一文讀懂!異常檢測全攻略!從統計方法到機器學習 ⛵
- 2022 年 11 月 29 日
- 筆記
- DBSCAN, LOF, 人工智慧, 四分位距, 孤立森林, 異常值, 異常檢測, 數據分析, 數據分析 ⛵ 面試寶典&實戰項目, 機器學習, 機器學習實戰通關指南 ⛵ 全場景覆蓋AI解決方案, 標準差

💡 作者:韓信子@ShowMeAI
📘 數據分析實戰系列://www.showmeai.tech/tutorials/40
📘 機器學習實戰系列://www.showmeai.tech/tutorials/41
📘 本文地址://showmeai.tech/article-detail/397
📢 聲明:版權所有,轉載請聯繫平台與作者並註明出處
📢 收藏ShowMeAI查看更多精彩內容

異常值是偏離數據集中大多數樣本點的數據點。出現異常值的原因有很多,例如自然偏差、欺詐活動、人為或系統錯誤。不過,在我們進行任何統計分析或訓練機器學習模型之前,對數據檢測和識別異常值都是必不可少的,這個預處理的過程會影響最後的效果。
大家可以查看ShowMeAI的文章 📘基於統計方法的異常值檢測程式碼實戰,我們圖解詳述了進行異常值檢測可以用的統計方法。

在本篇內容中,ShowMeAI將系統覆蓋「單變數」和「多變數」異常值場景、以及使用統計方法和機器學習異常檢測技術來識別它們,包括四分位距和標準差方法、孤立森林、DBSCAN模型以及 LOF 局部離群因子模型等。

💡 數據&場景方法概述
💦 數據
在本文中,我們將使用來自 UCI 的 🏆Glass Identification 數據集,數據集包含與玻璃含量和玻璃類型相關的 8 個屬性。大家可以通過 ShowMeAI 的百度網盤地址下載。
🏆 實戰數據集下載(百度網盤):公✦眾✦號『ShowMeAI研究中心』回復『實戰』,或者點擊 這裡 獲取本文 [33]異常檢測實戰全景圖:從統計方法到機器學習 『glass數據集』
⭐ ShowMeAI官方GitHub://github.com/ShowMeAI-Hub
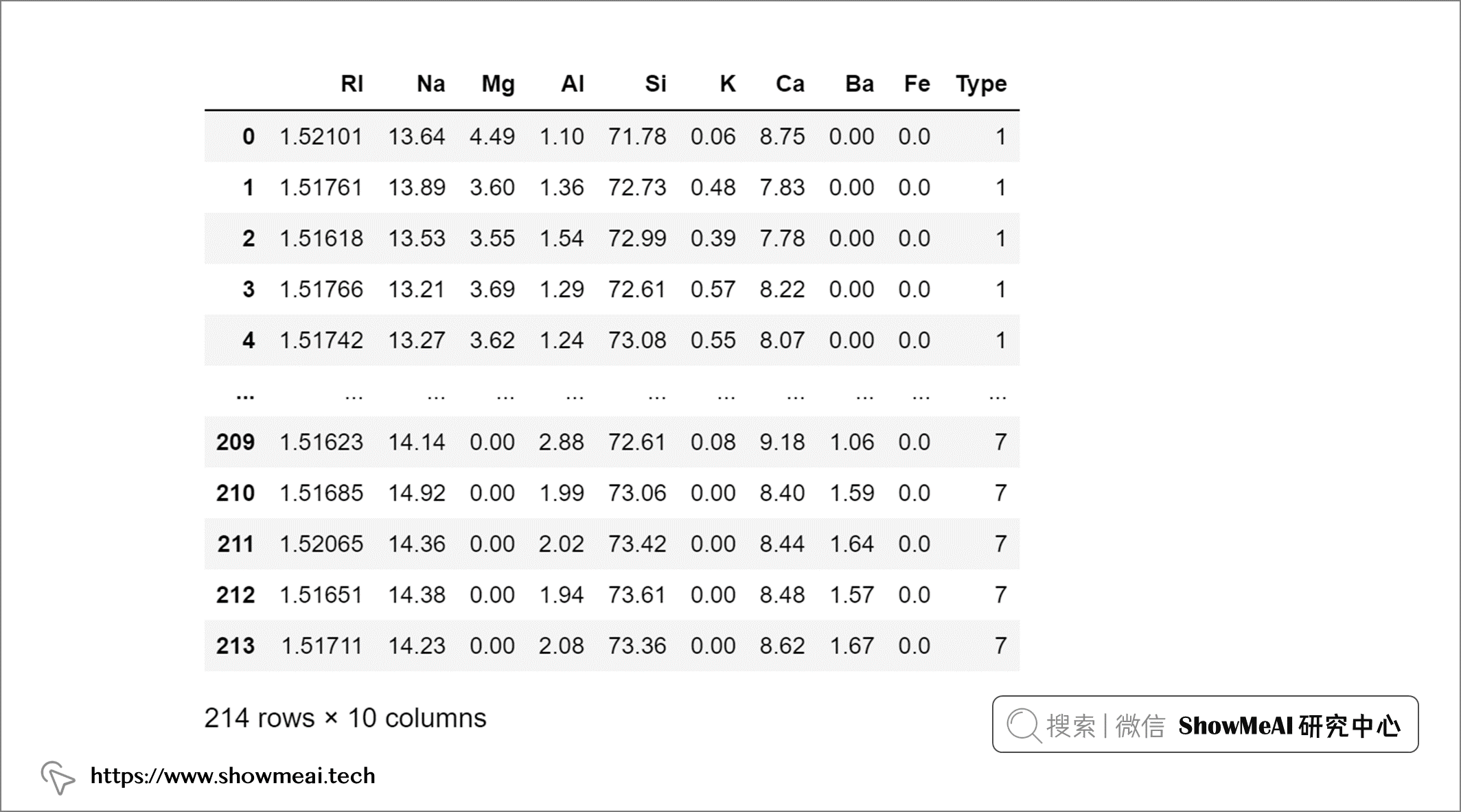
我們載入數據並速覽一下:
import pandas as pd
glass = pd.read_csv('glass.csv')
💦 單變數和多變數異常值
通過使用seaborn的pairplot我們可以繪製數據集不同欄位之間的兩兩分布關係,可以可視化地查看數據的分布情況。

關於數據分析和可視化的知識與工具庫使用,可以查看ShowMeAI的下述教程、文章和速查表
import seaborn as sns
sns.pairplot(glass, diag_kws={'color':'red'})

