我把 CPU 三級快取的秘密,藏在這 8 張圖裡
本文已收錄到 GitHub · AndroidFamily,有 Android 進階知識體系,歡迎 Star。技術和職場問題,請關注公眾號 [彭旭銳] 進 Android 面試交流群。
前言
大家好,我是小彭。
在上一篇文章里,我們聊到了電腦存儲器系統的金字塔結構,其中在 CPU 和記憶體之間有一層高速快取,就是我們今天要聊的 CPU 三級快取。
那麼,CPU Cache 的結構是怎樣的,背後隱含著哪些設計思想,CPU Cache 和記憶體數據是如何關聯起來的,今天我們將圍繞這些問題展開。
學習路線圖:
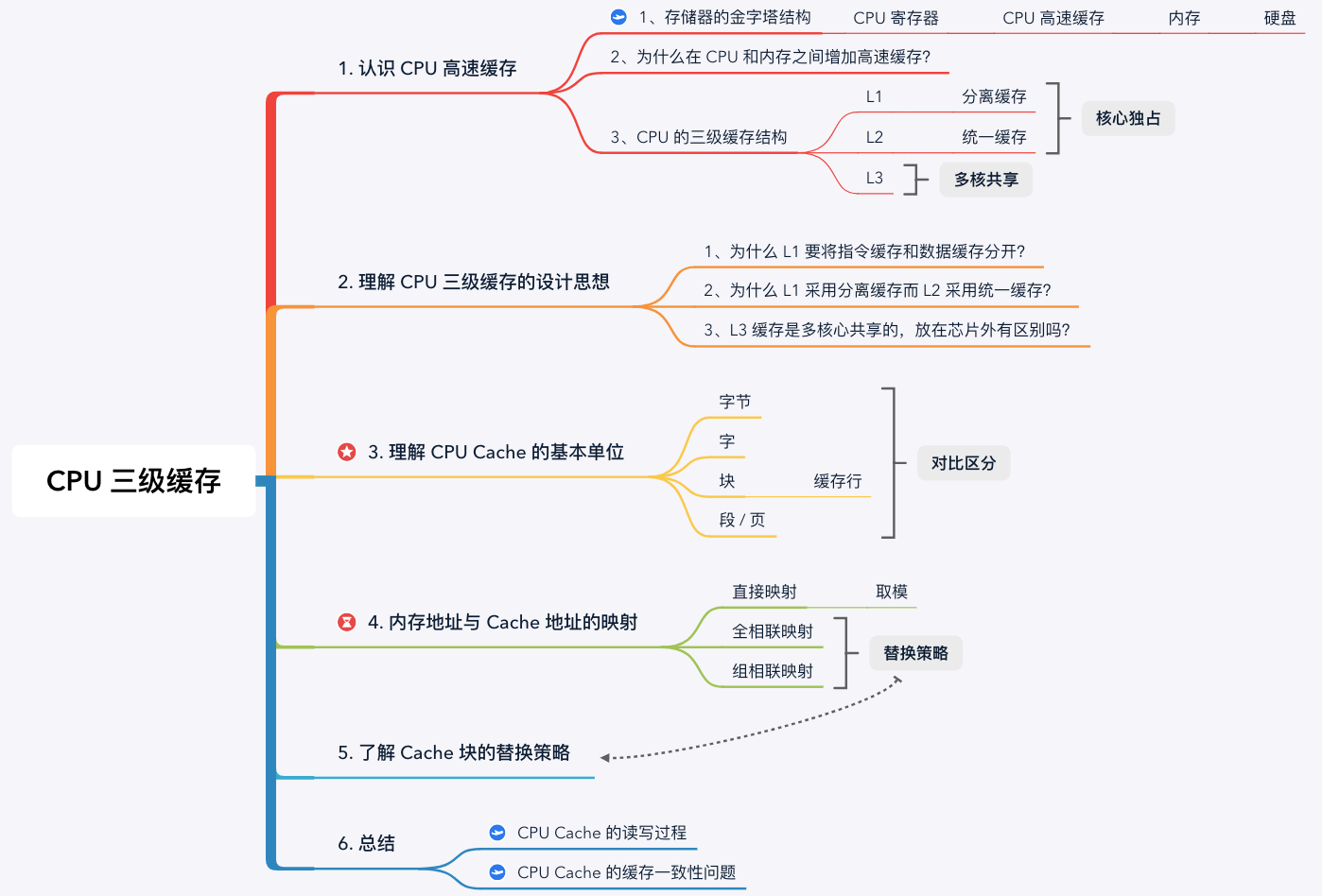
1. 認識 CPU 高速快取
1.1 存儲器的金字塔結構
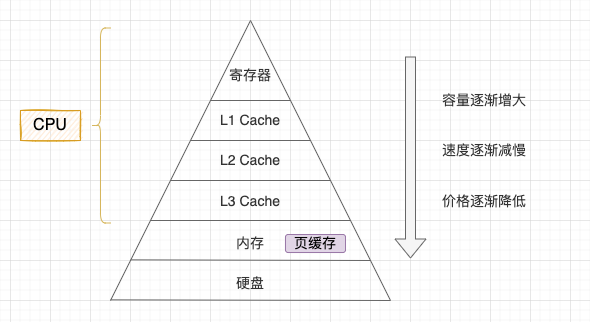
現代電腦系統為了尋求容量、速度和價格最大的性價比會採用分層架構,從 「CPU 暫存器 – CPU 高速快取 – 記憶體 – 硬碟」自上而下容量逐漸增大,速度逐漸減慢,單位價格也逐漸降低。
- 1、CPU 暫存器: 存儲 CPU 正在使用的數據或指令;
- 2、CPU 高速快取: 存儲 CPU 近期要用到的數據和指令;
- 3、記憶體: 存儲正在運行或者將要運行的程式和數據;
- 4、硬碟: 存儲暫時不使用或者不能直接使用的程式和數據。
存儲器金字塔
