嗨! Apriori演算法
- 2020 年 3 月 4 日
- 筆記
Association Rule
一:項集和規則
1.1 認識名詞:
- Association Rule : 關聯規則
- Frequent Itemsets : 頻繁項集
- Sequential Patterns: 模式序列
我們在網上購物的時候,經常會遇到這樣的推送, 比如買了A書的人, 同時購買了B書的情景, 在這個描述中: 包含如下的資訊:
- A書B書經常同時被購買: 頻繁項集
- 買了A書的人,經常會去購買B書: 關聯規則
1.2 什麼是項集?
比如用購物車的例子來說, 購物車裡面的每一件item都叫做一個項, 辣條是一個項, 薯片也是一個項, 所有的商品加起來叫做項集記作itemset, 如果有多件商品記作 k-itemset
1.3 什麼是Transaction?
transaction就是一組非空的 item的集合, 可以把它想成是購物時的小票。
1.4 什麼是資料庫?
多個 transaction 記錄的總和稱為 dataset
1.5 什麼是關聯規則?

關聯規則的定義如上公式:
這樣理解: 就是驗證一下P到Q之間有什麼關係, 其中P屬於itemset ,Q也屬於itemiset, 並且P並不是Q
比如:P是牙刷,Q是牙膏, 牙刷和牙膏都是商品,並且牙膏並不是牙刷,我們要做的就是推導出牙膏和牙刷之間之間被用戶購買的rule
1.6 什麼是Lk Ck?
Lk表示有k個元素的頻繁項集
CK表示有K個元素的候選項集, 既然是候選項集, 意味著它裡面的元素肯定存在不滿足場景規定的支援度大小, 需要被丟棄掉 (什麼是支援度? 往下看…)
關聯規則有何應用?
Cross Selling: 交叉銷售, 比如很經典的數據挖掘問題, 購買啤酒的人通常會購買尿布 , 商家知道這個規則後就可以將這兩個商品放在一起, 方便了購物者, 也能起到提醒的作用, 提高營業額。
二:支援度與置信度
介紹數據挖掘中的兩個重要概念:
-
itemset的支援度(Support)
公式:

含義: Support就是頻率的意思,比如說牛奶的支援度,比如一共10個人,其中3個人買了牛奶, 那麼牛奶的支援度就是3/10 , 它是個比例。如果物品的支援度低,很可能會被忽略不計
-
關聯規則的支援度
公式:
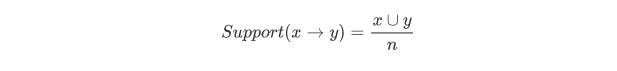
含義: 關聯規則的支援度,說的其實也是頻率,即同時購買X和Y的訂單數量,佔全部訂單數量的百分比
-
置信度(Confidence)
公式:
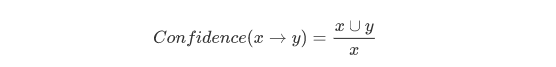
含義: 什麼是置信度? 比如X=牛奶, Y=麵包。置信度就是同時購買牛奶和麵包的人, 占購買麵包的數量
實際上它描述的就是我們原來學過的條件概率
P(Y|X) =P(Y*X) / P(X),這個公式至少高中都學過
三:頻繁項集和強規則
根據具體的場景,定義兩個變數:
- Minimum support 最小支援度 σ
- Minimun confidence 最小置信度 Φ
所謂頻繁項集大白話說就是這個項集出現的次數很頻繁,界定方法:這個項集的 支援度 要大於最小支援度
所謂牆規則大白話說就是這個規則很強大很有意義,界定方法:這個它置信度(條件概率)要大於 最小置信度
3.1 什麼是關聯規則的挖掘?
