硬核!Apache Hudi Schema演變深度分析與應用
- 2022 年 11 月 20 日
- 筆記
1.場景需求
在醫療場景下,涉及到的業務庫有幾十個,可能有上萬張表要做實時入湖,其中還有某些庫的表結構修改操作是通過業務人員在網頁手工實現,自由度較高,導致整體上存在非常多的新增列,刪除列,改列名的情況。由於Apache Hudi 0.9.0 版本到 0.11.0 版本之間只支援有限的schema變更,即新增列到尾部的情況,且用戶對數據品質要求較高,導致了非常高的維護成本。每次刪除列和改列名都需要重新導入,這種情況極不利於長期發展,所以需要一種能夠以較低成本支援完整schema演變的方案。
2.社區現狀
在 //hudi.apache.org/docs/schema_evolution 中提到:schema演化允許用戶輕鬆更改 Apache Hudi 表的當前 Schema,以適應隨時間變化的數據。從 0.11.0 版本開始,已添加 Spark SQL(Spark 3.1.x、3.2.1 及更高版本)對 Schema 演化的 DDL 支援並處於試驗階段。
- 可以添加、刪除、修改和移動列(包括嵌套列)
- 分區列不能進化
- 不能對 Array 類型的嵌套列進行添加、刪除或操作
為此我們針對該功能進行了相關測試和調研工作。
2.1 Schema演變的版本迭代
回顧Apache Hudi 對schema演變的支援隨著版本迭代的變化如下:
| 版本 | Schema演變支援 | 多引擎查詢 |
|---|---|---|
| *<0.9 | 無 | 無 |
| 0.9<* | 在最後的根級別添加一個新的可為空列 | 是(全) |
| 向內部結構添加一個新的可為空列(最後) | 是(全) | |
| 添加具有默認值的新複雜類型欄位(地圖和數組) | 是(全) | |
添加自定義可為空的 Hudi 元列,例如_hoodie_meta_col |
是(全) | |
為根級別的欄位改變數據類型從 int到long |
是(全) | |
將嵌套欄位數據類型從int到long |
是(全) | |
將複雜類型(映射或數組的值)數據類型從int到long |
是(全) | |
| 0.11<* | 相比之前版本新增:改列名 | spark以外的引擎不支援 |
| 相比之前版本新增:刪除列 | spark以外的引擎不支援 | |
| 相比之前版本新增:移動列 | spark以外的引擎不支援 |
Apache Hudi 0.11.0版本完整Schema演變支援的類型修改如下:
| Source\Target | long | float | double | string | decimal | date | int |
|---|---|---|---|---|---|---|---|
| int | Y | Y | Y | Y | Y | N | Y |
| long | Y | N | Y | Y | Y | N | N |
| float | N | Y | Y | Y | Y | N | N |
| double | N | N | Y | Y | Y | N | N |
