elasticsearch聚合之bucket terms聚合
- 2022 年 11 月 13 日
- 筆記
- elasticsearch, ELK
1. 背景
此處簡單記錄一下bucket聚合下的terms聚合。記錄一下terms聚合的各種用法,以及各種注意事項,防止以後忘記。
2. 前置條件
2.1 創建索引
PUT /index_person
{
"settings": {
"number_of_shards": 1
},
"mappings": {
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "keyword"
},
"sex": {
"type": "keyword"
},
"age": {
"type": "integer"
},
"province": {
"type": "keyword"
},
"address": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
2.2 準備數據
PUT /_bulk
{"create":{"_index":"index_person","_id":1}}
{"id":1,"name":"張三","sex":"男","age":20,"province":"湖北","address":"湖北省黃岡市羅田縣匡河鎮"}
{"create":{"_index":"index_person","_id":2}}
{"id":2,"name":"李四","sex":"男","age":19,"province":"江蘇","address":"江蘇省南京市"}
{"create":{"_index":"index_person","_id":3}}
{"id":3,"name":"王武","sex":"女","age":25,"province":"湖北","address":"湖北省武漢市江漢區"}
{"create":{"_index":"index_person","_id":4}}
{"id":4,"name":"趙六","sex":"女","age":30,"province":"北京","address":"北京市東城區"}
{"create":{"_index":"index_person","_id":5}}
{"id":5,"name":"錢七","sex":"女","age":16,"province":"北京","address":"北京市西城區"}
{"create":{"_index":"index_person","_id":6}}
{"id":6,"name":"王八","sex":"女","age":45,"province":"北京","address":"北京市朝陽區"}