1.2 為什麼在 CPU 和記憶體之間增加高速快取?
我認為有 2 個原因:
-
原因 1 – 彌補 CPU 和記憶體的速度差(主要): 由於 CPU 和記憶體的速度差距太大,為了拉平兩者的速度差,現代電腦會在兩者之間插入一塊速度比記憶體更快的高速快取。只要將近期 CPU 要用的資訊調入快取,CPU 便可以直接從快取中獲取資訊,從而提高訪問速度;
-
原因 2 – 減少 CPU 與 I/O 設備爭搶訪存: 由於 CPU 和 I/O 設備會競爭同一條記憶體匯流排,有可能出現 CPU 等待 I/O 設備訪存的情況。而如果 CPU 能直接從快取中獲取數據,就可以減少競爭,提高 CPU 的效率。
1.3 CPU 的三級快取結構
在 CPU Cache 的概念剛出現時,CPU 和記憶體之間只有一個快取,隨著晶片集成密度的提高,現代的 CPU Cache 已經普遍採用 L1/L2/L3 多級快取的結構來改善性能。自頂向下容量逐漸增大,訪問速度也逐漸降低。當快取未命中時,快取系統會向更底層的層次搜索。
- L1 Cache: 在 CPU 核心內部,分為指令快取和數據快取,分開存放 CPU 使用的指令和數據;
- L2 Cache: 在 CPU 核心內部,尺寸比 L1 更大;
- L3 Cache: 在 CPU 核心外部,所有 CPU 核心共享同一個 L3 快取。
CPU 三級快取

2. 理解 CPU 三級快取的設計思想
2.1 為什麼 L1 要將指令快取和數據快取分開?
