2022年Python頂級自動化特徵工程框架⛵

💡 作者:韓信子@ShowMeAI
📘 機器學習實戰系列://www.showmeai.tech/tutorials/41
📘 本文地址://www.showmeai.tech/article-detail/328
📢 聲明:版權所有,轉載請聯繫平台與作者並註明出處
📢 收藏ShowMeAI查看更多精彩內容

特徵工程(feature engineering)指的是:利用領域知識和現有數據,創造出新的特徵,用於機器學習演算法。
- 特徵:數據中抽取出來的對結果預測有用的資訊。
- 特徵工程:使用專業背景知識和技巧處理數據,使得特徵能在機器學習演算法上發揮更好的作用的過程。
在業界有一個很流行的說法:數據與特徵工程決定了模型的上限,改進演算法只不過是逼近這個上限而已。
特徵工程的目的是提高機器學習模型的整體性能,以及生成最適合用於機器學習的演算法的輸入數據集。
關於特徵工程的各種方法詳解,歡迎大家閱讀 ShowMeAI 整理的特徵工程解讀教程。
💡 自動化特徵工程
在很多生產項目中,特徵工程都是手動完成的,而且它依賴於先驗領域知識、直觀判斷和數據操作。整個過程是非常耗時的,並且場景或數據變換後又需要重新完成整個過程。而『自動化特徵工程』希望對數據集處理自動生成大量候選特徵來幫助數據科學家和工程師們,可以選擇這些特徵中最有用的進行進一步加工和訓練。
自動化特徵工程是很有意義的一項技術,它能使數據科學家將更多時間花在機器學習的其他環節上,從而提高工作效率和效果。