pairplot 的結果包含兩兩數據的關聯分析和每個變數的分布結果,其中對角線為單變數的分布可視化,我們發現並非所有屬性欄位都具有遵循正態分布。事實上,大多數屬性都偏向較低值(即 Ba、Fe*)或較高值(即 Mg)。
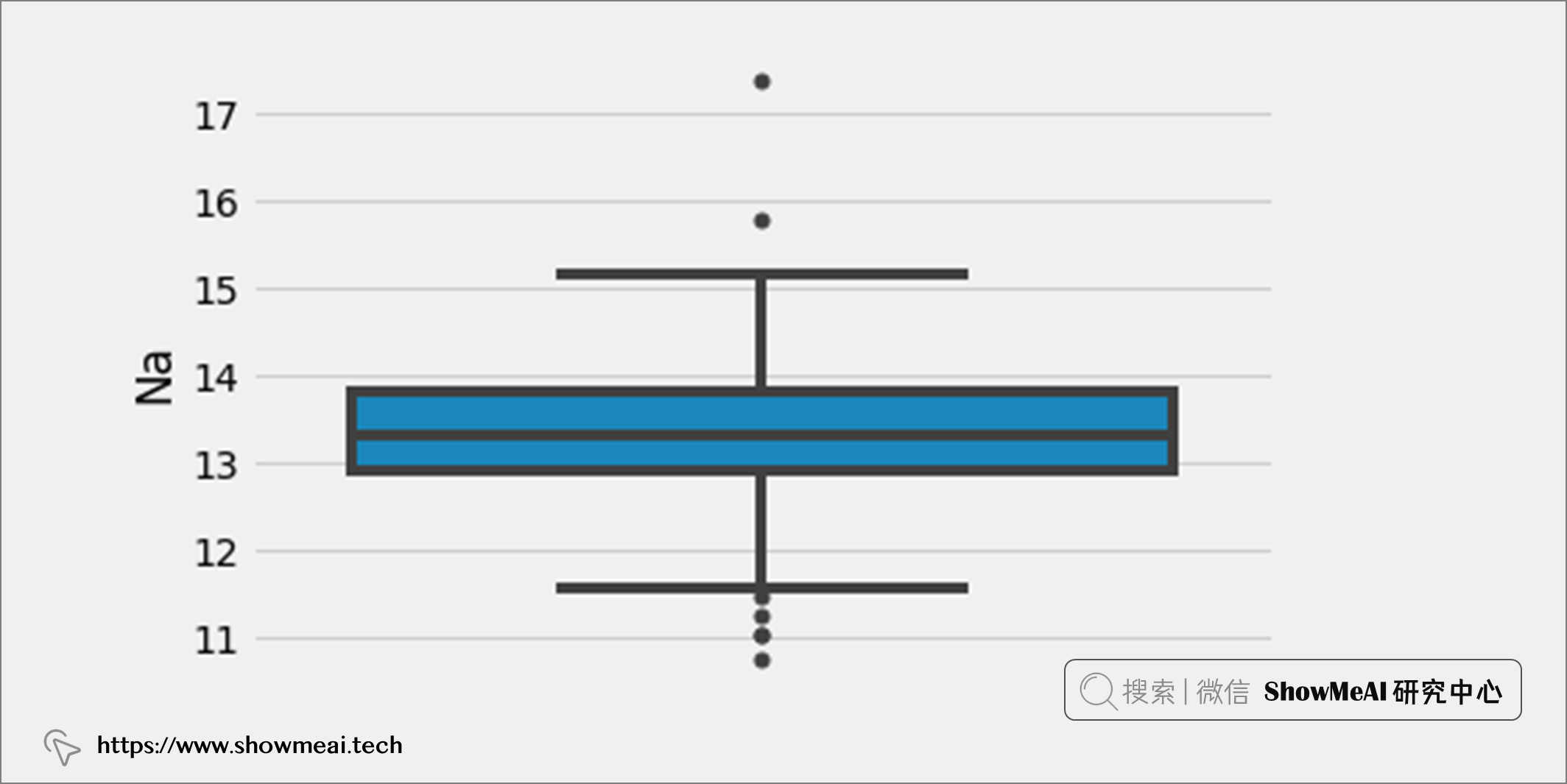
如果要檢測單變數異常值,我們應該關注單個屬性的分布,並找到遠離該屬性大部分數據的數據點。例如,如果我們選擇屬性「Na」並繪製箱線圖,可以找到哪些數據點在上下邊界之外,可以標記為異常值。
如果要檢測多變數異常值,我們應該關注 n 維空間中至少兩個變數的組合。例如,在上述數據集中,我們可以使用玻璃的所有八個屬性並將它們繪製在 n 維空間中,並通過檢測哪些數據點落在遠處來找到多元異常值。
但是因為繪製三維以上的圖非常困難,我們要想辦法將八個維度的數據在低維空間內表徵。我們可以使用PCA(主成分分析)降維方法完成,具體的程式碼如下所示:
關於數據降維原理和實踐,可以查看ShowMeAI的下述文章:
from sklearn.decomposition import PCA
import plotly.express as px
# Dimensionality reduction to 3 dimensions
pca = PCA(n_components=3)
glass_pca = pca.fit_transform(glass.iloc[:, :-1])
# 3D scatterplot
fig = px.scatter_3d(x=glass_pca[:, 0],
y=glass_pca[:, 1],
z=glass_pca[:, 2],
color=glass.iloc[:, -1])
fig.show()
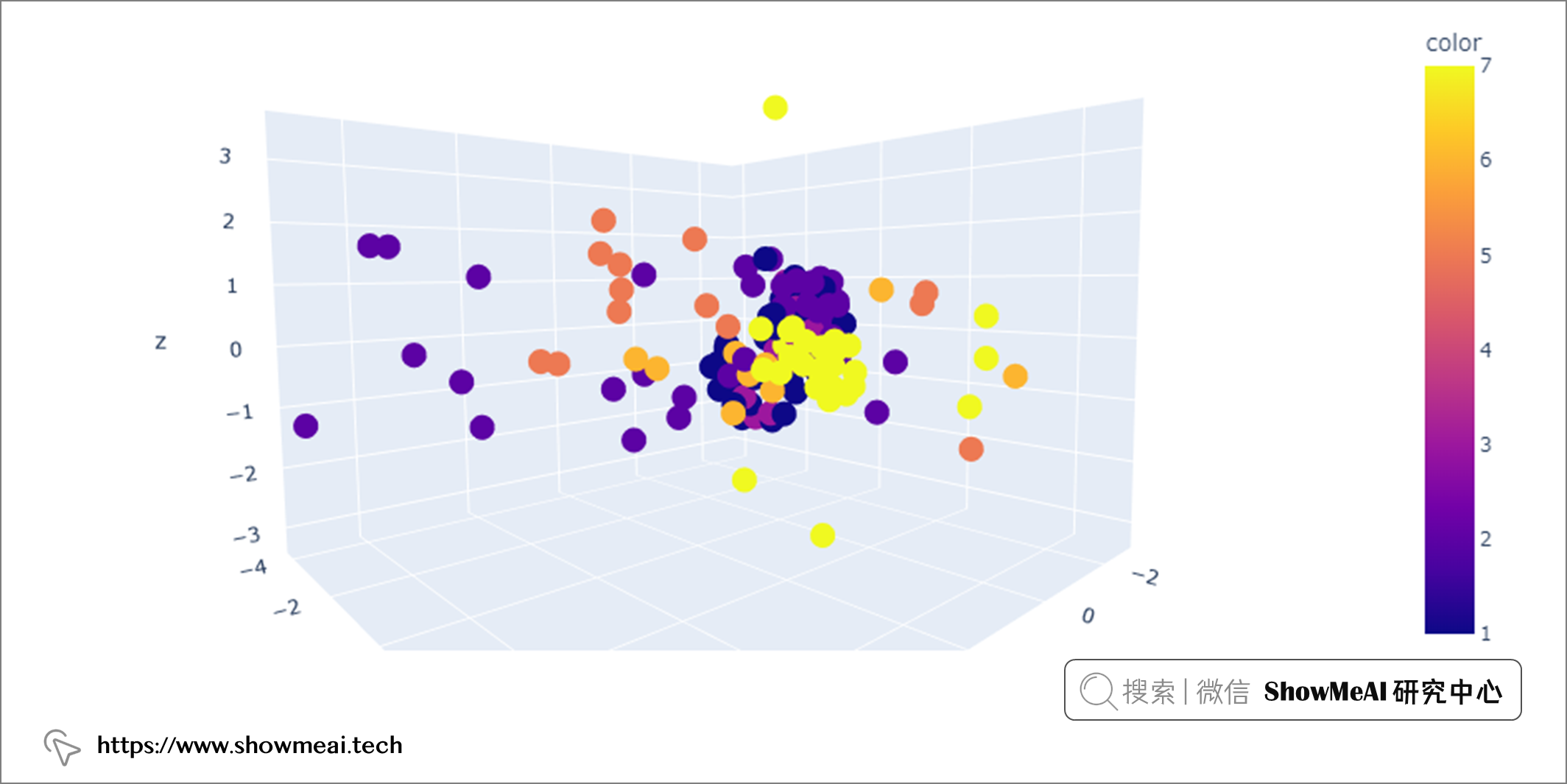
在上圖中可以看到,有些數據點彼此靠近(組成密集區域),有些距離很遠,可能是多變數異常值。
上面我們對異常值檢測的場景方法做了一些簡單介紹,下面ShowMeAI給大家系統講解檢測單變數和多變數異常值的方法。
💡 單變數異常值檢測
💦 標準差法
假設一個變數是正態分布的,那它的直方圖應遵循正態分布曲線(如下圖所示),其中 68.2% 的數據值位於距均值1個標準差範圍內,95.4% 的數據值位於距均值2個標準差範圍內,99.7% 的數據值位於距均值3個標準差範圍內。
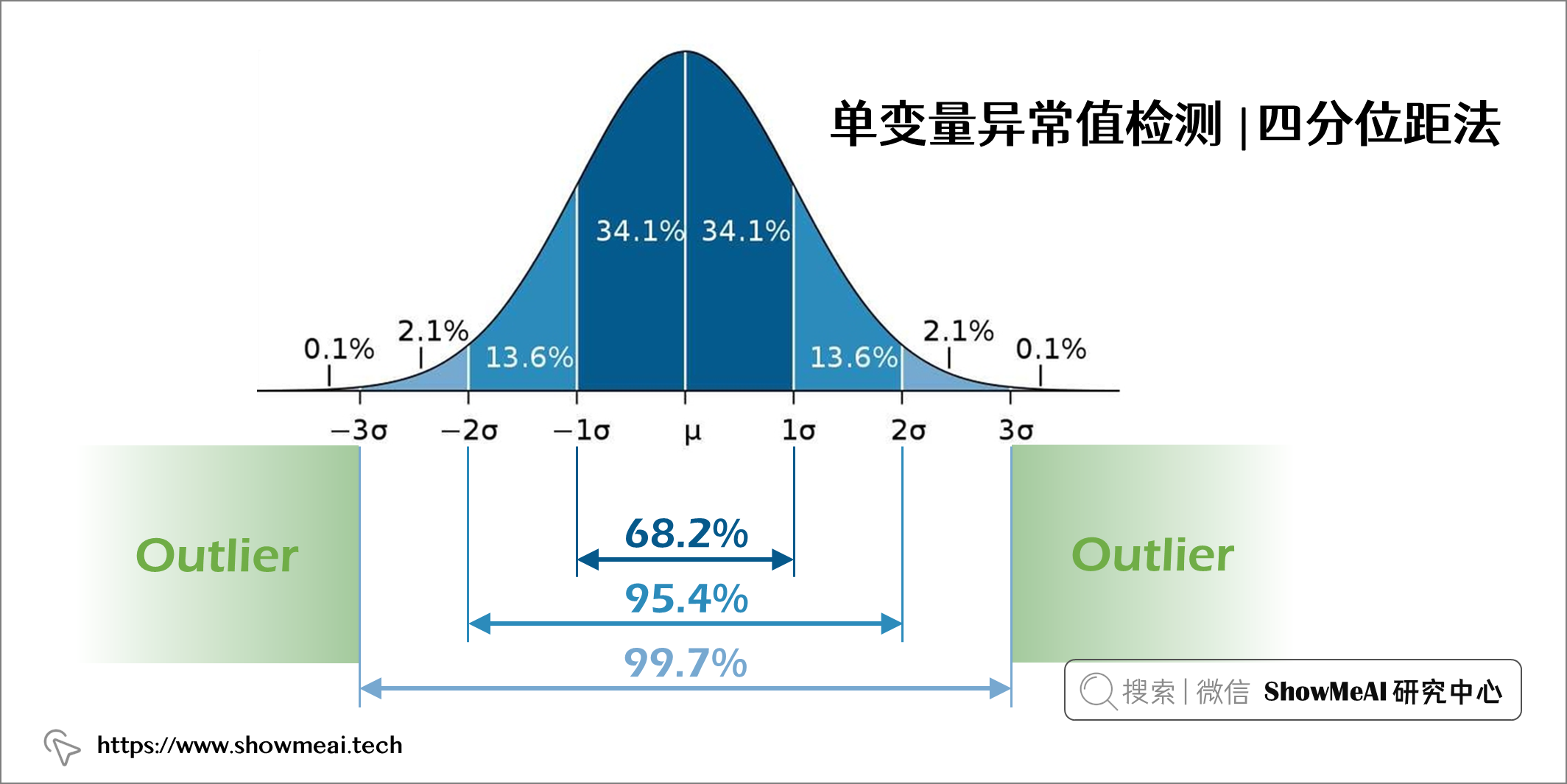
因此,如果有數據點距離平均值超過3個標準差,我們就可以將其視作異常值。這也是著名的異常檢測3sigma法。具體的的程式碼實現如下:
# Find mean, standard deviation and cut off value
mean = glass["Na"].mean()