| decimal | N | N | N | Y | Y | N | N |
| string | N | N | N | Y | Y | Y | N |
| date | N | N | N | Y | N | Y | N |
2.2 官網提供的方式
實踐中0.9.0版本的新增列未發現問題,已在正式環境使用。每次寫入前捕獲是否存在新增列刪除列的情況,新增列的情況及時補空數據和struct,新增列的數據及時寫入Hudi中;刪除列則數據補空,struct不變,刪除列仍寫入Hudi中;每天需要重導數據處理刪除列和修改列的情況,有變化的表在Hive中的元數據也以天為單位重新註冊。
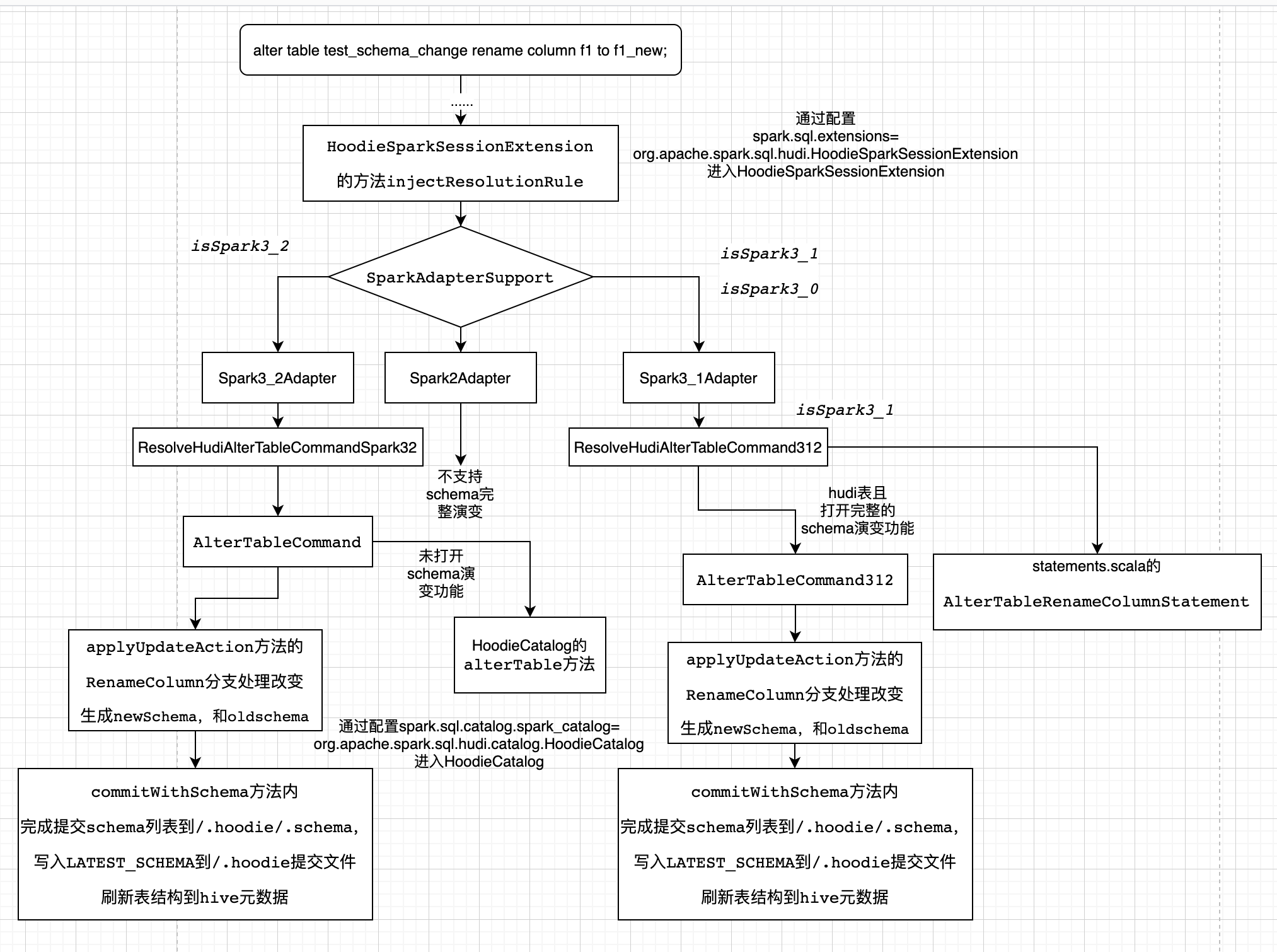
0.11開始的方式,按照官網的步驟:
進入spark-sql
# Spark SQL for spark 3.1.x
spark-sql --packages org.apache.hudi:hudi-spark3.1.2-bundle_2.12:0.11.1 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
# Spark SQL for spark 3.2.1 and above
spark-sql --packages org.apache.hudi:hudi-spark3-bundle_2.12:0.11.1 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog'
設置參數,刪列:
set hoodie.schema.on.read.enable=true;
---創建表---
create table test_schema_change (
id string,
f1 string,
f2 string,
ts bigint
) using hudi
tblproperties (
type = 'mor',
primaryKey = 'id',
preCombineField = 'ts'
);
---1.新增列---
alter table test_schema_change add columns (f3 string);
---2.刪除列---
alter table test_schema_change drop column f2;
---3.改列名---
alter table test_schema_change rename column f1 to f1_new;
2.3 其他方式
由於spark-sql的支援只在spark3.1之後支援,尋找並嘗試了 BaseHoodieWriteClient.java 中存在名為 addColumn renameColumn deleteColumns 的幾個方法,通過主動調用這些方法,也能達到schema完整變更的目的。使用這種方式需要將DDL的sql解析為對應的方法和參數,另外由於該方式測試和使用的例子還比較少,存在一些細節問題需要解決。
val hsec = new HoodieSparkEngineContext(spark.sparkContext);