在本篇內容中,ShowMeAI將總結數據科學家在 2022 年必須了解的 Python 中最流行的自動化特徵工程框架。
- Feature Tools
- TSFresh
- Featurewiz
- PyCaret
💡 Feature Tools
📌 簡介
📘Featuretools是一個用於執行自動化特徵工程的開源庫。 ShowMeAI在文章 機器學習實戰 | 自動化特徵工程工具Featuretools應用 中也對它做了介紹。

要了解 Featuretools,我們需要了解以下三個主要部分:
- Entities
- Deep Feature Synthesis (DFS)
- Feature primitives
在 Featuretools 中,我們用 Entity 來囊括原本 Pandas DataFrame 的內容,而 EntitySet 由不同的 Entity 組合而成。
Featuretools 的核心是 Deep Feature Synthesis(DFS) ,它實際上是一種特徵工程方法,它能從單個或多個 DataFrame中構建新的特徵。
DFS 通過 EntitySet 上指定的 Feature primitives 創建特徵。例如,primitives中的mean函數將對變數在聚合時進行均值計算。
📌 使用示例
💦 ① 數據與預處理
以下示例轉載自 📘官方快速入門。
# 安裝
# pip install featuretools
import featuretools as ft
data = ft.demo.load_mock_customer()
# 載入數據集
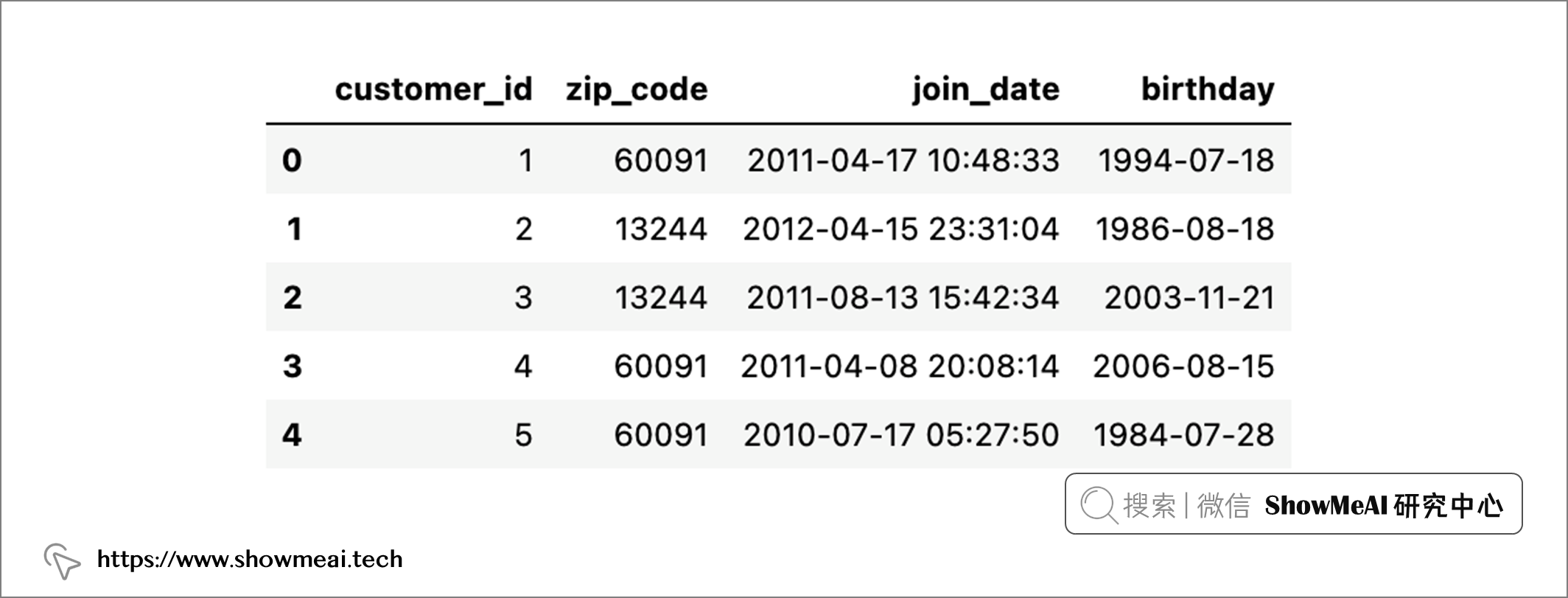
customers_df = data["customers"]
customers_df
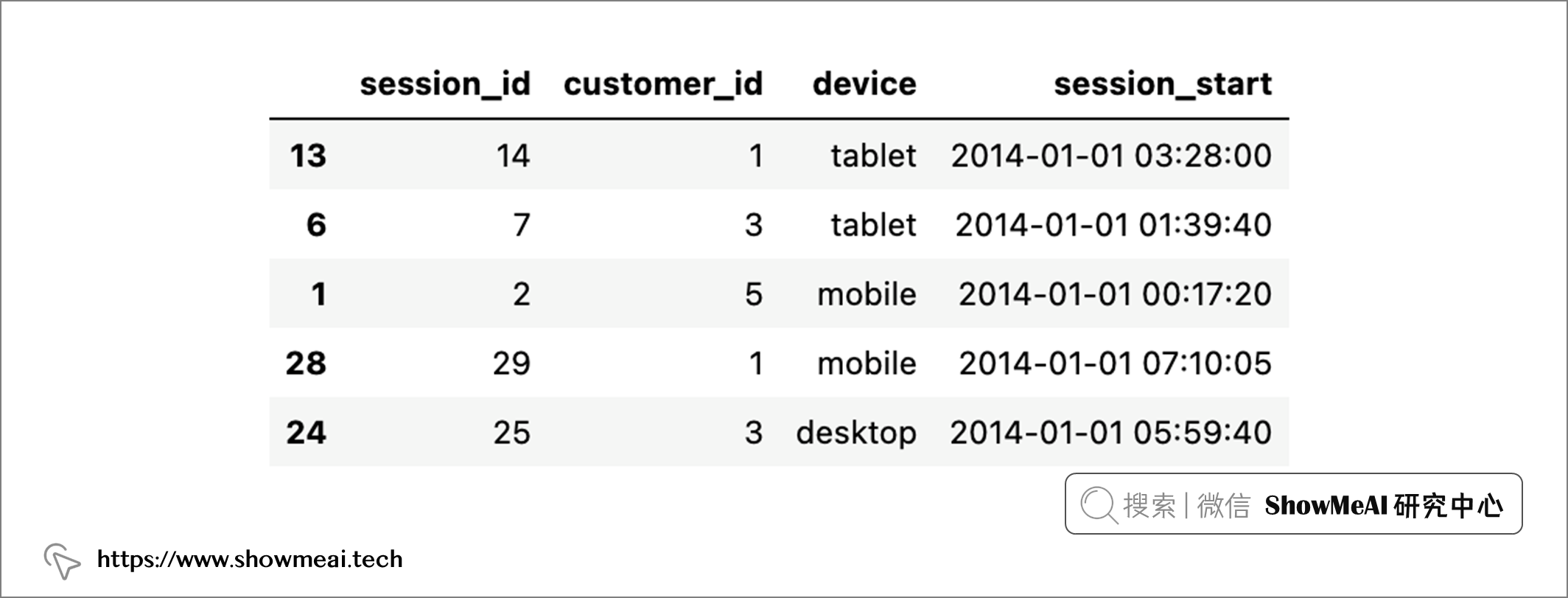
sessions_df = data["sessions"]
sessions_df.sample(5)
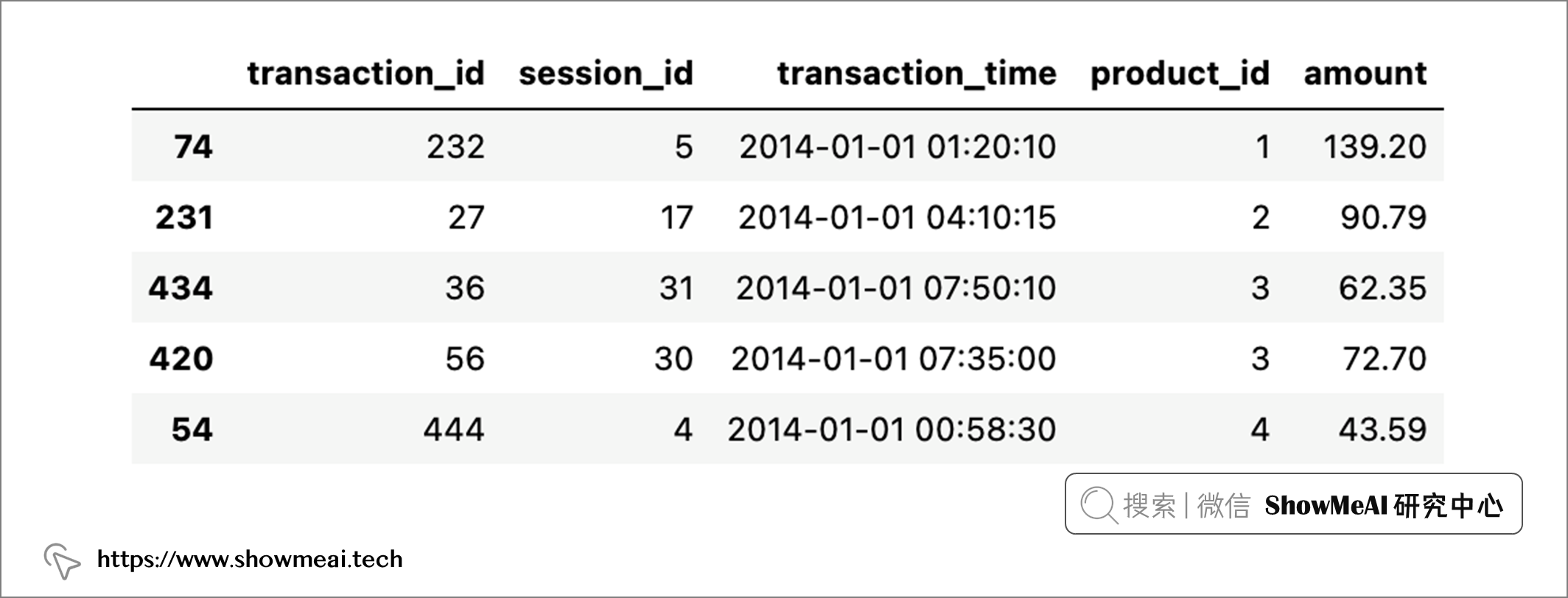
transactions_df = data["transactions"]
transactions_df.sample(5)
下面我們指定一個包含數據集中每個 DataFrame 的字典,如果數據集有索引index列,我們會和 DataFrames 一起傳遞,如下圖所示。
dataframes = {
"customers": (customers_df, "customer_id"),
"sessions": (sessions_df, "session_id", "session_start"),
"transactions": (transactions_df, "transaction_id", "transaction_time"),
}