std = glass["Na"].std()
cutoff = 3 * std
# Define lower and upper boundaries
lower, upper = mean-cutoff, mean+cutoff
# Define new dataset by masking upper and lower boundaries
new_glass = glass[(glass["Na"] > lower) & (glass["Na"] < upper)]
通過使用標準偏差法,我們基於「Na」變數刪除了2條極端記錄。大家可以用同樣的方法在其他屬性上,檢測和移除單變數異常值。
Shape of original dataset: (213, 9)
Shape of dataset after removing outliers in Na column: (211, 9)
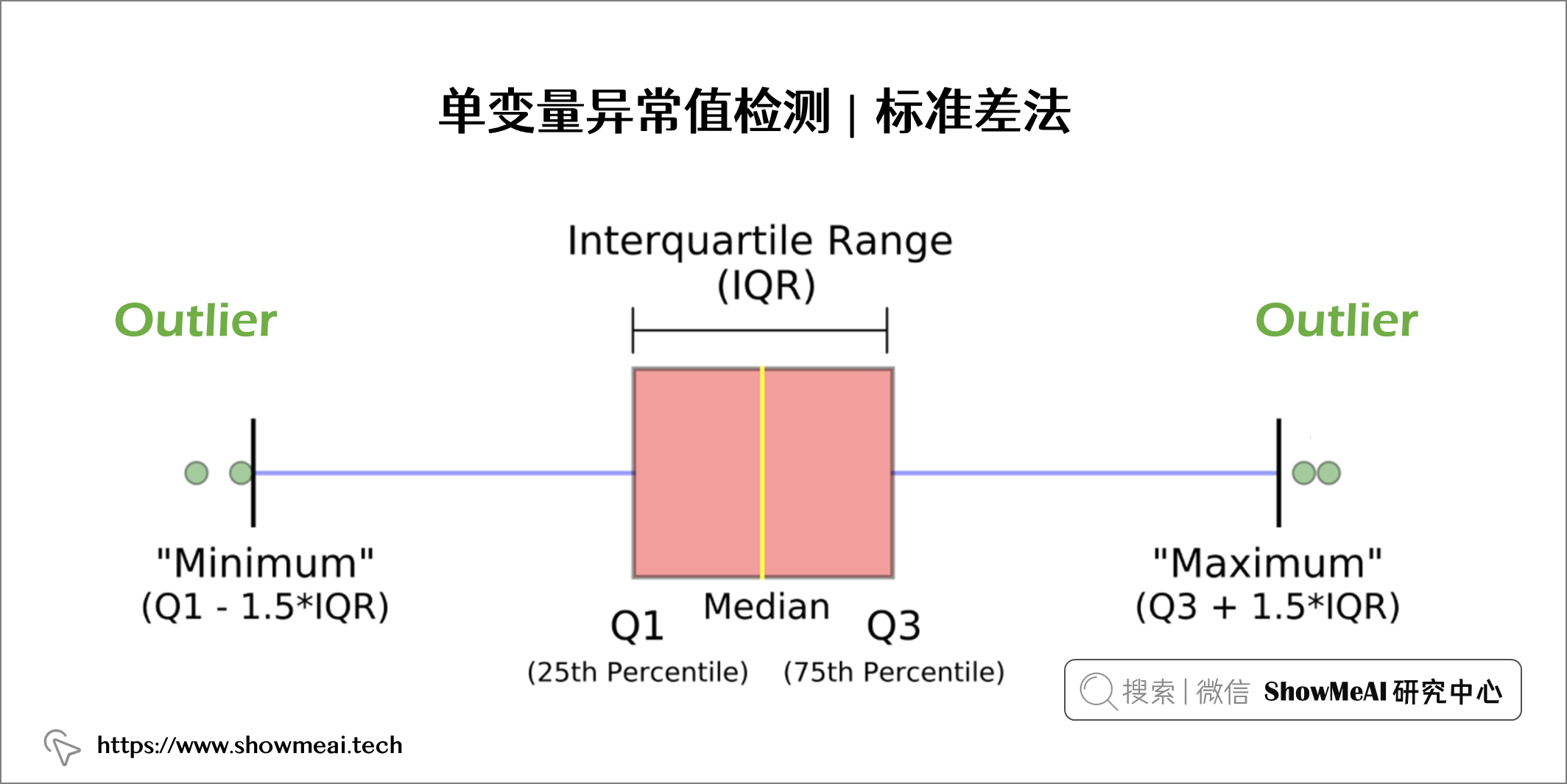
💦 四分位距法
四分位數間距方法是一個基於箱線圖的統計方法,它通過定義三個數據分布位點將數據進行劃分,並計算得到統計邊界值:
- 四分位數 1 (Q1) 表示第 25 個百分位數
- 四分位數 2 (Q2) 表示第 50 個百分位數
- 四分位數 3 (Q3) 表示第 75 個百分位數
箱線圖中的方框表示 IQR 範圍,定義為 Q1 和 Q3 之間的範圍:IQR = Q3 — Q1
低於的數據點Q1 - 1.5*IQR或以上Q3 + 1.5*IQR被定義為異常值。如下圖所示:
基於四分位距的異常檢測程式碼實現如下所示:
# Find Q1, Q3, IQR and cut off value
q25, q75 = np.quantile(glass["Na"], 0.25), np.quantile(glass["Na"], 0.75)
iqr = q75 - q25
cutoff = 1.5 * iqr
# Define lower and upper boundaries
lower, upper = q25 - cutoff, q75 + cutoff
# Define new dataset by masking upper and lower boundaries
new_glass = glass[(glass["Na"] > lower) & (glass["Na"] < upper)]
Shape of original dataset: (213, 9)
Shape of dataset after removing outliers in Na column: (206, 9)