給定 I ,D ,σ 和 Φ, 然後我們去找出 X->Y之間的所有的強規則
用大白話說就是: 當我有了所有的itemset ,dataset,最小支援度,最小置信度,然後去把X與Y之間,符合前面四個要要素的所有強規則都找出來,稱為關聯規則的挖掘
四. 從宏觀的角度看如果進行關聯規則挖掘
- 將所有的頻繁項集都找出來, 這也是最麻煩的一步
- 使用這些頻繁項集,生成關聯規則
- 遍歷這個頻繁項集, 生成出他所有的非空子集
- 利用生成出來的所有的非空子集,將所有可能的關聯規則都找出來
- 找出來這些關聯規則後去檢驗是否是強關聯規則
可以看到, 哪怕僅僅存在4件商品, 他們之間的排列組合也是相當的多

五. Apriori演算法
5.1 原理:
- 如果某個項集是頻繁的, 那麼它的所有非空子集也得是頻繁的
- 如果某個項集是不頻繁的, 那麼它的所有超集也一定是不頻繁的
- 所以, Apriori演算法就是從單元素項集開始, 通過組合滿足最小支援度的項集來形成更大的集合
5.2.0 例子: 找出所有的頻繁項集
假設我們現在有如下的數據: 一共是9條記錄, 我們規定這個場景下的支援度是3, 置信度是70%
| transactions | itemset |
|---|---|
| 1 | {a, b, c, d} |
| 2 | {a, c, d, f} |
| 3 | {a, c, d, e, g} |
| 4 | {a, b, d, f} |
| 5 | {b, c, h} |
| 6 | {d, f, g} |
| 7 | { a, b, g } |
| 8 | {c, d, f, g} |
| 9 | {b, c, d} |
如果我們想找出頻繁1項集, 也就是 L1的話, 很容易就能想到, 只要遍歷所有的itemset中的每一個item ,然後記錄下他們出現的次數, 但凡是出現次數大於2的, 都符合要求而被保留, 小於2的都不滿足要求而被丟棄, 所以我們能得到下面的結果:
| item | support |
|---|---|
| a | 5 |
| b | 5 |
| c | 6 |
| d | 7 |
| f | 4 |
| g | 4 |
所以, 這個問題比較複雜的地方就是如何通過 lK -> CK+1 , 換句話說, 就是如何通過現在已知的 l1求出 C2
思路:
同樣的我們可以對L1進行排列組合, 得出所有的情況稱它為set1, 然後再遍歷set1每一項, 去看看最開始給定的itemsets中是否包含它, 如果找到了包含它的項, 我們就給他的支援度計數+1, 同樣的遍歷完set1中所有的項後, 把支援度不滿足的項刪除, 保留支援度大於2的項, 至此, 也就意味著我們找到了 C2, 於是我們可以得到下面的結果
| item | support |
|---|---|
| {a,b} | 3 |
| {a,c} | 3 |
| {a,d} | 4 |
| {b,c} | 3 |
| {b,d} | 3 |
| {c,d} | 5 |
| {d,f} | 4 |
| {d,g} | 3 |
再往後就是從 L2 – > C3的過程:
思路1: 如果我們仍然使用自由組合的規則生成C3的話, 能產生向下先這麼多的組合,實際上裡面有很多不必要的項 根據Apriori演算法的規定, 如果一個項集是不頻繁的, 那麼它的所有超集都是不頻繁的
比如下面的{a,d,f} 其中的子項{a,d} 並不是頻繁二項集, 那麼我們根本沒必要把它也組合進來, 因為一旦被組合進來之後, 就意味著我們要求去為他掃描資料庫
| item | support |
|---|---|
| {a,b,c} | 1 |
| {a,b,d} | 2 |
| {a,c,d} | 3 |
| {b,c,d} | 2 |
| {a,d,f} | X |
| {a,d,g} | X |
| {b,d,f} | X |
| {b,d,g} | X |
| {c,d,f} | X |
| {c,d,g} | X |
| {d,f,g} | X |
那如果不自由組合, 具體怎麼做呢?