3. 各種聚合
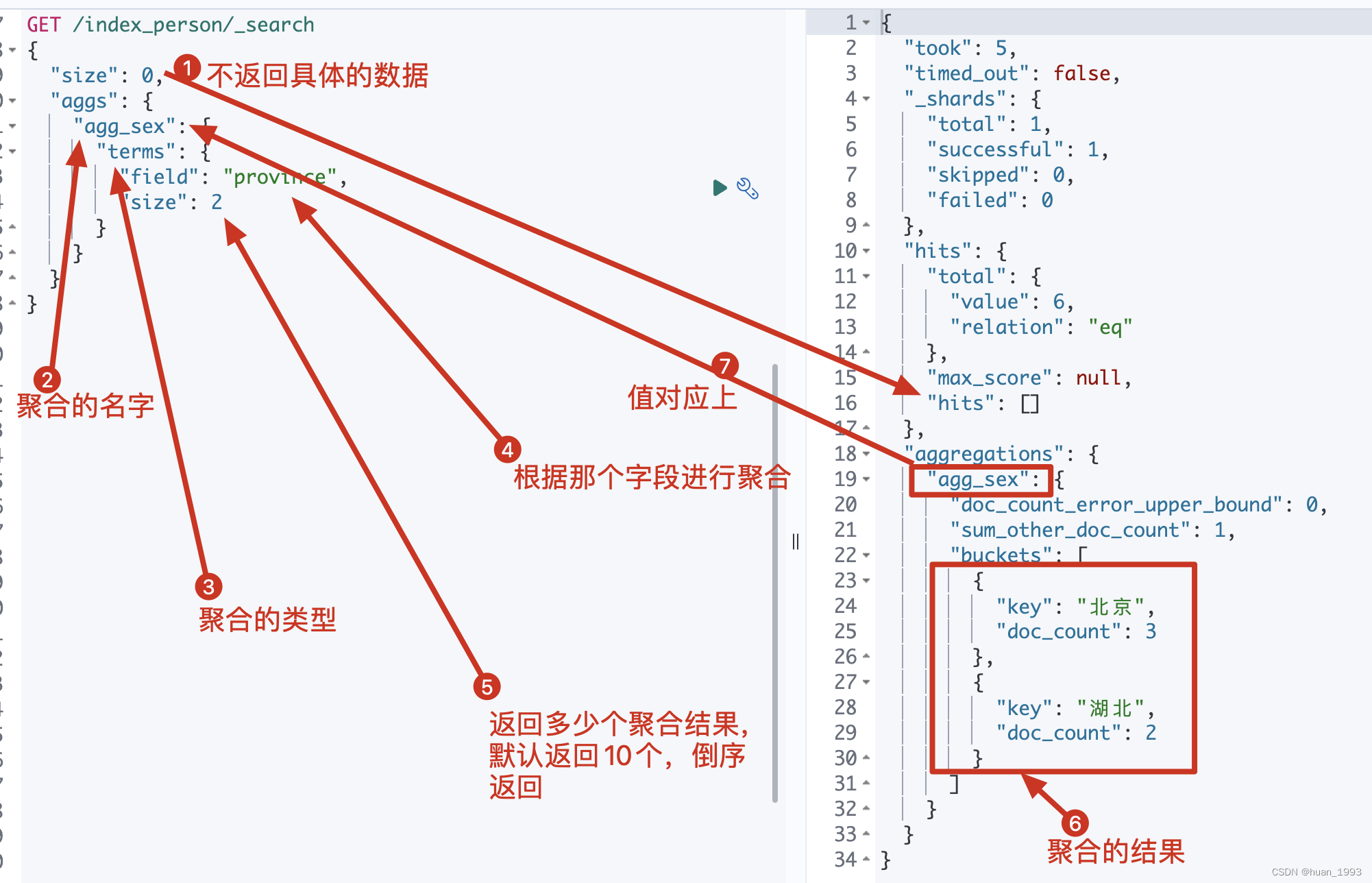
3.1 統計人數最多的2個省
3.1.1 dsl
GET /index_person/_search
{
"size": 0,
"aggs": {
"agg_sex": {
"terms": {
"field": "province",
"size": 2
}
}
}
}
3.1.2 運行結果
3.2 統計人數最少的2個省
3.2.1 dsl
GET /index_person/_search
{
"size": 0,
"aggs": {
"agg_sex": {
"terms": {
"field": "province",
"size": 2,
"order": {
"_count": "asc"
}
}
}
}
}
注意: 不推薦使用 _count:asc來統計,會導致統計結果不準,看下方的總結章節。
3.2.2 運行結果
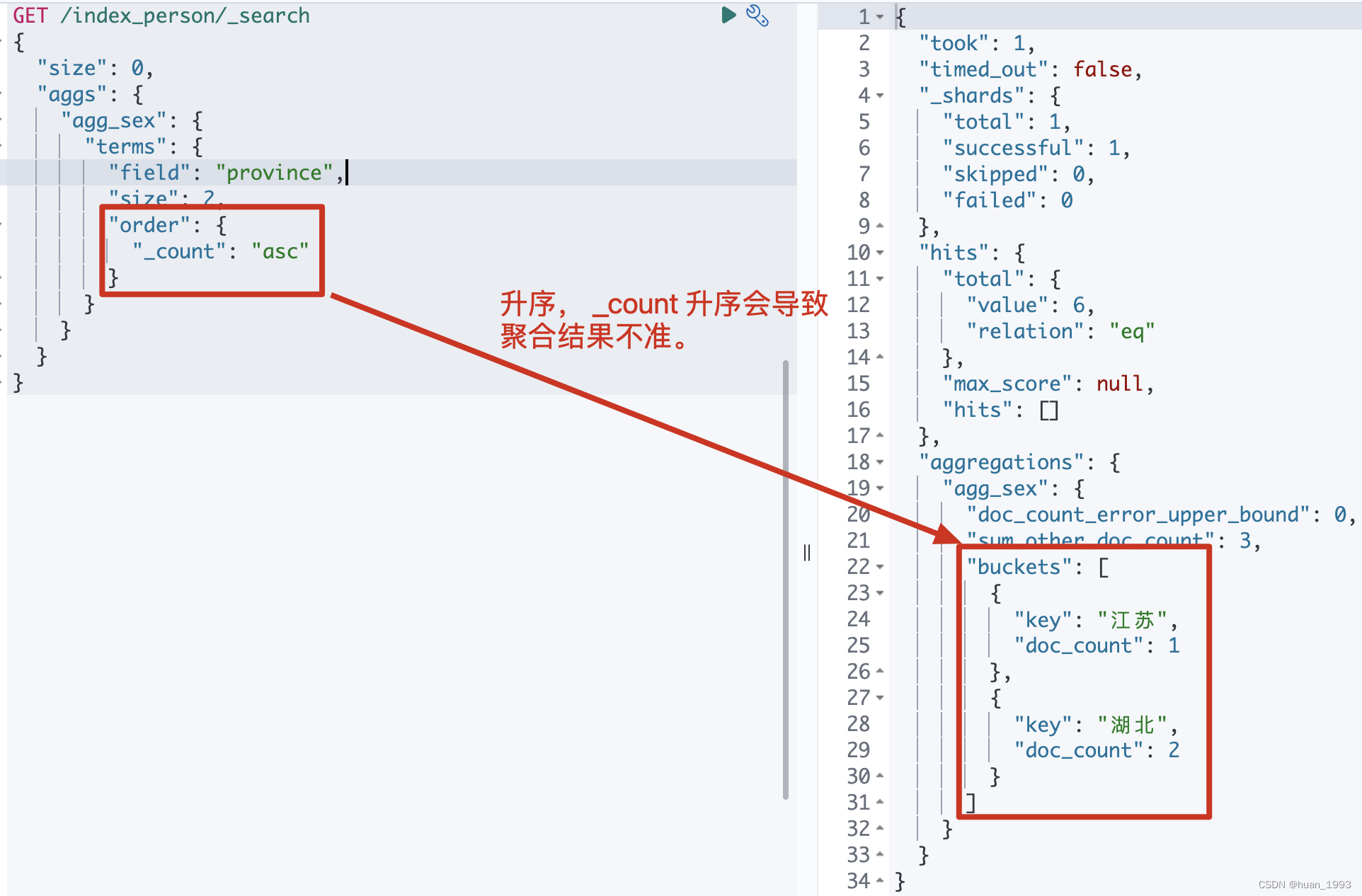
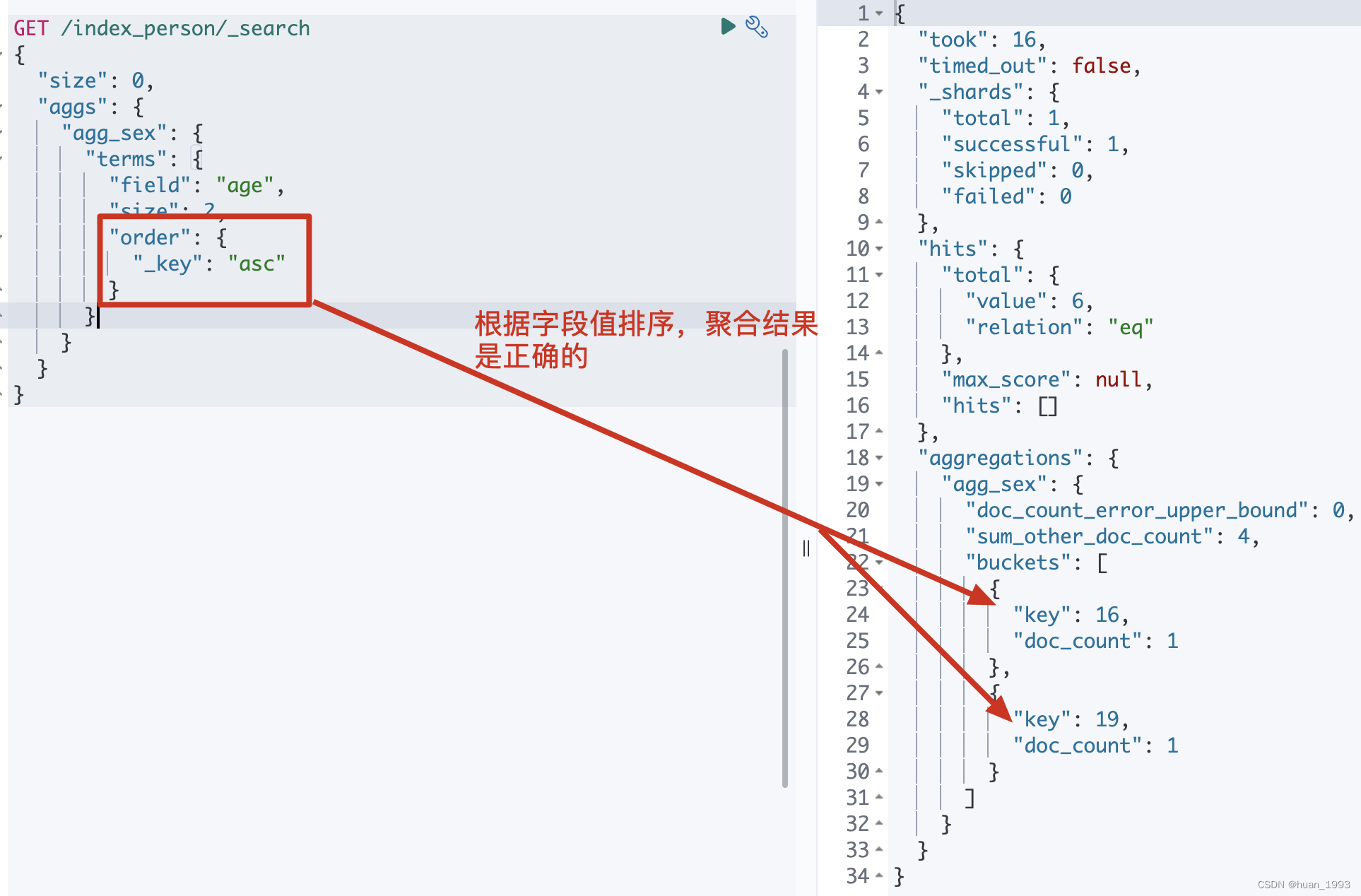
3.3 根據欄位值排序-根據年齡聚合,返回年齡最小的2個聚合
3.3.1 dsl
GET /index_person/_search
{
"size": 0,
"aggs": {
"agg_sex": {
