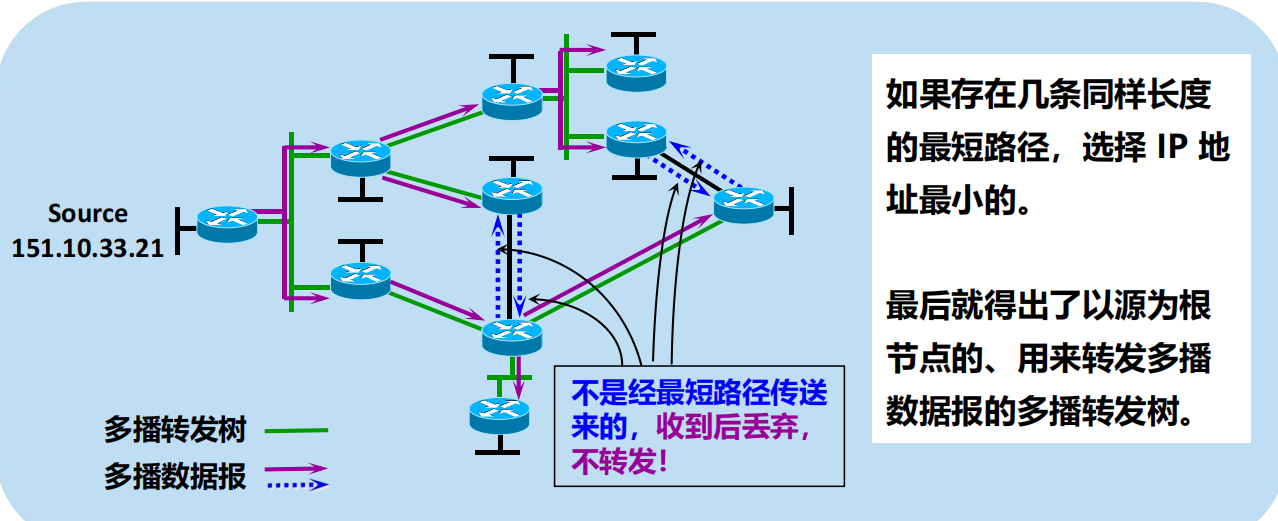
RPB 的要點:形成以源為根節點的多播轉發樹
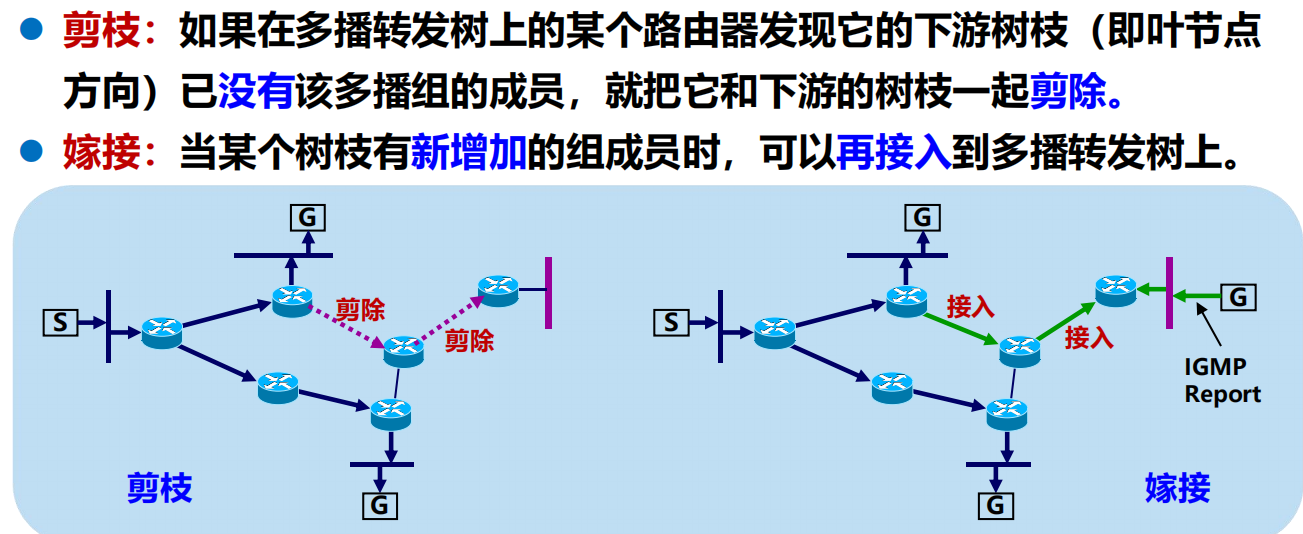
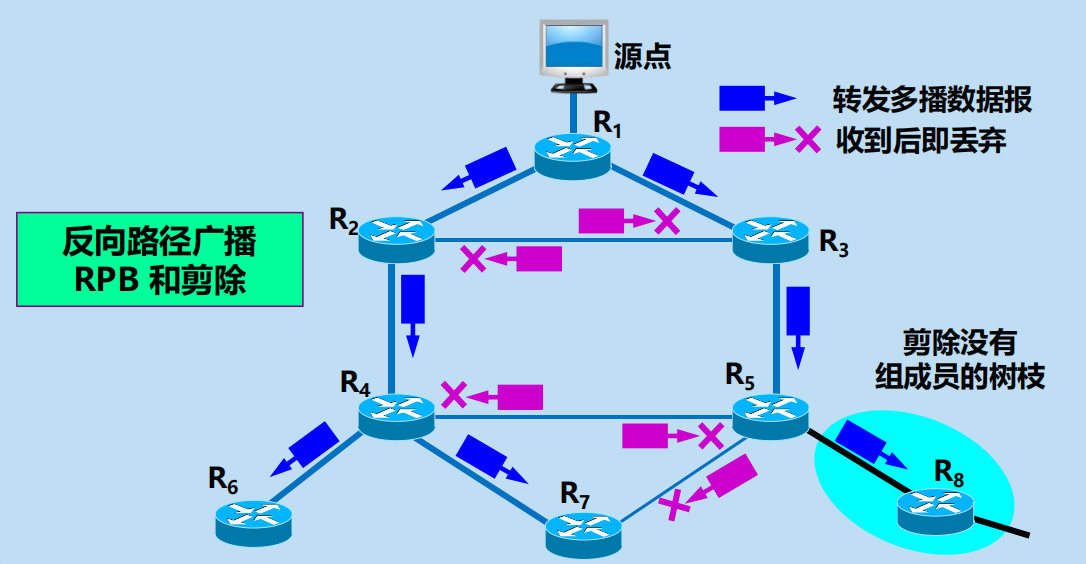
RPB 的要點:剪枝與嫁接
(2) 隧道技術 (tunneling)
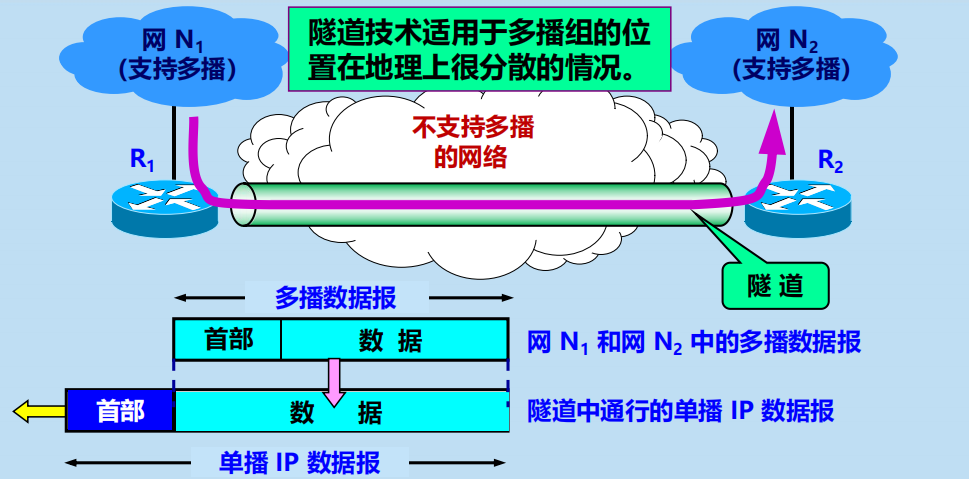
隧道技術在多播中的應用
(3) 基於核心的發現技術
對於多播組的大小在較大範圍內變化時都適合。
對每一個多播組 G 指定一個核心 (core) 路由器,並給出它的 IP 單播地址。
核心路由器按照前面講過的 2 種方法創建出對應於多播組 G 的轉發樹(核心路由器為根節點)。
1.為一個多播組構建一棵轉發樹,而不是為每個(源,組)組合構建一棵轉發樹。
2.構建轉發樹開銷較小,擴展性較好
如果有一個路由器 R1 向核心路由器發送數據報,那麼它在途中經過的每一個路由器都要檢查其內容。
當數據報到達參加了多播組 G 的路由器 R2 時,R2 就處理這個數據報。
