架構與思維:熔斷限流的一些使用場景
1 前言
在《微服務系列》中,我們講過很多限流,熔斷相關的知識。
老生長談的一個話題,服務的能力終歸是有限的,無論是記憶體、CPU、執行緒數都是,如果遇到突如其來的峰量請求,我們怎麼友好的使用限流來進行落地,避免整個服務集群的雪崩。
峰量請求主要有兩種場景:
1.1 突發高峰照成的服務雪崩
如果你的服務突然遇到持續性的、高頻率的、不符合預期的突發流量。你需要檢查一下服務是否有被錯誤調用、惡意攻擊,或者下遊程式邏輯問題。
這種超出預期的調用經常會造成你的服務響應延遲,請求堆積,甚至服務雪崩。而雪崩會隨著調用鏈向上傳遞,導致整個服務鏈的崩潰,對我們的系統造成很大的隱患。
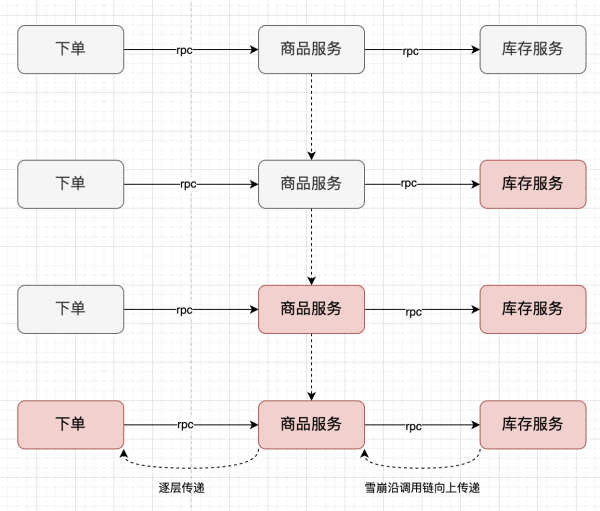
1.2 超出預期值的流量洪峰
如果你的商城或者平台搞活動(類似雙11、618),但你又無法有效評估出這個峰值的具象值和持續時間,那麼你的服務依然有被打垮的風險。
除非你能做到服務集群彈性伸縮(動態擴縮容)的能力,這個我在後面的雲原生系列中會詳細說。
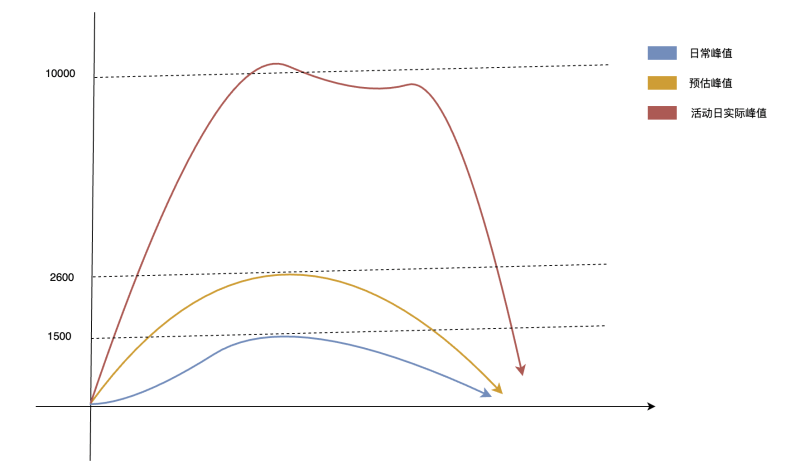
如上圖,正常量值為1500 QPS,預估模型的量值是2600的QPS,後面發現,來了幾波活動,量值增加到 10000,遠超過我們伺服器的負載。服務一過載,系統就開始出現各種問題,延遲、故障、請求堆積,甚至雪崩。
2 解決方案
2.1 雲原生和彈性伸縮
如果你的服務基架構與足夠強大,你的服務上雲足夠的徹底,那麼彈性伸縮是最好的辦法。類似淘寶、京東、百度APP,都是類似的做法。
kubernetes會根據流量的變化,CPU、記憶體的曲線過程實時計算需要的服務實例數,然後進行動態擴容,低峰期再還回去。這個要求你的服務上雲足夠徹底,並且有足夠的資源來達成資源擴容的目標。
★關於這塊內容筆者後續會有專門的系列來講解,以及如何在大廠實現落地的過程,這邊不展開。
2.2 兜底的限流、熔斷
最基本的保障就是能夠在服務做一層保護,避免因為過載而造成服務雪崩,導致整個系統不可用.
對超過預期或者承載能力的流量進行限流是比較好的一種辦法。所以你在雙11、618、搶購、競拍 等的選擇的時候會經常看到這樣的辭彙:
- 服務正在努力載入中,請稍候!
- 服務/網路錯誤,請重試!
- 哎呀,服務繁忙,請稍後再試!


