超精準!AI 結合郵件內容與附件的意圖理解與分類!⛵
- 2022 年 11 月 18 日
- 筆記
- RNN, Transformer, word2vec, 人工智慧, 數據挖掘, 深度學習, 深度學習實戰通關指南 ⛵ 頂級「煉丹師」案例驅動成長之路, 自然語言處理

💡 作者:韓信子@ShowMeAI
📘 深度學習實戰系列://www.showmeai.tech/tutorials/42
📘 TensorFlow 實戰系列://www.showmeai.tech/tutorials/43
📘 本文地址://www.showmeai.tech/article-detail/332
📢 聲明:版權所有,轉載請聯繫平台與作者並註明出處
📢 收藏ShowMeAI查看更多精彩內容

對於很多企業而言,電子郵件仍然是主要溝通渠道之一,很多正式的內容也要基於郵件傳達,供應商、合作夥伴和公共管理部門也每天會有大量的電子郵件。郵件的資訊提取和處理可能是一項耗時且重複的任務,對擁有大量客戶的企業而言尤其是這樣。
💡 場景 & 背景
有一些場景下,如果我們能藉助於AI自動做一些內容和附件等識別,可以極大提高效率,例如以下這些場景:
- 保險公司的客戶索賠管理。
- 電信和公用事業企業客戶投訴處理。
- 銀行處理各種與抵押貸款相關的請求。
- 旅遊行業公司的預訂相關電子郵件。
如果我們希望盡量智慧與自動化地進行電子郵件處理,我們需要完成以下任務:
- 電子郵件分流。我們希望智慧理解郵件,並將其轉到相應的專門業務部門進行處理。在AI的視角我們可以通過電子郵件的意圖分類來嘗試解決這個問題。
- 資訊提取。根據確定的意圖,提取一些資訊給到下游流程,例如在CRM系統中記錄客戶案例進行跟蹤。
在本篇文章中,ShowMeAI 將專註於意圖檢測部分,我們將一起看一看如何設計一個AI系統來解決這個任務。