我們可以看到,基於 IQR 技術,從「Na」變數維度我們刪除了七個記錄。我們注意到,基於標準偏差方法只能找到 2 個異常值,是非常極端的極值點,但是使用 IQR 方法我們能夠檢測到更多(5 個不是那麼極端的記錄)。我們可以基於實際場景和情況決定哪種方法。
💡 多變數異常值檢測
💦 孤立森林演算法-Isolation Forest
📘孤立森林 是一種基於隨機森林的無監督機器學習演算法。我們都知道,隨機森林是一種集成學習模型,它使用基模型(比如 100 個決策樹)組合和集成完成最後的預估。
關於隨機森林演算法的詳解可以參考ShowMeAI的下述文章 📘圖解機器學習 | 隨機森林分類模型詳解
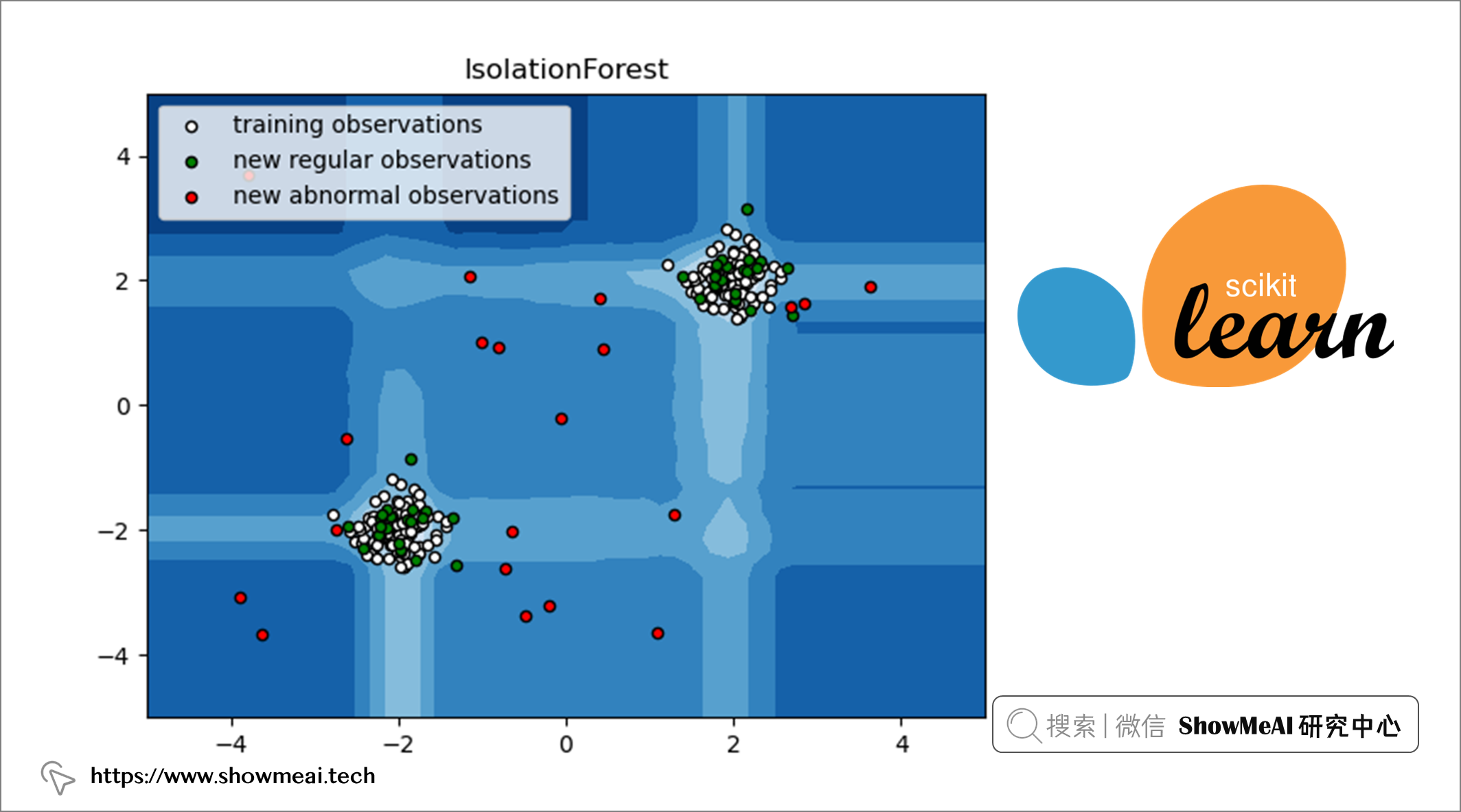
孤立森林遵循隨機森林的方法,但相比之下,它檢測(或叫做隔離)異常數據點。它有兩個基本假設:離群值是少數樣本,且它們是分布偏離的。
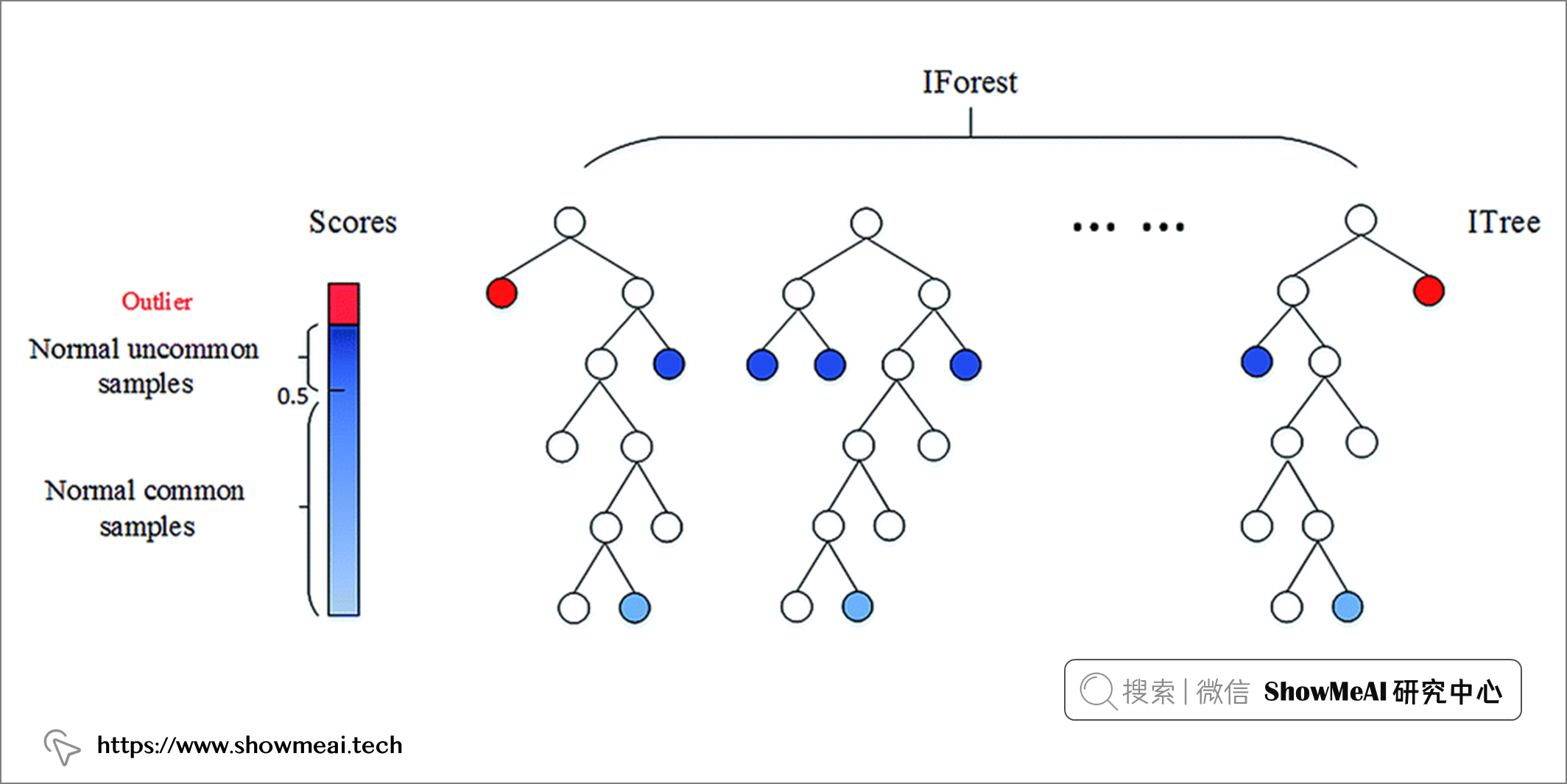
孤立森林通過隨機選擇一個特徵,然後隨機選擇一個分割規則來分割所選特徵的值來創建決策樹。這個過程一直持續到達到設置的超參數值。在構建好的孤立森林中,如果樹更短且對應分支樣本數更少,則相應的值是異常值(少數和不尋常)。
我們一起來看看 scikit-learn 中的IsolationForest類對應應用方法:
from sklearn.ensemble import IsolationForest
IsolationForest(n_estimators=100, max_samples='auto', contamination='auto', max_features=1.0, bootstrap=False, n_jobs=None, random_state=None, verbose=0, warm_start=False)
Isolation Forest 演算法有幾個超參數:
n_estimators:表示要集成的基模型的數量。max_samples:表示用於訓練模型的樣本數。contamination:用於定義數據中異常值的比例。max_features:表示取樣處的用於訓練的特徵數。
大家可以查看 📘文檔 了解更多的資訊。
from sklearn.ensemble import IsolationForest
# Initiate isolation forest
isolation = IsolationForest(n_estimators=100,
contamination='auto',
max_features=glass.shape[1])
# Fit and predict
isolation.fit(glass)
outliers_predicted = isolation.predict(glass)
