已經有 MESI 協議,為什麼還需要 volatile 關鍵字?
本文已收錄到 GitHub · AndroidFamily,有 Android 進階知識體系,歡迎 Star。技術和職場問題,請關注公眾號 [彭旭銳] 進 Android 面試交流群。
前言
大家好,我是小彭。
在上一篇文章里,我們聊到了 CPU 的快取一致性問題,分為縱向的 Cache 與記憶體的一致性問題以及橫向的多個核心 Cache 的一致性問題。我們也討論了 MESI 協議通過寫傳播和事務串列化實現快取一致性。
不知道你是不是跟我一樣,在學習 MESI 協議的時候,自然地產生了一個疑問:在不考慮寫緩衝區和失效隊列的影響下,在硬體層面已經實現了快取一致性,那麼在 Java 語言層面為什麼還需要定義 volatile 關鍵字呢?是多此一舉嗎?今天我們將圍繞這些問題展開。
學習路線圖:
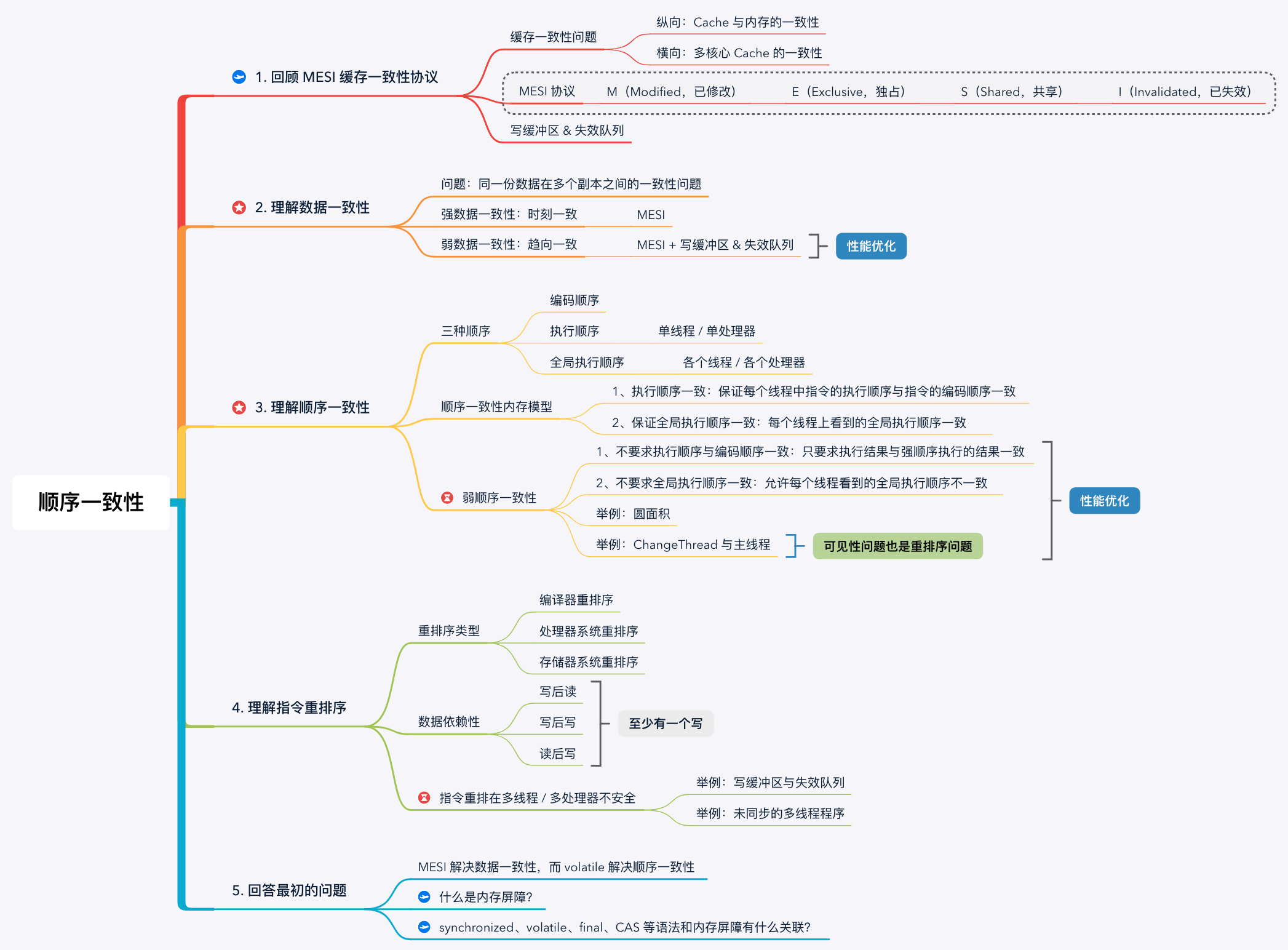
1. 回顧 MESI 快取一致性協議
由於 CPU 和記憶體的速度差距太大,為了拉平兩者的速度差,現代電腦會在兩者之間插入一塊速度比記憶體更快的高速快取,CPU 快取是分級的,有 L1 / L2 / L3 三級快取。其中 L1 / L2 快取是核心獨佔的,而 L3 快取是多核心共享的。
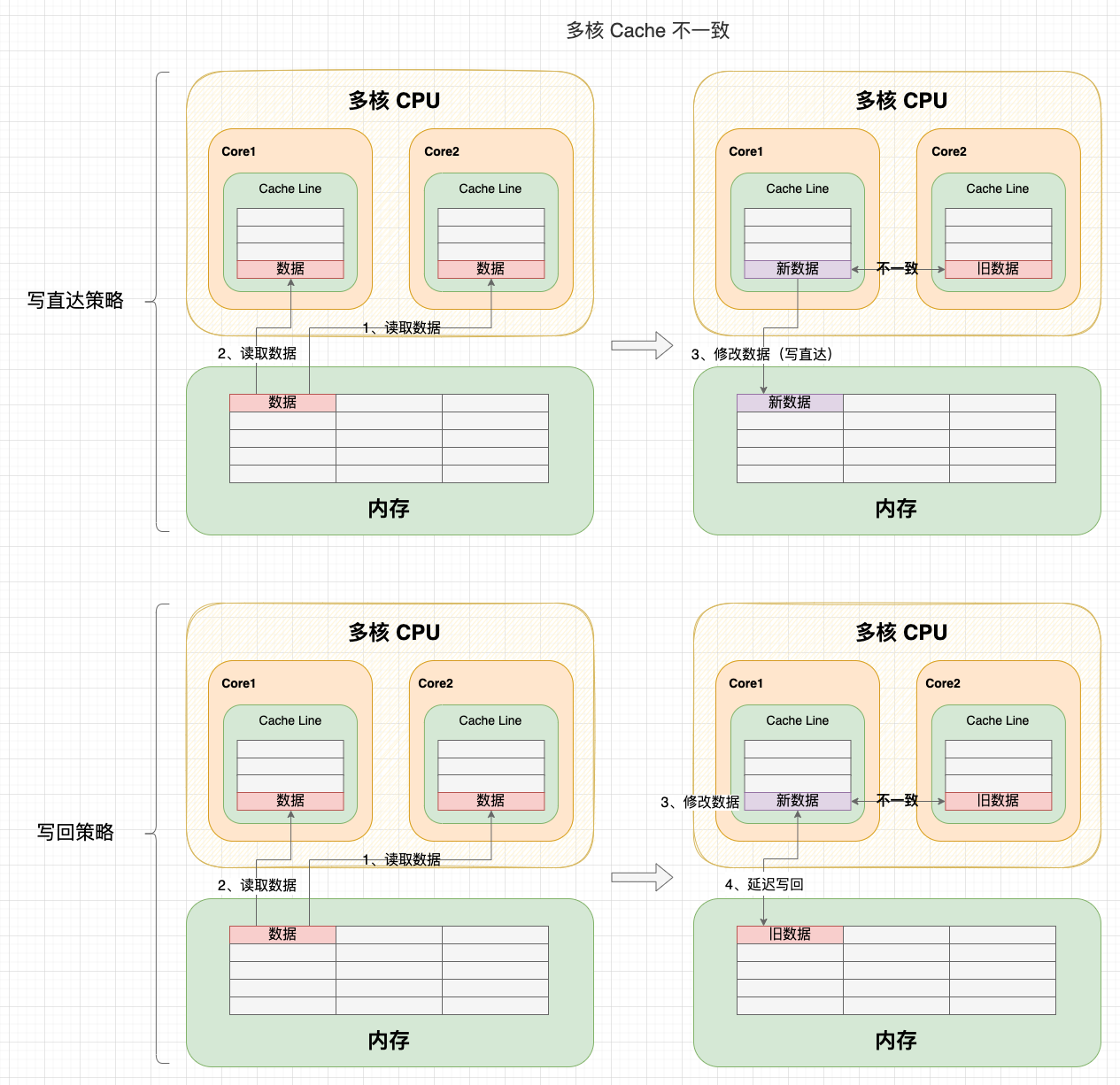
在 CPU Cache 的三級快取中,會存在 2 個快取一致性問題:
- 縱向 – Cache 與記憶體的一致性問題:通過寫直達或寫回策略解決;
- 橫向 – 多核心 Cache 的一致性問題:通過 MESI 等快取一致性協議解決。
MESI 協議能夠滿足寫傳播和事務串列化 2 點特性,通過 「已修改、獨佔、共享、已失效」 4 個狀態實現了 CPU Cache 的一致性;