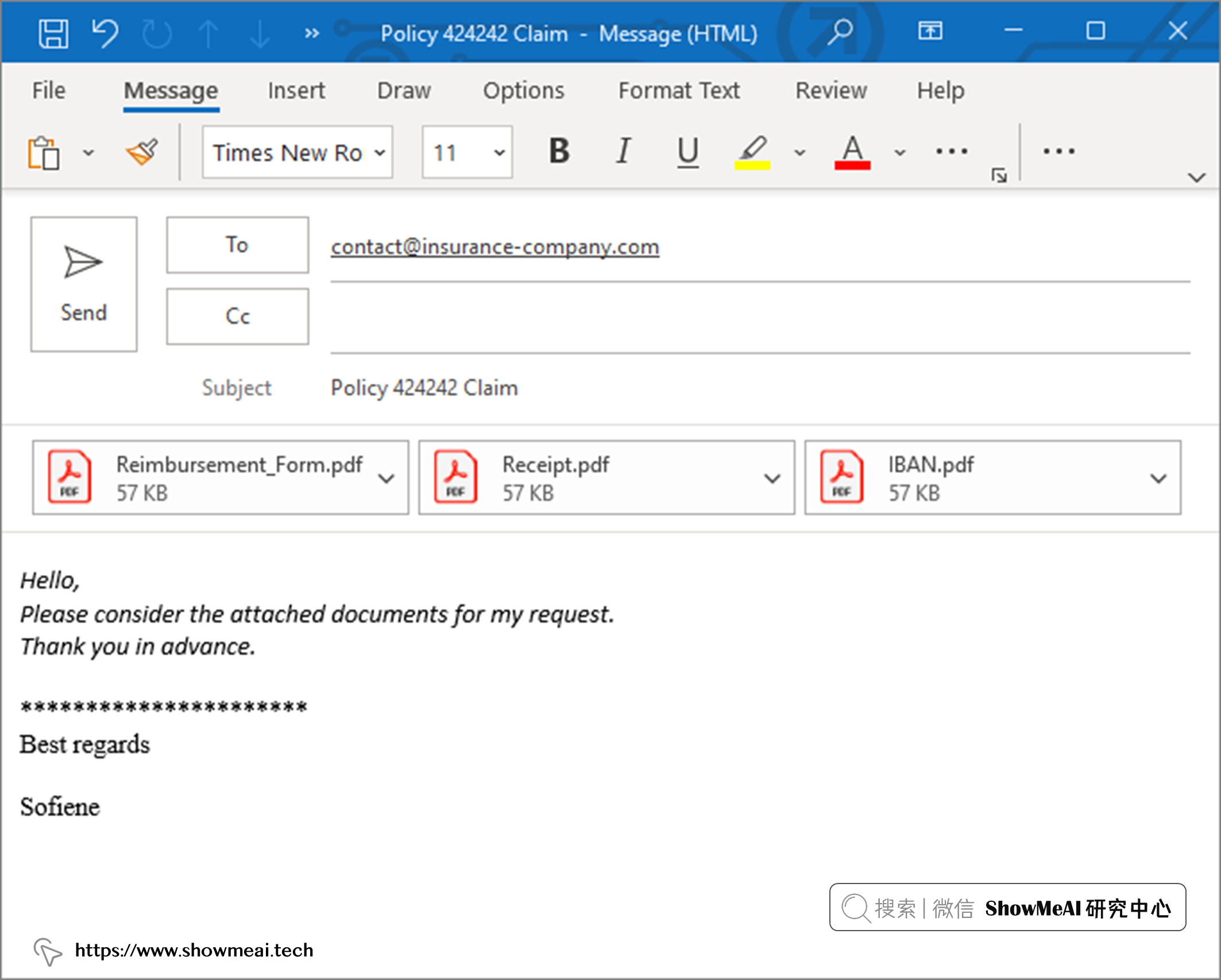
💦 場景 1
假設一家保險公司客戶,想申請理賠與報銷。 這個場景下他會填寫保險報銷表,並將其連同藥物收據和銀行 ID 文件附在電子郵件中。可能的一個電子郵件可能長這樣:
💦 場景 2
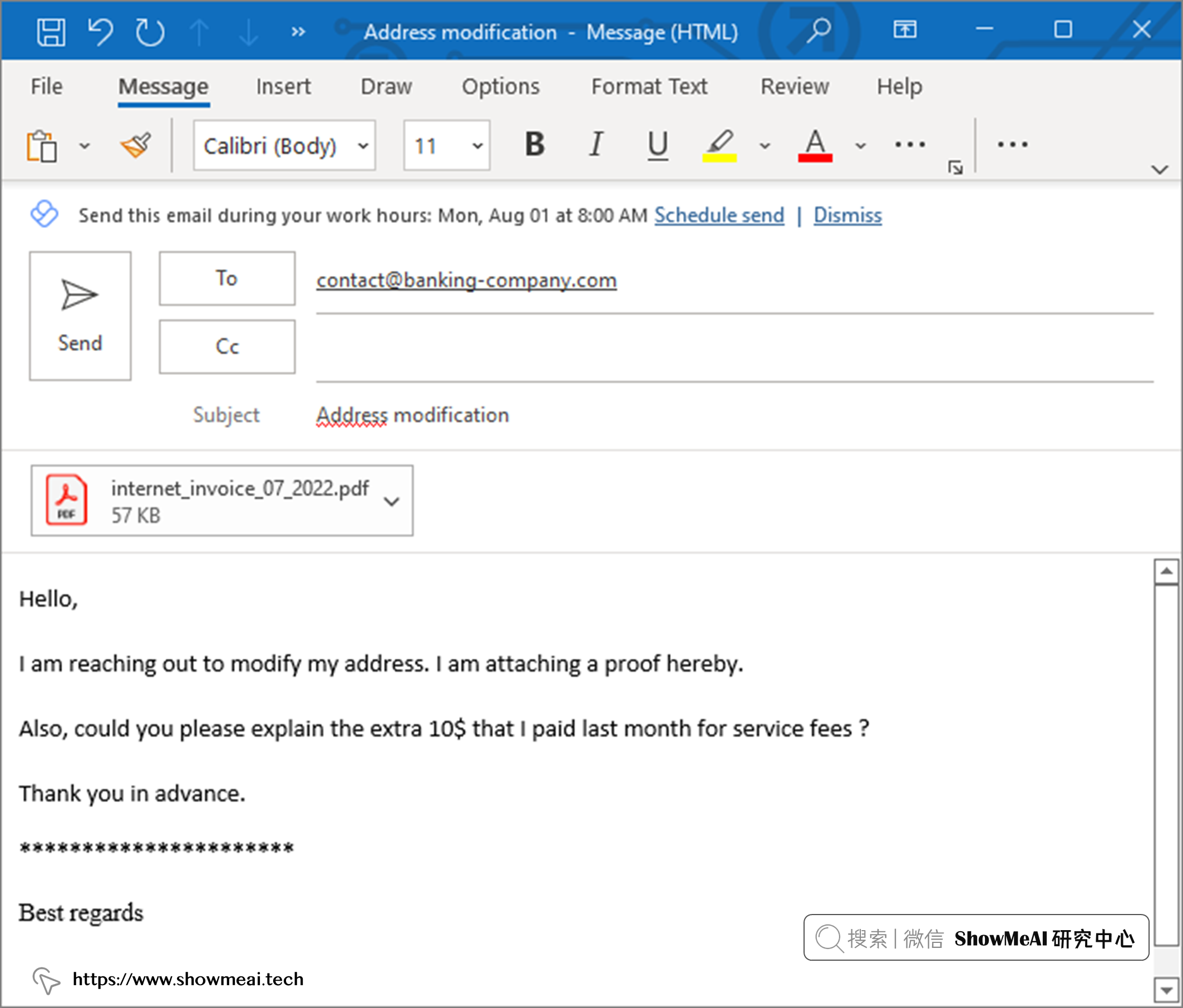
假設一家銀行的客戶,搬家並對之前的某項服務費有疑問。 如果選擇發送電子郵件來進行申請和處理,郵件可能長這樣:
💡 實現方案

本文會涉及到NLP相關知識,有興趣更系統全面了NLP知識的寶寶,建議閱讀ShowMeAI 整理的自然語言處理相關教程和文章
📘深度學習教程:吳恩達專項課程 · 全套筆記解讀
📘深度學習教程 | 自然語言處理與詞嵌入
📘NLP教程 | 斯坦福CS224n · 課程帶學與全套筆記解讀
📘NLP教程(1) – 詞向量、SVD分解與Word2Vec
📘NLP教程(2) – GloVe及詞向量的訓練與評估
💦 架構初覽
我們前面提到了,在意圖識別場景中,我們經常會視作『多分類問題』來處理,但在我們當前場景下,有可能郵件覆蓋多個意圖目的,或者本身意圖之間有重疊,因此我們先將其視為多標籤分類問題。
然而,在許多現實生活場景中,多標籤分類系統可能會遇到一些問題:
-
電子郵件在大多數情況下是關於一個主要意圖,有時它們具有次要意圖,在極少數情況下還有第三個意圖。
-
很難找到涵蓋所有多標籤組合的標籤數據。
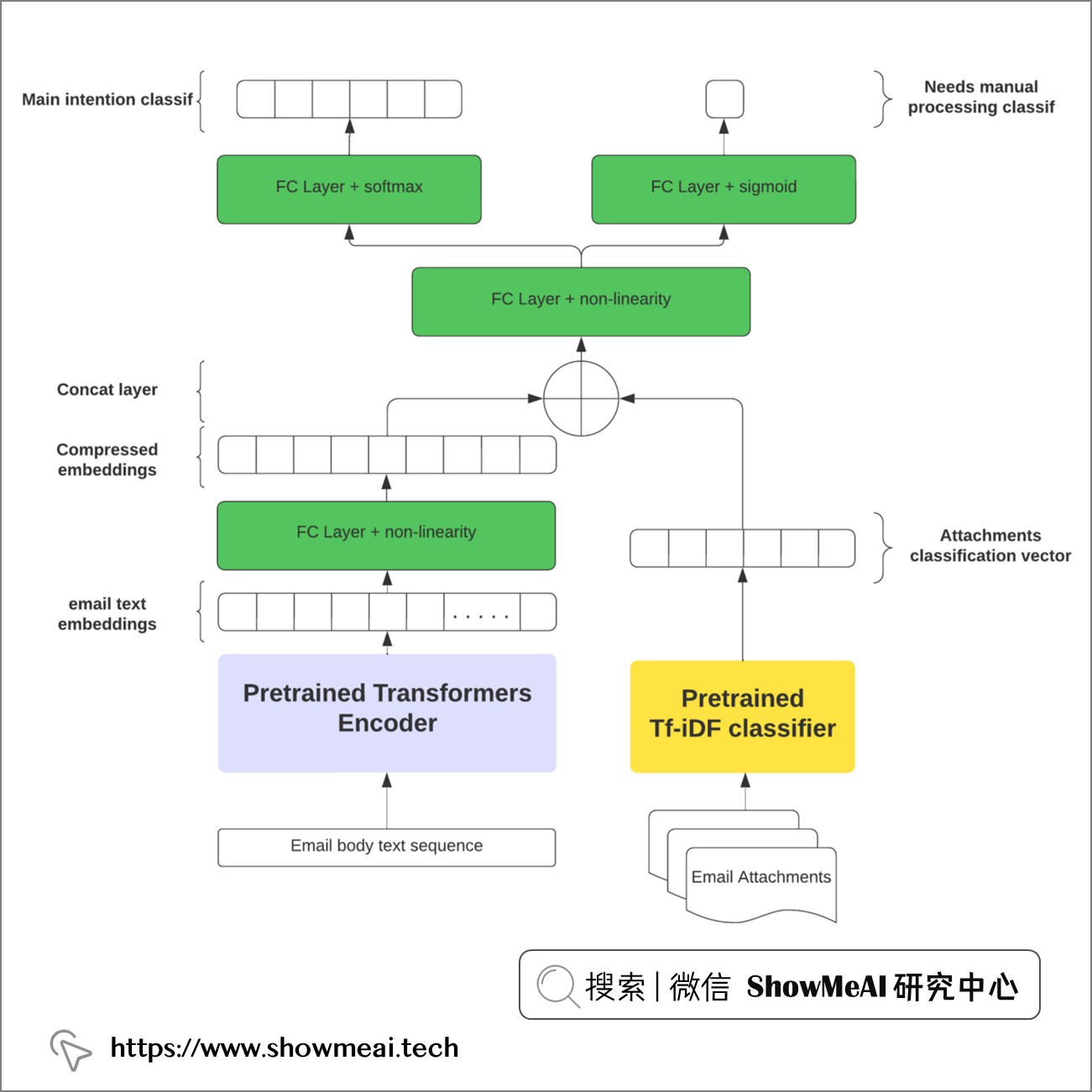
我們可以試著構建一個融合方案來解決,可以預測主要意圖並檢測剩餘的次要意圖和第三意圖,我們可以設計多輸出神經網路網路來實現這一點,如下圖所示。