"terms": {
"field": "age",
"size": 2,
"order": {
"_key": "asc"
}
}
}
}
}
注意: 這種根據欄位值來排序,聚合的結果是正確的。
3.3.2 運行結果
3.4 子聚合排序-先根據省聚合,然後根據每個聚合後的最小年齡排序
3.4.1 dsl
GET /index_person/_search
{
"size": 0,
"aggs": {
"agg_sex": {
"terms": {
"field": "province",
"order": {
"min_age": "asc"
}
},
"aggs": {
"min_age": {
"min": {
"field": "age"
}
}
}
}
}
}
GET /index_person/_search
{
"size": 0,
"aggs": {
"agg_sex": {
"terms": {
"field": "province",
"order": {
"min_age.min": "asc"
}
},
"aggs": {
"min_age": {
"stats": {
"field": "age"
}
}
}
}
}
}
注意: 子聚合排序一般也是不準的,但是如果是根據子聚合的最大值倒序和最小值升序又是準的。
3.4.2 運行結果

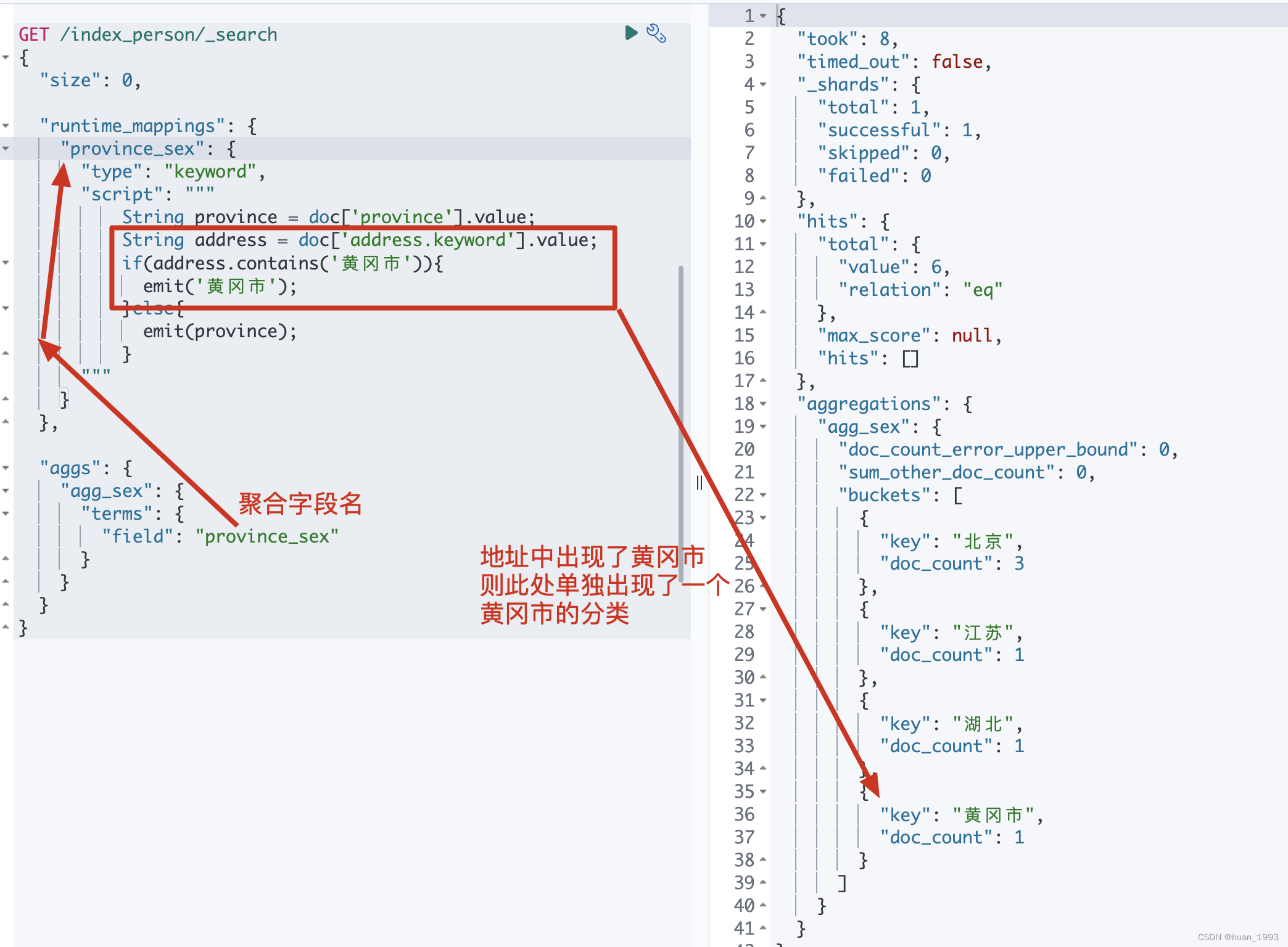
3.5 腳本聚合-根據省聚合,如果地址中有黃岡市則需要出現黃岡市
3.5.1 dsl
GET /index_person/_search
{
"size": 0,
"runtime_mappings": {
"province_sex": {
"type": "keyword",
"script": """
String province = doc['province'].value;
String address = doc['address.keyword'].value;
if(address.contains('黃岡市')){
emit('黃岡市');
}else{
emit(province);
}
"""
}
},
"aggs": {
"agg_sex": {
"terms": {
"field": "province_sex"
}
}
}
}

3.5.2 運行結果
3.6 filter-以省分組,並且只包含北的省,但是需要排除湖北省
3.6.1 dsl
GET /index_person/_search
{
"size": 0,
"aggs": {
"agg_province": {
"terms": {
"field": "province",
"include": ".*北.*",
"exclude": ["湖北"]