# Address outliers in a new column
glass['outlier'] = outliers_predicted
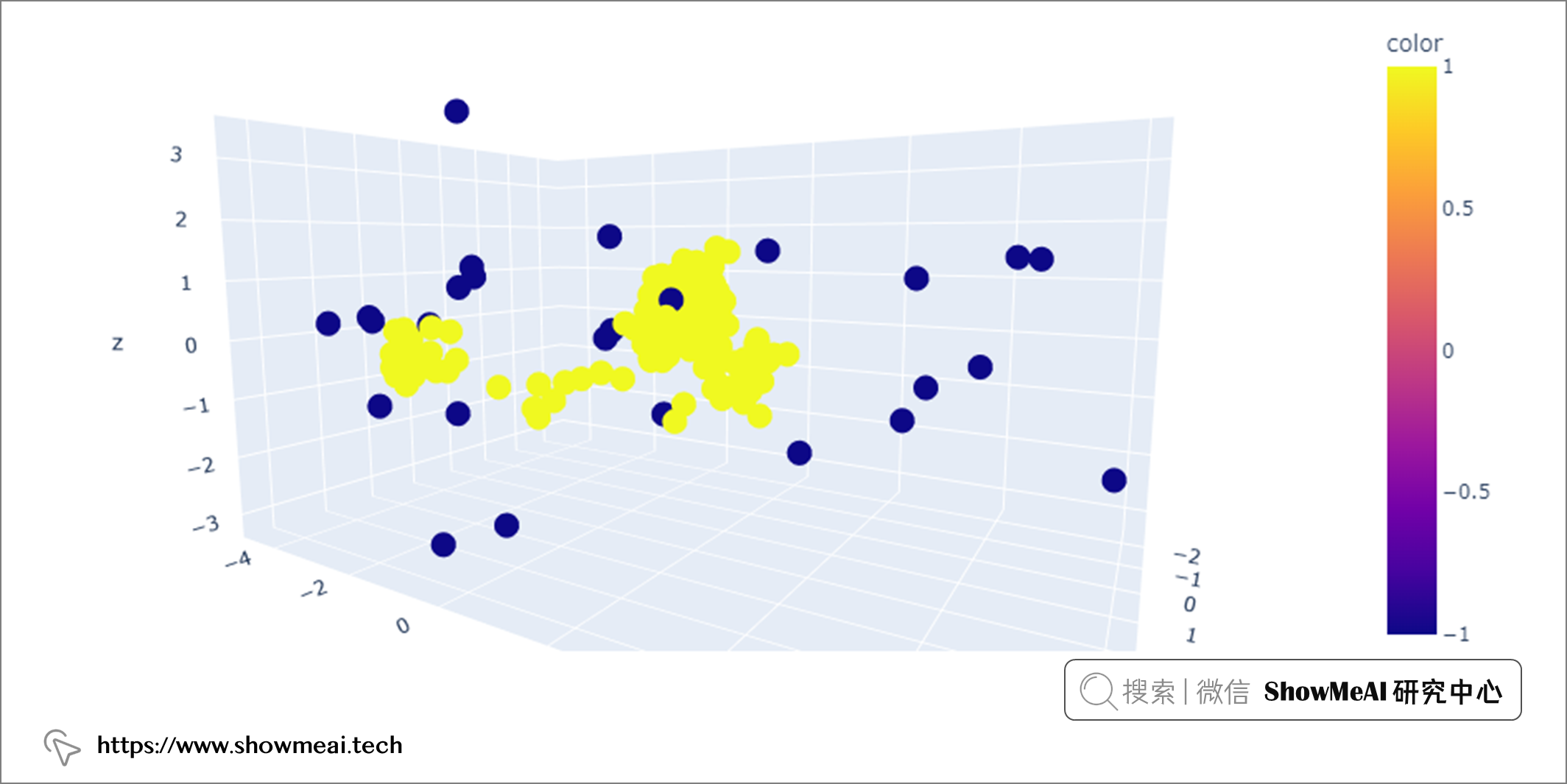
我們通過將基模型的數量設置為 100,將最大特徵設置為特徵總數,將異常值佔比設置為'auto',如果把它為 0.1,則總體 10% 的數據集將被定義為異常值。
我們在使用孤立森林學習後,調用 glass['outlier'].value_counts()可以看到有 19 條記錄被標記為-1(即異常值),其餘 195 條記錄被標記為1(正常值)。
1 195
-1 19
Name: outlier, dtype: int64
像上文一樣,我們可以通過使用 PCA 將特徵降維到3個組件來可視化異常值。
💦 基於空間密度的聚類演算法-DBSCAN
📘DBSCAN 是一種流行的聚類演算法,通常用作 K-means 的替代方法。它是基於分布密度的,專註於許多數據點所在的高密度區域。它通過測量數據之間的特徵空間距離(即歐氏距離)來識別哪些樣本可以聚類在一起。DBSCAN 作為聚類演算法最大的優勢之一就是我們不需要預先定義聚類的數量。
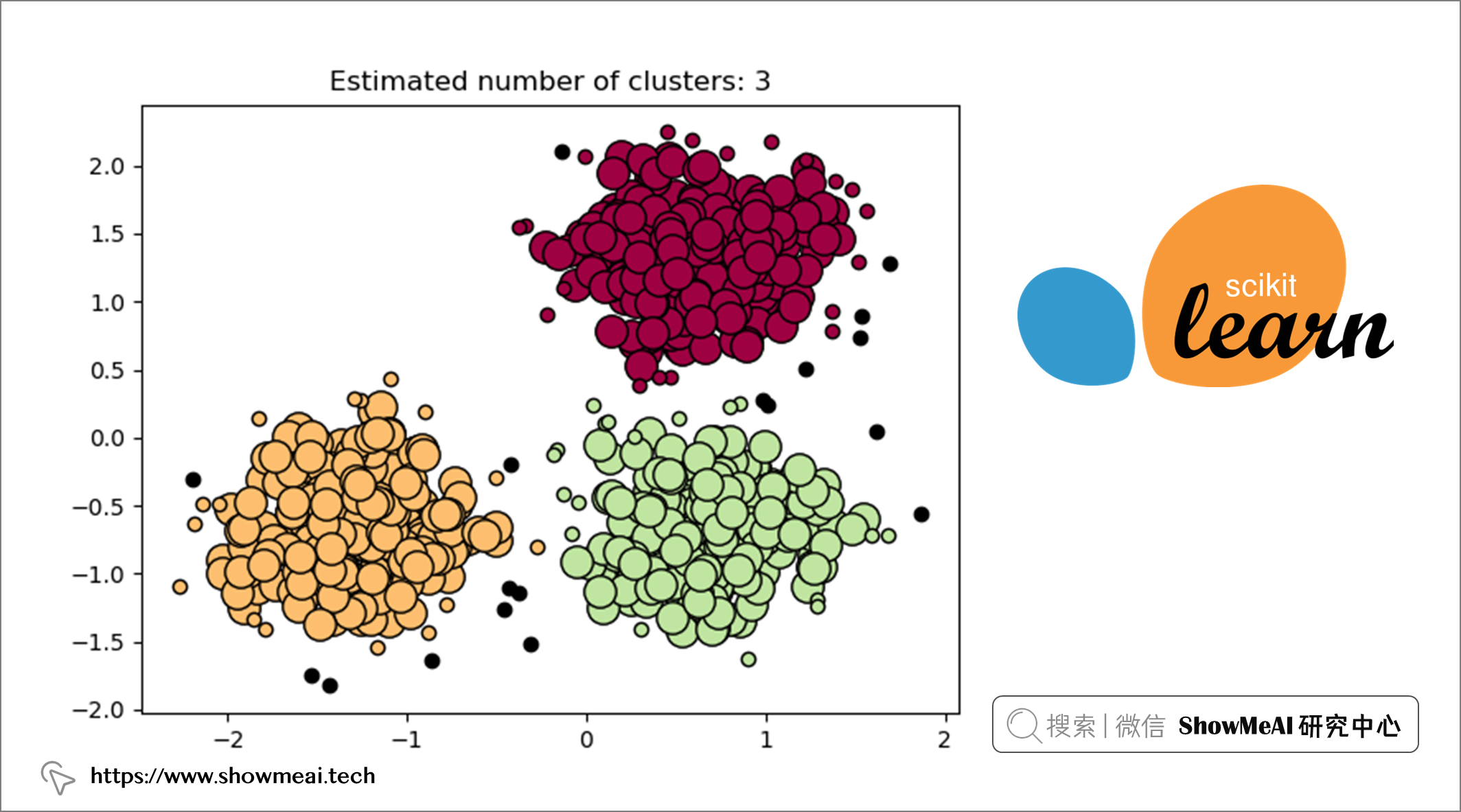
讓我們看看如何基於 scikit-learn 來應用DBSCAN:
from sklearn.cluster import DBSCAN
DBSCAN(eps=0.5, min_samples=5, metric='euclidean', metric_params=None, algorithm='auto', leaf_size=30, p=None, n_jobs=None)
DBSCAN 有幾個超參數:
eps(epsilon):考慮在同一個 cluster 中的兩個數據點之間的最大距離。min_samples:核心點的接近數據點的數量。metric:用於計算不同點之間的距離度量方法。
大家可以查看 📘文檔 了解更多的資訊。
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import MinMaxScaler
# Initiate DBSCAN
dbscan = DBSCAN(eps=0.4, min_samples=10)
# Transform data
glass_x = np.array(glass).astype('float')
# Initiate scaler and scale data
scaler = MinMaxScaler()
glass_scaled = scaler.fit_transform(glass_x)
# Fit DBSCAN on scaled data
dbscan.fit(glass_scaled)