我們涉及到2類輸入:電子郵件正文 和 附件,在深度學習場景下,我們都需要對它們做向量化標準。如下圖的架構是一個可行的嘗試方案:我們用transformer類的模型對正文進行編碼和向量化標註,而對於附件,可以用相對簡單的NLP編碼器,比如TF-IDF。
💦 實現細節
① 電子郵件正文:AI理解&處理
整個方案中最重要的輸入是正文數據,我們在深度學習中,需要把非結構化的數據表徵為向量化形式,方便模型進行資訊融合和建模,在自然語言處理NLP領域,我們也有一些典型的向量化嵌入技術可以進行對文本處理。
最『簡單』的處理方法之一是使用 📘TF-iDF + 📘PCA。
對於文本(詞與句)嵌入更現代一些的 NLP 方法,例如 Word2Vec 和 📘Doc2Vec ,它們分別使用淺層神經網路來學習單詞和文本嵌入。大家可以使用 gensim 工具庫或者 fasttext 工具庫完成文本嵌入,也有很多預訓練的詞嵌入和文本嵌入的模型可以使用。

關於 TF-IDF 和 DocVec 的詳細知識,可以查看ShowMeAI 的文章 📘基於NLP文檔嵌入技術的基礎文本搜索引擎構建。

現在最先進的技術是基於 transformer 的預訓練語言模型(例如 📘BERT)來構建『上下文感知』文本嵌入。我們上面的方案中也是使用最先進的深度學習方法——直接使用 📘HuggingFace的 📘預訓練模型 和 📘API 來構建正文文本嵌入。
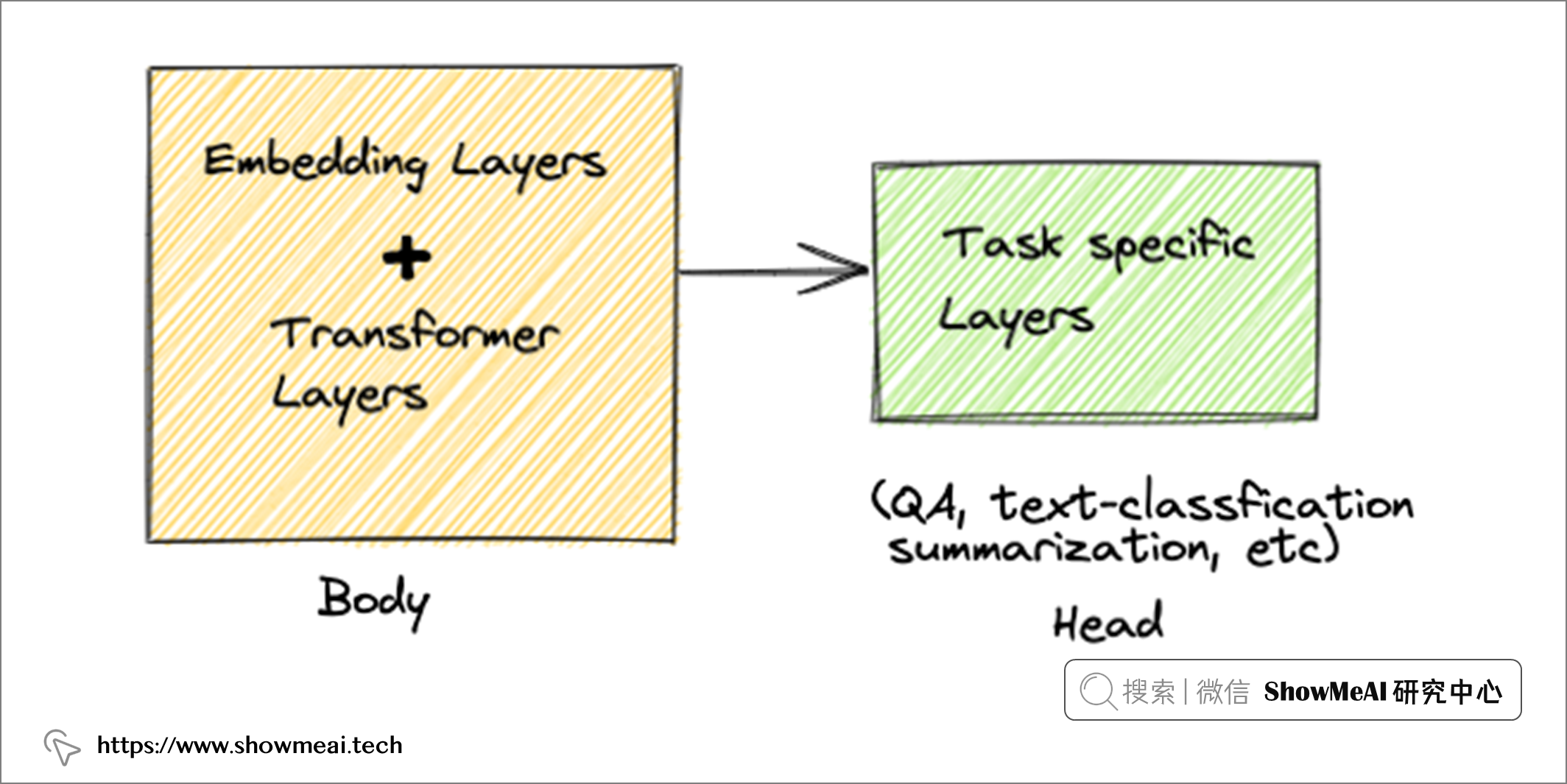
transformer 系列的模型有很多隱層,我們可以有很多方式獲取文本的向量化表徵,比如對最後的隱層做『平均池化』獲得文本嵌入,我們也可以用倒數第二層或倒數第三層(它們在理論上較少依賴於訓練語言模型的文本語料庫)。
對文本做嵌入表示的示例程式碼如下:
