「演算法01」排序演算法小結
- 2020 年 3 月 4 日
- 筆記
排序演算法是一類比較基礎的演算法,也是在學習編程與演算法的過程中必須學習的一類問題。初學者經常在排序時摸不著頭腦,面對一眾的排序,不知從何處下手。下面筆者將以筆記的形式分享一下我在學習演算法時整理的一些排序演算法。
假設現有亂序數組:5, 2, 7, 4, 6, 1, 8, 我們將其排序為升序數組,各種方法過程如下:
1.冒泡排序。
冒泡排序是最簡單的一種排序手段,也是新手最容易想到的一種演算法。它通過每一項與其後面的每一項依次比較,找到最大(最小)值並交換位置,經過一次遍歷,即可將數組排序。其過程大致如下:
首先提取第一個元素5, 與它後面每一項進行比較,找到最小項1,並與其交換位置,得到數組:1, 2, 7, 4, 6, 5, 8。
隨後的第二個元素2, 經比較後發現沒有比2更小的項,數組不變。
再依次提取7, 4, 6, 5,分別與它們後面的每一項進行對比,找到最小項並交換位置,最終數組將按照升序排序,即1, 2, 4, 5, 6, 7, 8。
其程式碼如下:
1 for (int i = 0; i < n - 1; i++) 2 for (int j = i + 1; j < n; j++) 3 if (arr[i] > arr[j]) 4 { 5 int tmp = arr[i]; 6 arr[i] = arr[j]; 7 arr[j] = tmp; 8 }
由執行過程可以看到,冒泡排序執行中需要雙層嵌套循環,一旦需要排序的數組過長,其效率也隨之迅速降低。
在日常使用中,筆者僅在小型數組的排序中使用這種演算法,因為其程式碼簡單直接,工程量比較小,程式碼也易於維護。
2.並歸排序。
並歸排序採用的是分治思想,利用函數的遞歸,將龐大的排序問題逐級化簡,最後並歸得到有序的數組。它的思想是將一個數組一分為二,再將兩個子數組分別排序,再依次比較數組的首項,將較小值依次放入原數組中,最終得到有序數組。其過程大致如下:
首先將數組拆分為array1:5, 2, 7, 4, 和array2:6, 1, 8, 分別對這兩個數組進行排序:array1:2, 4, 5, 7, 和array2:1, 6, 8。
再將兩個數組並歸為一個數組:首先比較兩個數組的首項:由於1 < 2,將array2中的1提取,歸入原數組。再比較兩個數組的首項:由於2 < 6,本次提取值為2。。。以此類推。同時,為了防止數組發生越界問題,需要在數組末項之後人為添加一個無窮項,保證該項大於數組中的每一項,從而防止數組越界的現象發生。經過並歸過程後,原數組排序完成。
但是這裡會引出一個問題,該如何排序這兩個子數組呢?這裡便需要用到遞歸的思想。我們可以讓函數調用它自身從而完成對拆分開來的子項的排序。
但這樣又會產生接下來的問題,該如何控制遞歸結束?這裡由於最後無窮項的存在,當數組長度為2時,數組內有效值便只有一個,在此時,遞歸結束,將這項返回,交由函數下面的內容完成並歸操作。
其程式碼如下:
1 void merge(int* arr, int n) //由於採用指針傳遞的方式,函數將直接對原地址進行操作,故函數被定義為無返回值 2 { 3 if (n > 1) //筆者的函數傳遞的n是數組長度,當數組長度大於1,數組可以被繼續拆分,繼續遞歸若等於1,無法拆分,遞歸結束 4 { 5 int* arr1 = new int[n / 2 + n % 2 + 1], * arr2 = new int[n / 2 + 1]; //開闢新數組,為了添加無窮項防止越界,每一個數組長度增加1位 6 for (int i = 0; i < n / 2 + n % 2; i++) 7 arr1[i] = arr[i]; 8 arr1[n / 2 + n % 2] = 