接下來我們定義 DataFrame 之間的連接。在這個例子中,我們有兩個關係:
relationships = [
("sessions", "session_id", "transactions", "session_id"),
("customers", "customer_id", "sessions", "customer_id"),
]
💦 ② 深度特徵合成
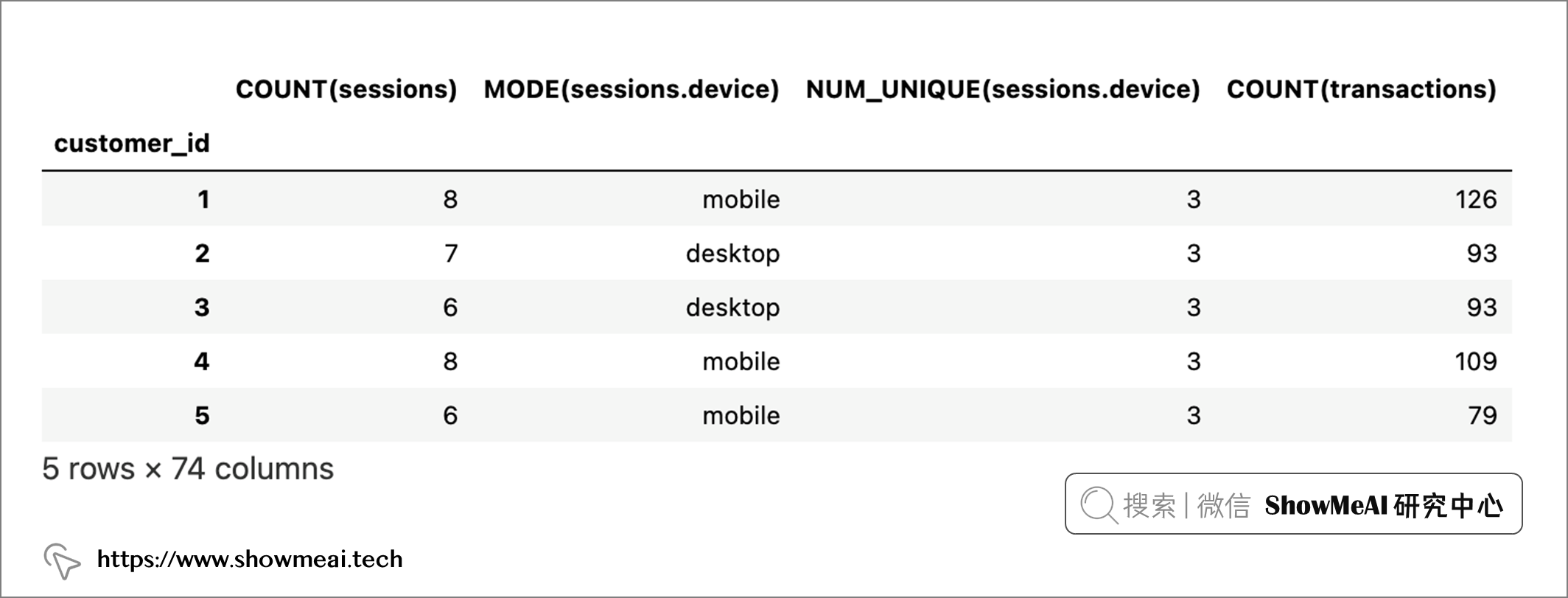
接下來我們可以通過DFS生成特徵了,它需要『DataFrame 的字典』、『Dataframe關係列表』和『目標 DataFrame 名稱』3個基本輸入。
feature_matrix_customers, features_defs = ft.dfs(
dataframes=dataframes,
relationships=relationships,
target_dataframe_name="customers",
)
feature_matrix_customers
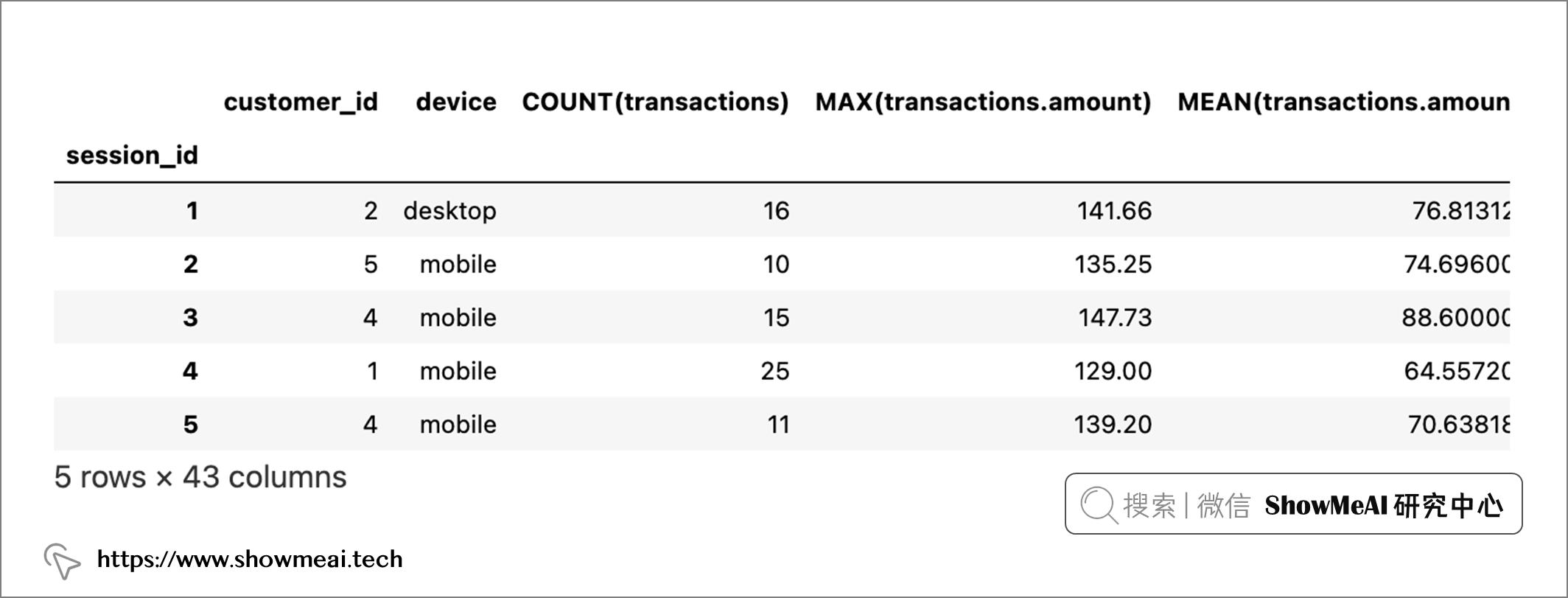
比如我們也可以以sessions為目標dataframe構建新特徵。
feature_matrix_sessions, features_defs = ft.dfs( dataframes=dataframes, relationships=relationships, target_dataframe_name="sessions"