-
第一步: 對所有的itemset進行一次排序, 因為第二步就要進行類似前綴的操作
-
第二步: 如果前k-1項相同, 第k項不同, 那麼把第k項搬過去, 就得到新的 候選項, 重複這個動作
通過步驟二的選擇方式, 可以排除掉大量的肯定不頻繁的候選項集, 但是也不能保證, 保存下來的候選項集就一定會是頻繁的
所以, 如果我們遵循Apriori演算法規定的話, 我們得到的集合如下應該長下面這樣,
| item | support |
|---|---|
| {a,b,c} | 1 |
| {a,b,d} | 2 |
| {a,c,d} | 3 |
| {b,c,d} | 2 |
同樣他們的支援度是具體是多少, 仍然得去掃描資料庫, 實際上就是遍歷這個C3, 然後看看一開始給定的itemsets中有多少個包含了它, 一旦發現就給它的計數+1 , 同樣僅僅保存符合規則的, 得到如下的結果:
| item | support |
|---|---|
| {a,c,d} | 3 |
5.2.1 例子: 找出所有的強關聯規則
找出所有的強關聯規則, 大白話講就是挨個計算所有的 L2 , L3 … (頻繁項集) 中, 他們的置信度是否在當前場景要求的70%以上, 如果滿足了這個條件, 說明它就是強關聯規則, (啤酒和尿布的關係)
計算公式就是它:
實際上就是計算:在Y發生的基礎上, X發生的條件概率, 直接看公式就是 X和Y同時出現的次數 / X 出現的次數
舉個例子: 比如求a->b , 就是 a b同時發生的支援度/ a的支援度 , 前者中C2中可以查處來, 後者從L1中可以查出來,也就是 3/5 = 60%
頻繁2項集:
- 對於{a,b}
- a->b : 置信度為 3/5 = 60%
- b->a : 置信度為 3/5 = 60%
- 對於{a,c}
- a->c : 置信度為 3/5 = 60%
- c->a : 置信度為 3/6 = 50%
- 對於{a,d}
- a->d : 置信度為 4/5 = 80%
- d->a : 置信度為 3/7 = 57%
- 對於{b,c}
- b->c : 置信度為 3/5 = 60%
- c->b : 置信度為 3/6 = 50%
- 對於{b,d}
- b->d : 置信度為 3/5 = 60%
- d->b : 置信度為 3/7 = 42%
- 對於{c,d}
- c->d : 置信度為 5/6 = 83%
- d->c : 置信度為 5/7 = 71%
- 對於{d,f}
- d->f : 置信度為 4/7 = 57%
- f->d : 置信度為 4/4= 100%
- 對於{d,g}
- d->g : 置信度為 3/7 = 42%
- g->d : 置信度為 3/4 = 75%
如果規定置信度是70% , 那麼強關聯規則如下:
- a->d
- c->d
- d->c
- f->d
- g->d
頻繁3項集:
頻繁3項集是 {a,c,d}, 那麼有如下幾種情況
計算公式如上, {a,c,d}的置信度 / 箭頭左邊出現的項集的置信度
- a,c -> d : 置信度是 3/3 = 100%
- a,d -> c : 置信度是 3/4 = 75%
- c,d -> a : 置信度是 3/5 = 60%
- a -> c,d : 置信度是 3/5 = 60%
- c -> a,d : 置信度是 3/6 = 50%
- d -> a,c : 置信度是 3/7 = 42%
和標準的置信度比較,得到的結強關聯規則如下:
- a,c -> d
- a,d -> c
5.3 程式碼實現:
# 載入數據集 def loadDataSet(): return [ ['a', 'b', 'c', 'd'], ['a', 'c', 'd', 'f'], ['a', 'c', 'd', 'e', 'g'], ['a', 'b', 'd', 'f'], ['b', 'c', 'h'], ['d', 'f', 'g'], ['a', 'b', 'g'], ['c', 'd', 'f', 'g'], ['b', 'c', 'd']] # 選取數據集的非重複元素組成候選集的集合C1 def createC1(dataSet): C1 = [] for transaction in dataSet: # 對數據集中的每條購買記錄 for item in transaction: # 對購買記錄中的每個元素 if [item] not in C1: # 注意,item外要加上[],便於與C1中的[item]對比 C1.append([item]) C1.sort() return list(map(frozenset, C1)) # 將C1各元素轉換為frozenset格式,注意frozenset作用對象為可迭代對象 # 現在的CK是所有的一項集, 通過下面的前兩個循環計算出每一個候選1項集出現的次數,進而才能判斷出是否滿足給定的支援度 # 由Ck產生Lk:掃描數據集D,計算候選集Ck各元素在D中的支援度,選取支援度大於設定值的元素進入Lk def scanD(DataSet, Ck, minSupport): ssCnt = {} # map字典結構, key = 項集 value = 支援度 for tid in DataSet: # 遍歷每一條購買記錄 for can in Ck: # 遍歷Ck,也就是所有候選集 if can.issubset(tid): # 如果候選集包含在購買記錄中,計數+1 ssCnt[can] = ssCnt.get(can, 0) + 1 numItems = float(len(DataSet)) # 購買記錄數 retList = [] # 用於存放支援度大於設定值的項集 supportData = {} # 用於記錄各項集對應的支援度 for key in ssCnt.keys(): support = ssCnt[key] / numItems if support >= minSupport: retList.insert(0, key) # 滿足最小支援度就存儲起來 supportData[key] = support return retList, supportData # 返回頻繁1項集和他們各自的支援度 # 由Lk產生Ck+1 , 那第一次進來就是頻繁1項集, 企圖生成頻繁二項集 def aprioriGen(Lk, k): # Lk的k和參數k不是同一個概念,Lk表示頻繁k項集, 參數K = CK+1 中的K+1 retList = [] lenLk = len(Lk) for i in range(lenLk): # 分別遍歷Lk中的每一項, 讓它們和其他的項組合 # 下面的for循環, 使用的是正宗的 類似前綴匹配的方式生成候選項集的方式 for j in range(i + 1, lenLk): # 從i+1開始, 是不讓當前元素和自己也進行組合 # 通過這兩層循環, 就能實現類似這種組合 01, 02 ,03 ... 12,13,... L1 = list(Lk[i])[:k - 2] # 將當前的頻繁項集轉換成list ,然後進行切片, 如果lk是頻繁1項集, 這裡根本切不出東西來 L2 = list(Lk[j])[:k - 2] # 前綴匹配前肯定需要先排序,讓它們相對是有序的 L1.sort() L2.sort() if L1 == L2: # 若前k-2項相同,則合併這兩項 retList.append(Lk[i] | Lk[j]) # 01, 02 ,03 ... 12,13,... return retList # Apriori演算法主函數 def apriori(dataSet, minSupport=0.5): # 創建c1 C1 = createC1(dataSet) # todo 為啥需要去除重複? # 將dataset中所有的元素進行一次set去重, 然後轉換成list返回得到D DataSet = list(map(set, dataSet)) # 得到頻繁1項集和各個項集的最小支援度 L1, supportData = scanD(DataSet, C1, minSupport) L = [L1] k = 2 # 從頻繁1項集開始, 進行從Lk -> CK+1的生成 while len(L[k - 2]) > 0: # 當L[k]為空時,停止迭代 Ck = aprioriGen(L[k - 2], k) # L[k-2]對應的值是Lk-1 # 獲取到候選項集後, 重新掃描資料庫, 計算出頻繁項集,以及他們各自的支援度 Lk, supK = scanD(DataSet, Ck, minSupport) # 更新他們各自的支援度 supportData.update(supK) # 將新推導出來的頻繁項集也添加進去 L.append(Lk) k += 1 return L, supportData # 處理兩個item項的 可信度(confidence) def calcConf(freqSet, supportData, strong_rule, minConf): # 那麼現在需要求出 frozenset([1]) -> frozenset([3]) 的可信度和 frozenset([3]) -> frozenset([1]) 的可信度 for conseq in freqSet: # print 'confData=', freqSet, H, conseq, freqSet-conseq # 支援度定義: a -> b = support(a | b) / support(a). the_list = list(conseq) left = the_list[0] right = the_list[1] # 計算a-b conf = supportData[conseq] / supportData[frozenset({left})] if conf >= minConf: strong_rule.append("{} -> {}".format(frozenset({left}),frozenset({right}))) # 計算b-a conf = supportData[conseq] / supportData[frozenset({right})] if