# Address outliers in a new column
glass['outlier'] = dbscan.labels_
在啟動 DBSCAN 時,仔細選擇超參數非常重要。例如,如果 eps 值選擇得太小,那麼大部分數據都可以歸類為離群值,因為鄰域區域被定義為更小。相反,如果 eps 值選擇太大,則大多數點會被聚類演算法聚到一起,因為它們很可能位於同一鄰域內。這裡我們使用 📘k 距離圖 選擇 eps 為 0.4。
import math
# Function to calculate k distance
def calculate_k_distance(X,k):
k_distance = []
for i in range(len(X)):
euclidean_dist = []
for j in range(len(X)):
euclidean_dist.append(
math.sqrt(
((X[i,0] - X[j,0]) ** 2) +
((X[i,1] - X[j,1]) ** 2)))
euclidean_dist.sort()
k_distance.append(euclidean_dist[k])
return k_distance
# Calculate and plot epsilon distance
eps_distance = calculate_k_distance(glass_scaled, 10)
px.histogram(eps_distance, labels={'value':'Epsilon distance'})
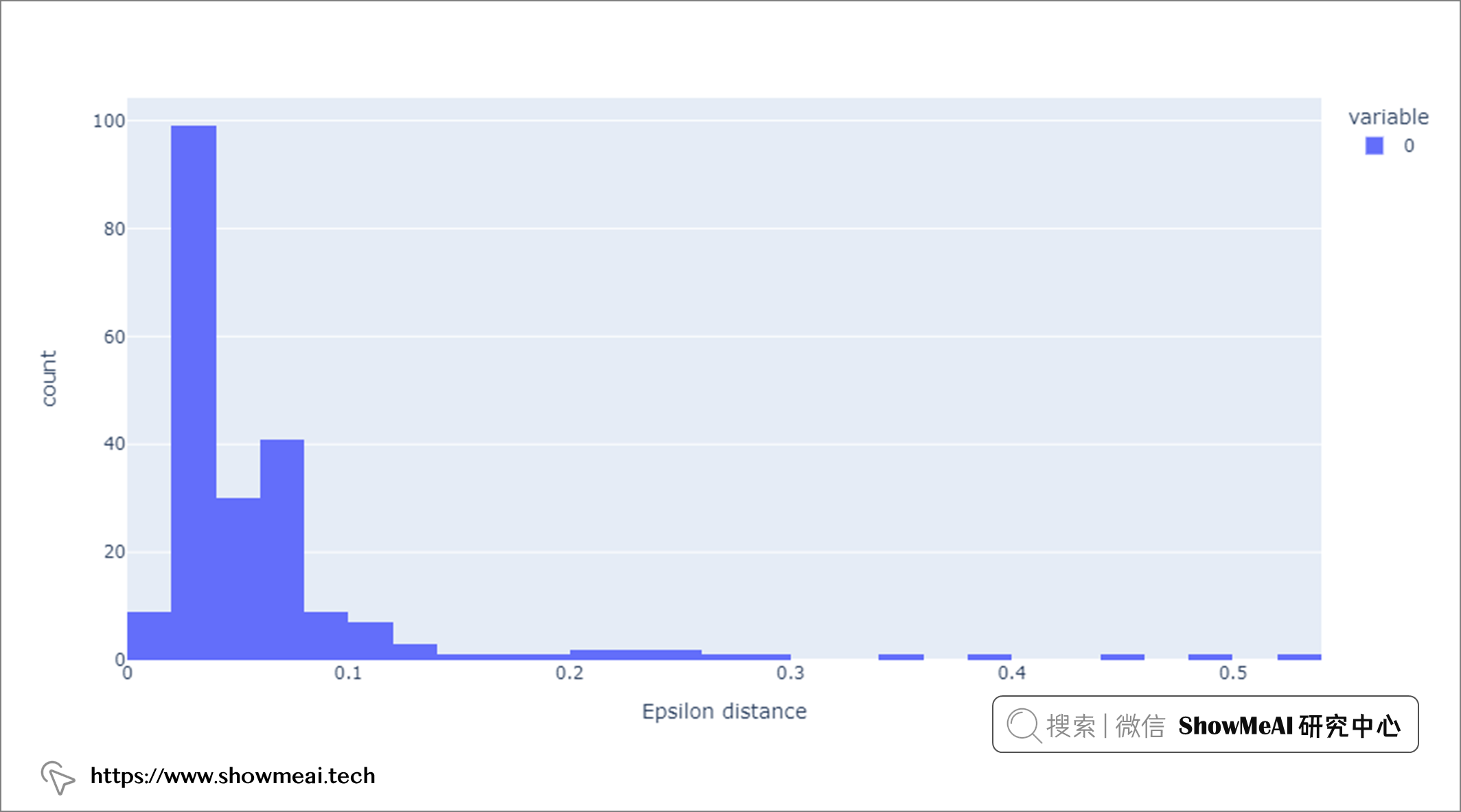
此外,min_samples是一個重要的超參數,通常等於或大於 3,大多數情況下選擇 D+1,其中 D 是數據集的維度。在上述程式碼中,我們將min_samples設置為 10。
由於 DBSCAN 是通過密度來識別簇的,所以高密度區域是簇出現的地方,低密度區域是異常值出現的地方。經過DBSCAN建模,我們調用glass['outlier'].value_counts()可以看到有 22 條記錄被標記為-1(異常值),其餘 192 條記錄被標記為1(正常值)。
0 192
-1 22
Name: outlier, dtype: int64
我們可以使用 PCA 可視化異常值。
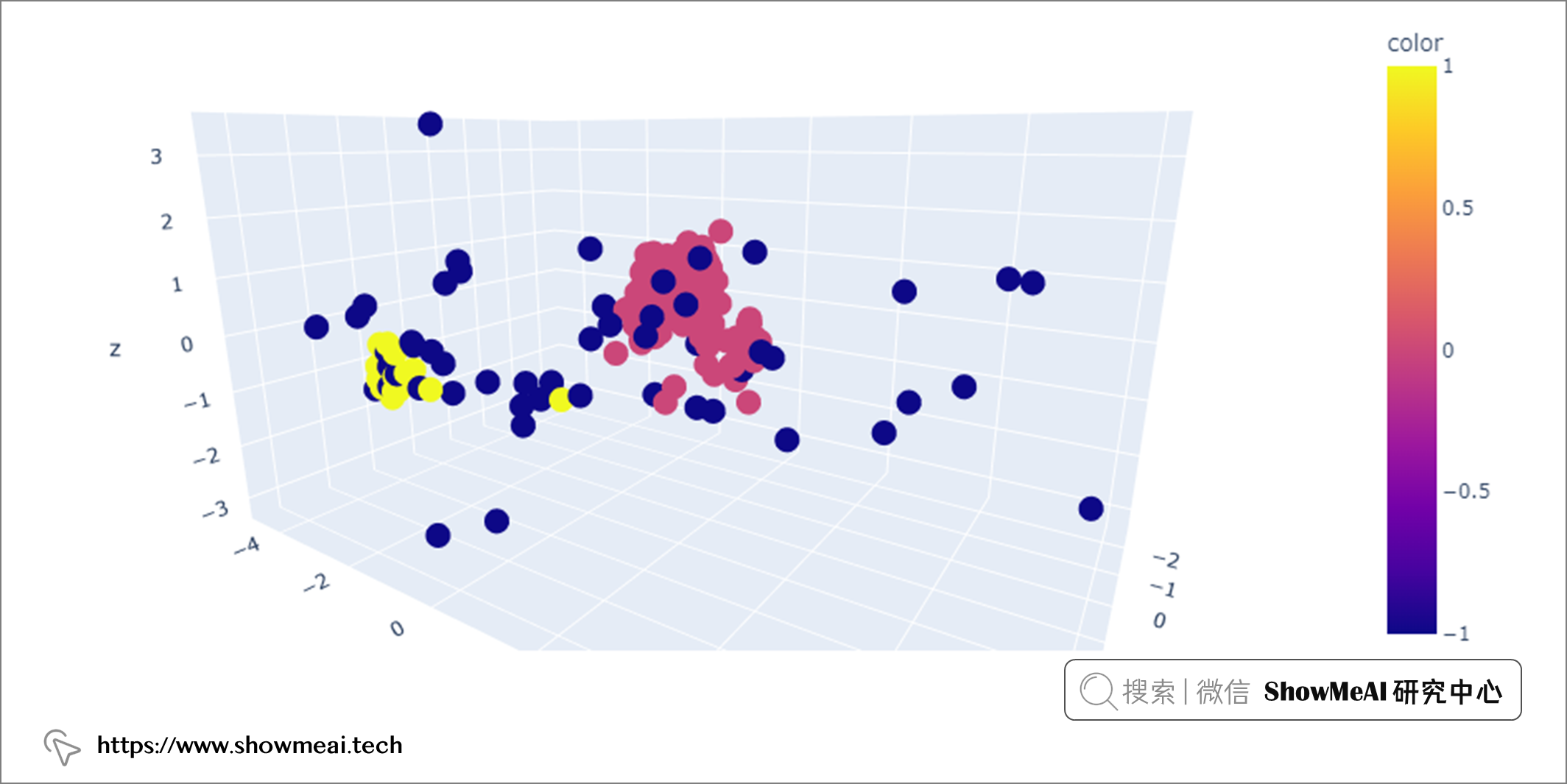
上圖中,DBSCAN 檢測到的異常值(黃色點)(eps=0.4,min_samples=10)
💦 局部異常因子演算法-LOF
📘LOF 是一種流行的無監督異常檢測演算法,它計算數據點相對於其鄰居的局部密度偏差。計算完成後,密度較低的點被視為異常值。