100; //筆者程式碼排序的數組最小項為0, 最大項為99, 故將無窮項設置為100 9 for (int i = n / 2 + n % 2; i < n; i++) 10 arr2[i - n / 2 - n % 2] = arr[i]; 11 arr2[n / 2] = 100; 12 merge(arr1, n / 2 + n % 2); //遞歸排序子數組 13 merge(arr2, n / 2); 14 for (int i = 0, j = 0, k = 0; i < n; i++) //將兩個子數組並歸 15 if (arr1[j] <= arr2[k]) 16 { 17 arr[i] = arr1[j]; 18 j++; 19 } 20 else 21 { 22 arr[i] = arr2[k]; 23 k++; 24 } 25 } 26 delete[] (arr1); //釋放由new申請的記憶體
27 delete[] (arr2);
28 }
並歸排序採用了遞歸的方式,由於無需雙重循環,其執行效率相較冒泡排序在處理長數組時有所提升。但是由於其程式碼相對複雜,筆者在日常使用中不常使用這種演算法。
3.堆排序。
堆排序利用了堆的性質,通過維護一個最大堆或最小堆,提取堆頂元素放入原數組完成排序。
這裡首先要理解二叉堆的性質:二叉堆是一個數組,可以近似為一個完全二叉樹。
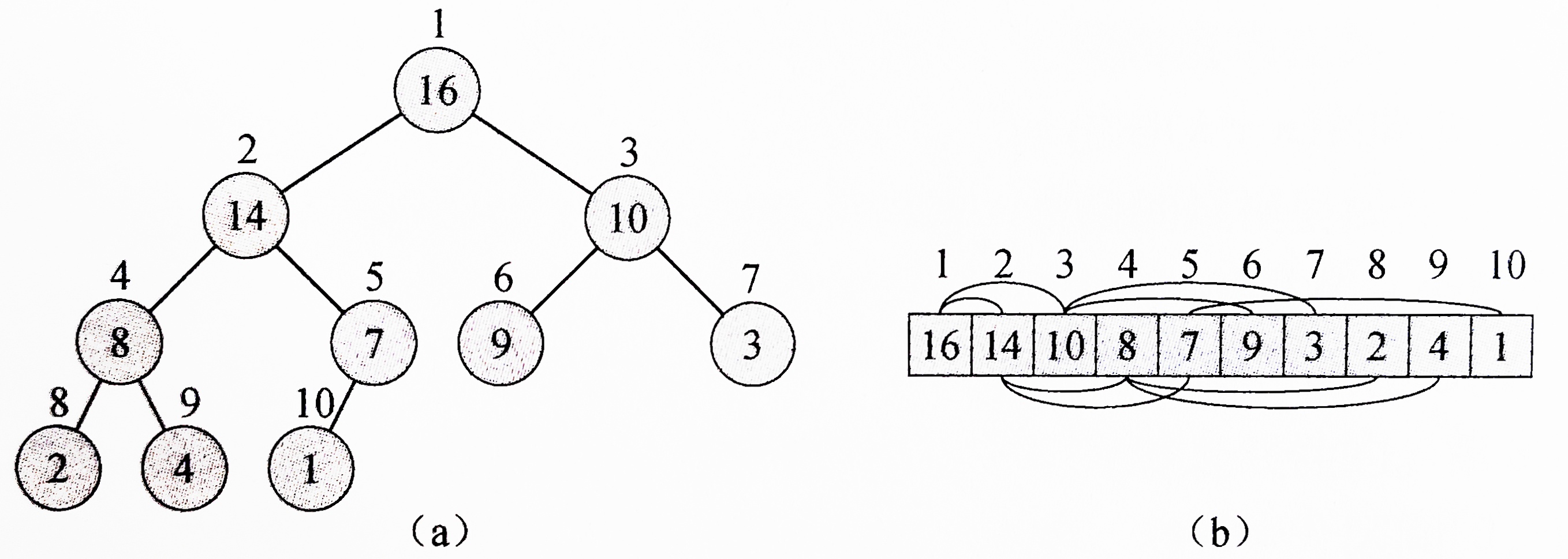

如圖為一個最大堆,a為展開為樹的形態,b為數組形態。由堆的對應關係容易得到,任意節點的下標除以2即可得到其父節點的下標,而父節點下標乘2可獲得子節點的左節點,乘2加1可獲得右節點,而這個最大堆的根是最大值。
若要維護堆的性質,需要自上而下比較,找到父節點與兩個子節點中的最大項,將最大的值與父節點交換位置,直到到堆的底層結束。
而建立堆的過程就是對堆的每一個節點執行維護堆的過程。而每次取出根節點,便需要重新執行維護堆,以確保堆始終為最大堆。
其程式碼如下:
1 void heap(int* arr, int n) //利用堆進行排序,筆者傳值方式採用指針,無返回值 2 { 3 for (int i = n / 2; i >= 0; i--) //建堆,自下而上對每一個非底層節點執行維護,確保最終得到最大堆 4 heapify(arr, i, n); 5 for (int i = n - 1; i >= 1; i--) //依次取出堆頂最大值,插入數組末端 6 { 7 int tmp = arr[i]; //用堆底層值替換掉頂層值,從而取出頂層值 8 arr[i] = arr[0]; 9 arr[0] = tmp; 10 heapify(arr, 0, --n); //由於取出最大值後,堆被破壞,重新維護,而此時需要維護的堆長度應該減1,因為末項已經是我們需要的值,因此從堆中剔除 11 } 12 } 13 14 void heapify(int* arr, int n, int size) //維護堆的性質 15 { 16 int largest, l, r; //分別為最大的節點,左節點,右節點 17 l = n * 2; 18 r = n * 2 + 1; 19 if (l < size && arr[l] > arr[n]) //兩次判斷,比較出三個節點中最大值的下標 20 largest = l; 21 else 22 largest = n; 23 if (r < size && arr[r] > arr[largest]) 24 largest = r; 25 if (largest != n) //如果父節點不是最大值,交換最大值到父節點,重新維護子節點所在分支堆的性質 26 { 27 int tmp = arr[n]; 28 arr[n] = arr[largest]; 29 arr[largest] = tmp; 30 heapify(arr, largest, size); 31 } 32 }