這個策略叫分離快取,與之相對應的叫統一快取:
- 分離快取: 指令和數據分別存放在不同快取中:
- 指令快取(Instruction Cache,I-Cache)
- 數據快取(Data Cache,D-Cache)
- 統一快取: 指令和數據統一存放在一個快取中。
那麼,為什麼 L1 快取要把指令和數據分開呢?我認為有 2 個原因:
-
原因 1 – 避免取指令單元和取數據單元爭奪訪快取(主要): 在 CPU 內核中,取指令和取數據指令是由兩個不同的單元完成的。如果使用統一快取,當 CPU 使用超前控制或流水線控制(並行執行)的控制方式時,會存在取指令操作和取數據操作同時爭用同一個快取的情況,降低 CPU 運行效率;
-
原因 2 – 記憶體中數據和指令是相對聚簇的,分離快取能提高命中率: 在現代電腦系統中,記憶體中的指令和數據並不是隨機分布的,而是相對聚集地分開存儲的。因此,CPU Cache 中也採用分離快取的策略更符合記憶體數據的現狀;
2.2 為什麼 L1 採用分離快取而 L2 採用統一快取?
我認為原因有 2 個:
-
原因 1: L1 採用分離快取後已經解決了取指令單元和取數據單元的爭奪訪快取問題,所以 L2 是否使用分離快取沒有影響;
-
原因 2: 當快取容量較大時,分離快取無法動態調節分離比例,不能最大化發揮快取容量的利用率。例如數據快取滿了,但是指令快取還有空閑,而 L2 使用統一快取則能夠保證最大化利用快取空間。
2.3 L3 快取是多核心共享的,放在晶片外有區別嗎?
集成在晶片內部的快取稱為片內快取,集成在晶片外部(主板)的快取稱為片外快取。最初,由於受到晶片集成製程的限制,片內快取不可能很大,因此 L2 / L3 快取都是設計在主板上,而不是在晶片內的。
後來,L2 / L3 才逐漸集成到 CPU 晶片內部後的。片內緩衝和片外快取是有區別的,主要體現在 2 個方面:
-
區別 1 – 片內快取物理距離更短: 片內快取與取指令單元和取數據單元的物理距離更短,速度更快;
-
區別 2 – 片內快取不佔用系統匯流排: 片內快取使用獨立的 CPU 片內匯流排,可以減輕系統匯流排的負擔。
3. CPU Cache 的基本單位 —— Cache Line
CPU Cache 在讀取記憶體數據時,每次不會只讀一個字或一個位元組,而是一塊塊地讀取,這每一小塊數據也叫 CPU 快取行(CPU Cache Line)。這也是對局部性原理的應用,當一個指令或數據被訪問過之後,與它相鄰地址的數據有很大概率也會被訪問,將更多可能被訪問的數據存入快取,可以提高快取命中率。