)
feature_matrix_sessions.head(5)
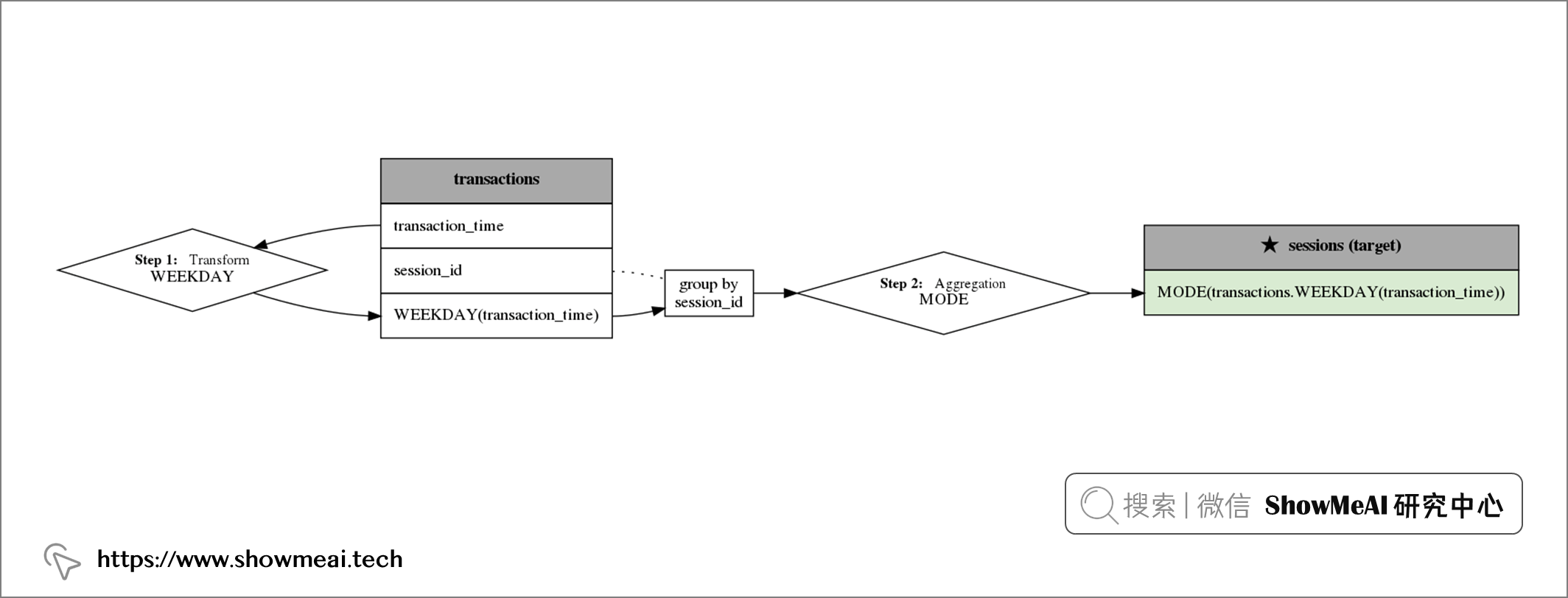
💦 ③ 特徵輸出
Featuretools不僅可以完成自動化特徵生成,它還可以對生成的特徵可視化,並說明Featuretools 生成它的方法。
feature = features_defs[18]
feature
💡 TSFresh
📌 簡介
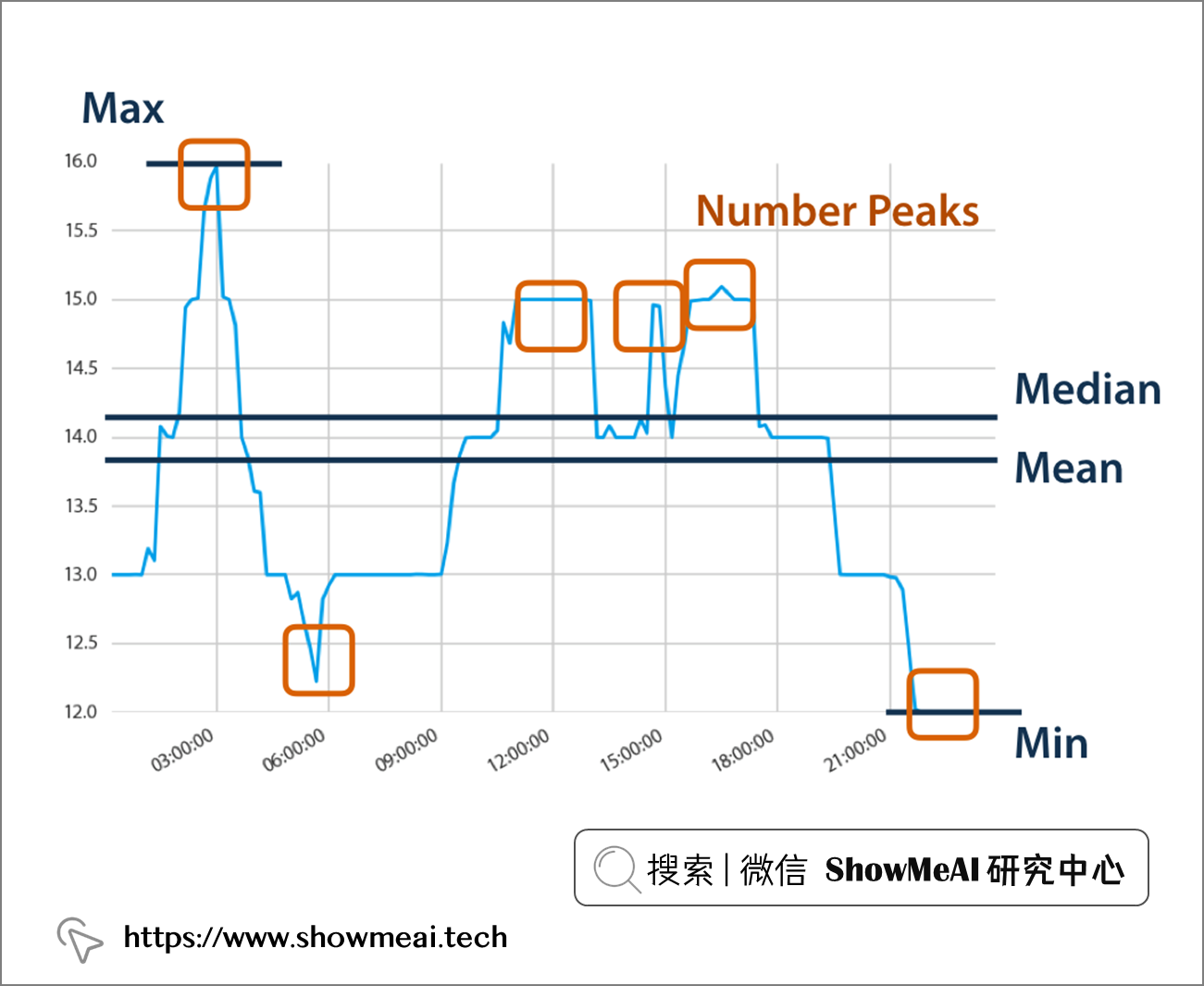
📘TSFresh 是一個開源 Python 工具庫,有著強大的時間序列數據特徵抽取功能,它應用統計學、時間序列分析、訊號處理和非線性動力學的典型演算法與可靠的特徵選擇方法,完成時間序列特徵提取。

TSFresh 自動從時間序列中提取 100 個特徵。 這些特徵描述了時間序列的基本特徵,例如峰值數量、平均值或最大值或更複雜的特徵,例如時間反轉對稱統計量。
📌 使用示例
# 安裝
# pip install tsfresh
# 數據下載
from tsfresh.examples.robot_execution_failures import download_robot_execution_failures, load_robot_execution_failures
download_robot_execution_failures()