val hoodieCfg = HoodieWriteConfig.newBuilder().forTable(tableName).withEmbeddedTimelineServerEnabled(true).withPath(basePath).build()
val client = new SparkRDDWriteClient(hsec, hoodieCfg)
//增加列
client.addColumn("f3",Schema.create(Schema.Type.STRING))
//刪除列
client.deleteColumns("f1")
//改列名
client.renameColumn("f2","f2_c1")
4. 完整Schema變更的寫入
4.1 核心實現
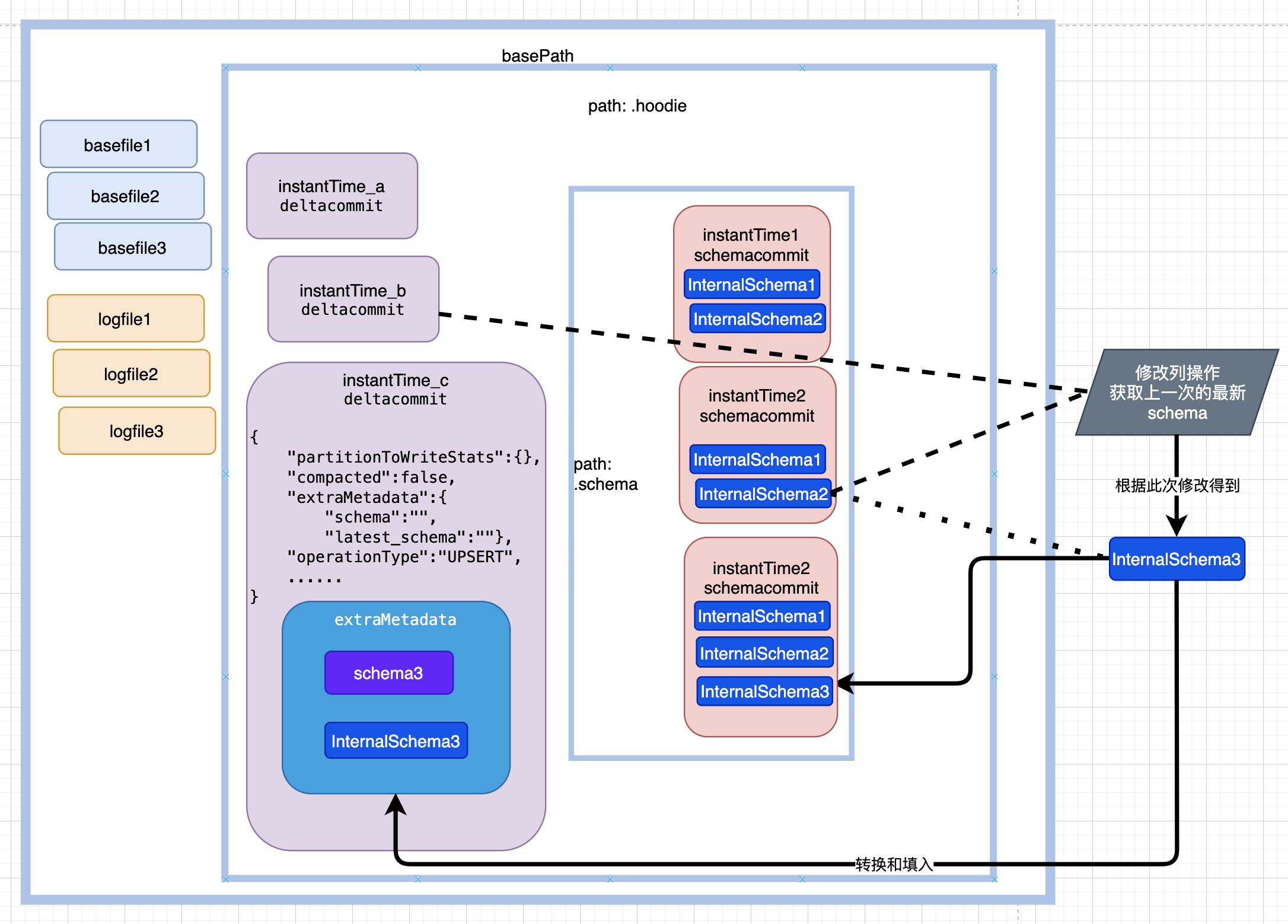
其中核心的類為 org.apache.hudi.internal.schema.InternalSchema ,出自HUDI-2429,通過記錄包括順序的完整列資訊,並且每次變更都保存歷史記錄,而非之前的只關注最新 org.apache.avro.Schema。
- 添加列:對於按順序添加列類型的添加操作,添加列資訊附加到 InternalSchema 的末尾並分配新的 ID。ID 值 +1
- 改列名 :直接更改 InternalSchema 中列對應的欄位的名稱、屬性、類型ID
- 刪除列:刪除 InternalSchema 中列對應的欄位
4.2 記錄完整schema變更
4.2.1 spark-sql方式
spark-sql的方式只支援Spark3.1、Spark3.2,分析如下:
4.2.2 HoodieWriteClient API方式
此處以BaseHoodieWriteClient.java 中具體修改方法的實現邏輯,分析完整schema演變在寫入過程的支援。
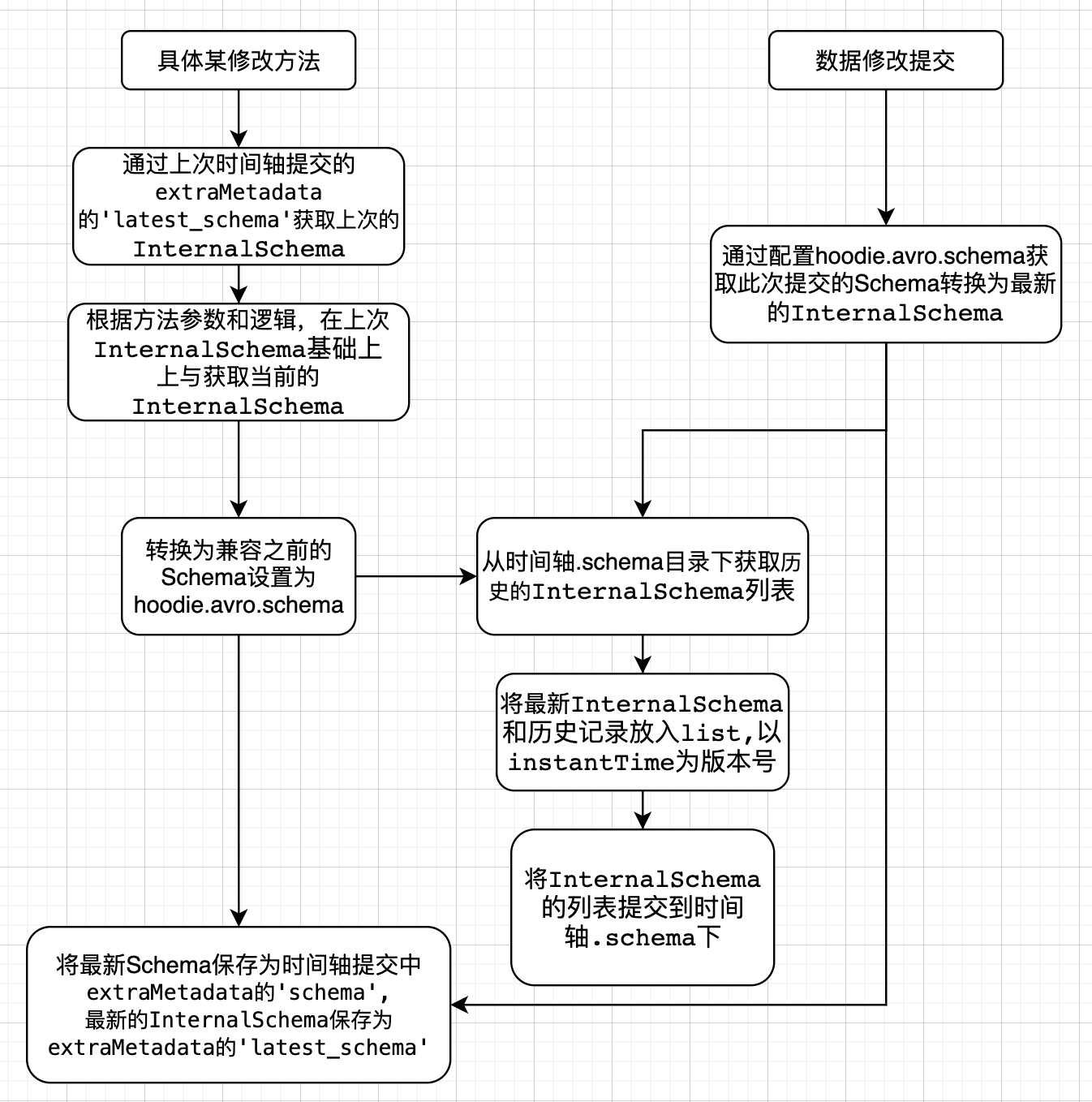
注意:在一次數據寫入操作完成後的commit階段,會根據條件判斷,是否保存 InternalSchema,關鍵條件為參數 hoodie.schema.on.read.enable
主動修改列的操作前,需要先存在歷史schema,否則會拋出異常 “cannot find schema for current table: ${basepath}”,因為metadata里不存在SerDeHelper.LATEST_SCHEMA(latest_schema)
4.3 時間軸示例
如圖所示,每次提交生成一份歷史的schema,位於${basePath}/.hoodie/.schema目錄下。
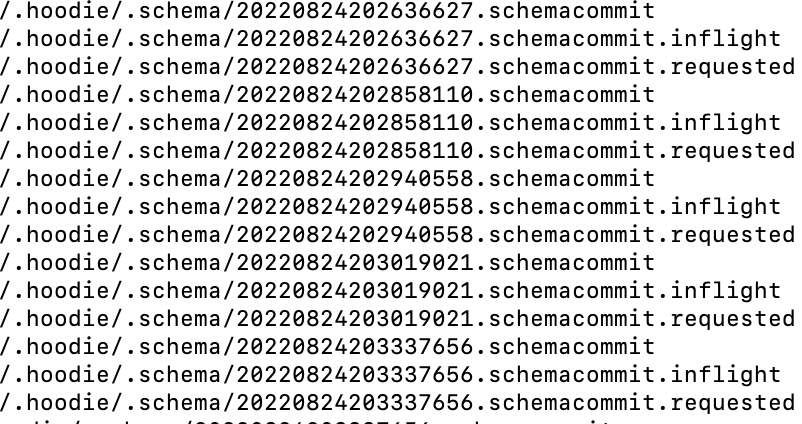
其中20220824202636627.schemacommit 內容:
{
"schemas": [
{
"max_column_id": 8,
"version_id": 20220824202636627,
"type": "record",
"fields": [
...