如果 R1 發出的是一個多播數據報,其目的地址是 G 的組地址,R2 就向 G 的成員轉發這個多播數據報。
如果 R1 發出的數據報是一個請求加入多播組 G 的數據報,R2 就把這個資訊加到它的路由中,並用隧道技術向 R1 轉發每一個多播數據報的副本。
幾種多播路由選擇協議
距離向量多播路由選擇協議 DVMRP (Distance Vector MulticastRouting Protocol)。互聯網上使用的第一個多播路由選擇協議。
基於核心的轉發樹 CBT (Core Based Tree)
開放最短通路優先的多播擴展 MOSPF (Multicast Extensions toOSPF)
協議無關多播-稀疏方式 PIM-SM (Protocol Independent Multicast-Sparse Mode) 。唯一成為互聯網標準的一個協議。
協議無關多播-密集方式 PIM-DM (Protocol Independent Multicast-Dense Mode)
4.8 虛擬專用網 VPN 和網路地址轉換 NAT
4.8.1 虛擬專用網 VPN
由於 IP 地址的緊缺,一個機構能夠申請到的IP地址數往往遠小於本機構所擁有的主機數。
考慮到互聯網並不是很安全,一個機構內也並不需要把所有的主機接入到外部的互聯網。
如果一個機構內部的電腦通訊也是採用 TCP/IP 協議,那麼這些僅在機構內部使用的電腦就可以由本機構自行分配其 IP 地址。
本地地址與全球地址
本地地址:僅在機構內部使用的 IP 地址,可以由本機構自行分配,而不需要向互聯網的管理機構申請。
全球地址:全球唯一的 IP 地址,必須向互聯網的管理機構申請。
問題:如何區分本地地址和全球地址?
解決:RFC 1918 指明了一些專用地址 (private address)
專用地址只能用作本地地址,而不能用作全球地址。
互聯網中的所有路由器對目的地址是專用地址的數據報一律不進行轉發。
RFC 1918 指明的專用 IP 地址

專用網
採用專用 IP 地址的互連網路稱為專用互聯網或本地互聯網,或更簡單些,就叫做專用網。
專用 IP 地址也叫做可重用地址 (reusable address)
虛擬專用網 VPN
利用公用互聯網作為本機構各專用網之間的通訊載體,這樣的專用網又稱為虛擬專用網 VPN (Virtual Private Network)。