}
}
}
}
注意: 當是字元串時,可以寫正則表達式,當是數組時,需要寫具體的值。
3.6.2 運行結果

3.7 多term聚合-根據省和性別聚合,然後根據最大年齡倒序
3.7.1 dsl
GET /index_person/_search
{
"size": 0,
"aggs": {
"genres_and_products": {
"multi_terms": {
"size": 10,
"shard_size": 25,
"order":{
"max_age": "desc"
},
"terms": [
{
"field": "province",
"missing": "defaultProvince"
},
{
"field": "sex"
}
]
},
"aggs": {
"max_age": {
"max": {
"field": "age"
}
}
}
}
}
}
注意: terms聚合默認不支援多欄位聚合,需要藉助別的方式。此處使用multi terms來實現多欄位聚合。
3.7.2 運行結果
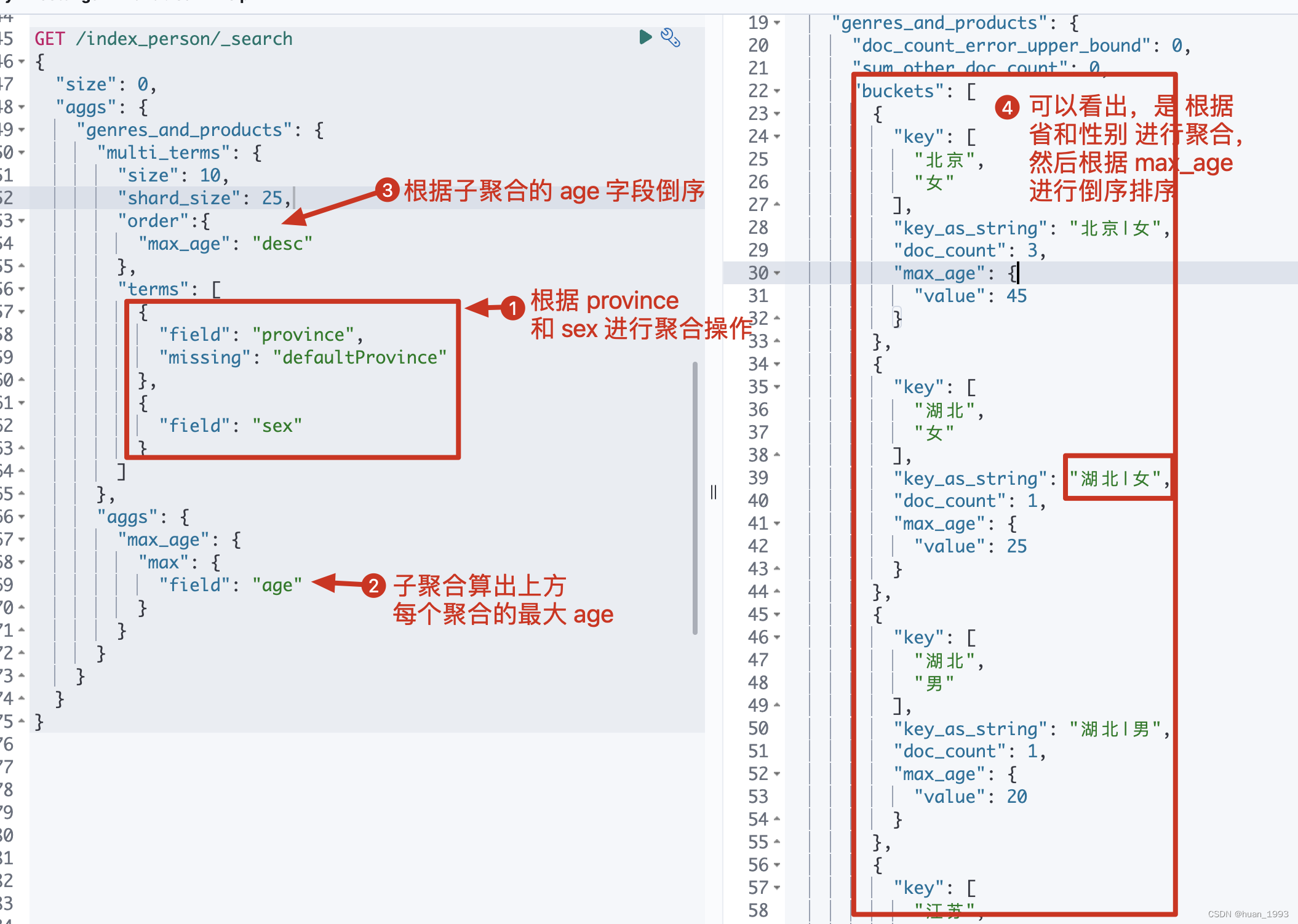
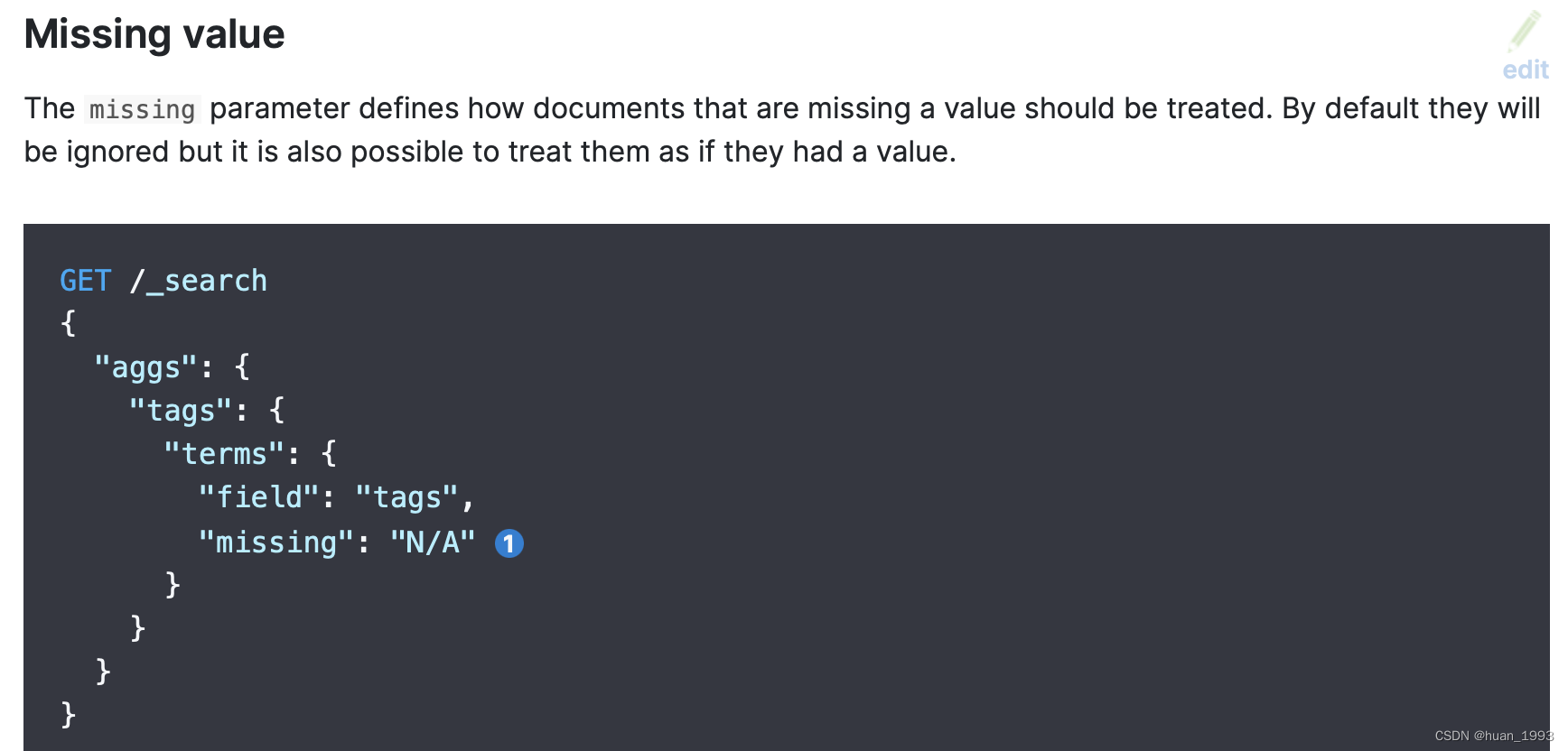
3.8 missing value 處理
3.9 多個聚合-同時返回根據省聚合和根據性別聚合
3.9.1 dsl