{
"id": 5,
"name": "id",
"optional": true,
"type": "string"
},
{
"id": 6,
"name": "f1",
"optional": true,
"type": "string"
},
{
"id": 7,
"name": "f2",
"optional": true,
"type": "string"
},
{
"id": 8,
"name": "ts",
"optional": true,
"type": "long"
}
]
}
]
}
期間新增了列f3後
20220824203337656.schemacommit 內容為:
{
"schemas": [
{
"max_column_id": 9,
"version_id": 20220824202940558,
"type": "record",
"fields": [
...
{
"id": 5,
"name": "id",
"optional": true,
"type": "string"
},
{
"id": 6,
"name": "f1",
"optional": true,
"type": "string"
},
{
"id": 7,
"name": "f2",
"optional": true,
"type": "string"
},
{
"id": 8,
"name": "ts",
"optional": true,
"type": "long"
},
{
"id": 9,
"name": "f3",
"optional": true,
"type": "string"
}
]
},
{
"max_column_id": 8,
"version_id": 20220824202636627,
"type": "record",
"fields": [
...
{
"id": 5,
"name": "id",
"optional": true,
"type": "string"
},
{
"id": 6,
"name": "f1",
"optional": true,
"type": "string"
},
{
"id": 7,
"name": "f2",
"optional": true,
"type": "string"
},
{
"id": 8,
"name": "ts",
"optional": true,
"type": "long"
}
]
}
]
}
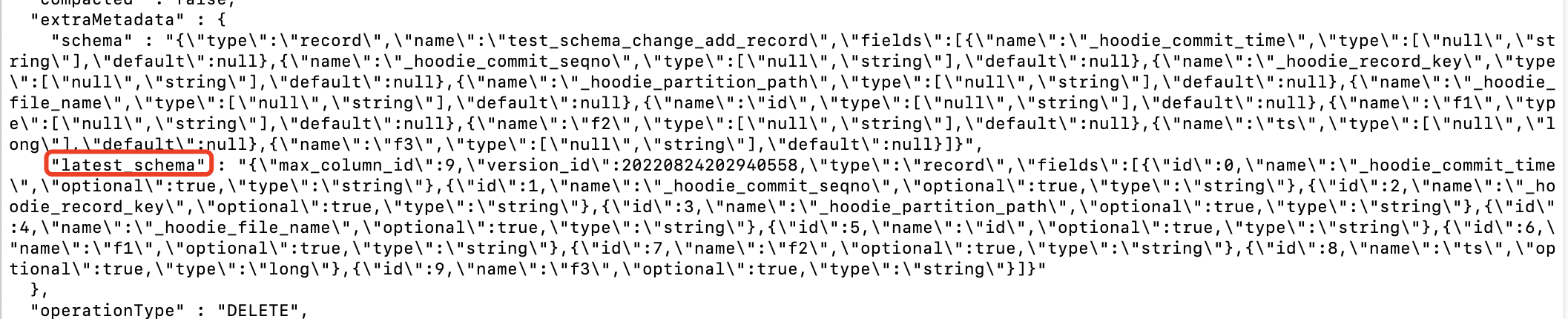
其中max_column_id 為列id最大值,version_id 為版本號,也為instantTime。
存在 latest_schema 的情況如下所示:
4.4 優化建議