當然,塊長也不是越大越好(一般是取 4 到 8 個字長,即 64 位):
- 前期:當塊長由小到大增長時,隨著局部性原理的影響使得命中率逐漸提高;
- 後期:但隨著塊長繼續增大,導致快取中承載的塊個數減少,很可能記憶體塊剛剛裝入快取就被新的記憶體塊覆蓋,命中率反而下降。而且,塊長越長,追加的部分距離被訪問的字越遠,近期被訪問的可能性也更低,無濟於事。
區分幾種容量單位:
- 位元組(Byte): 位元組是電腦數據存儲的基本單位,即使存儲 1 個位也需要按 1 個位元組存儲;
- 字(Word): 字長是 CPU 在單位時間內能夠同時處理的二進位數據位數。多少位 CPU 就是指 CPU 的字長是多少位(比如 64 位 CPU 的字長就是 64 位);
- 塊(Block): 塊是 CPU Cache 管理數據的基本單位,也叫 CPU 快取行;
- 段(Segmentation)/ 頁(Page): 段 / 頁是作業系統管理虛擬記憶體的基本單位。
事實上,CPU 在訪問記憶體數據的時候,與電腦中對於 「快取設計」 的一般性規律是相同的: 對於基於 Cache 的系統,對數據的讀取和寫入總會先訪問 Cache,檢查要訪問的數據是否在 Cache 中。如果命中則直接使用 Cache 上的數據,否則先將底層的數據源載入到 Cache 中,再從 Cache 讀取數據。
那麼,CPU 怎麼知道要訪問的記憶體數據是否在 CPU Cache 中,在 CPU 中的哪個位置,以及是不是有效的呢?這就是下一節要講的記憶體地址與 Cache 地址的映射問題。
4. 記憶體地址與 Cache 地址的映射
無論對 Cache 數據檢查、讀取還是寫入,CPU 都需要知道訪問的記憶體數據對應於 Cache 上的哪個位置,這就是記憶體地址與 Cache 地址的映射問題。
事實上,因為記憶體塊和快取塊的大小是相同的,所以在映射的過程中,我們只需要考慮 「記憶體塊索引 – 快取塊索引」 之間的映射關係,而具體訪問的是塊內的哪一個字,則使用相同的偏移在塊中尋找。舉個例子:假設記憶體有 32 個記憶體塊,CPU Cache 有 8 個快取塊,我們只需要考慮 紫色 部分標識的索引如何匹配即可。
目前,主要有 3 種映射方案:
- 1、直接映射(Direct Mapped Cache): 固定的映射關係;
- 2、全相聯映射(Fully Associative Cache): 靈活的映射關係;
- 3、組相聯映射(N-way Set Associative Cache): 前兩種方案的折中方法。
記憶體塊索引 - 快取塊索

4.1 直接映射