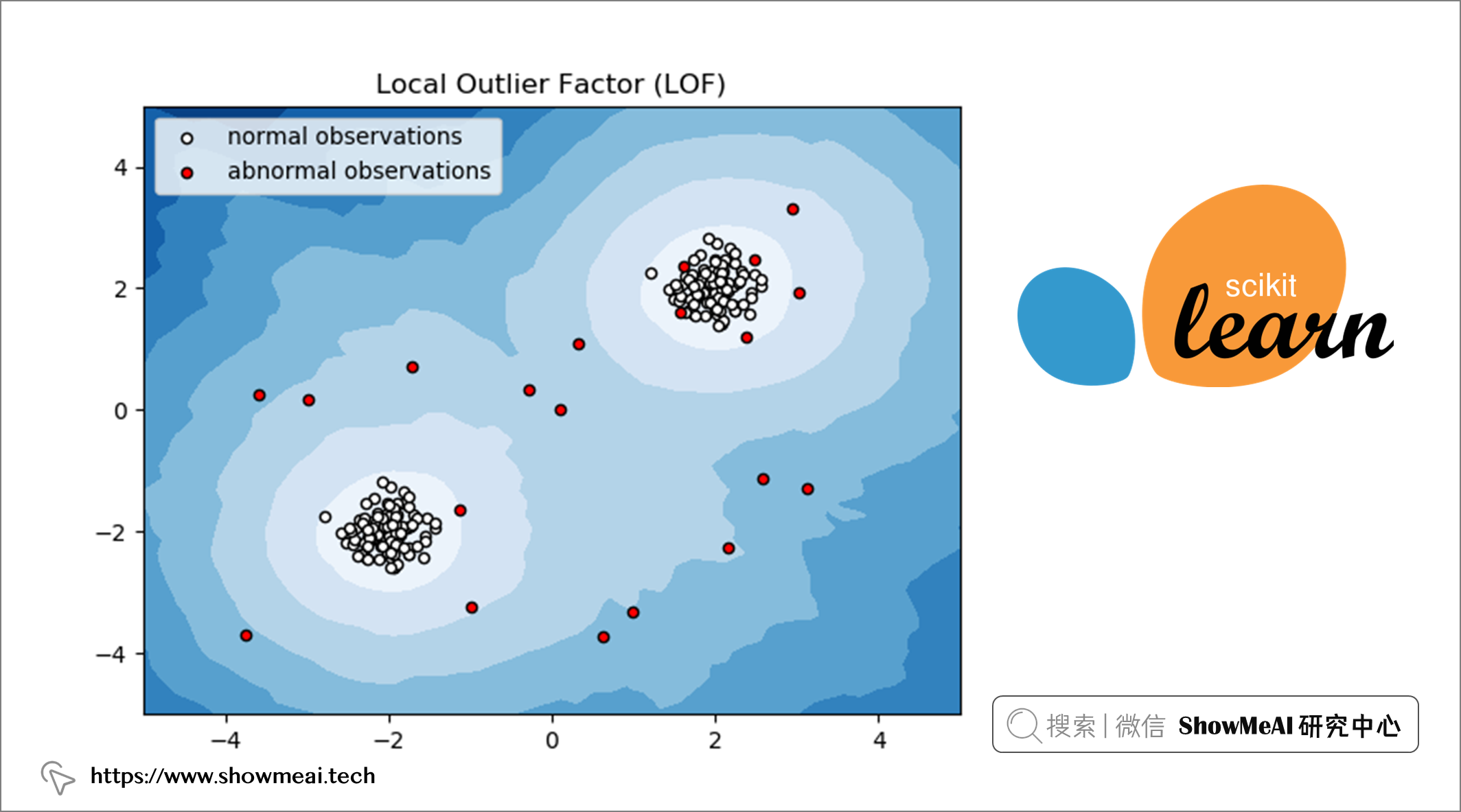
讓我們看看基於 scikit-learn 的 LOF 實現。
from sklearn.neighbors import LocalOutlierFactor
LocalOutlierFactor(n_neighbors=20, algorithm='auto', leaf_size=30, metric='minkowski', p=2, metric_params=None, contamination='auto', novelty=False, n_jobs=None)
LOF 有幾個超參數:
n_neighbors:用於選擇默認等於 20 的鄰居數量。contamination:用於定義離群值比例。
from sklearn.neighbors import LocalOutlierFactor
# Initiate LOF
lof = LocalOutlierFactor(n_neighbors=20, contamination='auto')
# Transform data
glass_x = np.array(glass).astype('float')
# Initiate scaler and scale data
scaler = MinMaxScaler()
glass_scaled = scaler.fit_transform(glass_x)
# Fit and predict on scaled data
clf = LocalOutlierFactor()
outliers_predicted = clf.fit_predict(glass)
# Address outliers in a new column
glass['outlier'] = outliers_predicted
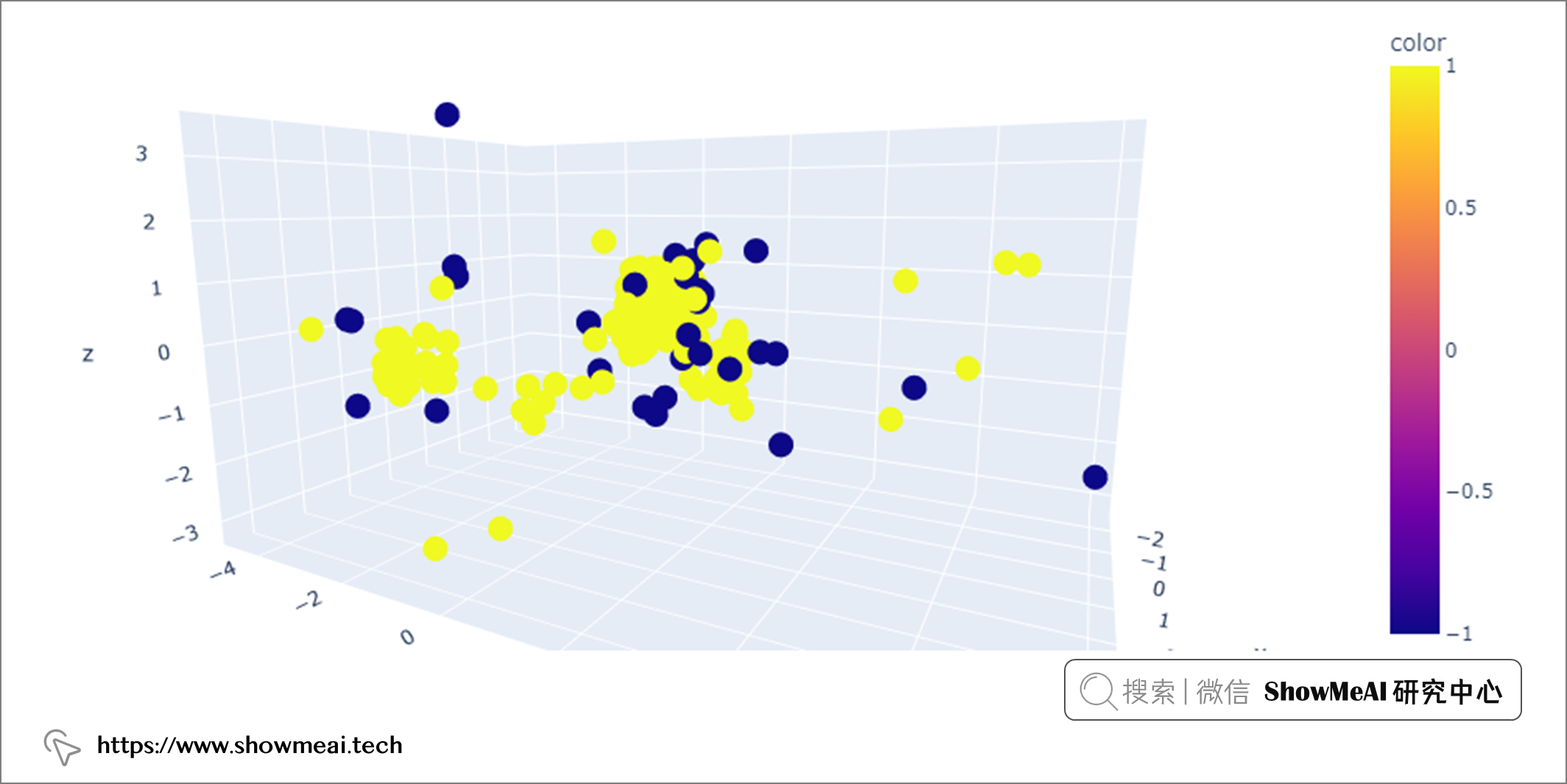
LOF建模完成後,通過調用glass['outlier'].value_counts()我們可以看到有 34 條記錄被標記為-1(異常值),其餘 180 條記錄被標記為1(正常值)。
1 180
-1 34
Name: outlier, dtype: int64
最後,我們可以使用 PCA 可視化這些異常值。
💡 總結
在本文中,我們探索了檢測數據集中異常值的不同方法。我們從單變數離群值檢測技術開始,涵蓋了標準差和四分位距方法。然後,我們轉向多變數離群值檢測技術,涵蓋孤立森林、DBSCAN 和局部離群值因子。通過這些方法,我們學習了如何使用特徵空間中的所有維度來檢測異常值。除了異常值檢測之外,我們還使用了 PCA 降維技術對數據降維和進行可視化。