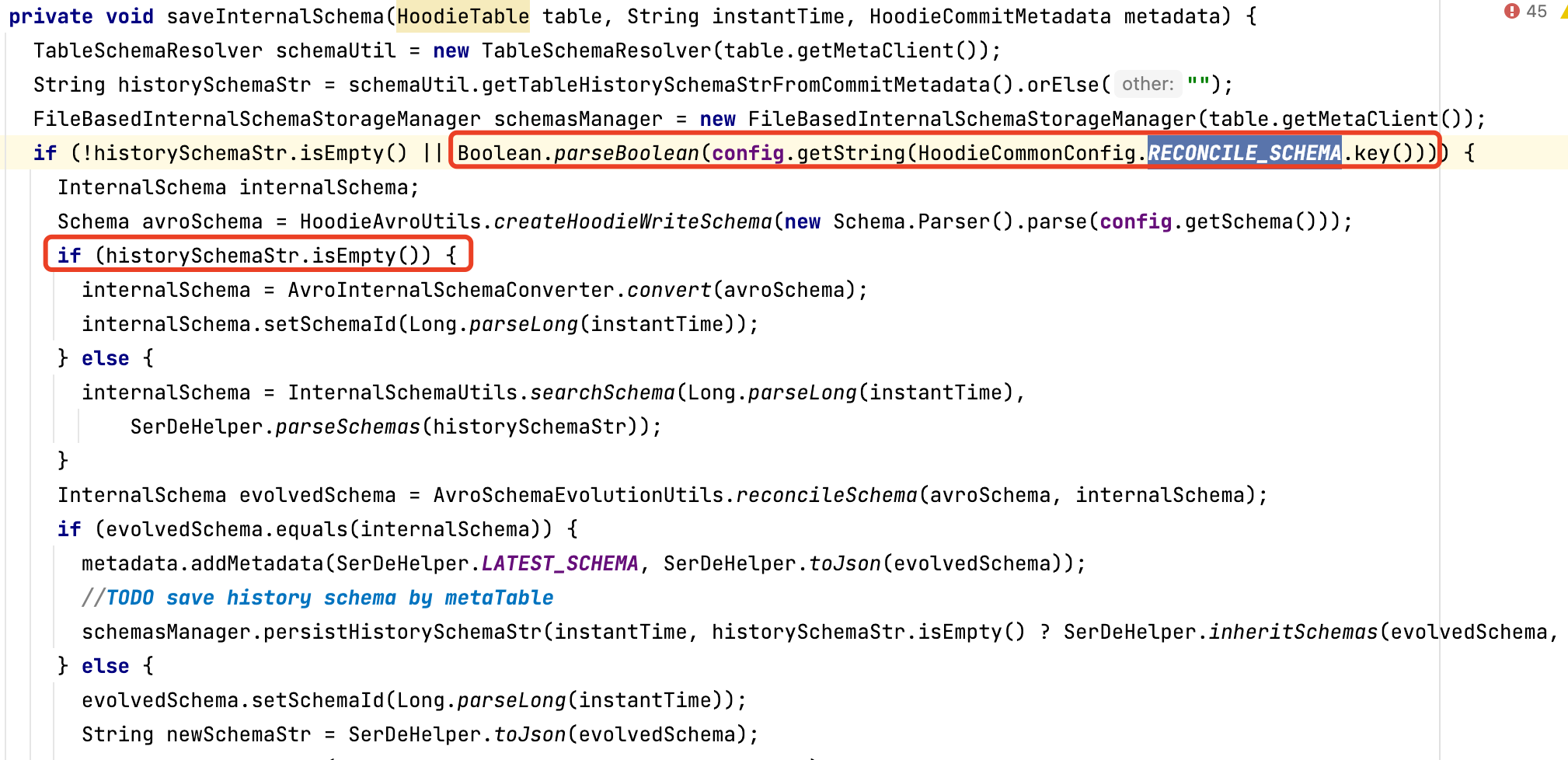
主動調用 BaseHoodieWriteClient.java 類中相應方法的方式下,由於保存歷史schema的邏輯上,a.打開該功能參數(hoodie.schema.on.read.enable) && b.存在歷史schema的才能保存歷史schema,在使用該功能之前或低於0.11版本的寫入升級到該版本,已經正在更新的hudi表,無法使用該功能。建議把條件a為真,b為假的情況,根據當前schema直接生成歷史schema

該處細節問題已經在HUDI-4276修復,0.12.0版本及以後不會有這個問題
hoodie.datasource.write.reconcile.schema 默認為false,如果要達到上述目的,改為true即可
5. 實現完整schema變更的查詢
大體流程如下:
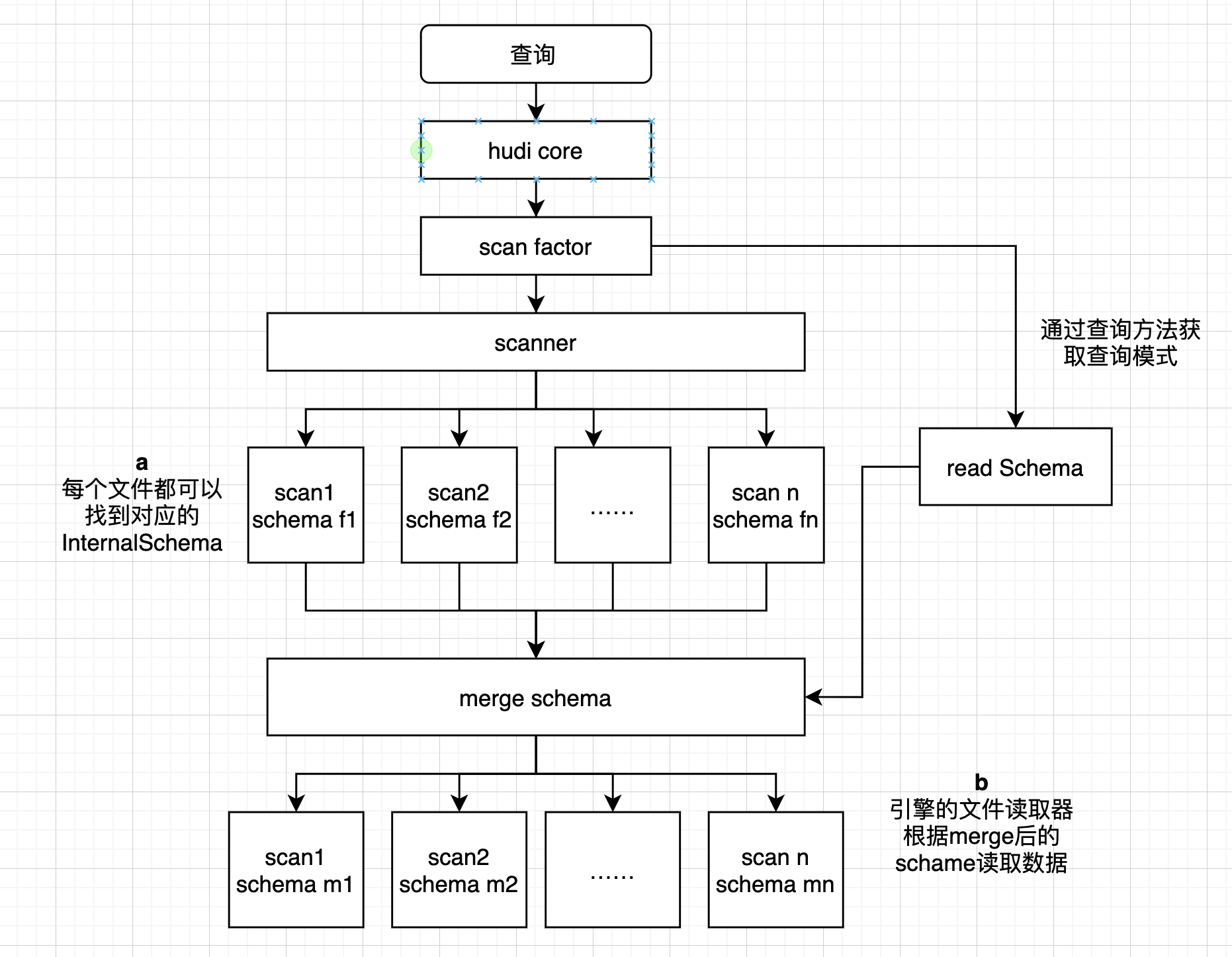
1.總體流程為某個查詢進入dataSource中,選擇具體的relacation,獲取查詢schema,獲取scan
2.在scan中獲取每個基礎文件或日誌的數據塊對應的數據schema
3.在scan中獲取數據schema後與查詢schema進行merge,通過merge的schema來讀取具體數據
5.1 獲取數據schema
上圖中流程 **a **大體流程如下:
5.1.1 基礎文件獲取流程
由於基礎文件的命名方式和組織形式,基礎文件的scan過程在HoodieParquetFileFormat中可以直接通過文件名獲取InstantTime:
在用於讀取和寫入hudi表DefaultSource中,createRelation方法按照參數創建對應的BaseRelation擴展子類
HoodieBaseRelation#buildScan中調用 composeRDD 方法,該方法分別在子類BaseFileOnlyRelation,MergeOnReadSnapshotRelation,MergeOnReadIncrementalRelation 中實現,
以MergeOnReadSnapshotRelation 即mor表的快照讀為例,在composeRDD 方法中調用父類createBaseFileReader的方法,其中val parquetReader = HoodieDataSourceHelper.buildHoodieParquetReader,以SparkAdapterSupport的createHoodieParquetFileFormat創建ParquetFileFormat,
SparkAdapterSupport的三個子類分別為Spark2Adapter,Spark3_1Adapter和Spark3_2Adapter,以Spark3_1Adapter實現的方法為例