專用網:指這種網路是為本機構的主機用於機構內部的通訊,而不是用於和網路外非本機構的主機通訊。
虛擬:表示實際上沒有使用通訊專線,只是在效果上和真正的專用網一樣。
虛擬專用網 VPN 的構建
如果專用網不同網點之間的通訊必須經過公用的互聯網,但又有保密的要求,那麼所有通過互聯網傳送的數據都必須加密。
必須為每一個場所購買專門的硬體和軟體,並進行配置,使每一個場所的 VPN 系統都知道其他場所的地址。
用隧道技術實現虛擬專用網
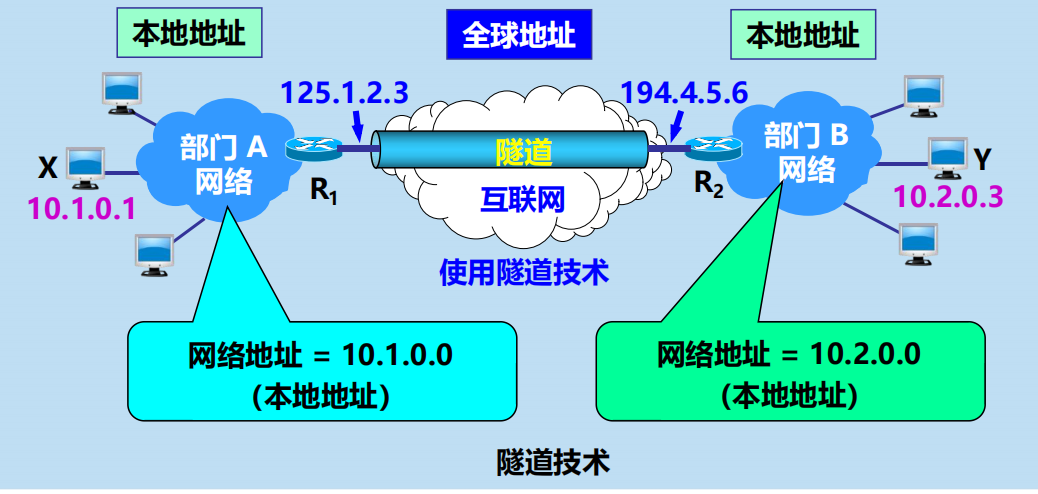
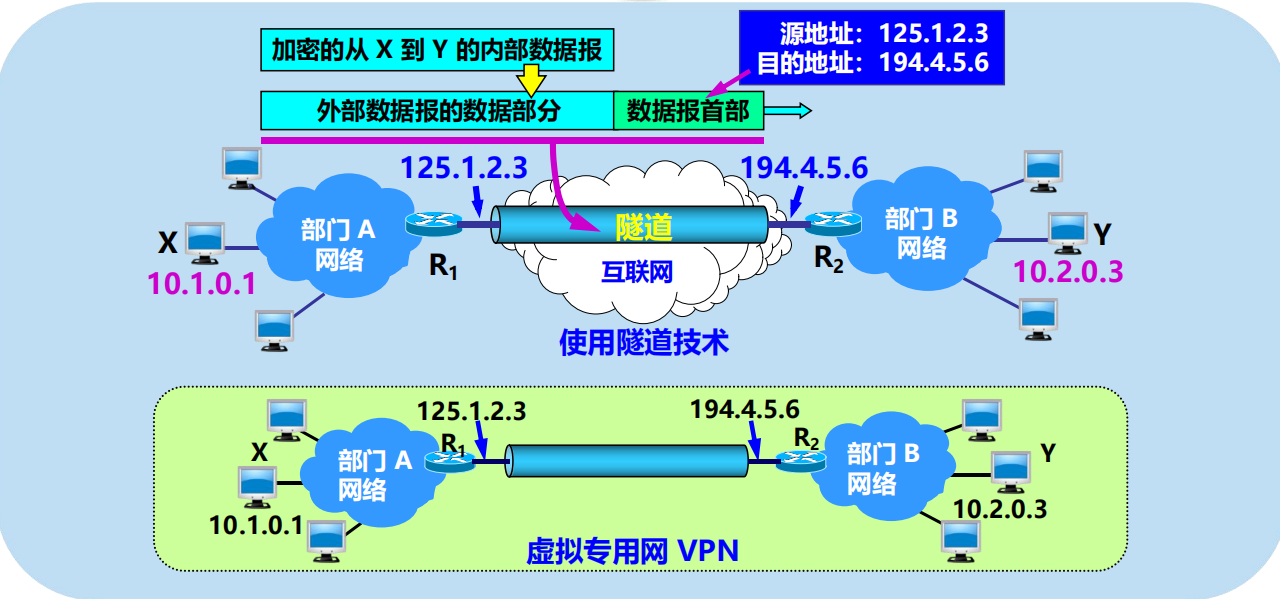
用隧道技術實現虛擬專用網
VPN 類型
內聯網 (intranet):同一個機構的內部網路所構成的 VPN。
外聯網 (extranet):一個機構和某些外部機構共同建立的 。
遠程接入 VPN (remote access VPN):允許外部流動員工通過接入 VPN 建立 VPN 隧道訪問公司內部網路,好像就是使用公司內部的本地網路訪問一樣。
4.8.2 網路地址轉換 NAT
問題:在專用網上使用專用地址的主機如何與互聯網上的主機通訊(並不需要加密)?