# 大家可以先命令行執行下列程式碼安裝sentence-transformers
# pip install -U sentence-transformers
from sentence_transformers import SentenceTransformer
# 需要編碼的文本內容列表
sentences = ["This is example sentence 1", "This is example sentence 2"]
# 編碼,文本向量化嵌入表徵
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
embeddings = model.encode(sentences)
print(embeddings)
② 電子郵件附件:AI理解&處理
我們在這個解決方案中,單獨把郵件附件拿出來做處理了。在有些處理方式中,會把附件的內容和正文直接拼接,用上面介紹的方式進行編碼,但這樣處理不夠精細,可能有如下問題而導致最後模型效果不佳:
-
附件文本可能非常大,包含許多多餘的內容,這些內容可能會淹沒電子郵件正文中更重要的微妙細節。
-
對於意圖檢測而言,重要的是文檔的性質或類型,而不是詳細的內容。
基於上述考慮,我們單獨訓練附件分類器來生成附件的密集向量表示。可能我們的附件包含不規則的 PDF 或者圖片,我們可能要考慮用 OCR 引擎(例如 Tesseract)進行識別和提取部分內容,
假設我們的附件數量為N,DC 是經過訓練的附件分類器。DC對每個附件預測處理輸出一個向量(文檔類型分布概率向量)。 由於最終的附件向量表示需要具有固定長度(但是N是不確定的),我們在附件維度上使用最大池化得到統一長度的表徵。
以下是為給定電子郵件生成附件向量化表徵的程式碼示例:
# DC是文檔分類器
distributions = []
for attachment in attachments:
current_distribution = DC(attachent)
distributions.append(current_distribution)
np_distributions = np.array(distributions) #維度為(X,N)的附件向量組
attachments_feat_vec = np.max(np_distributions, axis=0) #最大池化
③ 搭建多數據源混合網路
下面部分使用到了TensorFlow工具庫,ShowMeAI 製作了快捷即查即用的工具速查表手冊,大家可以在下述位置獲取:
在上述核心輸入處理和表徵後,我們就可以使用 Tensorflow 構建一個多分支神經網路了。參考程式碼如下:
def build_hybrid_mo_model(bert_input_size, att_features_size, nb_classes):
emb_input = tf.keras.Input(shape=(bert_input_size,), name="text_embeddings_input")
att_classif_input = tf.keras.Input(shape=(att_features_size,), name="attachments_repr_input")
DenseEmb1 = tf.keras.layers.Dense(units=256, activation='relu')(emb_input)
compressed_embs = tf.keras.layers.Dense(units=32, activation='relu', name="compression_layer")(DenseEmb1)
combined_features = tf.keras.layers.concatenate([compressed_embs,att_classif_input], axis=1)
Dense1= tf.keras.layers.Dense(units=128)(combined_features)
Dense2= tf.keras.layers.Dense(units=128)(Dense1)
out1 = tf.keras.layers.Dense(units=nb_classes, name="intention_category_output")(Dense2)
out2 = tf.keras.layers.Dense(units=1, name="information_request_output")(Dense2)
model = tf.keras.Model(inputs=[emb_input,att_classif_input], outputs=[out1, out2])
losses = {
"intention_category_output" : tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
"information_request_output" : tf.keras.losses.BinaryCrossentropy(from_logits=True)}
model.compile(optimizer="adam",loss= losses, metrics=["accuracy"])