創建Spark31HoodieParquetFileFormat,其中buildReaderWithPartitionValues方法中,會通過FSUtils.getCommitTime獲取InstantTime
5.1.2 日誌文件獲取流程
log文件的文件名中的時間戳與提交 instantTime不一致,一個log文件對應多次時間軸 instantTime 提交。
日誌文件的scan在AbstractHoodieLogRecordReader.java的的通過每個HoodieDataBlock的header中的 INSTANT_TIME 獲取對應的 instantTime
以MergeOnReadSnapshotRelation為例,在composeRDD中創建HoodieMergeOnReadRDD
在HoodieMergeOnReadRDD的compute方法中使用的LogFileIterator類及其子類中使用HoodieMergeOnReadRDD的scanLog方法
scanLog中創建HoodieMergedLogRecordScanner,創建時執行performScan() -> 其父類AbstractHoodieLogRecordReader的scan(),
scan() -> scanInternal() -> processQueuedBlocksForInstant() 循環獲取雙端隊列的logBlocks -> processDataBlock() -> getMergedSchema()
在getMergedSchema方法中通過HoodieDataBlock的getLogBlockHeader().get(INSTANT_TIME)獲取InstantTime
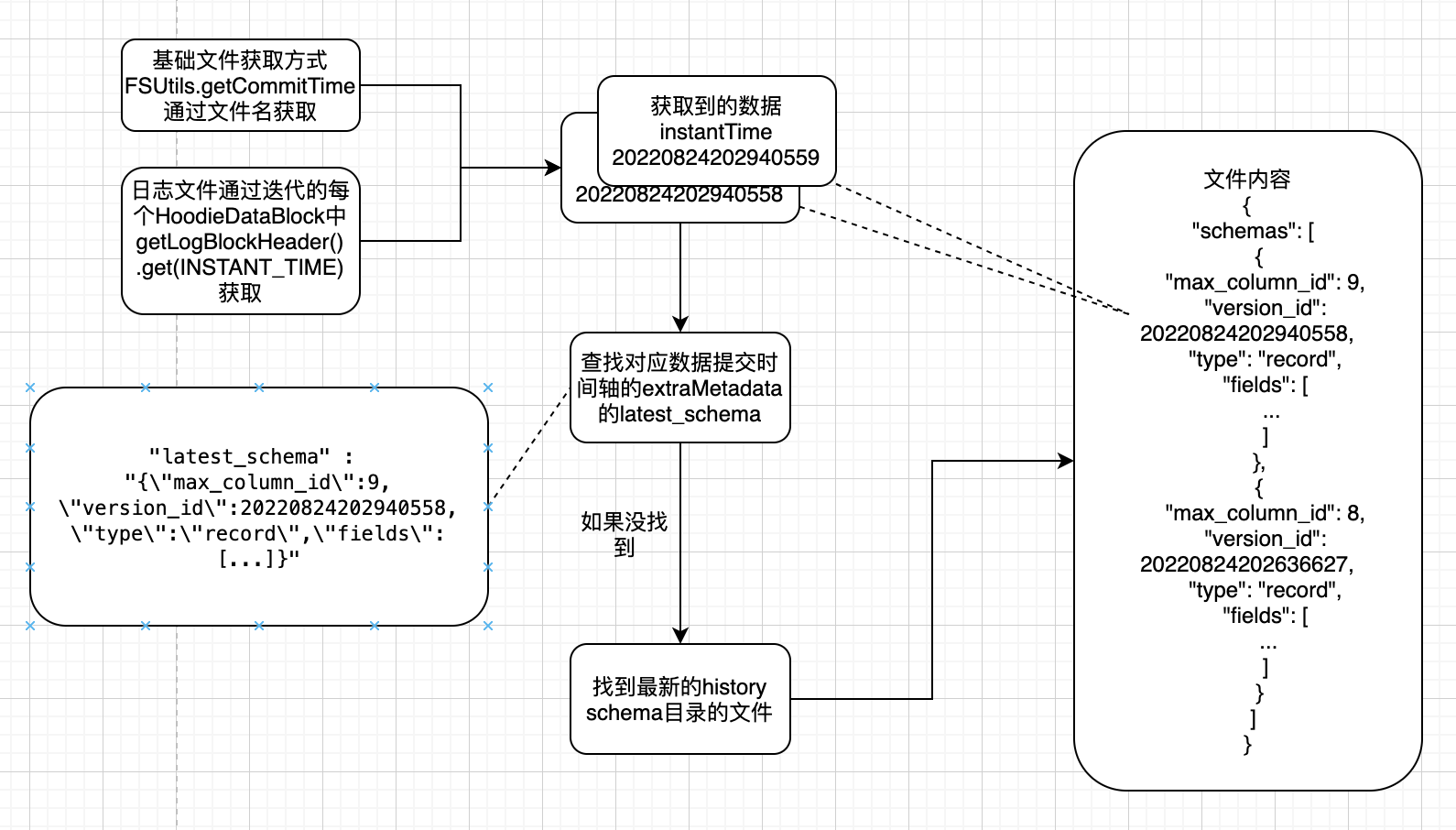
5.1.3 通過instantTime獲取數據schema
根據InstantTime獲取時間軸提交文件
如果能夠獲取,直接取其中extraMetadata中的latest_schema內容作為數據schema
如果不能獲取,在獲取最新的${basePath}/.hoodie/.schema/下的具體文件後,通過文件內容搜索具體 InternalSchema找到最新的history
如果有InstantTime對應的versino_id,直接獲取
如果沒有InstantTime對應的versino_id,說明那次寫入無變化,從那次寫入前的最新一次獲取
5.2 合併查詢schema與數據schema
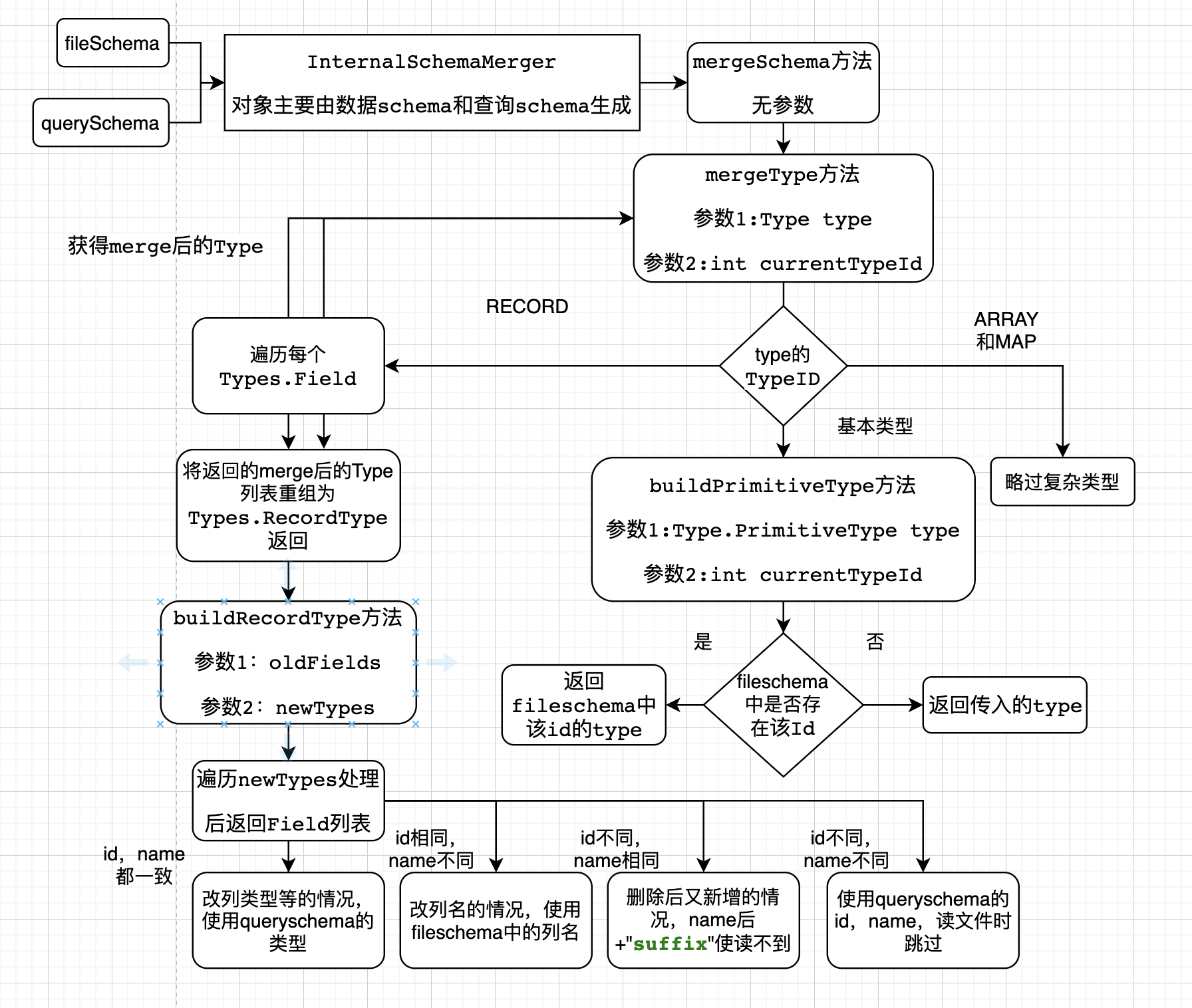
5.2.1 merge方法解析
-