GET /index_person/_search
{
"size": 0,
"aggs": {
"agg_province": {
"terms": {
"field": "province"
}
},
"agg_sex":{
"terms": {
"field": "sex",
"size": 10
}
}
}
}
3.9.2 運行結果

4. 總結
4.1 可以聚合的欄位
一般情況下,只有如下幾種欄位類型可以進行聚合操作 keyword,numeric,ip,boolean和binary類型的欄位。text類型的欄位默認情況下是不可以進行聚合的,如果需要聚合,需要開啟fielddata。

4.2 如果我們想返回所有的聚合Term結果
如果我們只想返回100或1000個唯一結果,可以增大size參數的值。但是如果我們想返回所有的,那麼推薦使用 composite aggregation
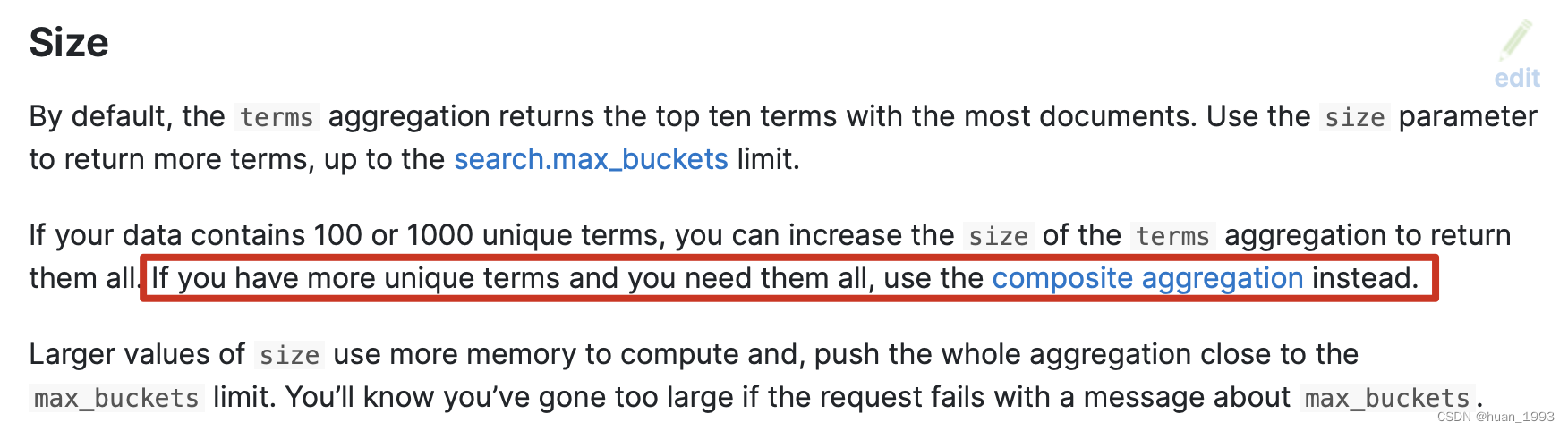
4.3 聚合數據不準
我們通過terms聚合到的結果是一個大概的結果,不一定是完全正確的。
為什麼?.
舉個例子: 如果我們的集群有3個分片,此處我們想返回值最高的5個統計。即size=5,假設先不考慮shard_size參數,那麼此時每個節點會返回值最高的5個統計,然後再次聚合,返回,返回最終值最高的5個。這個貌似沒什麼問題,但是因為我們的數據是分布es的各個節點上的,可能某個統計項(北京市的用戶數),在A節點是是排名前5,但是在B節點上不是排名前5,那麼最終的統計結果是否是就會漏統計了。
如何解決:
我們可以讓es在每個節點上多返回幾個結果,比如:我們的size=5,那麼我們每個節點就返回 size * 1.5 + 10 個結果,那麼誤差相應的就會減少。 而這個size * 1.5 + 10就是shard_size的值,當然我們也可以手動指定,但一般需要比size的值大。

4.4 排序注意事項
4.4.1 _count 排序
默認情況下,使用的是 _count 倒序的,但是我們可以指定成升序,但是這是不推薦的,會導致錯誤結果。如果我們想要升序,可以使用 rare_terms聚合。

4.4.2 欄位值排序
使用欄位值排序,不管是正序還是倒序,結果是準確的。

4.4.3 子聚合排序

4.5 多term聚合

5、源碼地址
6. 參考鏈接
- //www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket-terms-aggregation.html
- //www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket-multi-terms-aggregation.html