現代 CPU 為了提高並行度,會在增加寫緩衝區 & 失效隊列將 MESI 協議的請求非同步化,這其實是一種處理器級別的指令重排,會破壞了 CPU Cache 的一致性。
Cache 不一致問題
MESI 協議在線模擬
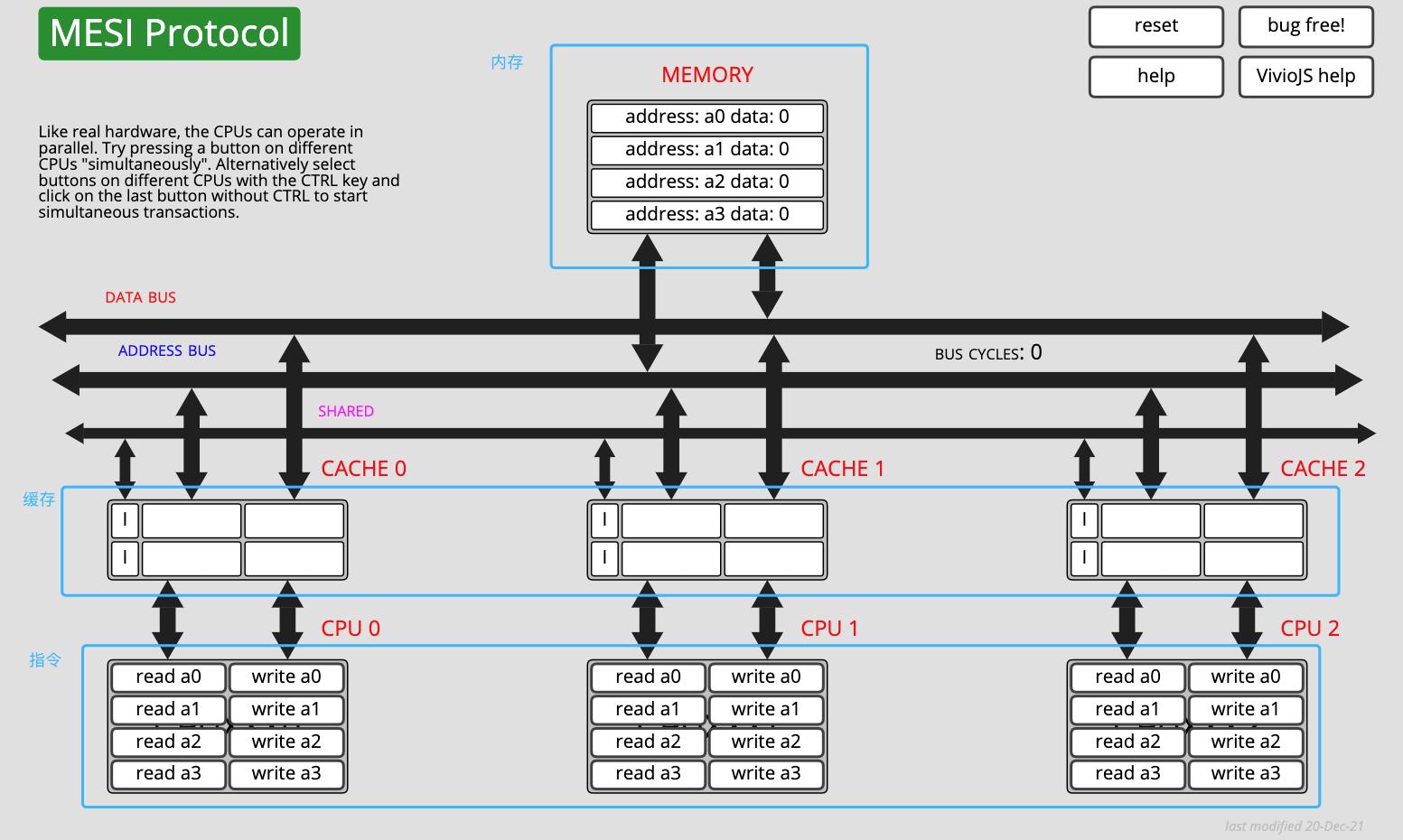
網站地址://www.scss.tcd.ie/Jeremy.Jones/VivioJS/caches/MESI.htm
現在,我們的問題是:既然 CPU 已經實現了 MESI 協議,為什麼 Java 語言層面還需要定義 volatile 關鍵字呢?豈不是多此一舉?你可能會說因為寫緩衝區和失效隊列破壞了 Cache 一致性。好,那不考慮這個因素的話,還需要定義 volatile 關鍵字嗎?