參考資料
- 📘 Glass Identification 數據集://www.kaggle.com/uciml/glass
- 📘 基於統計方法的異常值檢測程式碼實戰 ://showmeai.tech/article-detail/336
- 📘 圖解數據分析:從入門到精通系列教程://www.showmeai.tech/tutorials/33
- 📘 Python數據分析 | Seaborn工具與數據可視化://www.showmeai.tech/article-detail/151
- 📘 數據科學工具庫速查表 | Seaborn 速查表://www.showmeai.tech/article-detail/105
- 📘圖解機器學習 | 降維演算法詳解://showmeai.tech/article-detail/198
- 📘圖解機器學習 | 隨機森林分類模型詳解://showmeai.tech/article-detail/191
- 📘 Scikit-Learn 的孤立森林模型://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html
- 📘 Scikit-Learn 的 DBSCAN模型://scikit-learn.org/stable/modules/generated/sklearn.cluster.DBSCAN.html?highlight=dbscan#sklearn.cluster.DBSCAN
- 📘 Scikit-Learn 的局部異常值因子模型://scikit-learn.org/stable/auto_examples/neighbors/plot_lof_outlier_detection.html#sphx-glr-auto-examples-neighbors-plot-lof-outlier-detection-py
推薦閱讀
- 🌍 數據分析實戰系列 ://www.showmeai.tech/tutorials/40
- 🌍 機器學習數據分析實戰系列://www.showmeai.tech/tutorials/41
- 🌍 深度學習數據分析實戰系列://www.showmeai.tech/tutorials/42
- 🌍 TensorFlow數據分析實戰系列://www.showmeai.tech/tutorials/43
- 🌍 PyTorch數據分析實戰系列://www.showmeai.tech/tutorials/44
- 🌍 NLP實戰數據分析實戰系列://www.showmeai.tech/tutorials/45
- 🌍 CV實戰數據分析實戰系列://www.showmeai.tech/tutorials/46