直接映射是三種方式中最簡單的映射方式,直接映射的策略是: 在記憶體塊和快取塊之間建立起固定的映射關係,一個記憶體塊總是映射到同一個快取塊上。
具體方式:
-
1、將記憶體塊索引對 Cache 塊個數取模,得到固定的映射位置。例如 13 號記憶體塊映射的位置就是 13 % 8 = 5,對應 5 號 Cache 塊;
-
2、由於取模後多個記憶體塊會映射到同一個快取塊上,產生塊衝突,所以需要在 Cache 塊上增加一個 組標記(TAG),標記當前快取塊存儲的是哪一個記憶體塊的數據。其實,組標記就是記憶體塊索引的高位,而 Cache 塊索引就是記憶體塊索引的低 4 位(8 個字塊需要 4 位);
-
3、由於初始狀態 Cache 塊中的數據是空的,也是無效的。為了標識 Cache 塊中的數據是否已經從記憶體中讀取,需要在 Cache 塊上增加一個 有效位(Valid bit) 。如果有效位為 0,則 CPU 可以直接讀取 Cache 塊上的內容,否則需要先從記憶體讀取記憶體塊填入 Cache 塊,再將有效位改為 1。
直接映射

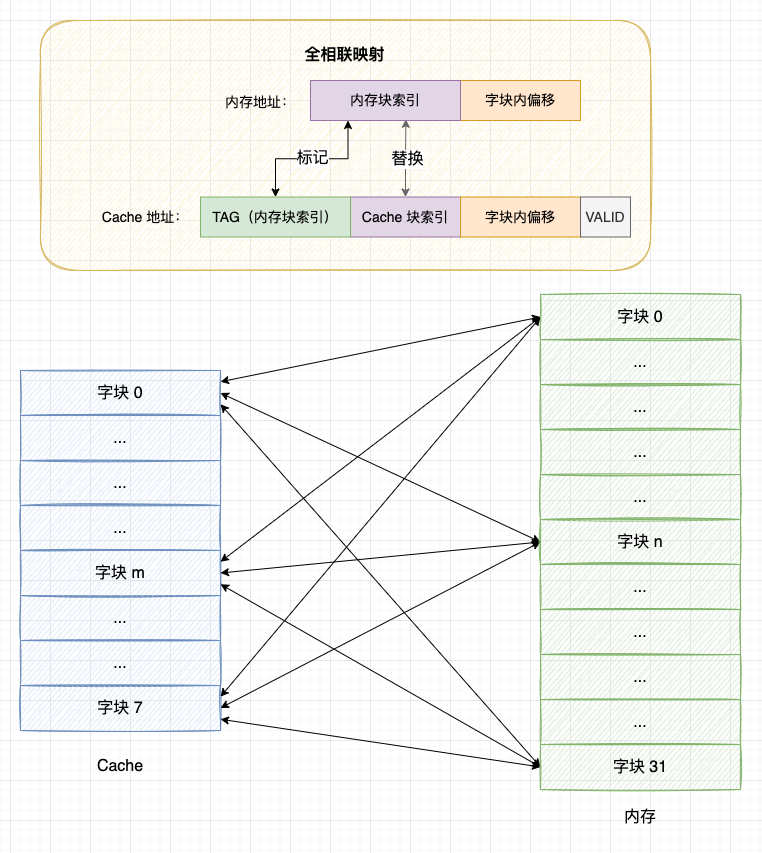
4.2 全相聯映射
理解了直接映射的方式後,我們發現直接映射存在 2 個問題:
- 問題 1 – 快取利用不充分: 每個記憶體塊只能映射到固定的位置上,即使 Cache 上有空閑位置也不會使用;
- 問題 2 – 塊衝突率高: 直接映射會頻繁出現塊衝突,影響快取命中率。
基於直接映射的缺點,全相聯映射的策略是: 允許記憶體塊映射到任何一個 Cache 塊上。 這種方式能夠充分利用 Cache 的空間,塊衝突率也更低,但是所需要的電路結構物更複雜,成本更高。
具體方式:
- 1、當 Cache 塊上有空閑位置時,使用空閑位置;
- 2、當 Cache 被佔滿時則替換出一個舊的塊騰出空閑位置;
- 3、由於一個 Cache 塊會映射所有記憶體塊,因此組標記 TAG 需要擴大到與主記憶體塊索引相同的位數,而且映射的過程需要沿著 Cache 從頭到尾匹配 Cache 塊的 TAG 標記。
全相聯映射
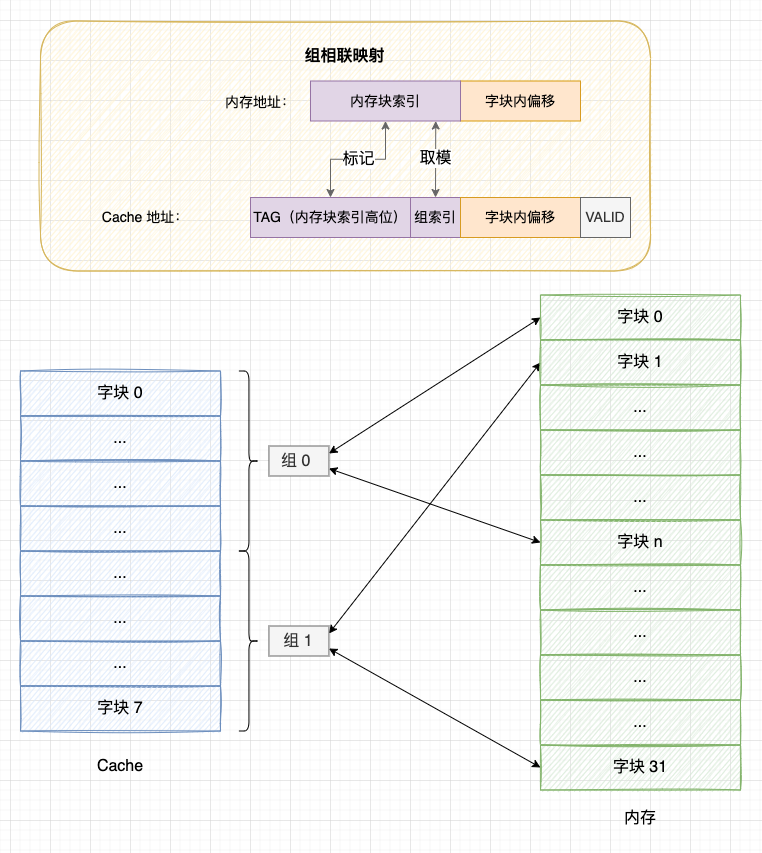
4.3 組相聯映射
組相聯映射是直接映射和全相聯映射的折中方案,組相聯映射的策略是: 將 Cache 分為多組,每個記憶體塊固定映射到一個分組中,又允許映射到組內的任意 Cache 塊。顯然,組相聯的分組為 1 時就等於全相聯映射,而分組等於 Cache 塊個數時就等於直接映射。
組相聯映射
5. Cache 塊的替換策略