堆排序同樣利用了遞歸的思想,效率相對較高,其主要時間消耗在建堆的過程,後期僅需要循環取值,重新維護堆即可。但是堆排序亦或是建堆,可以用於決策演算法等其它演算法,這是堆的獨特優勢,因此我們在大型項目可以重複利用建堆程式碼,發揮其獨到優勢,減少工程量。
4.快速排序。
快速排序,顧名思義它是排序速度最快的排序方式。它也利用了遞歸的思想。同並歸排序類似,它通過將數組一分為二,兩側分別排序,從而達到排序的目的。但與並歸不同的是,快速排序沒有後期並歸的過程。在拆分數組的過程中,快速排序可以做到一側的最大值小於另一側的最小值,故最後無需比較,直接連接即可。其思想如下:
首先取數組末尾值為中間值,對數組前面的所有值依次比較,小於該中間值的向前移動,大於的向後移動。即,當一個值小於中間值,它會與大於中間值部分的下標最小的值進行交換,同時令大於中間值部分的下標加一,實現大於中間支部分的移動。而當一個值大於中間值時,將大於中間值部分擴張包含該值即可。當大於中間值部分移動到中間值處,將中間值移動至兩個子數組之間。至此,中間值左側所有值都小於中間值,中間值右側所有值都大於中間值。將中間值兩側的數組再次分別排序,直到數組不可在分,排序結束。
其程式碼如下:
1 void quick(int* arr, int m, int n) //快速排序遞歸部分 2 { 3 if (m < n) 4 { 5 int i = partition(arr, m, n); //每次遞歸尋找中間值下標,再依次遞歸中間值左側與右側部分 6 quick(arr, m, i - 1); 7 quick(arr, i + 1, n); 8 } 9 } 10 11 int partition(int* arr, int m, int n) //快速排序處理數組部分 12 { 13 int x = arr[n]; //數組末尾值作為中間值 14 int i = m - 1; //i用於小於中間值部分下標的計數 15 for (int j = m; j < n; j++) //遍曆數組,將值歸檔 16 { 17 if (arr[j] <= x) //對大於中間值的值的處理 18 { 19 i++; 20 int tmp = arr[i]; 21 arr[i] = arr[j]; 22 arr[j] = tmp; 23 } 24 } 25 int tmp = arr[i + 1]; //將中間值插入兩個子數列之間 26 arr[i + 1] = arr[n]; 27 arr[n] = tmp; 28 return i + 1; //返回中間值 29 }
快速排序是運行效率極高的一種排序演算法,在處理大型數組時極其有效,而且演算法消耗的記憶體少,適合對性能有要求的項目。當然,對於小型數組的排序很難體現快速排序的優越性,微小型數組排序更多還是冒泡等相對簡單的排序比較方便開發。
5.線性時間排序。
線性時間排序是一類特殊的排序演算法,這類演算法不是簡單的依賴比較數組元素的大小,而是巧妙地利用數組的下標對其進行排序。其時間消耗隨著需要排序的數組的特點會有所變化,有時效率會很高,甚至超過快速排序,而有時效率則一般。但是這類演算法普遍的特點是會有記憶體消耗,記憶體的開銷會大於快速排序,因此僅適用於特定數據的排序,不如快速排序普適。
計數排序
計數排序適用於一個連續正整數數組,數組的連續性越強,其效率也就越高。
計數排序巧妙地將數組的元素當作數組下標,開闢一個新數組,利用數組元素充當新數組的下標,利用新數組的值來計數,最後直接將新數組的下標從小到大按統計的數量輸出,完成排序。