輸入數據schema和查詢schema,和幾個布爾屬性,獲得InternalSchemaMerger對象
-
遞歸調用mergeType方法處理查詢schema,首先進入RECORD,遍歷每個列,mergeType方法處理
-
略過複雜類型
-
基本類型中會進入buildPrimitiveType方法
-
根據輸入的id獲取數據schena的Type,如果沒有,就返回輸入的Type
-
-
將返回的Type加入名為 newTypes的Type列表,把newTypes和查詢schema的欄位列表的輸入buildRecordType方法
-
遍歷查詢schema的列,並用id和name獲取數據schema的列
-
如果id和name都一致,為改列類型,使用數據schema的類型
-
如果id相同,name不同,改列名,使用數據schema的名字
-
如果id不同,name相同,先刪後加,加後綴保證讀不到文件內容
-
如果id不同,name不同,後來新增列
-
-
組裝返回merge後的schema
5.2.2 merge示例
如下所示:
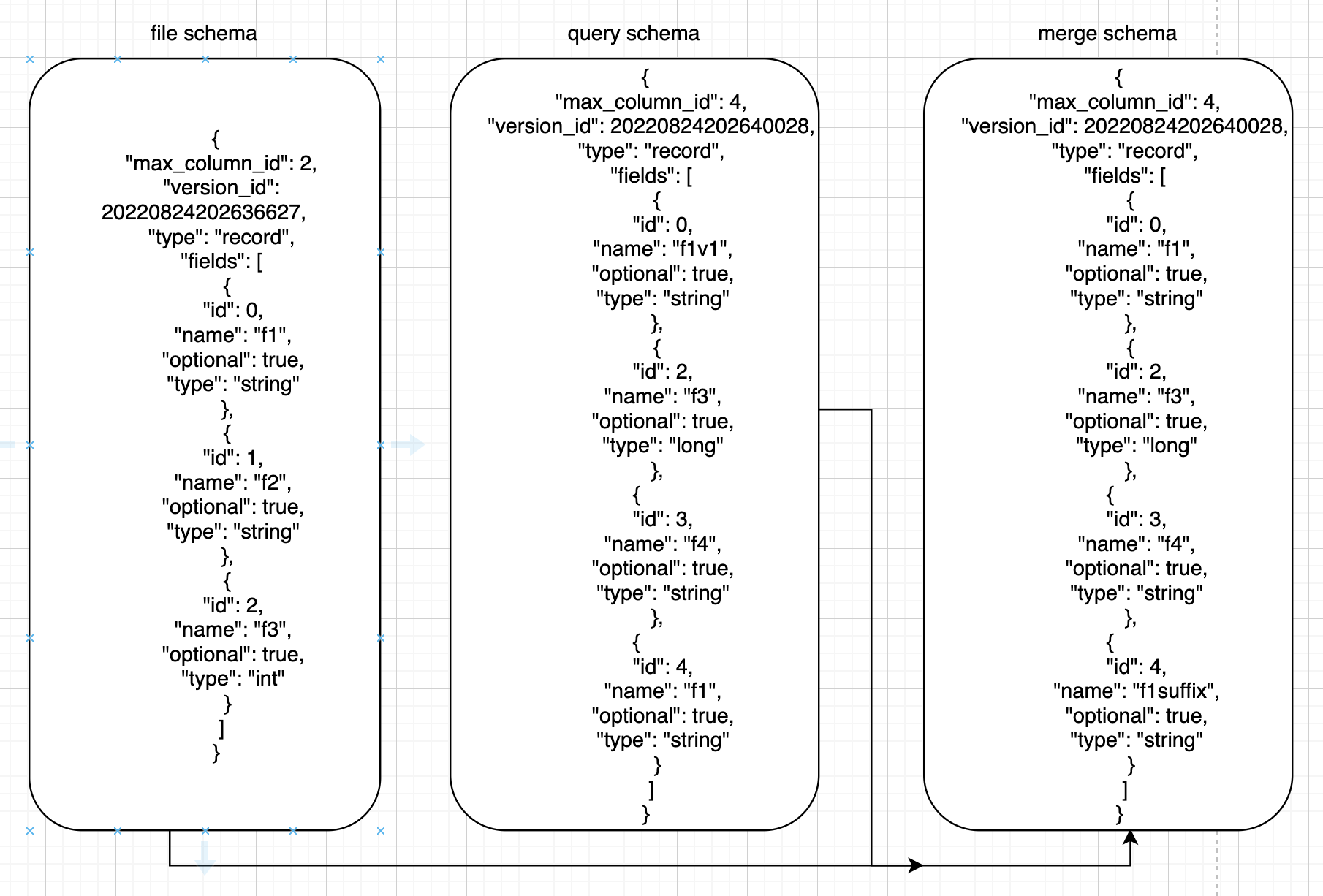
其中id為唯一標誌性,
id=0的query里改名為f1v1,merge後為f1,
id=1的query里刪除,merge里也沒有,
id=2的query里為long型,files里為int型,merge里為long型
id=3的query里新增,返回query的欄位
id=4的query里name為f1,對應file里的name為f1的id為0,所以merge里id為4,name為 (“f1″+”suffix”)
6. 各種引擎的支援
6.1 Spark測試結果
測試的Spark版本 > spark3.1且 hoodie.schema.on.read.enable=true
完全支援
否則測試結果如下:
| 操作類型 | 是否支援 | 原因 |
|---|---|---|
| 新增列 | 是 | 按列名查詢,沒有的列返回null |
| 刪除列 | 是 | 按列名查詢,原有的列跳過 |
| 改列名 | 否 | 按列名查詢不到old_field值,能查詢到new_field的值 |
6.2 Hive遇到的問題
Hive查詢MOR的rt表有些問題,此處不再細述,此處修改列操作後都同步Hive元數據
| 操作類型 | 是否支援 | 原因 |
|---|---|---|
| 新增列 | 是 | 按列名查詢基礎文件,文件沒有的列返回null |
| 刪除列 | 是 | 按列名查詢基礎文件,文件原有列跳過 |
| 改列名 | 否 | 按列名查詢不到old_field值,能查詢到new_field的值 |