其實,MESI 解決數據一致性(Data Conherence)問題,而 volatile 解決順序一致性(Sequential Consistency)問題。 WC,這兩個不一樣嗎?

2. 數據一致性 vs 順序一致性
2.1 數據一致性
數據一致性討論的是同一份數據在多個副本之間的一致性問題, 你也可以理解為多個副本的狀態一致性問題。例如記憶體與多核心 Cache 副本之間的一致性,或者數據在主從資料庫之間的一致性。
當我們從 CPU 快取一致性問題開始,逐漸討論到 Cache 到記憶體的寫直達和寫回策略,再討論到 MESI 等快取一致性協議,從始至終我們討論的都是 CPU 快取的 「數據一致性」 問題,只是為了簡便我們從沒有刻意強調 「數據」 的概念。
數據一致性有強弱之分:
- 強數據一致性: 保證在任意時刻任意副本上的同一份數據都是相同的,或者允許不同,但是每次使用前都要刷新確保數據一致,所以最終還是一致。
- 弱數據一致性: 不保證在任意時刻任意副本上的同一份數據都是相同的,也不要求使用前刷新,但是隨著時間的遷移,不同副本上的同一份數據總是向趨同的方向變化,最終還是趨向一致。
例如,MESI 協議就是強數據一致性的,但引入寫緩衝區或失效隊列後就變成弱數據一致性,隨著緩衝區和失效隊列被消費,各個核心 Cache 最終還是會趨向一致狀態。
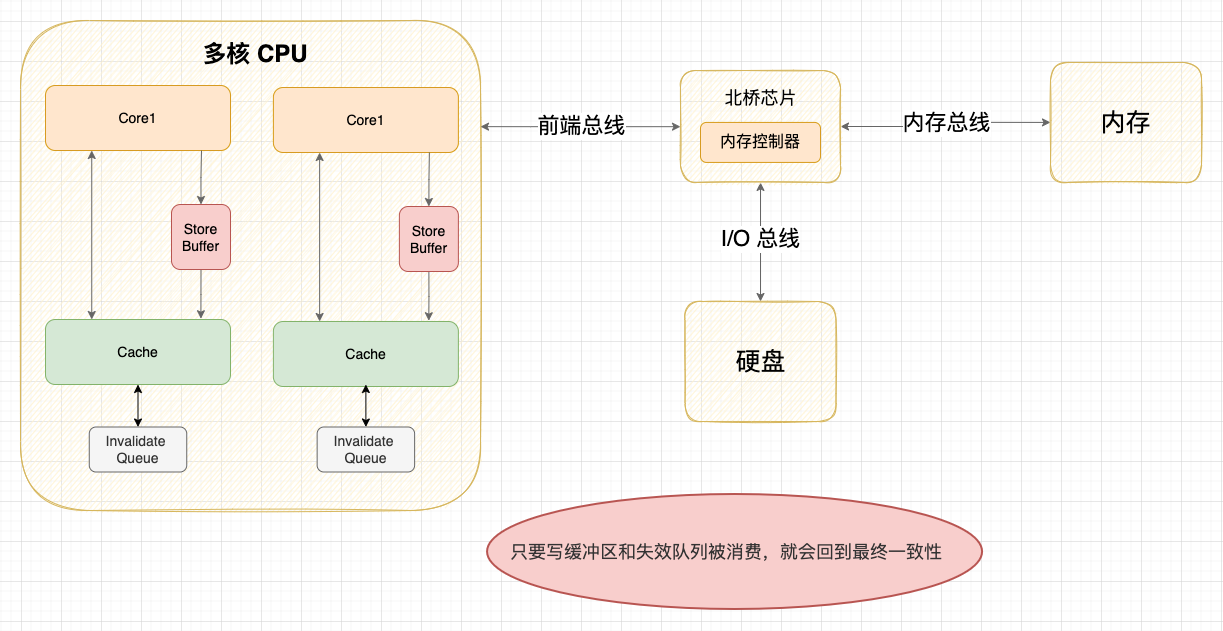
2.2 順序一致性
順序一致性討論的是對多個數據的多次操作順序在整個系統上的一致性。在並發編程中,存在 3 種指令順序:
- 編碼順序(Progrom Order): 指源碼中指令的編寫順序,是程式設計師視角看到的指令順序,不一定是實際執行的順序;
- 執行順序(Memory Order): 指單個執行緒或處理器上實際執行的指令順序;
- 全局執行順序(Global Memory Order): 每個執行緒或處理器上看到的系統整體的指令順序,在弱順序一致性模型下,每個執行緒看到的全局執行順序可能是不同的。
順序一致性模型是電腦科學家提出的一種理想參考模型,為程式設計師描述了一個極強的全局執行順序一致性,由 2 個特性組成:
- 特性 1 – 執行順序與編碼順序一致: 保證每個執行緒中指令的執行順序與編碼順序一致;
- 特性 2 – 全局執行順序一致: 保證每個指令的結果會同步到主記憶體和各個執行緒的工作記憶體上,使得每個執行緒上看到的全局執行順序一致。
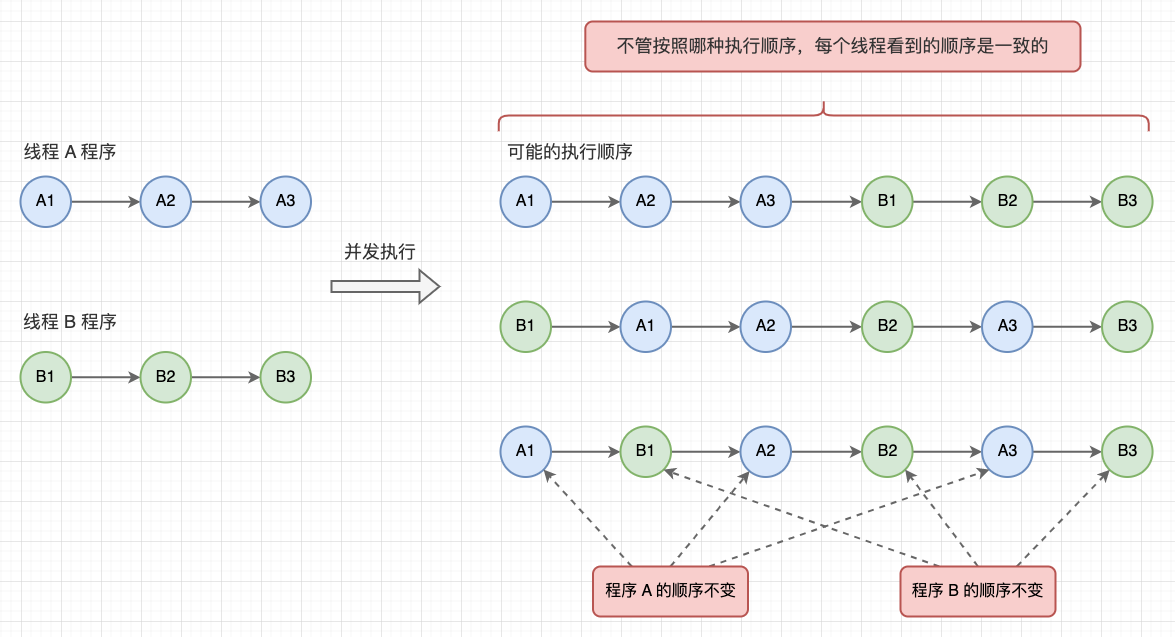
舉個例子,執行緒 A 和執行緒 B 並發執行,執行緒 A 執行 A1 → A2 → A3,執行緒 B 執行 B1 → B2 → B3。那麼,在順序一致性記憶體模型下,雖然程式整體執行順序是不確定的,但是執行緒 A 和執行緒 B 總會按照 1 → 2 → 3 編碼順序執行,而且兩個執行緒總能看到相同的全局執行順序。
順序一致性記憶體模型
2.3 弱順序一致性(一定要理解)
雖然順序一致性模型對程式設計師非常友好,但是對編譯器和處理器卻不見得喜聞樂見。如果程式完全按照順序一致性模型來實現,那麼處理器和編譯器的很多重排序優化都要被禁止,這對程式的 「並行度」 會有影響。例如:
- 1、重排序問題: 編譯器和處理器不能重排列沒有依賴關係的指令;
- 2、記憶體可見性問題: CPU 不能使用寫回策略,也不能使用寫緩衝區和失效隊列機制。其實,從記憶體的視角看也是指令重排問題。
所以,在 Java 虛擬機和處理器實現中,實際上使用的是弱順序一致性模型:
- 特性 1 – 不要求執行順序與編碼順序一致: 不要求單執行緒的執行順序與編碼順序一致,只要求執行結果與強順序執行的結果一致,而指令是否真的按編碼順序執行並不關心。因為結果不變,從程式設計師的視角看程式就是按編碼順序執行的假象;
- 特性 2 – 不要求全局執行順序一致: 允許每個執行緒看到的全局執行順序不一致,甚至允許看不到其他執行緒已執行指令的結果。
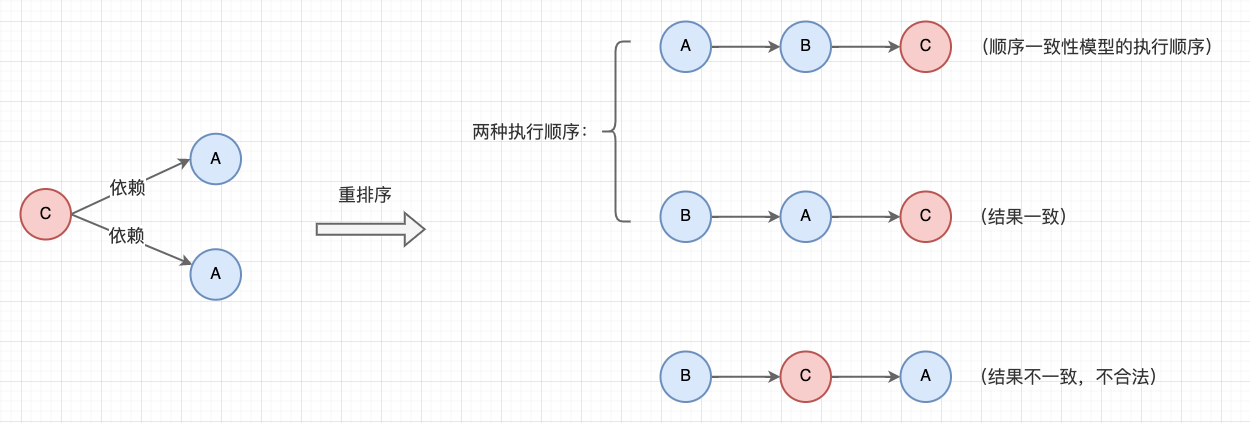
舉個單執行緒的例子: 在這段計算圓面積的程式碼中,在弱順序一致性模型下,指令 A 和 指令 B 可以不按編碼順序執行。因為 A 和 B 沒有數據依賴,所以對最終的結果也沒有影響。但是 C 對 A 和 B 都有數據依賴,所以 C 不能重排列到 A 或 B 的前面,否則會改變程式結果。