解決:
1. 再申請一些全球 IP 地址。但這在很多情況下是不容易做到的。
2. 採用網路地址轉換 NAT。這是目前使用得最多的方法。
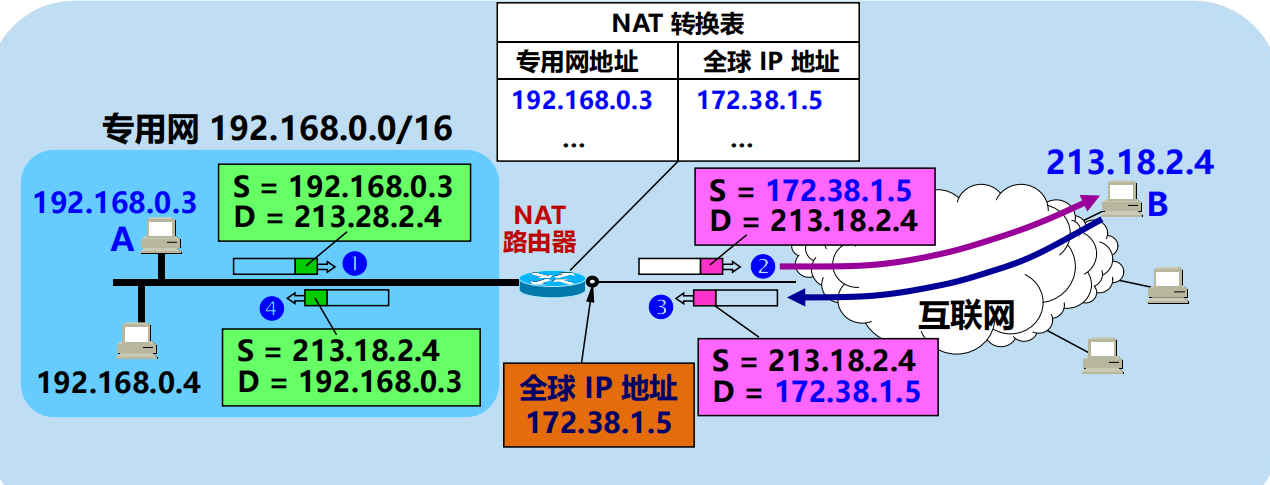
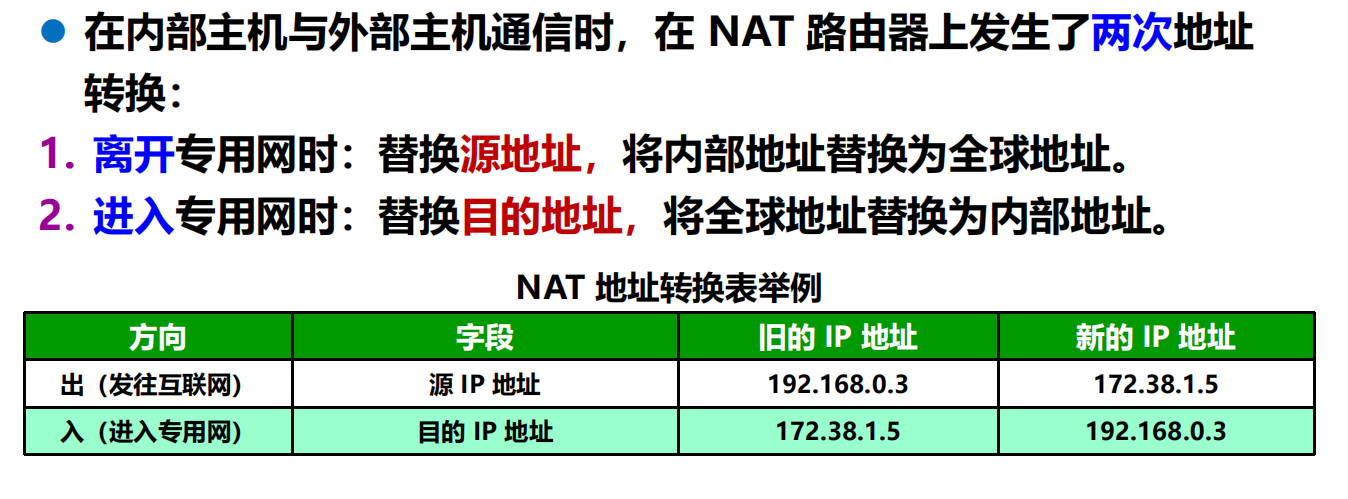
網路地址轉換 NAT (Network Address Translation)
1994 年提出。
需要在專用網連接到互聯網的路由器上安裝 NAT 軟體。
裝有 NAT 軟體的路由器叫做 NAT路由器,它至少有一個有效的外部全球 IP 地址。
所有使用本地地址的主機在和外界通訊時,都要在 NAT 路由器上將其本地地址轉換成全球 IP 地址,才能和互聯網連接。