2.1 應用層面解決方案
2.1.1 常見的限流演算法
- 計數限流演算法
計數演算法是指再一定的時間間隔里,記錄請求次數,當時間間隔到期之後,就把計數清零,重新計算。

- 固定窗口限流演算法(取樣時間窗)
相對於上一個 計數限流,多了個時間窗口的概念,計數器每過一個時間窗口就重置,重新開始計算。

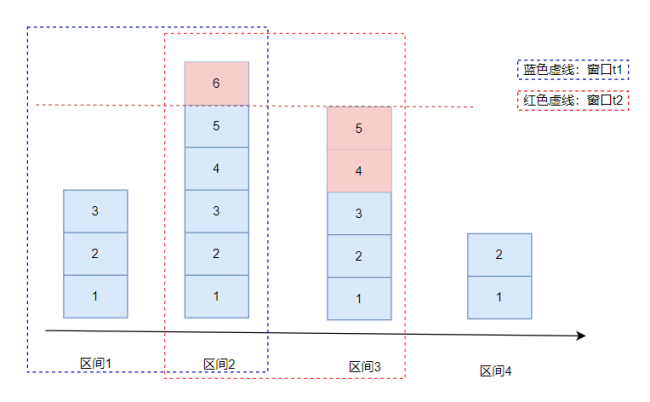
- 滑動窗口限流(記錄每個請求到達的時間點)
滑動窗口限流解決固定窗口臨界值的問題,可以保證在任意時間窗口內都不會超過閾值。
- 漏桶演算法(漏斗池演算法)
類似沙漏思維,大家都用過,沙子是勻速流出得。對於漏桶來說,由於它的出水口的速度是恆定的,也就是消化處理請求的速度是恆定的,所以它可以保證服務以恆定的速率來處理請求,

- 令牌桶演算法(定速流入)
令牌桶和漏桶的原理類似,只不過漏桶是定速流出,令牌桶是定速流入(即往桶里塞入令牌),每個請求進來,分配一個令牌,只有拿到了令牌才能進入伺服器處理,拿不到令牌的就被拒絕了。
因為令牌桶的大小也是有限制的,所以一旦令牌桶滿,後續生成的令牌就會被丟棄,拿不到令牌的服務請求就被拒絕了,達到限流的目的。執行原理如下:

2.1.2 相關實現的框架
- Spring Cloud 的 Hystrix
- Sentinel 熔斷降級能力
- Google Guava 的 Ratter Limitter
2.1.3 達到限流條件的時候的做法
fallback:返回固定的對象或者執行固定的方法
// 返回固定的對象
{
"timestamp": 1649756501928,
"status": 429,
"message": "Too Many Requests",
}
// 執行固定的處理方法
function fallBack(Context ctx) {
// Todo 默認的處理邏輯
}
2.1.4 Web/Mobile/PC/3d
接收到固定的消息結構或者固定的處理結果之後,以友好的方式提示給用戶。
- 提示服務正在努力載入中,請稍候!
- 服務/網路錯誤,請重試!
- 哎呀,服務繁忙,請稍後再試!
2.2 存儲層面解決方案
Redis熱點數據同時並發請求處理,1000W+請求同時投向後端,如果快取未建立,直接投向資料庫,可能會造成擊穿,怎麼破?一般有如下解決方法,優劣各異:
-
分散式鎖:只允許一個請求執行緒去訪問DB,其他請求被阻塞,這樣就避免了很多請求投放到DB上。但是這樣吞吐量降低。
-
請求按照隊列執行:按照隊列順序執行,避免全部投向資料庫。這樣還是吞吐量降低。
-
快取預熱:進入資料庫的快取數量會比較少,保證有一部分的數據先做出來。
-
空/默認 初始值:第一個請求進去的時候,創建空初始值或者默認初始值的快取,並進入資料庫查詢。查詢之後,更新快取,保證後續的拿到正確的值。而在查詢的這個過程中(可能幾ms到幾十ms),拿到的是默認值或空置,前端做一下友好的提示。這是一種降級的策略,保證僅有1個或者前n個進入資料庫。
-
本地快取:改造web應用服務,在獲取到redis快取後,在web服務本地把熱點的數據進行快取,因為熱點的商品不會很多,所以保存在本地快取中,是沒有問題的。這樣請求數據時,如果web本地有快取數據,就直接返回了。本地快取和服務進程快取混用的情況。快取更新會增加額外的負擔。
這裡面,空初始值和和分散式鎖的結合使用是目前很多大廠的處理方式,如下:

-
第一個請求進去的時候,創建空初始值或者默認初始值的快取
-
後續進來的同類請求會短暫獲取到 默認值的快取資訊
-
當第一個請求從資料庫查詢到結果,立即更新快取,保證後續的同類請求拿到的是正確的值
-
而第一個請求調用資料庫的過程中(可能幾ms到幾十ms),其他同類請求拿到的是默認值或空值,前端做一下友好的提示
-
這是一種典型的降級策略,保證僅有1個或者前n個進入資料庫

3 總結
無論是應用層級還是存儲層級,無非是跟前端約定一個規則,返回默認參數或者默認回到方法,讓前端以用戶友好體驗的方式進行降級,保證服務端不至於崩潰。

