【原創】機器學習從零開始系列連載(8)——機器學習中的統一框架
- 2020 年 3 月 4 日
- 筆記
機器學習中的統一框架
很多機器學習問題都可以放在一個統一的框架下討論,這樣大家在理解各種模型時就是相互聯繫的。
目標函數
回憶一下目標函數的定義:

其實,很多模型可以用這種形式框起來:
比如linear regression、logistic regression、SVM、additive models、k-means,neural networks 等等。
其中損失函數部分用來控制模型的擬合能力,期望降低偏差;正則項部分用來提升模型泛化能力,期望降低方差,最優模型是對偏差和方差的最優折中。
損失函數
損失函數反應了模型對歷史數據的學習程度,我們期望模型能儘可能學到歷史經驗,得到一個低偏差模型。

Q:大家想想橫坐標是什麼?

實踐當中很少直接使用0-1損失做優化(當然也有這麼用的,比如下面兩篇論文,可以通過公眾號後台獲得:
Direct 0-1 Loss Minimization and Margin Maximization with Boosting:【公眾號後台回復 Loss 獲取這篇論文】
和
Algorithms for Direct 0–1 Loss Optimization in Binary Classification:【公眾號後台回復Loss獲取這篇論文 】
但總的來說應用有限),原因如下:
- 0-1損失的優化是組合優化問題且為NP-hard,無法在多項式時間內求得;
- 損失函數非凸非光滑,很多優化方法無法使用;
- 對權重的更新可能會導致損失函數大的變化,即變化不光滑;
- 只能使用正則,其他正則形式都不起作用;
- 即使使用正則,依然是非凸非光滑,優化求解困難。
由於0-1損失的問題,所以以上損失函數都是對它的近似。原理細節可以參考:Understanding Machine Learning: From Theory to Algorithms
不同損失函數在相同數據集下的直觀表現如下:

正則化項
正則化項影響的是模型在未知樣本上的表現,我們希望通過它能降低模型方差提高泛化性。
如果有數據集:

在給定假設下,通常採用極大似然估計(MLE)求解參數:

假設模型參數也服從某種概率分布 , 可以採用極大後驗概率估計(MAP)求解參數。

L2 正則
假設
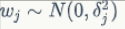


L1 正則
假設

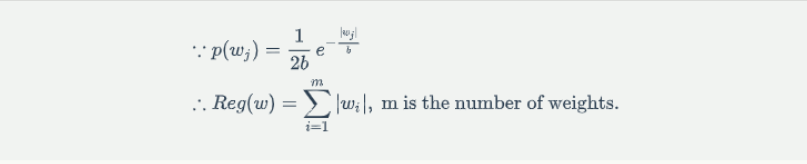

正則化的幾何解釋

L1 and L2 Regularization

不同q的取值下正則項的幾何表現如下:

from wiki
Dropout正則化與數據擴充
這兩類方法在神經網路中比較常用,後面會專門介紹。
神經網路框架
很多模型可以看做是神經網路,例如:感知機、線性回歸、支援向量機、邏輯回歸等。
Linear Regression
線性回歸可以看做是激活函數的單層神經網路:

Logistic Regression
邏輯回歸可以看做是激活函數的單層神經網路:

Support Vector Machine
採用核方法後的支援向量機可以看做是含有一個隱層的3層神經網路:

Bootstrap Neural Network
採用bagging方式的組合神經網路:

Boosting Neural Network
採用boosting方式的組合神經網路:

前情回顧
神經網路在維基百科上的定義是:
NN is a network inspired by biological neural networks (the central nervous systems of animals, in particular the brain) which are used to estimate or approximate functions that can depend on a large number of inputs that are generally unknown.(from wikipedia)

神經元
神經元是神經網路和SVM這類模型的基礎模型和來源,它是一個具有如下結構的線性模型:

其輸出模式為:

示意圖如下:

神經網路的常用結構
神經網路由一系列神經元組成,典型的神經網路結構如下:

其中最左邊是輸入層,包含若干輸入神經元,最右邊是輸出層,包含若干輸出神經元,介於輸入層和輸出層的所有層都叫隱藏層,由於神經元的作用,任何權重的微小變化都會導致輸出的微小變化,即這種變化是平滑的。
神經元的各種組合方式得到性質不一的神經網路結構 :

前饋神經網路

反向傳播神經網路

循環神經網路

卷積神經網路

自編碼器

Google DeepMind 記憶神經網路(用於AlphaGo)
一個簡單的神經網路例子
假設隨機變數 , 使用3層神經網路擬合該分布:
import numpy as np import matplotlib matplotlib.use('Agg') import matplotlib.pyplot as plt import random import math import keras from keras.models import Sequential from keras.layers.core import Dense,Dropout,Activation def gd(x,m,s): left=1/(math.sqrt(2*math.pi)*s) right=math.exp(-math.pow(x-m,2)/(2*math.pow(s,2))) return left*right def pt(x, y1, y2): if len(x) != len(y1) or len(x) != len(y2): print 'input error.' return plt.figure(num=1, figsize=(20, 6)) plt.title('NN fitting Gaussian distribution', size=14) plt.xlabel('x', size=14) plt.ylabel('y', size=14) plt.plot(x, y1, color='b', linestyle='--', label='Gaussian distribution') plt.plot(x, y2, color='r', linestyle='-', label='NN fitting') plt.legend(loc='upper left') plt.savefig('ann.png', format='png') def ann(train_d, train_l, prd_d): if len(train_d) == 0 or len(train_d) != len(train_l): print 'training data error.' return model = Sequential() model.add(Dense(30, input_dim=1)) model.add(Activation('relu')) model.add(Dense(30)) model.add(Activation('relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='mse', optimizer='rmsprop', metrics=['accuracy']) model.fit(train_d,train_l,batch_size=250, nb_epoch=50, validation_split=0.2) p = model.predict(prd_d,batch_size=250) return p if __name__ == '__main__': x = np.linspace(-5, 5, 10000) idx = random.sample(x, 900) train_d = [] train_l = [] for i in idx: train_d.append(x[i]) train_l.append(gd(x[i],0,1)) y1 = [] y2 = [] for i in x: y1.append(gd(i,0,1)) y2 = ann(np.array(train_d).reshape(len(train_d), 1), np.array(train_l), np.array(x).reshape(len(x), 1)) pt(x, y1, y2.tolist())