偽程式碼
double pi = 3.14; // A
double r = 1.0; // B
double area = pi * r * r; // C(數據依賴於 A 和 B,不能重排列到前面執行)
指令重排
再舉個多執行緒的例子: 我們在 ChangeThread 執行緒修改變數,在主執行緒觀察變數的值。在弱順序一致性模型下,允許 ChangeThread 執行緒 A 指令的執行結果不及時同步到主執行緒,在主執行緒看來就像沒執行過 A 指令。
這個問題我們一般會理解為記憶體可見性問題,其實我們可以統一理解為順序一致性問題。 主執行緒看不到 ChangeThread 執行緒 A 指令的執行結果,就好像兩個執行緒看到的全局執行順序不一致:ChangeThread 執行緒看到的全局執行順序是:[B],而主執行緒看到的全局執行順序是 []。
可見性示常式序
public class VisibilityTest {
public static void main(String[] args) {
ChangeThread thread = new ChangeThread();
thread.start();
while (true) {
if (thread.flag) { // B
System.out.println("Finished");
return;
}
}
}
public static class ChangeThread extends Thread {
private boolean flag = false;
@Override
public void run() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
flag = true; // A
System.out.println("Change flag = " + flag);
}
}
}
程式輸出
Change flag = true
// 無限等待
前面你說到編譯器和處理器的重排序,為什麼指令可以重排序,為什麼重排序可以提升性能,重排序不會出錯嗎?