在使用直接映射的 Cache 中,由於每個主記憶體塊都與某個 Cache 塊有直接映射關係,因此不存在替換策略。而使用全相聯映射或組相聯映射的 Cache 中,主記憶體塊與 Cache 塊沒有固定的映射關係,當新的記憶體塊需要載入到 Cache 中時(且 Cache 塊沒有空閑位置),則需要替換到 Cache 塊上的數據。此時就存在替換策略的問題。
常見替換策略:
-
1、隨機法: 使用一個隨機數生成器隨機地選擇要被替換的 Cache 塊,實現簡單,缺點是沒有利用 「局部性原理」,無法提高快取命中率;
-
2、FIFO 先進先出法: 記錄各個 Cache 塊的載入事件,最早調入的塊最先被替換,缺點同樣是沒有利用 「局部性原理」,無法提高快取命中率;
-
3、LRU 最近最少使用法: 記錄各個 Cache 塊的使用情況,最近最少使用的塊最先被替換。這種方法相對比較複雜,也有類似的簡化方法,即記錄各個塊最近一次使用時間,最久未訪問的最先被替換。與前 2 種策略相比,LRU 策略利用了 「局部性原理」,平均快取命中率更高。
6. 總結
-
1、為了彌補 CPU 和記憶體的速度差和減少 CPU 與 I/O 設備爭搶訪存,電腦在 CPU 和記憶體之間增加高速快取,一般存在 L1/L2/L3 多級快取的結構;
-
2、對於基於 Cache 的存儲系統,對數據的讀取和寫入總會先訪問 Cache,檢查要訪問的數據是否在 Cache 中。如果命中則直接使用 Cache 上的數據,否則先將底層的數據源載入到 Cache 中,再從 Cache 讀取數據;
-
3、CPU Cache 是一塊塊地從記憶體讀取數據,一塊數據就是快取行;
-
4、記憶體地址與 Cache 地址的映射有直接映射、全相聯映射和組相聯映射;
-
5、使用全相聯映射或組相聯映射的 Cache 中,當新的記憶體塊需要載入到 Cache 中時且 Cache 塊沒有空閑位置,則需要替換到 Cache 塊上的數據。
今天,我們主要討論了 CPU Cache 的基本設計思想以及 Cache 與記憶體的映射關係。具體 CPU Cache 是如何讀取和寫入的還沒講,另外有一個 CPU 快取一致性問題 說的又是什麼呢?下一篇文章我們詳細展開討論,請關注。
參考資料
- 深入淺出電腦組成原理(第 37、38 講) —— 徐文浩 著,極客時間 出品
- 電腦組成原理教程(第 7 章) —— 尹艷輝 王海文 邢軍 著
- 面試官:如何寫出讓 CPU 跑得更快的程式碼? —— 小林 Coding 著
- CPU cache —— Wikipedia
- CPU caches —— LWN.net