timeseries, y = load_robot_execution_failures()
# 特徵抽取
from tsfresh import extract_features
extracted_features = extract_features(timeseries, column_id="id", column_sort="time")
💡 Featurewiz
📌 簡介
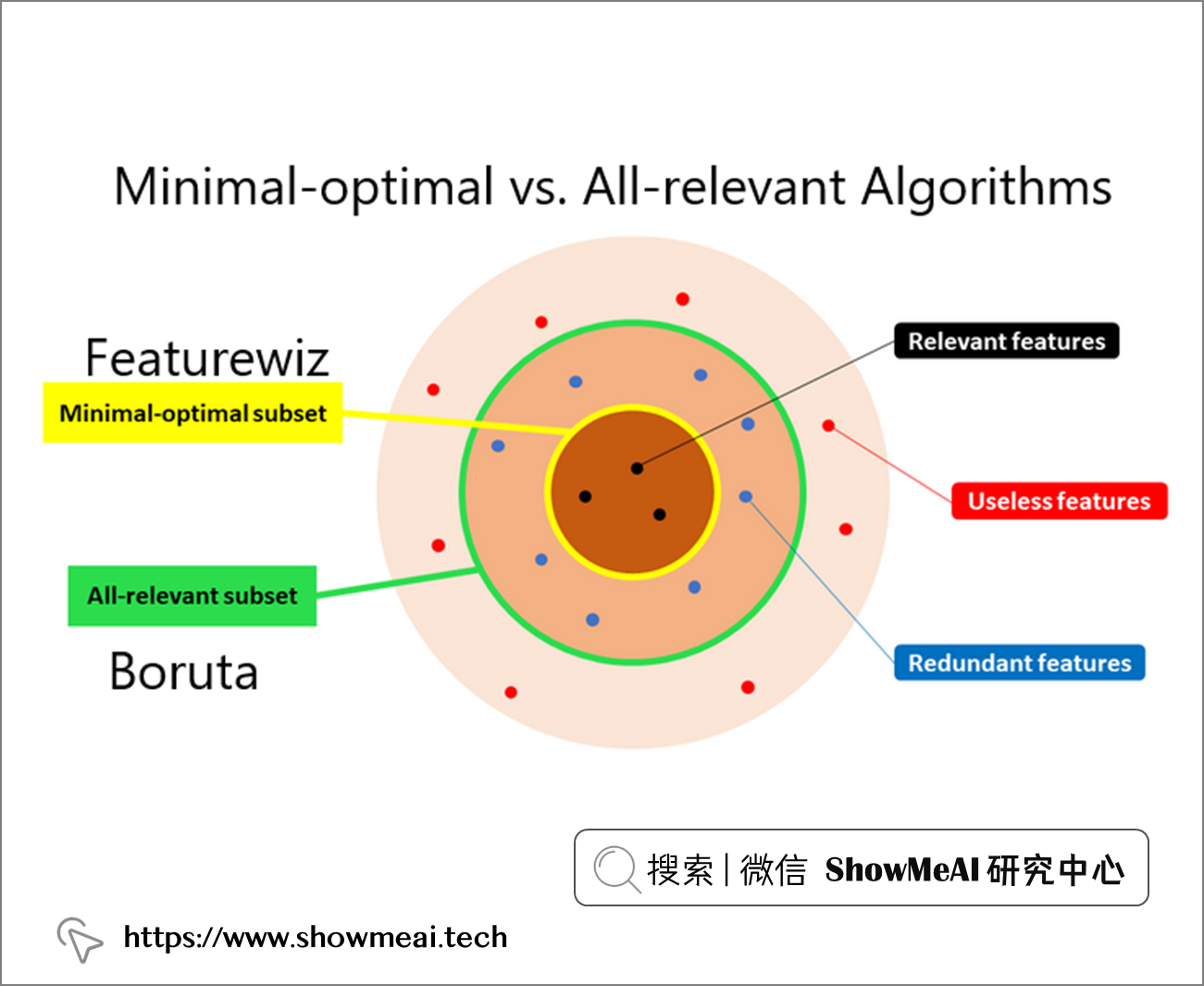
Featurewiz 是另外一個非常強大的自動化特徵工程工具庫,它結合兩種不同的技術,共同幫助找出最佳特性:

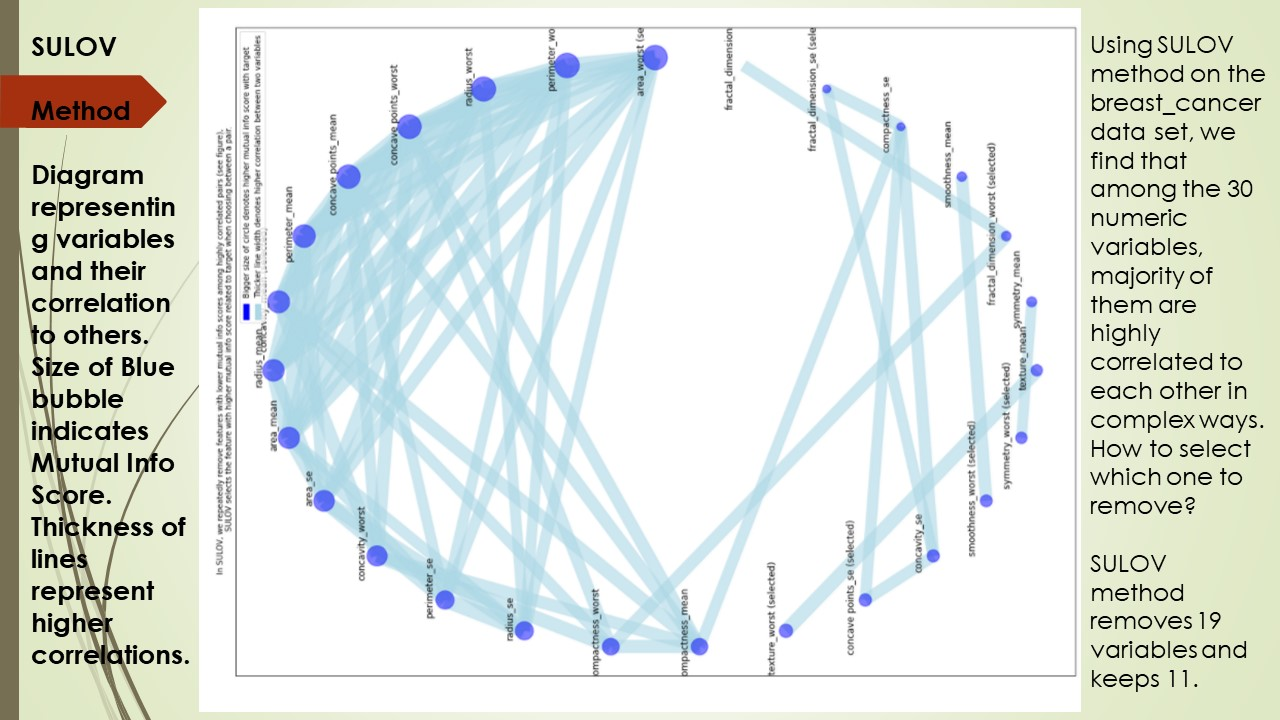
💦 ① SULOV
Searching for the uncorrelated list of variables:這個方法會搜索不相關的變數列表來識別有效的變數對,它考慮具有最低相關性和最大 MIS(互資訊分數)評級的變數對並進一步處理。
💦 ② 遞歸 XGBoost
上一步SULOV中識別的變數遞歸地傳遞給 XGBoost,通過xgboost選擇和目標列最相關的特徵,並組合它們,作為新的特徵加入,不斷迭代這個過程,直到生成所有有效特徵。

📌 使用示例
簡單的使用方法示例程式碼如下:
from featurewiz import FeatureWiz