conf >= minConf: strong_rule.append("{} -> {}".format(frozenset({right}), frozenset({left}))) def calcConfidence(Ck, fullSet,all_set,supportData, strong_rule, minConf): ''' Ck : k階的頻繁項集 fullSet : k階頻繁項集拆開後的元素 set : 由set 反向拆分出 Ck supportData, strong_rule, minConf ''' for itemset in Ck: the_list = list(itemset) temp = fullSet.copy() for item in the_list: temp.remove({item}) s = set() for i in temp: for j in i: s.add(j) # confidence(a->b) = support(a,b) / support(a) confidence1 = supportData[all_set] / supportData[frozenset(itemset)] if(confidence1>=minConf): strong_rule.append("{} -> {}".format(frozenset(itemset), frozenset(s))) # confidence(b->a) = support(a,b) / support(b) confidence2 = supportData[all_set] / supportData[frozenset(s)] if (confidence2 >= minConf): strong_rule.append("{} -> {}".format(frozenset(s), frozenset(itemset))) def rulesFromConseq(freqSet, supportData, strong_rule, minConf): for itemset in freqSet: for set in itemset: H = list(set) the_list = [] for i in H: the_list.append({i}) LL = [] LL.append(the_list) k = 2 # 從頻繁1項集開始, 進行從Lk -> CK+1的生成 while len(LL[k - 2]) > 0: # 當L[k]為空時,停止迭代 # 直接對CK進行 統計置信度, 是因為根據Apriori演算法的約定, 如果CK是頻繁的,那麼它的非空子集也是頻繁的 Ck = aprioriGen(LL[k - 2], k) # L[k-2]對應的值是Lk-1 # temp = the_list - Ck if len(Ck[0]) == len(the_list): break else: # 統計強關聯規則 calcConfidence(Ck, LL[k - 2],set,supportData, strong_rule, minConf) # 添加繼續循環的條件 LL.append(Ck) k += 1 def get_strong_rule(L,supportData,confidence): freSet = [L[k] for k in range(2, len(L))] strong_rule = [] # 處理兩項 calcConf(L[1], supportData, strong_rule, confidence) # 處理三項及以上 rulesFromConseq(freSet, supportData, strong_rule, confidence) return strong_rule if __name__ == '__main__': minSupport = 0.3 confidence = 0.7 # 載入數據 dataset = loadDataSet() # 找出各頻繁項集的, 及其支援度 L, supportData = apriori(dataset, minSupport) # 找出強規則 strong_rules = get_strong_rule(L, supportData,confidence) print('所有項集及其支援度: ',supportData) print('所有頻繁項集: ',L) print("強規則: ",strong_rules) 演算法參考: 《機器學習實戰》 Peter Harrington Chapter11
另外, 添加了求強規則的邏輯
六: Apriori演算法的不足
每次雖然從Lk->CK+1 都是儘可能的生成出數量最少候選項集, 還保證了不會丟失頻繁的候選項集, 但是依然需要校驗生成出來的所有的候選項集的支援度是否符合場景要求的支援度大小, 不足的地方就體現在這裡, 因為每次去校驗的時候都得掃描一遍資料庫, 如果資料庫很大, 大量的IO會讓演算法變慢