其程式碼如下:
1 void count(int* arr, int n) 2 { 3 int max = arr[0]; 4 for (int i = 1; i < n; i++) //找出數組最大值 5 if (arr[i] > max) 6 max = arr[i]; 7 max++; 8 int* tmp = new int[n]; 9 int* count = new int[max]; 10 for (int i = 0; i < max; i++) //數組初始化 11 count[i] = 0; 12 for (int i = 0; i < n; i++) //將數組下標用於計數 13 count[arr[i]]++; 14 for (int i = 1; i < max; i++) //統計每個下標的排位 15 count[i] += count[i - 1]; 16 for (int i = n - 1; i > 0; i--) //重新寫回原數組 17 { 18 tmp[count[arr[i]]] = arr[i]; 19 count[arr[i]]--; 20 } 21 for (int i = 0; i < n; i++) 22 arr[i] = tmp[i]; 23 delete[] (tmp); //釋放空間 24 delete[] (count); 25 }
基數排序:
基數排序同樣適用於連續正整數數組,與計數排序不同的是,基數排序數組最大值位數越低,其排序效率越高。
基數排序也是將數組元素作為下標,依次統計在每一位上的數據的數量,經過多次循環排序統計後,可以得到有序數組。
其程式碼如下:
1 void radix(int* arr, int n) 2 { 3 int max = arr[0]; //找到最高為位數 4 for (int i = 1; i < n; i++) 5 if (arr[i] > max) 6 max = arr[i]; 7 int digit = 0; 8 while (max > 10) 9 { 10 max /= 10; 11 digit++; 12 } 13 int* tmp = new int[n]; //用於存儲中間數據 14 int* count = new int[10]; //用於位數的統計 15 for (int i = 0, radix = 1; i <= digit; i++, radix *= 10) 16 { 17 for (int j = 0; j < 10; j++) //初始化統計數組 18 count[j] = 0; 19 for (int j = 0; j < n; j++) //位數數量統計 20 { 21 int k = (arr[j] / radix) % 10; 22 count[k]++; 23 } 24 for (int j = 1; j < 10; j++) 25 count[j] += count[j - 1]; 26 for (int j = n - 1; j >= 0; j--) //將一輪排列的值寫入中間數組 27 { 28 int k = (arr[j] / radix) % 10; 29 tmp[count[k] - 1] = arr[j]; 30 count[k]--; 31 } 32 for (int j = 0; j < n; j++) //將中間數組值寫回 33 arr[j] = tmp[j]; 34 } 35 delete[] (tmp); //釋放空間 36 delete[] (count); 37 }
以上就是筆者最近統計的一些排序演算法,同時筆者也在不斷學習其它的演算法。歡迎指正。
(演算法參考自《演算法導論(原書第三版)》–機械工業出版社)