features = FeatureWiz(corr_limit=0.70, feature_engg='', category_encoders='', dask_xgboost_flag=False, nrows=None, verbose=2)
X_train_selected = features.fit_transform(X_train, y_train)
X_test_selected = features.transform(X_test)
features.features # 選出的特徵列表 #
# 自動化特徵工程構建特徵
import featurewiz as FW
outputs = FW.featurewiz(dataname=train, target=target, corr_limit=0.70, verbose=2, sep=',',
header=0, test_data='',feature_engg='', category_encoders='',
dask_xgboost_flag=False, nrows=None)
💡 PyCaret
📌 簡介
📘PyCaret是 Python 中的一個開源、低程式碼機器學習庫,可自動執行機器學習工作流。它是一個端到端的機器學習和模型管理工具,可加快實驗周期並提高工作效率。

與本文中的其他框架不同,PyCaret 不是一個專用的自動化特徵工程庫,但它包含自動生成特徵的功能。
📌 使用示例
# 安裝
# pip install pycaret
# 載入數據
from pycaret.datasets import get_data
insurance = get_data('insurance')
# 初始化設置
from pycaret.regression import *
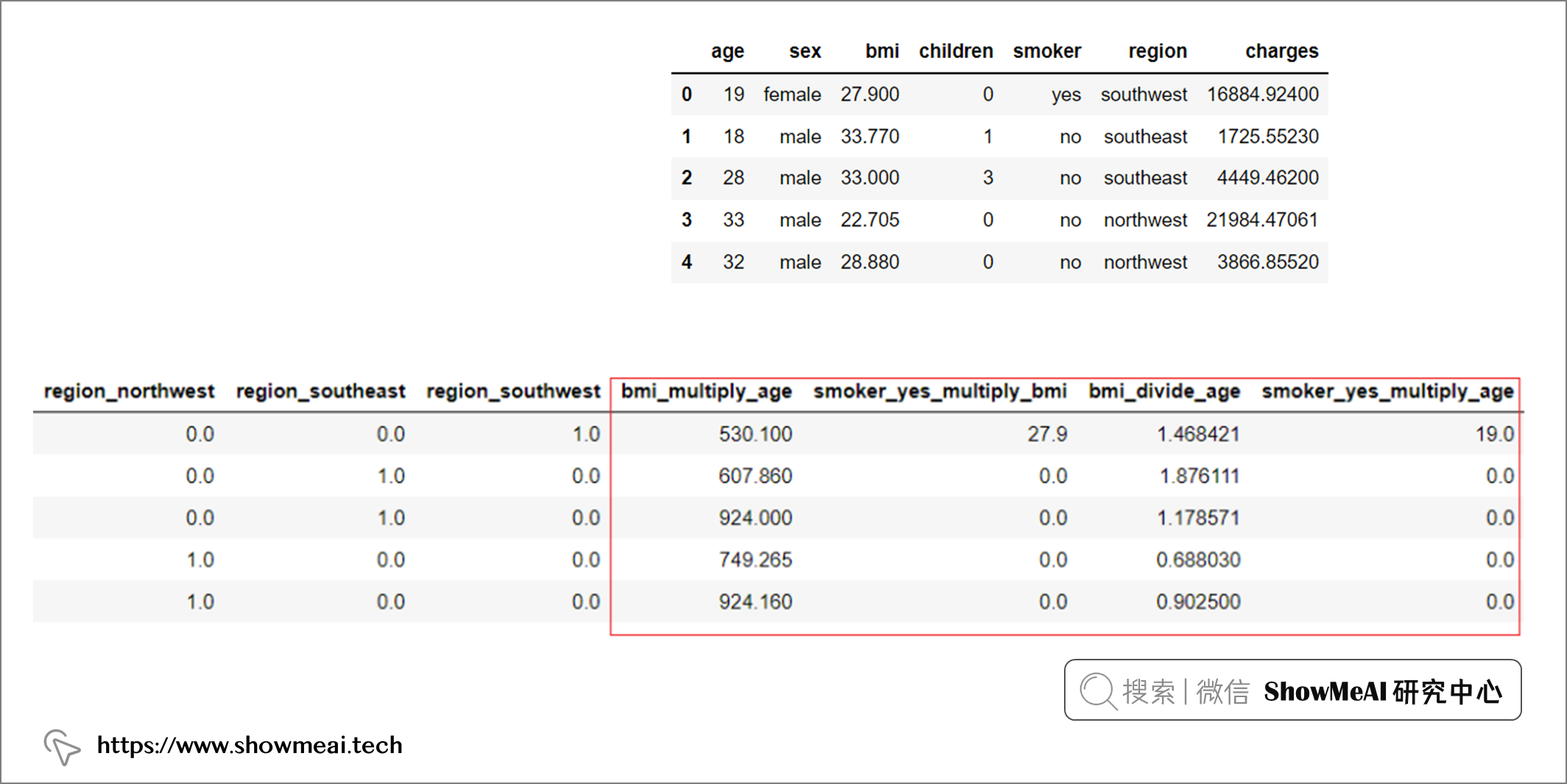
reg1 = setup(data = insurance, target = 'charges', feature_interaction = True, feature_ratio = True)
參考資料
- 📘 機器學習實戰 | 機器學習特徵工程全面解讀://www.showmeai.tech/article-detail/208
- 📘 Featuretools://featuretools.alteryx.com/en/stable/
- 📘 機器學習實戰 | 自動化特徵工程工具Featuretools應用://www.showmeai.tech/article-detail/209
- 📘 官方快速入門://featuretools.alteryx.com/en/stable/
- 📘 TSFresh://github.com/blue-yonder/tsfresh
- 📘 Featurewiz://github.com/AutoViML/featurewiz
- 📘 PyCaret://pycaret.org