3. 什麼是指令重排序?
3.1 重排序類型
從源碼到指令執行一共有 3 種級別重排序:
- 1、編譯器重排序: 例如將循環內重複調用的操作提前到循環外執行;
- 2、處理器系統重排序: 例如指令並行技術將多條指令重疊執行,或者使用分支預測技術提前執行分支的指令,並把計算結果放到重排列緩衝區(Reorder Buffer)的硬體快取中,當程式真的進入分支後直接使用快取中的結算結果;
- 3、存儲器系統重排序: 例如寫緩衝區和失效隊列機制,即是可見性問題,從記憶體的角度也是指令重排問題。
指令重排序類型

3.2 什麼是數據依賴性?
編譯器和處理器在重排序時,會遵循數據依賴性原則,不會試圖改變存在數據依賴關係的指令順序。如果兩個操作都是訪問同一個數據,並且其中一個是寫操作,那麼這兩個操作就存在數據依賴性。此時一旦改變順序,程式最終的執行結果一定會發生改變。
數據依賴性分為 3 種類型::
| 數據依賴性 | 描述 | 示例 |
|---|---|---|
| 寫後讀 | 寫一個數據,再讀這個數據 | a = 1; // 寫 b = a; // 讀 |
| 寫後寫 | 寫一個數據,再寫這個數據 | a = 1; // 寫 a = 2; // 寫 |
| 讀後寫 | 讀一個數據,再寫這個數據 | b = a; // 讀 a = 1; // 寫 |
3.3 指令重排序安全嗎?
需要注意的是:數據依賴性原則只對單個處理器或單個執行緒有效,因此即使在單個執行緒或處理器上遵循數據依賴性原則,在多處理器或者多執行緒中依然有可能改變程式的執行結果。
舉例說明吧。
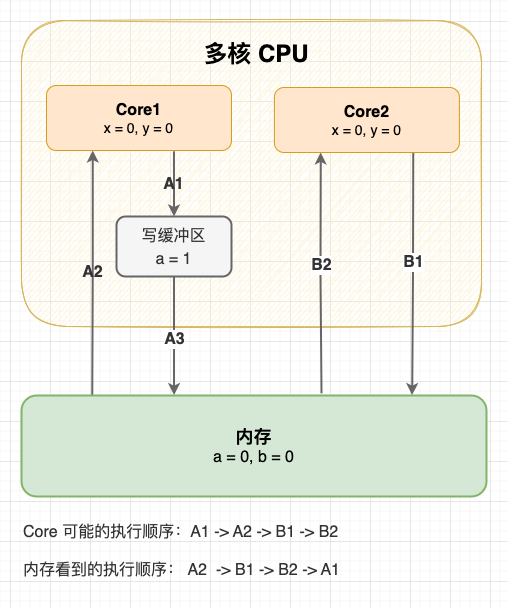
例子 1 – 寫緩衝區和失效隊列的重排序: 如果是在一個處理器上執行 「寫後讀」,處理器不會重排這兩個操作的順序;但如果是在一個處理器上寫,之後在另一個處理器上讀,就有可能重排序。關於寫緩衝區和失效隊列引起的重排序問題,上一篇文章已經解釋過,不再重複。
寫緩衝區造成指令重排
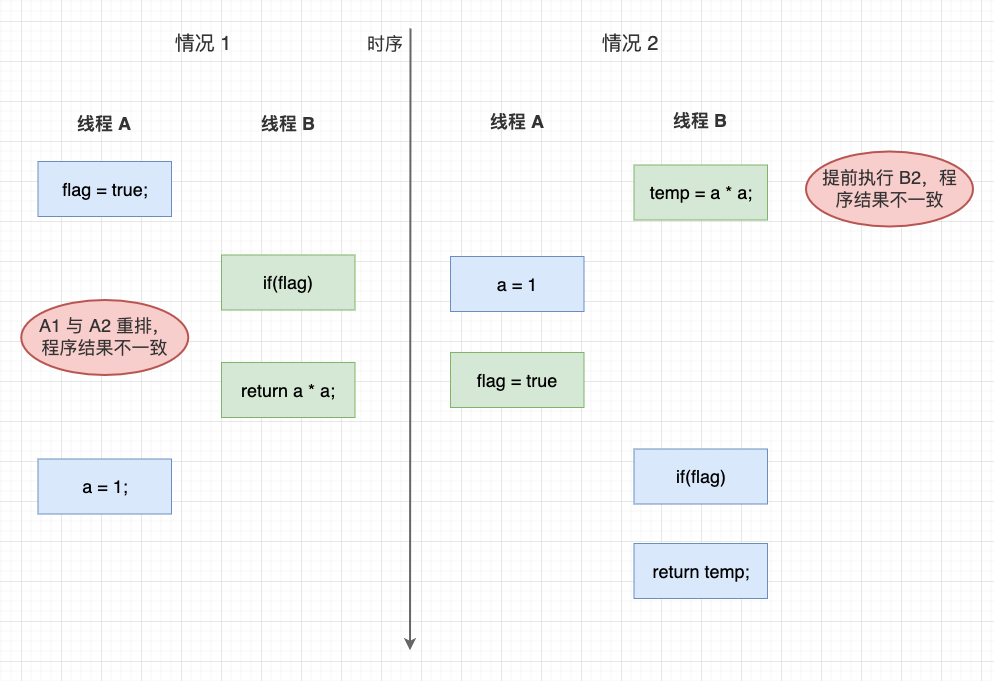
例子 2 – 未同步的多執行緒程式中的指令重排: 在未同步的兩個執行緒 A 和 執行緒 B 上分別執行這兩段程式,程式的預期結果應該是 4,但實際的結果可能是 0。
執行緒 A
a = 2; // A1
flag = true; // A2
執行緒 B
while (flag) { // B1
return a * a; // B2
}