由於hive的查詢依據的是hive metastore中的唯一版本的元數據,數據修改列後還需要同步到hive後才能查詢到表的變更,該過程只讀取時間軸中最新提交的schema,且查詢使用的類 org.apache.hudi.hadoop.HoodieParquetInputFormat 中並不存在針對schema完整變更做出的改動,所以測試結果與 spark2.* 或hoodie.schema.on.read.enable=false 的情況相當。
重命名列的情況下,查詢不到改名後的列名對應的數據。需要所有文件組都在改列名後產生新的基礎文件後,數據才準確。
6.3 Presto遇到的問題
由於Presto同樣使用hive的元數據,330的presto遇到的問題和hive遇到的問題一致,查詢rt表仍為查詢ro表
trino-360 和 presto275 使用某個patch支援查詢rt表後,查詢ro表問題如下:
| 操作類型 | 是否支援 | 原因 |
|---|---|---|
| 新增列 | 否 | 按順序查詢基礎文件,導致串列,新增列在ts列之前可能拋出異常 |
| 刪除列 | 否 | 按順序查詢基礎文件,導致串列,因為ts類型很可能拋出異常 |
| 改列名 | 是 | 按順序查詢基礎文件,名字不同,順序相同 |
出現串列異常,除非所有文件組的最新基礎文件都是修改列操作之後產生的,才能準確。
原因大致為:這些版本中查詢hudi表,讀取parquet文件中數據時按順序和查詢schema對應,而非使用parquet文件自身攜帶的schema去對應

查詢rt表如下:
| 操作類型 | 是否支援 | 原因 |
|---|---|---|
| 新增列 | 是 | 按列名查詢基礎文件和日誌文件,文件沒有的列返回null |
| 刪除列 | 是 | 按列名查詢基礎文件和日誌文件,文件原有列跳過 |
| 改列名 | 否 | 按列名查詢不到old_field值,能查詢到new_field的值 |
可見查詢rt表仍按parquet文件的schema對應,所以沒有上述串列問題,等效於 spark2.* 或hoodie.schema.on.read.enable=false 的情況
7. 總結與展望
目前該方案在Spark引擎上支援完整schema演變, 降低生產環境下上游欄位變更的處理成本。但該方案還比較粗糙,後續有以下方面可以繼續改進
- 多引擎支援: 支援所有引擎的查詢比如Hive,Presto,Trino等
- 降低小文件影響:由於歷史schema的寫入邏輯,如果打開這個功能,一次數據寫入,時間軸/.hoodie目錄下除了原本要產生的文件外,還要產生/.hoodie/.schema下的3個文件,建議把/.hoodie/.schema下內容寫入元數據表中
- 現有表的schema變更提取:4.4中的建議忽略了未打開該功能前的現存錶的歷史變更(忽略後問題不大)。