print (model.summary())
return model
構建完模型之後,可以通過tf.keras.utils.plot_model列印出模型架構,如下圖所示:
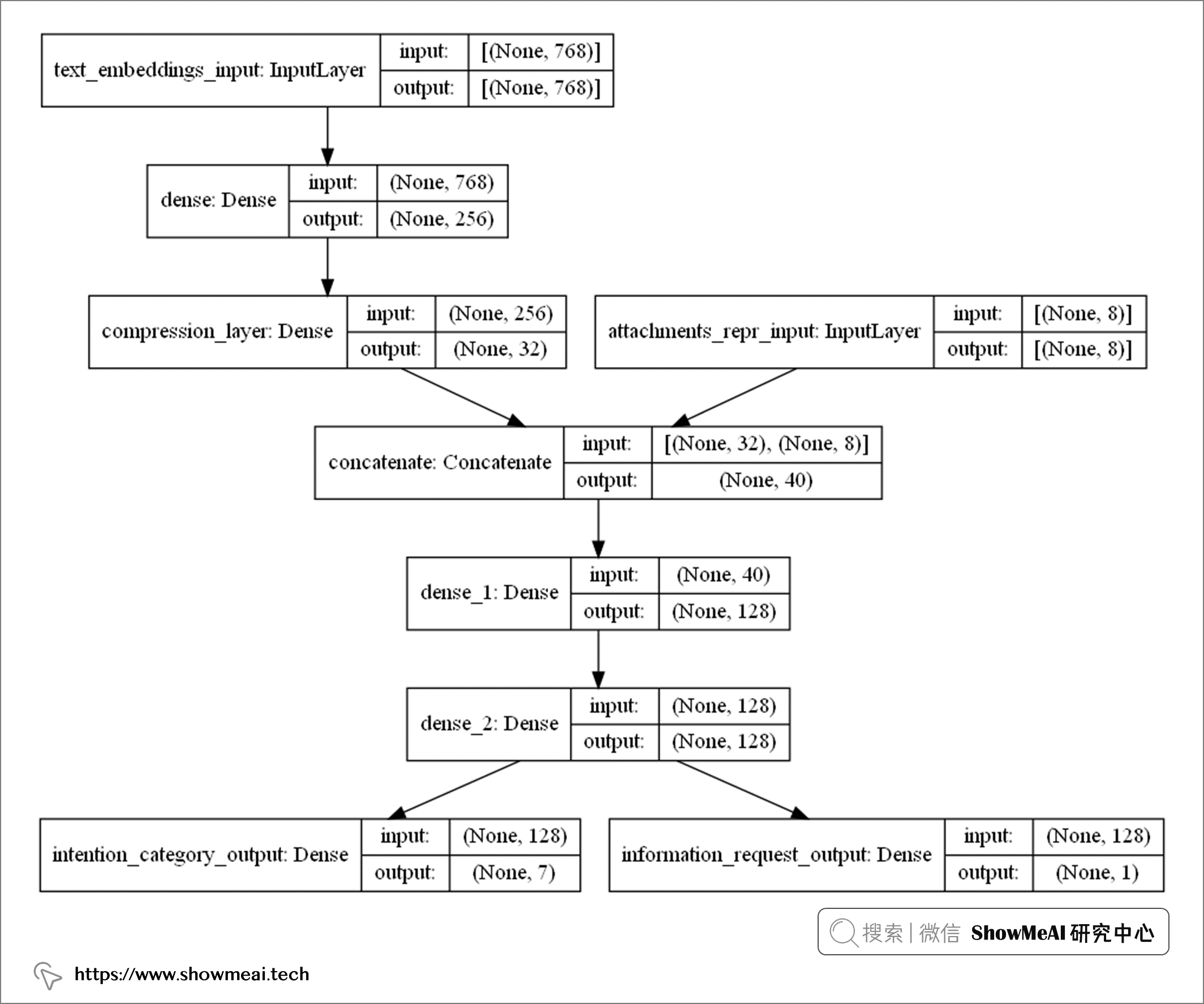
上圖的模型架構,和我們在『架構初覽』板塊的設計完全一致,它包含更多的細節資訊:
- 電子郵件正文文本嵌入,維度為768維
- 附件文件包含8種類型,向量化表徵為8維
模型的輸出部分包含:
- 7個主要意圖
- 1個次要意圖
④ 訓練&評估
作為測試,作者在銀行業務相關電子郵件的專有數據集上訓練了模型,具體情況如下:
- 數據集由 1100 封電子郵件組成,包含 7 個主要意圖,但分布不均。
- 構建的神經網路包含 22.7w 個參數( 具體細節如上圖,大家也可以通過model.summary()輸出模型資訊)。
- 以batch size大小為32訓練了 50 個 epoch
- 實際沒有使用到GPU,在16核的CPU上做的訓練(但大家使用GPU一定有更快的速度)
- 主要意圖分類任務上達到了 87% 的加權 F1 分數平均值。如果不使用附件,加權 F1 分數平均值降低10%。(可見2部分資訊都非常重要)
💡 總結
我們通過對電子郵件自動意圖識別和歸類場景進行分析和處理,構建了有效的混合網路高效地完成了這個任務。這裡面非常值得思考的點,是不同類型的數據輸入與預處理,合適的技術選型(並非越複雜越好),充分又恰當的輸入資訊融合方式。
大家在類似的場景問題下,還可以嘗試不同的正文預處理和附件分類模型,觀察效果變化。其餘的一些改進點包括,對於預估不那麼肯定(概率偏低)的郵件樣本,推送人工審核分類,會有更好的效果。
參考資料
- 📘 AI實戰 | 基於NLP文檔嵌入技術的基礎文本搜索引擎構建://showmeai.tech/article-detail/321
- 📘 TensorFlow 速查手冊://www.showmeai.tech/article-detail/109
- 📘 深度學習教程:吳恩達專項課程 · 全套筆記解讀://www.showmeai.tech/tutorials/35
- 📘 深度學習教程 | 自然語言處理與詞嵌入://www.showmeai.tech/article-detail/226
- 📘 NLP教程 | 斯坦福CS224n · 課程帶學與全套筆記解讀://www.showmeai.tech/tutorials/36
- 📘 NLP教程(1) – 詞向量、SVD分解與Word2Vec://www.showmeai.tech/article-detail/230
- 📘 NLP教程(2) – GloVe及詞向量的訓練與評估://www.showmeai.tech/article-detail/232
- 📘 TF-iDF://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html
- 📘 PCA://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html
- 📘 Doc2Vec://radimrehurek.com/gensim/models/doc2vec.html
- 📘 BERT:[//huggingface.co/docs/transformers/model_doc/bert](//huggingface.co/docs/transformers/model_doc/bert)
- 📘 HuggingFace://huggingface.co/