情況 1:由於 A1 和 A2 沒有數據依賴性,所以編譯器或處理器可能會重排序 A1 和 A2 的順序。在 A2 將 flag 改為 true 後,B1 讀取到 flag 條件為真,並且進入分支計算 B2 結果,但 A1 還未寫入,計算結果是 0。此時,程式的運行結果就被重排列破壞了。
情況 2:另一種可能,由於 B1 和 B2 沒有數據依賴性,CPU 可能用分支預測技術提前執行 B2,但 A1 還未寫入,計算結果還是 0。此時,程式的運行結果就被重排列破壞了。
多執行緒的數據依賴性不被考慮
小結一下: 重排序在單執行緒程式下是安全的(與預期一致),但在多執行緒程式下是不安全的。
4. 回答最初的問題
到這裡,雖然我們的討論還未結束,但已經足夠回答標題的問題:「已經有 MESI 協議,為什麼還需要 volatile 關鍵字?」
即使不考慮寫緩衝區或失效隊列,MESI 也只是解決數據一致性問題,並不能解決順序一致性問題。在實際的電腦系統中,為了提高程式的性能,Java 虛擬機和處理器會使用弱順序一致性模型。
在單執行緒程式下,弱順序一致性與強順序一致性的執行結果完全相同。但在多執行緒程式下,重排序問題和可見性問題會導致各個執行緒看到的全局執行順序不一致,使得程式的執行結果與預期不一致。
為了糾正弱順序一致性的影響,編譯器和處理器都提供了 「記憶體屏障指令」 來保證程式關鍵節點的執行順序能夠與程式設計師的預期一致。在高級語言中,我們不會直接使用記憶體屏障,而是使用更高級的語法,即 synchronized、volatile、final、CAS 等語法。
那麼,什麼是記憶體屏障?synchronized、volatile、final、CAS 等語法和記憶體屏障有什麼關聯,這個問題我們在下一篇文章展開討論,請關注。
參考資料
- Java 並發編程的藝術(第 1、2、3 章) —— 方騰飛 魏鵬 程曉明 著
- 深入理解 Android:Java 虛擬機 ART(第 12.4 節) —— 鄧凡平 著
- 深入理解 Java 虛擬機(第 5 部分) —— 周志明 著
- 深入淺出電腦組成原理(第 55 講) —— 徐文浩 著,極客時間 出品
- CPU有快取一致性協議(MESI),為何還需要 volatile —— 一角錢技術 著
- 一文讀懂 Java 記憶體模型(JMM)及 volatile 關鍵字 —— 一角錢技術 著
- MESI protocol —— Wikipedia
- Cache coherence —— Wikipedia
- Sequential consistency —— Wikipedia
- Out-of-order execution —— Wikipedia
- std::memory_order —— cppreference.com


